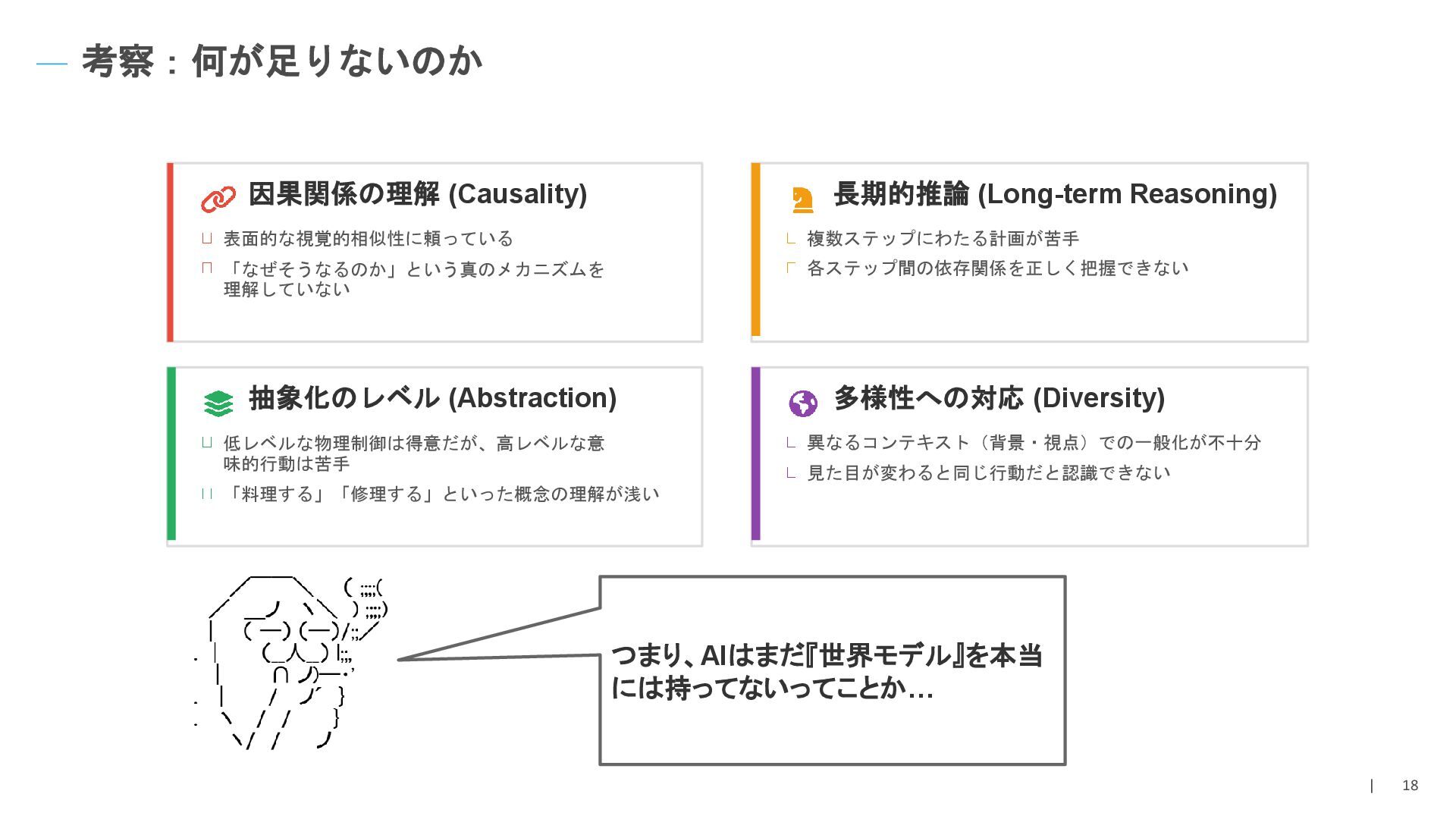
Long-horizon Procedural Planning Delong Chen, Willy Chung, Yejin Bang, Ziwei Ji, Pascale Fung 「今更『世界の予測』かお? 動画生成AIならSoraとかでもも う完璧じゃないかお? この論文、読む必要あるか?」 「その考えが甘いんだろ、常識 的に考えて。ピクセル生成で出 来ることと、因果関係を理解し て計画でることは別物だ。 Meta FAIRと香港科技大の 『 WorldPrediction 』で現実をみ せてやる」
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}