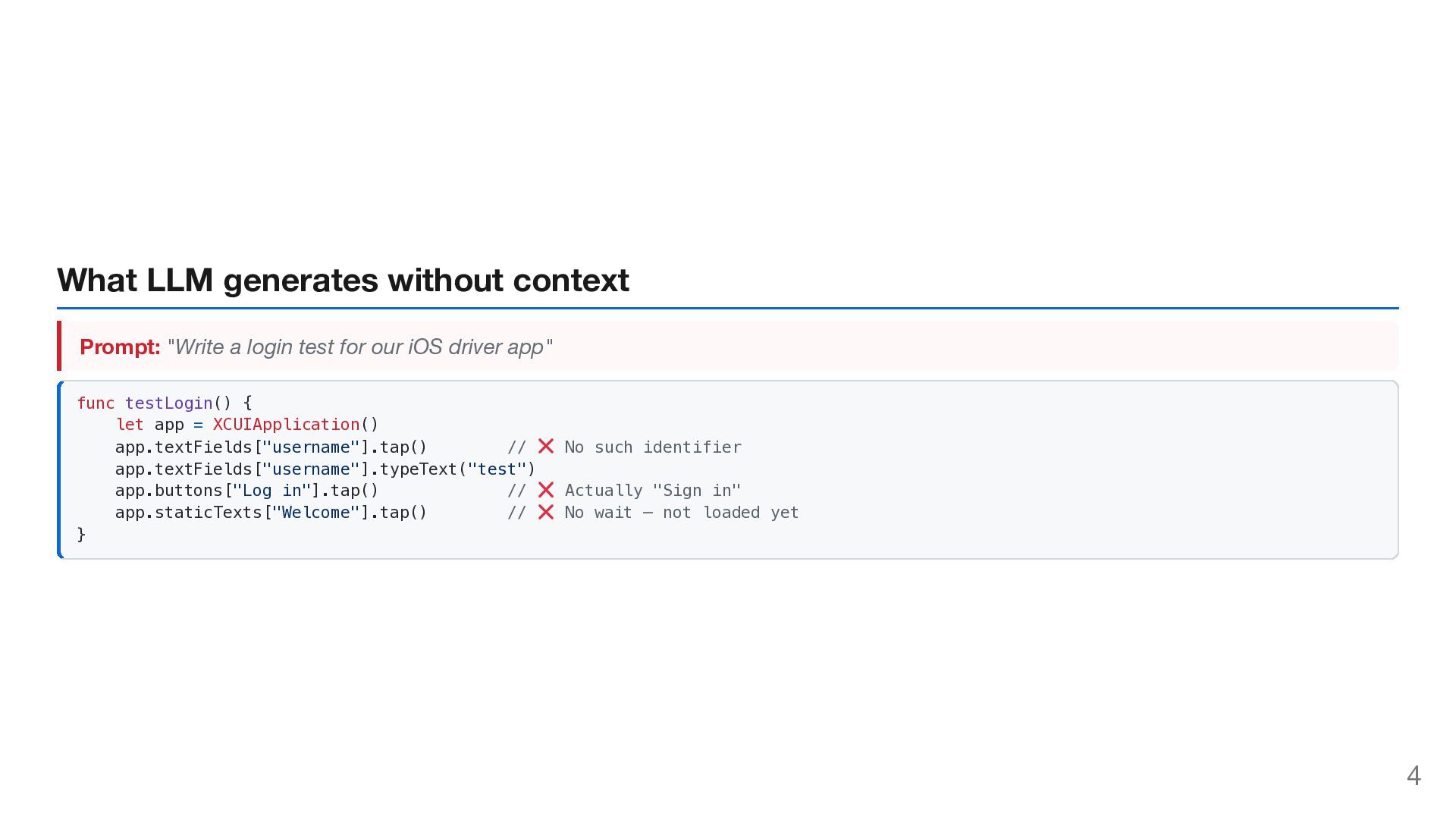
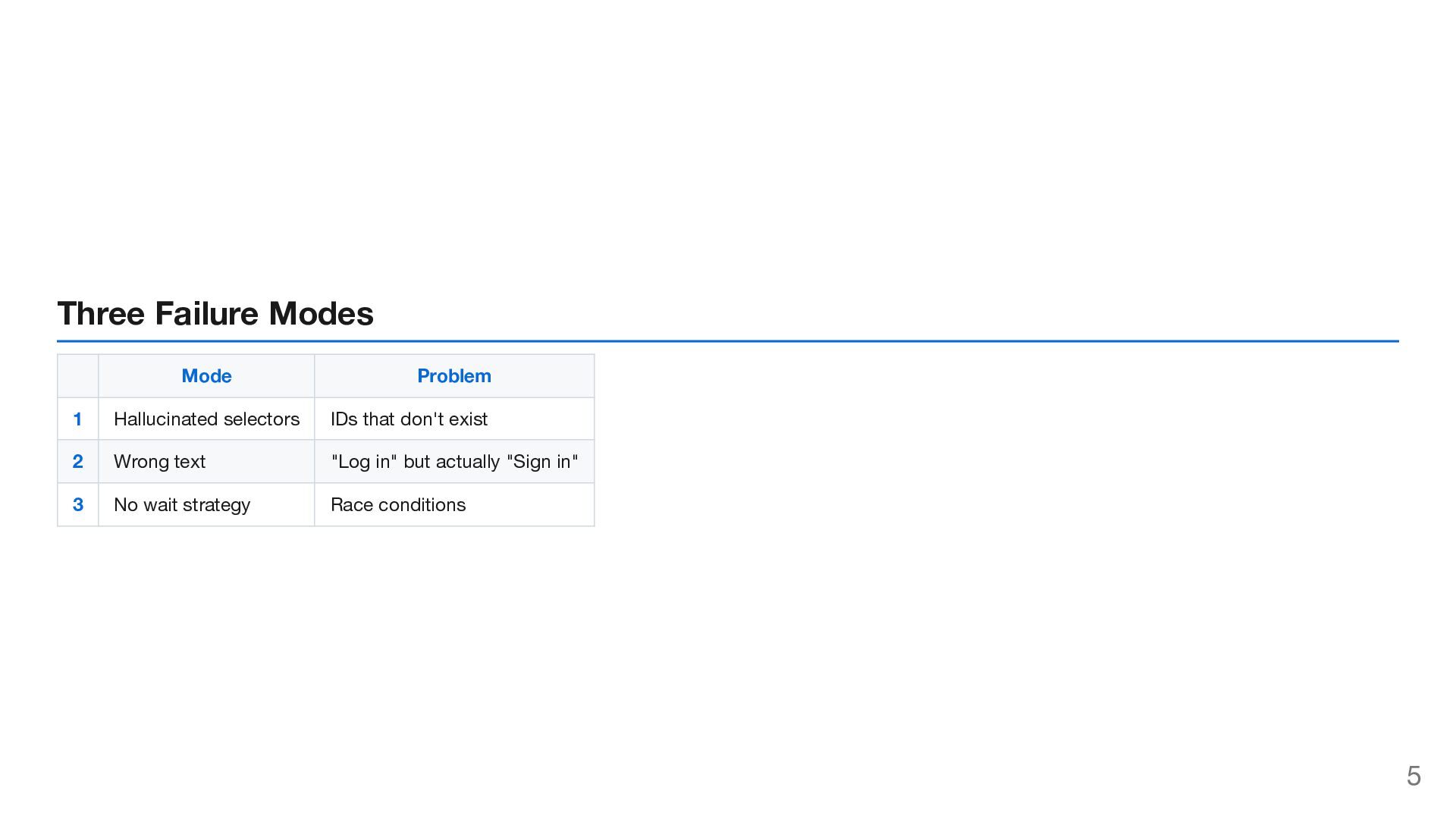
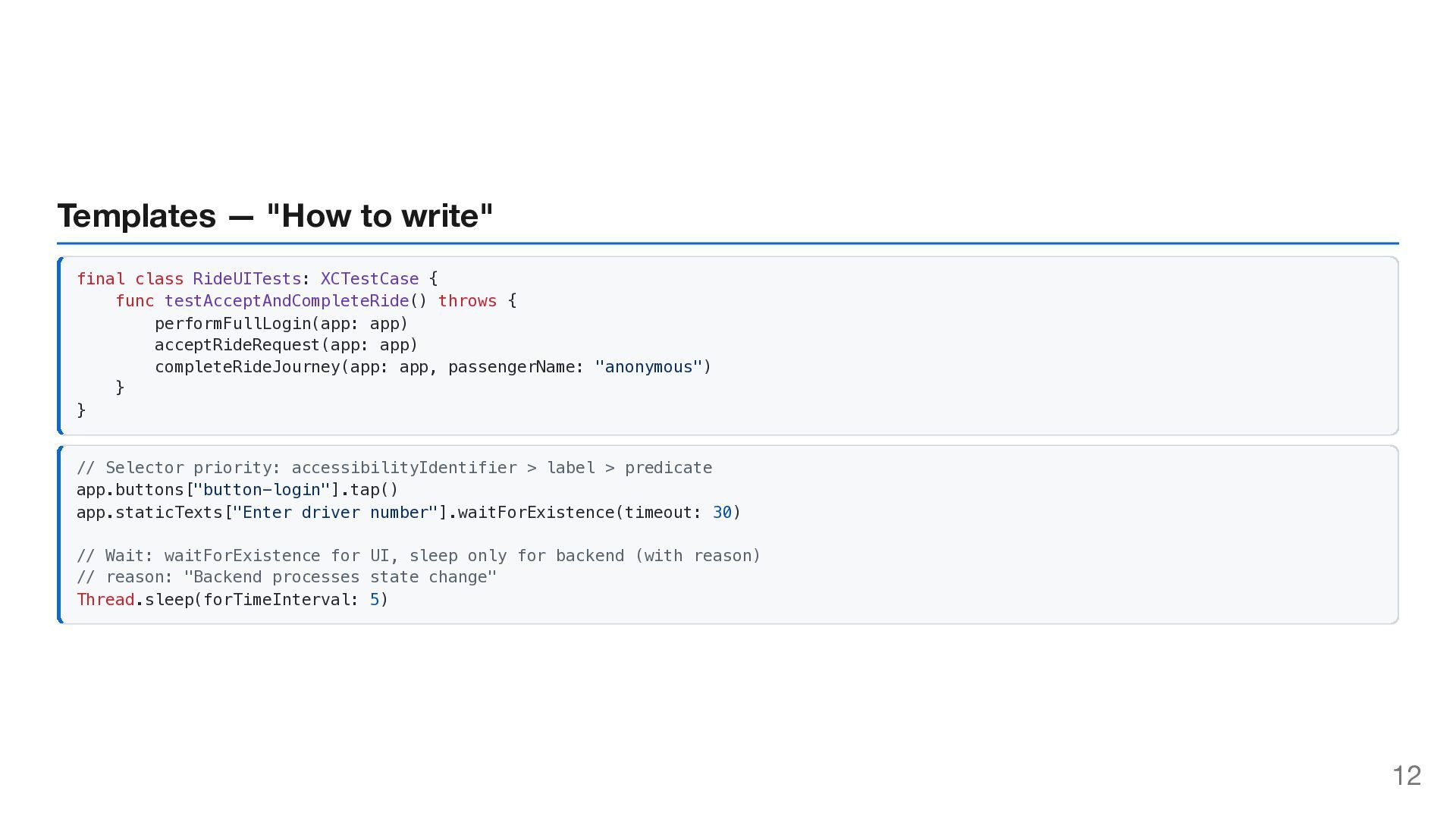
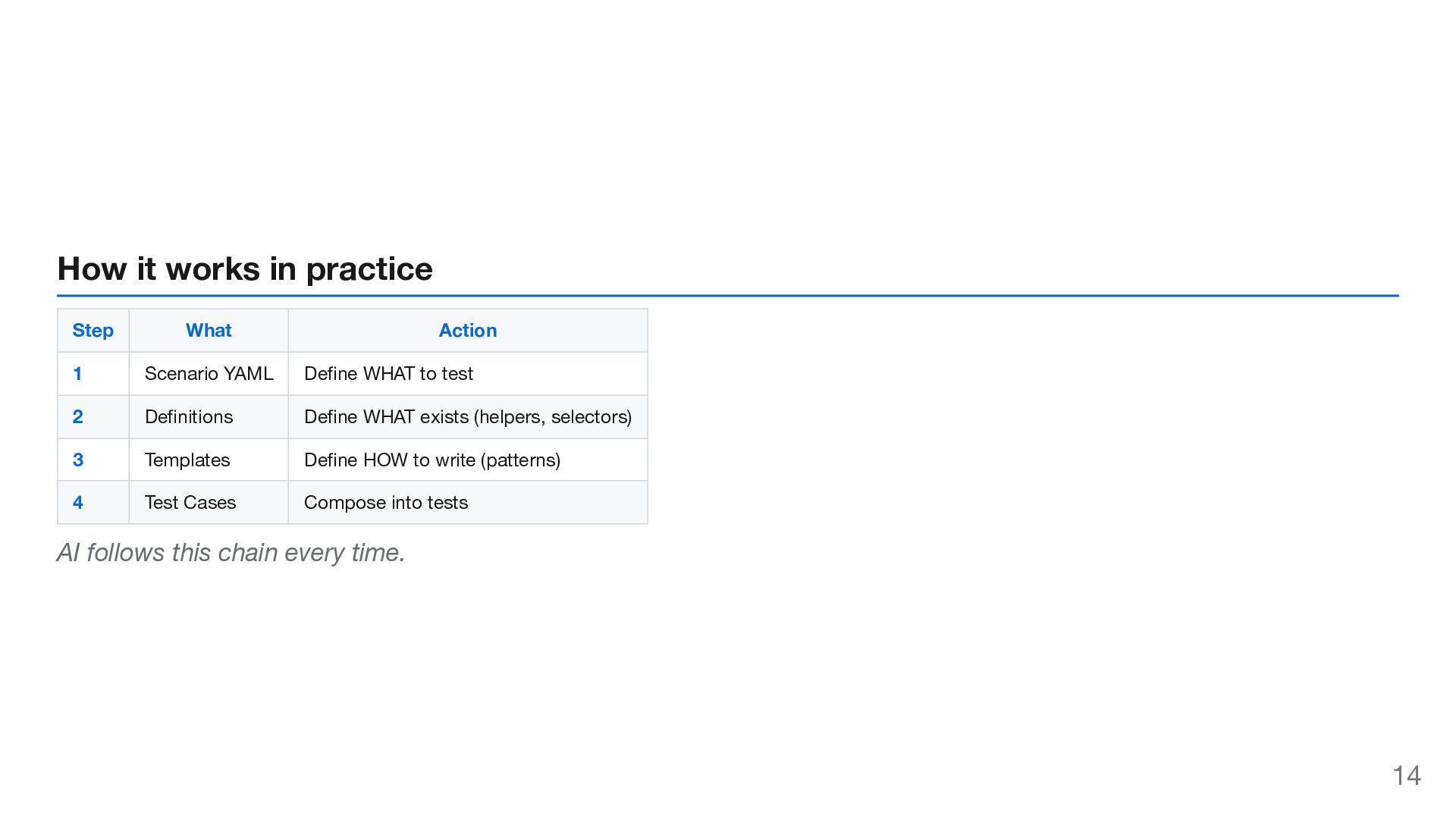
YAML Define WHAT to test 2 Definitions Define WHAT exists (helpers, selectors) 3 Templates Define HOW to write (patterns) 4 Test Cases Compose into tests AI follows this chain every time. 14
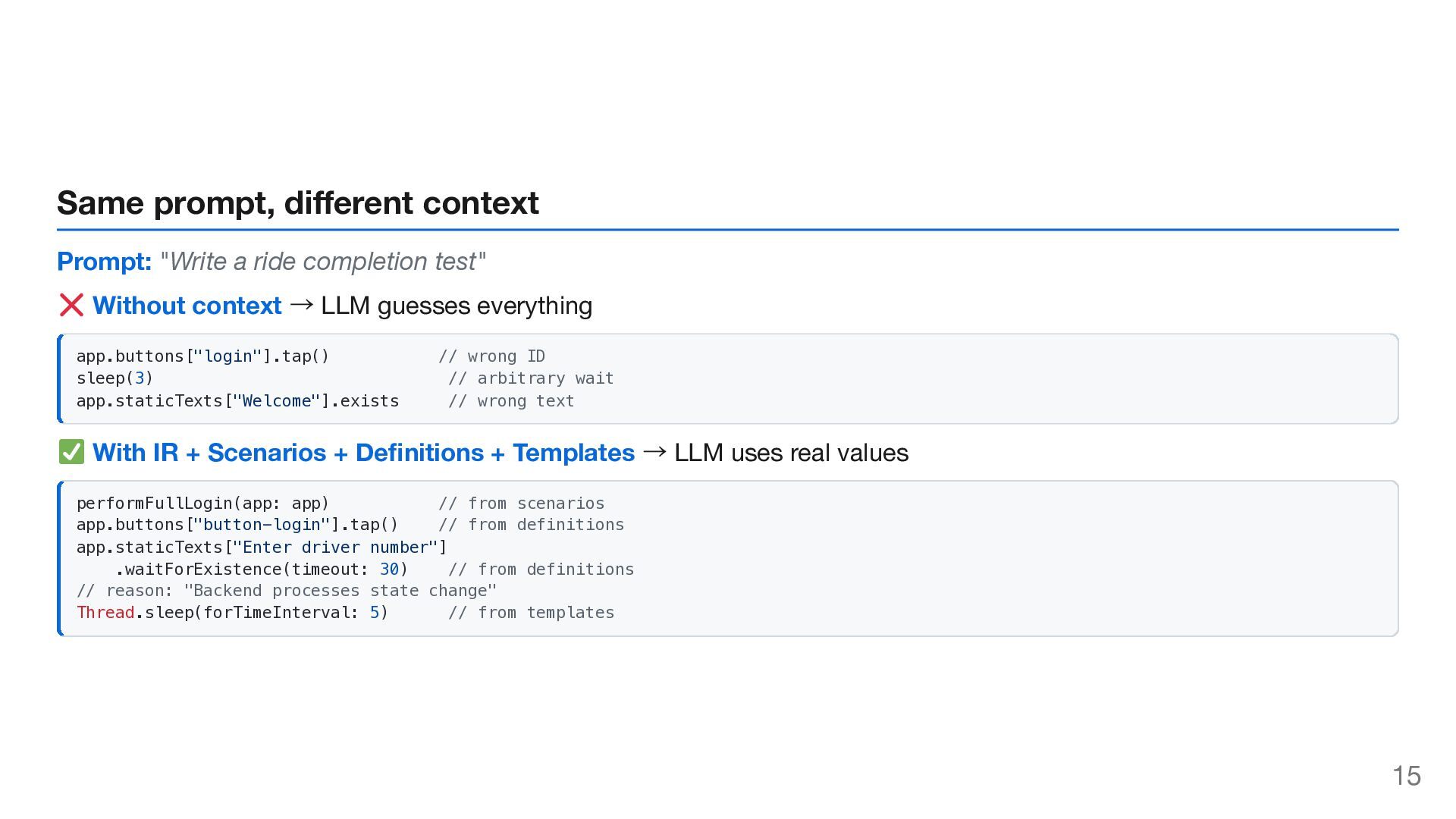
LLM selectors, definitions, patterns — not just instructions. 2. Single Source of Truth Update once → all tests benefit. Humans and AI read the same source. 3. Context Prevents Hallucination AI knows what to test, what exists, and how to write → no guessing. 18
before any code is generated Single source of truth — update one file, all tests stay consistent Onboarding — new members read structured files, not ask around 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}