より大きいとき, growth function は d の多 項式オーダーになることを保証 Lemma 1 (Sauer’s Lemma (Lemma 2.1)) ▶ |Y| = 2, ▶ H = {h : X → Y}, ▶ V Cdim(H) = d このとき, n ≥ d に対して ΠH(n) ≤ en d d = O(nd) 10
Learning ΠH (x1 , ..., xn ) ≤ (⋄) d i=0 n i ≤ d i=0 n i n d d−i ≤ n i=0 n i n d d−i = n i=0 n i n d d−i n d i d n i = n d d n i=0 n i d n i (1+ d n )n = n d d 1 + d n n (∵) 1 + d n n → ed as n → ∞ → ≤ n d d ed 2 11
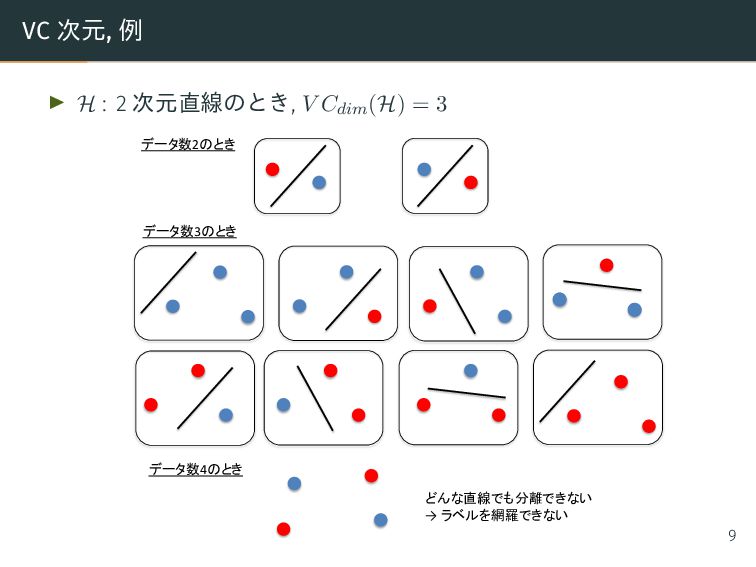
VC 次元の上界を計算 ▶ S1 , S2 : S = {x1 , ..., xd+2 } ⊂ Rd の Radon partition ▶ true label : yi = +1 if xi ∈ S1 −1 if xi ∈ S2 ▶ true label に正答する線形判別器 h ∈ H が存在すると仮定: h(xi ) = +1 if xi ∈ conv(S1 ) −1 if xi ∈ conv(S2 ) ▶ しかし, h は x ∈ conv(S1 ) ∩ conv(S2 ) に対してはどちらのラベルも付 与してしまい矛盾 → d + 2 個の入力点のラベル付けは線形判別器では網羅できない → V Cdim(H) ≤ d + 1 ▶ 一方, 線形判別器の VC 次元は V Cdim(H) ≥ d + 1 を満たすから, 両者 を合わせると V Cdim(H) = d + 1 を得る 24
i=1 : input data ▶ H = {h : X → {+1, −1}} : 仮説集合 with VCdim(H) = d ▶ A = {(h(x1), ..., h(xn)) ∈ {+1, −1}n | h ∈ H} このとき, n ≥ d ならば, |A| = ΠH(x1, ..., xn) ≤ max x1,...,xn ΠH(x1, ..., xn) growth function ≤ Sauer en d d が成立. S における H の経験ラデマッハ複雑度は ˆ RS(H) = 1 n Eσ sup h∈H n i=1 σih(xi) = 1 n Eσ sup z∈A n i=1 σizi ≤ 2d n log en d 最後の不等式は Massart’s lemma を使った. 45
⊂ Rm : finite set ▶ r = maxx∈A x 2 ▶ σ1, ..., σm ∼i.i.d. Unif({+1, −1}) このとき, 以下が成立 Eσ 1 m sup x∈A m i=1 σixi ≤ r 2 log |A| m xi として zi ∈ {+1, −1} ( z = √ n) をとれば, 1 n Eσ sup z∈A n i=1 σizi ≤ √ n 2 log |A| n ≤ 2 n log en d d = 2d n log en d がいえる. 46
w⊤x | w ∈ Rd, w ≤ Λ} の経験ラデマッハ複雑度 ˆ RS (G) = Eσ 1 n sup ∥w∥≤Λ n i=1 σi w⊤xi = Eσ 1 n sup ∥w∥≤Λ w⊤ n i=1 σi xi = (⋄) 1 n Eσ Λ n i=1 σi xi ( ) Claim sup∥x∥≤r |x⊤y| = r y ∵ (≤) Cauchy-Schwartz 不等式より, |x⊤y| ≤ x y ≤ r y . (≥) x = r ∥y∥ y ととると, x ≤ r で, |x⊤y| = r y y ⊤ y = r y y y = r y が成立 (2 つめの等号は, Cauchy-Schwarz 不等式の等号成立条件 (∃λ s.t. x = λy) による). 特に, |x⊤y| ≥ r y . 51
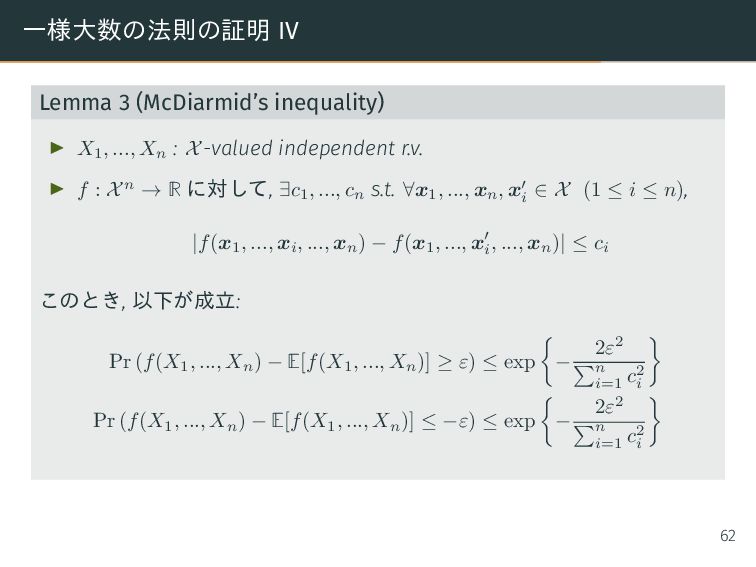
(Azuma’s inequality) ▶ Xi , Zi , Vi : r.v. (1 ≤ i ≤ n) ▶ Vi = V (X1 , ..., Xi ) s.t. E[Vi | X1 , ..., Xi−1 ] = 0 ▶ Zi = Z(X1 , ..., Xi−1 ) s.t. ∃c1 , ..., cn , Zi ≤ Vi ≤ Zi + ci このとき, ∀ε > 0, Pr n i=1 Vi ≥ ε ≤ exp − 2ε2 n i=1 c2 i Pr n i=1 Vi ≤ −ε ≤ exp − 2ε2 n i=1 c2 i が成立. 59
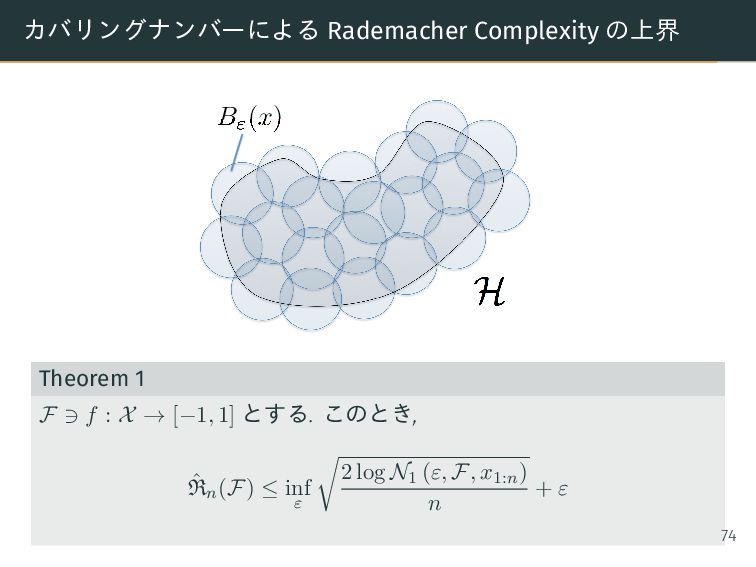
i=1 を点集合, V ⊂ Rn とする. 任意の f ∈ H に対して, v ∈ V が存在して, 1 n n i=1 |vi − f(xi)|p 1/p ≤ ε を満たすとき, V を H の p-次 ε-cover と呼ぶ Definition 6 (covering number) H の p-次 covering number は以下で定義される Np(ε, H, n) = sup x1:n min{|V | | V : H の x1:n 上の p-次 ε-cover} 73
minimal cover V を 1 つ固定する. Uε(v) = {f ∈ F | f : ε-covered by v} とする. このとき, ∪v∈V Uε(v) = F より以下が成立. ˆ Rn(F) = E sup f∈F 1 n n i=1 σif (xi) = E sup v∈V sup f∈Uε(v) 1 n n i=1 σif (xi) = E sup v∈V sup f∈Uε(v) 1 n n i=1 σivi + 1 n n i=1 σi (f (xi) − vi) ≤ E sup v∈V 1 n n i=1 σivi + E sup v∈V sup f∈Uε(v) 1 n n i=1 σi (f (xi) − vi) 75
to statistical learning theory. In Advanced lectures on machine learning, pages 169–207. Springer, 2004. [2] Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar. Foundations of machine learning. MIT press, 2012. [3] Shai Shalev-Shwartz and Shai Ben-David. Understanding machine learning: From theory to algorithms. Cambridge university press, 2014. [4] 金森敬文. 統計的学習理論 (機械学習プロフェッショナルシリーズ). 講談社, 2015. 78
![統計的学習理論読み(Chapter 2) 松井孝太 名古屋大学大学院医学系研究科 生物統計学分野 [email protected]](https://files.speakerdeck.com/presentations/7ef8eda5c51a49599c78ebe44135741e/slide_0.jpg){kind=link}
{kind=link}
![導入 本スライドは [4] の第 2 章のまとめである. ▶ 仮説空間の複雑さの指標: VC 次元,](https://files.speakerdeck.com/presentations/7ef8eda5c51a49599c78ebe44135741e/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![一様大数の法則の証明 X 次に, E[A(Z1 , ..., Zn )] を評価する. Z1](https://files.speakerdeck.com/presentations/7ef8eda5c51a49599c78ebe44135741e/slide_68.jpg){kind=link}
![一様大数の法則の証明 XI Fact より, Eσ,Z [A(Z1 , ..., Zn )]](https://files.speakerdeck.com/presentations/7ef8eda5c51a49599c78ebe44135741e/slide_69.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [1] Olivier Bousquet, Stéphane Boucheron, and Gábor Lugosi. Introduction](https://files.speakerdeck.com/presentations/7ef8eda5c51a49599c78ebe44135741e/slide_78.jpg){kind=link}