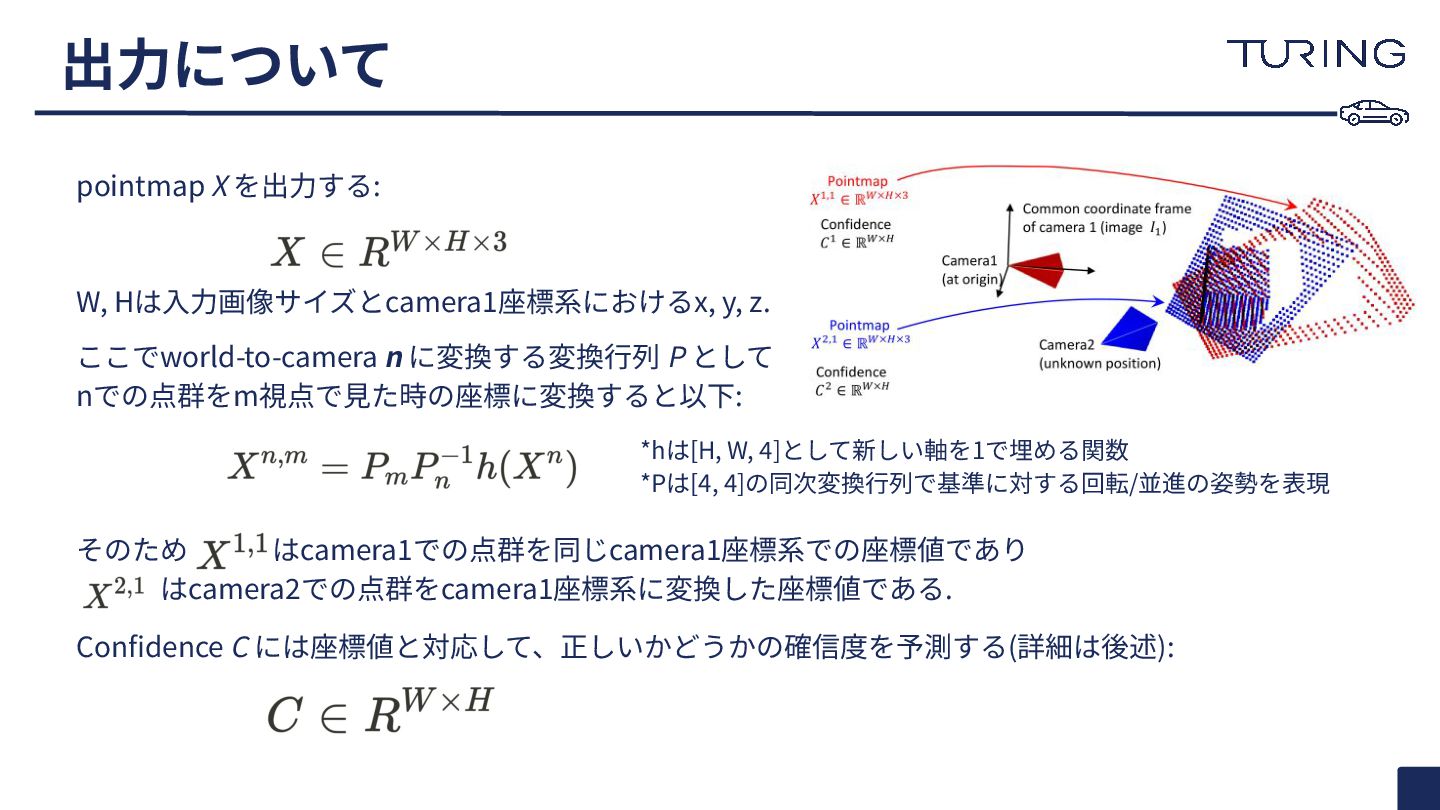
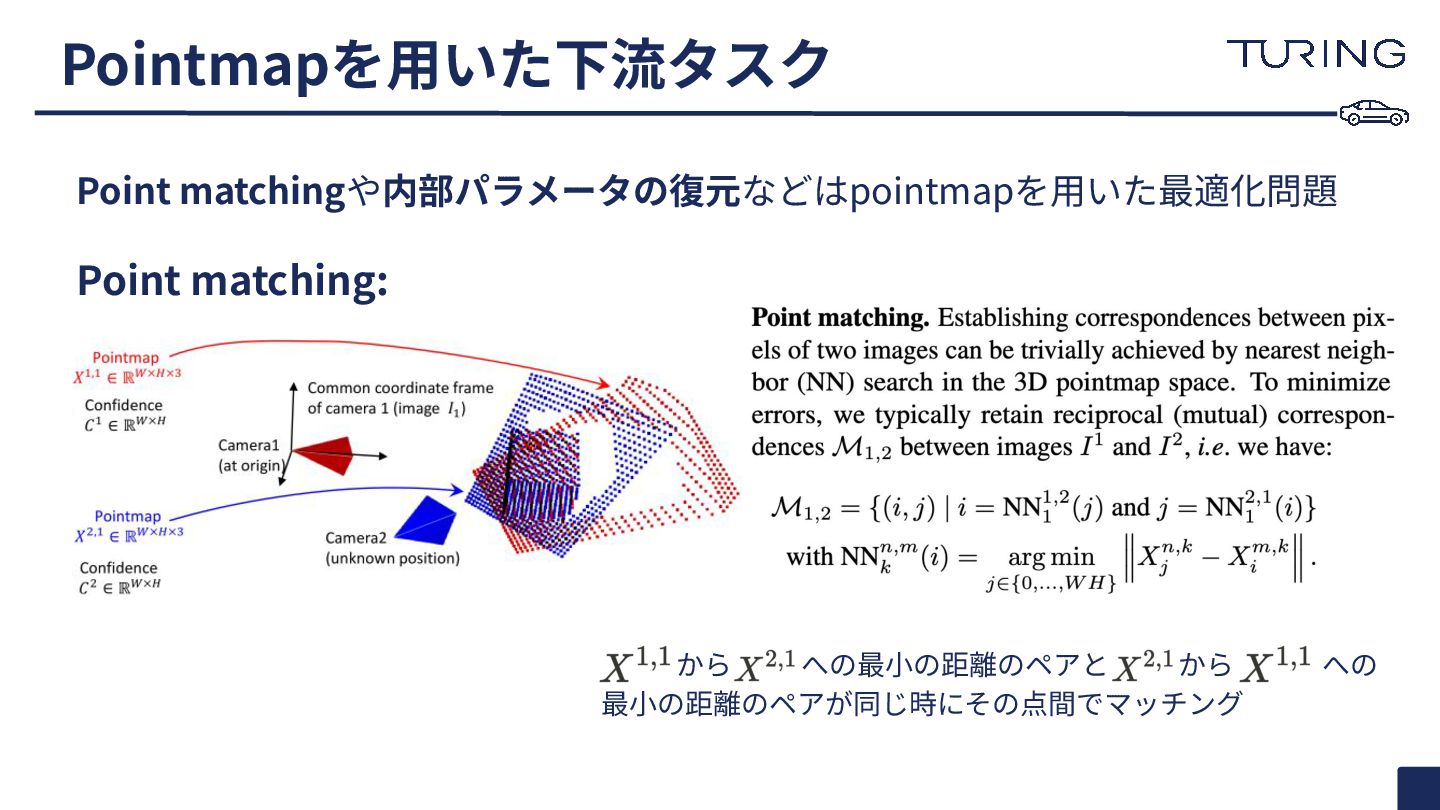
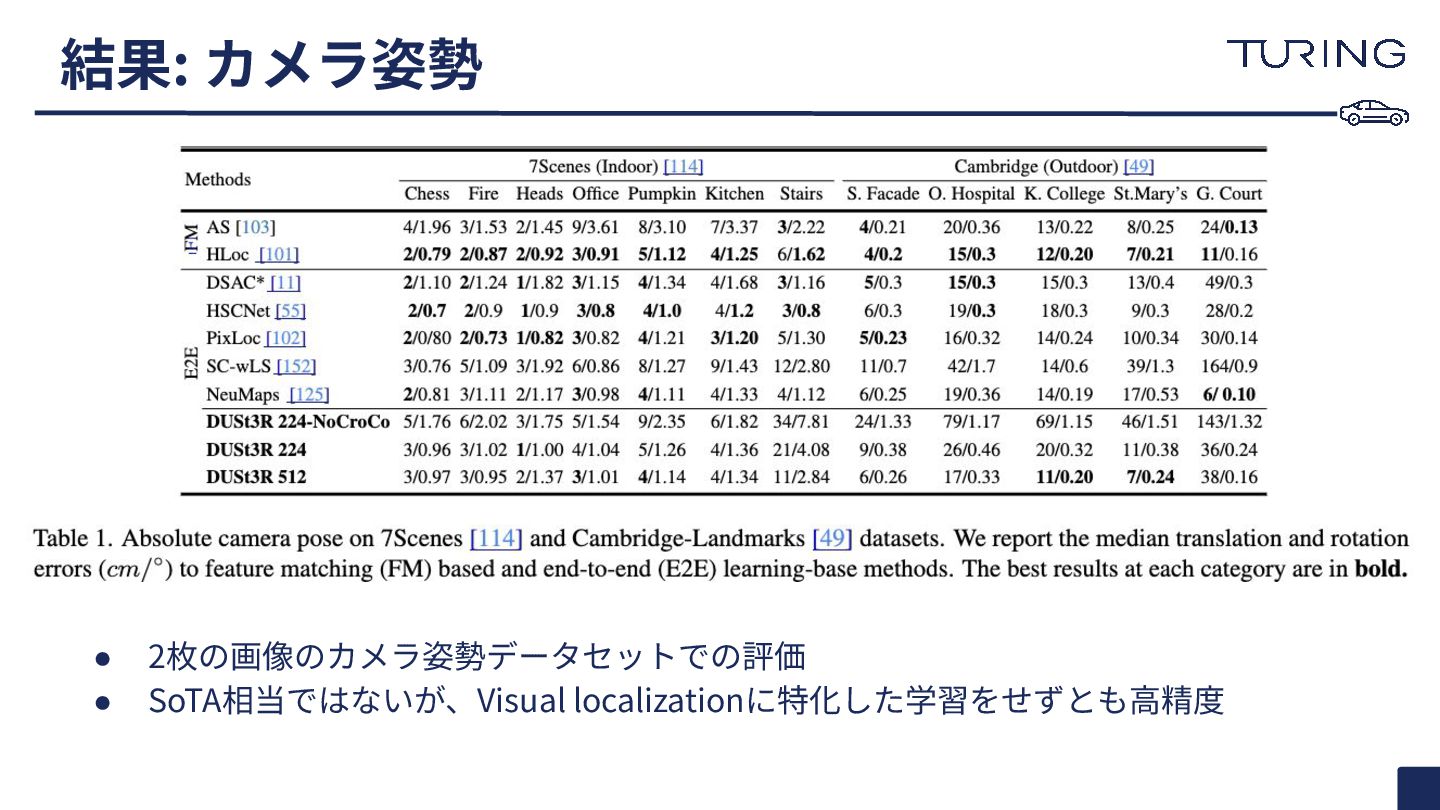
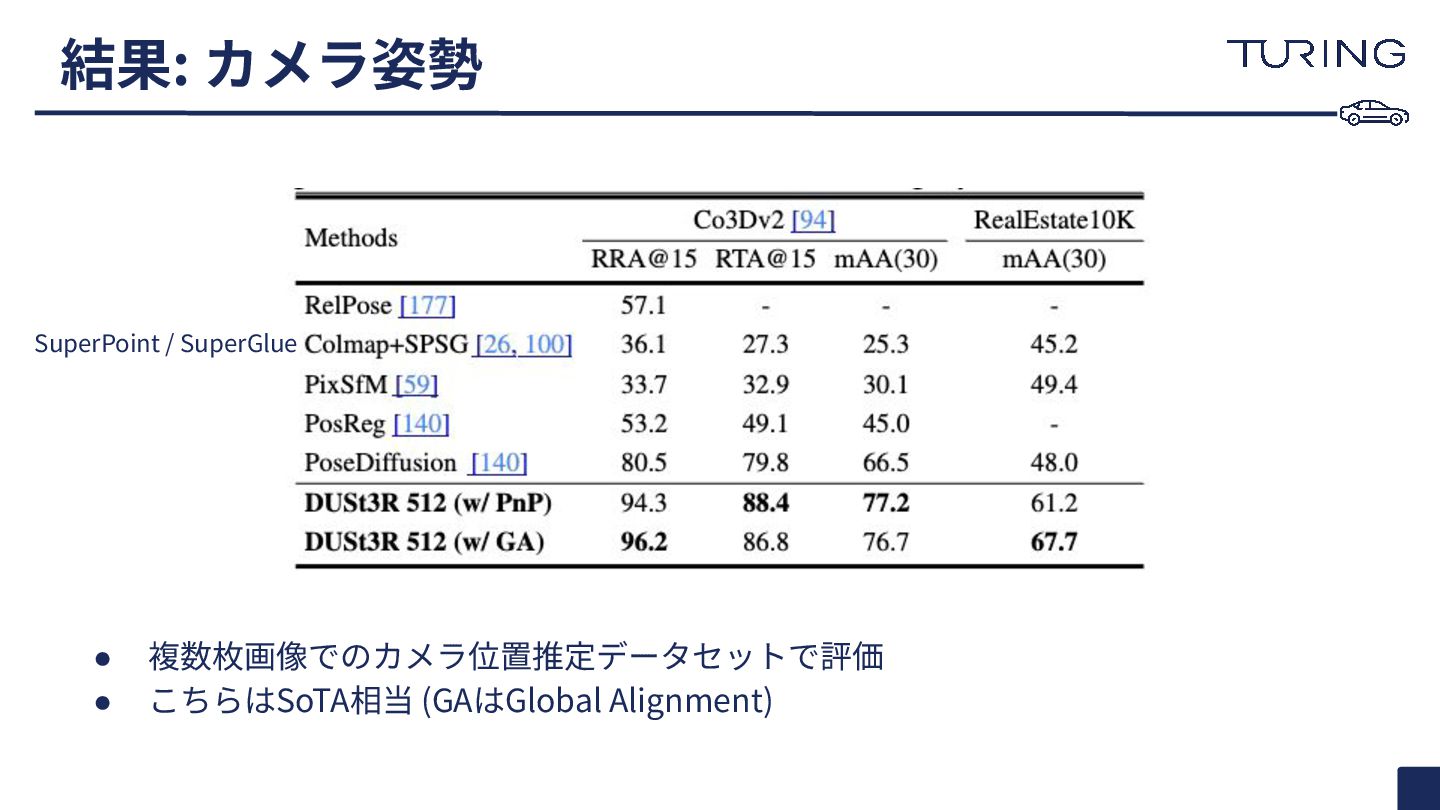
a set of photographs with unknown camera poses and intrinsics, our proposed method DUSt3R outputs a set of corresponding pointmaps, from which we can straightforwardly recover a variety of geometric quantities normally difficult to estimate all at once, such as the camera parameters, pixel correspondences, depthmaps, and fully-consistent 3D reconstruction. Note that DUSt3R also works for a single input image (e.g. achieving in this case monocular reconstruction). We also show qualitative examples on the DTU, Tanks and Temples and ETH-3D datasets] obtained without known camera parameters. For each sample, from left to right: input image, colored point cloud, and rendered with shading for a better view of the underlying geometry. 図1: 制約のない画像コレクション、すなわちカメラの姿勢や内部パラメータが未知の写 真群が与えられた場合、我々の提案手法 DUSt3Rは対応する ポイントマップ の集合を 出力します。これにより、通常は一度に推定するのが困難なカメラパラメータ、ピクセル 間対応、深度マップ、そして完全に一貫性のある 3D再構成といった様々な幾何学的量 を容易に回復することが可能となります。なお、 DUSt3Rは単一の入力画像に対しても 機能し(e.g., 単眼再構成の達成 )、既知のカメラパラメータを用いずに 得られたDTU、 Tanks and Temples、ETH-3Dの各データセットでの 定性的な例 も示しています。各サ ンプルでは、左から右へ、入力画像、カラーのポイントクラウド、そして下地の幾何学構 造をより良く表現するためにシェーディングでレンダリングされたものが順に表示され ています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![視覚基盤モデル ImageNet [Deng+ 2009] • ImageNetなどの⼤規模データの教師あり学習により汎⽤的な特徴抽出を可能に! • CLIPによる対照学習でVision-Languageの統⼀的なマッピングが可能に! • 3次元視覚認識の基盤モデルは存在するのか?](https://files.speakerdeck.com/presentations/025017ec0e4b46baad3d7bd1cad22191/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
![*Vision Transformer (ViT) ViT [Dosovitskiy+ 2020] • ViTは画像認識においてTransformerを⽤いた⼿法 (当時のCNNのSoTAと同様の性能) •](https://files.speakerdeck.com/presentations/025017ec0e4b46baad3d7bd1cad22191/slide_12.jpg){kind=link}
![*CroCo [Weinzaepfel+ NeurIPS2022] • マスクされた画像に対してペアになる参照画像を⽤いて復元する⾃⼰教師あり学習 • ViTで特徴トークンに変換し絶対位置エンコーディング後にCrossBlockでMaskを復元 ◦ CrossBlock: Self-Attention](https://files.speakerdeck.com/presentations/025017ec0e4b46baad3d7bd1cad22191/slide_13.jpg){kind=link}
![*CroCo v2 [Weinzaepfel+ ICCV2023] • CroCoから、学習データ作成、RoPEの導⼊、モデルサイズを⼤きくする改善 • Stereo matchingやoptical flowの下流タスクの事前学習として効果的](https://files.speakerdeck.com/presentations/025017ec0e4b46baad3d7bd1cad22191/slide_14.jpg){kind=link}
![*Depth Prediction Transformer (DPT) [Ranftl+ 2021] • 画像特徴トークンを⼊⼒にTransformer構造で深度推定を⾏う構造 • 雑に⾔えばTransformer版のU-Net](https://files.speakerdeck.com/presentations/025017ec0e4b46baad3d7bd1cad22191/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
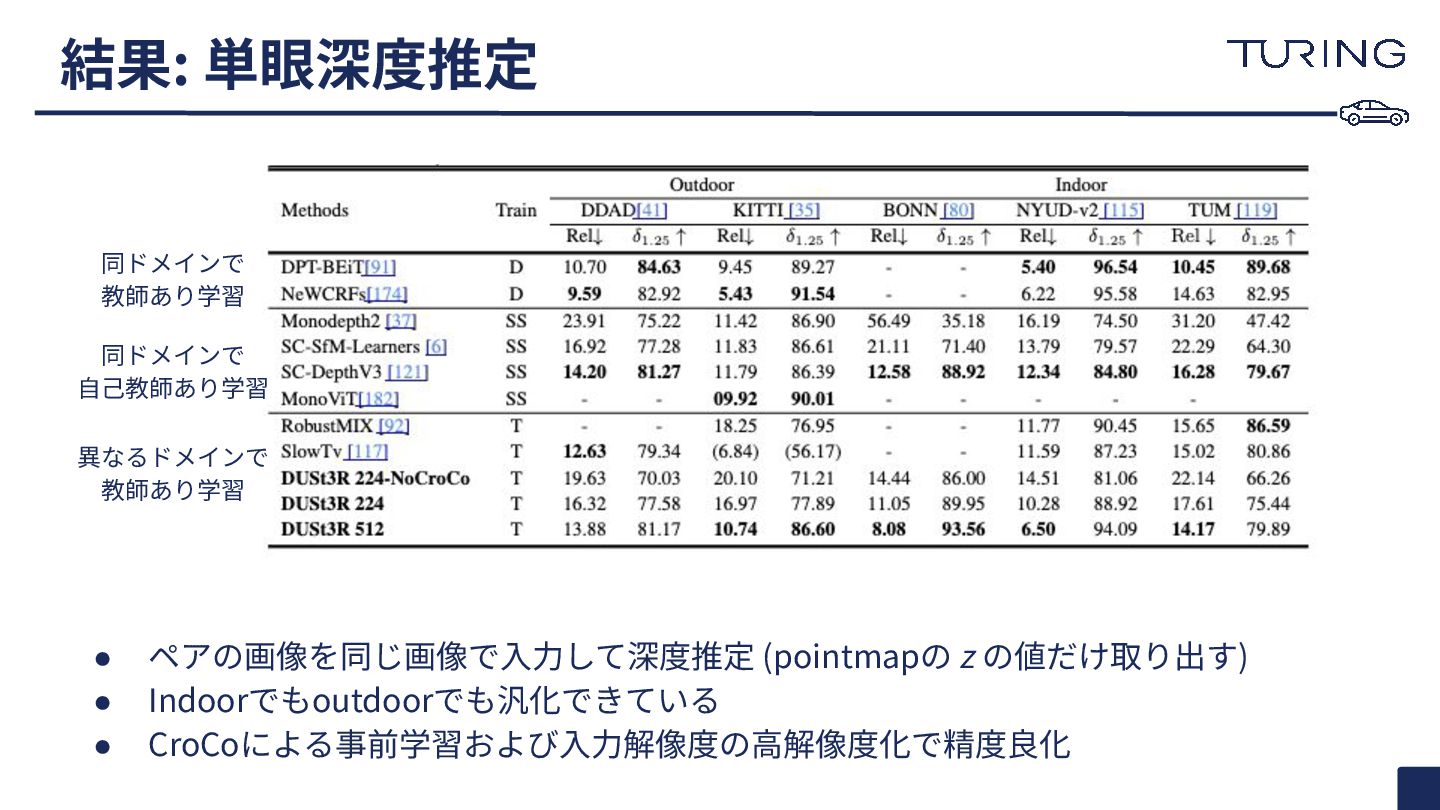{kind=link}
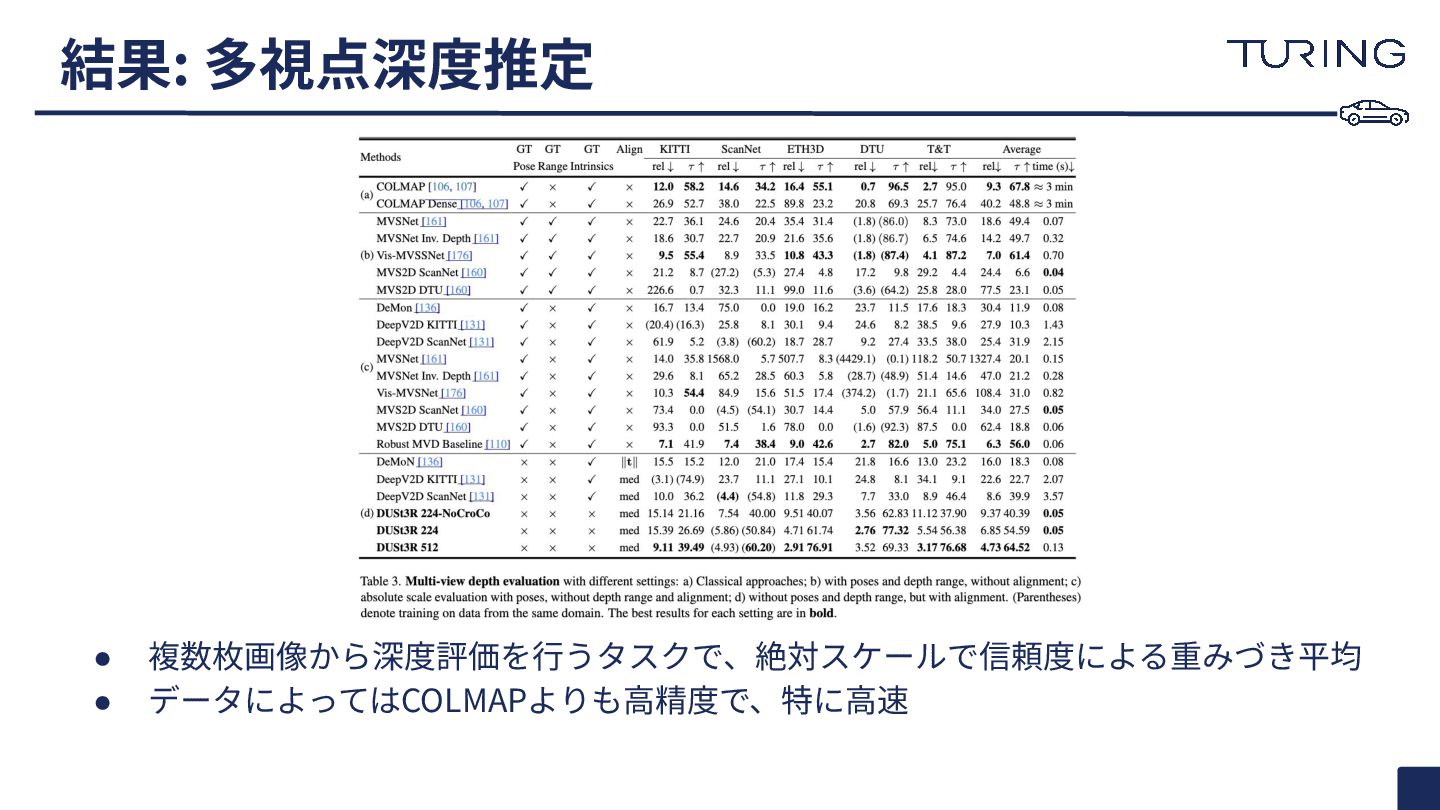{kind=link}
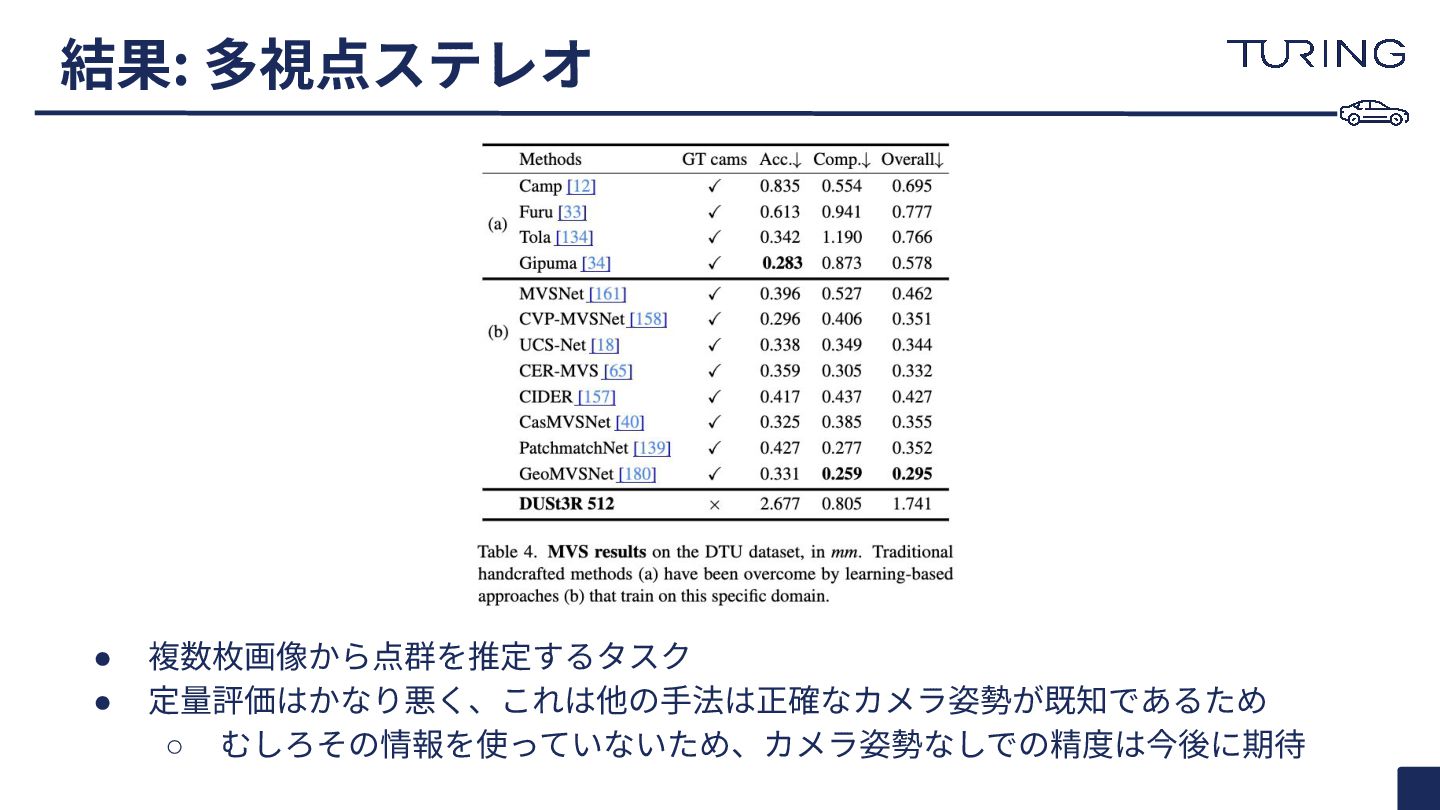{kind=link}
{kind=link}
![派⽣⼿法: MASt3R [Leroy+ CVPR2024] • DUSt3Rの構造に新しくlocal featureを出⼒するHeadを追加 • DUSt3Rの損失関数に加えてpoint matchingの損失関数を追加](https://files.speakerdeck.com/presentations/025017ec0e4b46baad3d7bd1cad22191/slide_29.jpg){kind=link}
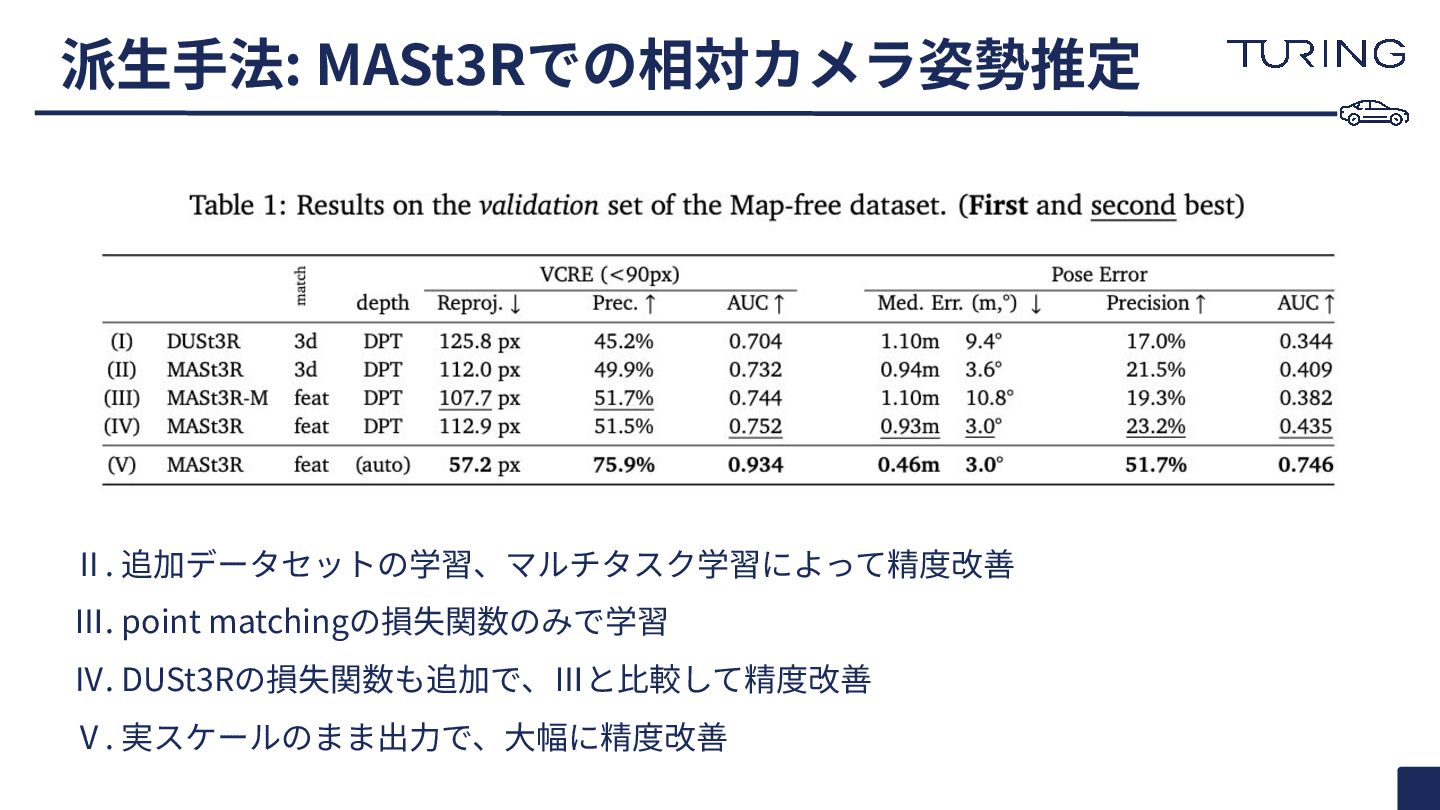{kind=link}
![派⽣⼿法: MonST3R [Zhang+ ICLR2025] • 動的なシーンに対応したDUSt3R系の⼿法 • 時系列で関係する2フレームからpointmapを出⼒後に後処理的にoptical flowを計算 •](https://files.speakerdeck.com/presentations/025017ec0e4b46baad3d7bd1cad22191/slide_31.jpg){kind=link}
![派⽣⼿法: Fast3R [Yang+ CVPR2025] • 任意の複数枚の画像を⼊⼒可能にしたDUSt3R系の⼿法 (テスト時は1,500枚でも可能) • Cross-AttentionのところをカメラIDによるpositional encodingをしてSelf-Attention](https://files.speakerdeck.com/presentations/025017ec0e4b46baad3d7bd1cad22191/slide_32.jpg){kind=link}
{kind=link}
![VGGT [Wang+ CVPR2025] • Fast3R-likeな構造で後処理で求めていたカメラパラメータやmatchingも同時に解く • Global AttentionとFrame内でのAttentionのAlternating-Attention (AA) がいいらしい](https://files.speakerdeck.com/presentations/025017ec0e4b46baad3d7bd1cad22191/slide_34.jpg){kind=link}
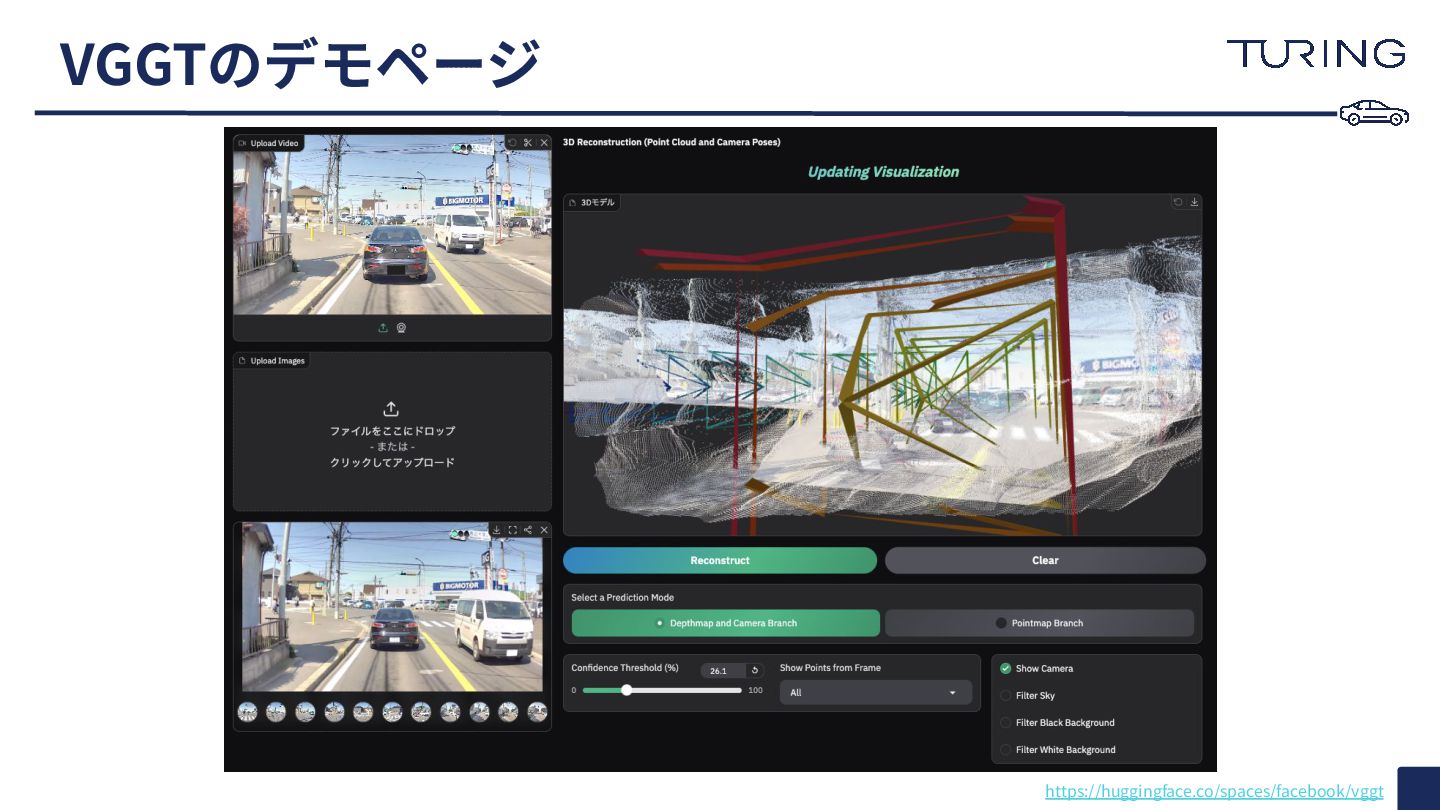{kind=link}
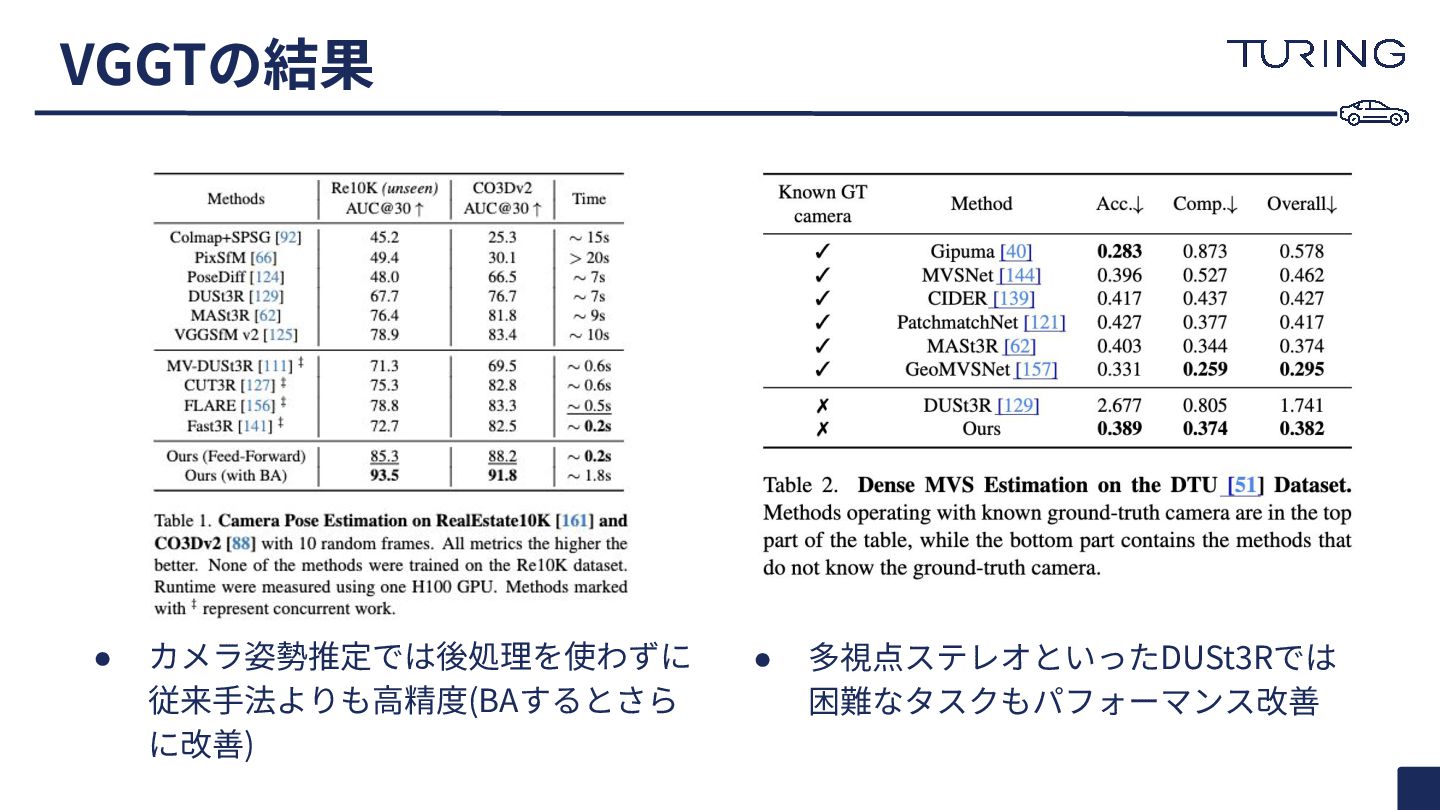{kind=link}
{kind=link}
{kind=link}
{kind=link}