Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
自動運転開発の実験管理とKagglerたちの実験管理術
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Kohei Iwamasa
March 27, 2025
800
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
自動運転開発の実験管理とKagglerたちの実験管理術
Kohei Iwamasa
March 27, 2025
More Decks by Kohei Iwamasa
See All by Kohei Iwamasa
numpyやPyTorchの配列にdtypeとshapeをアノテーションするjaxtypingのススメ
koheiiwamasa
4
2.1k
[関西Kaggler会2025#2LT] 初学者+MLエンジニア対象! モダンなPythonの書き方
koheiiwamasa
5
4.6k
[Turing Inc.] DUSt3R勉強会
koheiiwamasa
1
2.1k
Polarsで始める時系列データ処理 #atmaCup 19 振り返り会 LT枠
koheiiwamasa
2
790
FiT3D: Improving 2D Feature Representations by 3D-Aware Fine-Tuning - 第62回 コンピュータビジョン勉強会 ECCV論文読み会
koheiiwamasa
0
470
[IBIS2024 ビジネスと機械学習] 近年のData-Centricな 自動運転AI開発
koheiiwamasa
5
3.2k
LaneSegNet: Map Learning with Lane Segment Perception for Autonomous Driving - ICLR2024論文読み会
koheiiwamasa
0
1.2k
Unsupervised_3D_Perception_with_2D_Vision-Language_Distillation_for_Autonomous_Driving_CV勉強会
koheiiwamasa
3
650
大規模走行データを 効率的に活用する検索システムの開発 第3回Data-Centric AI勉強会
koheiiwamasa
0
1.3k
Featured
See All Featured
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
250
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2k
A designer walks into a library…
pauljervisheath
211
24k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
The B2B funnel & how to create a winning content strategy
katarinadahlin
PRO
1
420
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
250
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.7k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Transcript
⾃動運転開発の実験管理と Kagglerたちの実験管理術 チューリング株式会社 岩政 公平 W&Bミートアップ 2025/03/27
• 岩政 公平 • チューリング株式会社 E2E⾃動運転チーム MLエンジニア ◦ 2022年8⽉~ インターン
◦ 2023年4⽉~ ⼊社 ⾃⼰紹介
Agenda • 会社紹介 • End-to-End⾃動運転チームの実験管理 • Kagglerたちの実験管理術
会社概要 名称 Turing株式会社 創業 2021年8⽉20⽇ 事業内容 完全⾃動運転AIの開発 本社所在地 東
京 都 品 川 区 ⼤ 崎 1 丁 ⽬ 11−2 ゲートシティ⼤崎 イースト棟4階 資本金 3000万円(累計70億円調達) 社員数 社 員 数 92 名 (正社員66名、アルバイト‧インターン26名)
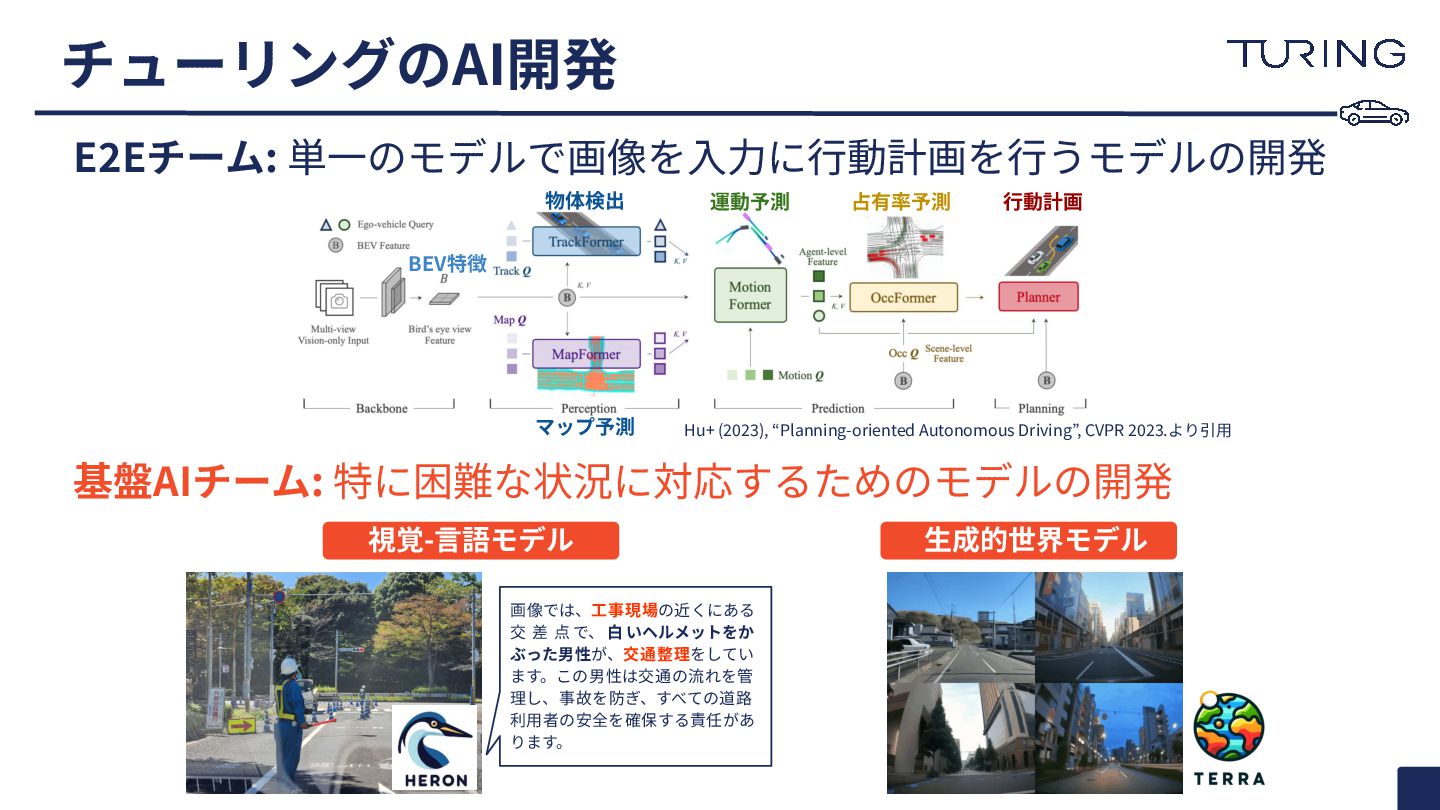
チューリングのAI開発 Hu+ (2023), “Planning-oriented Autonomous Driving”, CVPR 2023.より引⽤ 物体検出 マップ予測
運動予測 占有率予測 ⾏動計画 BEV特徴 E2Eチーム: 単⼀のモデルで画像を⼊⼒に⾏動計画を⾏うモデルの開発 基盤AIチーム: 特に困難な状況に対応するためのモデルの開発 視覚-⾔語モデル ⽣成的世界モデル 画像では、⼯事現場の近くにある 交 差 点 で、 ⽩ いヘルメットをか ぶった男性が、交通整理をしてい ます。この男性は交通の流れを管 理し、事故を防ぎ、すべての道路 利⽤者の安全を確保する責任があ ります。
⽇本語VLMベンチマーク: Heron-Bench ⽇本語VLMのベンチマーク • ⽇本特有の画像や⽂化理解に関する質問 • CVPR 2024 The 3rd
Workshop on Computer Vision in the Wildに採択 Heron-VLM Leaderboardの公開 • W&B様と技術協⼒して⽇本語VLMの リーダボードを整備! • Heron-Bench, LLaVA-Bench (in-the-wild) を⽤いた⾃動評価
Heron-Benchを⽤いた開発 Q. この建物は何⾊でしょうか?
Heron-Benchを⽤いた開発 🤖「この建物は⾦⾊です。」
Heron-Benchを⽤いた開発 W&B上でVLMの推論結果やスコアが確認できる!
Heron-Benchを⽤いた開発 リーダーボード機能も⽤いることで他のモデルとの相対評価も可能に! https://zenn.dev/turing_motors/articles/bf84fad186a23b
E2E⾃動運転チームの 実験管理
Tokyo30 2025年末までに、カメラと AIだけで 東京エリアを30分以上介入なしで走行し続ける自 動運転モデルを開発します
チューリングが開発しているE2Eモデル 2025/03現在のモデル • カメラ画像のみで学習‧推論 • データ量は約1,000時間 • 学習はH100 48枚で1週間
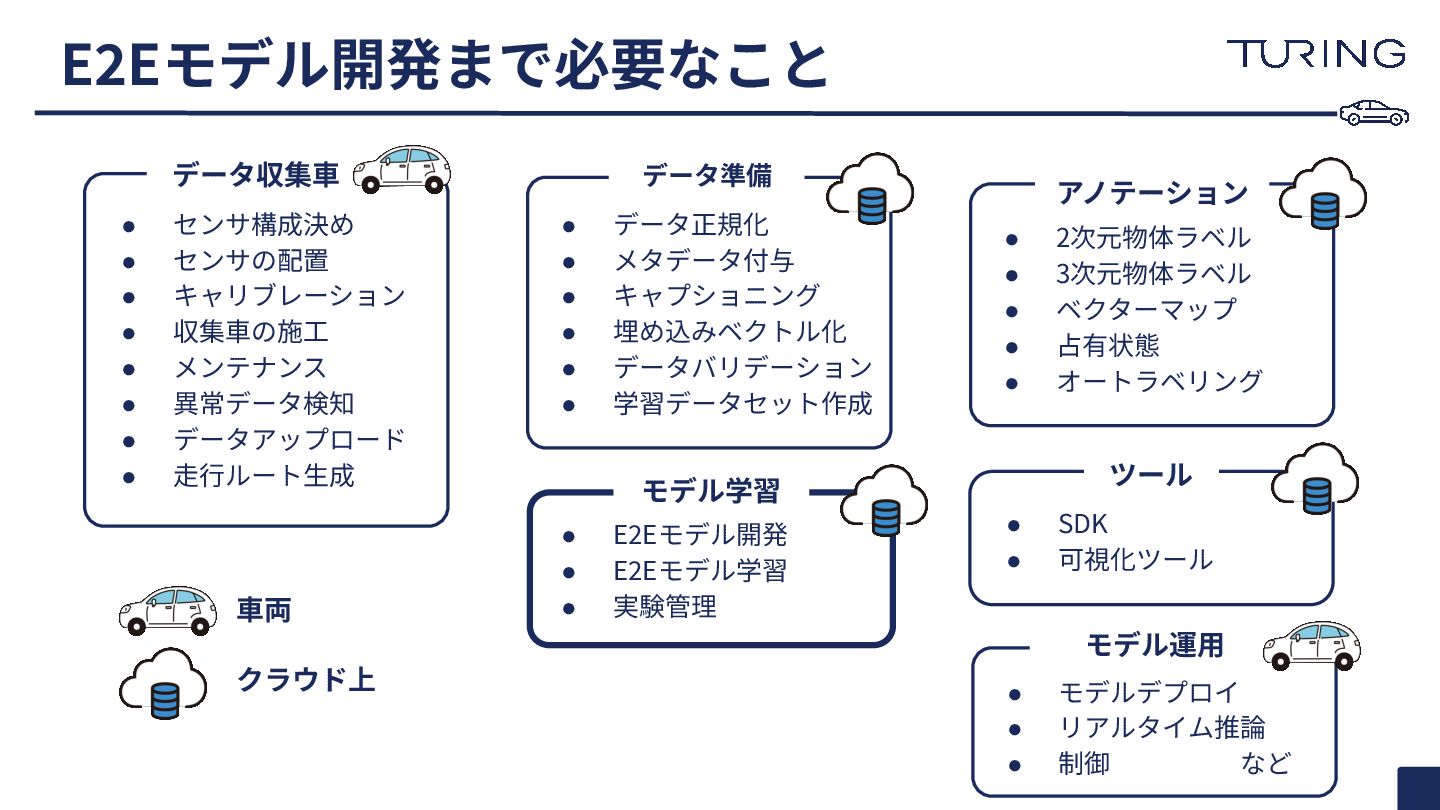
E2Eモデル開発まで必要なこと データ収集⾞ アノテーション データ準備 モデル学習 • センサ構成決め • センサの配置 •
キャリブレーション • 収集⾞の施⼯ • メンテナンス • 異常データ検知 • データアップロード • ⾛⾏ルート⽣成 • データ正規化 • メタデータ付与 • キャプショニング • 埋め込みベクトル化 • データバリデーション • 学習データセット作成 ツール • 2次元物体ラベル • 3次元物体ラベル • ベクターマップ • 占有状態 • オートラベリング • E2Eモデル開発 • E2Eモデル学習 • 実験管理 • SDK • 可視化ツール • モデルデプロイ • リアルタイム推論 • 制御 など ⾞両 クラウド上 モデル運⽤
何の実験を管理するか • データセットの管理 • モデルの管理
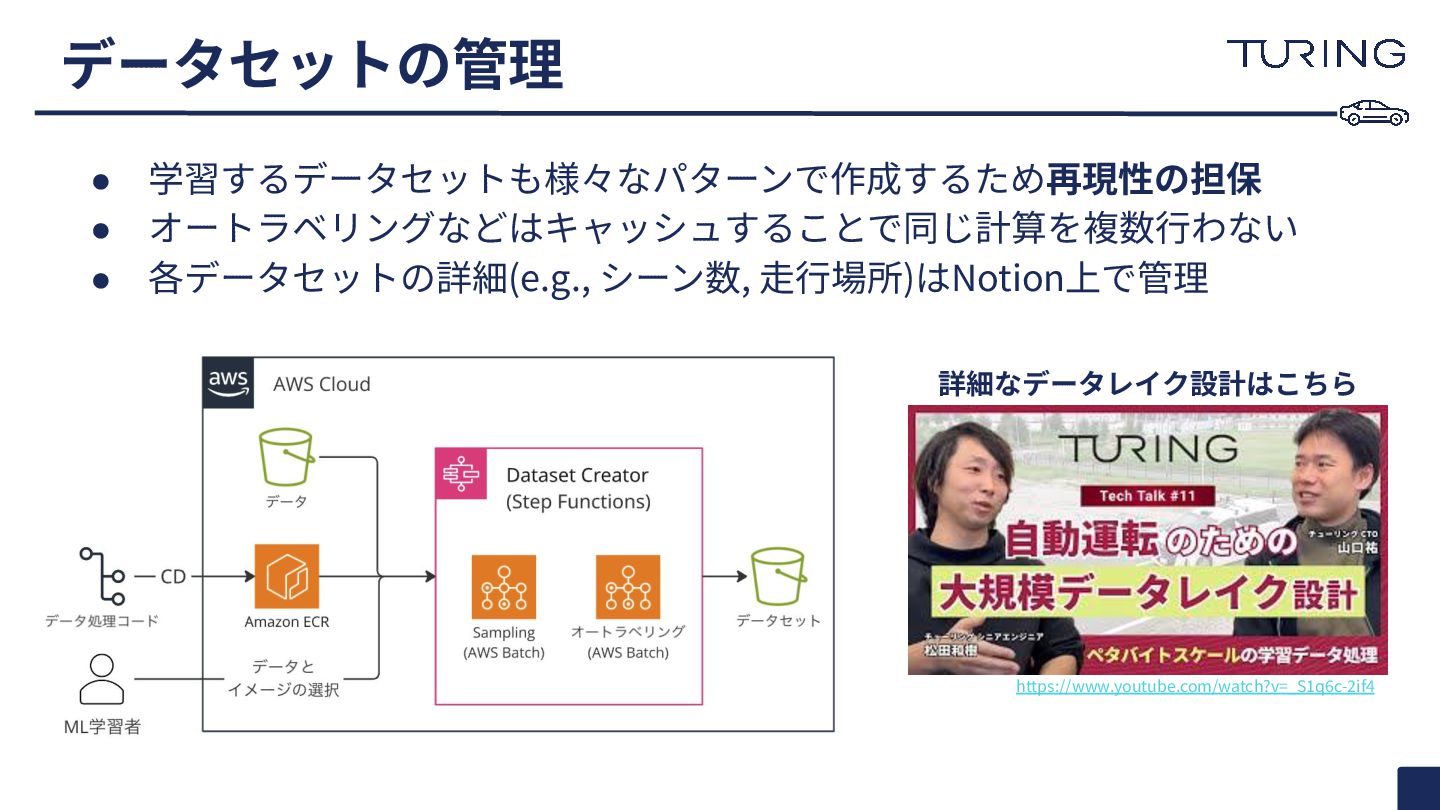
データセットの管理 • 学習するデータセットも様々なパターンで作成するため再現性の担保 • オートラベリングなどはキャッシュすることで同じ計算を複数⾏わない • 各データセットの詳細(e.g., シーン数, ⾛⾏場所)はNotion上で管理 https://www.youtube.com/watch?v=_S1q6c-2if4
詳細なデータレイク設計はこちら
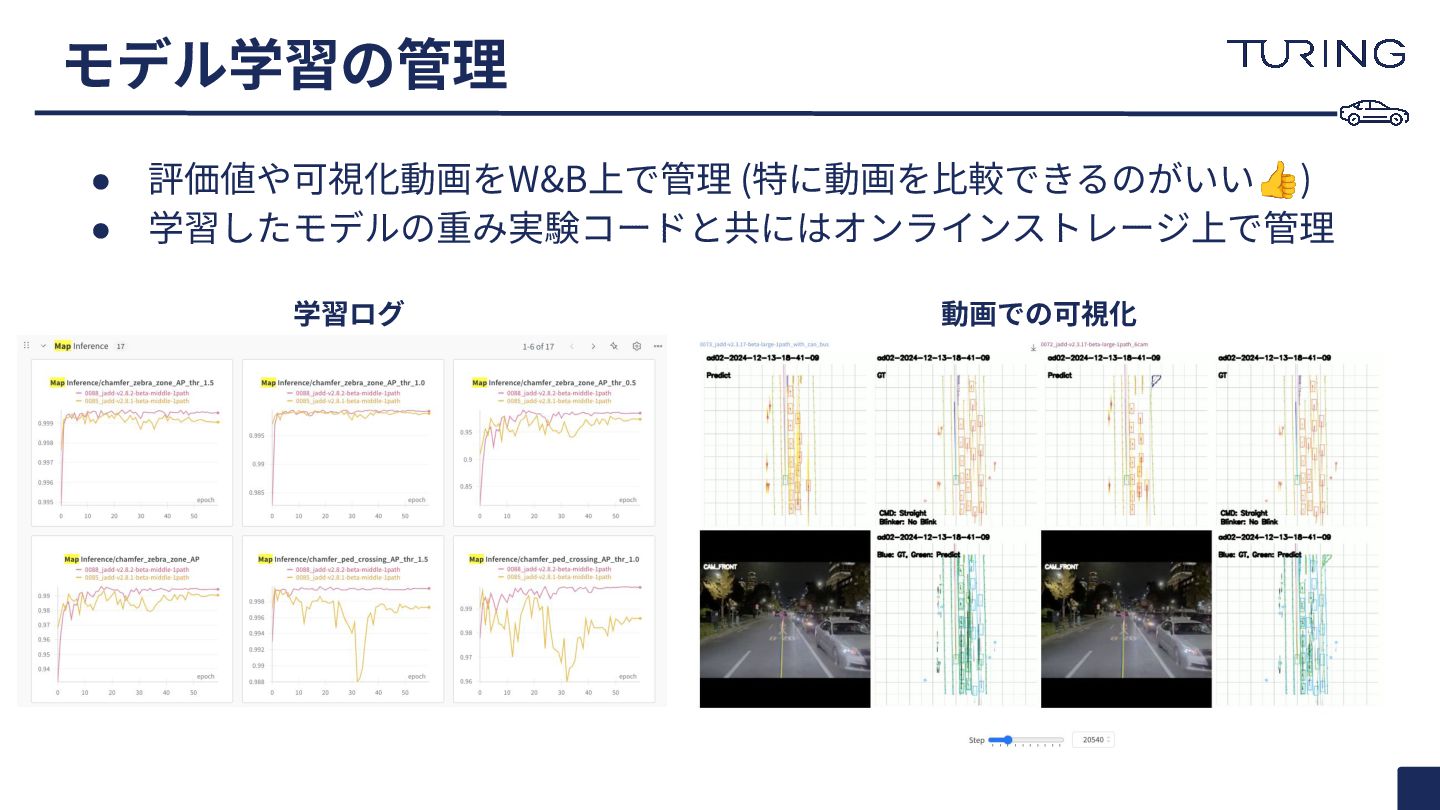
モデル学習の管理 • 評価値や可視化動画をW&B上で管理 (特に動画を⽐較できるのがいい👍) • 学習したモデルの重み実験コードと共にはオンラインストレージ上で管理 学習ログ 動画での可視化
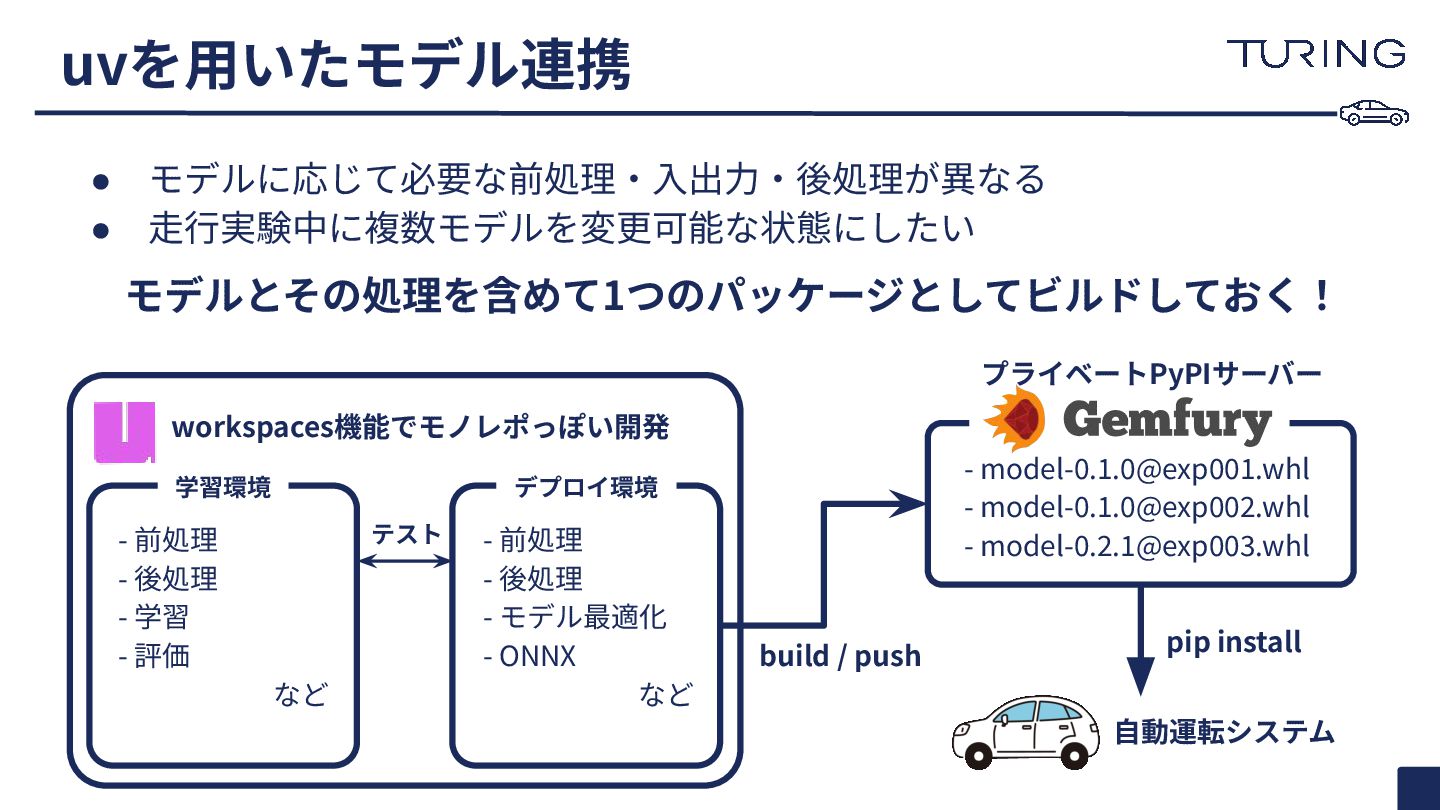
uvを⽤いたモデル連携 • モデルに応じて必要な前処理‧⼊出⼒‧後処理が異なる • ⾛⾏実験中に複数モデルを変更可能な状態にしたい モデルとその処理を含めて1つのパッケージとしてビルドしておく! 学習環境 デプロイ環境 workspaces機能でモノレポっぽい開発 ⾃動運転システム
pip install build / push -
[email protected]
-
[email protected]
-
[email protected]
- 前処理 - 後処理 - 学習 - 評価 など - 前処理 - 後処理 - モデル最適化 - ONNX など テスト プライベートPyPIサーバー
どのデータ、どのモデルの組み合わせがいいのか知るには
どのデータ、どのモデルの組み合わせがいいのか知るには 正しい評価指標 が必要
運転ポリシーの評価 オープンループ評価 • 実際のデータを⽤いて⾃動運転システムが実際の⾛⾏データと どれだけ誤差なく同様の操作ができているかを評価 • e.g., 将来の予測運転軌道と実際の運転軌道との回帰誤差 クローズドループ評価 •
シミュレータなどを⽤いて、⾃⾞と他の交通エージェントの⾏動が タイムステップごとに相互作⽤するような世界で⾛⾏能⼒を評価 • e.g., 衝突性, ルートの逸脱性, 交通ルールの厳守性 正解点列 予測点列
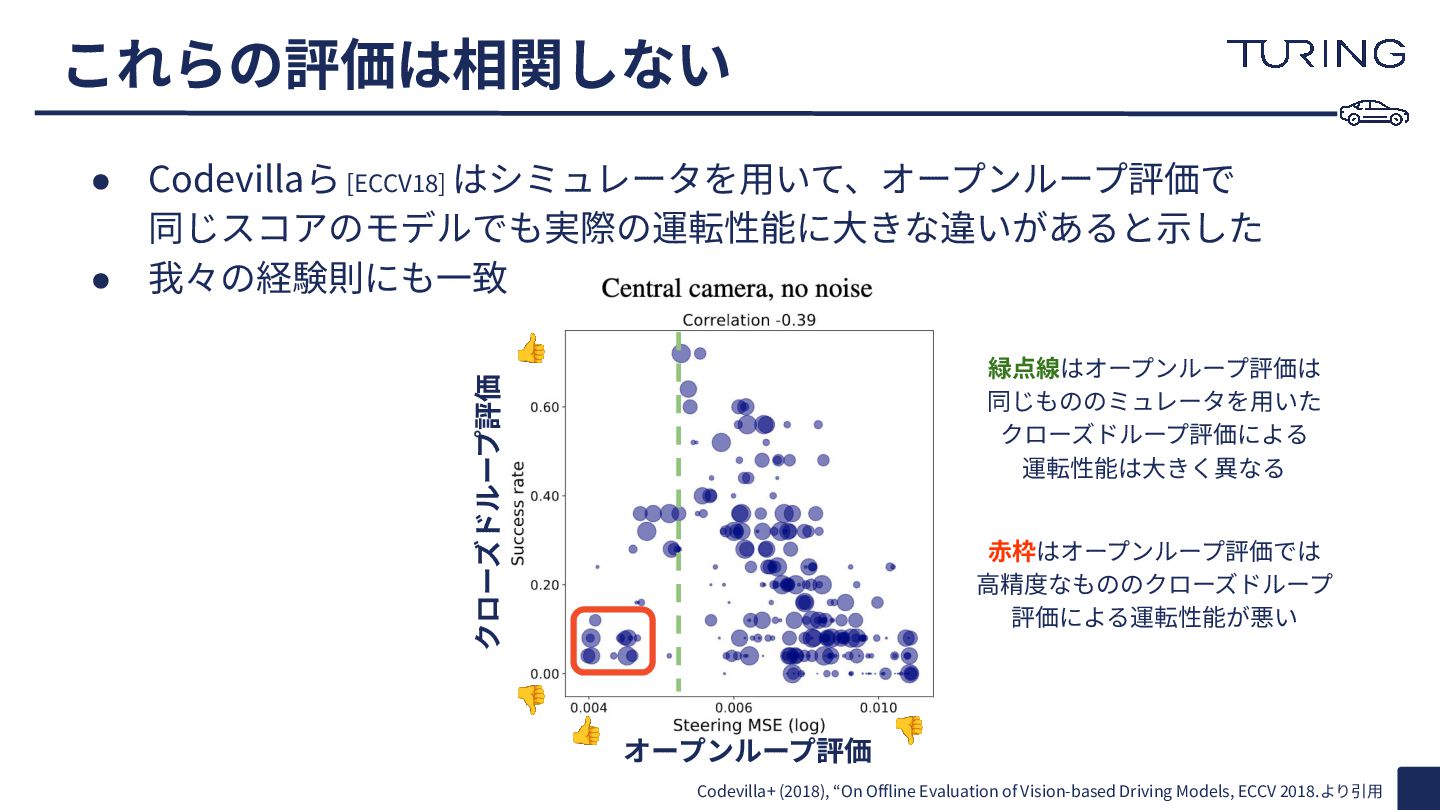
これらの評価は相関しない Codevilla+ (2018), “On Offline Evaluation of Vision-based Driving Models,
ECCV 2018.より引⽤ オープンループ評価 クローズドループ評価 👍 👎 👍 👎 • Codevillaら [ECCV18] はシミュレータを⽤いて、オープンループ評価で 同じスコアのモデルでも実際の運転性能に⼤きな違いがあると⽰した • 我々の経験則にも⼀致 ⾚枠はオープンループ評価では ⾼精度なもののクローズドループ 評価による運転性能が悪い 緑点線はオープンループ評価は 同じもののミュレータを⽤いた クローズドループ評価による 運転性能は⼤きく異なる
E2Eモデルは運転性能評価が難しい 様々なギャップと評価の困難さがある • シミュレーションと現実世界のドメインギャップ • オープンループ評価とクローズドループ評価のギャップ • クローズドループ評価の定量評価をどうするか • 複数の指標のうち、どの指標を最適化するのが望ましいか
複数のモデルの実験管理と再現性の困難さがある • ⾃動運転システム⾃体の更新に対する再現性の担保 • 現実世界では同じ現象に⼆度と遭遇しない • 複数のモデルを効率的にシステムに組み込むか など
解決策 シミュレータを活⽤する • CARLAやMetaDriveを活⽤した 簡易的な運転性能の評価 • 制御システムを介して⾛⾏ 実際に⾞両にデプロイ • 予測結果に問題なければ実際に⾞両にモデルを載せて⾛⾏させる
• リアルタイム推論が必要なためモデルの推論速度に制限あり ◦ 量⼦化やTensorRT化などのモデル最適化を⾏う • ⾛⾏ログを残し机上で再現を⾏うシステムも構築 (モデルを差し替えも可能) MetaDrive https://github.com/metadriverse/metadrive
将来的な解決策: データ駆動のシミュレータ NAVSIM [Dauner+ NeurIPS2024] • 実際の⾛⾏データを⽤いた⾮反応型のシミュレータの活⽤ • 中間的な評価⽅法で、クローズドループ評価に⽐較的相関する https://www.youtube.com/watch?v=Qe76HRmPDe0
Dauner+ (2024), “NAVSIM: Data-Driven Non-Reactive Autonomous Vehicle Simulation and Benchmarking”, NeurIPS 2024. https://opendrivelab.com/challenge2024/#end_to_end_driving_at_scale CVPR 2024/2025ではWorkshop competitionも開催
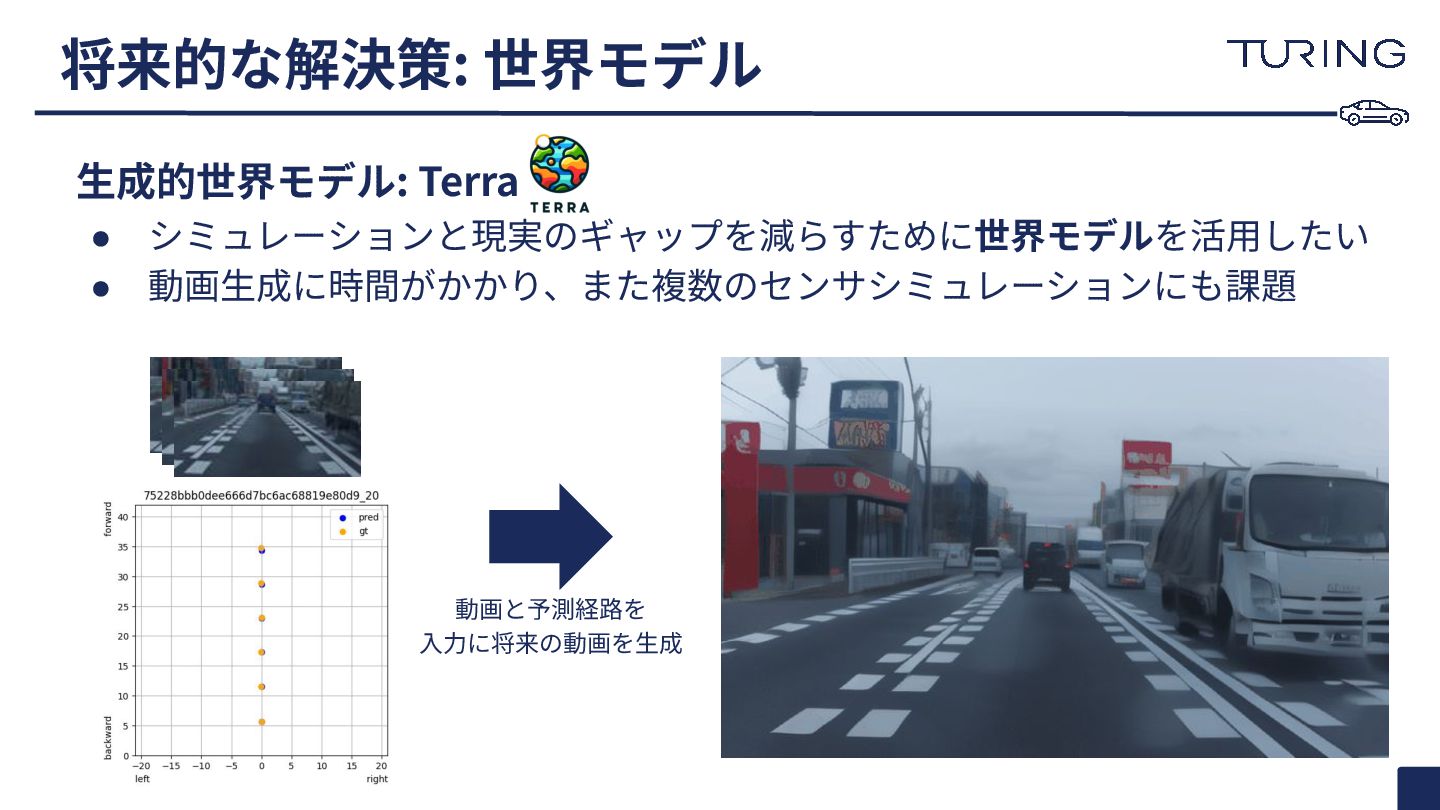
将来的な解決策: 世界モデル 動画と予測経路を ⼊⼒に将来の動画を⽣成 ⽣成的世界モデル: Terra • シミュレーションと現実のギャップを減らすために世界モデルを活⽤したい • 動画⽣成に時間がかかり、また複数のセンサシミュレーションにも課題
Kagglerの実験管理術
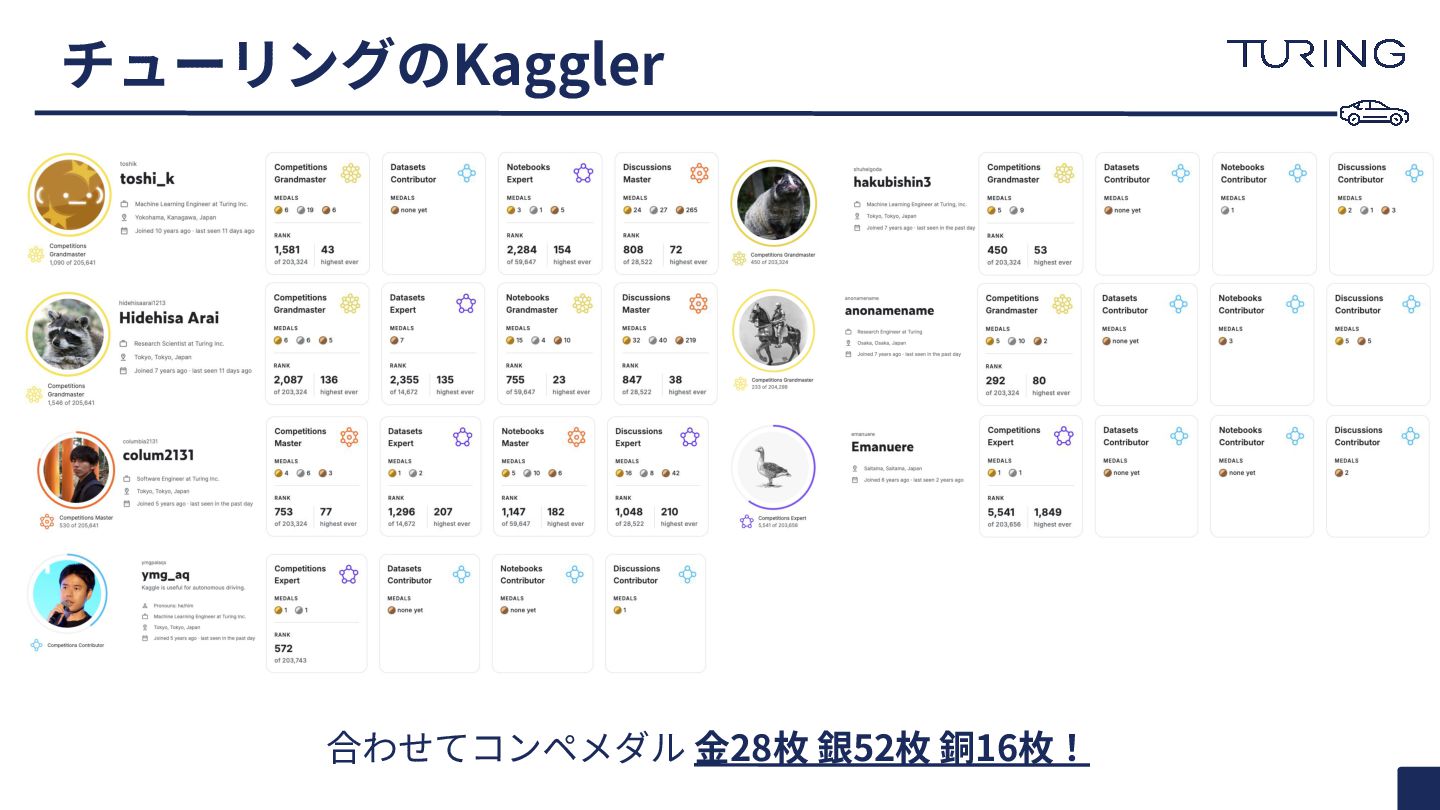
合わせてコンペメダル ⾦28枚 銀52枚 銅16枚! チューリングのKaggler
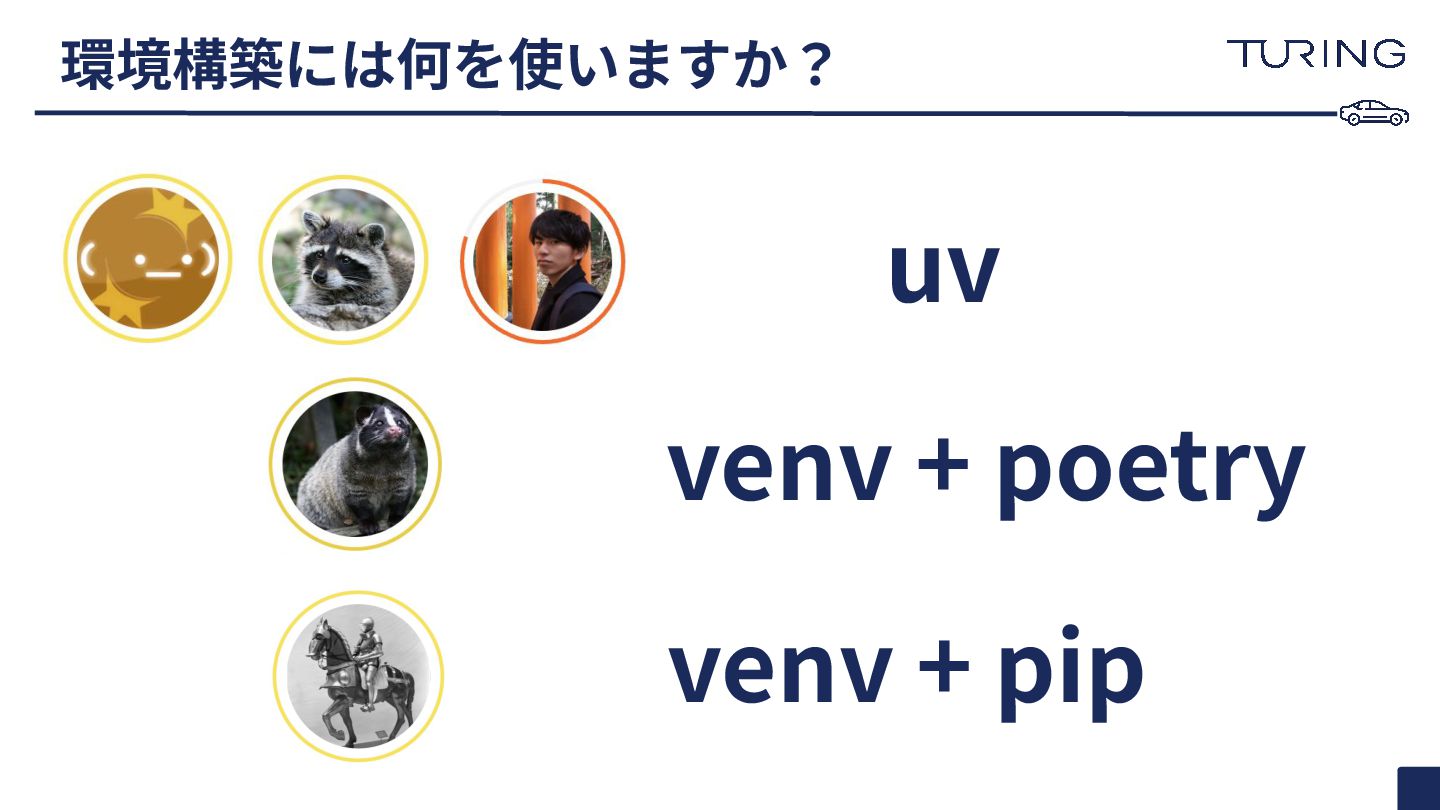
Kagglerアンケート 以下についてアンケートしました! • コンペで⼀番使っている実験管理サービスは何ですか?(e.g., W&B, MLFlow) • 環境構築には何を使いますか? (e.g., uv,
Poetry) • ⼀番使っている深層学習フレームワークは何ですか? ◦ 画像認識タスクで使っている深層学習フレームワークは何ですか? ◦ NLPタスクで使っている深層学習フレームワークは何ですか? • Kaggleでの実験スタイルは何ですか?(e.g., 1実験1スクリプト) • Kaggleでチームでの実験管理するときに気をつけていることはありますか?
⼀番使っている実験管理サービスは何ですか W&B スプレッドシート
環境構築には何を使いますか? uv venv + poetry venv + pip
画像タスクで使う深層学習フレームワークは PyTorch 物体検出はmmdet。それ以外はフレームワークの機能をフルで使うことはあまりない。 拡散モデルの学習の際に⼀部機能だけDiffusersを使⽤する。 画像分類などはPyTorch。物体検出系はmmdet, detectron2, Transformers を使う。 GitHubのコード (YOLOX
や Grounded-SAMとか) を直接使うことも多い。 Semantic segmentationはSegmentation Models PyTorch (SMP) を使う。 PyTorch 。画像分類などでしか画像タスクをやったことがない。 PyTorch Lightning (pl) をメインで使う。Semantic segmentationならSMP+ pl。 Instance segmentationならmmdet、物体検出ならそのモデルに合わせる(e.g., YOLOX)
NLPタスクで使う深層学習フレームワークは Keras Transformersを使うことが多いが、trainerは使わない。学習部分は⽣PyTorch Transformersを使う。Trainerを使う。 PyTorch, Transformers Transformersをメインで使う。最近はTrainerも使う。
実験スタイルは何ですか commit ID+configスクリプト 1実験1スクリプト 1実験1スクリプトを⼼がけている。 実験増えてくるとスプレッドシートで実験名とスコアをまとめる。 1実験1スクリプト 1実験1スクリプト。汎⽤的に使うコードはmoduleとして分けておく。
チームでの実験管理に気をつけていることは 実験にモデル番号と名前をつけて他のメンバーが⾒ても何のログか分かるようにしている。 実験の再現をしやすいようにどのような環境でどのような設定で実験を⾏なっていたかは 記録するようにしている。 環境構築。他メンバーのコード実⾏できるように、ライブラリのバージョンをチーム内で できるだけそろえる。 何もない気がする。最初は⾊々揃えた⽅が良いと思っていたが、 直近のKaggleだと「うんうん、それも多様性だよね」という考えになった。 コンペならインターフェイスや評価⽅法を揃える(出⼒csvは揃える、foldは揃えない)。 Submit時は、それぞれの推論コードは%%pythonでセルごとに管理する。
業務ならlinterをつける。特に最近はjaxtypingでテンソルのshapeの型付けするのが好き。
イベント情報 Kaggler向けイベントを⾏います!connpassで申し込みお願いします! https://turing.connpass.co m/event/347982/
応募待っています!(カジュアル⾯談も!) • MLエンジニア(⾃動運転エンジニア‧リサーチャー) • ソフトウェアエンジニア (プラットフォーム / MLOps) • ⾞やセンサが好きな⼈‧運転が上⼿い⼈
• GPU使うことが好きな⼈ などなど \インターン‧新卒も!∕
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![将来的な解決策: データ駆動のシミュレータ NAVSIM [Dauner+ NeurIPS2024] • 実際の⾛⾏データを⽤いた⾮反応型のシミュレータの活⽤ • 中間的な評価⽅法で、クローズドループ評価に⽐較的相関する https://www.youtube.com/watch?v=Qe76HRmPDe0](https://files.speakerdeck.com/presentations/79118e4aa17b470798f255b0104df6ef/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}