Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
厳密コアセット抽出に基づく点群ダウンサンプリングと点群・IMUタイトカップリングを用いた三次元...
Search
koide3
March 21, 2025
1.4k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
厳密コアセット抽出に基づく点群ダウンサンプリングと点群・IMUタイトカップリングを用いた三次元SLAM / Exact Point Cloud Downsampling @ Robotics symposia 2025
第30回ロボティクスシンポジア最優秀賞 2025年3月18日
産業技術総合研究所 スマートモビリティ研究チーム
小出 健司、高野瀬碧輝、大石修士、横塚将志
koide3
March 21, 2025
More Decks by koide3
See All by koide3
GLIM とMegaParticles:正規分布近似の限界とタイトカップリング&パーティクルフィルタの進展 / GLIM and MegaParticles : Progress of the distribution representation in SLAM
koide3
0
520
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
530
正規分布と最適化について
koide3
1
290
事後確率分布の共分散について
koide3
0
170
国際論文を出そう!ICRA / IROS / RA-L への論文投稿の心構えとノウハウ / RSJ2025 Luncheon Seminar
koide3
14
9.3k
大域マッチングコスト最小化とLiDAR-IMUタイトカップリングに基づく三次元地図生成 / GLIM @ Robotics symposia 2022
koide3
0
850
[ICRA2025] Tightly Coupled Range Inertial Odometry and Mapping with Exact Point Cloud Downsampling
koide3
1
170
[IROS2020] Non-overlapping RGB-D Camera Network Calibration with Monocular Visual Odometry
koide3
0
240
[IROS2022] Scalable Fiducial Tag Localization on a 3D Prior Map Via Graph-Theoretic Global Tag-Map Registration
koide3
0
180
Featured
See All Featured
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
270
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
280
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
エンジニアに許された特別な時間の終わり
watany
107
250k
For a Future-Friendly Web
brad_frost
183
10k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
300
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
460
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
YesSQL, Process and Tooling at Scale
rocio
174
15k
Transcript
2025年3月18日 第30回ロボティクスシンポジア@道後温泉 大和屋本店 厳密コアセット抽出に基づく点群ダウンサンプリングと 点群・IMUタイトカップリングを用いた三次元SLAM 小出 健司、高野瀬碧輝、大石修士、横塚将志 産業技術総合研究所 デジタルアーキテクチャ研究センター スマートモビリティ研究チーム
2 概略
3 提案手法 ⚫ ファクタグラフ上で直接点群レジストレーション誤差を最小化する ⚫ 従来は強い近似やGPU並列が必要であったものを精度を保ちつつCPUのみで実現する ⚫ 元の誤差関数と同じ二次関数を与えるコアセットによって精度を保ちつつ点数を激減させる オドメトリ推定グラフ 大域軌跡最適化グラフ
超高密度なグラフをCPUのみで最適化する (Intel N150で2倍速処理) 精度を保ったまま点数を激減 (10,000点 → 10 ~ 150点)
4 背景
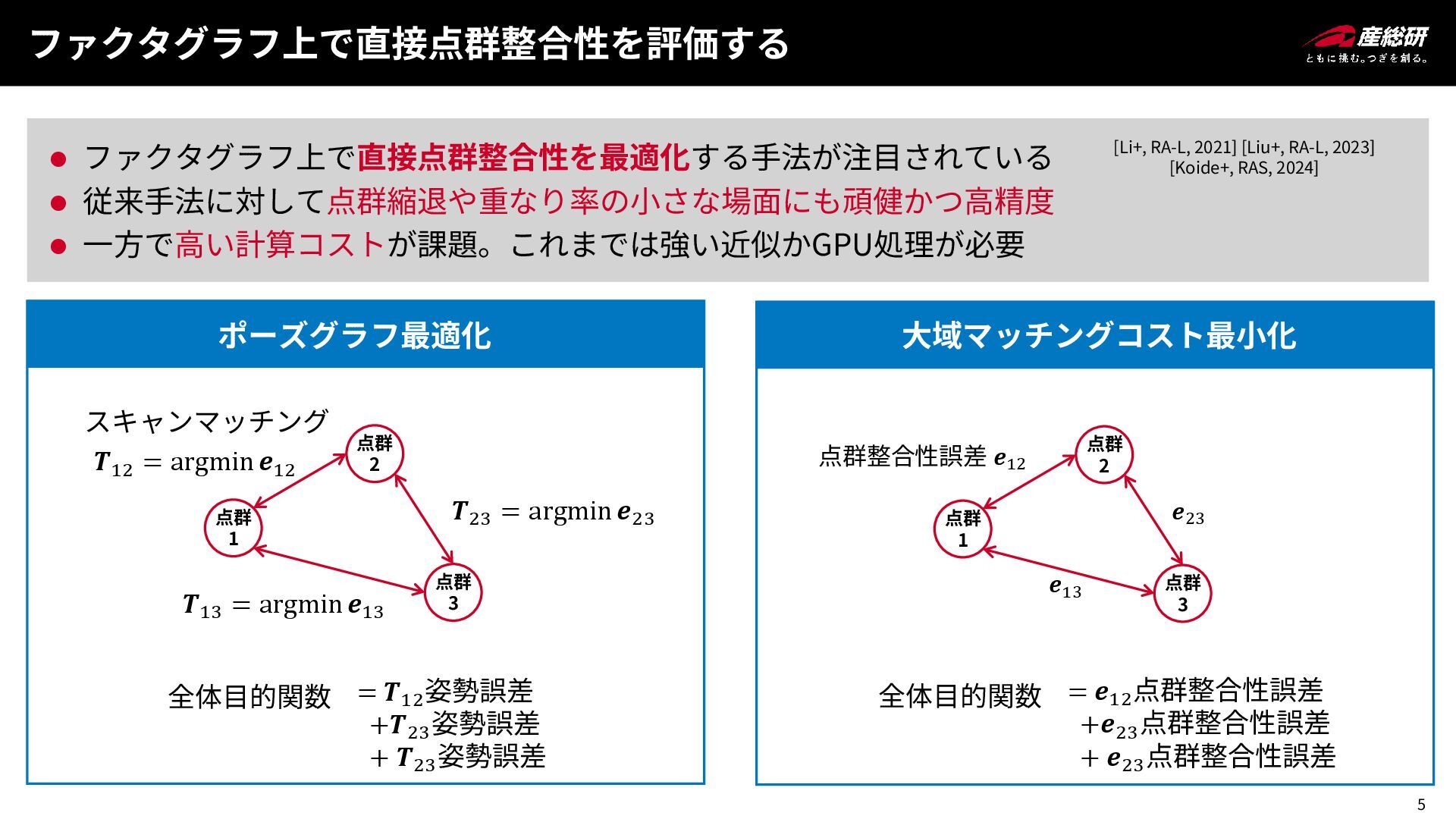
5 ファクタグラフ上で直接点群整合性を評価する ⚫ ファクタグラフ上で直接点群整合性を最適化する手法が注目されている ⚫ 従来手法に対して点群縮退や重なり率の小さな場面にも頑健かつ高精度 ⚫ 一方で高い計算コストが課題。これまでは強い近似かGPU処理が必要 [Li+, RA-L,
2021] [Liu+, RA-L, 2023] [Koide+, RAS, 2024] 点群 1 点群 2 点群 3 スキャンマッチング 点群 1 点群 2 点群 3 点群整合性誤差 𝒆12 𝑻23 = argmin 𝒆23 𝑻13 = argmin 𝒆13 全体目的関数 = 𝑻12 姿勢誤差 +𝑻23 姿勢誤差 + 𝑻23 姿勢誤差 ポーズグラフ最適化 大域マッチングコスト最小化 全体目的関数 = 𝒆12 点群整合性誤差 +𝒆23 点群整合性誤差 + 𝒆23 点群整合性誤差 𝒆23 𝒆13 𝑻12 = argmin 𝒆12
6 手法
7 点群レジストレーション誤差関数(Generalized ICP関数) 𝑓𝑅𝐸𝐺 𝒫𝑖 , 𝒫𝑗 , 𝑻𝑖𝑗 =
𝒑𝑘∈𝒫𝑗 𝑓𝐷2𝐷 𝒑𝑘 ′ , 𝒑𝑘 , 𝑻𝑖𝑗 点群 𝒫𝑖 と 𝒫𝑗 間の整合性を評価する誤差関数 𝒓𝑘 = 𝜱𝑘 ⊤ 𝝁𝑘 ′ − 𝑻𝑖𝑗 𝝁𝑘 𝑓𝐷2𝐷 𝒑𝑘 ′ , 𝒑𝑘 , 𝑻𝑖𝑗 = 𝒓𝑘 𝒓𝑘 ⊤ 対応点ごとの残差関数(分布対分布距離:Generalized ICP) [Segal+, RSS2009] ※最小二乗形式であればどのような関数を使用しても良い 𝒑𝑘 ∼ 𝒩(𝝁𝑘 , 𝚺𝑘 ) 𝒑𝑘 ′ ∼ 𝒩(𝝁𝑘 ′ , 𝚺𝑘 ′ ) 𝒓𝑘 𝜴𝑘 各点周りの局所形状を正規分布で表現 点間距離を混合共分散で重みづけ 𝜱𝑘 𝜱𝑘 ⊤ = 𝜴𝑘 = 𝚺𝑘 ′ + 𝑻𝑖𝑗 𝚺𝑘 𝑻𝑖𝑗 ⊤ −1 ターゲット点群: 𝒫𝑖 ソース点群 : 𝒫𝑗 相対姿勢∶ 𝑻𝑖𝑗 𝒑𝑘 ′ ∈ 𝒫𝑖 ∶ 𝑻𝑖𝑗 𝒑𝑘 の最近傍点
8 ガウスニュートン法 レジストレーション関数の二次関数近似(線形化) 変数更新量の計算(線形方程式を解く) 𝑯Δ𝒙∗ = −𝒃 𝑻∗ =
𝑻 ⊞ Δ𝒙∗ 𝑯, 𝒃 : 全ファクタの情報行列・ベクトルを足し合わせたもの 得られた更新量を変数に適用 𝒆𝑖𝑗 = 𝑓𝐷2𝐷 𝒑1 ⊤ ⋯ 𝑓𝐷2𝐷 𝒑𝑘 ⊤ ⋯ 𝑓𝐷2𝐷 𝒑𝑁 ⊤ ⊤ 現在の推定値 𝑻𝑖𝑗 における残差を並べたベクトル ℝ3𝑁 𝑱𝑖𝑗 = 𝜕𝒆𝑖𝑗 𝜕𝑻𝑖𝑗 残差のヤコビ行列 ℝ3𝑁×6 𝑯𝑖𝑗 = 𝑱𝑖𝑗 ⊤ 𝑱𝑖𝑗 𝒃𝑖𝑗 = 𝑱𝑖𝑗 𝑇 𝒆𝑖𝑗 𝑐𝑖𝑗 = 𝒆𝑖𝑗 ⊤ 𝒆𝑖𝑗 情報行列・情報ベクトル・誤差定数 𝑓𝑅𝐸𝐺 𝒫𝑖 , 𝒫𝑗 , 𝑻𝑖𝑗 + Δ𝒙 ≈ Δ𝒙⊤ 𝑯ij Δ𝐱 + 2𝒃ij ⊤Δ𝒙 + 𝑐ij 現在の推定値において線形化された誤差関数 𝑯𝑖𝑗 , 𝒃𝑖𝑗 , 𝑐𝑖𝑗 で定義される 二次誤差関数 元の非線形誤差関数 線形化
9 𝑯𝑖𝑗 , 𝒃𝑖𝑗 , 𝑐𝑖𝑗 で定義される 二次誤差関数 元の非線形誤差関数 線形化
ガウスニュートン法 レジストレーション関数の二次関数近似(線形化) 𝑱𝑖𝑗 = 𝜕𝒆𝑖𝑗 𝜕𝑻𝑖𝑗 𝒆𝑖𝑗 = 𝑓𝐷2𝐷 𝒑1 ⊤ ⋯ 𝑓𝐷2𝐷 𝒑𝑘 ⊤ ⋯ 𝑓𝐷2𝐷 𝒑𝑁 ⊤ ⊤ 変数更新量の計算(線形方程式を解く) 𝑯Δ𝒙∗ = −𝒃 𝑻∗ = 𝑻 ⊞ Δ𝒙∗ 𝑯, 𝒃 : 全ファクタの情報行列・ベクトルを足し合わせたもの 得られた更新量を変数に適用 現在の推定値 𝑻𝑖𝑗 における残差を並べたベクトル ℝ3𝑁 残差のヤコビ行列 ℝ3𝑁×6 𝑯𝑖𝑗 = 𝑱𝑖𝑗 ⊤ 𝑱𝑖𝑗 𝒃𝑖𝑗 = 𝑱𝑖𝑗 𝑇 𝒆𝑖𝑗 𝑐𝑖𝑗 = 𝒆𝑖𝑗 ⊤ 𝒆𝑖𝑗 𝑓𝑅𝐸𝐺 𝒫𝑖 , 𝒫𝑗 , 𝑻𝑖𝑗 + Δ𝒙 ≈ Δ𝒙⊤ 𝑯ij Δ𝐱 + 2𝒃ij ⊤Δ𝒙 + 𝑐ij 情報行列・情報ベクトル・定数 現在の推定値において線形化された誤差関数 数千~数万点の残差・ヤコビアンの計算が必要! 全点使った再線形化はコストが高い → 点数を減らしたい!
10 レジストレーションのための点群ダウンサンプリング 精度と速度 (点数) を極限まで両立することはできないか? レジストレーション誤差の評価を軽量化するには? → ダウンサンプリング ランダムサンプリング 幾何特徴サンプリング
減らしすぎると精度悪化・破綻 (少なくとも1000点必要) 精度と速度 (点数) のトレードオフ Reijgwart+, RA-L, 2020 Yokozuka+, ICRA2021 Tuna+, T-RO, 2023 Jiao+, ICRA2021 Shiquan+, RA-L, 2024 貪欲法サンプリング 一定数の点をランダムに選択 幾何的多様性を保つよう選択 (e.g., ボクセルグリッド) 品質指標から貪欲選択 リッチな環境では高精度 縮退など影響を強く受ける 実装が簡単&処理が速い 精度の保証が一切できない ある程度品質を担保可能 結局点数次第で劣化
11 厳密コアセット(計算幾何学) 𝑓 𝒳 ≈ 𝑓( ෩ 𝒳) コアセット:関数 𝑓
に対する入力集合 𝒳 の出力を近似する部分集合 ෩ 𝒳 元集合 コアセット 𝑠. 𝑡. ෩ 𝒳 ⊂ 𝒳 and ෩ 𝒳 ≪ 𝒳 𝑓 𝒳 = 𝑓( ෩ 𝒳) 元集合 厳密コアセット 厳密コアセット:関数 𝑓 に対する入力集合 𝒳 の出力と同じ出力を与える部分集合 ෩ 𝒳 𝑠. 𝑡. ෩ 𝒳 ⊂ 𝒳 and ෩ 𝒳 ≪ 𝒳
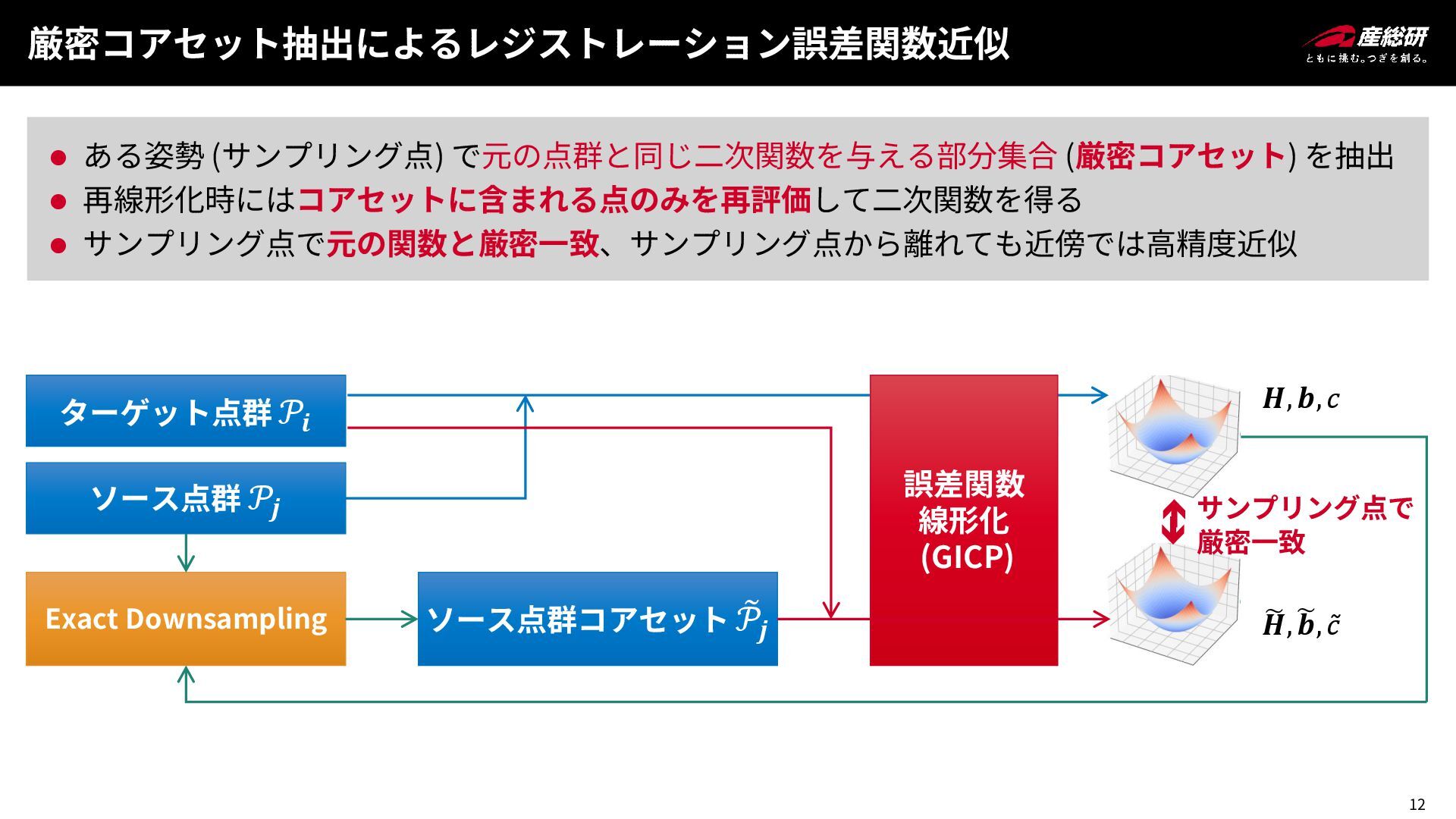
12 𝑯, 𝒃, 𝑐 厳密コアセット抽出によるレジストレーション誤差関数近似 ⚫ ある姿勢 (サンプリング点) で元の点群と同じ二次関数を与える部分集合 (厳密コアセット)
を抽出 ⚫ 再線形化時にはコアセットに含まれる点のみを再評価して二次関数を得る ⚫ サンプリング点で元の関数と厳密一致、サンプリング点から離れても近傍では高精度近似 ターゲット点群 𝒫𝒊 ソース点群 𝒫𝒋 Exact Downsampling ソース点群コアセット ෨ 𝒫𝒋 誤差関数 線形化 (GICP) ෩ 𝑯, ෩ 𝒃, ǁ 𝑐 サンプリング点で 厳密一致
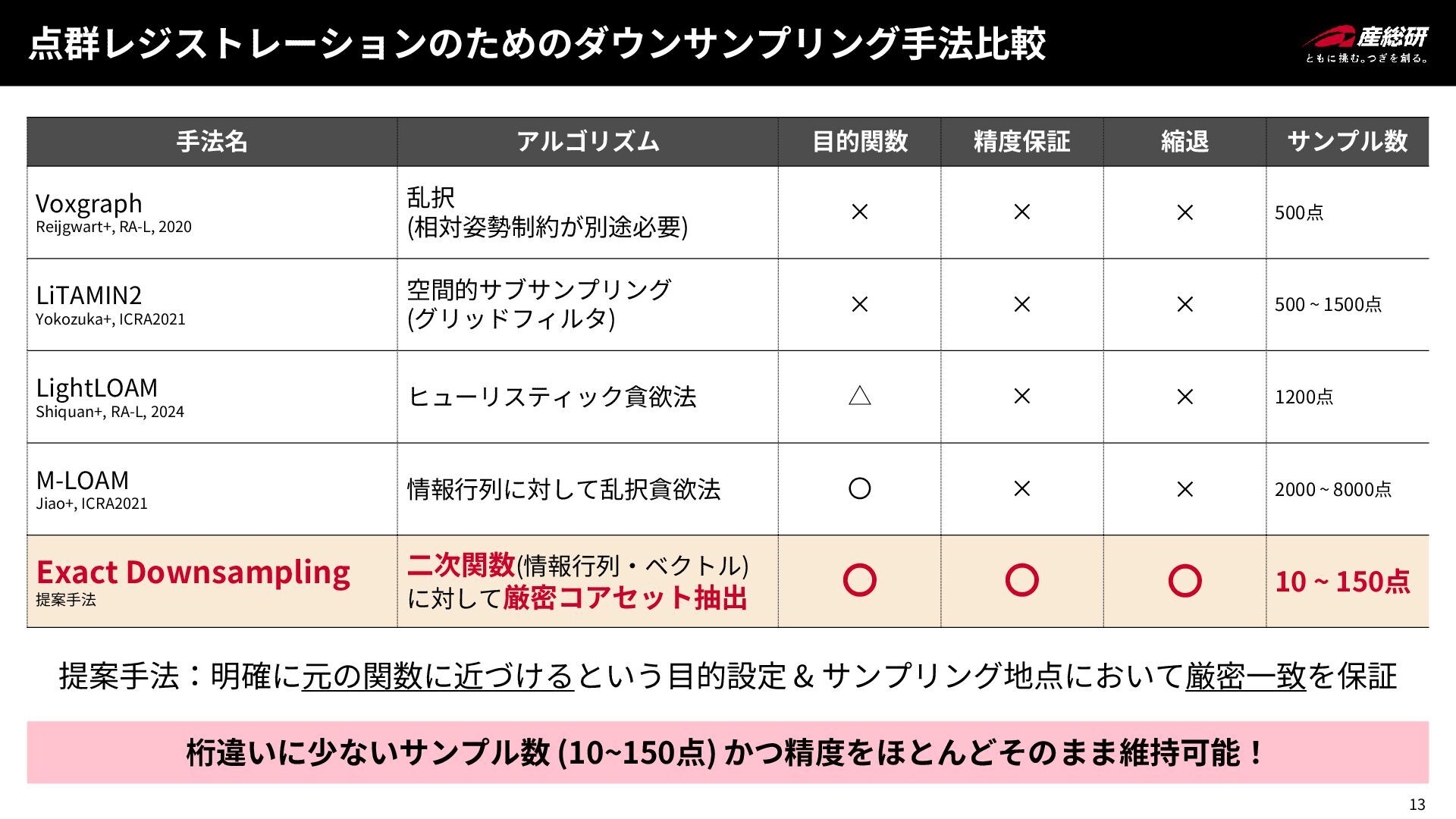
13 点群レジストレーションのためのダウンサンプリング手法比較 手法名 アルゴリズム 目的関数 精度保証 縮退 サンプル数 Voxgraph Reijgwart+,
RA-L, 2020 乱択 (相対姿勢制約が別途必要) × × × 500点 LiTAMIN2 Yokozuka+, ICRA2021 空間的サブサンプリング (グリッドフィルタ) × × × 500 ~ 1500点 LightLOAM Shiquan+, RA-L, 2024 ヒューリスティック貪欲法 △ × × 1200点 M-LOAM Jiao+, ICRA2021 情報行列に対して乱択貪欲法 〇 × × 2000 ~ 8000点 Exact Downsampling 提案手法 二次関数(情報行列・ベクトル) に対して厳密コアセット抽出 〇 〇 〇 10 ~ 150点 提案手法:明確に元の関数に近づけるという目的設定 & サンプリング地点において厳密一致を保証 桁違いに少ないサンプル数 (10~150点) かつ精度をほとんどそのまま維持可能!
14 厳密コアセットの存在証明 情報行列 𝑯𝑖𝑗 を厳密復元する残差部分集合は存在する? ※便宜上、ファクタ添え字 𝑖, 𝑗 を省略& 𝑘
を残差番号に変更 ※[Maalouf+, NeurIPS2019] に則った説明 𝑯 = 𝑱⊤𝑱 ℝ𝐷×𝐷 𝑱 = 𝑱𝟏 ⋮ 𝑱𝒌 ⋮ 𝑱𝑵 ℝ𝑁×𝐷 1 𝑁 𝒉 = 1 𝑁 𝑘 𝒉𝑘 𝒉 = flatten(𝑯) ℝ𝐷2 ℝ1×𝐷 ←1番目の残差の偏微分 ←k番目の残差の偏微分 ℝ1×𝐷 = 𝑘 𝑯𝑘 𝑯 = 𝑘 𝑱𝑘 ⊤𝑱𝑘 各残差に対応する積の総和 𝒉𝑘 = flatten 𝑯𝑘 ℝ𝐷2 ※要素を一列に並べる 情報行列 𝑯 はヤコビ行列の各行に対応する 𝑱𝐤 ⊤𝑱𝐤 = 𝑯𝒌 の平均をN倍すれば求められる
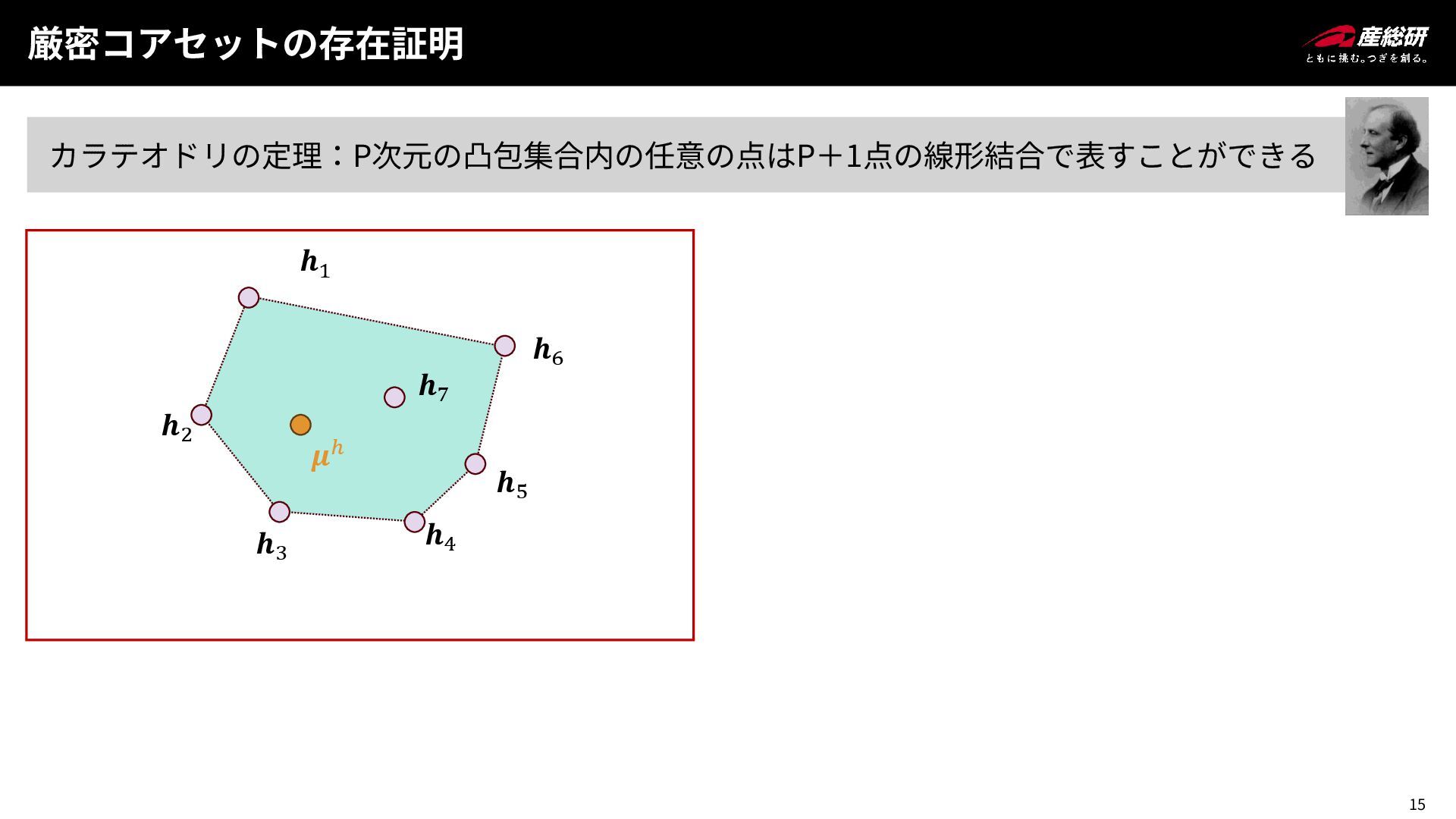
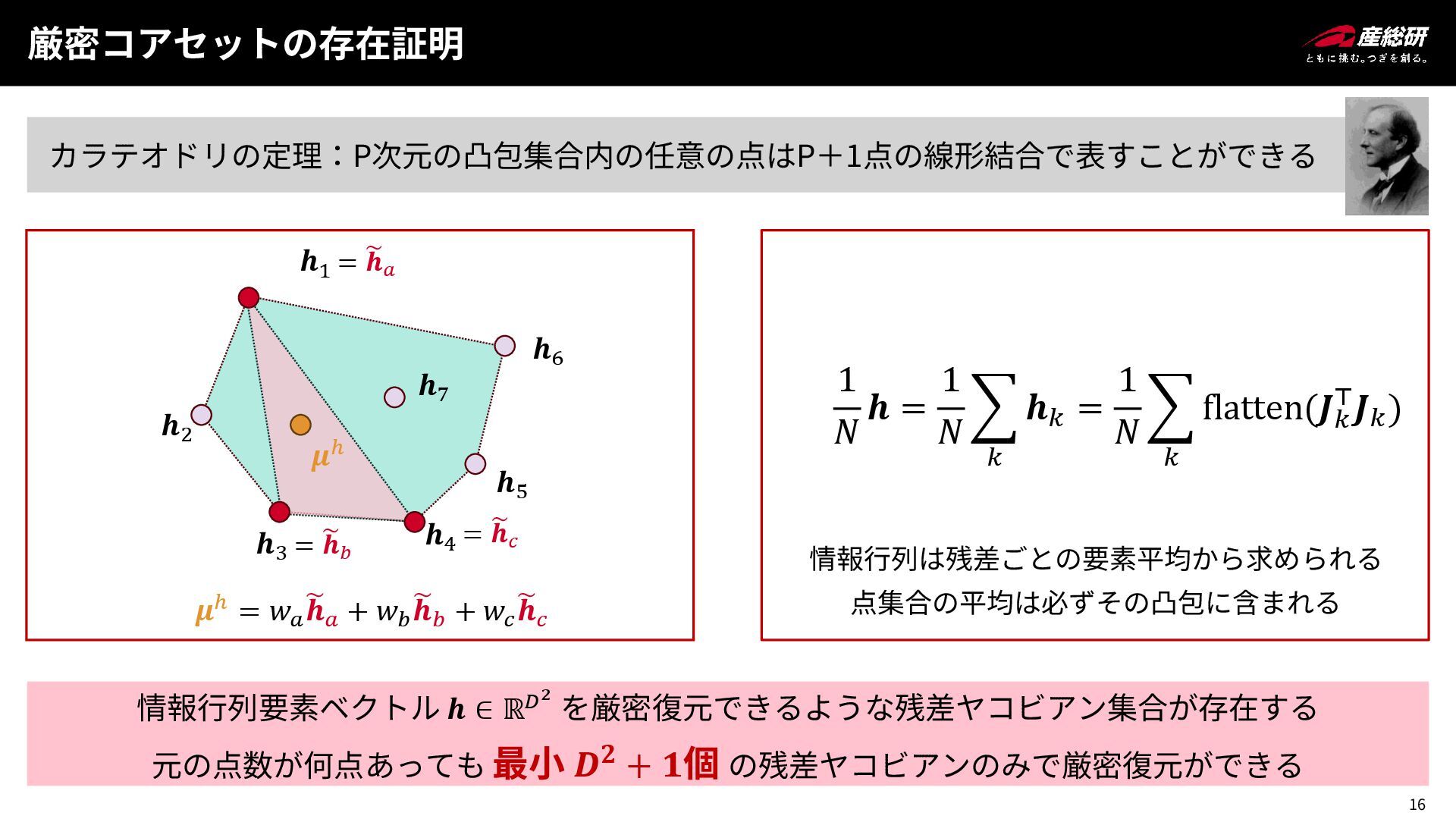
15 厳密コアセットの存在証明 カラテオドリの定理:P次元の凸包集合内の任意の点はP+1点の線形結合で表すことができる 𝒉1 𝒉2 𝒉3 𝒉4 𝒉5 𝒉7 𝒉6
𝝁ℎ
16 厳密コアセットの存在証明 カラテオドリの定理:P次元の凸包集合内の任意の点はP+1点の線形結合で表すことができる 𝒉1 𝒉2 𝒉3 𝒉4 𝒉5 𝒉7 𝒉6
𝝁ℎ 𝝁ℎ = 𝑤𝑎 ෩ 𝒉𝑎 + 𝑤𝑏 ෩ 𝒉𝑏 + 𝑤𝑐 ෩ 𝒉𝑐 情報行列要素ベクトル 𝒉 ∈ ℝ𝐷2 を厳密復元できるような残差ヤコビアン集合が存在する 元の点数が何点あっても 最小 𝑫𝟐 + 𝟏個 の残差ヤコビアンのみで厳密復元ができる 1 𝑁 𝒉 = 1 𝑁 𝑘 𝒉𝑘 = 1 𝑁 𝑘 flatten(𝑱𝑘 ⊤𝑱𝑘 ) 情報行列は残差ごとの要素平均から求められる 点集合の平均は必ずその凸包に含まれる = ෩ 𝒉𝑎 = ෩ 𝒉𝑏 = ෩ 𝒉𝑐
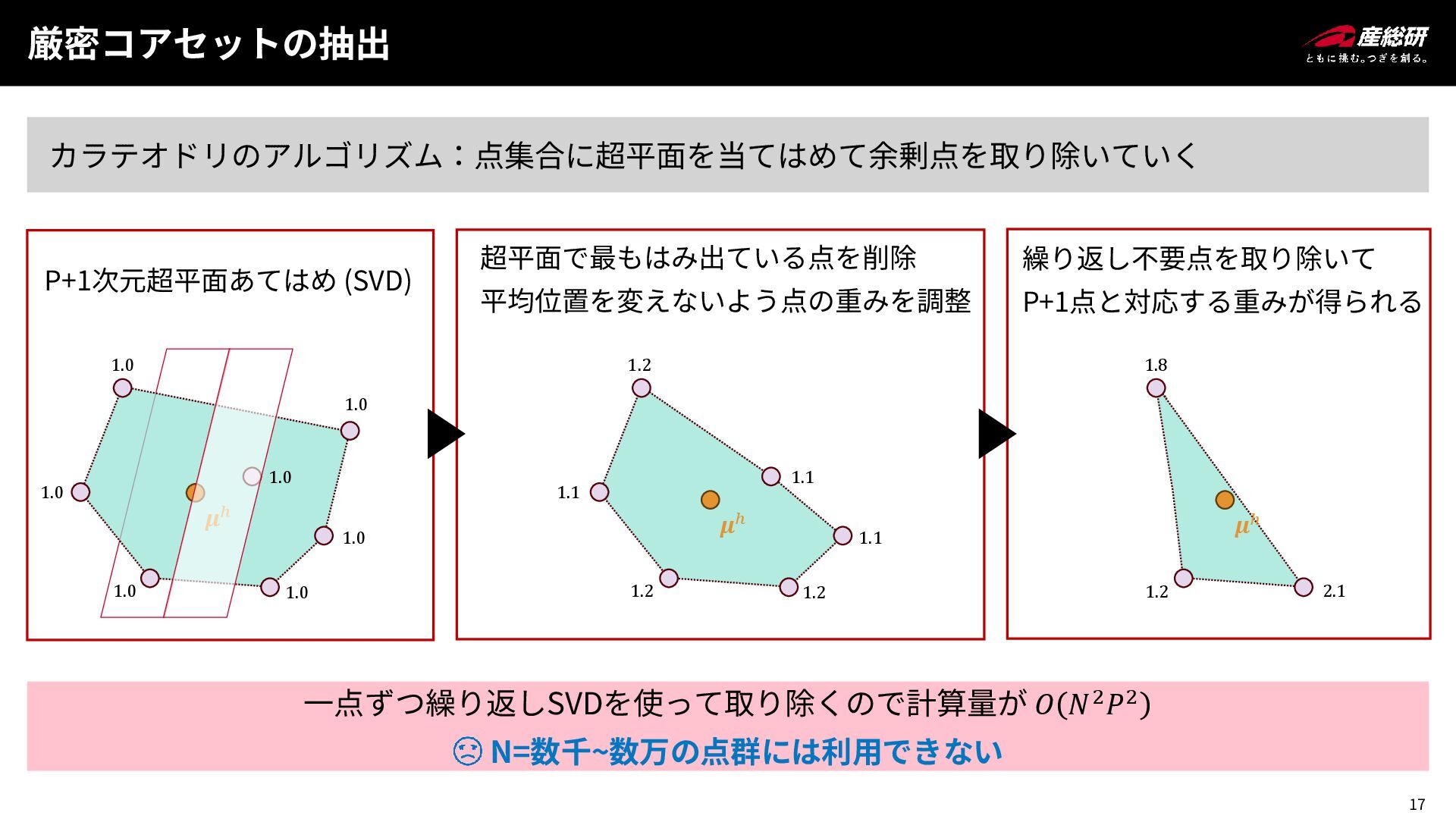
17 厳密コアセットの抽出 カラテオドリのアルゴリズム:点集合に超平面を当てはめて余剰点を取り除いていく 𝝁ℎ P+1次元超平面あてはめ (SVD) 1.0 1.0 1.0 1.0
1.0 1.0 1.0 一点ずつ繰り返しSVDを使って取り除くので計算量が 𝑂 𝑁2𝑃2 N=数千~数万の点群には利用できない 𝝁ℎ 超平面で最もはみ出ている点を削除 平均位置を変えないよう点の重みを調整 1.2 1.1 1.2 1.2 1.1 1.1 𝝁ℎ 繰り返し不要点を取り除いて P+1点と対応する重みが得られる 1.8 1.2 2.1
18 厳密コアセットの高速抽出 コアセットの高速抽出 [Maalouf+, NeurIPS2019] 入力集合をK個のクラスタに分割 各クラスタの平均を計算 𝜇1 𝜇2 𝜇3
𝜇4 𝜇5 𝜇6 𝜇7 𝜇8 𝑥
19 厳密コアセットの高速抽出 コアセットの高速抽出 [Maalouf+, NeurIPS2019] 入力集合をK個のクラスタに分割 各クラスタの平均を計算 𝜇1 𝜇2 𝜇3
𝜇4 𝜇5 𝜇6 𝜇7 𝜇8 𝑥 カラテオドリのアルゴリズムで クラスタ平均のコアセット抽出 𝜇1 𝜇2 𝜇3 𝜇4 𝜇5 𝜇6 𝜇7 𝜇8 𝑥
20 厳密コアセットの高速抽出 コアセットの高速抽出 [Maalouf+, NeurIPS2019] 𝜇5 入力集合をK個のクラスタに分割 各クラスタの平均を計算 カラテオドリのアルゴリズムで クラスタ平均のコアセット抽出
コアセットに選ばれたクラスタに 含まれる点集合を選択 𝜇1 𝜇2 𝜇3 𝜇4 𝜇5 𝜇6 𝜇7 𝜇8 𝑥 𝜇1 𝜇2 𝜇3 𝜇4 𝜇5 𝜇6 𝜇7 𝜇8 𝑥 𝜇1 𝜇2 𝜇3 𝜇4 𝜇6 𝜇7 𝜇8 𝑥
21 𝜇5 厳密コアセットの高速抽出 コアセットの高速抽出 [Maalouf+, NeurIPS2019] 入力集合をK個のクラスタに分割 各クラスタの平均を計算 カラテオドリのアルゴリズムで クラスタ平均のコアセット抽出
コアセットに選ばれたクラスタに 含まれる点集合を選択 1~3 を繰り返して点を 取り除いていく 𝜇1 𝜇2 𝜇3 𝜇4 𝜇5 𝜇6 𝜇7 𝜇8 𝑥 𝜇1 𝜇2 𝜇3 𝜇4 𝜇5 𝜇6 𝜇7 𝜇8 𝑥 𝜇1 𝜇2 𝜇3 𝜇4 𝜇6 𝜇7 𝜇8 𝑥 𝑥 計算量が 𝑂 𝑁2𝑃2 から 𝑶 𝑵𝑷𝟐 に軽減 → 点群にも適用可能に レジストレーション誤差関数への応用 ⚫ 𝐻 に加えて 𝑏, 𝑐 も同様に復元することで二次関数自体を復元する (𝑃 = 𝐷2 + 𝐷 + 1 = 43) ⚫ 情報行列は対称なので非上三角成分を除いて 𝑃 = 28 に削減 (28 + 1 = 29残差が最小 約10点に相当) ⚫ 最小個数以上の任意個数の抽出を可能にして、関数の非線形性をより正確に近似 ⚫ SVDの代わりにLU分解を使って高速化 (元手法 125ms → 提案手法 5ms)
22 再サンプリングによる精度担保 ⚫ 推定姿勢がサンプリング点から離れると近似精度が劣化する ⚫ 精度を担保するため推定姿勢がサンプリング点から離れた場合、再サンプリングする ෩ 𝑻 近傍における姿勢変化=高精度近似 サンプリング点
෩ 𝑻 で関数をキャプチャ ෩ 𝑻 から離れた姿勢=近似精度劣化 →再サンプリング 姿勢変動の大きい初期イテレーションで不要なサンプリングによるオーバーヘッドが発生する 姿勢変動 姿勢変動 サンプリング点
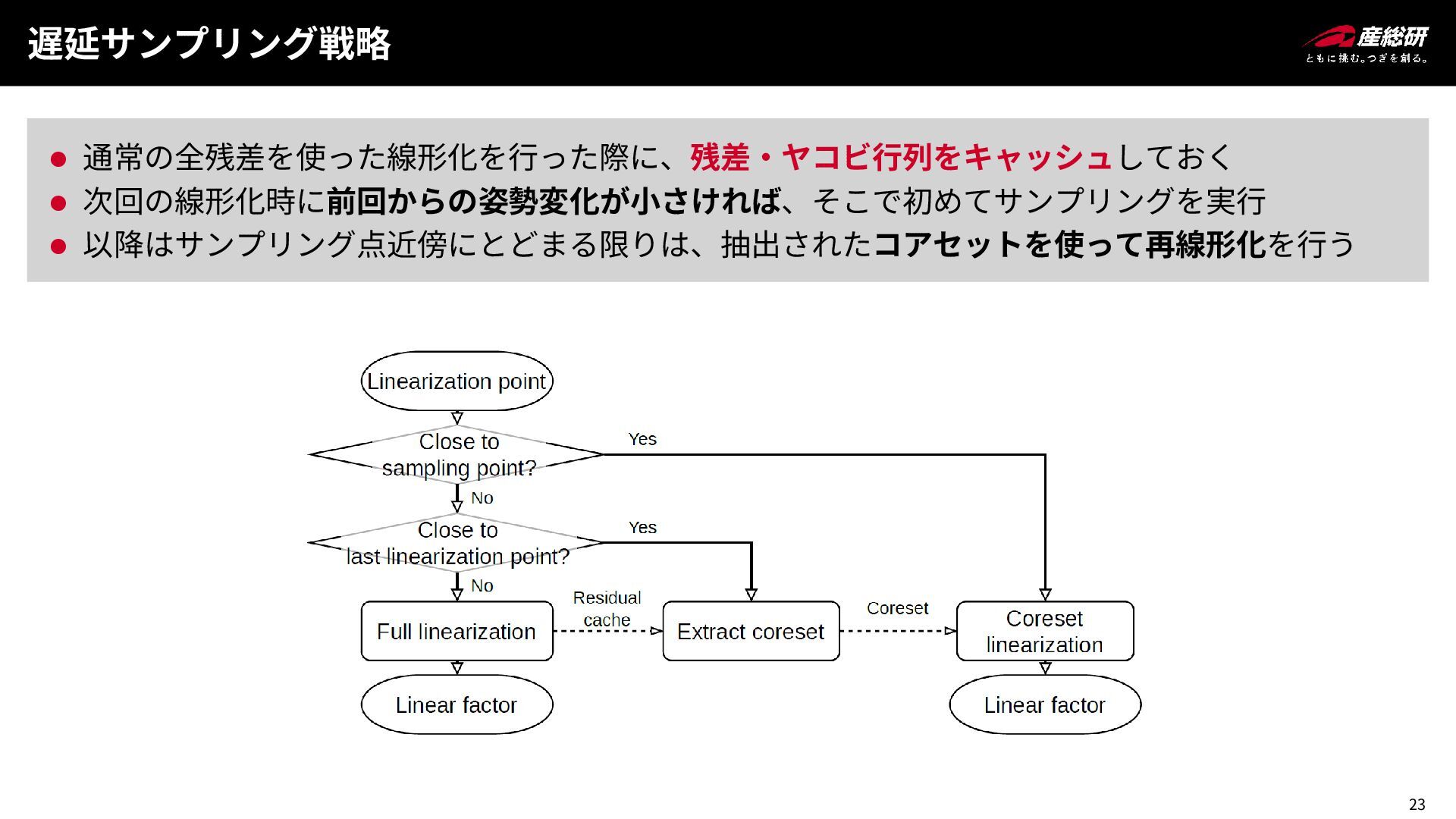
23 遅延サンプリング戦略 ⚫ 通常の全残差を使った線形化を行った際に、残差・ヤコビ行列をキャッシュしておく ⚫ 次回の線形化時に前回からの姿勢変化が小さければ、そこで初めてサンプリングを実行 ⚫ 以降はサンプリング点近傍にとどまる限りは、抽出されたコアセットを使って再線形化を行う
24 実装
25 オドメトリ推定ファクタグラフ ⚫ GPU用に設計されたキーフレームマッチング&ウィンドウ最適化グラフをそのまま利用 [Koide+, RAS2024] ⚫ 各フレームと過去3フレーム・キーフレーム間でマッチングコスト制約を生成 ⚫ IMU制約と併せて、過去5秒間
(50フレーム) のセンサ状態 (姿勢・速度) を同時推定
26 大域軌跡最適化ファクタグラフ ⚫ GPU用に設計された大域軌跡最適化グラフをそのまま利用 [Koide+, RAS2024] ⚫ オーバーラップ率15%以上の全てのサブマップ間にマッチングコスト制約を生成 𝑥0 𝑥1
𝑥2 𝑥3 𝑥4 𝑥5 Submap Matching cost factor 高密度な大域最適化グラフ 最適化にはインクリメンタル最適化 (iSAM2) を使用
27 その他の実装詳細 チャンクベースボクセルマップによる高速重なり率推定 並列計算 8 8 8 ⚫ 8x8x8 =
512bit の占有状態を1チャンクとしたボクセルマップ ⚫ キャッシュフレンドリーな Flat Hashmap によるボクセル検索 ⚫ Intel TBB のタスクスティーリングを利用した高並列計算 ⚫ 点群前処理・オドメトリ推定・大域軌跡最適化が非同期に 現在空いているコアをフル活用して動作する https://actor-framework.readthedocs.io 1チャンク = 512bit
28 実験
29 レジストレーション誤差関数の近似精度評価 (1/2) ⚫ 前後点群ペアに対して初期姿勢でダウンサンプリングを実行 (1000ペア) ⚫ サンプリング地点からランダムに動かした時の元の関数との誤差を評価する ⚫ 比較対象として
ランダムサンプリング と 二次関数近似 を用いる ⚫ サンプル数は32 ~ 256残差で評価 (11 ~ 86点) ターゲット点群 𝒫𝑖 ソース点群 𝒫𝑗 サンプリング 変位ノイズ コアセット ෨ 𝒫𝑗 サンプリング点 ෩ 𝑻 = 初期姿勢 非線形誤差 線形化 (GICP) 比較 + KITTI Vision Benchmark Suite [Geiger+, CVPR2012]
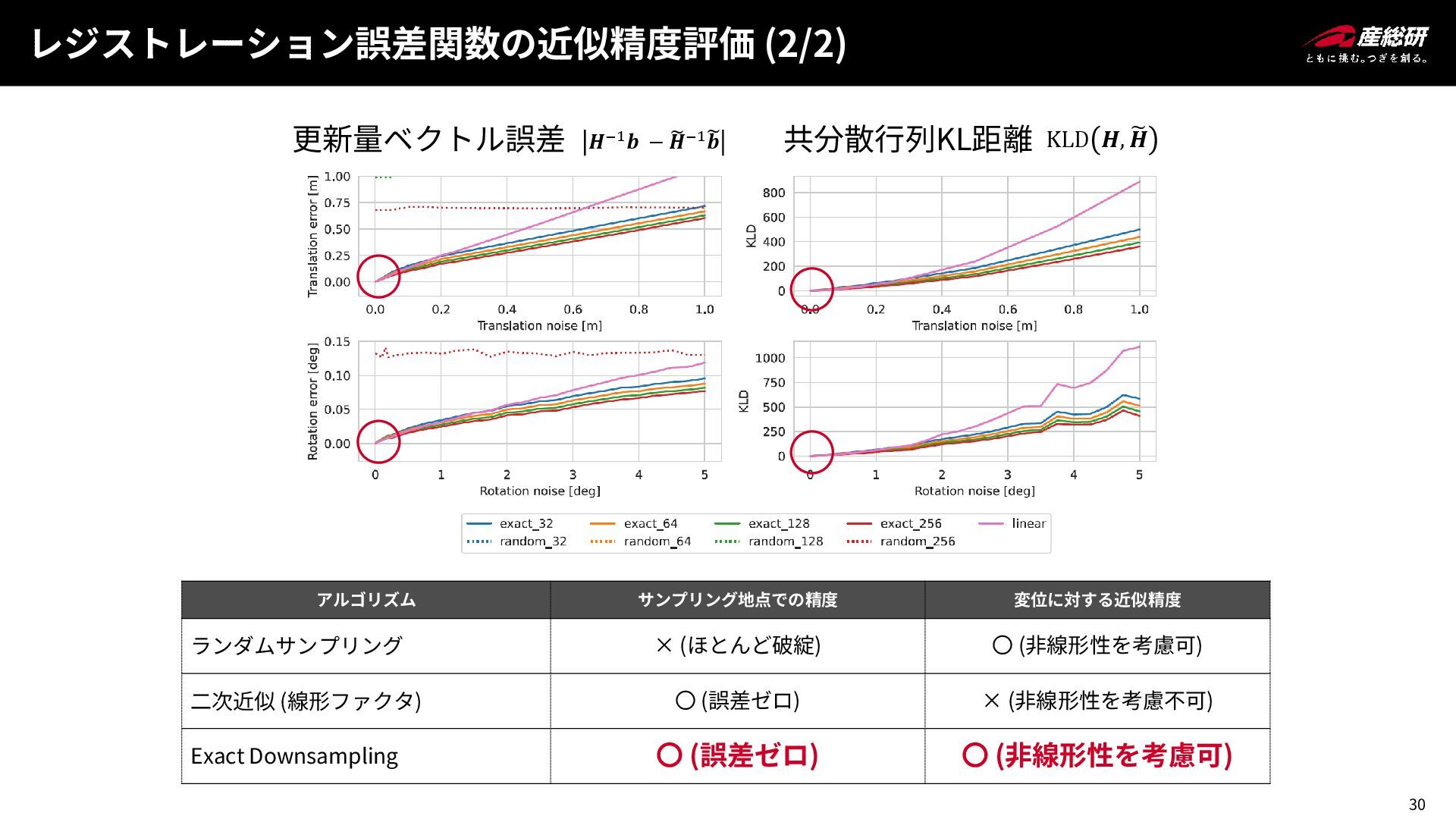
30 レジストレーション誤差関数の近似精度評価 (2/2) 更新量ベクトル誤差 共分散行列KL距離 𝑯−1𝒃 − ෩ 𝑯−1෩ 𝒃
KLD 𝑯, ෩ 𝑯 アルゴリズム サンプリング地点での精度 変位に対する近似精度 ランダムサンプリング × (ほとんど破綻) 〇 (非線形性を考慮可) 二次近似 (線形ファクタ) 〇 (誤差ゼロ) × (非線形性を考慮不可) Exact Downsampling 〇 (誤差ゼロ) 〇 (非線形性を考慮可)
31 SLAM精度比較データセット ⚫ LiDAR : Ouster OS1-128 & Livox Mid-70
(提案手法はOusterのみ使用) IMU : VN100 & VN200 ⚫ 車載 (ntu) と 手持ち (kth & tuhh) の二種類のセットアップ ⚫ ループクローズ有/無 で分けて精度評価 (オドメトリ推定のみ & 大域最適化込み) MCD VIRAL Dataset [Thien-Minh+, CVPR2024]
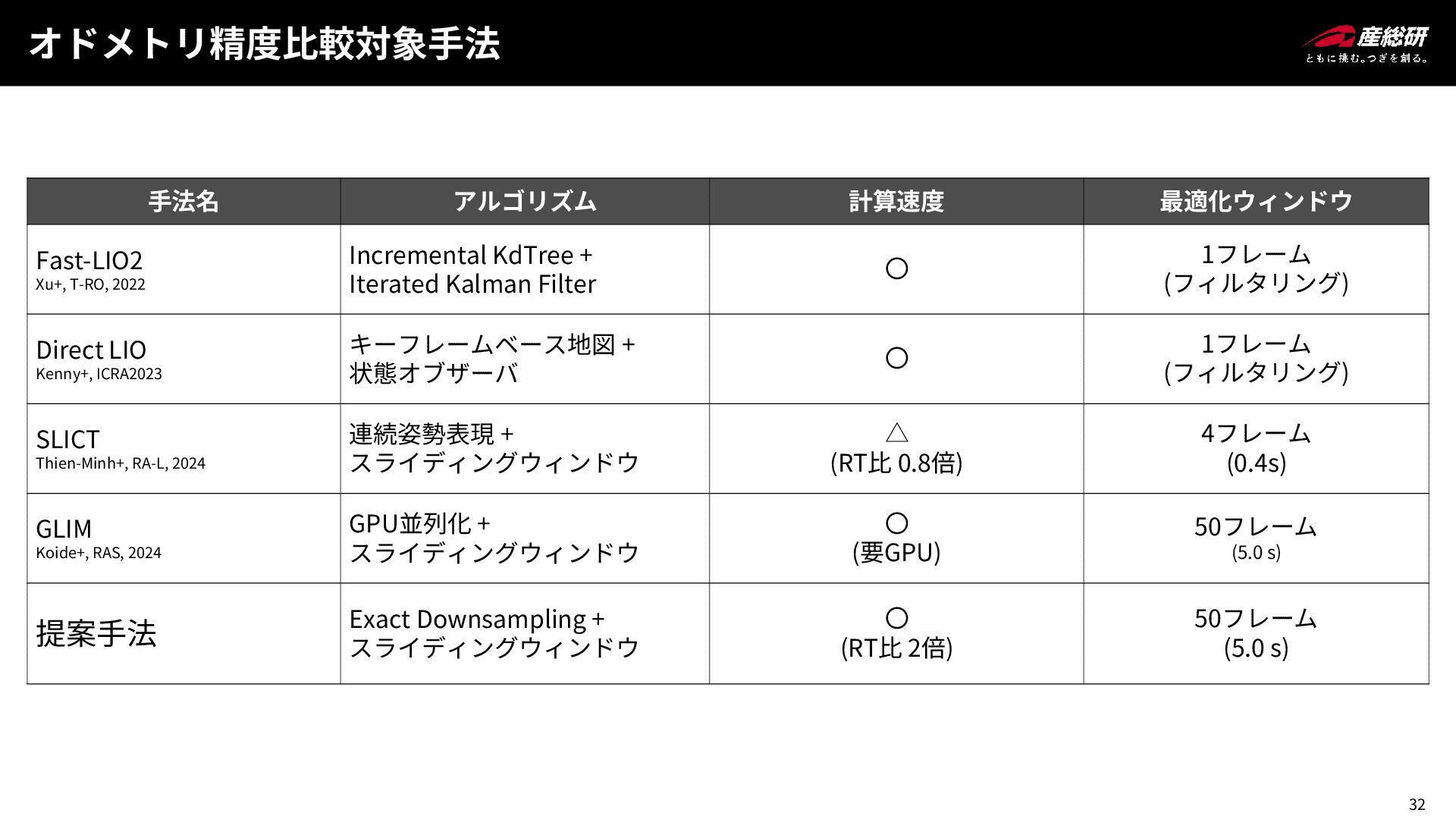
32 オドメトリ精度比較対象手法 手法名 アルゴリズム 計算速度 最適化ウィンドウ Fast-LIO2 Xu+, T-RO, 2022
Incremental KdTree + Iterated Kalman Filter 〇 1フレーム (フィルタリング) Direct LIO Kenny+, ICRA2023 キーフレームベース地図 + 状態オブザーバ 〇 1フレーム (フィルタリング) SLICT Thien-Minh+, RA-L, 2024 連続姿勢表現 + スライディングウィンドウ △ (RT比 0.8倍) 4フレーム (0.4s) GLIM Koide+, RAS, 2024 GPU並列化 + スライディングウィンドウ 〇 (要GPU) 50フレーム (5.0 s) 提案手法 Exact Downsampling + スライディングウィンドウ 〇 (RT比 2倍) 50フレーム (5.0 s)
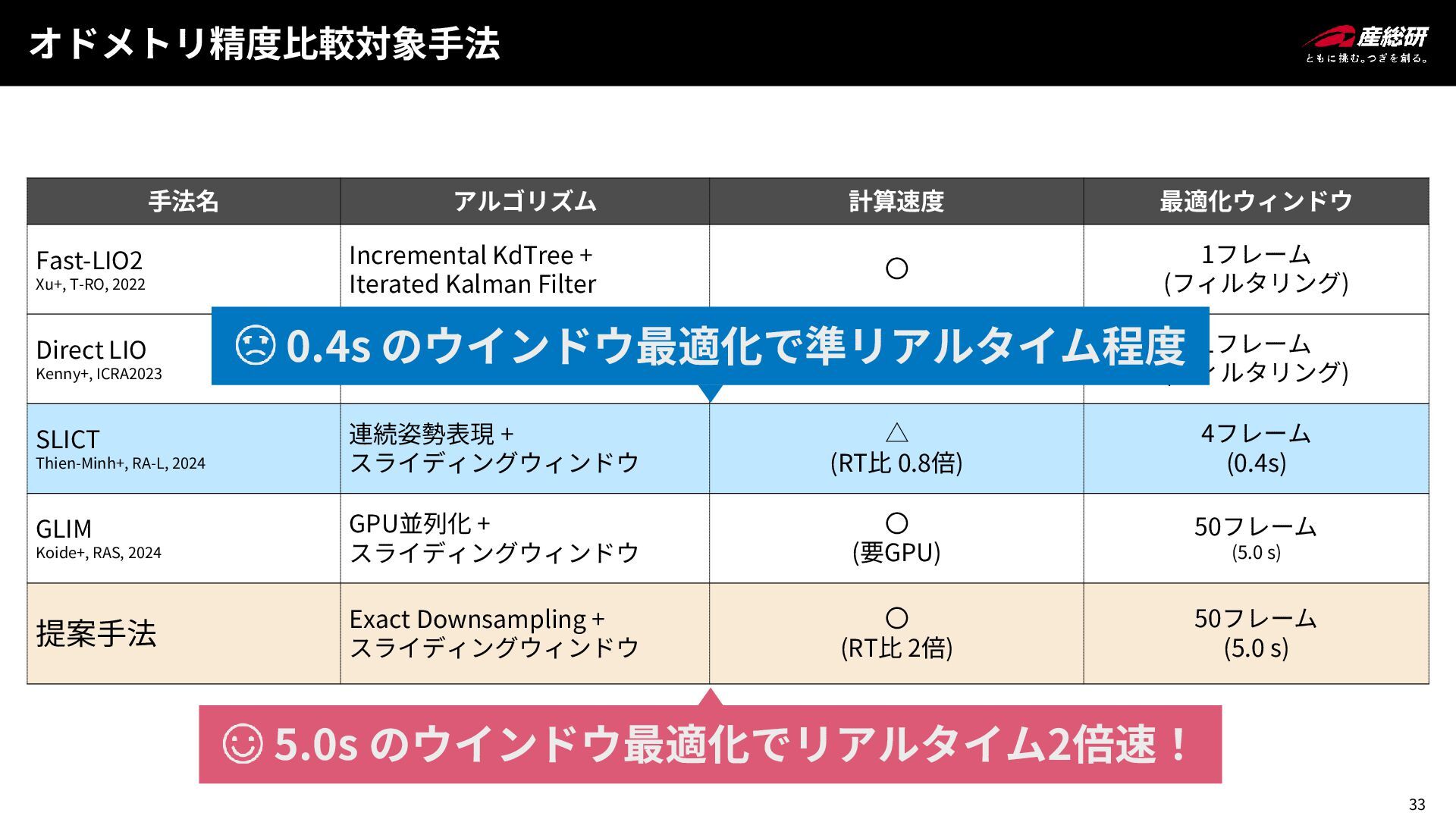
33 オドメトリ精度比較対象手法 手法名 アルゴリズム 計算速度 最適化ウィンドウ Fast-LIO2 Xu+, T-RO, 2022
Incremental KdTree + Iterated Kalman Filter 〇 1フレーム (フィルタリング) Direct LIO Kenny+, ICRA2023 キーフレームベース 〇 1フレーム (フィルタリング) SLICT Thien-Minh+, RA-L, 2024 連続姿勢表現 + スライディングウィンドウ △ (RT比 0.8倍) 4フレーム (0.4s) GLIM Koide+, RAS, 2024 GPU並列化 + スライディングウィンドウ 〇 (要GPU) 50フレーム (5.0 s) 提案手法 Exact Downsampling + スライディングウィンドウ 〇 (RT比 2倍) 50フレーム (5.0 s) 0.4s のウインドウ最適化で準リアルタイム程度 5.0s のウインドウ最適化でリアルタイム2倍速!
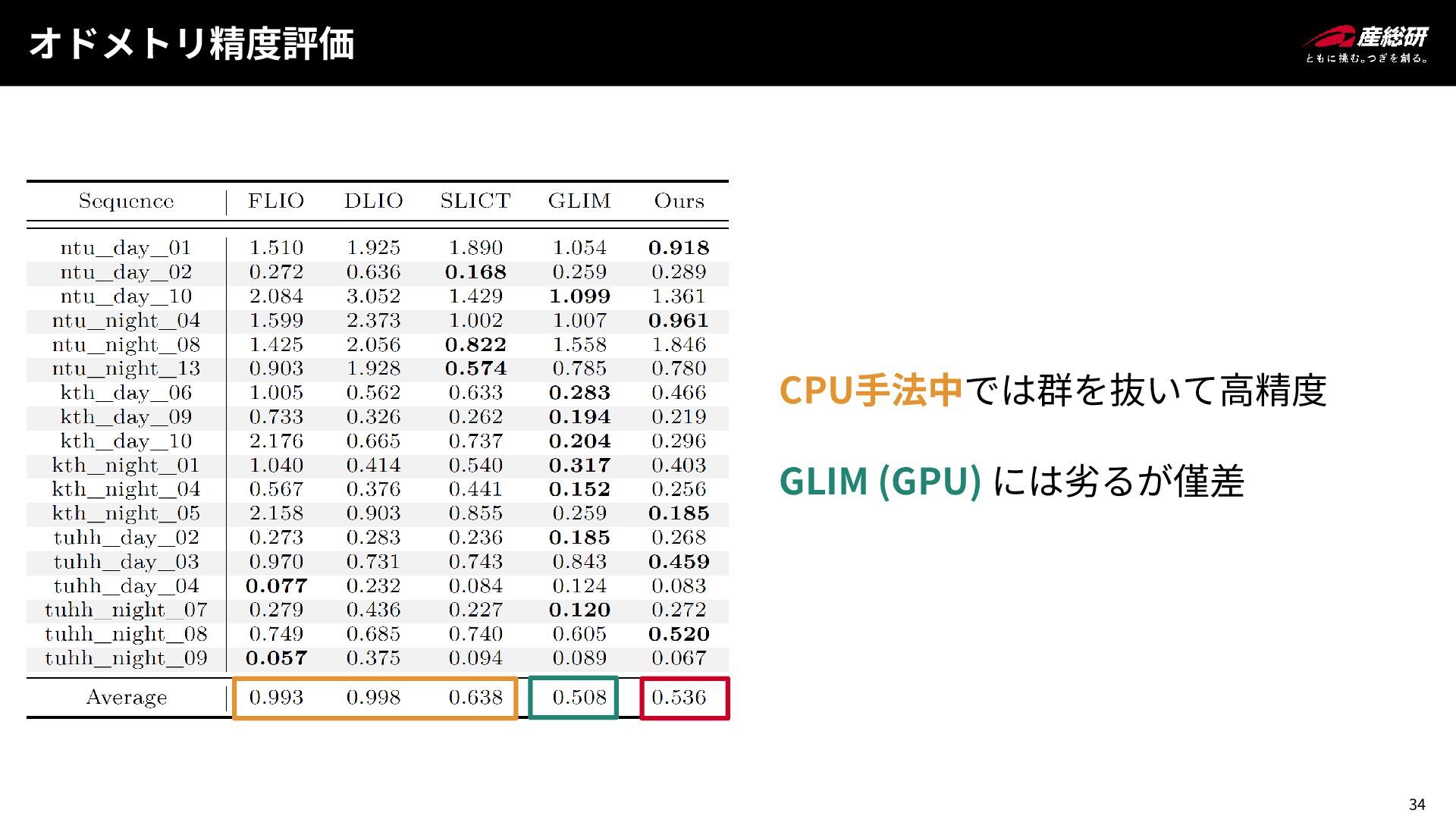
34 オドメトリ精度評価 CPU手法中では群を抜いて高精度 GLIM (GPU) には劣るが僅差
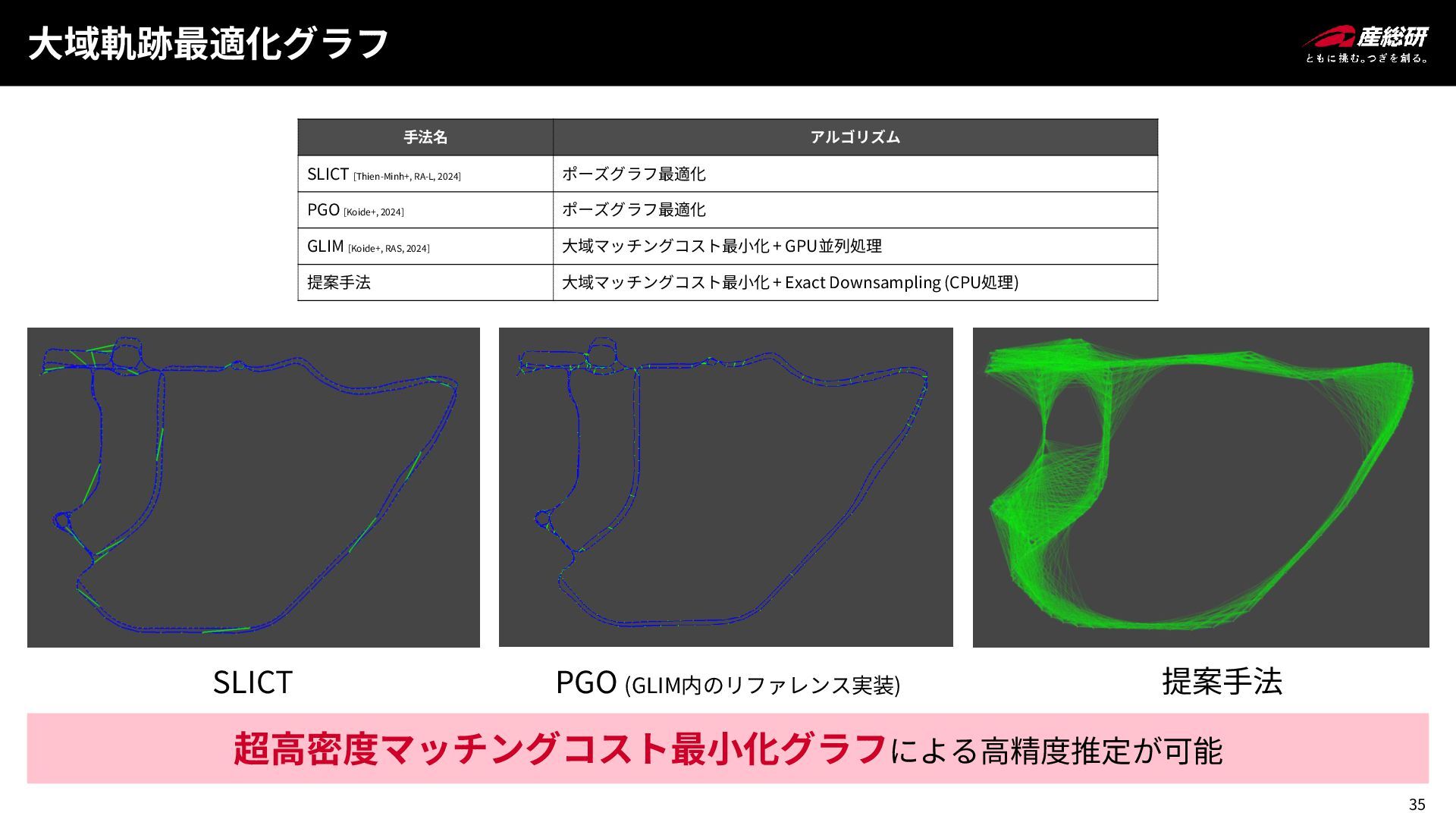
35 大域軌跡最適化グラフ SLICT PGO (GLIM内のリファレンス実装) 提案手法 手法名 アルゴリズム SLICT [Thien-Minh+,
RA-L, 2024] ポーズグラフ最適化 PGO [Koide+, 2024] ポーズグラフ最適化 GLIM [Koide+, RAS, 2024] 大域マッチングコスト最小化 + GPU並列処理 提案手法 大域マッチングコスト最小化 + Exact Downsampling (CPU処理) 超高密度マッチングコスト最小化グラフによる高精度推定が可能
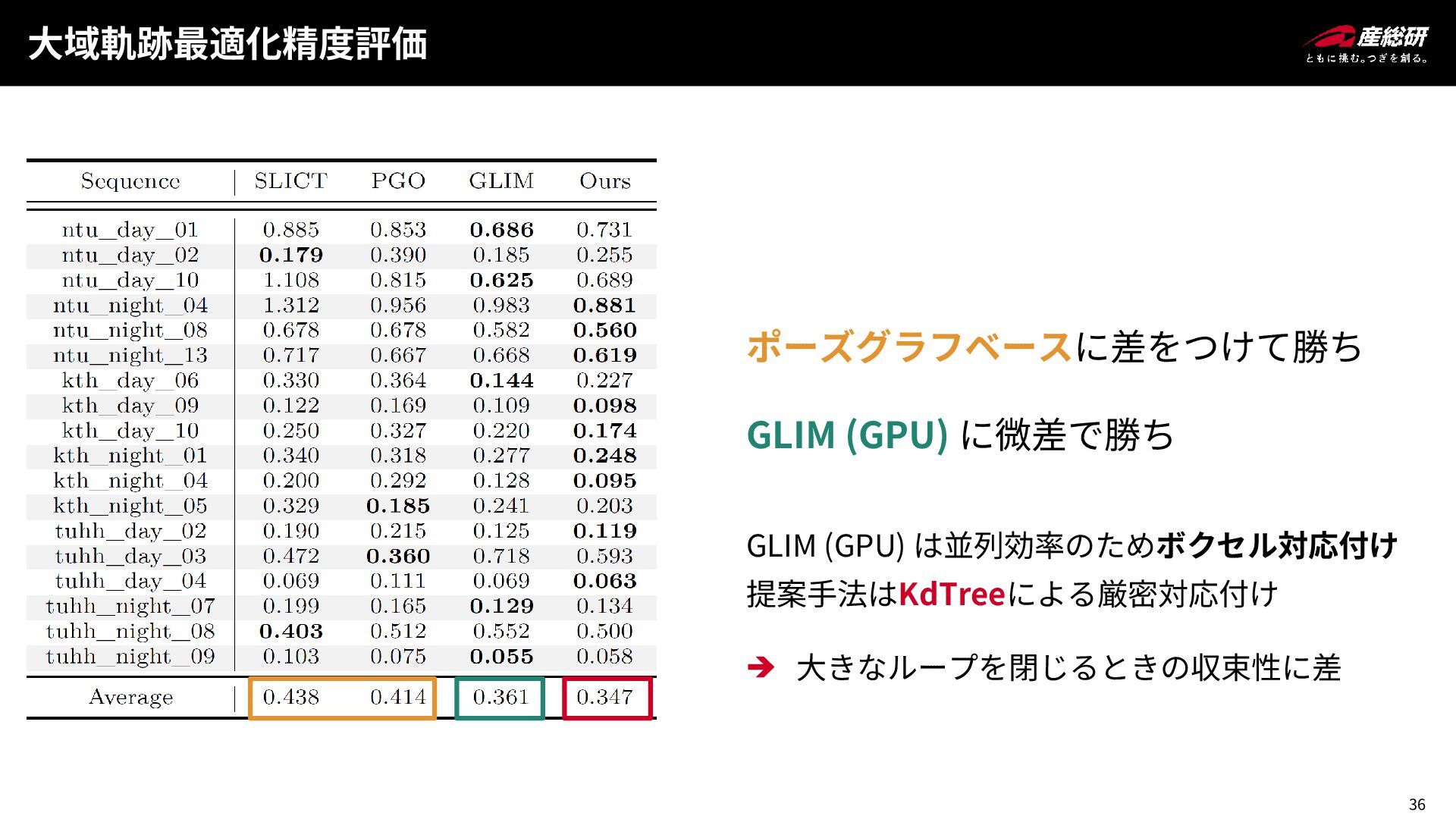
36 大域軌跡最適化精度評価 ポーズグラフベースに差をつけて勝ち GLIM (GPU) に微差で勝ち GLIM (GPU) は並列効率のためボクセル対応付け 提案手法はKdTreeによる厳密対応付け
大きなループを閉じるときの収束性に差
37 大域軌跡最適化精度評価 GPUに匹敵する精度の推定をCPUのみで実現
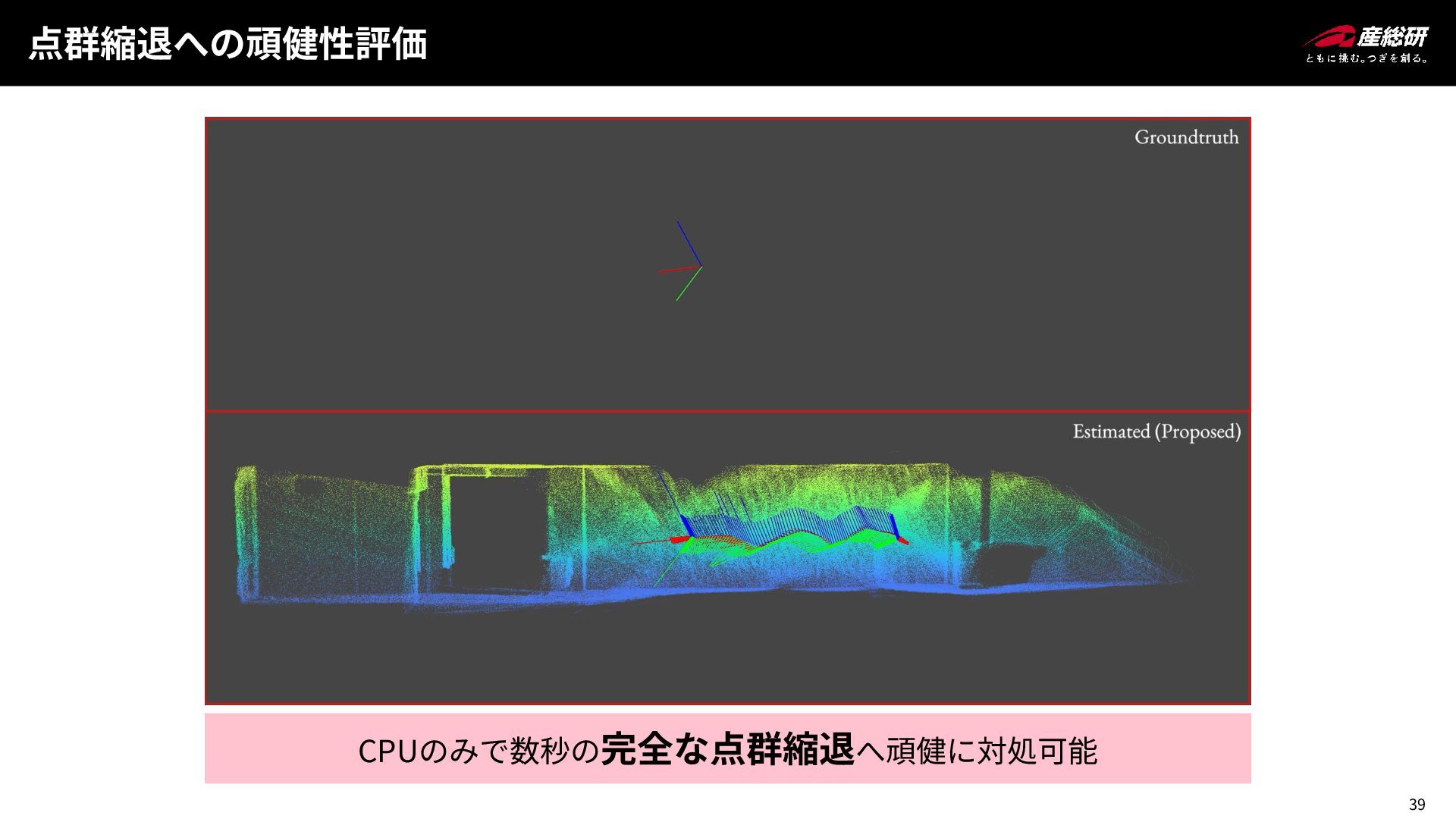
38 点群縮退への頑健性評価 大きなウィンドウ幅 (5s) を持つ GLIM (GPU) と提案手法のみ妥当な精度 ⚫ 数秒にわたる完全な点群縮退を含むデータセット
⚫ 状態フィルタリングや短い最適化ウィンドウを用いる従来手法では対処が不可能 Flatwall Dataset [Koide+, RAS, 2024]
39 点群縮退への頑健性評価 CPUのみで数秒の完全な点群縮退へ頑健に対処可能
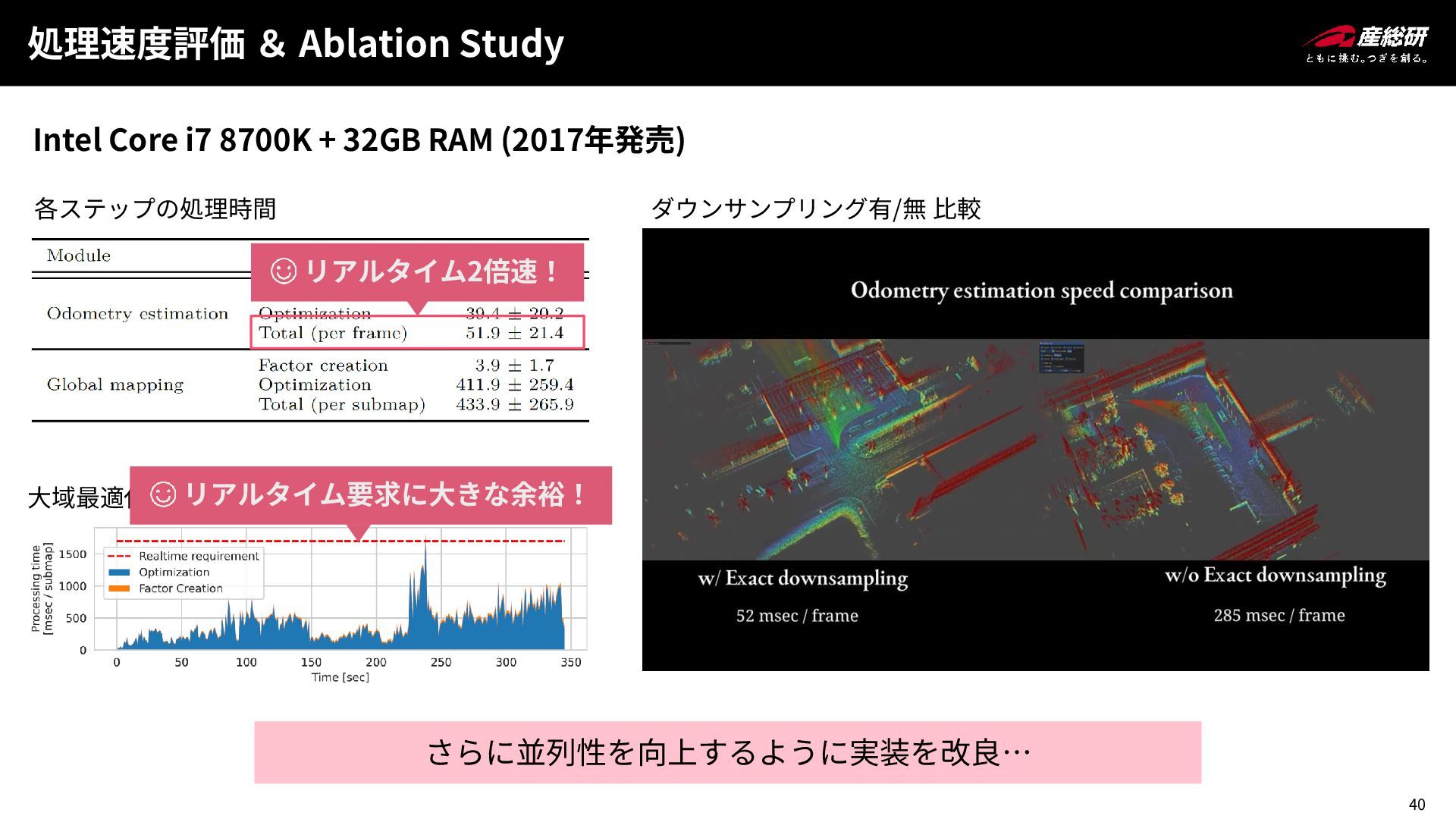
40 処理速度評価 & Ablation Study 各ステップの処理時間 大域最適化の処理時間推移 リアルタイム2倍速! リアルタイム要求に大きな余裕! さらに並列性を向上するように実装を改良…
Intel Core i7 8700K + 32GB RAM (2017年発売) ダウンサンプリング有/無 比較
41 低廉PC上でのリアルタイム処理 GMKTec G3 Plus Intel N150 (4コア) 18,000円 設定の軽微変更で1.5
~ 2倍速処理 組み込み用途での利用も可能
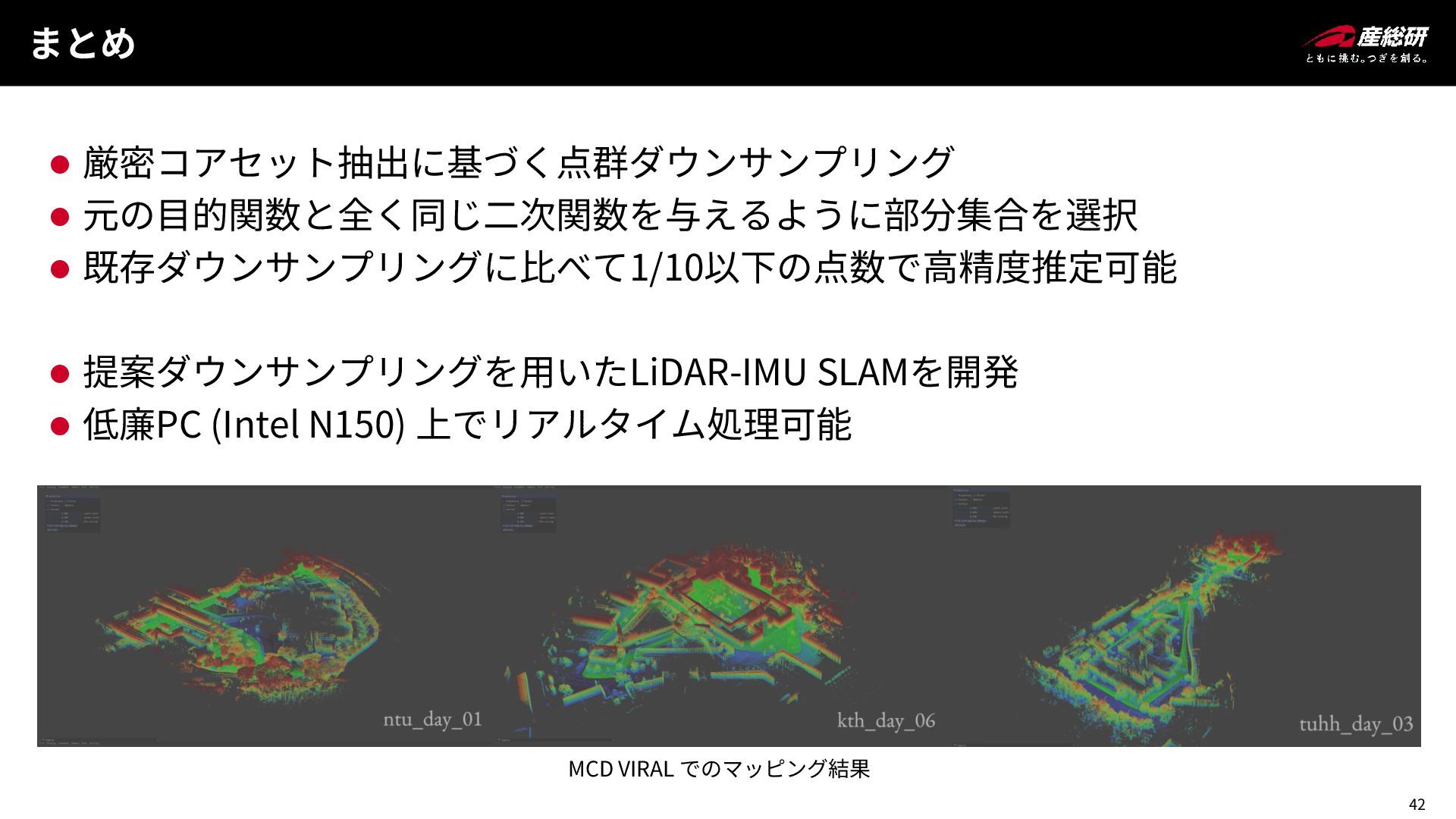
42 まとめ ⚫ 厳密コアセット抽出に基づく点群ダウンサンプリング ⚫ 元の目的関数と全く同じ二次関数を与えるように部分集合を選択 ⚫ 既存ダウンサンプリングに比べて1/10以下の点数で高精度推定可能 ⚫ 提案ダウンサンプリングを用いたLiDAR-IMU
SLAMを開発 ⚫ 低廉PC (Intel N150) 上でリアルタイム処理可能 MCD VIRAL でのマッピング結果
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![18 厳密コアセットの高速抽出 コアセットの高速抽出 [Maalouf+, NeurIPS2019] 入力集合をK個のクラスタに分割 各クラスタの平均を計算 𝜇1 𝜇2 𝜇3](https://files.speakerdeck.com/presentations/9e884a9b25cc4612a308ee5bba7dac71/slide_17.jpg){kind=link}
![19 厳密コアセットの高速抽出 コアセットの高速抽出 [Maalouf+, NeurIPS2019] 入力集合をK個のクラスタに分割 各クラスタの平均を計算 𝜇1 𝜇2 𝜇3](https://files.speakerdeck.com/presentations/9e884a9b25cc4612a308ee5bba7dac71/slide_18.jpg){kind=link}
![20 厳密コアセットの高速抽出 コアセットの高速抽出 [Maalouf+, NeurIPS2019] 𝜇5 入力集合をK個のクラスタに分割 各クラスタの平均を計算 カラテオドリのアルゴリズムで クラスタ平均のコアセット抽出](https://files.speakerdeck.com/presentations/9e884a9b25cc4612a308ee5bba7dac71/slide_19.jpg){kind=link}
![21 𝜇5 厳密コアセットの高速抽出 コアセットの高速抽出 [Maalouf+, NeurIPS2019] 入力集合をK個のクラスタに分割 各クラスタの平均を計算 カラテオドリのアルゴリズムで クラスタ平均のコアセット抽出](https://files.speakerdeck.com/presentations/9e884a9b25cc4612a308ee5bba7dac71/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![25 オドメトリ推定ファクタグラフ ⚫ GPU用に設計されたキーフレームマッチング&ウィンドウ最適化グラフをそのまま利用 [Koide+, RAS2024] ⚫ 各フレームと過去3フレーム・キーフレーム間でマッチングコスト制約を生成 ⚫ IMU制約と併せて、過去5秒間](https://files.speakerdeck.com/presentations/9e884a9b25cc4612a308ee5bba7dac71/slide_24.jpg){kind=link}
![26 大域軌跡最適化ファクタグラフ ⚫ GPU用に設計された大域軌跡最適化グラフをそのまま利用 [Koide+, RAS2024] ⚫ オーバーラップ率15%以上の全てのサブマップ間にマッチングコスト制約を生成 𝑥0 𝑥1](https://files.speakerdeck.com/presentations/9e884a9b25cc4612a308ee5bba7dac71/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}