Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介:Not All Tokens Are What You Need for Pretr...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Kosuke Nishida
August 21, 2025
Research
280
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介:Not All Tokens Are What You Need for Pretraining
Kosuke Nishida
August 21, 2025
More Decks by Kosuke Nishida
See All by Kosuke Nishida
⼤規模⾔語モデルとVision-and-Language
kosuken
6
2.4k
論文紹介:What Learning Algorithm is In-Context Learning? Investigation with Linear Models
kosuken
0
1.1k
論文紹介: Memorisation versus Generalisation in Pre-trained Language Models
kosuken
2
1.3k
Other Decks in Research
See All in Research
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
360
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
300
Using our influence and power for patient safety
helenbevan
0
380
【Zozo Research 技術共有会】三次元領域の現在と展望
mickey_0226
3
500
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
140
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
160
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
170
医療LLMの現在地〜最新研究から社会実装までを考える〜
kento1109
1
1.6k
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
710
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
410
LA-Bench 2025:実験指示から 実行可能手順を生成するためのデータセット/LA-Bench 2025: A Dataset for Generating Executable Experimental Procedures from Experimental Instructions
stktu
0
110
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
530
Featured
See All Featured
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
The untapped power of vector embeddings
frankvandijk
2
1.8k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Between Models and Reality
mayunak
4
380
Navigating Team Friction
lara
192
16k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Designing for Timeless Needs
cassininazir
1
420
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
820
My Coaching Mixtape
mlcsv
0
180
Design in an AI World
tapps
1
270
Building Applications with DynamoDB
mza
96
7.1k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
370
Transcript
© NTT, Inc. 2025 紹介者:西田光甫(NTT人間研) 最先端NLP勉強会2025
© NTT, Inc. 2025 1 • 背景 • 提案手法 •
実験 • まとめ 目次
© NTT, Inc. 2025 2 背景
© NTT, Inc. 2025 3 本研究の動機と目的 • LLMの事前学習において,全データの活用が常に最適・実行可能とは限らない • 文書レベルのデータフィルタリングは有効だが,なおノイズが残る
• 強すぎるフィルタリングは有効なデータを削除してしまう • webから集めたデータは下流タスクにおける理想的な分布と乖離 →全てのトークンに同じ損失を割り当てることは非効率的なのでは?
© NTT, Inc. 2025 4 本研究の提案と貢献 • 事前学習中に損失を計算するトークンを選抜するSelective Language Modeling
(SLM)を提案 • 簡単・難しいトークンは学習対象から除き,学習する価値のあるトークンだけを学習したい
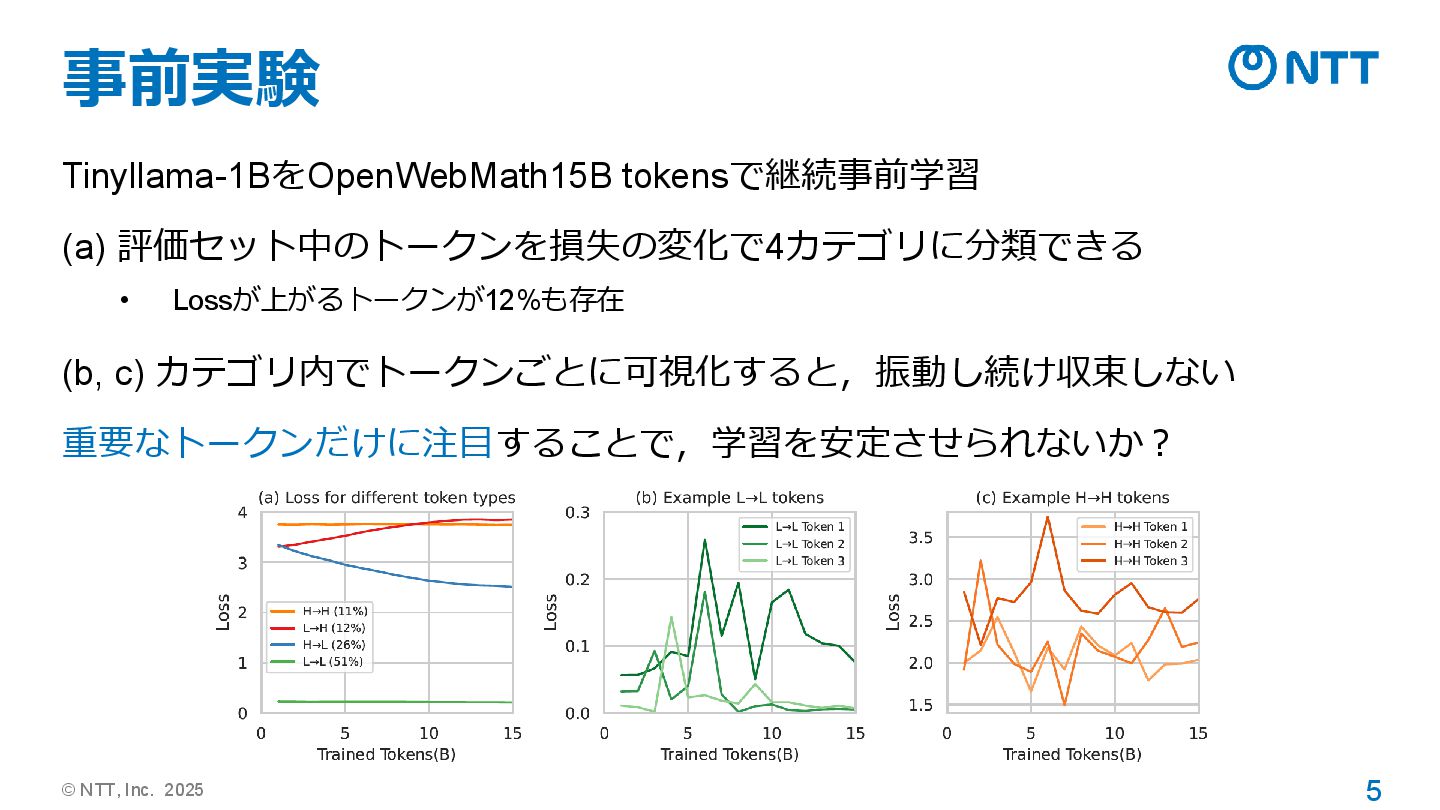
© NTT, Inc. 2025 5 事前実験 Tinyllama-1BをOpenWebMath15B tokensで継続事前学習 (a) 評価セット中のトークンを損失の変化で4カテゴリに分類できる
• Lossが上がるトークンが12%も存在 (b, c) カテゴリ内でトークンごとに可視化すると,振動し続け収束しない 重要なトークンだけに注目することで,学習を安定させられないか?
© NTT, Inc. 2025 6 提案手法
© NTT, Inc. 2025 7 提案手法概要 Required: 学習対象モデル𝑀, 高品質データ𝐷𝑞, 大規模データ𝐷
1. モデル𝑀を𝐷𝑞 を用いたCausal Language Modelingで訓練し,Referenceモデル (RM)を得る 2. モデル𝑀を𝐷を用いたSelective Language Modelingで訓練し,学習したモデル を出力する
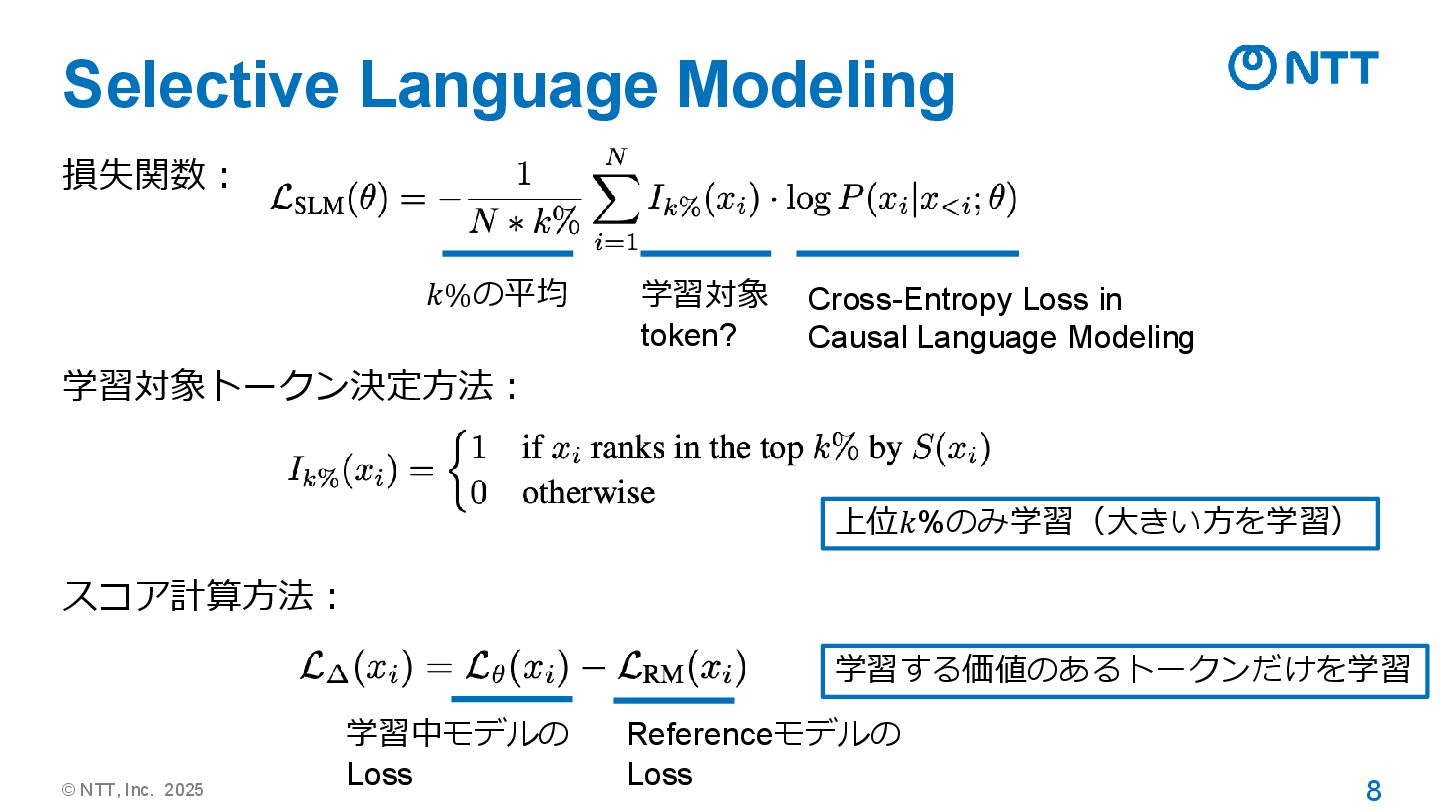
© NTT, Inc. 2025 8 Selective Language Modeling 損失関数: 学習対象トークン決定方法:
スコア計算方法: 𝑘%の平均 学習対象 token? Cross-Entropy Loss in Causal Language Modeling 上位𝑘%のみ学習(大きい方を学習) 学習中モデルの Loss Referenceモデルの Loss 学習する価値のあるトークンだけを学習
© NTT, Inc. 2025 9 実験
© NTT, Inc. 2025 10 実験設定・データ • 数学ドメイン • 高品質データ:数学Instruction-Tuningデータセット混合(0.5B
tokens) • 学習コーパス:OpenWebMath (14B tokens) • 評価ベンチマーク:math-evaluation-harness • 一般ドメイン • 高品質データ:Tulu-v2 + OpenHermes-2.5(1.9B tokens) • 学習コーパス:SlimPajama + StarCoderData + OpenWebMath (80B tokens) • 評価ベンチマーク:lm-evaluation-harness [所感] 高品質データがInstruction-Tuning用データなので,Instruction-Tuningに 近い事前学習をする効果?
© NTT, Inc. 2025 11 実験設定・その他 • 学習対象モデル • Tinyllama-1.1B
• Mistral-7B • トークン選択率𝑘 • 60% for Tinyllama-1.1B • 70% for Mistral-7B • ベースラインモデル • 提案手法を用いずに継続事前学習したモデル(CT) • 市中LLM
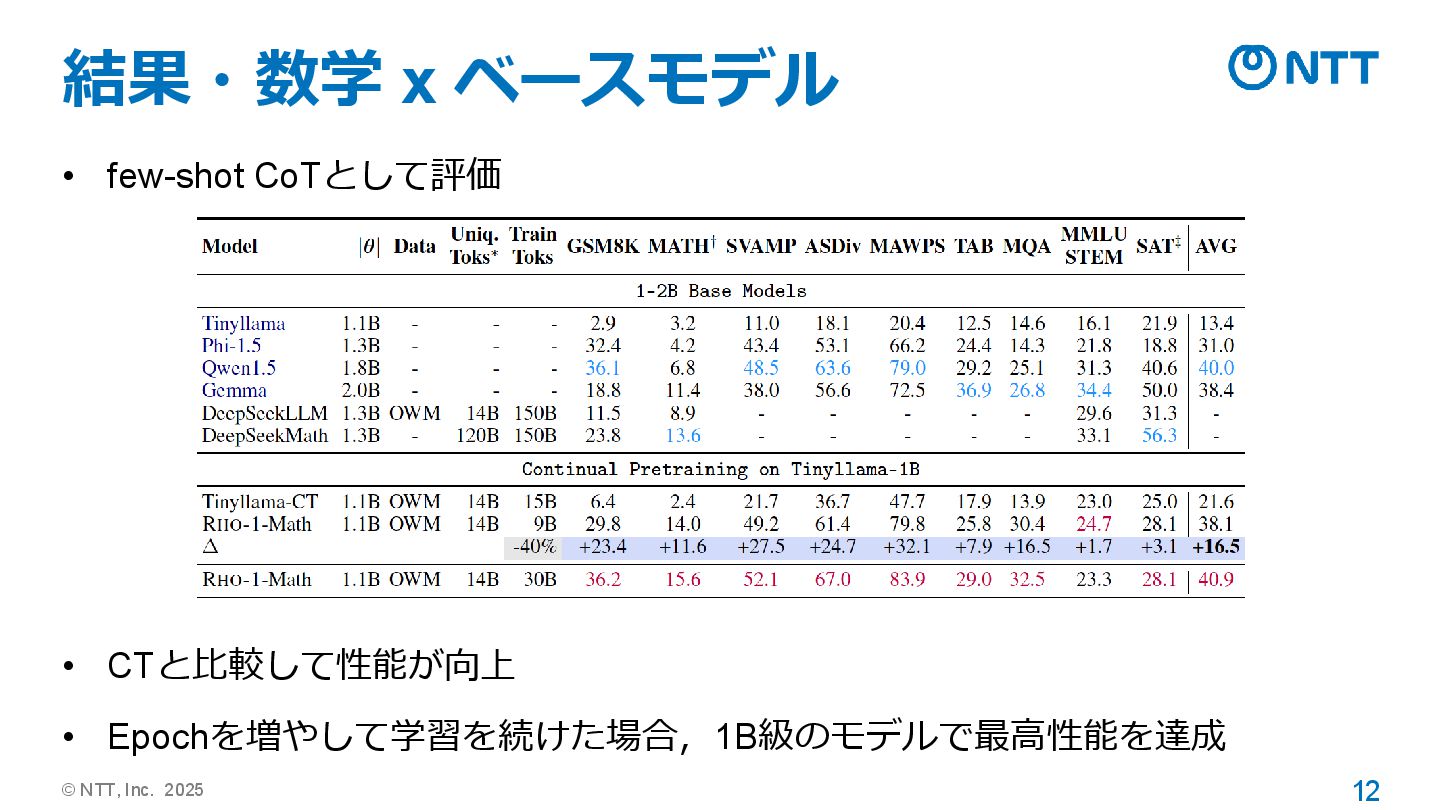
© NTT, Inc. 2025 12 結果・数学 x ベースモデル • few-shot
CoTとして評価 • CTと比較して性能が向上 • Epochを増やして学習を続けた場合,1B級のモデルで最高性能を達成
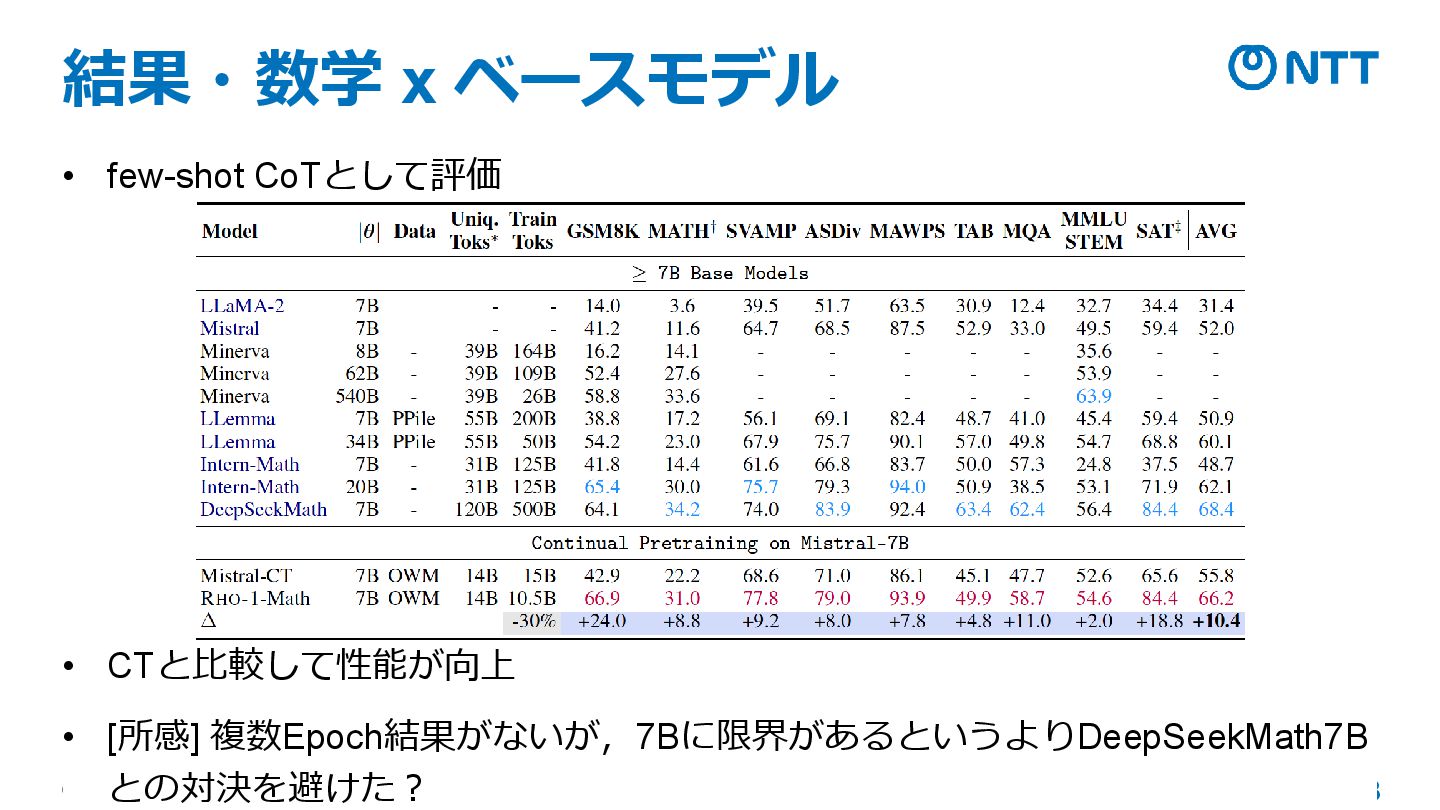
© NTT, Inc. 2025 13 結果・数学 x ベースモデル • few-shot
CoTとして評価 • CTと比較して性能が向上 • [所感] 複数Epoch結果がないが,7Bに限界があるというよりDeepSeekMath7B との対決を避けた?
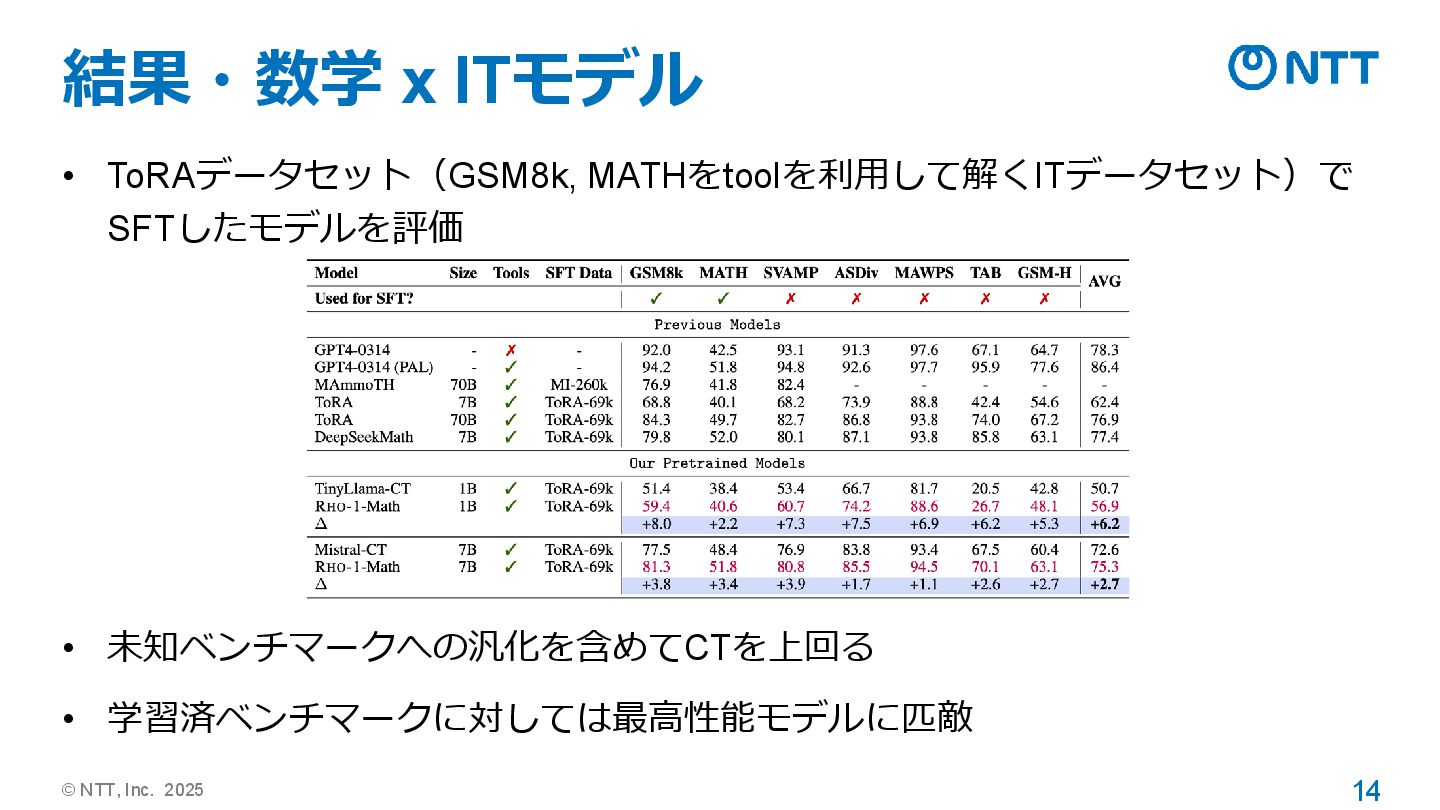
© NTT, Inc. 2025 14 結果・数学 x ITモデル • ToRAデータセット(GSM8k,
MATHをtoolを利用して解くITデータセット)で SFTしたモデルを評価 • 未知ベンチマークへの汎化を含めてCTを上回る • 学習済ベンチマークに対しては最高性能モデルに匹敵
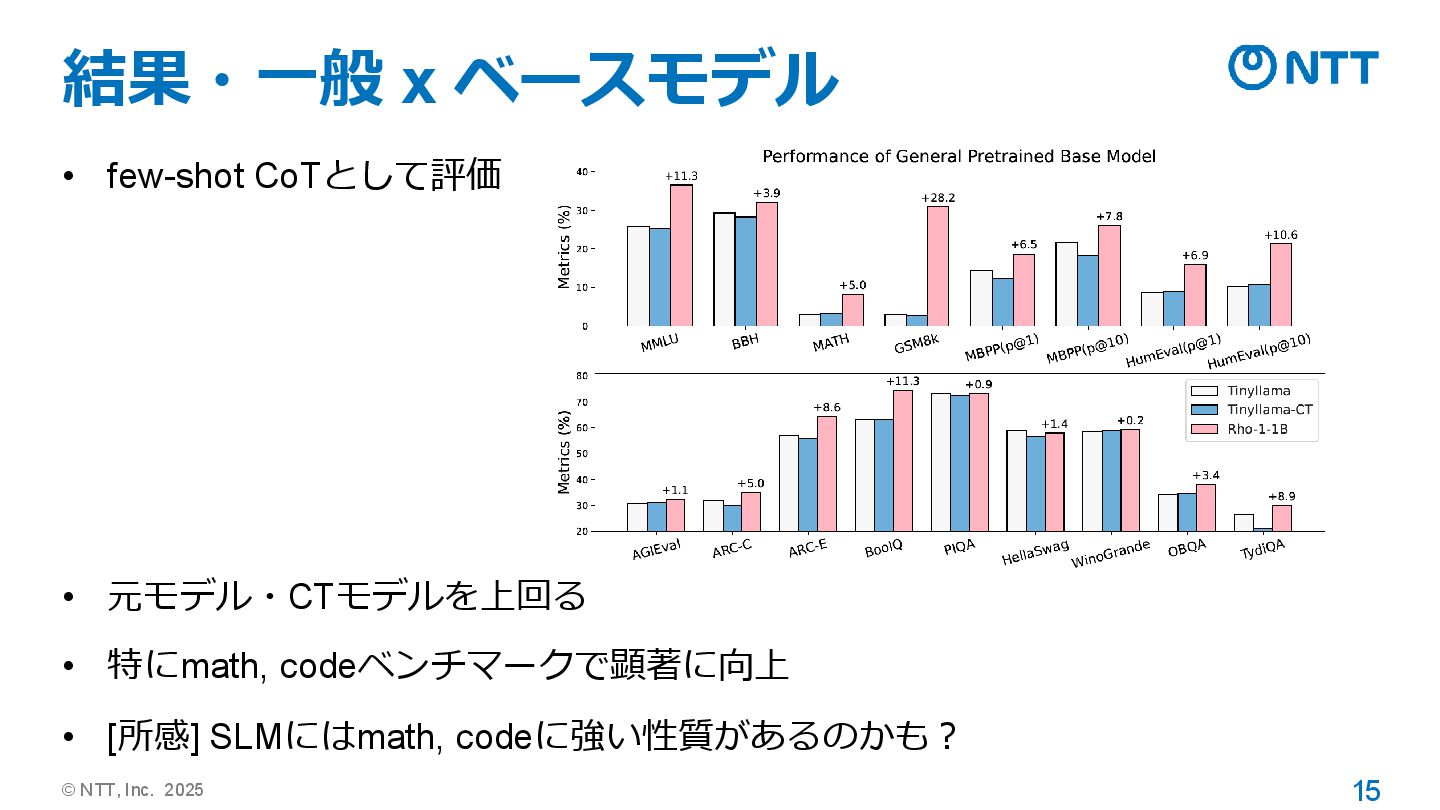
© NTT, Inc. 2025 15 結果・一般 x ベースモデル • few-shot
CoTとして評価 • 元モデル・CTモデルを上回る • 特にmath, codeベンチマークで顕著に向上 • [所感] SLMにはmath, codeに強い性質があるのかも?
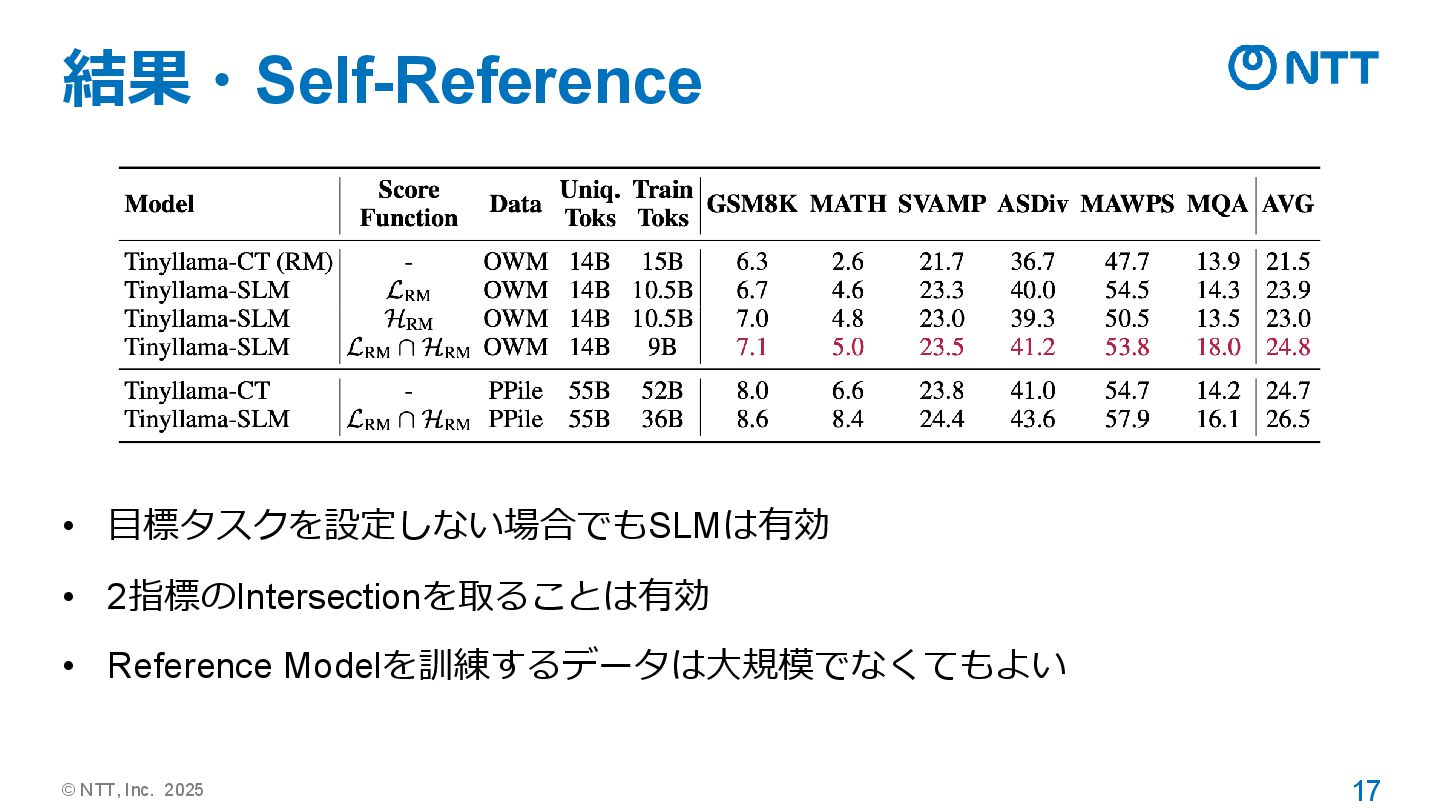
© NTT, Inc. 2025 16 実験設定・Self-Reference • 特定の目標タスクが存在しない現実的な設定の実験も行った • 𝐷𝑞
= 𝐷 = OpenWebMath • 𝐷𝑞 =OpenWebMath, 𝐷 =Proof-Pile2 • ノイズ除去としての役割に期待 • [所感] 一般ドメインでやらないとRQに答えられないのでは? • 学習対象トークンの決定方法を3パターン実験 • Reference ModelのCross-Entropy(デフォルト) • Reference ModelのEntropy(ランダムに近いものは学習しない) • 上記2つそれぞれで決定したトークンのintersection
© NTT, Inc. 2025 17 結果・Self-Reference • 目標タスクを設定しない場合でもSLMは有効 • 2指標のIntersectionを取ることは有効
• Reference Modelを訓練するデータは大規模でなくてもよい
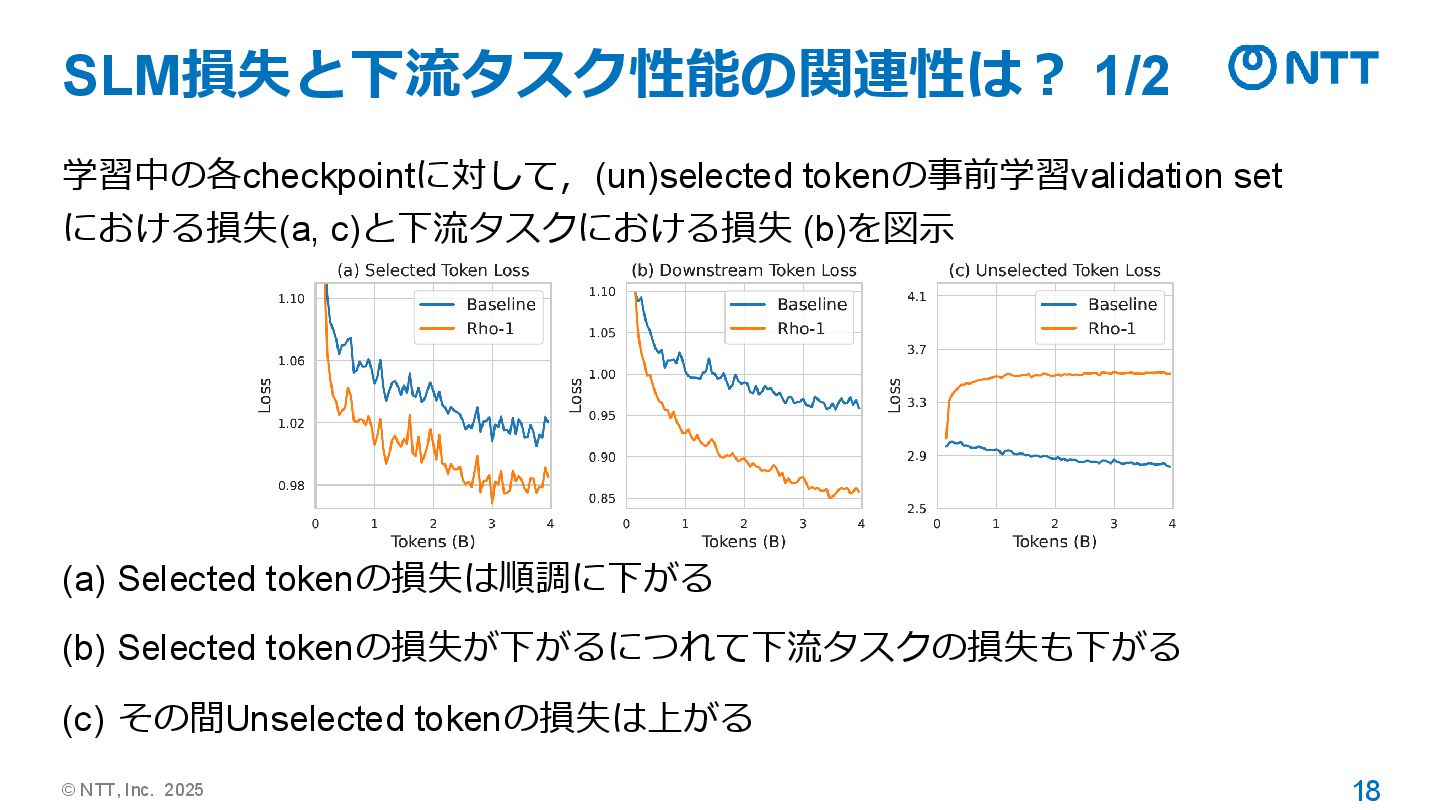
© NTT, Inc. 2025 18 SLM損失と下流タスク性能の関連性は? 1/2 学習中の各checkpointに対して,(un)selected tokenの事前学習validation set
における損失(a, c)と下流タスクにおける損失 (b)を図示 (a) Selected tokenの損失は順調に下がる (b) Selected tokenの損失が下がるにつれて下流タスクの損失も下がる (c) その間Unselected tokenの損失は上がる
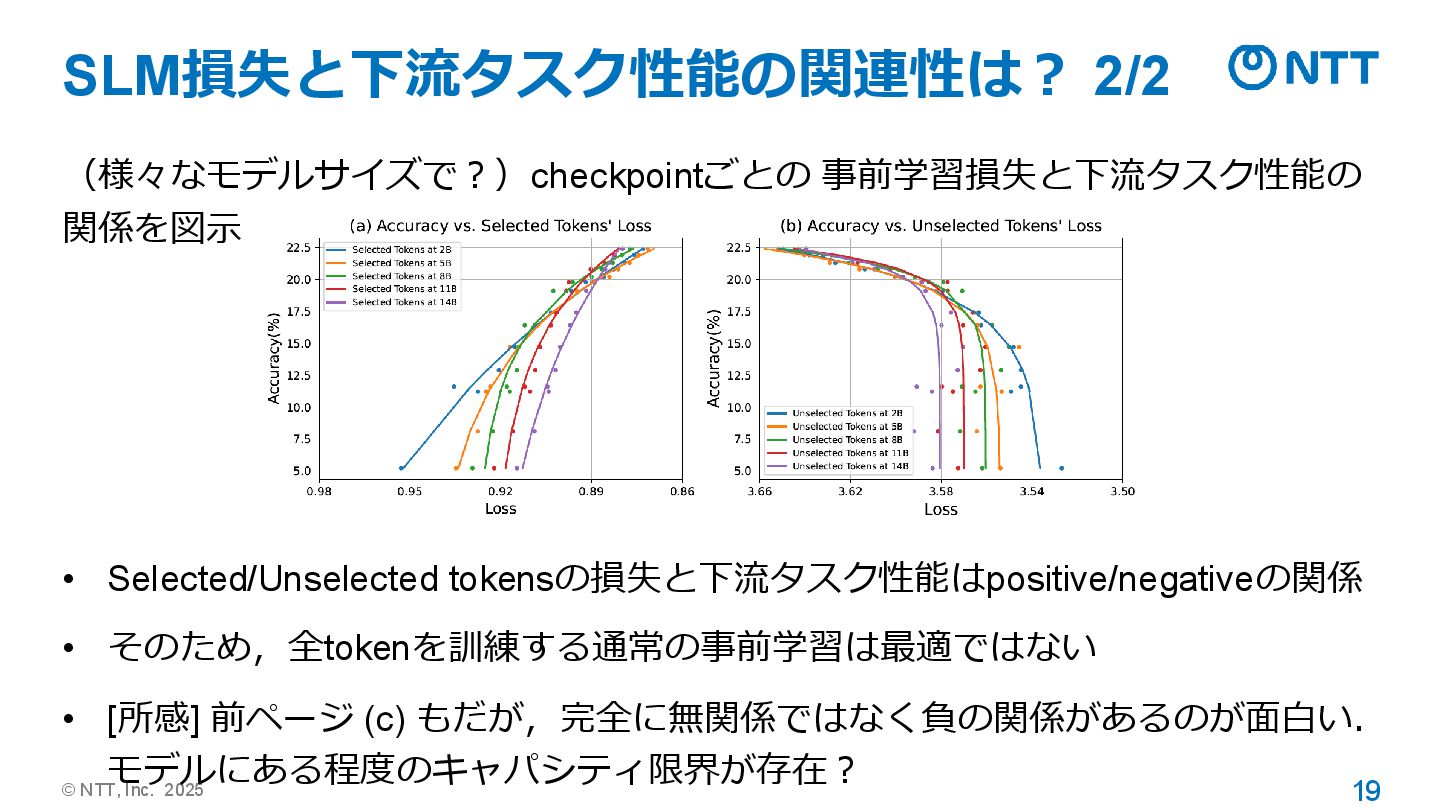
© NTT, Inc. 2025 19 SLM損失と下流タスク性能の関連性は? 2/2 (様々なモデルサイズで?)checkpointごとの 事前学習損失と下流タスク性能の 関係を図示
• Selected/Unselected tokensの損失と下流タスク性能はpositive/negativeの関係 • そのため,全tokenを訓練する通常の事前学習は最適ではない • [所感] 前ページ (c) もだが,完全に無関係ではなく負の関係があるのが面白い. モデルにある程度のキャパシティ限界が存在?
© NTT, Inc. 2025 20 どんなトークンが選ばれる? • mathドメインでのSLM中に選ばれたトークン.math関連のトークンが多い
© NTT, Inc. 2025 21 まとめ
© NTT, Inc. 2025 22 Limitation・所感 1/3 • Reference Model
(RM)を訓練するデータをどう決定するかが重要 • mathデータでRMを作ってmathデータで評価,ITデータでRMを作ってbase modelのまま評価, で向上するのは当然に思える › ITデータでRMを作成・SLMした後に,十分なITデータセットでFine-Tuningしてから 評価しても有効なのか? • 一般ドメインでRMを訓練てもmath, codeに関して性能向上が大きい.なぜ? • 目的ドメインが決定しているドメイン適応の文脈では有用そう • 一般的な事前学習の文脈でどうRMを訓練するとよいか,が重要なfuture work • RMとして巨大モデルを使うのでは不十分?
© NTT, Inc. 2025 23 Limitation・所感 2/3 • tokenを厳選することで高性能なモデルを実現できる,のRQは面白い. が,計算効率を向上させるわけではないことに注意
• Reference Modelの学習・推論が必要.Backward計算もほとんど減らない • Unselected tokenの損失が上がっていくのが面白い • なんらかの理由でselected tokenで下げるときにはunselected tokenは上がらざるをえない? • なんとかできないか?なんとかすることに意味はあるのか? • Scaling Lawとの関連 • トークンを厳選することで性能が上がるなら,Scaling Lawで知られるトークン数と性能の関係 の裏には真に考慮すべき要因がある?
© NTT, Inc. 2025 24 Limitation・所感 3/3 • SLMの使い方はトークン選択でいいのか? •
連続的reweighting, Reward Model, 複数Reference Model. 反復的SLM • SLMの適用先は事前学習だけか? • fine-tuning, multi-modal pre-training • 大規模な設定でも有効か? • モデルサイズ,コーパスサイズ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}