Share
WebDB夏のワークショップ2025、オーガナイズドセッション、2025/9/16 @浜松 https://amagata-daichi.notion.site/20ab718c179d80d9aa83d1962eb64283
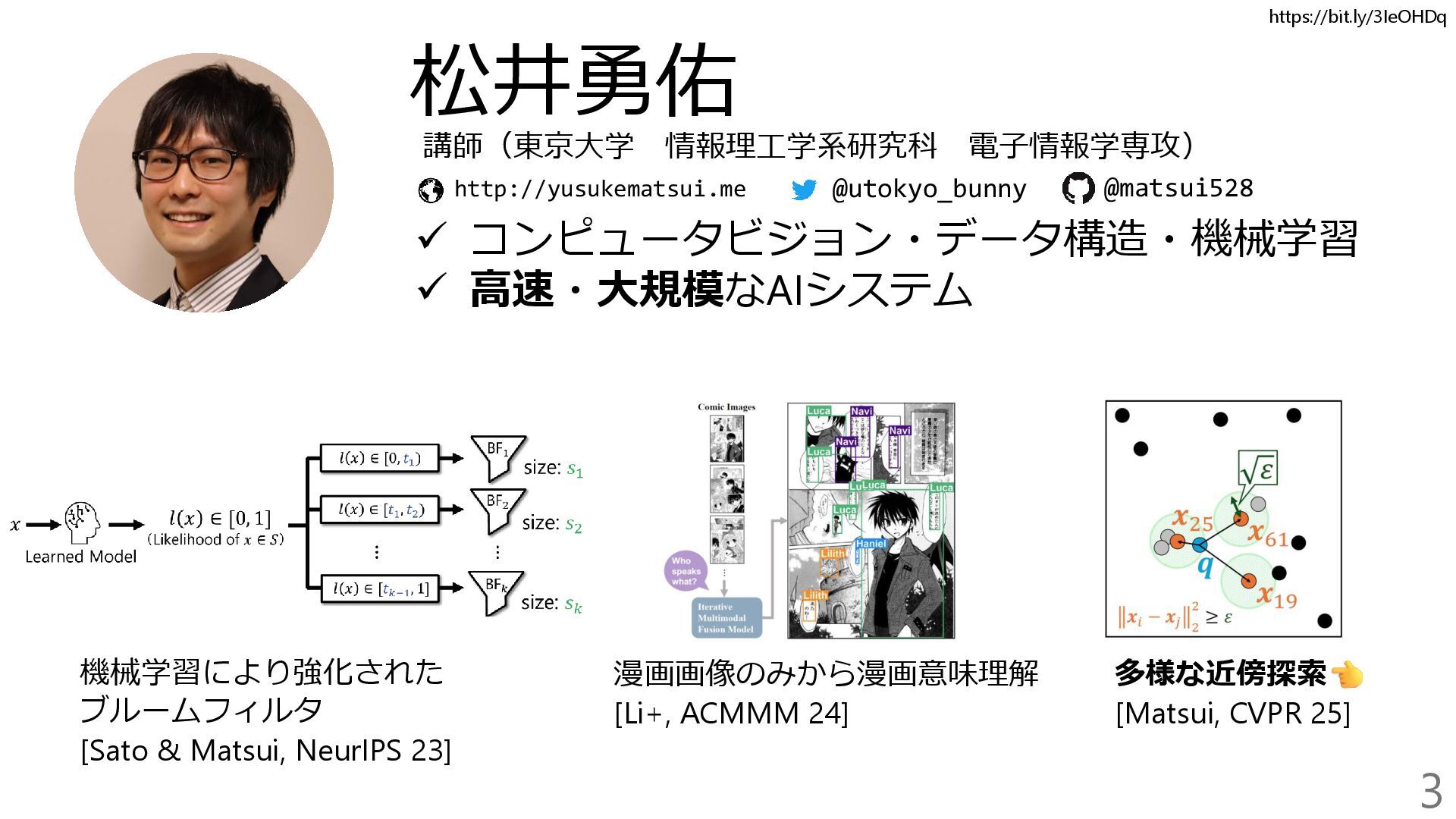
松井勇佑(東京大学)http://yusukematsui.me/index_jp.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
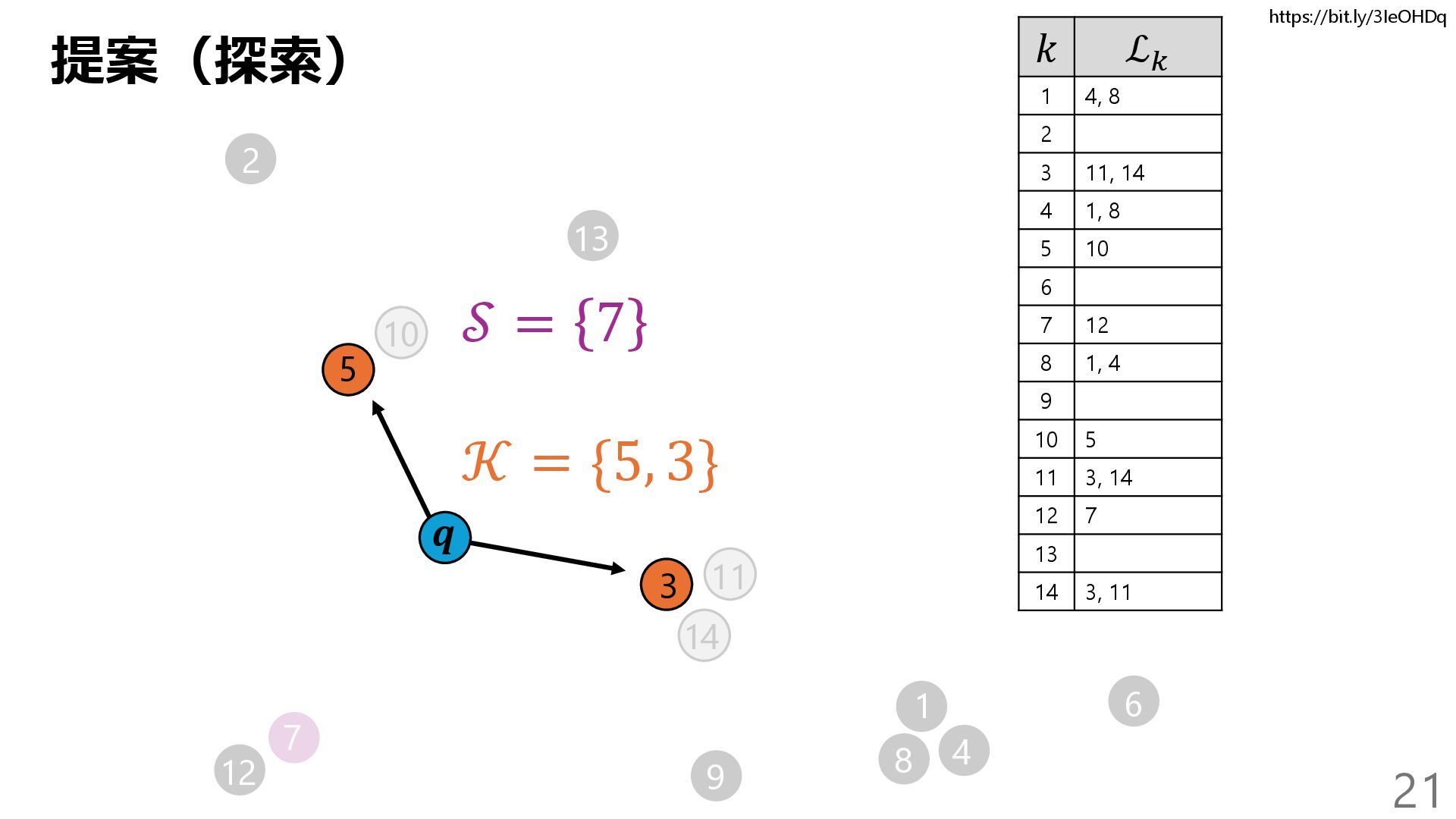{kind=link}
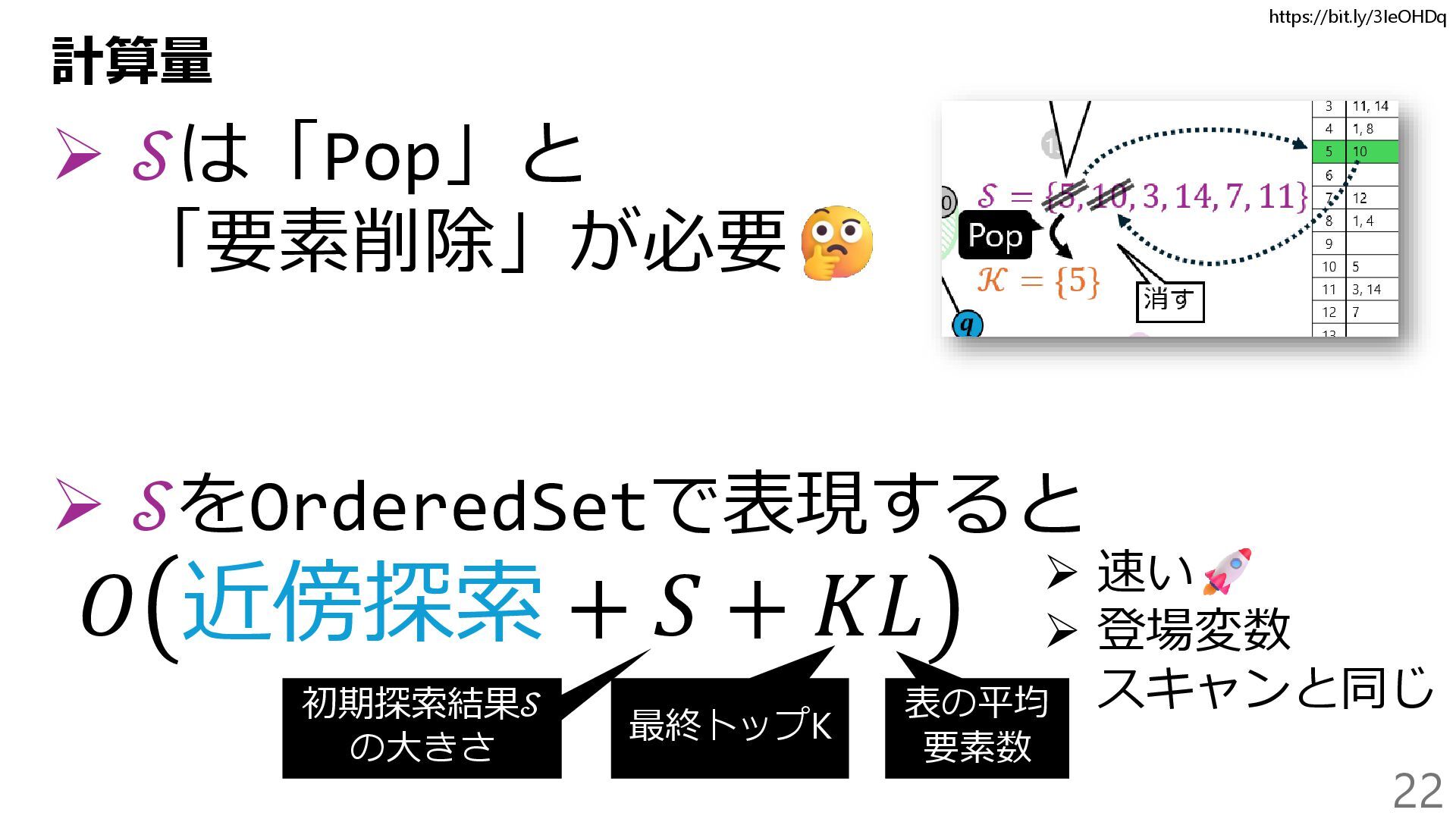{kind=link}
{kind=link}
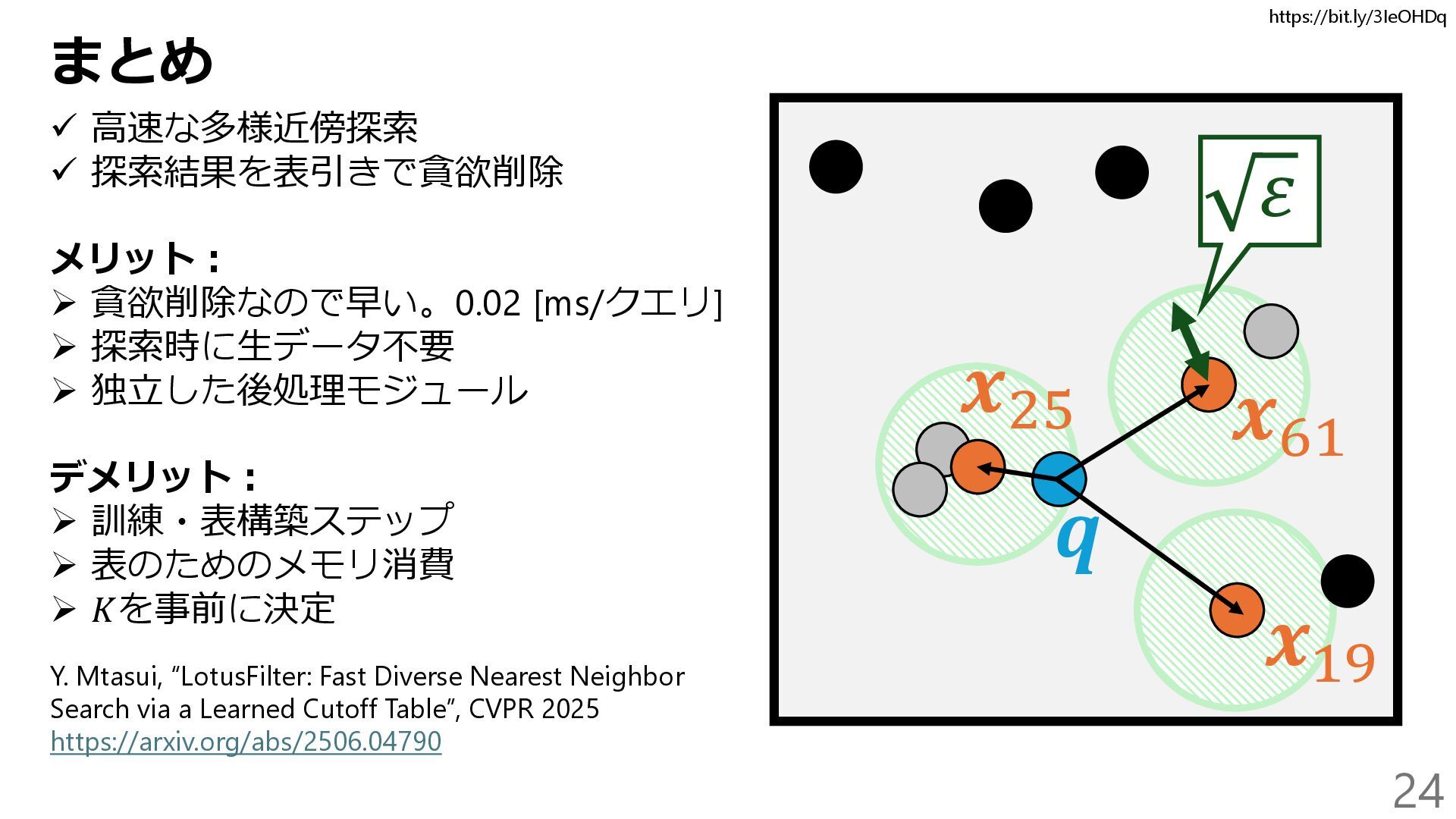{kind=link}
{kind=link}
{kind=link}
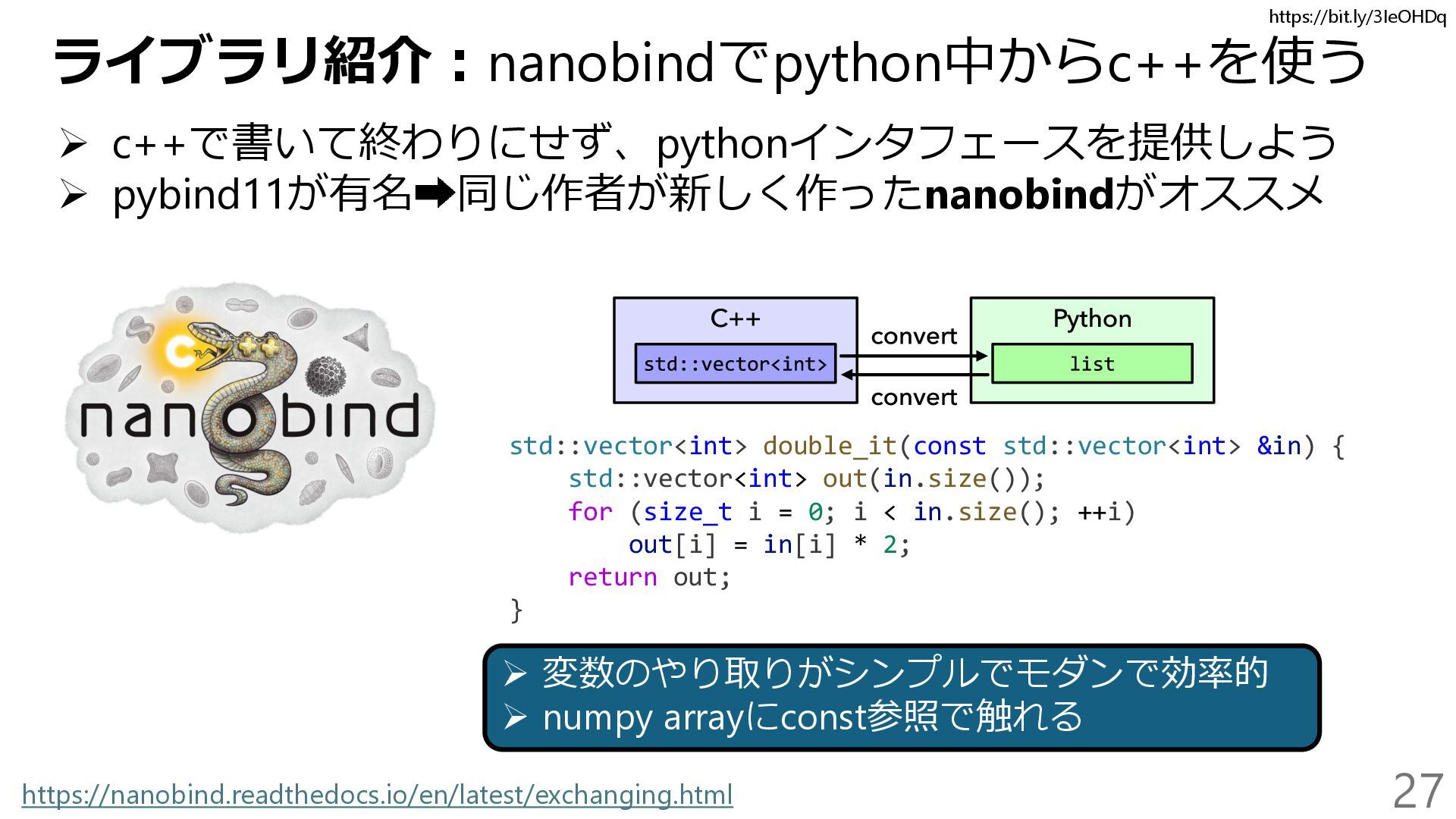{kind=link}
{kind=link}
{kind=link}
{kind=link}