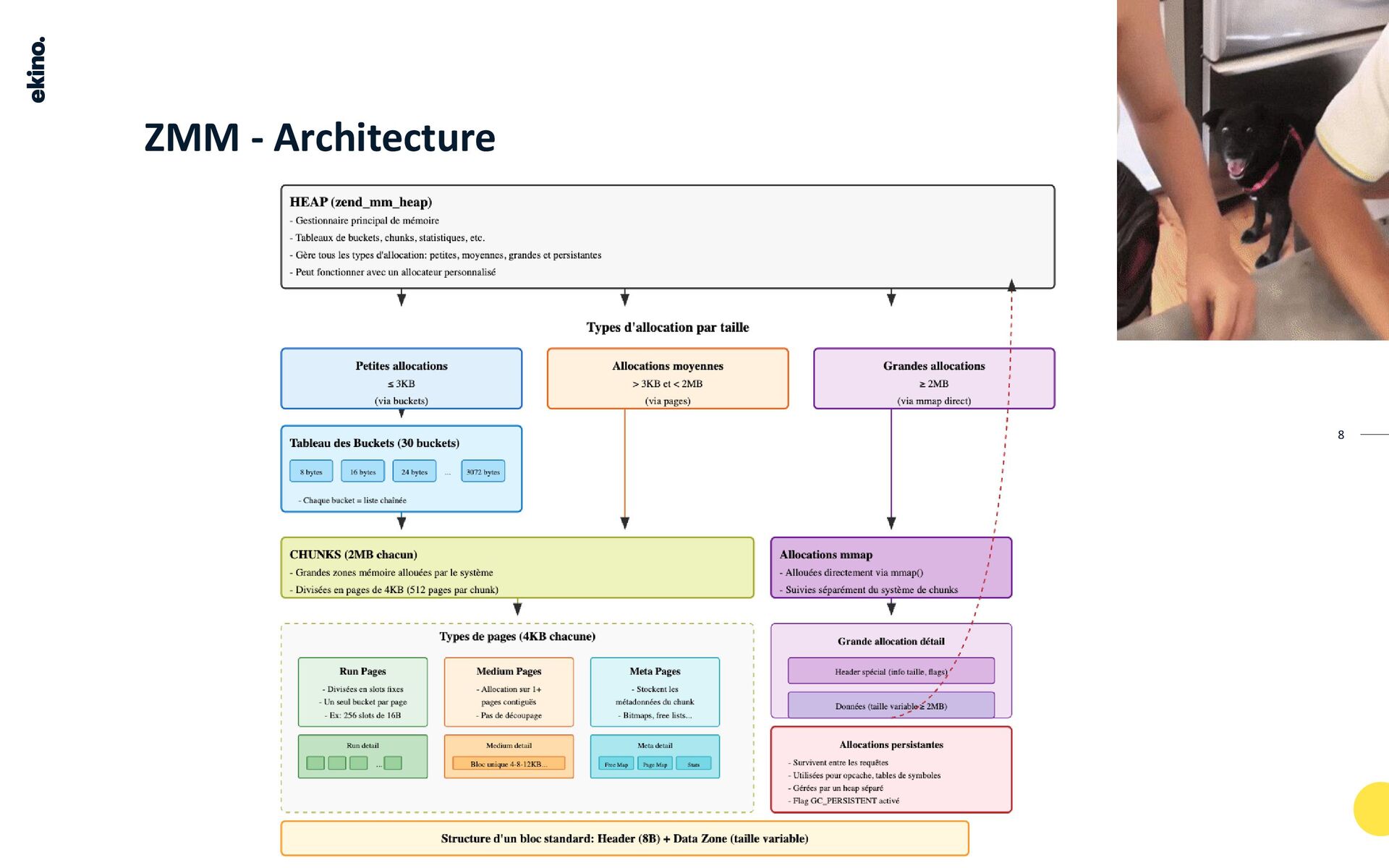
Ce TALK, explore en détail le Zend Memory Manager (ZMM) de PHP. Il explique son architecture, inspirée de JMALLOC et TCMalloc, et son fonctionnement basé sur des allocations par runs et buckets pour optimiser la gestion de la mémoire, notamment pour les petites allocations fréquentes.
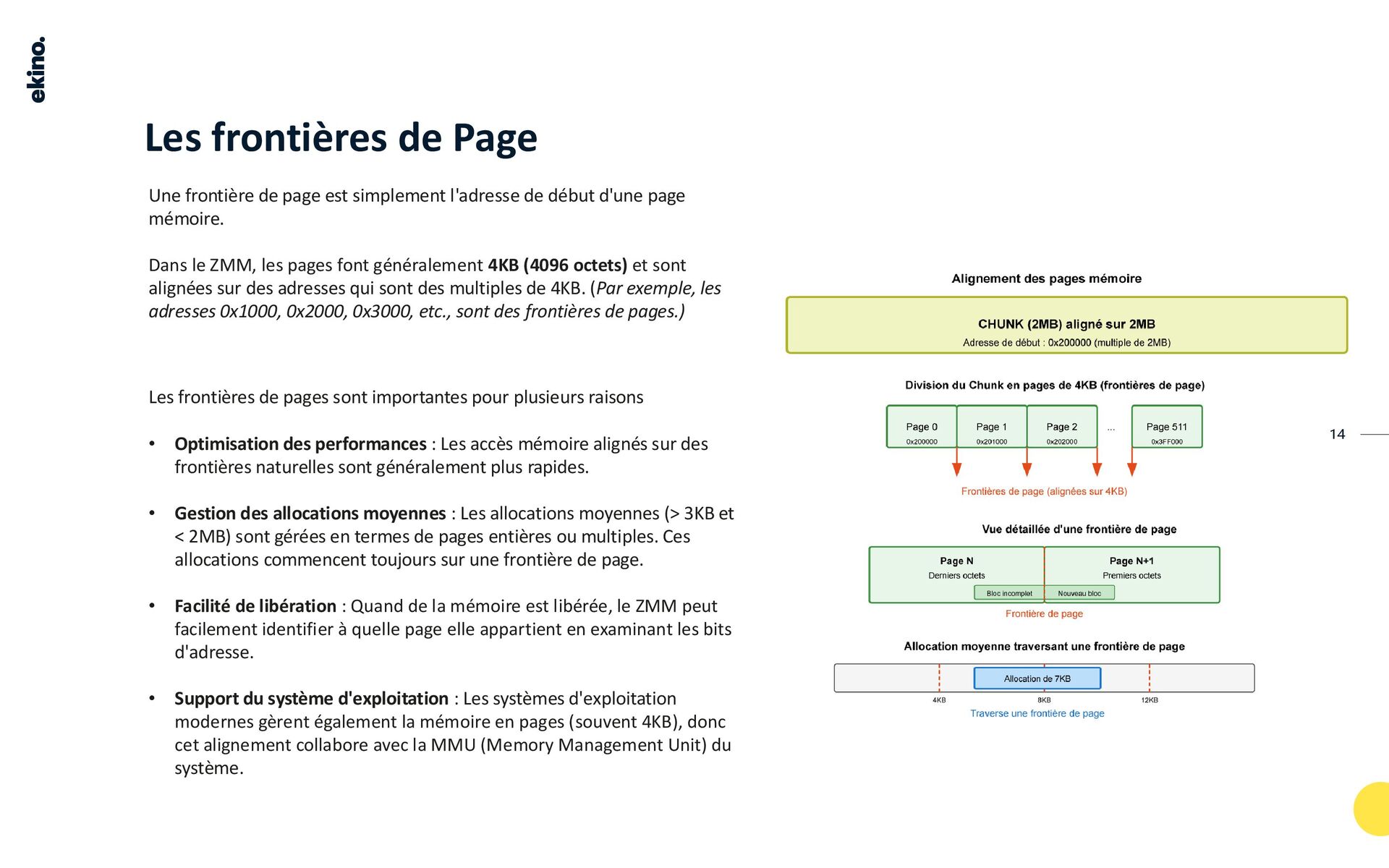
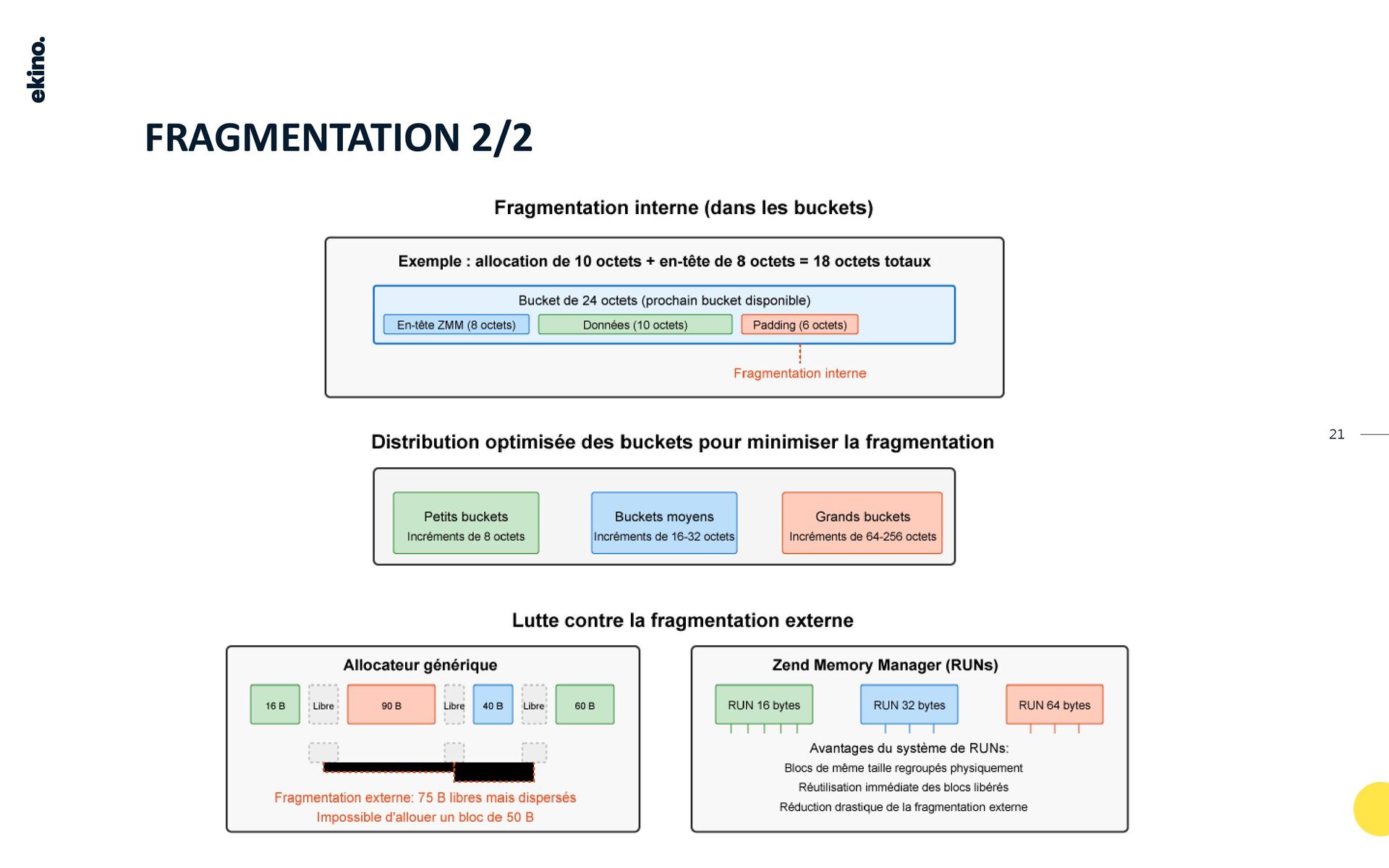
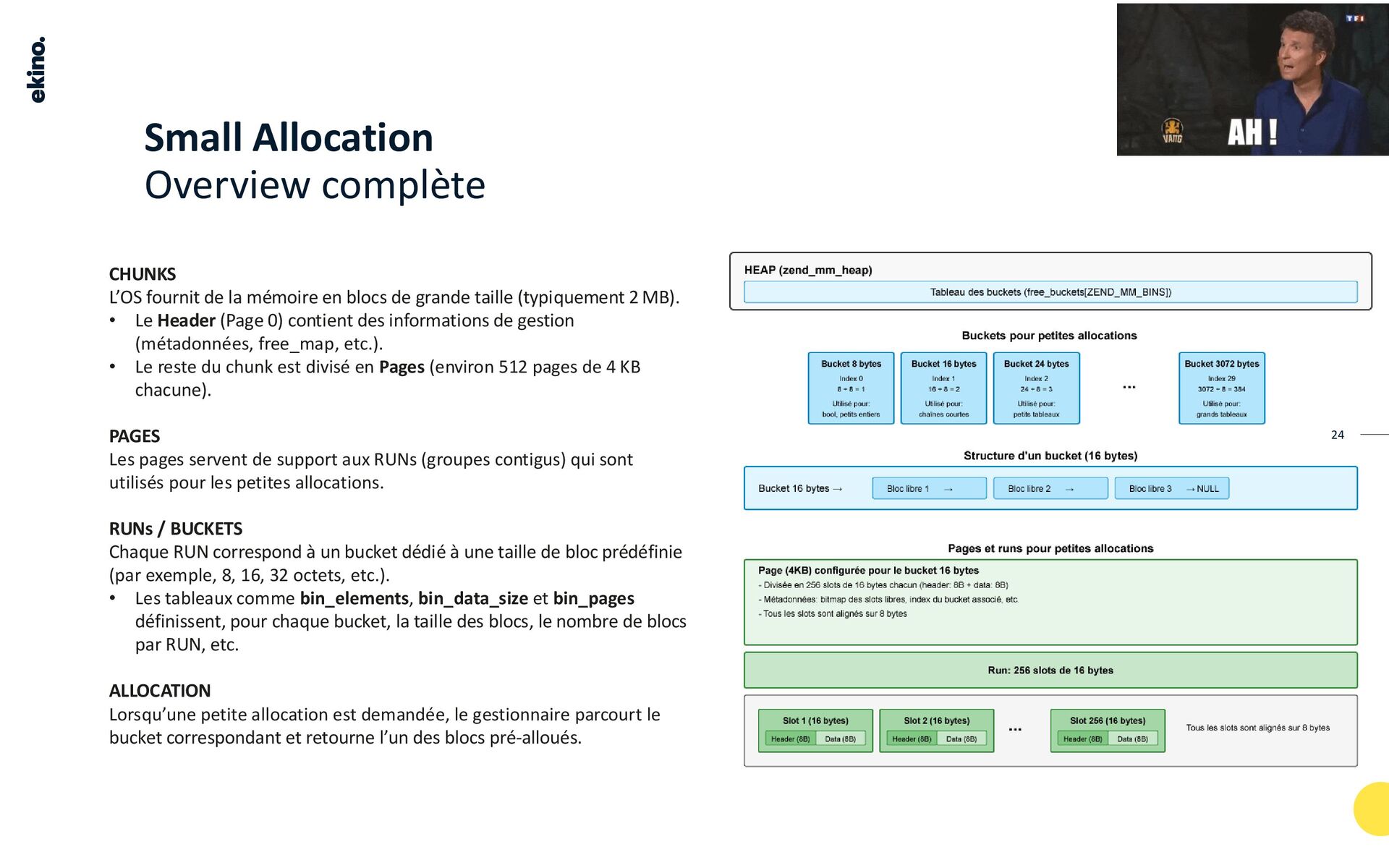
Ce TALK aborde des concepts fondamentaux comme les bits, les octets, la Heap, l'alignement, le padding et la fragmentation. Il décrit le processus d'allocation pour différentes tailles, le rôle des chunks, des pages et des slots, ainsi que les structures de données internes et les stratégies pour minimiser le gaspillage de mémoire.
L'objectif est d'offrir une compréhension approfondie du ZMM pour optimiser les performances des applications PHP et diagnostiquer les problèmes liés à la mémoire.
{kind=link}
{kind=link}
![3 [INTERNE] • Schémas Présentations](https://files.speakerdeck.com/presentations/d10e21c900454926862c2ffd0179504a/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![9 [INTERNE] • Schémas Présentations On inspire, on expire…](https://files.speakerdeck.com/presentations/d10e21c900454926862c2ffd0179504a/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![15 [INTERNE] • Schémas Présentations Petite pause détente](https://files.speakerdeck.com/presentations/d10e21c900454926862c2ffd0179504a/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![22 [INTERNE] • Schémas Présentations Go ride on memory !](https://files.speakerdeck.com/presentations/d10e21c900454926862c2ffd0179504a/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
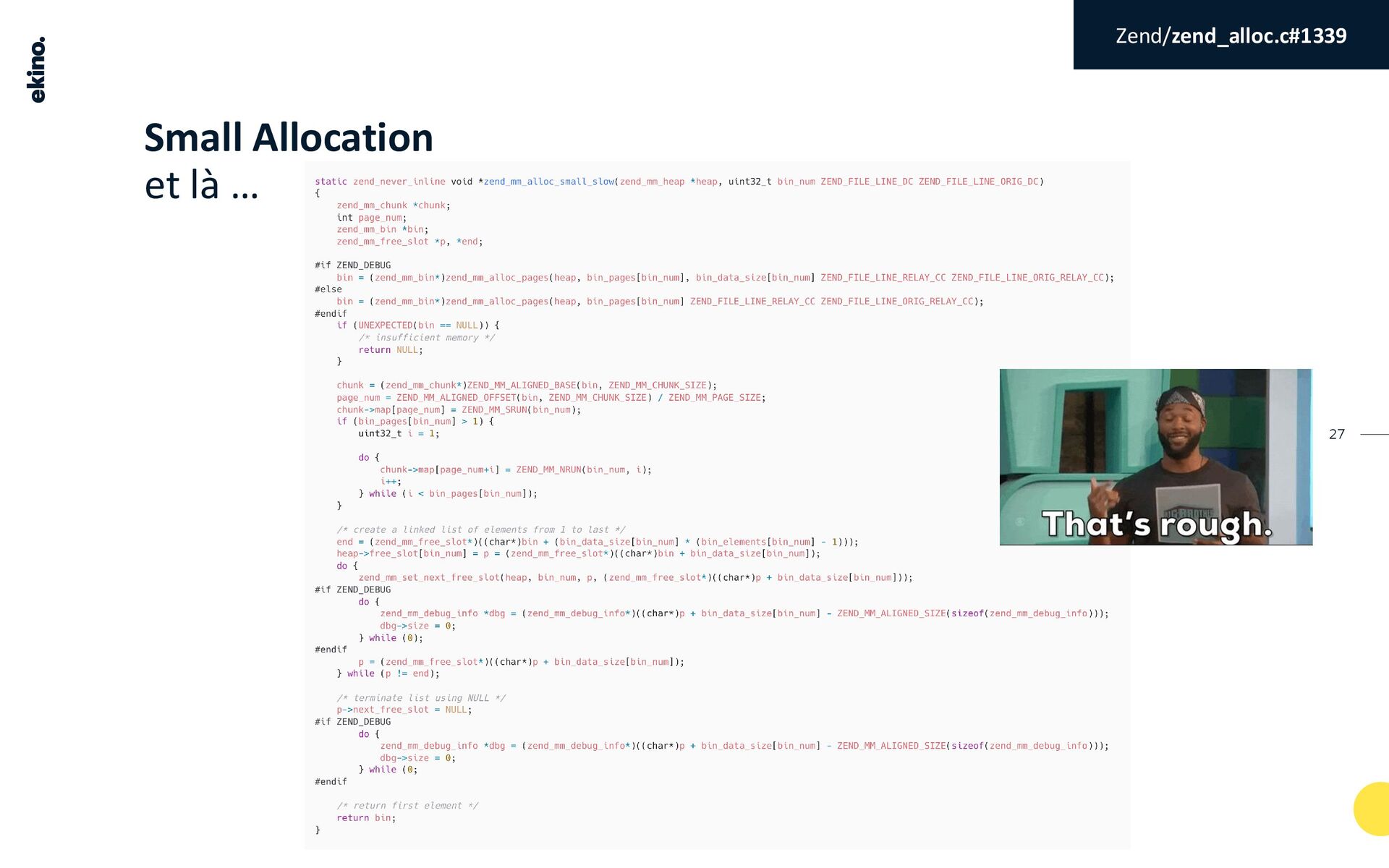{kind=link}
{kind=link}
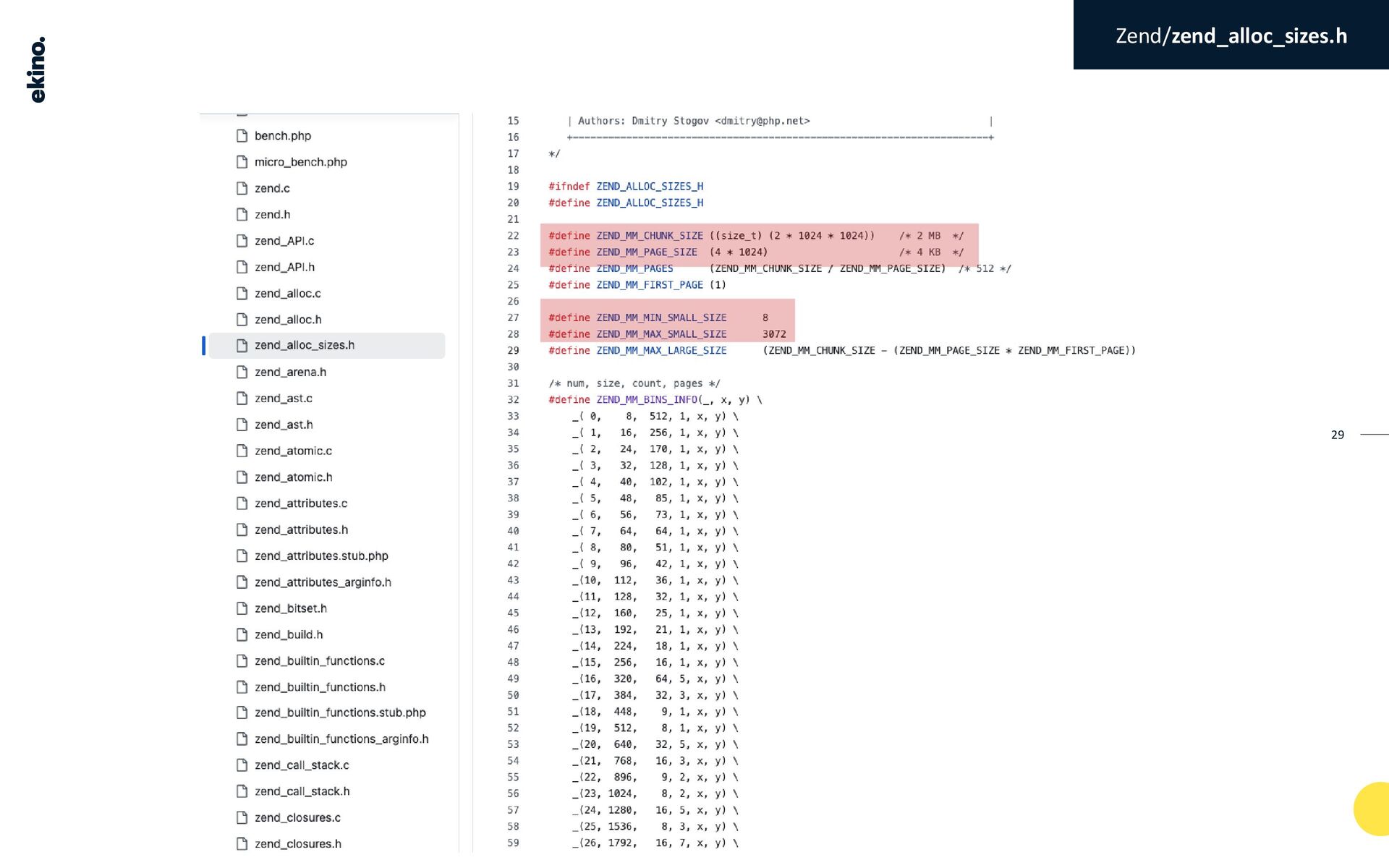{kind=link}
![30 [INTERNE] • Schémas Présentations Petite pause détente](https://files.speakerdeck.com/presentations/d10e21c900454926862c2ffd0179504a/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
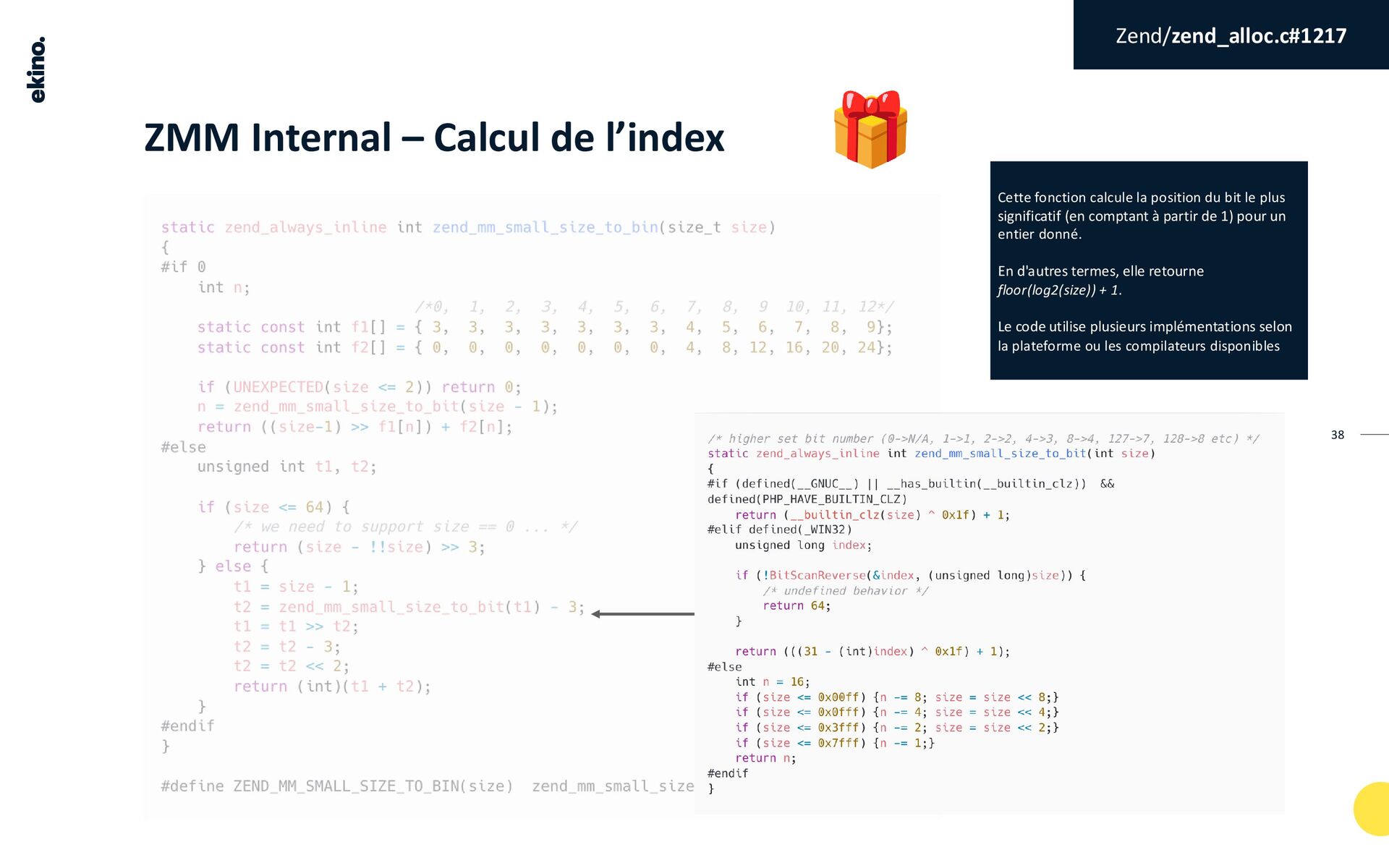{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![46 [INTERNE] • Schémas Présentations On inspire, on expire…](https://files.speakerdeck.com/presentations/d10e21c900454926862c2ffd0179504a/slide_45.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}