Organizacion del Data Science Meetup • Mucho interes en Machine Learning y Ciencia de Datos • Trabajando en Extraccion de Datos desde el 2012 • Vivo en Arequipa • matiskay en Twitter, Gmail y Github.
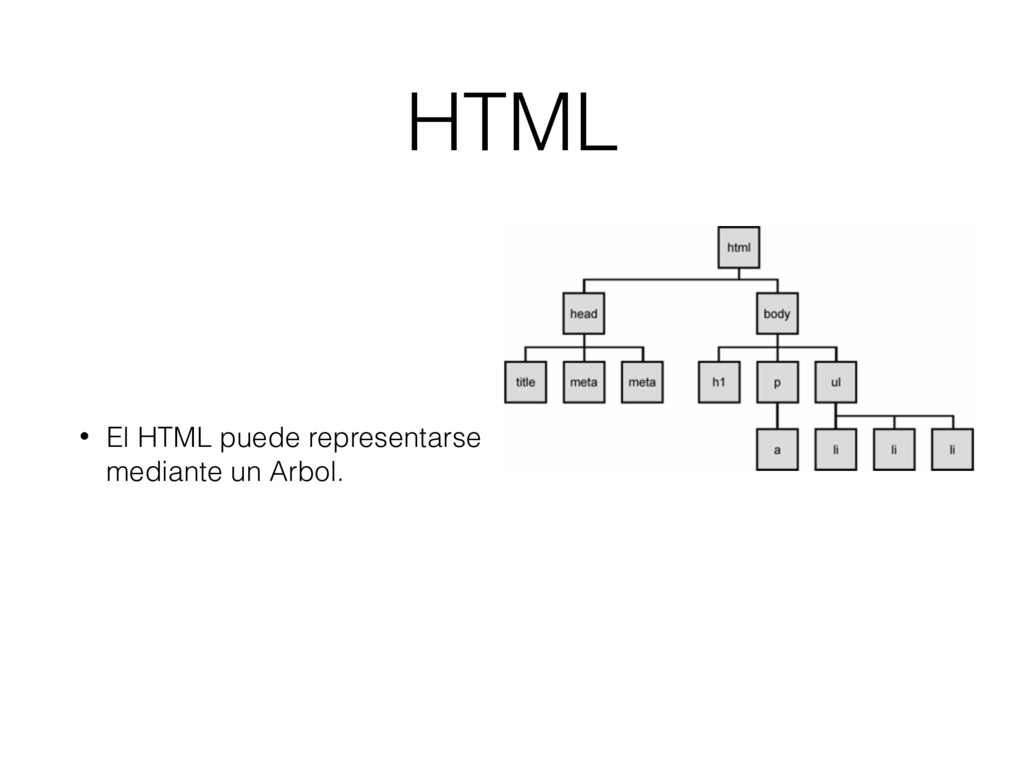
pagina web? • Transformar arboles HTML en HTML tokens es decir la informacion de la posicion en el HTML es preservada. • Agrupar grupos en textos. • Representar el HTML como una secuencia de tags. • Anotar informacion usando https://github.com/ scrapinghub/webstruct
no encontrada / Contenido no disponible). • https://github.com/TeamHG-Memex/soft404 • Entrenado en 120k paginas de 25k dominios, con una razon 1/3. • Usando 10-fold-cross validation, ROC AUC es 0.995 +/- 0.002 • SGDClassifier + Logistic Regression
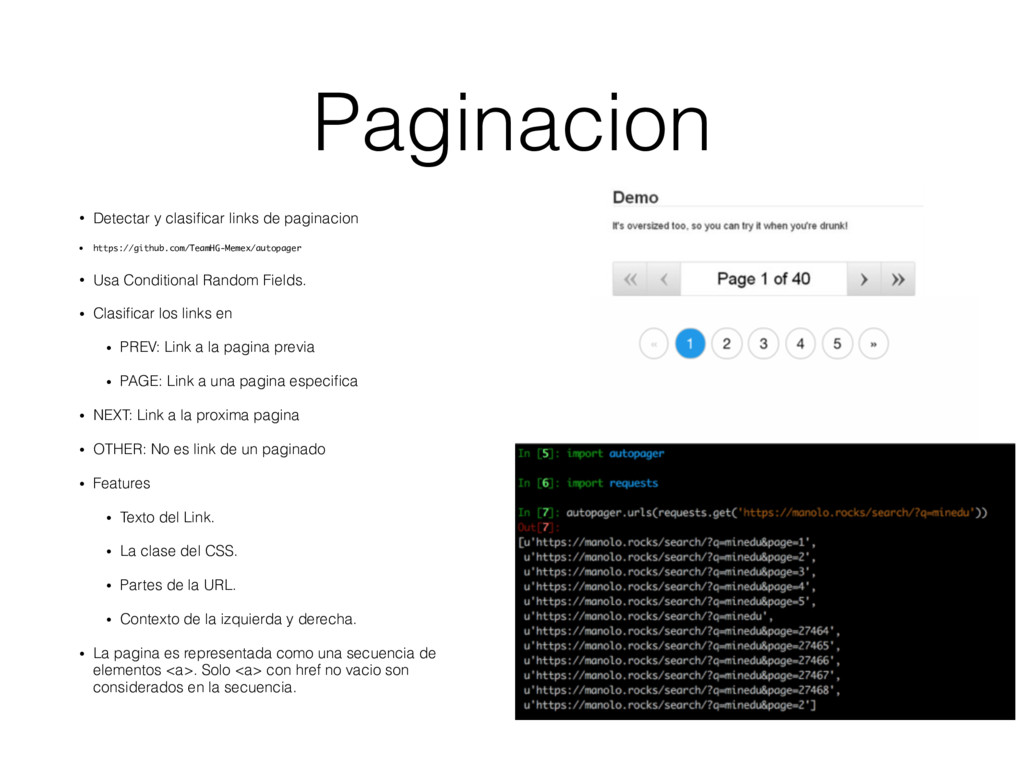
• Usa Conditional Random Fields. • Clasificar los links en • PREV: Link a la pagina previa • PAGE: Link a una pagina especifica • NEXT: Link a la proxima pagina • OTHER: No es link de un paginado • Features • Texto del Link. • La clase del CSS. • Partes de la URL. • Contexto de la izquierda y derecha. • La pagina es representada como una secuencia de elementos <a>. Solo <a> con href no vacio son considerados en la secuencia.
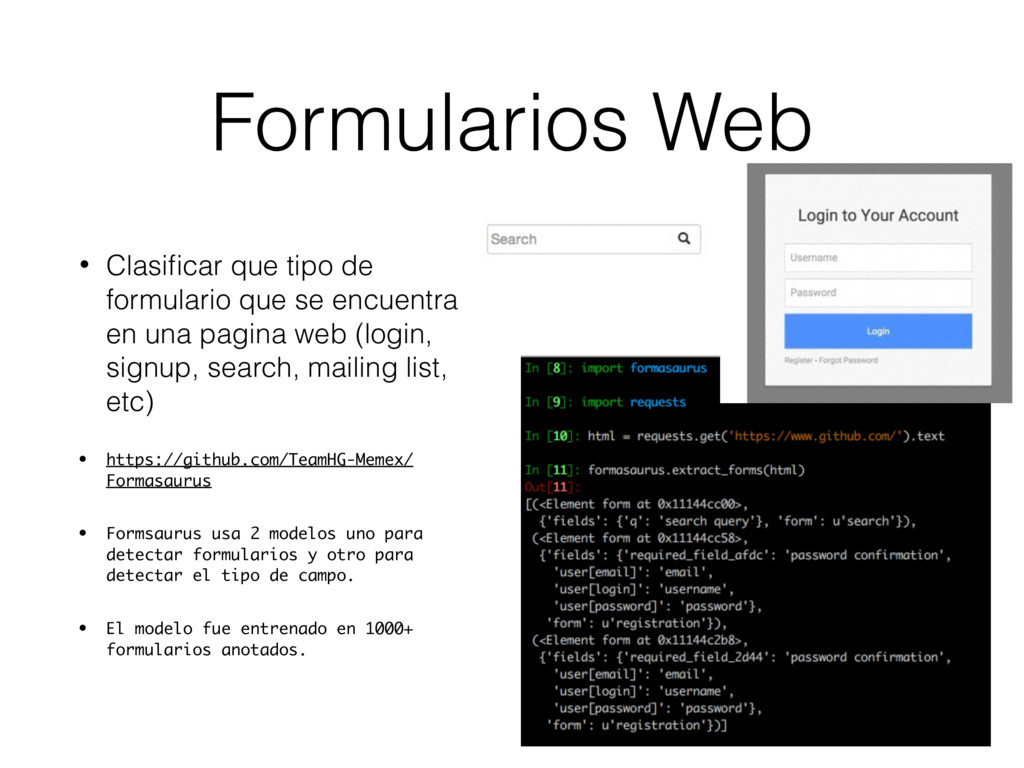
encuentra en una pagina web (login, signup, search, mailing list, etc) • https://github.com/TeamHG-Memex/ Formasaurus • Formsaurus usa 2 modelos uno para detectar formularios y otro para detectar el tipo de campo. • El modelo fue entrenado en 1000+ formularios anotados.
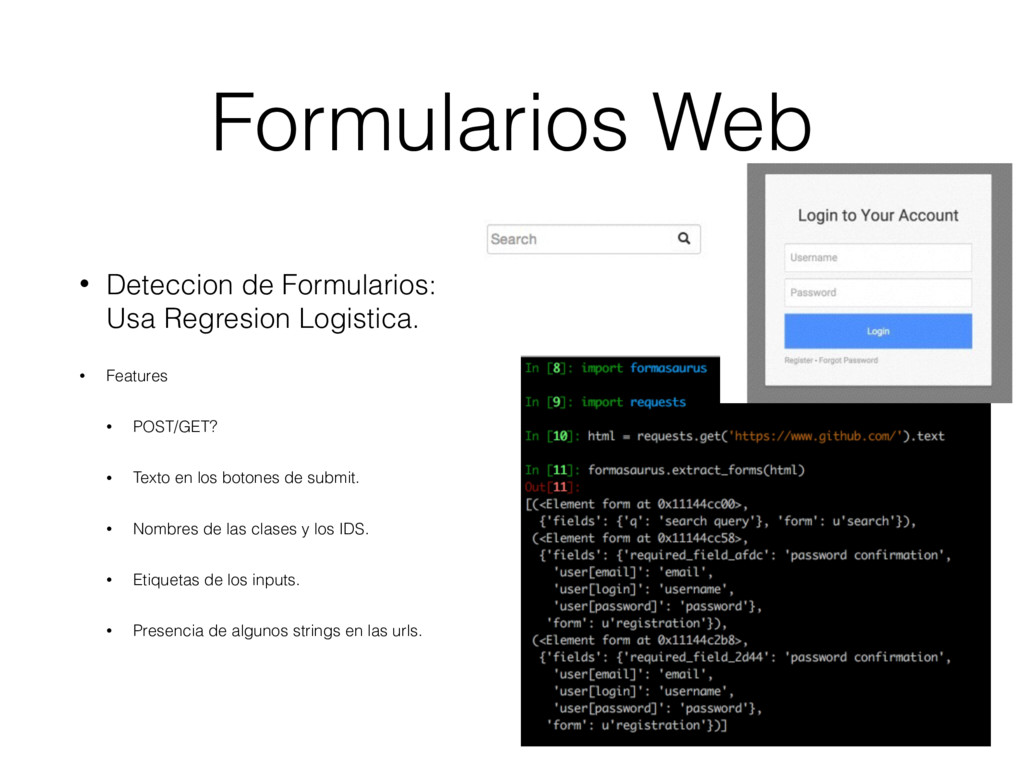
Features • POST/GET? • Texto en los botones de submit. • Nombres de las clases y los IDS. • Etiquetas de los inputs. • Presencia de algunos strings en las urls.
Conditional Random Field. Todos los campos en el formulario es una secuencia donde el orden importa. • Features • El tipo de formulario predecido por el clasificador de formularios. • El tag del campo. • El valor del campo • El texto anterior y posterior del campo • El css y el ID del campo • El texto de la etiqueta
web y luego calcula la similaridad de Jaccard para ver que tan similares son las paginas web en terminos de estilos. • El numero de classes repetidas no afecta la metrica • Documentos que tiene el mismo conjunto de clases poseen una mayor metrica. • La similaridad de estilo puede causar falsos positivos.
• Automatic Item List Extraction: https://github.com/ scrapinghub/aile • Extract structured data from HTML page: https:// github.com/scrapinghub/pydepta Otras Bibliotecas Interesantes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}