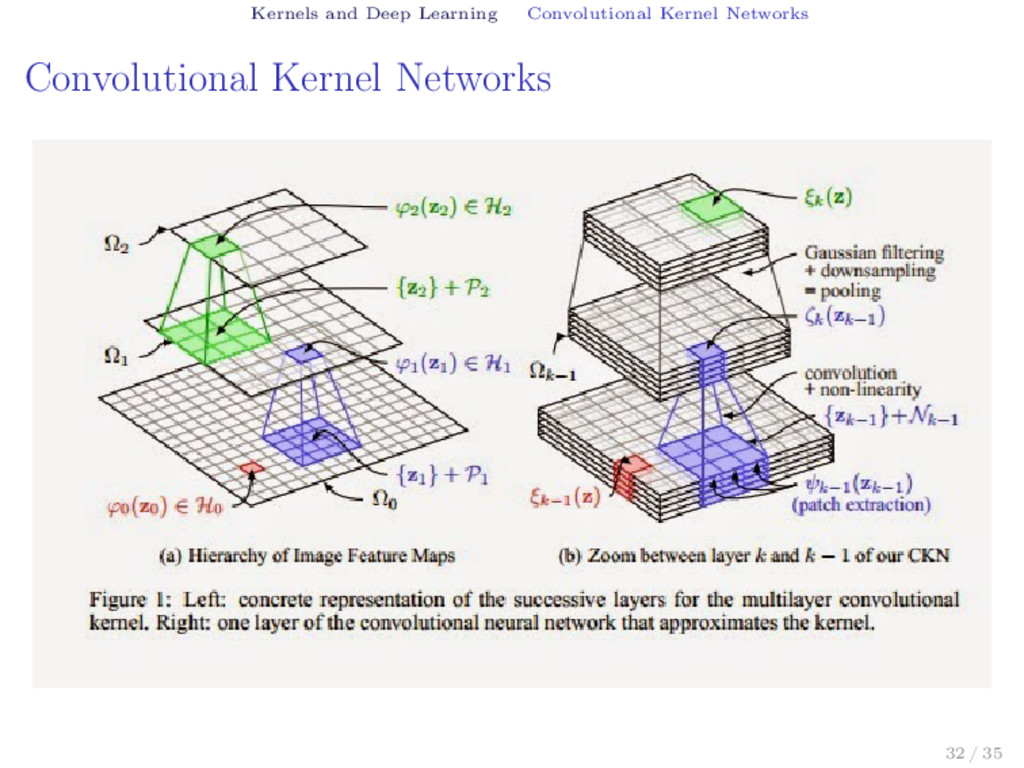
Neural Networks Software How to start Kernel Methods SVM The Kernel Trick History of Kernel Methods Software How to start Kernels and Deep Learning Convolutional Kernel Networks Deep Fried Convnets 2 / 35
Deep Learning Course by Nando de Freitas — https://www.youtube.com/watch?v=PlhFWT7vAEw&list= PLjK8ddCbDMphIMSXn-w1IjyYpHU3DaUYw. ▶ Alex Smola Lecture on Deep Networks — https://www.youtube.com/watch?v=xZzZb7wZ6eE. ▶ Convolutional Neural Networks for Visual Recognition — http://vision.stanford.edu/teaching/cs231n/. ▶ Deep Learning, Spring 2015 — http://cilvr.cs.nyu.edu/doku.php?id=courses: deeplearning2015:start. 8 / 35
Deep Learning for Natural Language Processing — http://cs224d.stanford.edu/. ▶ Applied Deep Learning for Computer Vision with Torch – http://torch.ch/docs/cvpr15.html. ▶ DEEP LEARNING, An MIT Press book in preparation — http://www.iro.umontreal.ca/~bengioy/dlbook/. ▶ Reading List — http://deeplearning.net/reading-list/. 9 / 35
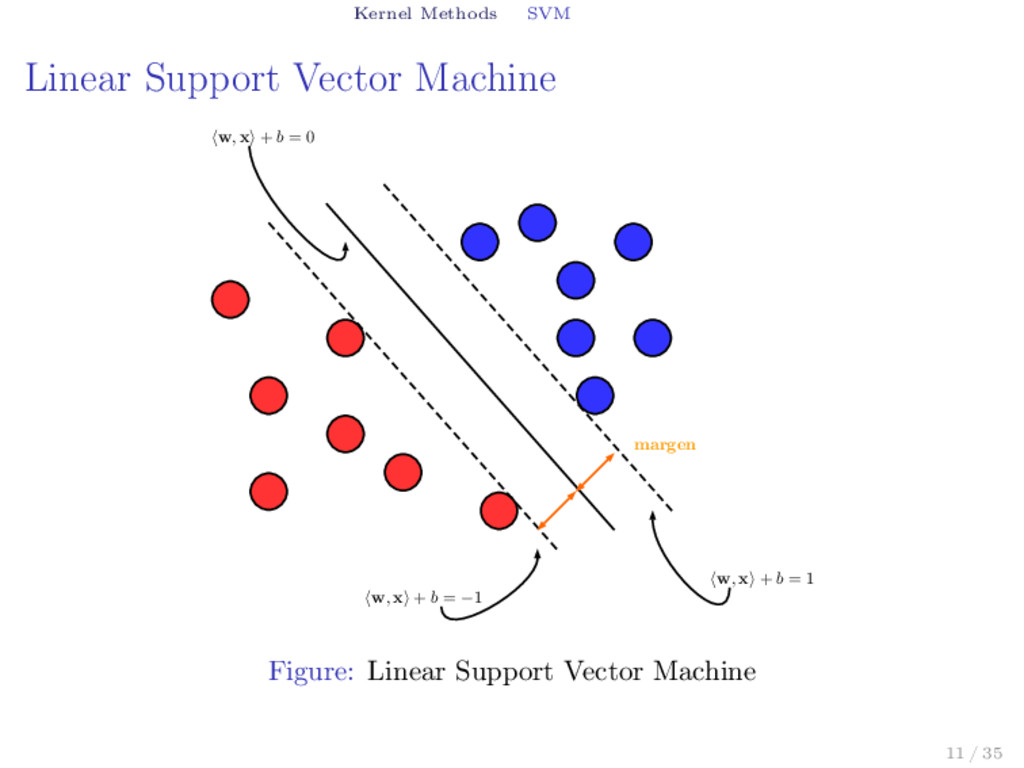
Primal Problem Given a linear separable training set D = {(x1, y1), (x2, y2), ..., (xl, yl)} ⊂ Rn × {+1, −1}, we can calculate the max margin decision surface ⟨w∗, x⟩ = b∗ solving the convex program (P) min w,b ϕ(w, b) = 1 2 ⟨w, w⟩ subject to ⟨w, yixi⟩ ≥ 1 + yib, where (xi, yi) ∈ D ⊂ Rn × {−1, +1}. (1) 1. The objective function doesn’t depends on b. 2. The displacement b appears in the restrictions. 3. The number of restrictions is equal to the number of training points. 12 / 35
Dual Problem (DP) max α h(α) = max α ( l ∑ i=1 αi − 1 2 l ∑ i=1 l ∑ j=1 αiαjyiyj⟨xi, xj⟩ ) sujeto a l ∑ i=1 αiyi = 0, αi ≥ 0 for i = 1, . . . , l. The calculus of b es in terms of w∗, as following: b+ = min {⟨w∗, x⟩ | (x, y) ∈ D where y = +1)} b− = max {⟨w∗, x⟩ | (x, y) ∈ D where y = −1)} Then b∗ = b++b− 2 The training vectors associated to αi > 0 are named support vectors. 13 / 35
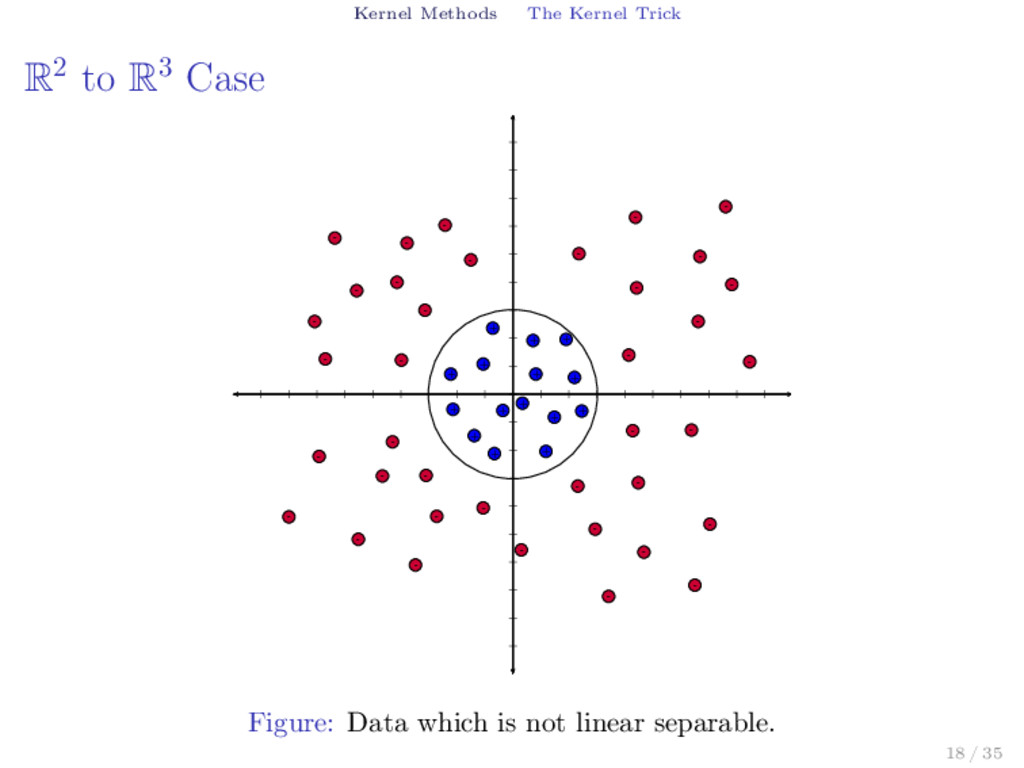
split data that is not linear separable? ▶ How we can utilize algorithms that works for linear separable data that only depends on the inner product? 16 / 35
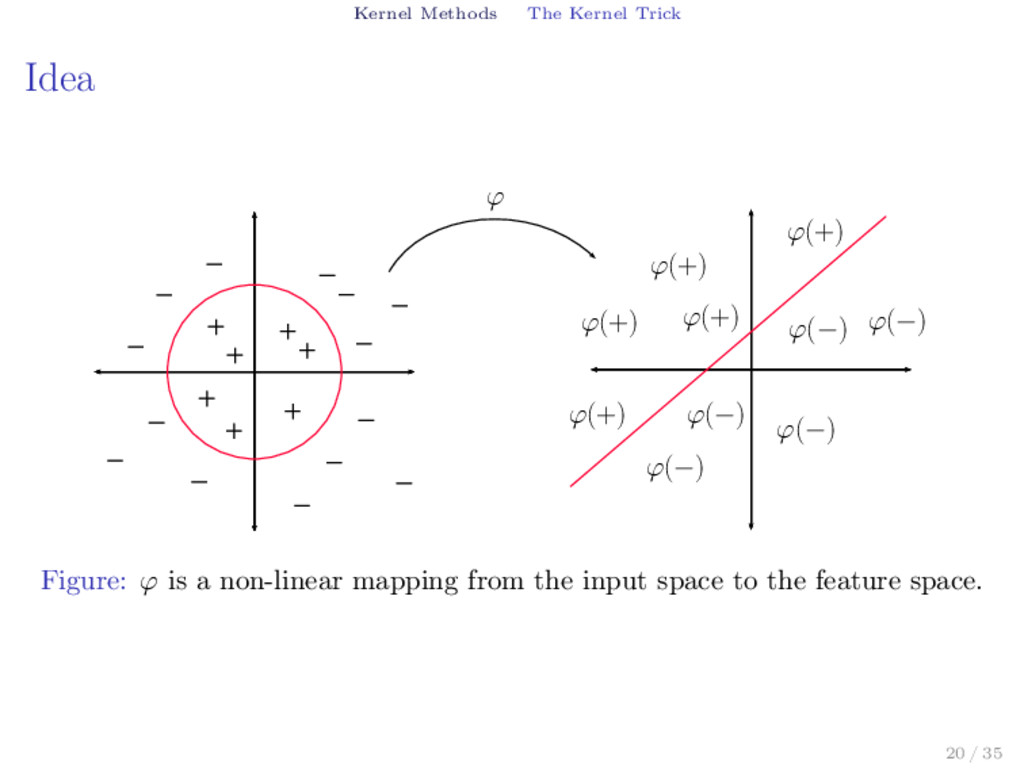
to separate two classes? 0 R R2 ϕ(x) = (x, x 2) ϕ Figure: Separating the two classes of points by transforming the points into a higher dimensional space where the data is separable. 17 / 35
Now we can use a non-linear function φ to map the information from the initial space to a higher dimensional space. Non Linear Support Vector Machine ˆ f(x) = sign ( l ∑ i=1 α∗ i yi⟨φ(xi), φ(x)⟩ − b∗ ) 21 / 35
a non-empty set. A function k : X × X → K is called kernel in X if and only if there is Hilbert Space H and a mapping Φ : X → H such that for all s, t it holds k(t, s) := ⟨Φ(t), Φ(s)⟩H (2) The function Φ is called feature mapping and H feature space of k. 22 / 35
R and the function k defined by k(s, t) = st = ⟨ [ s √ 2 s √ 2 ] , [ t √ 2 t √ 2 ]⟩ where the feature mappings are Φ(s) = s and ˜ Φ(s) = [ s √ 2 s √ 2 ] and the features spaces are H = R and ˜ H = R2 respectively. 23 / 35
Support Vector Machines Algorithm Development 1909 • Mercer Theorem — James Mercer. "Functions of Positive and Negative Type, and their Connection with the Theory of Integral Equations". 1950 • "Moore-Aronzajn Theorem" — Nachman Aronszajn. "Reproducing Kernel Hilbert Spaces". 1964 • Introduced the geometrical interpretation of the kernels as inner products in a feature space — Aizerman, Braverman and Rozonoer. "Theoretical Foundations of the Potential Function Method in Pattern Recognition Learning". 1964 • Original SVM algorithm — Vladimir Vapnik and Alexey Chervonenkis. "A Note on One Class of Perceptrons" 26 / 35
Support Vector Machines Algorithm Development 1965 • Cover’s Theorem — Thomas Cover. "Geometrical and Statistical Properties of Systems of Linear Inequalities with Applications in Pattern Recognition". 1992 • Support Vector Machines — Bernhard Boser, Isabelle Guyon and Vladimir Vapnik. "A Training Algorithm for Optimal Margin Classifiers". 1995 • Soft Support Vector Machines — Corinna Cortes and Vladimir Vapnik. "Support Vector Networks". 27 / 35
to Support Vector Machines — https://beta.oreilly.com/learning/intro-to-svm ▶ Lutz H. Hamel, Knowledge Discovery with Support Vector Machines. ▶ John Shawe-Taylor and Nello Cristianini, Kernel Methods for Pattern Analysis. 29 / 35
![Deep Networks and Kernel Methods Edgar Marca [email protected] Grupo de](https://files.speakerdeck.com/presentations/d6406acb2b1243ba95778f0f7d1d2c65/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}