Duke University [email protected] Mark McChaill Duke University [email protected] Leveraging LLMs for Student Feedback in Introductory Data Science Courses Triangle AI Summit > Teaching with AI Showcase
world exploring data ethics rigorous conclusions looking further visualize import wrangle misrepre- sentaton data privacy algorith- mic bias model infer predict communicate
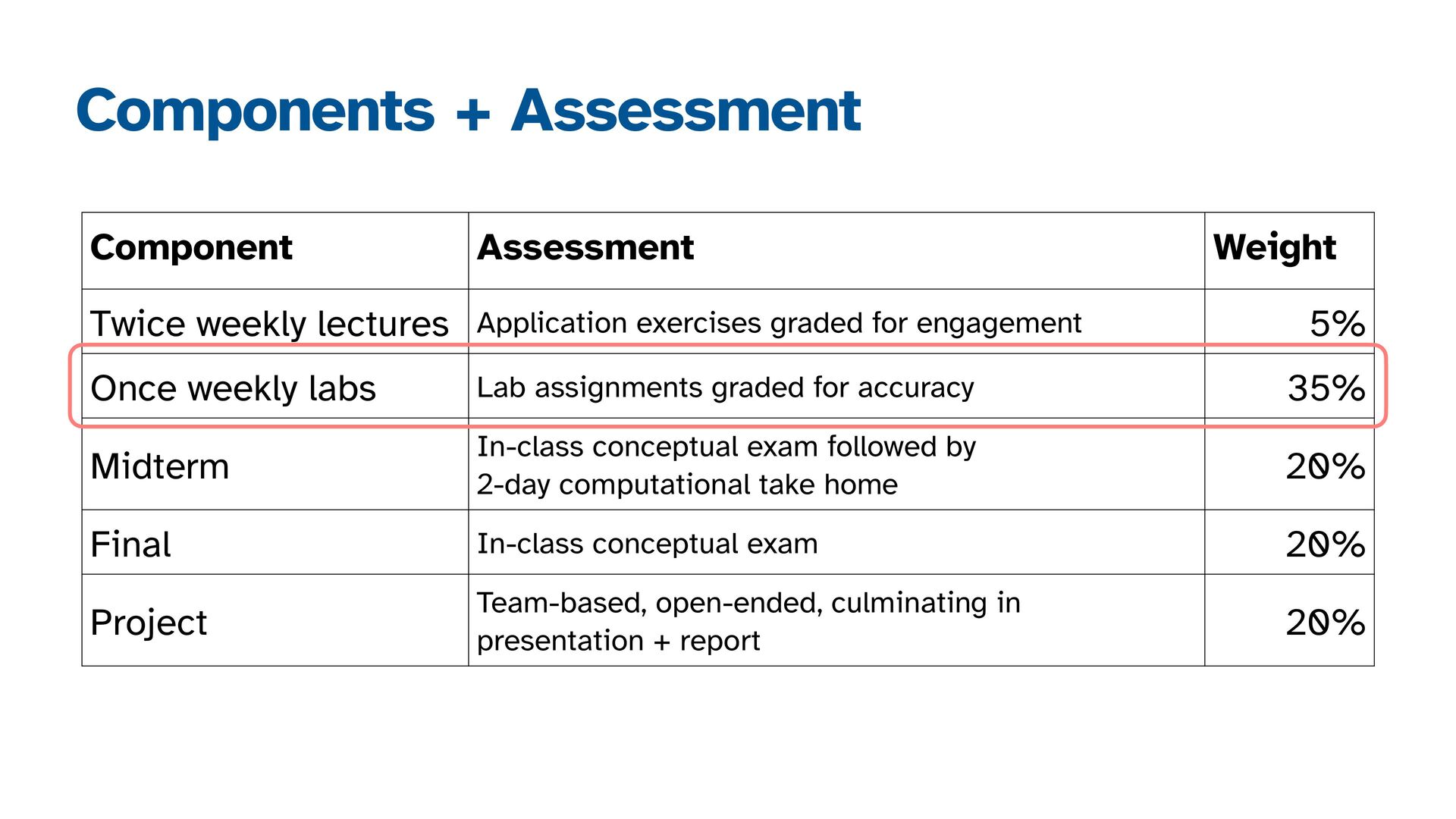
exercises graded for engagement 5% Once weekly labs Lab assignments graded for accuracy 35% Midterm In-class conceptual exam followed by 2-day computational take home 20% Final In-class conceptual exam 20% Project Team-based, open-ended, culminating in presentation + report 20%
for code: You may use, you must explicitly cite. [some guidance for how to cite] The prompt you use cannot be copied and pasted directly from the assignment; you must create a prompt yourself. ❌ AI tools for narrative: Unless instructed otherwise, you may not use generative AI to generate a narrative that you then copy-paste verbatim into an assignment or edit and then insert into your assignment. ✅ AI tools for learning: You’re welcomed to ask AI tools questions that might help your learning and understanding in this course.
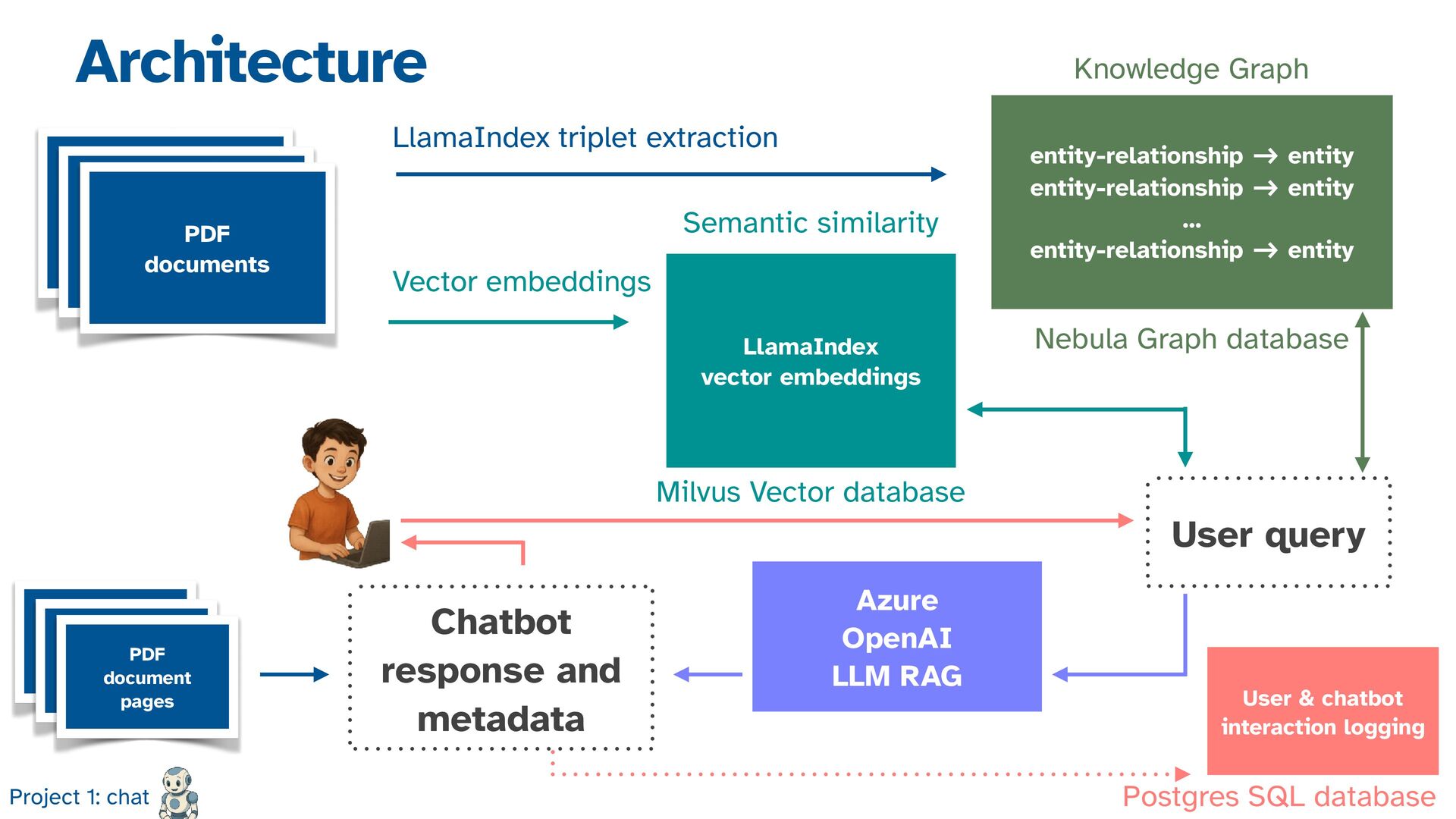
chatbot on course content, give it context, and obtain pointers to specific pages of interest in the course textbooks: ✴ Knowledge Graph: Searchable/traversable graph database of subject - > predicate - > object statements from text. ✴ Semantic Similarity: Search identifies nearest neighbors based on word similarity using a vector database. ✴ Relevant content from the course textbooks identified by combining semantic similarity and knowledge graph searches. ✴ Embed the chatbot into the Canvas Learning Management System as an LTI tool for student and instructor access. Project 1: chat
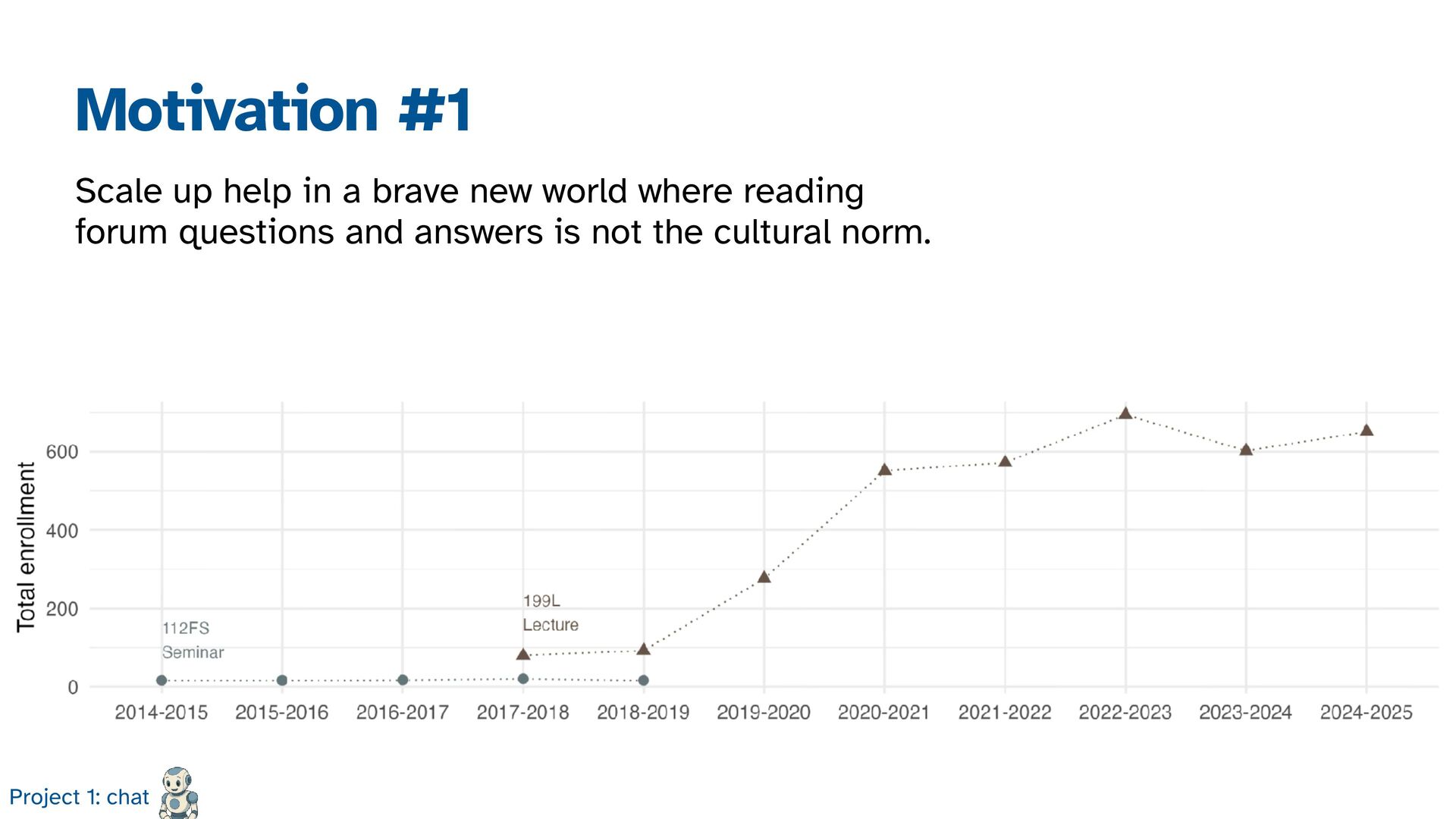
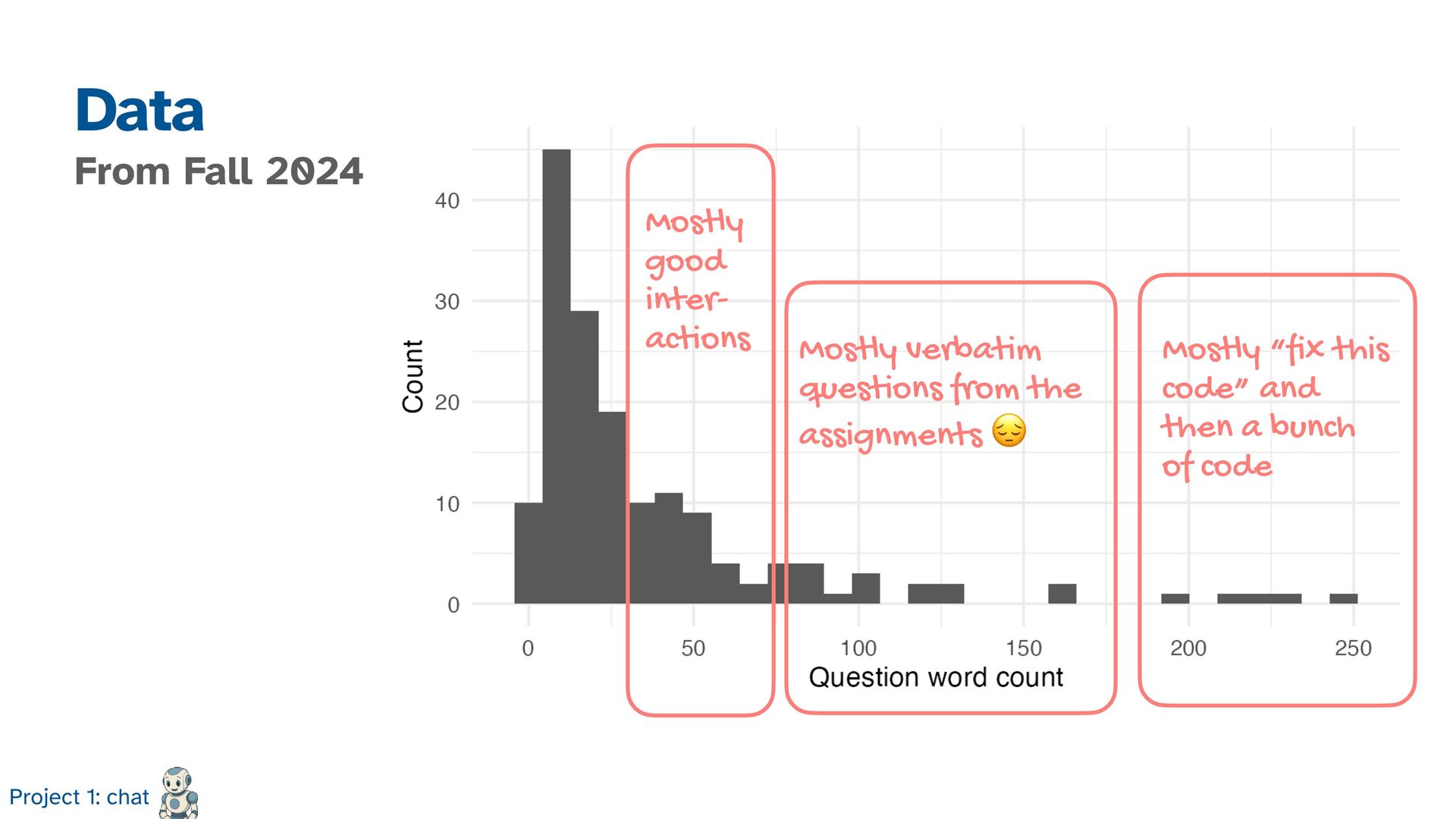
tools as their first step, before thinking about how to approach a task. Project 2: feeedback Microsoft Study Finds AI Makes Human Cognition “Atrophied and Unprepared” “[A] key irony of automation is that by mechanising routine tasks and leaving exception-handling to the human user, you deprive the user of the routine opportunities to practice their judgement and strengthen their cognitive musculature, leaving them atrophied and unprepared when the exceptions do arise,” the researchers wrote. 404media.co/microsoft-study-finds-ai-makes-human-cognition-atrophied-and-unprepared-3. Lee, Hao-Ping Hank, et al. "The Impact of Generative AI on Critical Thinking: Self-Reported Reductions in Cognitive Effort and Confidence Effects From a Survey of Knowledge Workers." (2025).
of help them take shortcuts in their learning? ✴ Can AI help TAs redistribute their time towards more higher-value (and more enjoyable!) touch points with students and away from repetitive (and error-prone) tasks much of which go unread? https://x.com/AuthorJMac Project 2: feeedback
want to provide detailed feedback to answers generated solely with AI tools. ✴ Thanks to large numbers of students and TAs, and thanks to Gradescope, I’m already writing the darn detailed rubrics! Project 2: feeedback
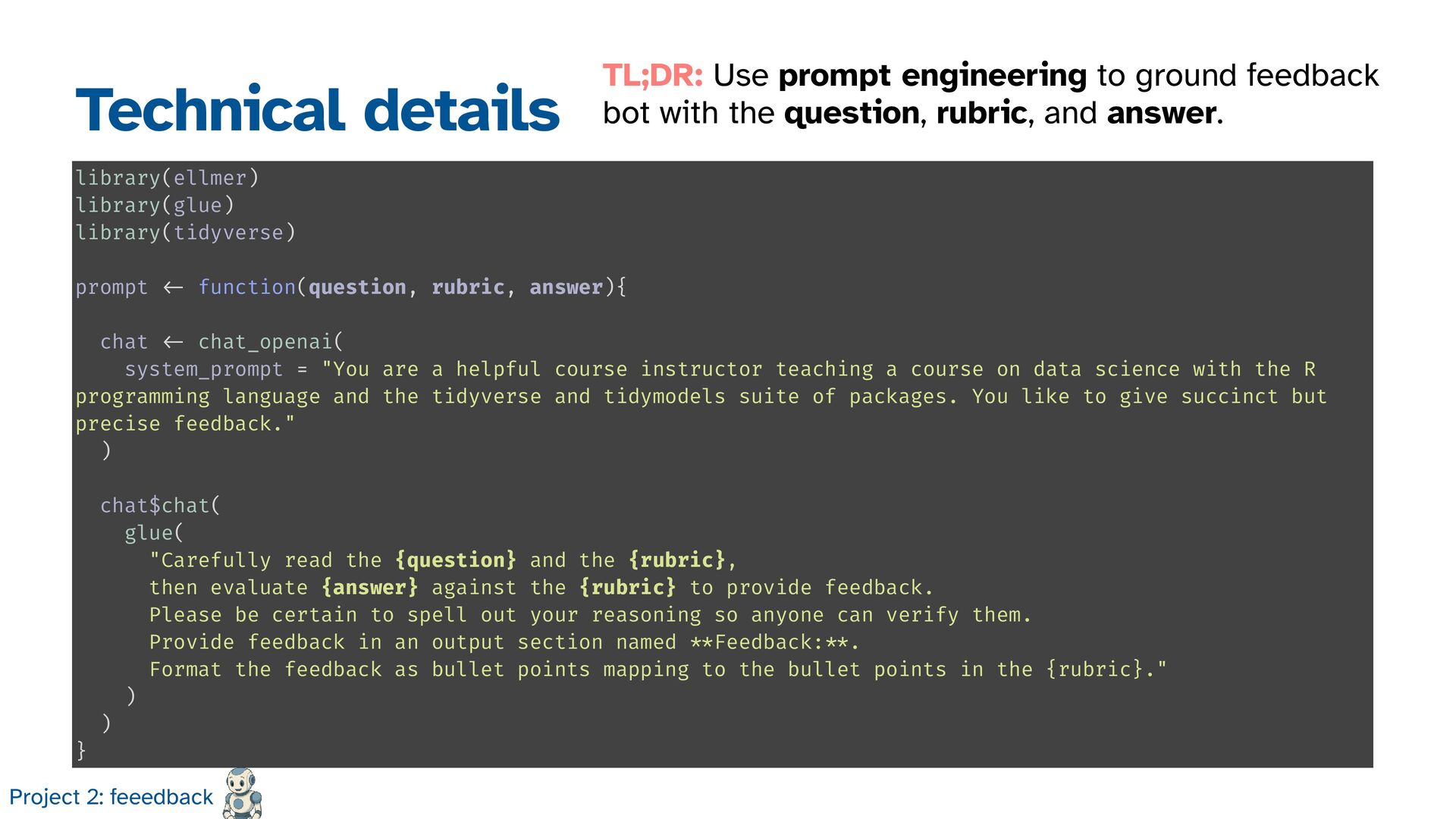
with the question, rubric, and answer. library(ellmer) library(glue) library(tidyverse) prompt < - function(question, rubric, answer){ chat < - chat_openai( system_prompt = "You are a helpful course instructor teaching a course on data science with the R programming language and the tidyverse and tidymodels suite of packages. You like to give succinct but precise feedback." ) chat$chat( glue( "Carefully read the {question} and the {rubric}, then evaluate {answer} against the {rubric} to provide feedback. Please be certain to spell out your reasoning so anyone can verify them. Provide feedback in an output section named * * Feedback: * * . Format the feedback as bullet points mapping to the bullet points in the {rubric}." ) ) } Project 2: feeedback
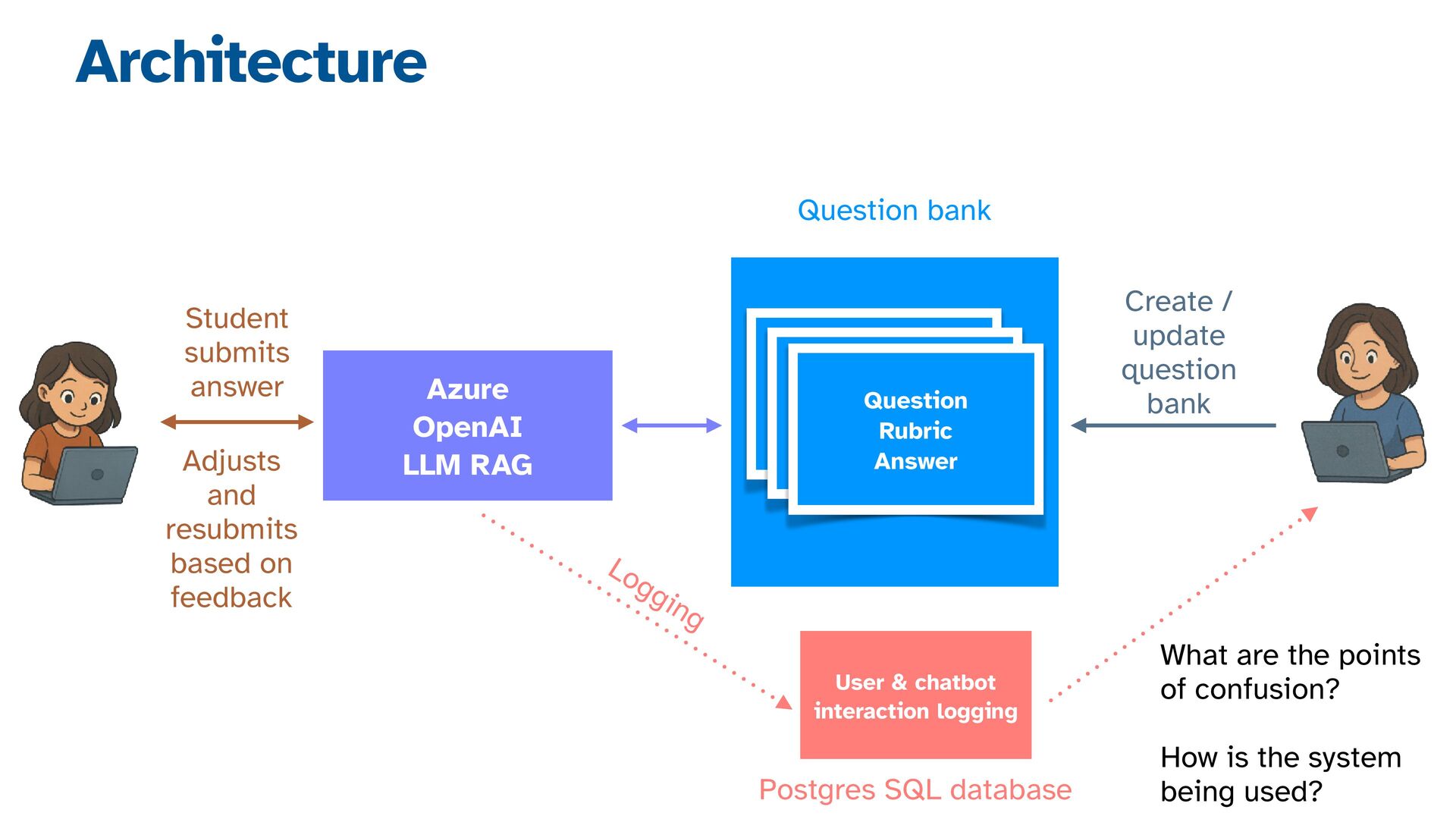
User & chatbot interaction logging Postgres SQL database Student submits answer Adjusts and resubmits based on feedback What are the points of confusion? How is the system being used? Logging Create / update question bank
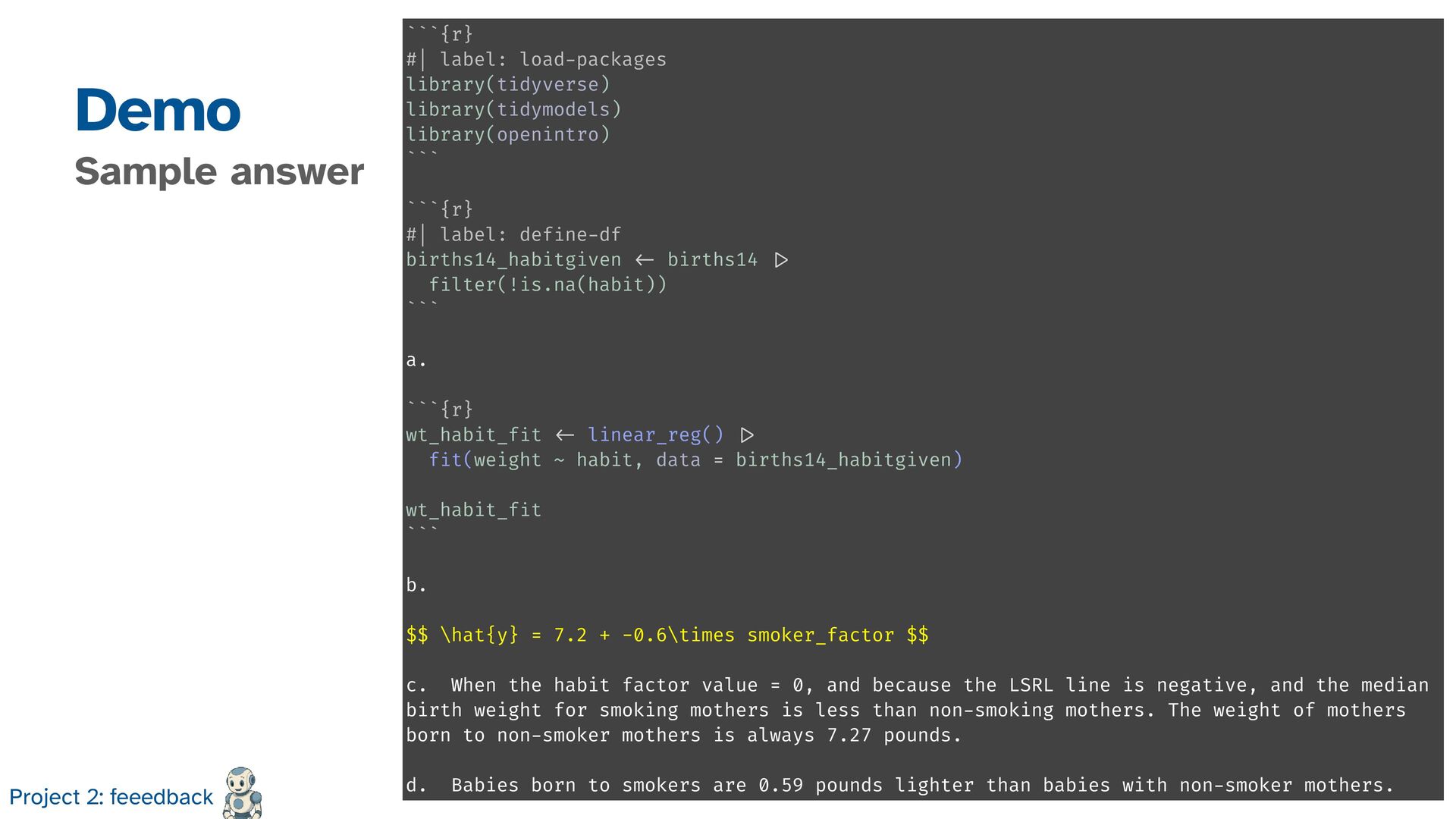
set that will be used is called `births14` , and it is included in the openintro package you loaded at the beginning of the assignment. Note: this question relies on an earlier part of the assignment, where the `births14` dataset is f i ltered to remove NA values and assigned the name `births14_habitgiven`. a. Fit a linear model that predicts weight from habit and save the model object. Then, provide the tidy summary output. b. Write the estimated least squares regression line below using proper notation. c. Interpret the intercept in the context of the data and the research question. Is the intercept meaningful in this context? Why or why not? d. Interpret the slope in the context of the data and the research question. TL;DR: Fit a regression model, then interpret the coefficients. Project 2: feeedback
library(tidymodels) library(openintro) ``` ```{r} #| label: def i ne - df births14_habitgiven < - births14 | > f i lter(!is.na(habit)) ``` a. ```{r} wt_habit_f i t < - linear_reg() | > f i t(weight ~ habit, data = births14_habitgiven) wt_habit_f i t ``` b. $$ \hat{y} = 7.2 + -0.6\times smoker_factor $$ c. When the habit factor value = 0, and because the LSRL line is negative, and the median birth weight for smoking mothers is less than non - smoking mothers. The weight of mothers born to non - smoker mothers is always 7.27 pounds. d. Babies born to smokers are 0.59 pounds lighter than babies with non - smoker mothers. Project 2: feeedback
ts linear regression model with the correct response and predictor variables using `tidymodels` functions. - Part (a) - Regression summary is displayed with `tidy()`. - Part (b) - Estimated least squares regression line is correct. - The outcome is the predicted value of the variable, either spelled out in words or using math text. - Correct values from the model output. - Part (c) - Narrative provides correct interpretation of the intercept in context of the data. - Part (c) - Narrative states that the intercept is meaningful and provides correct justif i cation. - Part (d) - Narrative provides correct interpretation of the slope in context of the data. - Code style and readability: Line breaks after each | > , proper indentation, spaces around = signs, and spaces after commas, if there are commas present. Project 2: feeedback
regression model: The model is correctly specified using tidymodels functions. ✴ Part (a) - Regression summary displayed with `tidy()`: The tidy() function ismissing from the code which is needed to display the coefficient summary. ✴ Part (b) - Estimated least squares regression line is correct: The equation has incorrect coefficient values and lacks proper notation for predicted values. ✴ Part (c) - Narrative provides correct interpretation of intercept: The interpretation is unclear and doesn't mention expected/average values. ✴ Part (c) - Narrative states intercept is meaningful with justification: The response doesn't explicitly address whether the intercept is meaningful or provide justification. ✴ Part (d) - Narrative provides correct interpretation of slope: The interpretation needs to reference expected/average values rather than individual cases. ✴ Code smell, style, and readability: The code needs spaces around operators (=) and after commas in function arguments. Project 2: feeedback
code correctly uses the `pivot_longer()` function. ✴ Code names the data frame something short and informative: Not met - the code overwrites the original `country_inflation` data frame instead of creating a new one. ✴ Code names the year variable `year` and the inflation variable `annual_inflation`: Partially met - while year is correctly named, the inflation variable is named `inflationrate` instead of `annual_inflation`. ✴ Code transforms the year variable to numeric inside `pivot_longer()`: Not met - the code does not include the required `names_transform = as.numeric` argument. ✴ Output displays `country_inflation_longer`: Not met - the output shows a data frame named `country_inflation`. ✴ Output has 3 columns — `country`, `year`, and `annual_inflation`: Partially met - while there are 3 columns, the inflation column has a different name than specified. ✴ Narrative states the correct numbers of rows and columns, 1,178 rows and 3: Met - the narrative correctly states there are 3 columns and 1,178 rows. ✴ Code style and readability: Partially met - while the code has proper line breaks and indentation, there are inconsistent spaces around commas. Project 2: feeedback
rubric file, though unclear / hard to measure to what end. ✴ Separating out to rubric and rubric_detailed helps hide the answer while giving constructive feedback. Project 2: feeedback
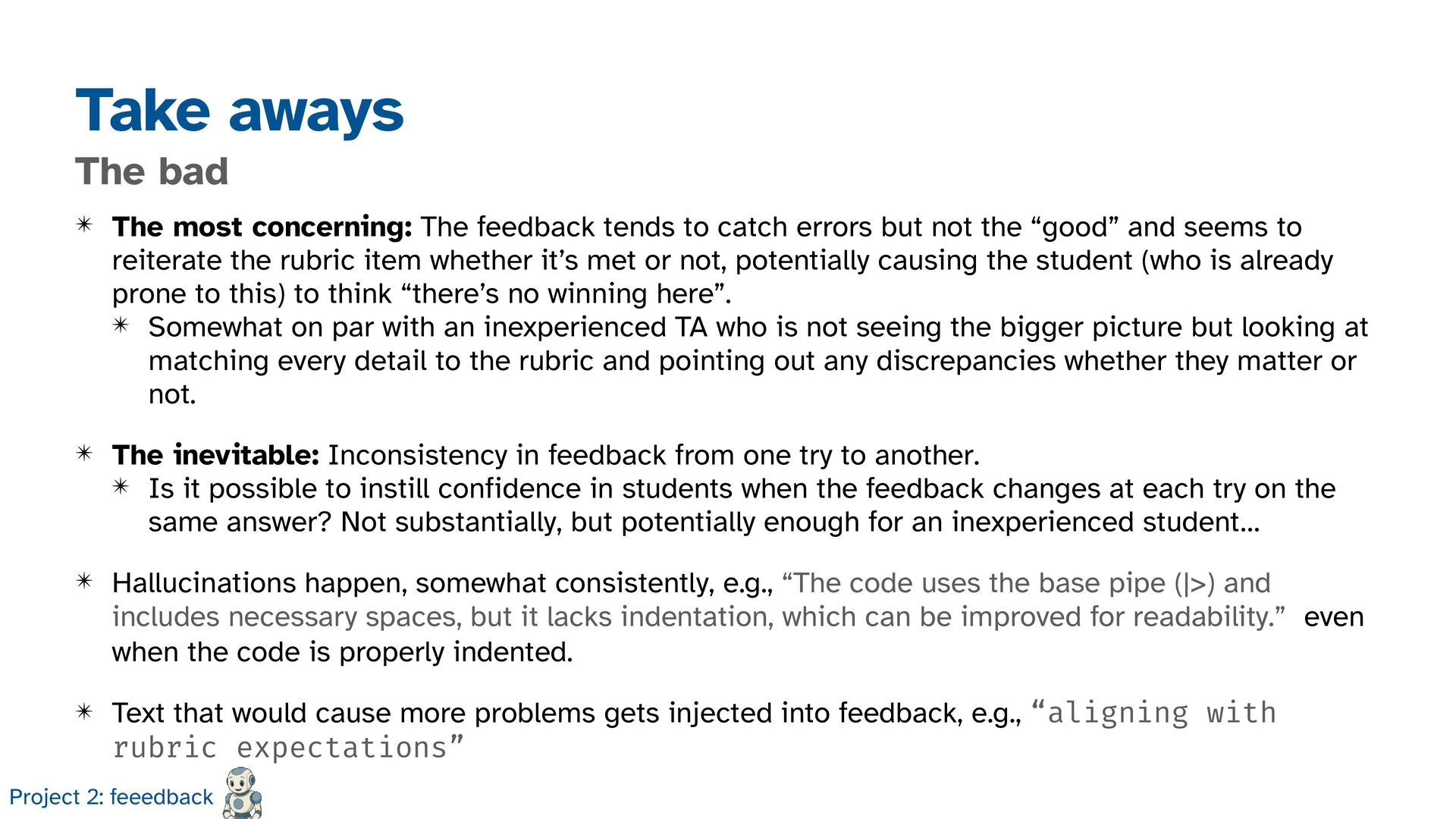
tends to catch errors but not the “good” and seems to reiterate the rubric item whether it’s met or not, potentially causing the student (who is already prone to this) to think “there’s no winning here”. ✴ Somewhat on par with an inexperienced TA who is not seeing the bigger picture but looking at matching every detail to the rubric and pointing out any discrepancies whether they matter or not. ✴ The inevitable: Inconsistency in feedback from one try to another. ✴ Is it possible to instill confidence in students when the feedback changes at each try on the same answer? Not substantially, but potentially enough for an inexperienced student… ✴ Hallucinations happen, somewhat consistently, e.g., “The code uses the base pipe (|>) and includes necessary spaces, but it lacks indentation, which can be improved for readability.” even when the code is properly indented. ✴ Text that would cause more problems gets injected into feedback, e.g., “aligning with rubric expectations” Project 2: feeedback
evaluation and tradeoffs between cost, speed, and accuracy with different approaches. ✴ Send prompt to multiple models with an additional prompt to summarize the various model results and evaluate if this leads to more accurate and consistent feedback. ✴ Continue system prompt enhancements and tuning. ✴ Measure learning outcomes for students using the LLM feedback and evaluate if this approach is “effective” (for a variety of goals). ✴ Consider packaging the LLM feedback tool for application to other fields. Project 1: chat + Project 2: feeedback
an image with a robot helping children. The kids should be looking at a laptop. And make the image rectangle, with height less than width.” https://chatgpt.com/share/682c8623-b100-8000-972c-e7384801436f Mark McChaill Duke University [email protected] Mine Çetinkaya-Rundel Duke University [email protected] duke.is/help-from-ai
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}