Share
第157回音声言語情報処理研究発表会 招待講演
日程: 2025年10月1日(水) 場所:オンライン 主催:電子情報通信学会および日本音響学会 音声研究会(SP) 情報処理学会 音声言語情報処理研究会(SLP)
![立命館大学 情報理工学部 メディア情報コース 特任助教 永瀬亮太郎 [招待講演] 音声感情認識技術の進展と展望 音声研究会/音声言語情報処理研究会 2025/10/01 ©](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
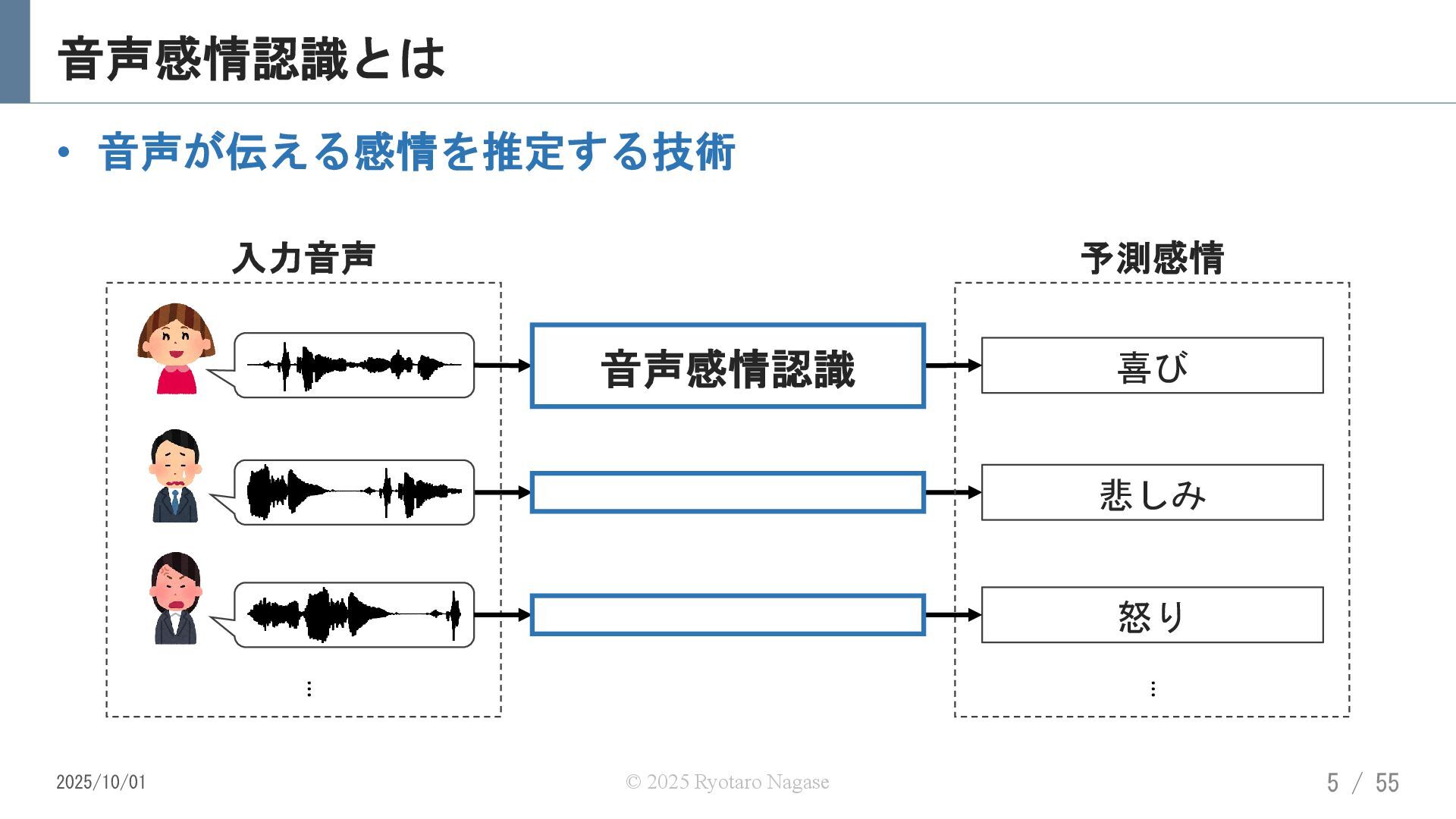{kind=link}
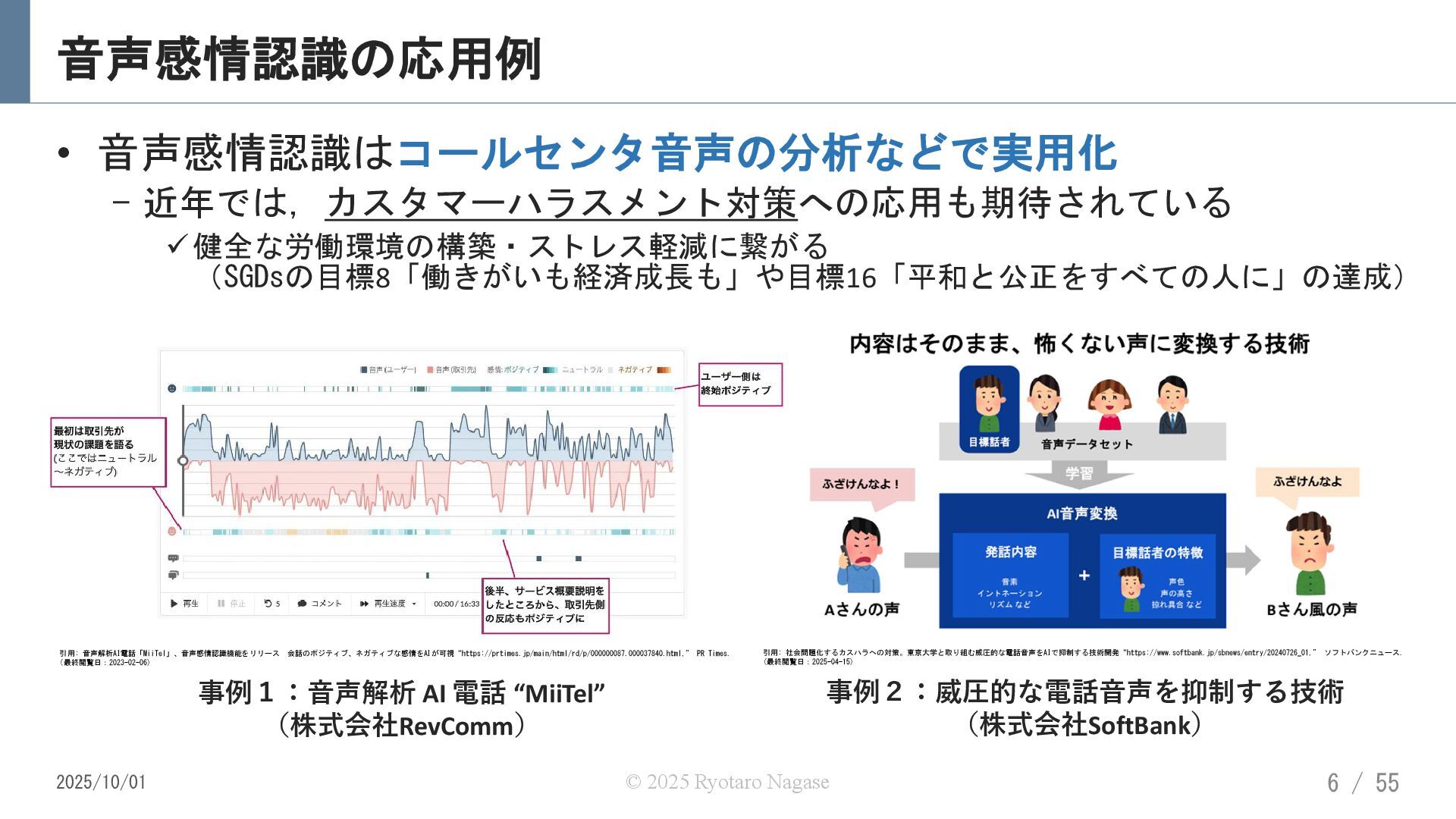{kind=link}
![タスク設定 • カテゴリ感情認識 ‒ 「喜び」や「怒り」などの離散的なクラスを推定 e.g. Plutchik の感情の輪における基本8感情 [R.Plutchik 2001]](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_6.jpg){kind=link}
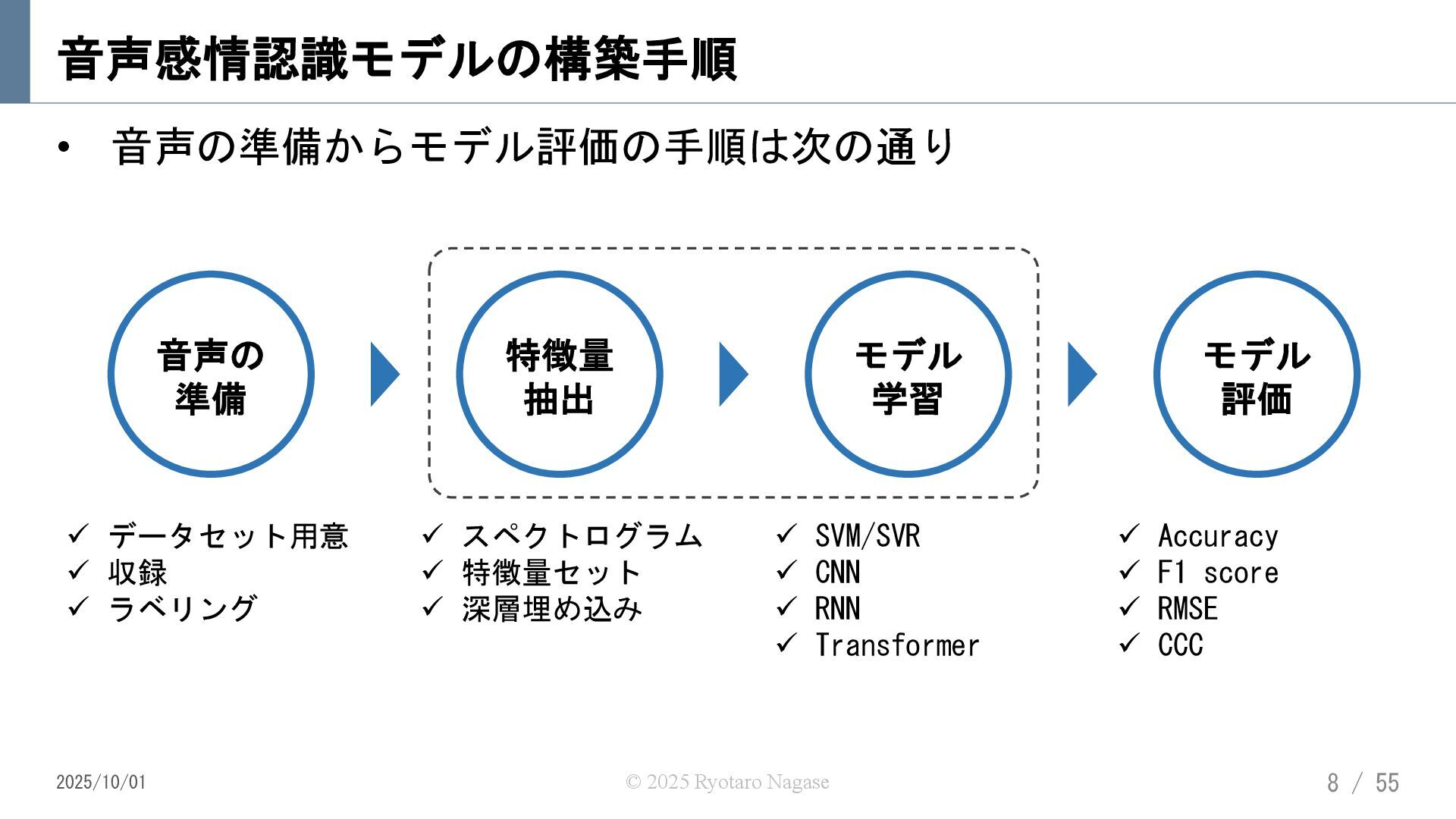{kind=link}
{kind=link}
{kind=link}
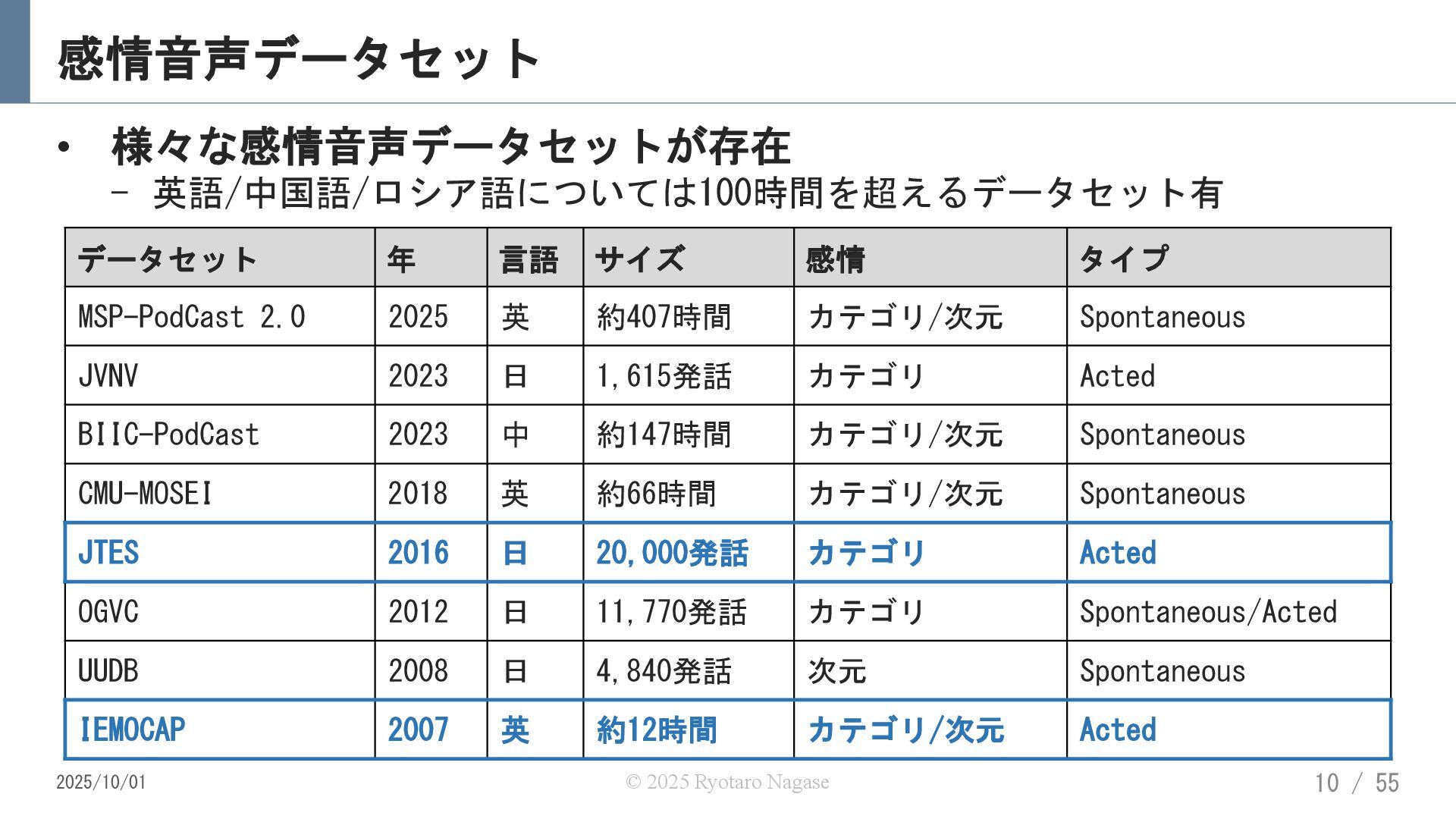
![感情音声データセット(日本語) • JTES (Japanese Twitter based emotional speech) [E.Takeishi+ 2016]](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_10.jpg){kind=link}
![感情音声データセット • IEMOCAP (Interactive emotional dyadic motion capture) [C.Busso+ 2016]](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![音声感情認識の歴史 [B.W.Schuller 2018 を参考に作成] 2025/10/01 [1970年代] 音声から感情を 判定する 最初期の特許群が 出願・登録](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_22.jpg){kind=link}
![音声における感情認識 [F.Dellaert+, ICSLP’96] [概要] ‒ ピッチ情報(基本周波数:F0)を用いた5感情分類 喜び,悲しみ,怒り,恐れ,平静 約1,000発話の感情音声音声を収録 [ポイント] ‒](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_23.jpg){kind=link}
![音声感情認識の歴史 [B.W.Schuller 2018 を参考に作成] 2025/10/01 [1970年代] 音声から感情を 判定する 最初期の特許群が 出願・登録](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_24.jpg){kind=link}
![INTERSPEECH2009 Emotion Challenge [B.Schuller+, INTERSPEECH2016] [概要] ‒ カテゴリ感情認識のコンペティション Open Performance](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_25.jpg){kind=link}
![音声感情認識の歴史 [B.W.Schuller 2018 を参考に作成] 2025/10/01 [1970年代] 音声から感情を 判定する 最初期の特許群が 出願・登録](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_26.jpg){kind=link}
![スペクトログラムを用いたCNNによる音声感情認識 [AM.Badshah+, PlatCon, 2017] [概要] ‒ 音声感情認識に畳み込みニューラルネットワーク(CNN)を導入 [ポイント] ‒ スペクトログラムから階層化したCNNで感情を推定](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_27.jpg){kind=link}
![音声感情認識の歴史 [B.W.Schuller 2018 を参考に作成] 2025/10/01 [2000年代] 特徴量セット設計と 機械学習による 認識モデルの 研究が盛んに](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_28.jpg){kind=link}
![注意機構とLSTMを用いた音声感情認識 [Y.Xie+, IEEE/ACM Trans. ASLP, 2019] [概要] ‒ 音声感情認識に注意機構とLSTMを導入 時間および特徴量における感情の濃淡を考慮](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_29.jpg){kind=link}
![音声感情認識の歴史 [B.W.Schuller 2018 を参考に作成] 2025/10/01 [2000年代] 特徴量セット設計と 機械学習による 認識モデルの 研究が盛んに](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_30.jpg){kind=link}
![wav2vec2.0を用いた音声からの感情認識 [L.Pepino+, INTERSPEECH2021] [概要] ‒ wav2vec2.0の埋め込み表現を活用した認識器を構築 データ不足による認識モデルの学習の難しさを解消 [ポイント] ‒ wav2vec2.0の出力を音声感情認識に使う効果を調査](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_31.jpg){kind=link}
![音声感情認識の歴史 [B.W.Schuller 2018 を参考に作成] 2025/10/01 [2000年代] 特徴量セット設計と 機械学習による 認識モデルの 研究が盛んに](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_32.jpg){kind=link}
![LanSER: 言語モデルの支援による音声感情認識 [T.Gong+, INTERSPEECH2023] [概要] ‒ 大規模言語モデル(LLM)で音声感情認識のための弱ラベルを生成 感情ラベルなし音声データセットを利用可能に [ポイント] ‒](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
![課題の解決に向けた取り組み • 感情音声と感情ラベルのペアデータ不足 ‒ 音声認識のデータセットと比べると圧倒的に少ない 事前学習済みモデルの構築 [W.Chen+ 2024][Z.Ma+ 2024] •](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_36.jpg){kind=link}
![課題の解決に向けた取り組み • 感情音声と感情ラベルのペアデータ不足 ‒ 音声認識のデータセットと比べると圧倒的に少ない 事前学習済みモデルの構築 [W.Chen+ 2024][Z.Ma+ 2024] 2025/10/01](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_37.jpg){kind=link}
![Vesper:音声感情認識のための小型で効果的な事前学習済みモデル [W.Chen+, IEEE Trans. AC, 2024] [概要] ‒ 小型で音声感情認識に強い事前学習済みモデルの構築 [ポイント]](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_38.jpg){kind=link}
![emotion2vec:音声感情表現のための自己教師あり事前学習 [Z.Ma+, ACL, 2024] 2025/10/01 [概要] ‒ 様々な言語/タスクに汎用的に使えるモデルの構築 [ポイント] ‒](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_39.jpg){kind=link}
![課題の解決に向けた取り組み • 感情の時間的変化の扱いが難しい ‒ 発話中の感情をただ一つのラベルで表現するのは不十分 短区間音声感情認識 [W.Han+ 2018][R.Nagase+ 2025] 2025/10/01](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_40.jpg){kind=link}
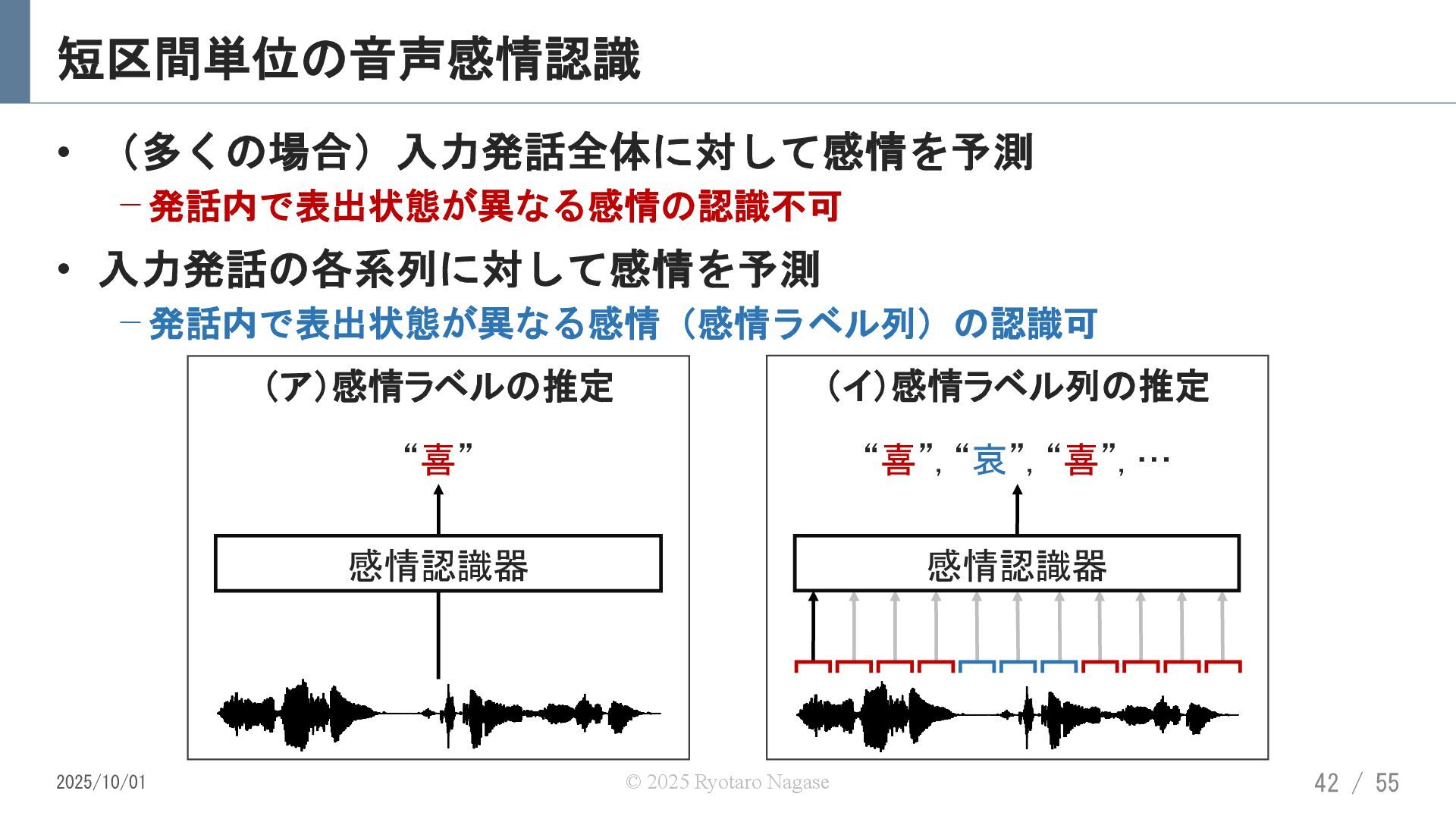{kind=link}
![音声感情認識のための時間的モデリング [W. Han+ 18] • 次の規則に従って生成された感情ラベル列の認識器を学習 a. 感情状態: 有声音素(母音+有声子音) b.](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_42.jpg){kind=link}
![音素クラス属性を考慮した短区間音声感情認識 [R.Nagase+, APSIPA Trans. SIP, 2025] • 感情ラベルを母音や有声子音,無声子音などの単位で細分化 −これらの単位を音素クラス属性と呼ぶ 音素クラス属性付き感情ラベル列](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_43.jpg){kind=link}
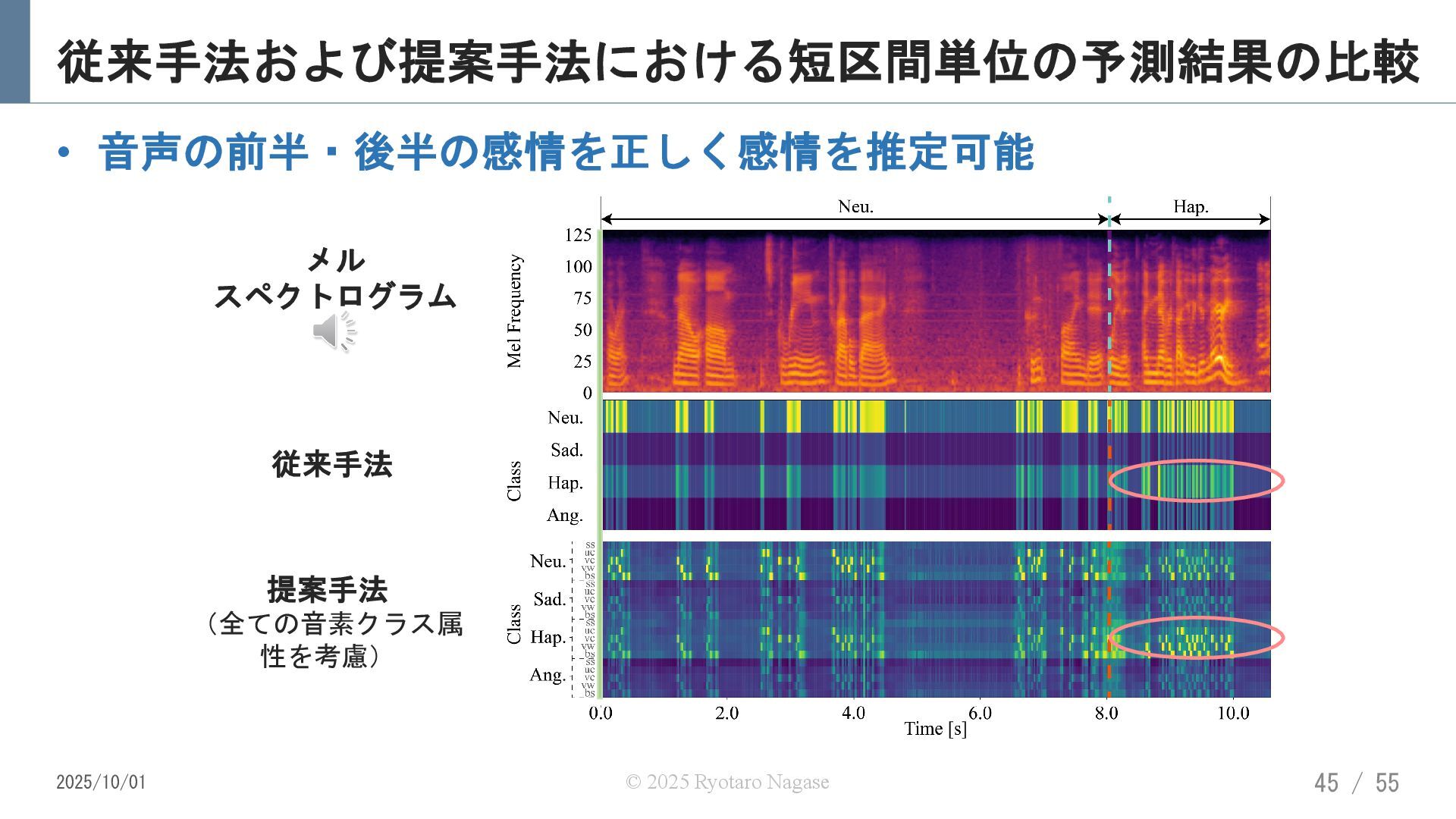{kind=link}
{kind=link}
![課題の解決に向けた取り組み • 多様で複雑な感情の扱いが難しい ‒ カテゴリ感情と次元感情にはそれぞれ欠点がある カテゴリ感情:複数感情が混在する感情などの表現が難しい 次元感情:認識結果の解釈が難しい 感情の説明文を活用した音声感情認識 [Y.Pan+ 2024][R.Nagase+](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_46.jpg){kind=link}
![CLAPに基づく音声感情認識 [Y.Pan+, ICASSP, 2024] [概要] ‒ 分類したいカテゴリを自然言語で定義可能な音声感情認識 [ポイント] ‒ 音声感情認識にCLAP(Contrastive](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_47.jpg){kind=link}
![ゼロショット音声感情認識で購買意欲を推定できるか? [R.Nagase+, APSIPA ASC, 2024] [概要] ‒ ゼロショット音声感情認識を用いた購買意欲推定 ゼロショット音声感情認識:学習時には未知の感情を推論可能な枠組み [ポイント]](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_48.jpg){kind=link}
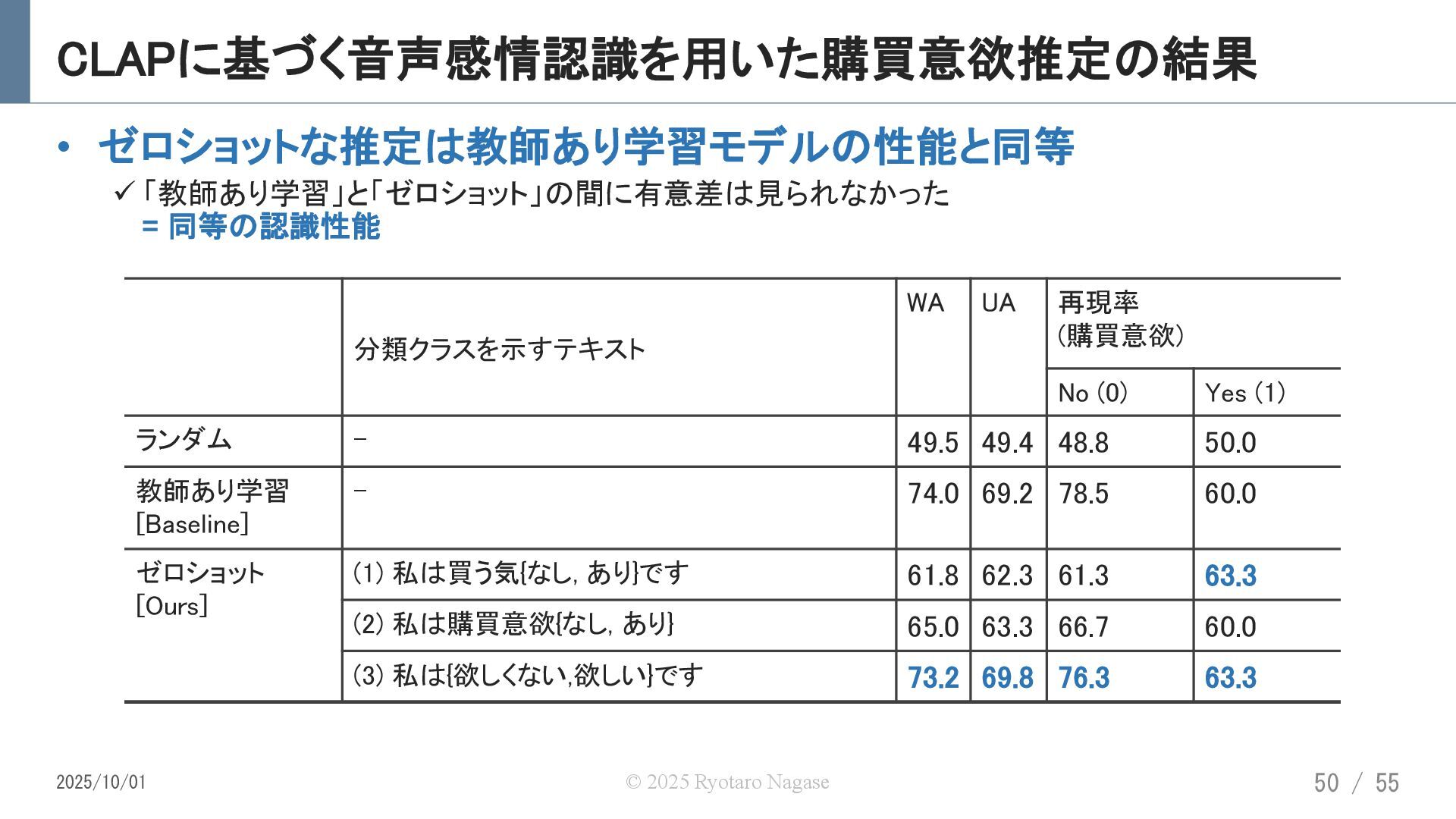{kind=link}
![SECap [Y. Xu+, AAAI, 2024] [概要] ‒ 音声が伝える感情を自然言語で記述する音声感情キャプショニング [ポイント] ‒](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_50.jpg){kind=link}
![大規模言語モデルを活用した音声感情キャプション収集 ※ 音声言語シンポジウム2024/ASJ2025にて発表 [概要] ‒ 音声感情キャプショニング用データの収集とモデル構築 [ポイント] ‒ ChatGPTとクラウドソーシングを活用して半自動的にデータを収集 発話内容と教師信号の感情ラベルから感情キャプション候補をChatGPTで生成](https://files.speakerdeck.com/presentations/02ce65114b0b49d88e371bc37ef3f5d7/slide_51.jpg){kind=link}
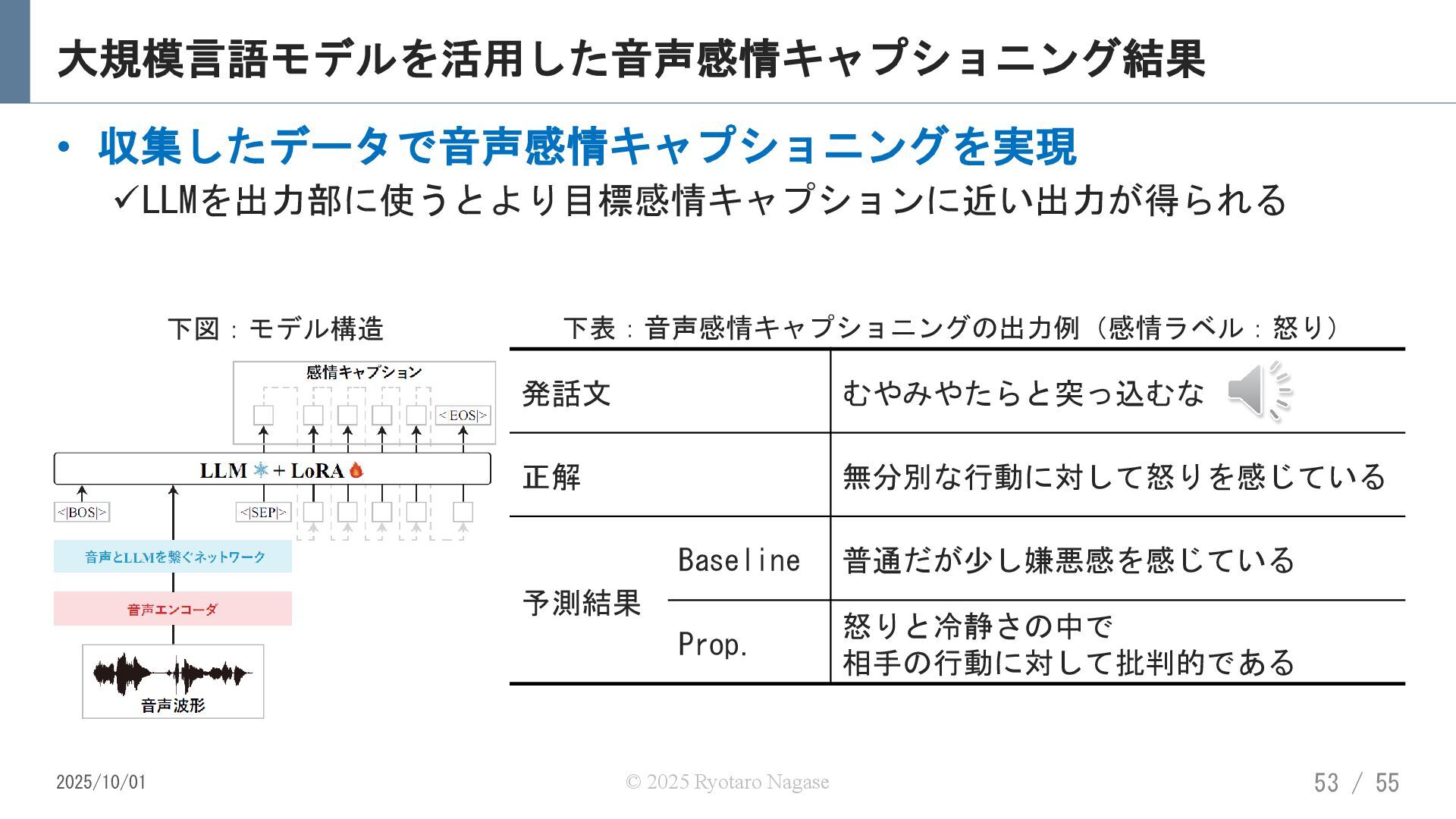{kind=link}
{kind=link}
{kind=link}