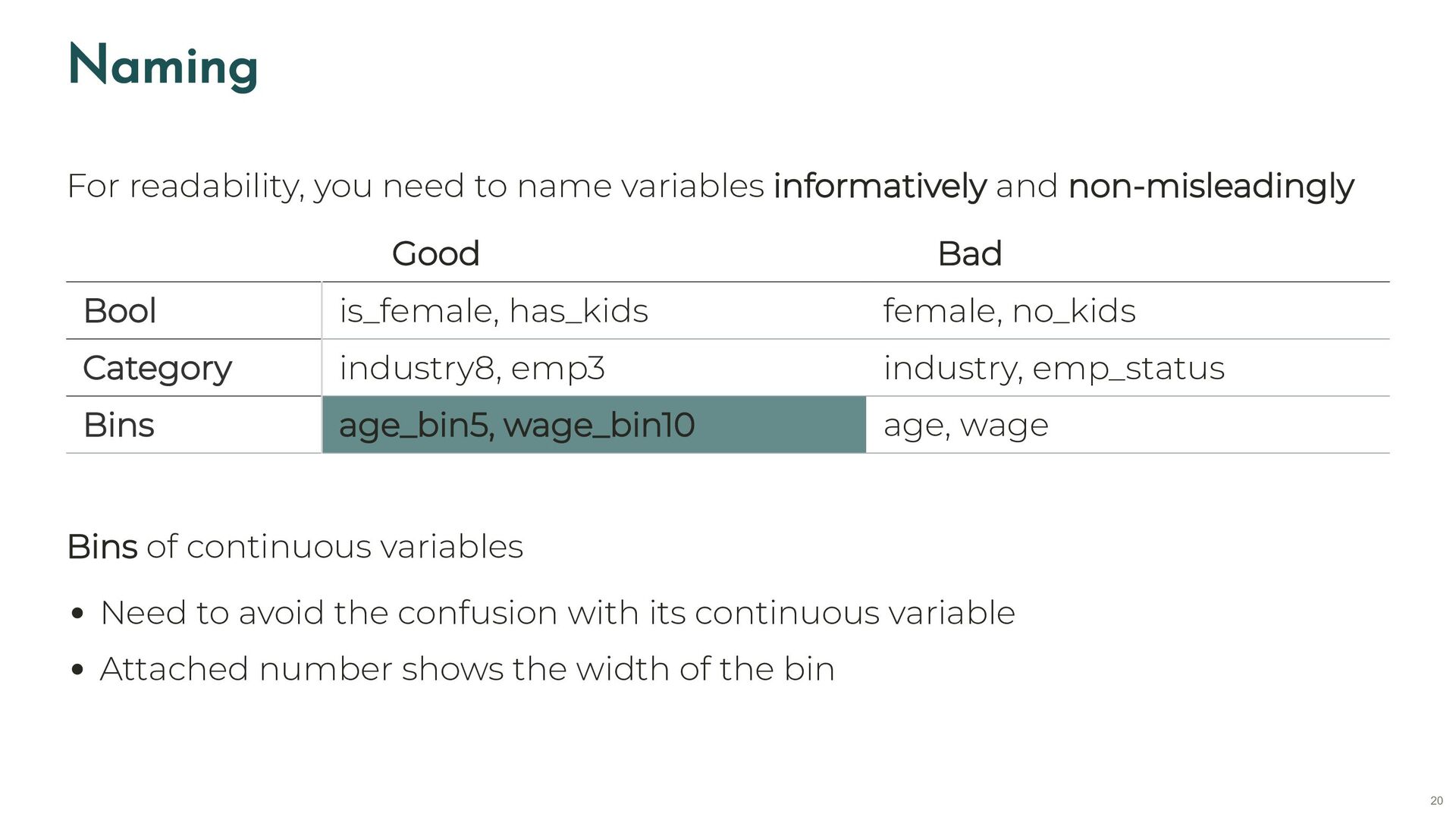
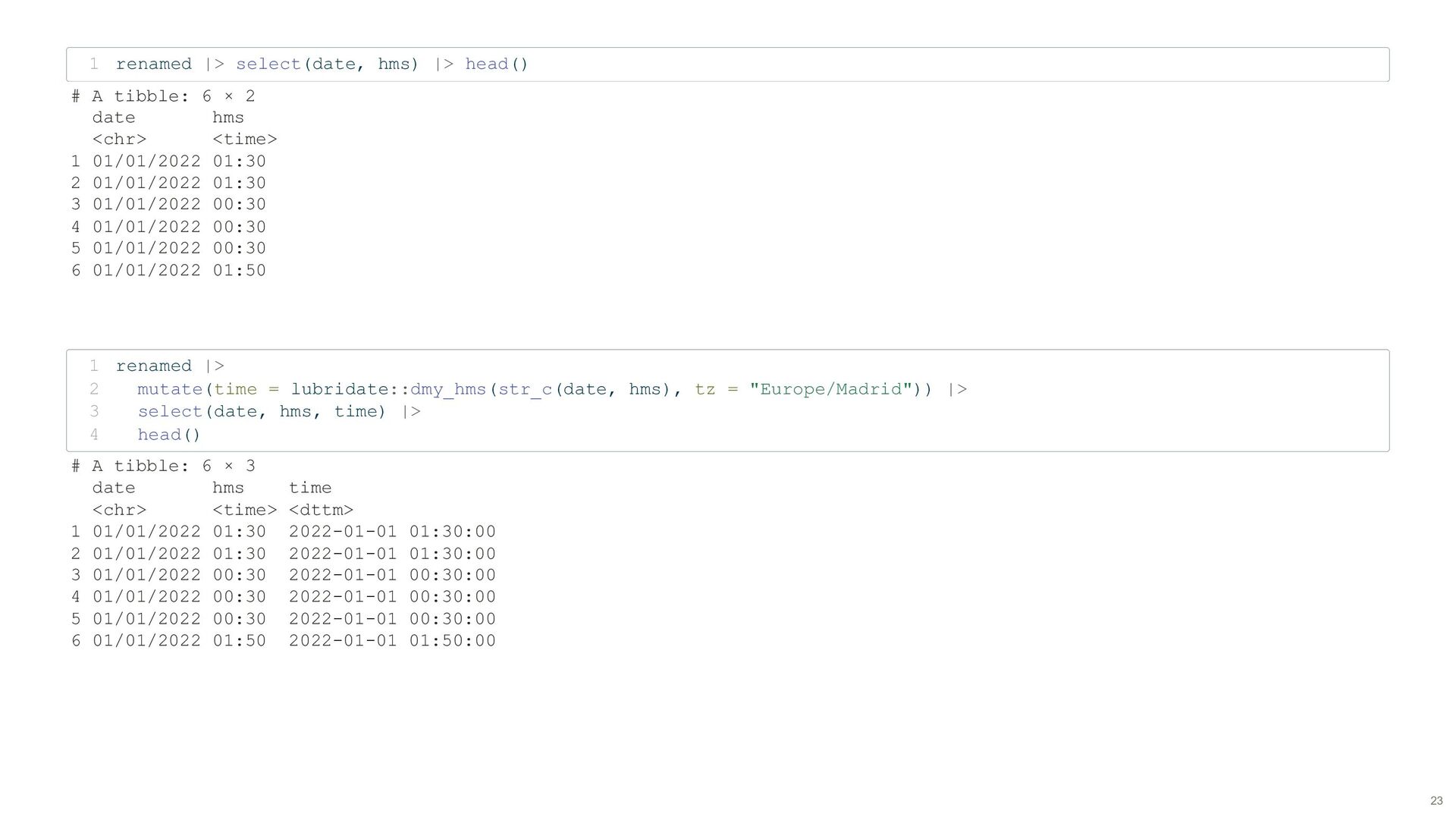
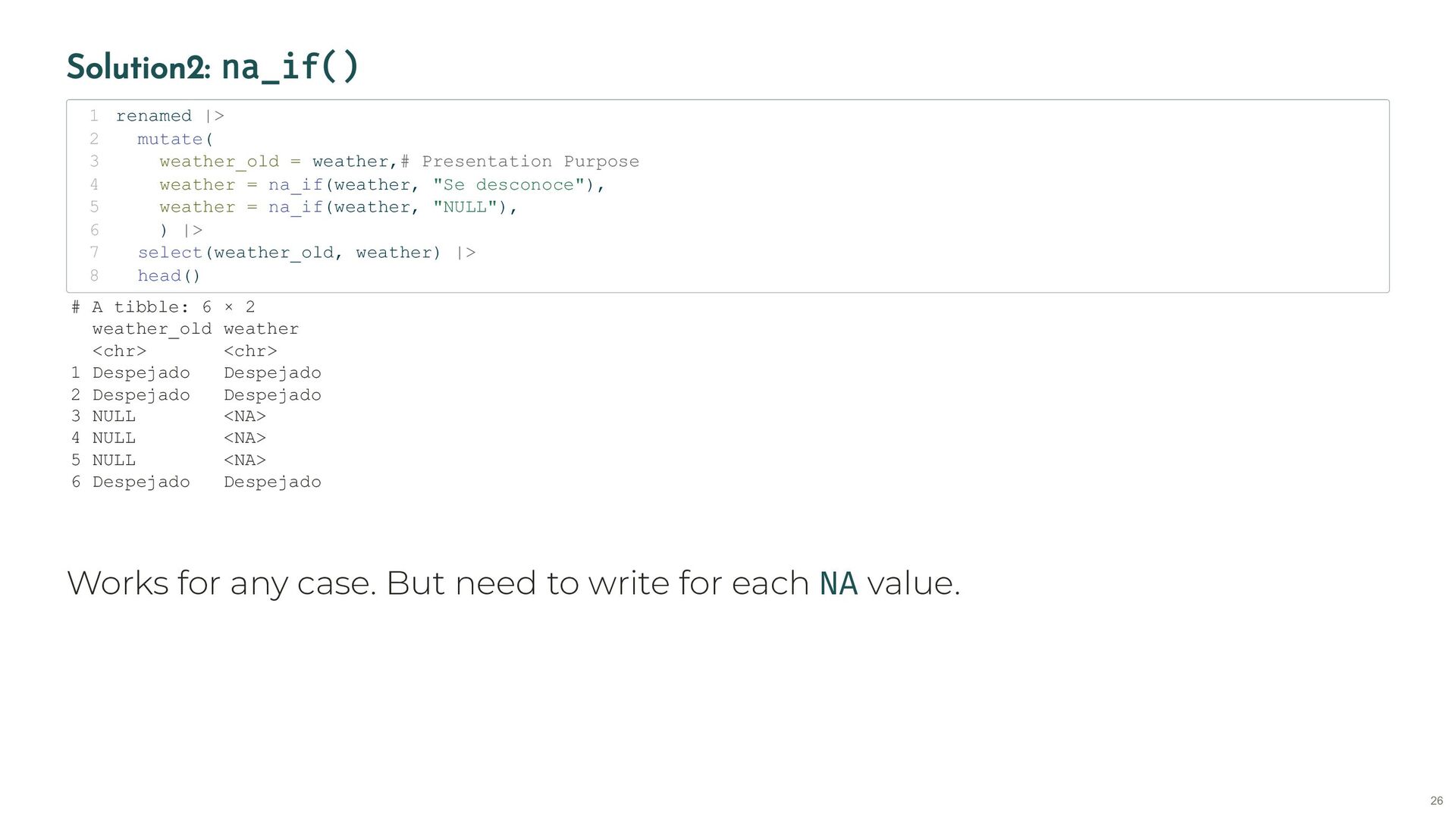
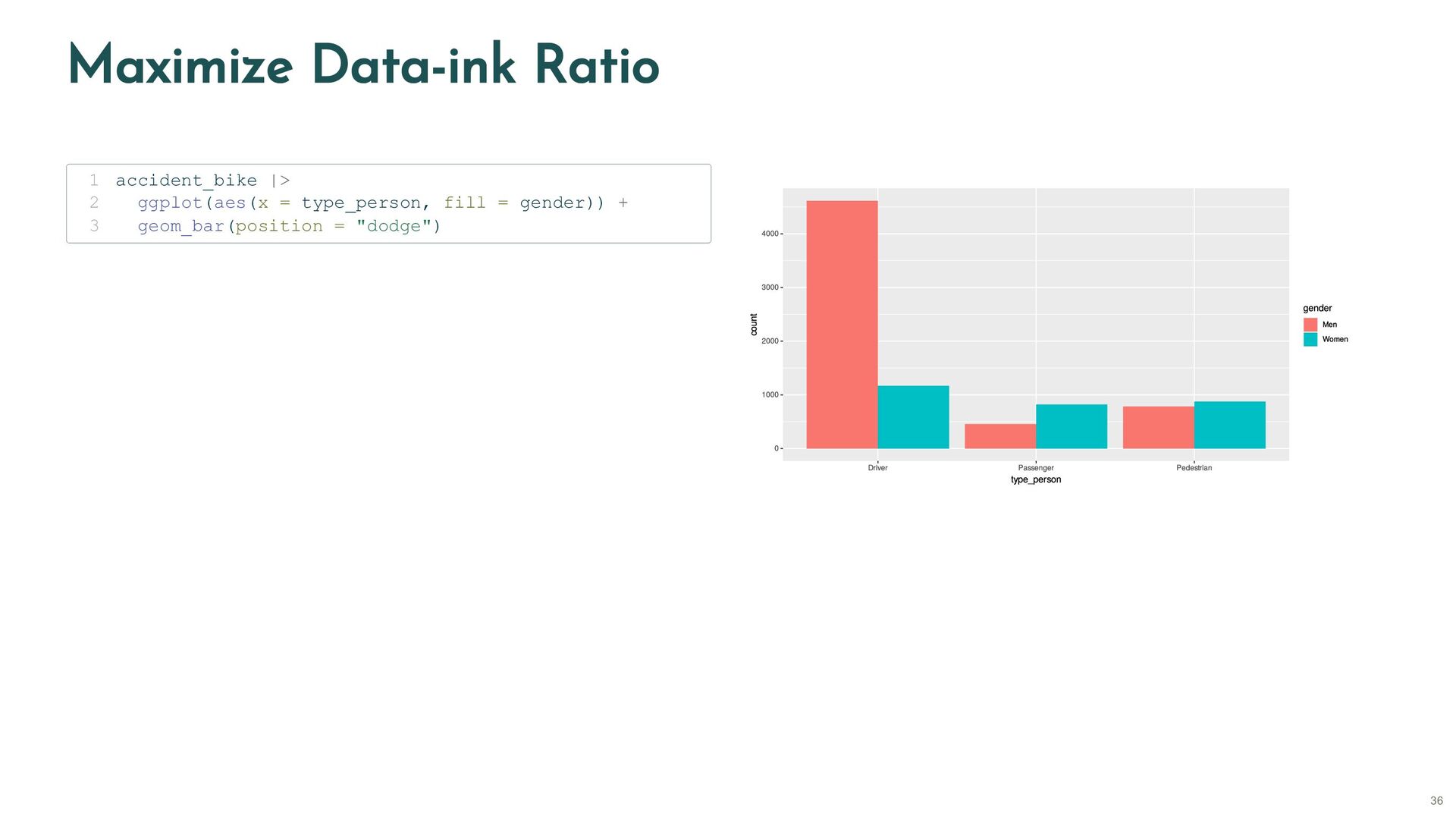
hms localizacion street numero num_street cod_distrito code_district distrito district tipo_accidente type_accident estado_meteorológico weather tipo_vehiculo type_vehicle tipo_persona type_person rango_edad age_c sexo gender cod_lesividad code_injury8 lesividad injury8 coordenada_x_utm coord_x coordenada_y_utm coord_y positiva_alcohol positive_alcohol positiva_droga positive_drug raw <- read_delim(here("data/raw/accident_bike/txt/year=2022/file.txt"), 1 delim = ";", show_col_types = FALSE) 2 Rows: 42,547 Columns: 5 $ num_expediente <dbl> 2.022e+04, 2.022e+04, 2.022e+05, 2.022e+05, 2.022e+05, … $ fecha <chr> "01/01/2022", "01/01/2022", "01/01/2022", "01/01/2022",… $ hora <time> 01:30:00, 01:30:00, 00:30:00, 00:30:00, 00:30:00, 01:5… $ localizacion <chr> "AVDA. ALBUFERA, 19", "AVDA. ALBUFERA, 19", "PLAZA. CAN… $ numero <chr> "19", "19", "2", "2", "2", "53", "53", "728", "728", "+… code <- read_csv(here("data/translate/accident_bike.csv"), 1 show_col_types = FALSE) 2 renamed <- raw |> 3 rename_at(vars(code$spanish), ~code$english) 4 Rows: 42,547 Columns: 5 $ id_1922 <dbl> 2.022e+04, 2.022e+04, 2.022e+05, 2.022e+05, 2.022e+05, 2.02… $ date <chr> "01/01/2022", "01/01/2022", "01/01/2022", "01/01/2022", "01… $ hms <time> 01:30:00, 01:30:00, 00:30:00, 00:30:00, 00:30:00, 01:50:00… $ street <chr> "AVDA. ALBUFERA, 19", "AVDA. ALBUFERA, 19", "PLAZA. CANOVAS… $ num_street <chr> "19", "19", "2", "2", "2", "53", "53", "728", "728", "+0050… 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
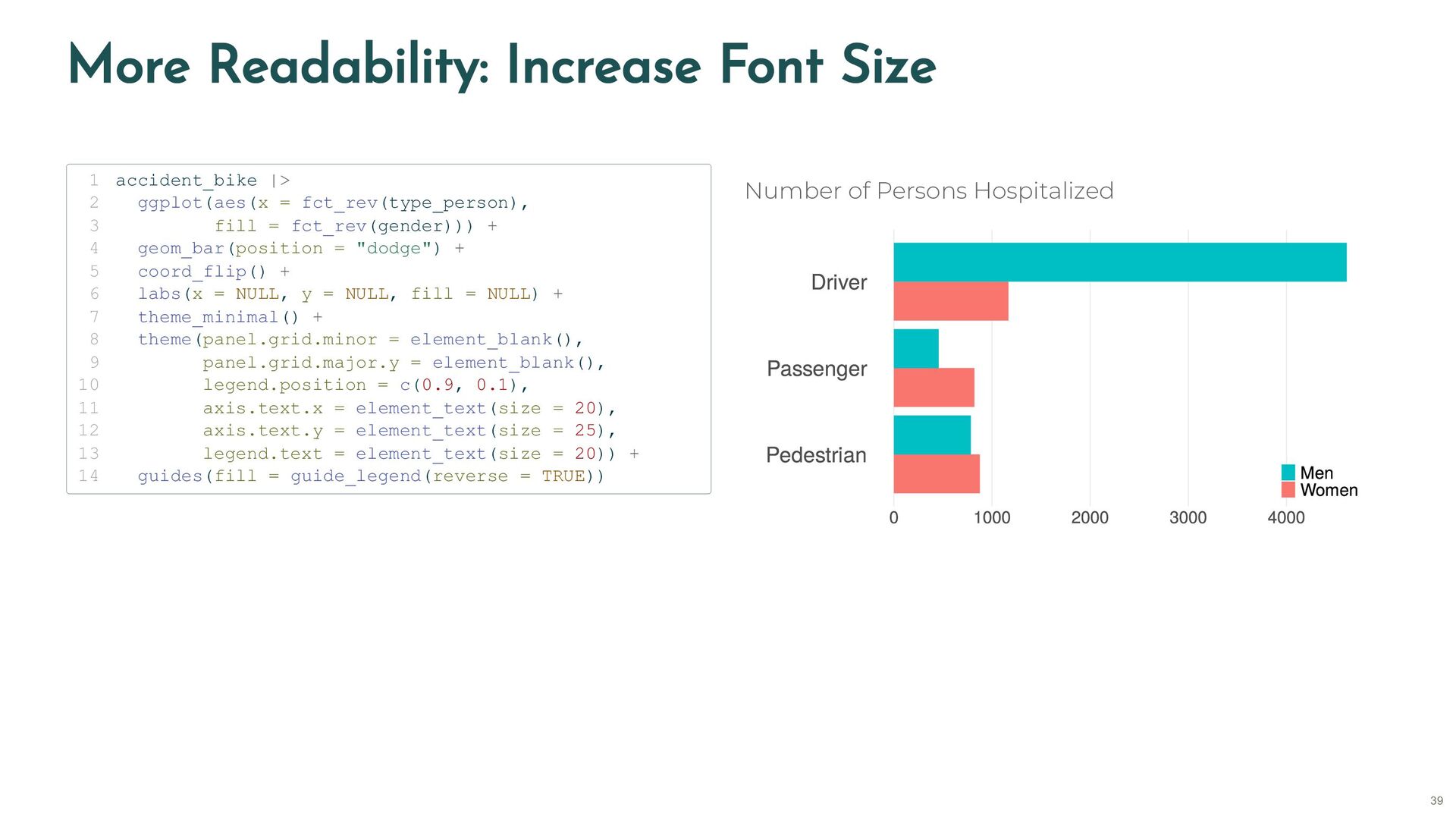{kind=link}
{kind=link}
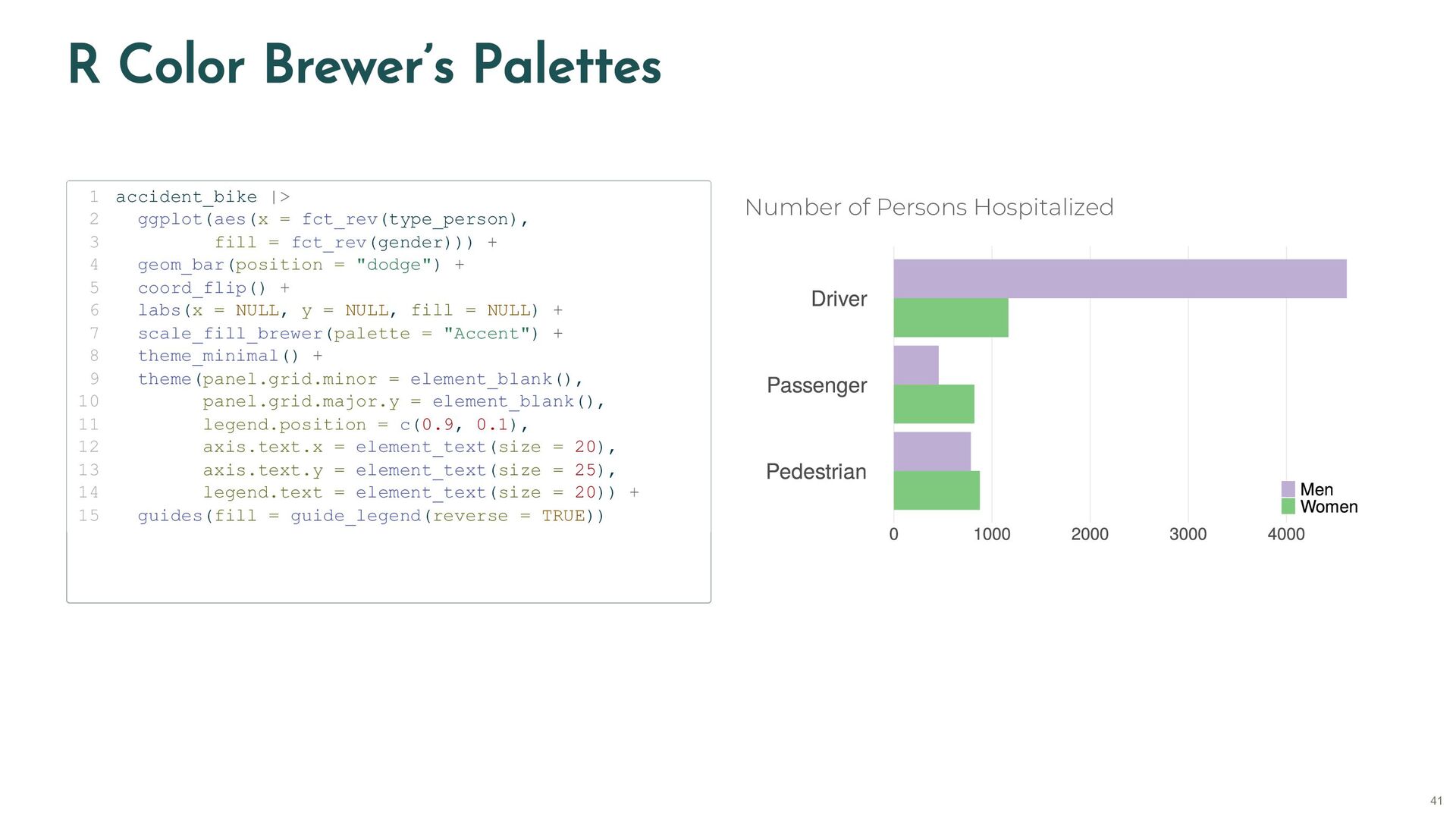{kind=link}
{kind=link}
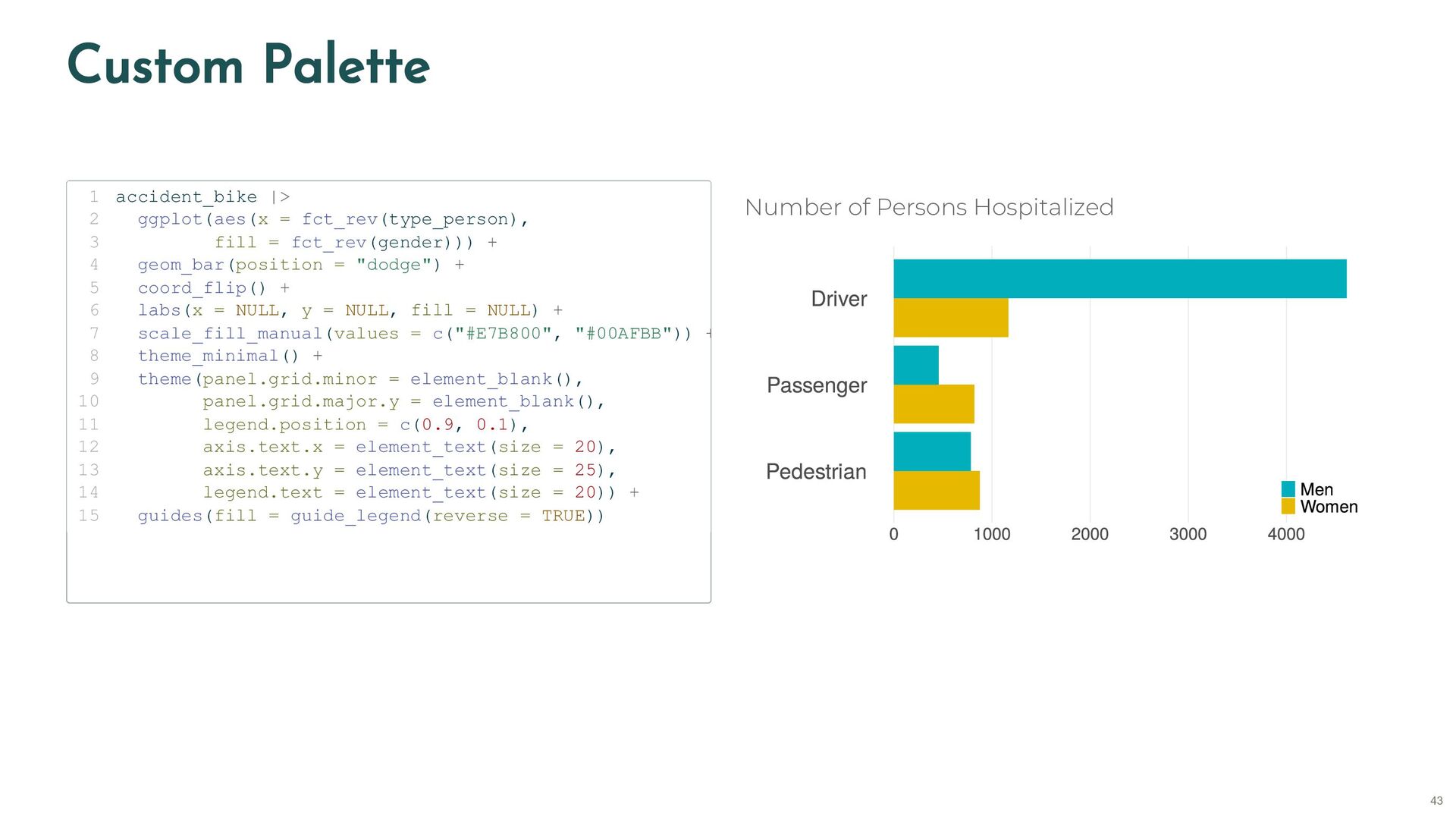{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
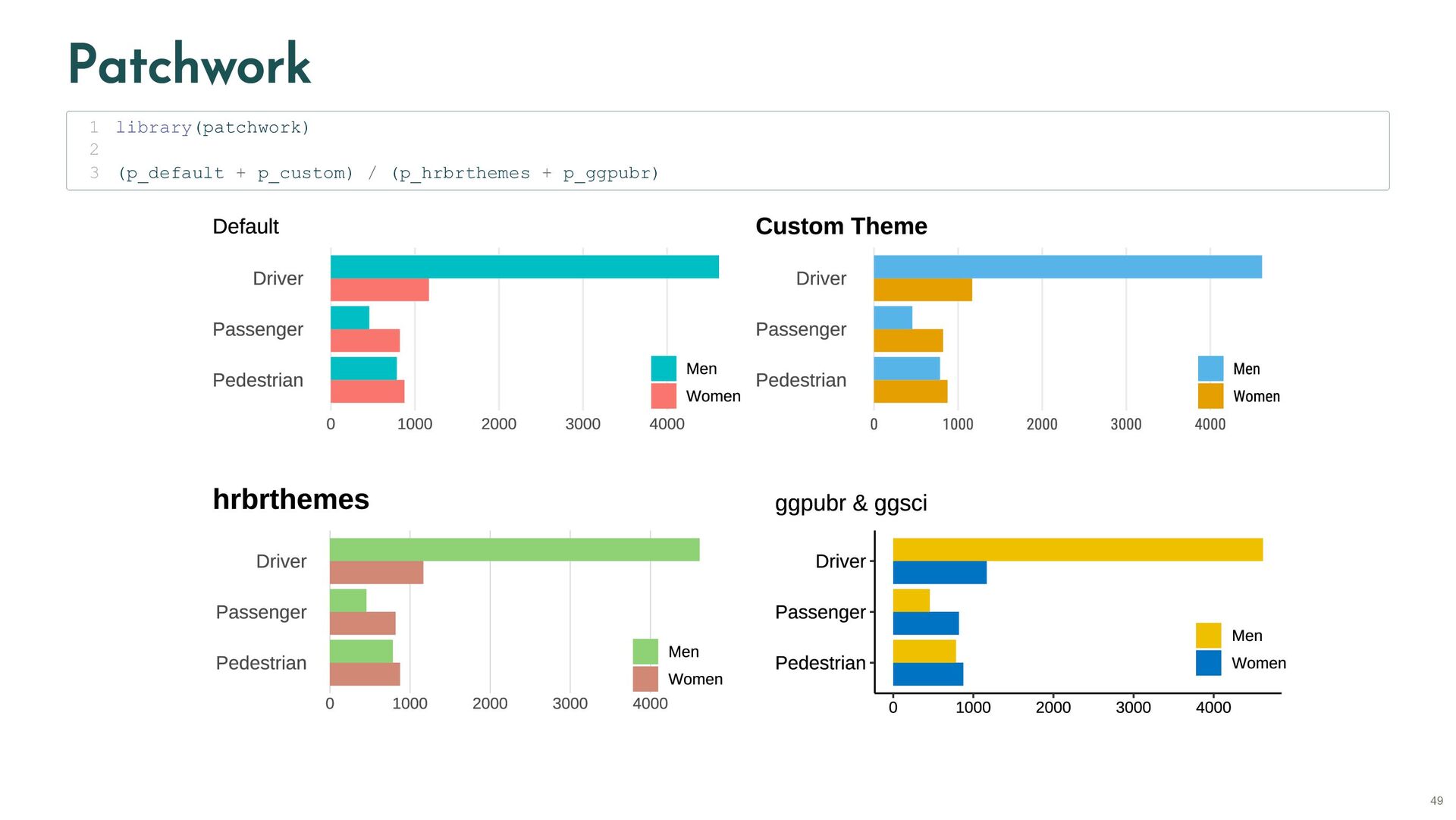{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}