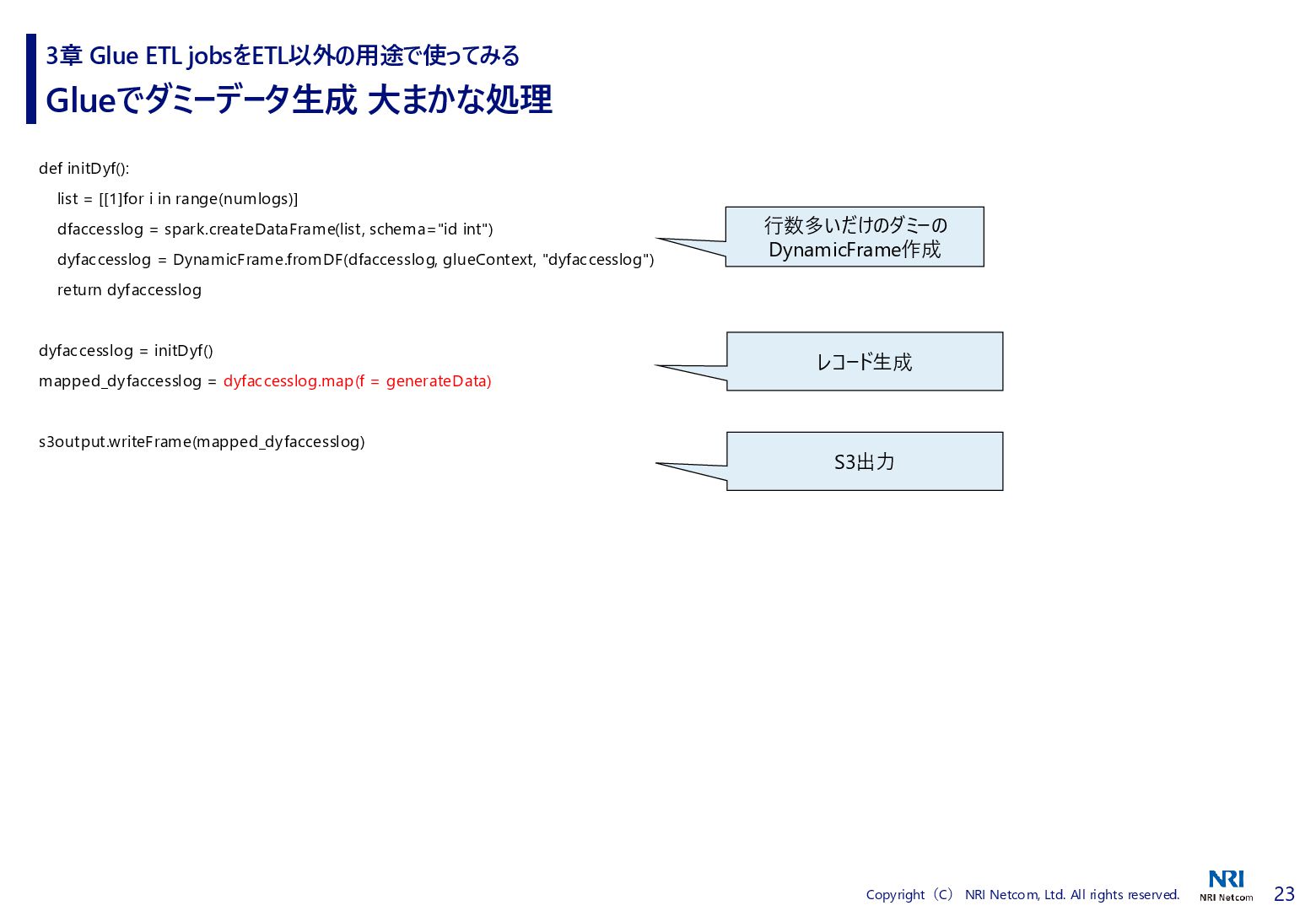
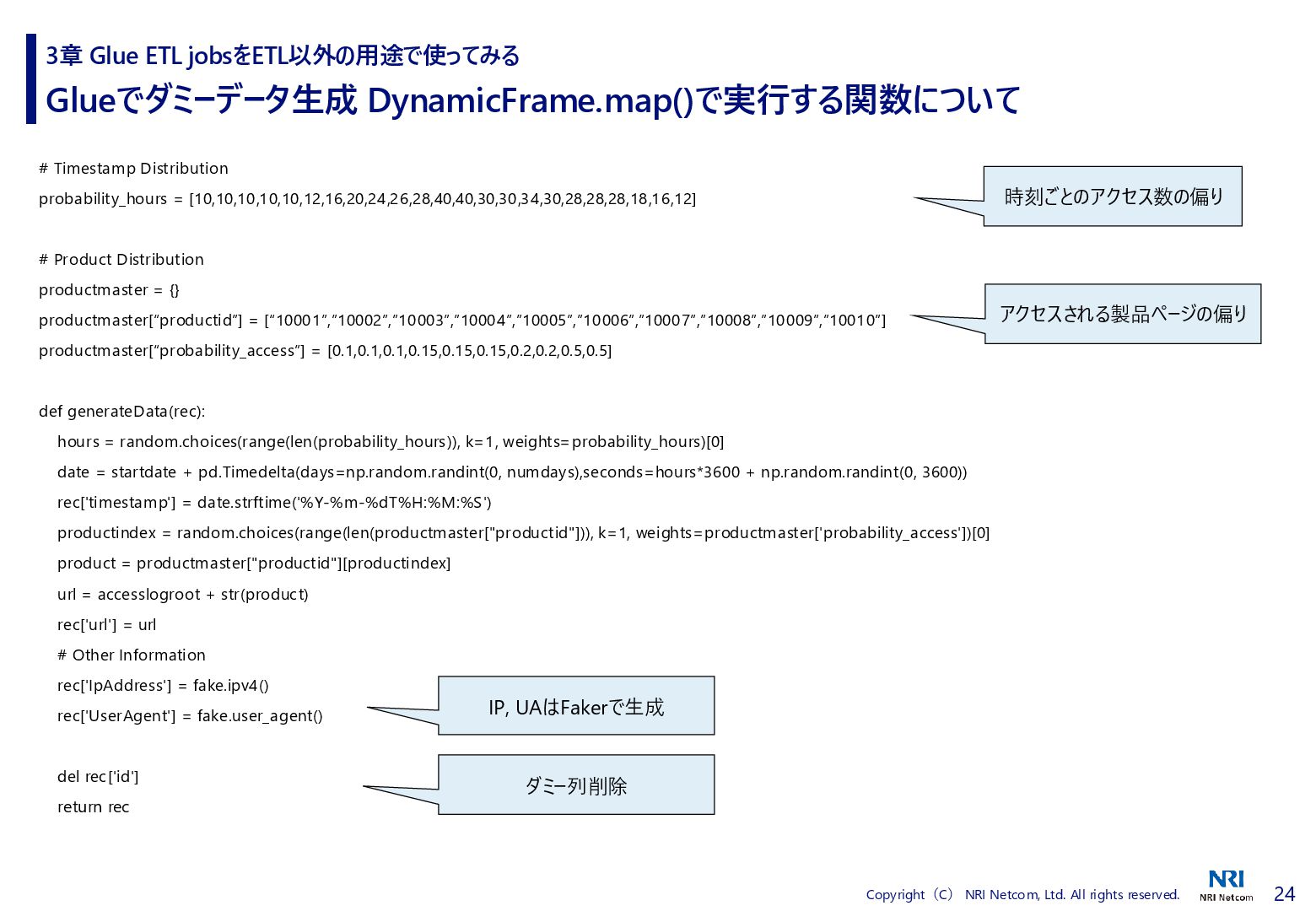
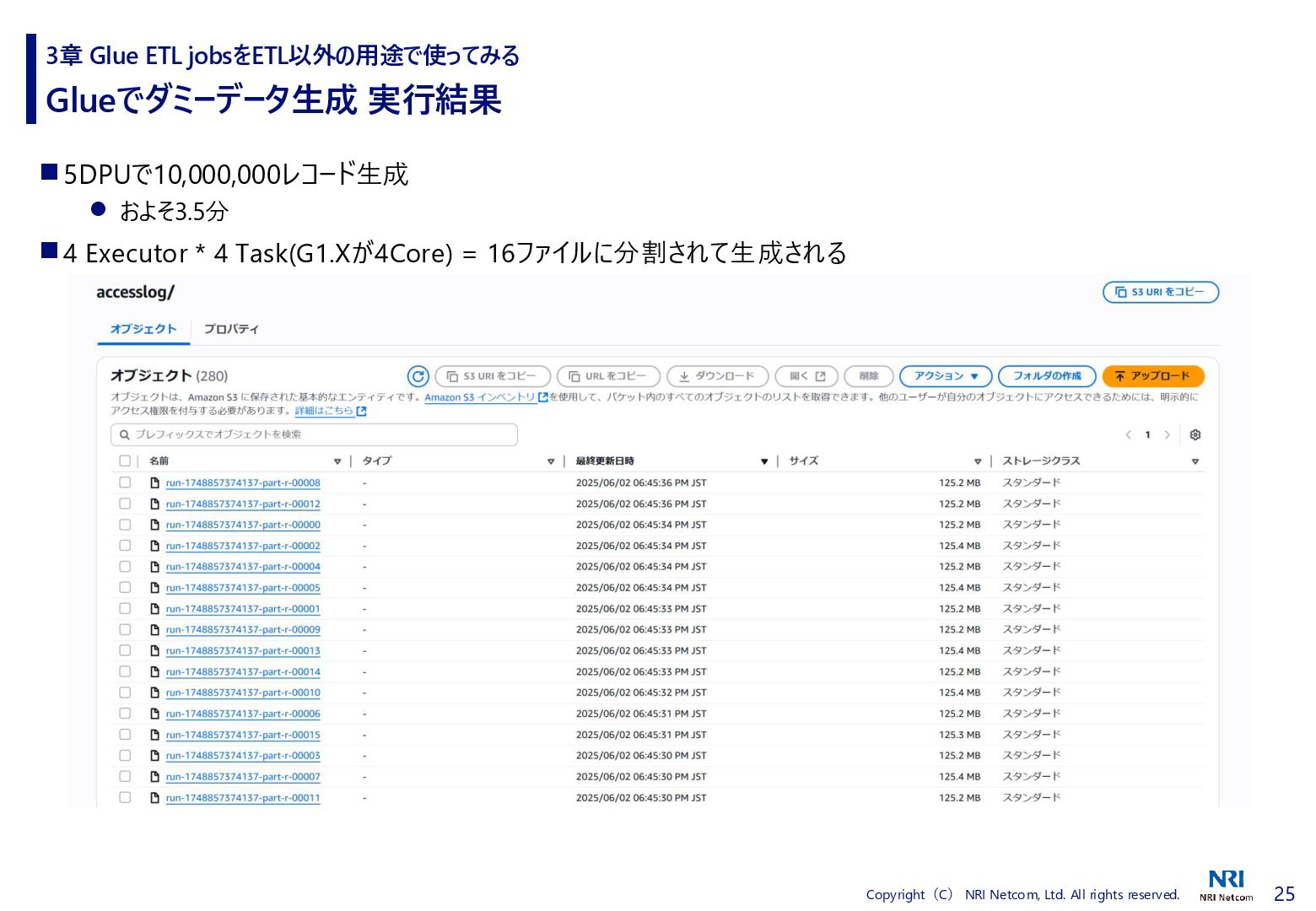
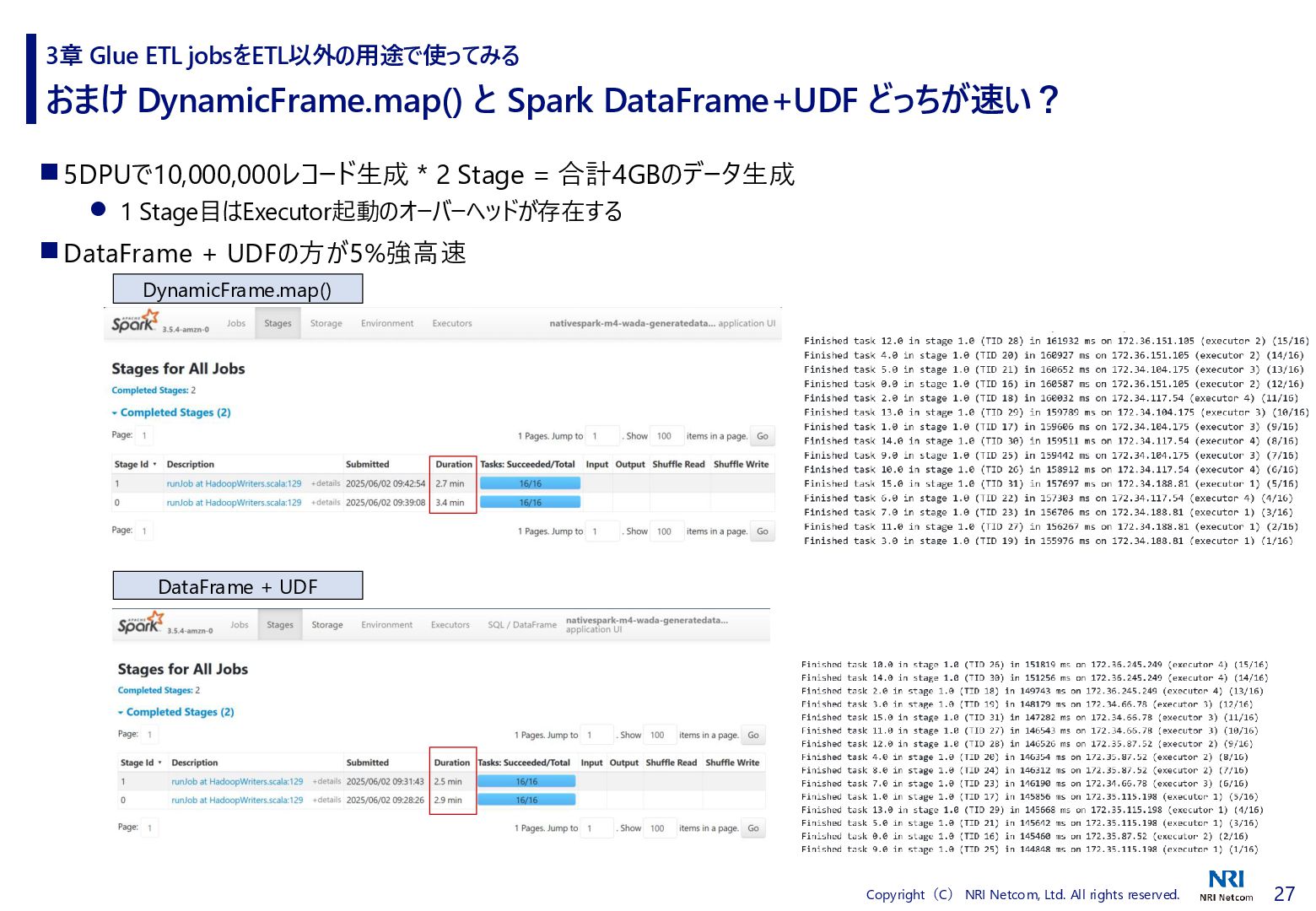
# Timestamp Distribution probability_hours = [10,10,10,10,10,12,16,20,24,26,28,40,40,30,30,34,30,28,28,28,18,16,12] # Product Distribution productmaster = {} productmaster[“productid”] = [“10001”,”10002”,”10003”,”10004”,”10005”,”10006”,”10007”,”10008”,”10009”,”10010”] productmaster[“probability_access”] = [0.1,0.1,0.1,0.15,0.15,0.15,0.2,0.2,0.5,0.5] def generateData(rec): hours = random.choices(range(len(probability_hours)), k=1, weights=probability_hours)[0] date = startdate + pd.Timedelta(days=np.random.randint(0, numdays),seconds=hours*3600 + np.random.randint(0, 3600)) rec['timestamp'] = date.strftime('%Y-%m-%dT%H:%M:%S') productindex = random.choices(range(len(productmaster["productid"])), k=1, weights=productmaster['probability_access'])[0] product = productmaster["productid"][productindex] url = accesslogroot + str(product) rec['url'] = url # Other Information rec['IpAddress'] = fake.ipv4() rec['UserAgent'] = fake.user_agent() del rec['id'] return rec 3章 Glue ETL jobsをETL以外の用途で使ってみる 時刻ごとのアクセス数の偏り アクセスされる製品ページの偏り IP, UAはFakerで生成 ダミー列削除
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}