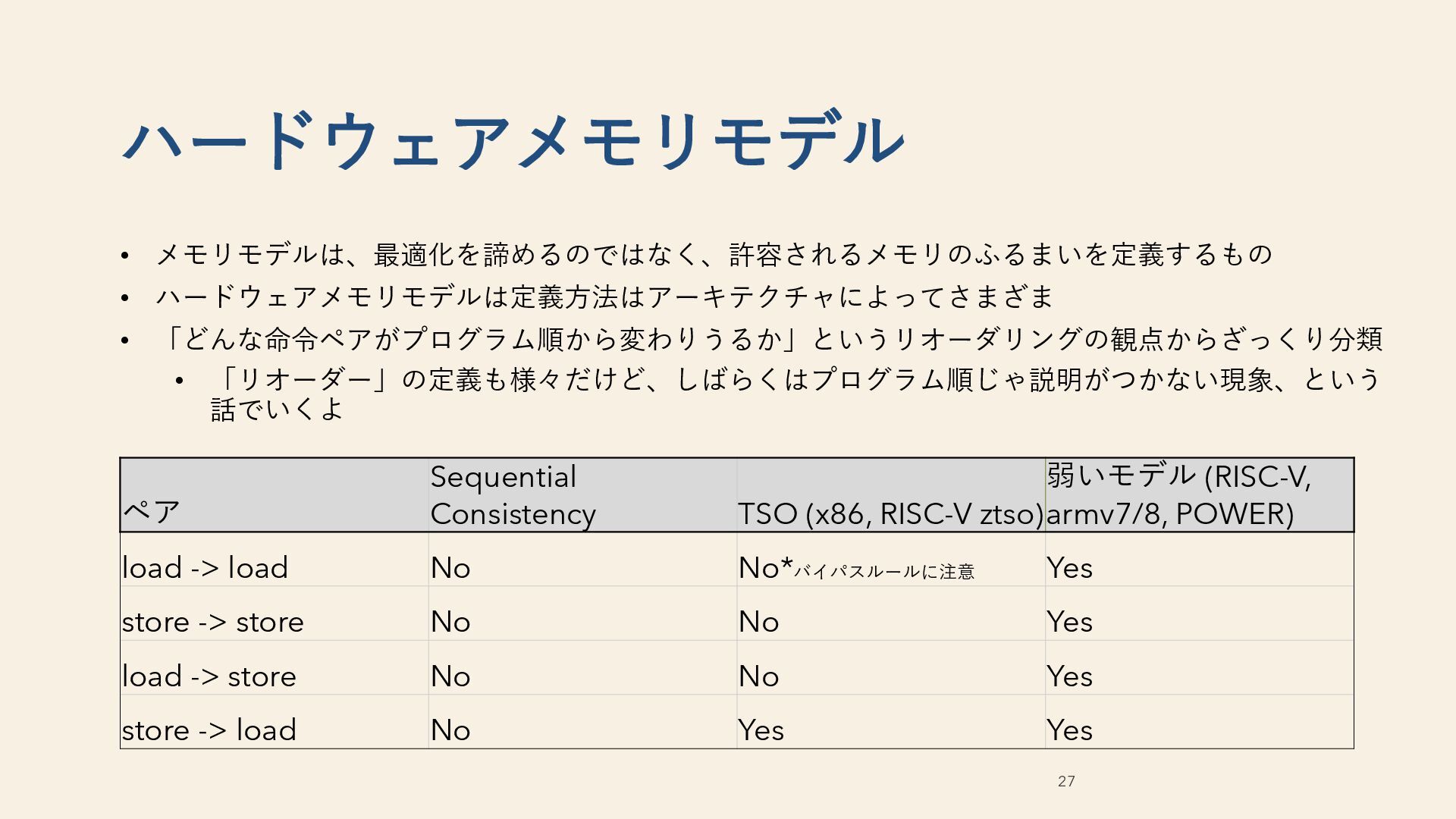
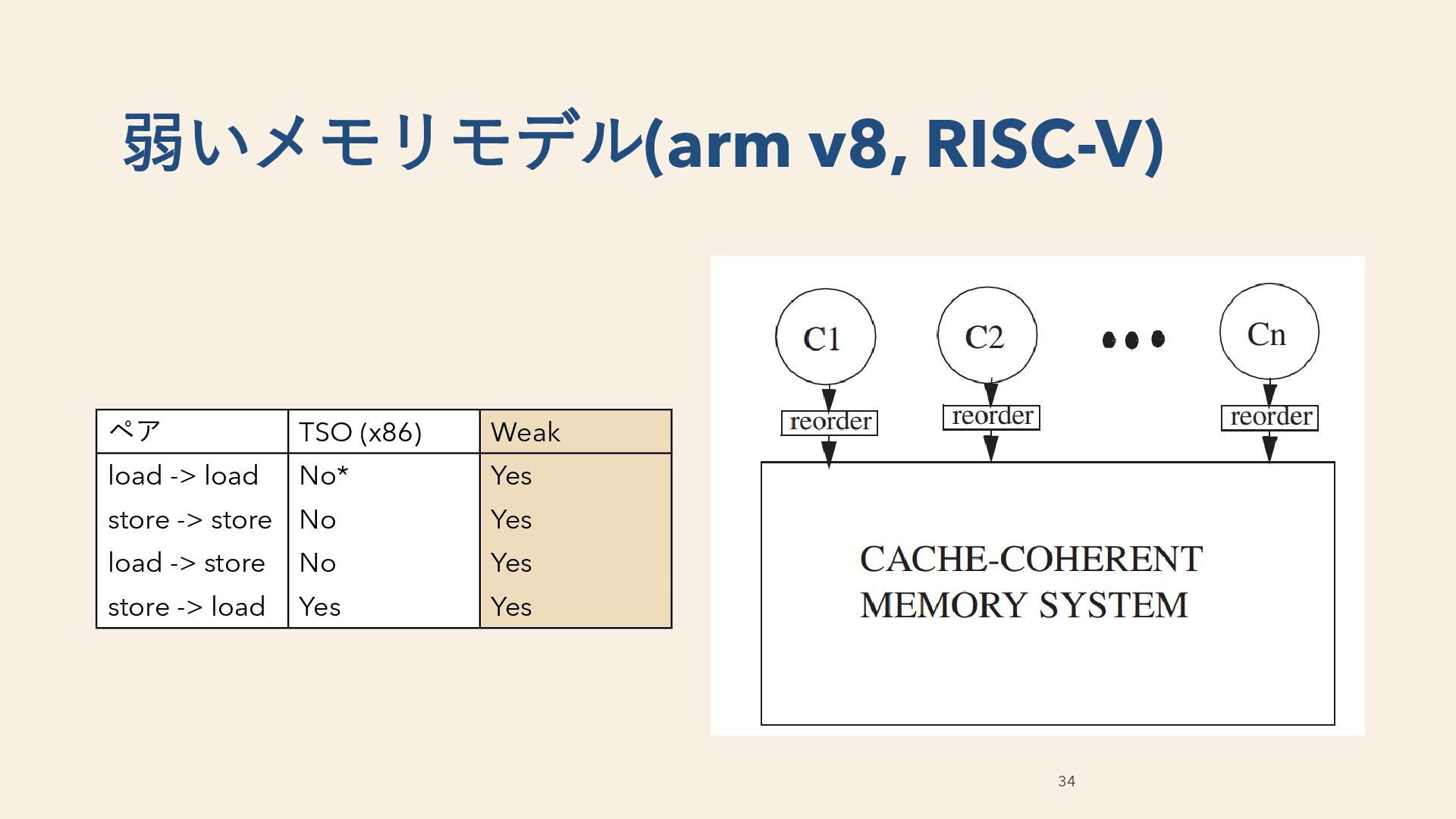
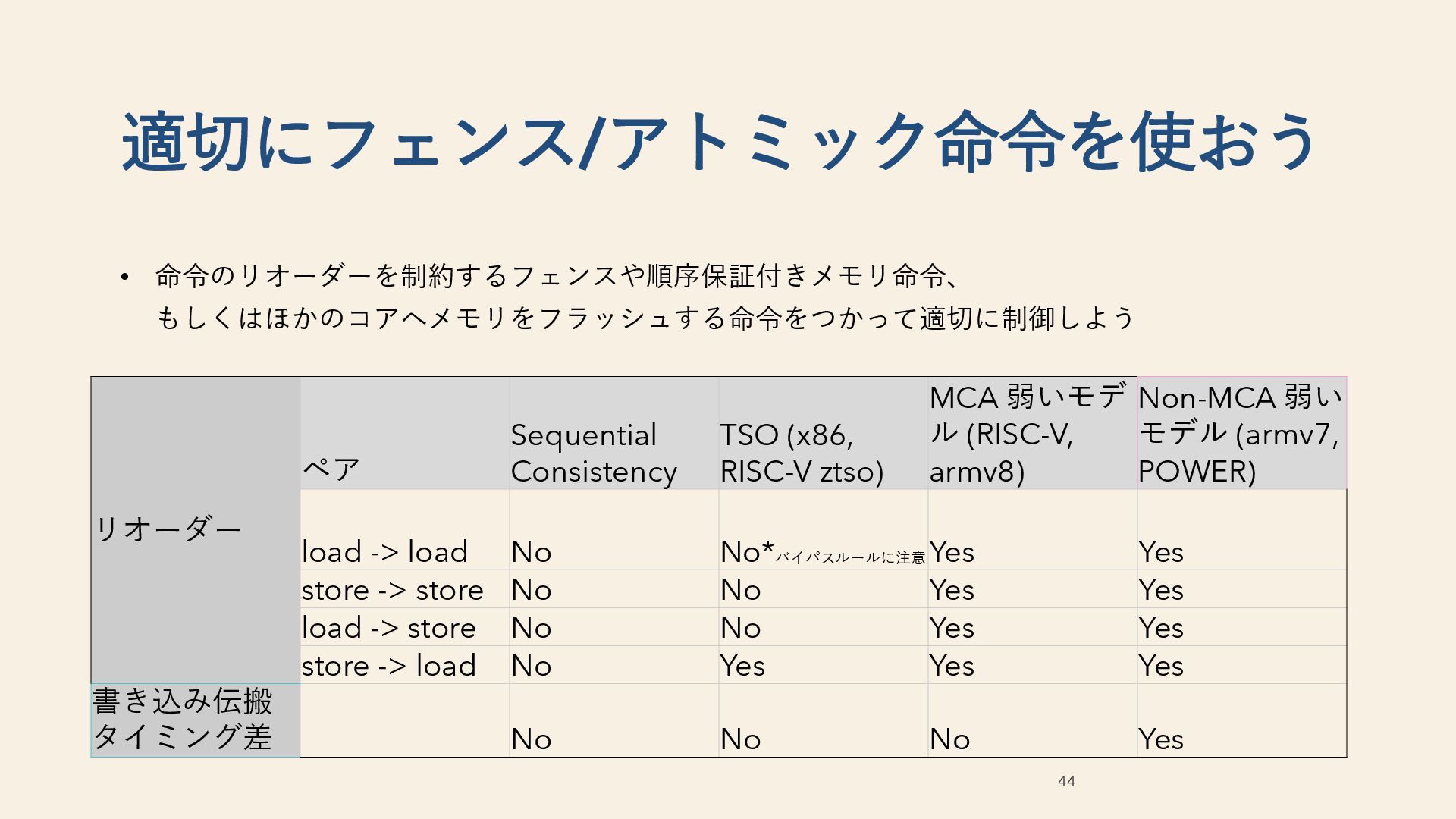
ハードウェアメモリモデル ペア Sequential Consistency TSO (x86, RISC-V ztso) 弱いモデル (RISC-V, armv7/8, POWER) load -> load No No*バイパスルールに注意 Yes store -> store No No Yes load -> store No No Yes store -> load No Yes Yes
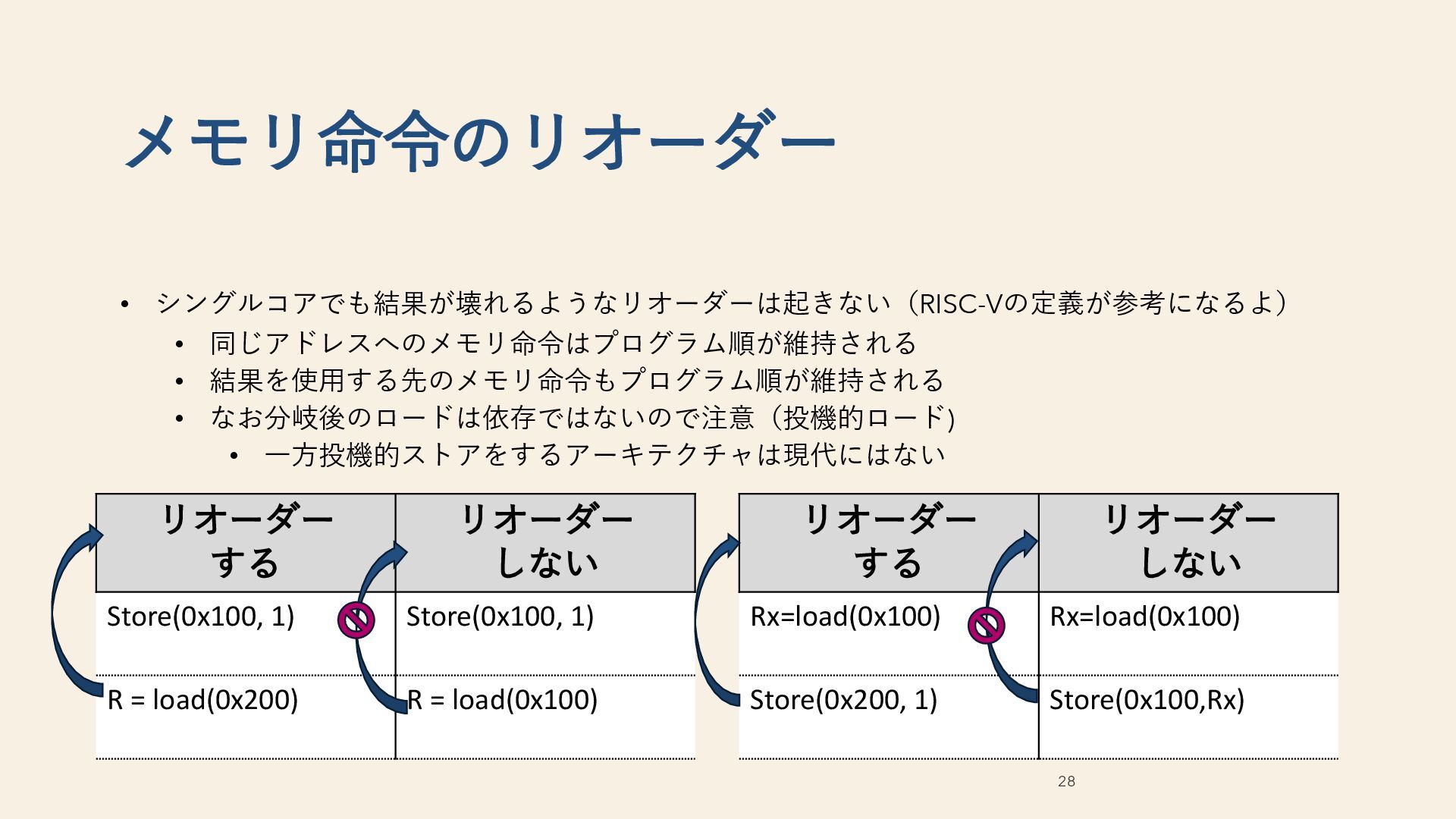
(x86, RISC-V ztso) MCA 弱いモデ ル (RISC-V, armv8) Non-MCA 弱い モデル (armv7, POWER) load -> load No No*バイパスルールに注意 Yes Yes store -> store No No Yes Yes load -> store No No Yes Yes store -> load No Yes Yes Yes 書き込み伝搬 タイミング差 No No No Yes
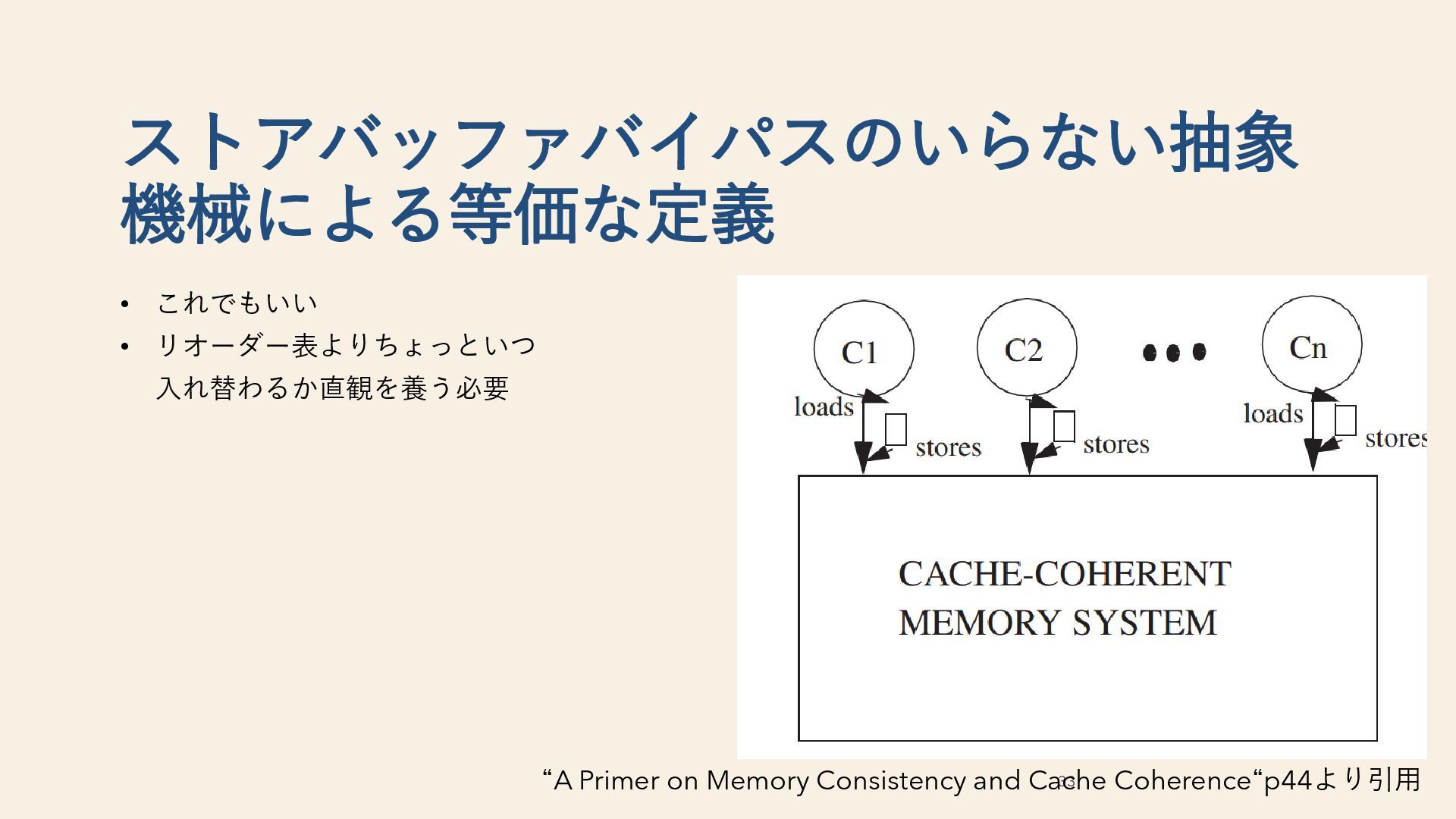
“A Primer on Memory Consistency and Cache Coherence“ • 詳細な教科書だが、Non-MCAなアーキテクチャとC++への言及がない • https://docs.kernel.org/core-api/wrappers/memory-barriers.html Linux kerenlのメモリモデルて • C++ほど抽象的ではないモデルで、具体例をもとに説明してくれる • 最近はもっとフォーマルなメモリモデルも生えたらしいけど読んでいない • Rust atomics and lock • いいらしい • C++ spec 65 参考文献
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}