AI Shift Academy(シフアカ)
サイバーエージェントグループ・株式会社AI Shiftがお届けする、AI技術の進化を読み解くAI教養ポッドキャストです。
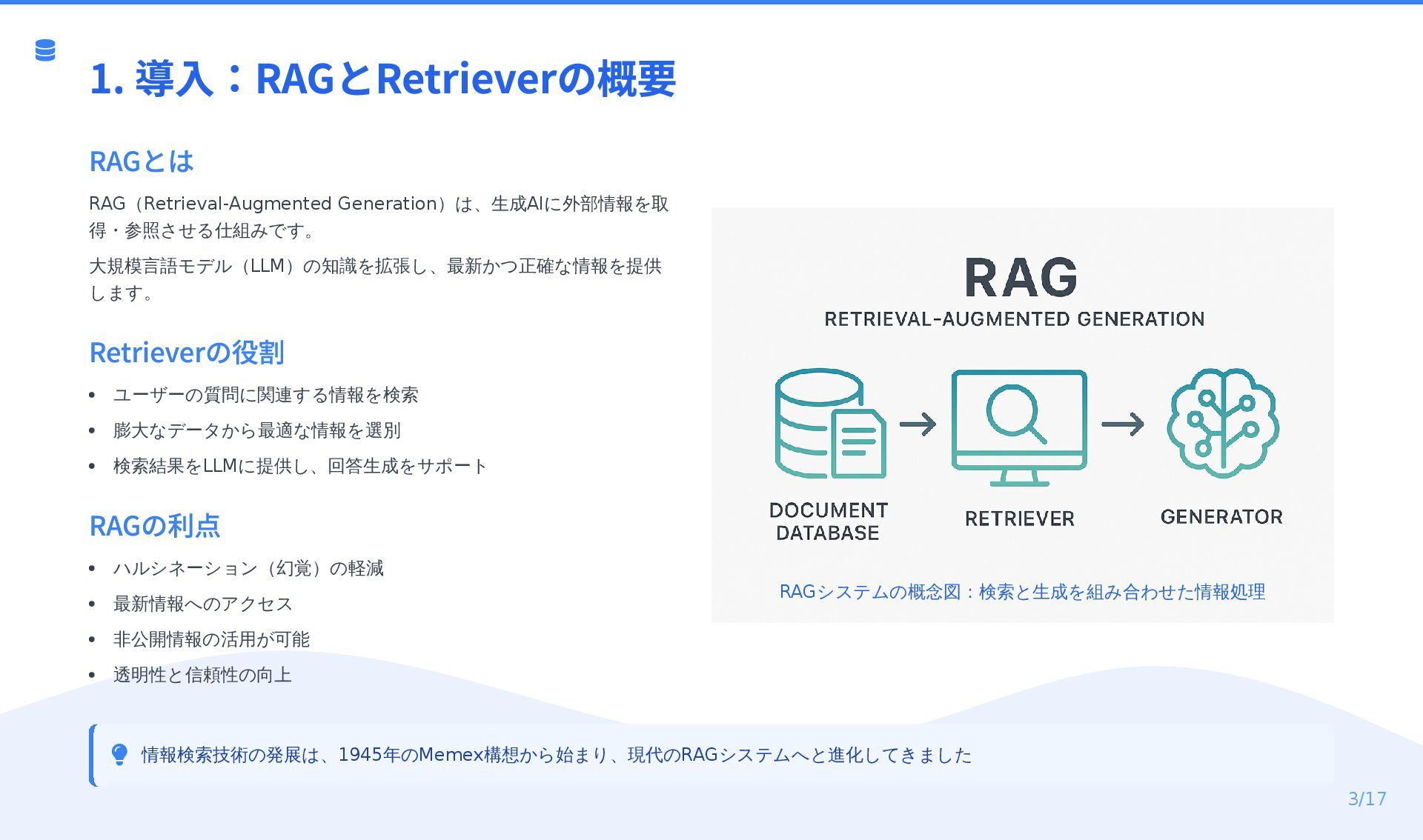
記念すべき第1弾テーマである「RAGのR」について、Gensparkを利用して内容をまとめました。
詳しくは各種配信サイトからご視聴ください。
🔴YouTube
https://www.youtube.com/channel/UCFzrc7UMBpfsMKzpSVGDaxw
🟢Spotify
https://open.spotify.com/show/5xalUSHrlVQdtp6snX9nvb?si=uOpf3V7YTxC641TwnqN5lg
🟣Apple Podcast
https://podcasts.apple.com/jp/podcast/ai-shift-academy/id1831264848
🔵Amazon Music
https://music.amazon.co.jp/podcasts/74698840-2938-47b1-82ef-84725e8c4d00/ai-shift-academy
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}