Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
decode17
Search
OZAWA Tsuyoshi
May 24, 2017
Programming
5.2k
18
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
decode17
分散並列処理の基本に関する解説と,分散並列処理のオープンソース界隈で最近起こっていることをまとめた資料です.
OZAWA Tsuyoshi
May 24, 2017
More Decks by OZAWA Tsuyoshi
See All by OZAWA Tsuyoshi
[Japanese only] Data Analysis and Data processing framework
oza
3
620
Other Decks in Programming
See All in Programming
Semantic Version 単位で戦略を柔軟に変えて、パッケージアップデートを自動化する
daitasu
1
320
Developing with AI Agents — Codex, Claude Code & Cowork Practical Guide
x5gtrn
PRO
0
1.3k
決定論的オーケストレーションの設計と実装 / Design and Implementation of Deterministic Orchestration
nrslib
4
1.5k
Skillsは効率化、Agentsは"自分の拡張"——Builder時代のエージェント編成(CC Night 2026)
wemra
1
180
Vite+ Unified Toolchain for the Web
naokihaba
0
370
LaravelLive Japan の裏方のすべて — 第188回 PHP勉強会@東京 (2026-06-24)
suguruooki
2
130
Javaの型とAI時代に型が大事な理由 / java types and type in AI era
kishida
2
150
正しくソフトウェアを作る、前提を疑うための認知の視点 / doubt-premise
minodriven
21
7.1k
ECSアプリログをFireLensでコスト削減しようとしたけど諦めた話 in Fargate×Node.js
akihisaikeda
2
4.2k
技術的負債解消で開発者の未来を開く- AIの力でコード刷新
kmd2kmd
0
120
気圧・高度・GPSを記録&可視化するアプリ「Koudo」を作った話
hjmkth
1
330
Lessons from Spec-Driven Development
simas
PRO
0
230
Featured
See All Featured
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
480
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.7k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Color Theory Basics | Prateek | Gurzu
gurzu
0
370
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
260
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
370
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
A designer walks into a library…
pauljervisheath
211
24k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
790
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
220
Into the Great Unknown - MozCon
thekraken
41
2.6k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Transcript
Copyright©2017 NTT corp. All Rights Reserved. 分散並列処理の基本と 分散並列処理系の最近の動向について 小沢健史 NTT
Software Innovation Center 2017/5/24
2 Copyright©2017 NTT corp. All Rights Reserved. •小沢 健史(Ozawa Tsuyoshi)
•Apache Hadoop Committer/PMC •Hadoop 徹底入門第2版 Chapter 22(YARN) •gihyo.jp “Hadoopはどのように動くのか” Hadoop,Tez,YARN 自己紹介
3 Copyright©2017 NTT corp. All Rights Reserved. 分析で Excel・DB を
使っている方
4 Copyright©2017 NTT corp. All Rights Reserved. •処理するデータがどんどん増える… •HDD からデータの読み込み
→ データ量に応じて時間がかかってしまう 困ったことはありませんか? 100MB 100GB 100TB 1秒 1000秒 (=約16分) 読み込みで1000000秒! (=約11日)
5 Copyright©2017 NTT corp. All Rights Reserved. •処理するデータがどんどん増える… •HDD からデータの読み込み
→ データ量に応じて時間がかかってしまう 困ったことはありませんか? 100MB 100GB 100TB 1秒 10000秒 (=1分半) 読み込みで1000000秒! (=約11日) そこで並列処理!
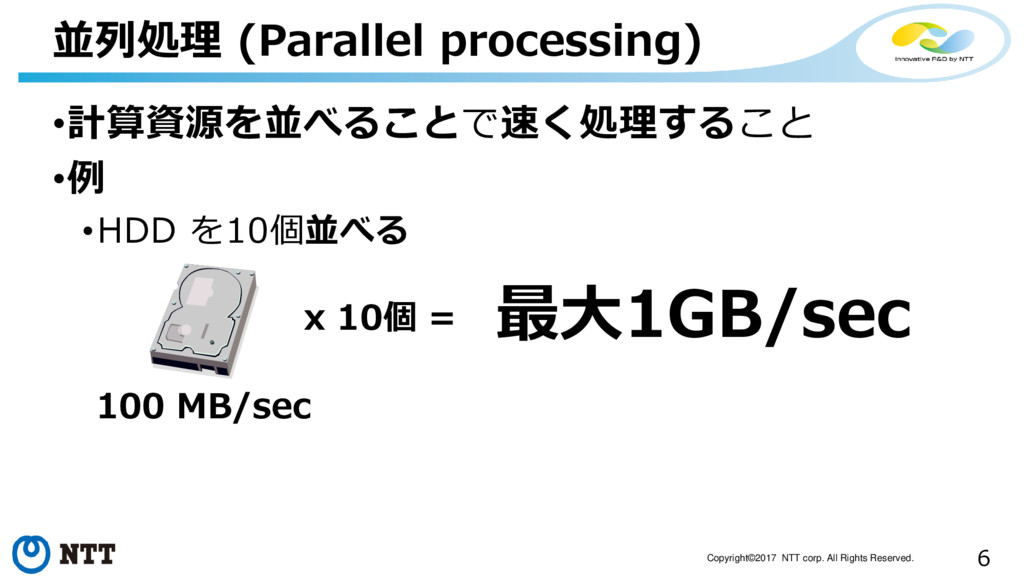
6 Copyright©2017 NTT corp. All Rights Reserved. •計算資源を並べることで速く処理すること •例 •HDD
を10個並べる 並列処理 (Parallel processing) 100 MB/sec x 10個 = 最大1GB/sec
7 Copyright©2017 NTT corp. All Rights Reserved. 並列処理の注意どころ (1) 並列処理の効果は処理依存
•ディスクI/Oの割合が 99% 99 1
8 Copyright©2017 NTT corp. All Rights Reserved. 並列処理の注意どころ (1) 並列処理の効果は処理依存
•ディスクI/Oの割合が 99% 99 1 1 1 99倍 効果:50倍
9 Copyright©2017 NTT corp. All Rights Reserved. 並列処理の注意どころ (1) 並列処理の効果は処理依存
•ディスクI/Oの割合が 99% 99 1 1 1 効果:50倍 99倍 •ディスクI/Oの割合が 50% 50 50 0.5 99倍 50
10 Copyright©2017 NTT corp. All Rights Reserved. 並列処理の注意どころ (1) 並列処理の効果は処理依存
•ディスクI/Oの割合が 99% 99 1 1 1 99倍 •ディスクI/Oの割合が 50% 50 50 0.5 効果:約2倍 99倍 50 効果:50倍
11 Copyright©2017 NTT corp. All Rights Reserved. 並列処理の注意どころ (2) 拡張性の限界
•値段的限界 L4 L8 L16 L32 $0.5 $1 $2 $4 https://azure.microsoft.com/en- us/pricing/details/virtual-machines/windows/
12 Copyright©2017 NTT corp. All Rights Reserved. 並列処理の注意どころ (2) 拡張性の限界
•値段的限界 •物理的限界 一台の計算機に足せる ドライブ数に限界 L4 L8 L16 L32 $0.5 $1 $2 $4 https://azure.microsoft.com/en- us/pricing/details/virtual-machines/windows/
13 Copyright©2017 NTT corp. All Rights Reserved. •故障確率が向上 •1日に1%の確率で1つのHDDが壊れると仮定 •64個ドライブのある計算機の場合,
1日に1つ以上ドライブが壊れる確率は 約48%=1 – (0.99 ** 64) 並列処理の注意どころ (3)
14 Copyright©2017 NTT corp. All Rights Reserved. •性能向上率はワークロード次第 •拡張性に限界 •故障確率が向上
並列処理の注意どころ まとめ
15 Copyright©2017 NTT corp. All Rights Reserved. •性能向上率はワークロード次第 •拡張性に限界 •故障確率が向上
並列処理の注意どころ まとめ 並列処理の特性
16 Copyright©2017 NTT corp. All Rights Reserved. •性能向上率はワークロード次第 •拡張性に限界 •故障確率が向上
並列処理の注意どころ まとめ
17 Copyright©2017 NTT corp. All Rights Reserved. •性能向上率はワークロード次第 •拡張性に限界 •故障確率が向上
並列処理の注意どころ まとめ そこで分散処理!
18 Copyright©2017 NTT corp. All Rights Reserved. •複数の計算機をまたがって処理すること •目的は処理の高速化に限らない 分散処理
(Distributed processing)
19 Copyright©2017 NTT corp. All Rights Reserved. •複数の計算機をまたがって処理すること •目的は処理の高速化に限らない •例
•異なる計算機2台に同じ計算をさせる → 故障しなかった方を採用 分散処理 (Distributed processing) 計算機1 計算機2 依頼主 投入
20 Copyright©2017 NTT corp. All Rights Reserved. •複数の計算機をまたがって処理すること •目的は処理の高速化に限らない •例
•異なる計算機2台に同じ計算をさせる → 故障しなかった方を採用 分散処理 (Distributed processing) 計算機1 計算機2 故障 依頼主
21 Copyright©2017 NTT corp. All Rights Reserved. •複数の計算機をまたがって処理すること •目的は処理の高速化に限らない •例
•異なる計算機2台に同じ計算をさせる → 故障しなかった方を採用 分散処理 (Distributed processing) 計算機1 計算機2 無事回答! 依頼主
22 Copyright©2017 NTT corp. All Rights Reserved. •データのコピーを複数持つ •目的 •データへアクセスできる確率を向上させるため
•処理が無事に終わる確率を向上させるため 分散処理でよく行われること
23 Copyright©2017 NTT corp. All Rights Reserved. •データのコピーを複数持つ •目的 •データへアクセスできる確率を向上させるため
•処理が無事に終わる確率を向上させるため 分散処理でよく行われること 計算機1 計算機2 書き手 保存しといて データ
24 Copyright©2017 NTT corp. All Rights Reserved. •データのコピーを複数持つ •目的 •データへアクセスできる確率を向上させるため
•処理が無事に終わる確率を向上させるため 分散処理でよく行われること 計算機1 計算機2 書き手 コピー データ データ
25 Copyright©2017 NTT corp. All Rights Reserved. •データのコピーを複数持つ •目的 •データへアクセスできる確率を向上させるため
•処理が無事に終わる確率を向上させるため 分散処理でよく行われること 計算機1 計算機2 データ データ
26 Copyright©2017 NTT corp. All Rights Reserved. •データのコピーを複数持つ •目的 •データへアクセスできる確率を向上させるため
•処理が無事に終わる確率を向上させるため 分散処理でよく行われること 計算機1 計算機2 データ データ 故障
27 Copyright©2017 NTT corp. All Rights Reserved. •データのコピーを複数持つ •目的 •データへアクセスできる確率を向上させるため
•処理が無事に終わる確率を向上させるため 分散処理でよく行われること 計算機1 計算機2 データ データ 読み手 読みたい
28 Copyright©2017 NTT corp. All Rights Reserved. •データのコピーを複数持つ •目的 •データへアクセスできる確率を向上させるため
•処理が無事に終わる確率を向上させるため 分散処理でよく行われること 計算機1 計算機2 データ データ 読み手 成功! データ
29 Copyright©2017 NTT corp. All Rights Reserved. 分散処理の注意どころ (1) 分散のためにオーバヘッドが発生
•1台にコピー •2台にコピー 通信量増大 書き手 計算機 書き手 計算機1 計算機2
30 Copyright©2017 NTT corp. All Rights Reserved. •故障時のエラーハンドリング 分散処理の注意どころ (2)
書き手 計算機1 計算機2 データ
31 Copyright©2017 NTT corp. All Rights Reserved. •故障時のエラーハンドリング 分散処理の注意どころ (2)
書き手 計算機1 計算機2 データ 書込要求
32 Copyright©2017 NTT corp. All Rights Reserved. •故障時のエラーハンドリング 分散処理の注意どころ (2)
書き手 計算機1 計算機2 データ 書込応答 応答なし
33 Copyright©2017 NTT corp. All Rights Reserved. •故障時のエラーハンドリング 分散処理の注意どころ (2)
書き手 計算機1 計算機2 データ 過負荷で 書き込みに失敗
34 Copyright©2017 NTT corp. All Rights Reserved. •故障時のエラーハンドリング 分散処理の注意どころ (2)
計算機1 計算機2 データ
35 Copyright©2017 NTT corp. All Rights Reserved. •故障時のエラーハンドリング 分散処理の注意どころ (2)
計算機1 計算機2 データ 読み手
36 Copyright©2017 NTT corp. All Rights Reserved. •故障時のエラーハンドリング 分散処理の注意どころ (2)
計算機1 計算機2 データ 読み手 過負荷で アクセスできず 読込要求
37 Copyright©2017 NTT corp. All Rights Reserved. •故障時のエラーハンドリング 分散処理の注意どころ (2)
計算機1 計算機2 データ 読み手 過負荷で アクセスできず データがないように 見える!
38 Copyright©2017 NTT corp. All Rights Reserved. •故障時のエラーハンドリング 分散処理の注意どころ (2)
計算機1 計算機2 データ 読み手 過負荷で アクセスできず データがないように 見える! 自分でケアするのは大変
39 Copyright©2017 NTT corp. All Rights Reserved. •故障時のエラーハンドリング 分散処理の注意どころ (2)
計算機1 計算機2 データ 読み手 過負荷で アクセスできず データがないように 見える! とても大変!
40 Copyright©2017 NTT corp. All Rights Reserved. •故障時のエラーハンドリング 分散処理の注意どころ (2)
計算機1 計算機2 データ 読み手 過負荷で アクセスできず データがないように 見える! そこで 並列分散処理 基盤
41 Copyright©2017 NTT corp. All Rights Reserved. 並列処理と分散処理を組み合わせた処理基盤 → 高速に,故障を意識せずに使える!
並列分散処理基盤
42 Copyright©2017 NTT corp. All Rights Reserved. •データを溜めるファイルシステム データを処理する処理系 •Spark/MapReduce
+ HDFS など •データベース •SQL Server・Amazon Redshift など 最近の並列分散処理基盤 の組み合わせ
43 Copyright©2017 NTT corp. All Rights Reserved. なぜFSとDBは分かれているか?
44 Copyright©2017 NTT corp. All Rights Reserved. なぜFSとDBは分かれているか? 大量のデータを永続的に格納する手段としては,(中略) OS
により提供されるファイルがある. しかし,ファイルシステムには(中略)問題点があり,こ れらがデータベースの開発の動機となっている. データベースシステム・北川博之著 p.2-p.3 より抜粋
45 Copyright©2017 NTT corp. All Rights Reserved. なぜFSとDBは分かれているか? 大量のデータを永続的に格納する手段としては,(中略) OS
により提供されるファイルがある. しかし,ファイルシステムには(中略)問題点があり,こ れらがデータベースの開発の動機となっている. データベースシステム・北川博之著 p.2-p.3 より抜粋 思想から異なる
Copyright©2017 NTT corp. All Rights Reserved. ファイルシステムベース の並列分散処理基盤
47 Copyright©2017 NTT corp. All Rights Reserved. •処理系を柔軟に変更可能 ファイルシステムベースの処理系の利点 ファイルシステム
処理系1 処理系2
48 Copyright©2017 NTT corp. All Rights Reserved. •処理系を柔軟に変更可能 Hadoop エコシステムで起きていること
FileSystem API Spark HDFS MapReduce
49 Copyright©2017 NTT corp. All Rights Reserved. •処理系を柔軟に変更可能 Hadoop エコシステムで起きていること
FileSystem API Spark HDFS MapReduce
50 Copyright©2017 NTT corp. All Rights Reserved. •処理系を柔軟に変更可能 Hadoop エコシステムで起きていること
FileSystem API Spark HDFS MapReduce Azure Data Lake Store Amazon S3
51 Copyright©2017 NTT corp. All Rights Reserved. •処理系を柔軟に変更可能 •ファイルシステムの実装が変更可能に →
クラウドとの相性良い Hadoop エコシステムで起きていること FileSystem API Spark HDFS MapReduce Azure Data Lake Store Amazon S3
52 Copyright©2017 NTT corp. All Rights Reserved. •処理系とファイルシステムが疎結合 →最適化度合いが限定的 ファイルシステムベースの処理系の欠点
FileSystem API Spark HDFS MapReduce Azure Data Lake Store Amazon S3
53 Copyright©2017 NTT corp. All Rights Reserved. •処理系とファイルシステムが疎結合 →最適化度合いが限定的 ファイルシステムベースの処理系の欠点
FileSystem API Spark HDFS MapReduce Azure Data Lake Store Amazon S3
54 Copyright©2017 NTT corp. All Rights Reserved. •処理系とファイルシステムが疎結合 →最適化度合いが限定的 ファイルシステムベースの処理系の欠点
FileSystem API Spark HDFS MapReduce Azure Data Lake Store Amazon S3 最適化のために やりとりできる 情報が 限られる
Copyright©2017 NTT corp. All Rights Reserved. 代表的な処理系 MapReduce と Spark
56 Copyright©2017 NTT corp. All Rights Reserved. •データを分散ファイルシステムから読む MapReduce FileSystem
API HDFS MapReduce Azure Data Lake Store Amazon S3 読出
57 Copyright©2017 NTT corp. All Rights Reserved. •データを分散ファイルシステムから読む •ユーザが指定した処理をする MapReduce
FileSystem API HDFS MapReduce Azure Data Lake Store Amazon S3 処理
58 Copyright©2017 NTT corp. All Rights Reserved. •データを分散ファイルシステムから読む •ユーザが指定した処理をする •分散ファイルシステムに結果を書き出し
MapReduce FileSystem API HDFS MapReduce Azure Data Lake Store Amazon S3 書出
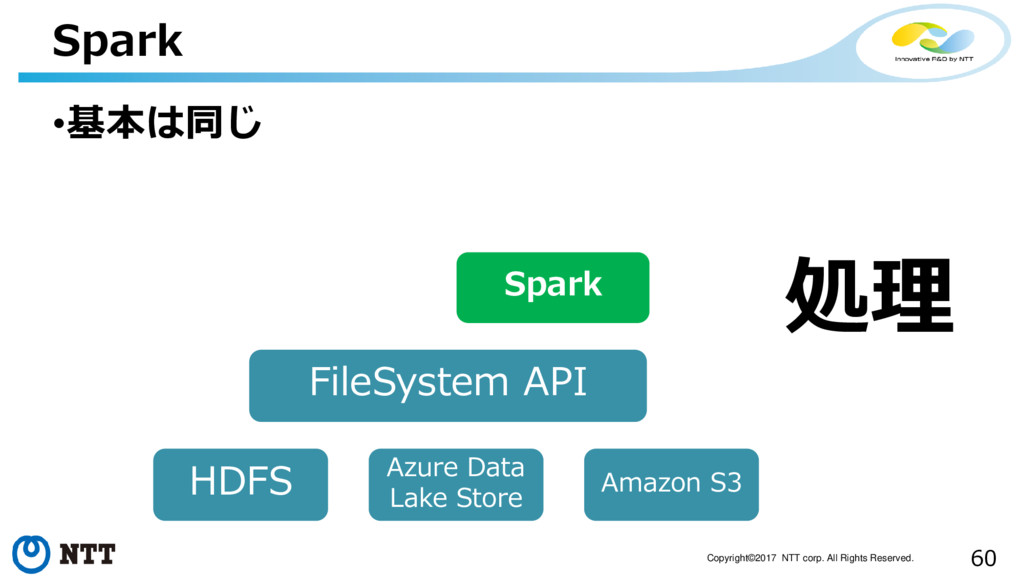
59 Copyright©2017 NTT corp. All Rights Reserved. •基本は同じ Spark FileSystem
API HDFS Azure Data Lake Store Amazon S3 Spark 読出
60 Copyright©2017 NTT corp. All Rights Reserved. •基本は同じ Spark FileSystem
API HDFS Azure Data Lake Store Amazon S3 Spark 処理
61 Copyright©2017 NTT corp. All Rights Reserved. •基本は同じ •毎回も書き出さずに,Spark の世界の中で
最適化されたデータ形式で保持が可能 Spark FileSystem API HDFS Azure Data Lake Store Amazon S3 Spark 結果 保持
62 Copyright©2017 NTT corp. All Rights Reserved. •基本は同じ •毎回も書き出さずに,Spark の世界の中で
最適化されたデータ形式で保持が可能 •最終的には書出 Spark FileSystem API HDFS Azure Data Lake Store Amazon S3 Spark 書出
Copyright©2017 NTT corp. All Rights Reserved. データベース
64 Copyright©2017 NTT corp. All Rights Reserved. •データ処理とデータ保持部が密結合 データベース 保持部
処理部 データベース
65 Copyright©2017 NTT corp. All Rights Reserved. •密結合により,最適化がしやすい •プログラミングしやすい特性(ACID)をもつ データベースの利点
保持部 処理部 データベース
66 Copyright©2017 NTT corp. All Rights Reserved. •スキーマ(型情報)を予め定義し、それを 並列処理のヒント情報として利用 •分析用DBの場合、列数がかなり多い傾向(30以上)
分析用データベースの概要
67 Copyright©2017 NTT corp. All Rights Reserved. •スキーマ(型情報)を予め定義し、それを 並列処理のヒント情報として利用 •分析用DBの場合、列数がかなり多い傾向(30以上)
→列方向にデータを分割 必要な列のみにアクセス 分析用データベースの概要
68 Copyright©2017 NTT corp. All Rights Reserved. •スキーマ(型情報)を予め定義し、それを 並列処理のヒント情報として利用 •分析用DBの場合、列数がかなり多い傾向(30以上)
→列方向にデータを分割 必要な列のみにアクセス 分析用データベースの概要 userId username project … 1 Tsuyoshi Hadoop … 2 Neo Azure … … … … …
69 Copyright©2017 NTT corp. All Rights Reserved. •スキーマ(型情報)を予め定義し、それを 並列処理のヒント情報として利用 •分析用DBの場合、列数がかなり多い傾向(30以上)
→列方向にデータを分割 必要な列のみにアクセス 分析用データベースの概要 userId username project … 1 Tsuyoshi Hadoop … 2 Neo Azure … … … … … 計算機1
70 Copyright©2017 NTT corp. All Rights Reserved. •スキーマ(型情報)を予め定義し、それを 並列処理のヒント情報として利用 •分析用DBの場合、列数がかなり多い傾向(30以上)
→列方向にデータを分割 必要な列のみにアクセス 分析用データベースの概要 userId username project … 1 Tsuyoshi Hadoop … 2 Neo Azure … … … … … 計算機1 計算機2
71 Copyright©2017 NTT corp. All Rights Reserved. •スキーマ変更をする際にはシステムが しばらく停止しうる →
データの移動を伴うため 分析用データベースの注意どころ
72 Copyright©2017 NTT corp. All Rights Reserved. •スキーマが激しく変化する •クエリの変化が激しい →
MapReduce や Spark など ファイルシステムベースの処理系 •スキーマ変化がまれ •性能要求が非常に高い •クエリがある程度決まっている → データベース FSベース処理系/データベースの使い分け
73 Copyright©2017 NTT corp. All Rights Reserved. •NTT DATA の例
MapReduce/データベースの使い分け 秒 分 時間 日 Big Data Processing 応 答 時 間 Size Online Processing GB TB PB Online Batch Processing データ ベース 分析データベース Hadoop/ Spark Query & Search Processing Enterprise Batch Processing
Copyright©2017 NTT corp. All Rights Reserved. 最近の動向
75 Copyright©2017 NTT corp. All Rights Reserved. •処理速度に対する要求の多様化 •ミドルウェアの増加からくるデータ同期の複雑化 最近の動向
: Hadoop への不満からくる改善
76 Copyright©2017 NTT corp. All Rights Reserved. •処理速度に対する要求の多様化 →特化した処理系が出てきた •ミドルウェアの増加からくるデータ同期の複雑化
→ ハブを担うミドルウェアが出てきた 最近の動向 : Hadoop への不満からくる改善
77 Copyright©2017 NTT corp. All Rights Reserved. •超巨大なバッチ処理が「安定して動けば良い」 処理速度に対する要求の多様化
78 Copyright©2017 NTT corp. All Rights Reserved. •超巨大なバッチ処理が「安定して動けば良い」 → もっと色々やりたい!
処理速度に対する要求の多様化
79 Copyright©2017 NTT corp. All Rights Reserved. •速く結果を受け取って,試行錯誤やアクションの 回数を増やしたい 処理速度に対する要求の多様化
インタラクティブ クエリ系 • Apache Impala • Presto • Hive(LLAP)
80 Copyright©2017 NTT corp. All Rights Reserved. •深層学習を高速に動作させたい 処理速度に対する要求の多様化 インタラクティブ
クエリ系 • Apache Impala • Presto • Hive(LLAP) 深層学習特化 • TensorFlow • MXNet • CNTK • Chainer
81 Copyright©2017 NTT corp. All Rights Reserved. •バッチではなく,ストリーミング処理を 高速に動作させたい 処理速度に対する要求の多様化
インタラクティブ クエリ系 • Apache Impala • Presto • Hive(LLAP) 深層学習特化 • TensorFlow • MXNet • CNTK • Chainer ストリーミング 処理系 • Apache Storm • Spark Streaming
82 Copyright©2017 NTT corp. All Rights Reserved. •ワークロードによる使い分けが普通に 処理速度に対する要求の多様化 インタラクティブ
クエリ系 • Apache Impala • Presto • Hive(LLAP) 深層学習特化 • TensorFlow • MXNet • CNTK • Chainer ストリーミング 処理系 • Apache Storm • Spark Streaming
83 Copyright©2017 NTT corp. All Rights Reserved. •ワークロードによる使い分けが普通に 処理速度に対する要求の多様化 インタラクティブ
クエリ系 • Apache Impala • Presto • Hive(LLAP) 深層学習特化 • TensorFlow • MXNet • CNTK ストリーミング 処理系 • Apache Storm • Spark Streaming データ同期が 大変に…
84 Copyright©2017 NTT corp. All Rights Reserved. •実際の運用の中で,処理系やサービスの間で データの同期を複雑に行う必要 ミドルウェアの増加に伴う同期複雑化
推薦エンジン 分析DB Hadoop 検索エンジン
85 Copyright©2017 NTT corp. All Rights Reserved. •実際の運用の中で,処理系やサービスの間で データの同期を複雑に行う必要 ミドルウェアの増加に伴う同期複雑化
推薦エンジン 分析DB Hadoop メール通知
86 Copyright©2017 NTT corp. All Rights Reserved. •実際の運用の中で,処理系やサービスの間で データの同期を複雑に行う必要 ミドルウェアの増加に伴う同期複雑化
推薦エンジン 分析DB Hadoop メール通知 そこで Apache Kafka
87 Copyright©2017 NTT corp. All Rights Reserved. •データの「ハブ」の役割 •分散並列の特性を上手く利用し ボトルネックにならないよう設計されている
Apache Kafka 推薦エンジン 分析DB Hadoop メール通知 Apache Kafka
88 Copyright©2017 NTT corp. All Rights Reserved. •並列処理 •分散処理 •MapReduce系統の処理の特徴
•データベースの特徴 •最近の動向 まとめ
89 Copyright©2017 NTT corp. All Rights Reserved. •並列処理 •分散処理 •MapReduce系統の処理の特徴
•データベースの特徴 •最近の動向 まとめ
90 Copyright©2017 NTT corp. All Rights Reserved. •並列処理 •分散処理 •MapReduce系統の処理の特徴
•データベースの特徴 •最近の動向 まとめ さいごに
91 Copyright©2017 NTT corp. All Rights Reserved. •並列処理 •分散処理 •MapReduce系統の処理の特徴
•データベースの特徴 •最近の動向 まとめ 分散並列処理が身近に なってきた
92 Copyright©2017 NTT corp. All Rights Reserved. •並列処理 •分散処理 •MapReduce系統の処理の特徴
•データベースの特徴 •最近の動向 まとめ 何が何でも 分散処理?
93 Copyright©2017 NTT corp. All Rights Reserved. •並列処理 •分散処理 •MapReduce系統の処理の特徴
•データベースの特徴 •最近の動向 まとめ 何が何でも 分散処理?
94 Copyright©2017 NTT corp. All Rights Reserved. •並列処理 •分散処理 •MapReduce系統の処理の特徴
•データベースの特徴 •最近の動向 まとめ 効果が出るかは 問題次第
95 Copyright©2017 NTT corp. All Rights Reserved. •並列処理 •分散処理 •MapReduce系統の処理の特徴
•データベースの特徴 •最近の動向 まとめ 上手く使いこなして ビジネスの役に 立ててください
96 Copyright©2017 NTT corp. All Rights Reserved. •並列処理 •分散処理 •MapReduce系統の処理の特徴
•データベースの特徴 •最近の動向 まとめ エンジニアの みなさまの力量に かかっています!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}