ΤʔδΣϯτ͕ ະͷڥͰ ࢼߦࡨޡ͍ͯ͘͠தͰ কདྷతʹಘΒΕΔऩӹΛ࠷େԽ͢ΔΑ͏ͳ ঢ়ଶʹԠͨ͡ํࡦΛֶश͢Δ u ΤʔδΣϯτɿֶश͢ΔओମʢϩϘοτɾήʔϜAIͳͲʣ u ڥɿΤʔδΣϯτ͕׆ಈ͢Δ u ऩӹɿڥʹજΉධՁػߏ͔ΒಘΒΕΔ֤࣌ࠁͷධՁ݁Ռʢใुʣͷྦྷੵ u ঢ়ଶɿڥʢʴΤʔδΣϯτʣ͕Ͳ͏ͳ͍ͬͯΔ͔Λతʹද͢σʔλ u ํࡦɿΤʔδΣϯτ͕ڥʹհೖ͢Δํ๏ʢߦಈʣͷҙࢥܾఆػߏ
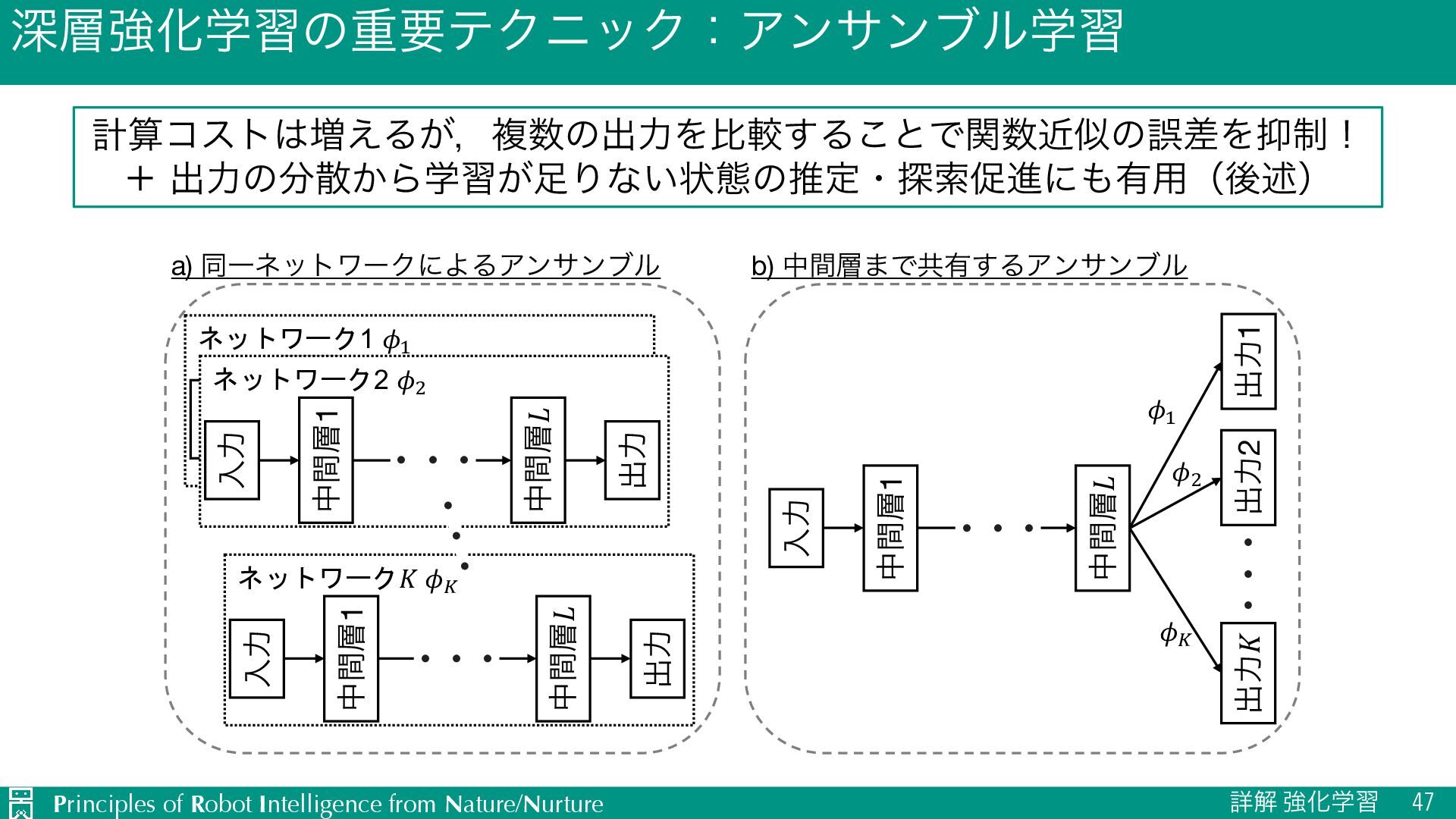
ৄղ ڧԽֶश 59 † https://proceedings.mlr.press/v80/fujimoto18a.html u ํࡦͱՁؔͷֶशλΠϛϯάΛඇಉظԽ L ՁؔΛઌʹֶशͰ͖͍ͯͳ͍ͱํࡦ࠷దԽͰ͖ͳ͍… Ø ํࡦͷֶशසΛՁؔΑΓݮΒ͢ʢσϑΥϧτʣ u Qֶश૬͔ΒExpected SARSA૬ʹมߋ L QֶशͩͱকདྷͷՁΛաେධՁͯ͠ޡͬͨߦಈΛ࠷దͱޡఆ͍͢͠… Ø কདྷͷՁΛฏԽͯ͠աେධՁΛ੍ u ߦಈՁؔͷΞϯαϯϒϧֶश L ۙࣅޡࠩʹΑΓաେධՁͯ͠͠·͏ͱ ʏ Ø ಠཱͨ̎ͭ͠ͷߦಈՁؔΛֶशͯ͠খ͍͞ํͷকདྷͷՁΛ࠾༻
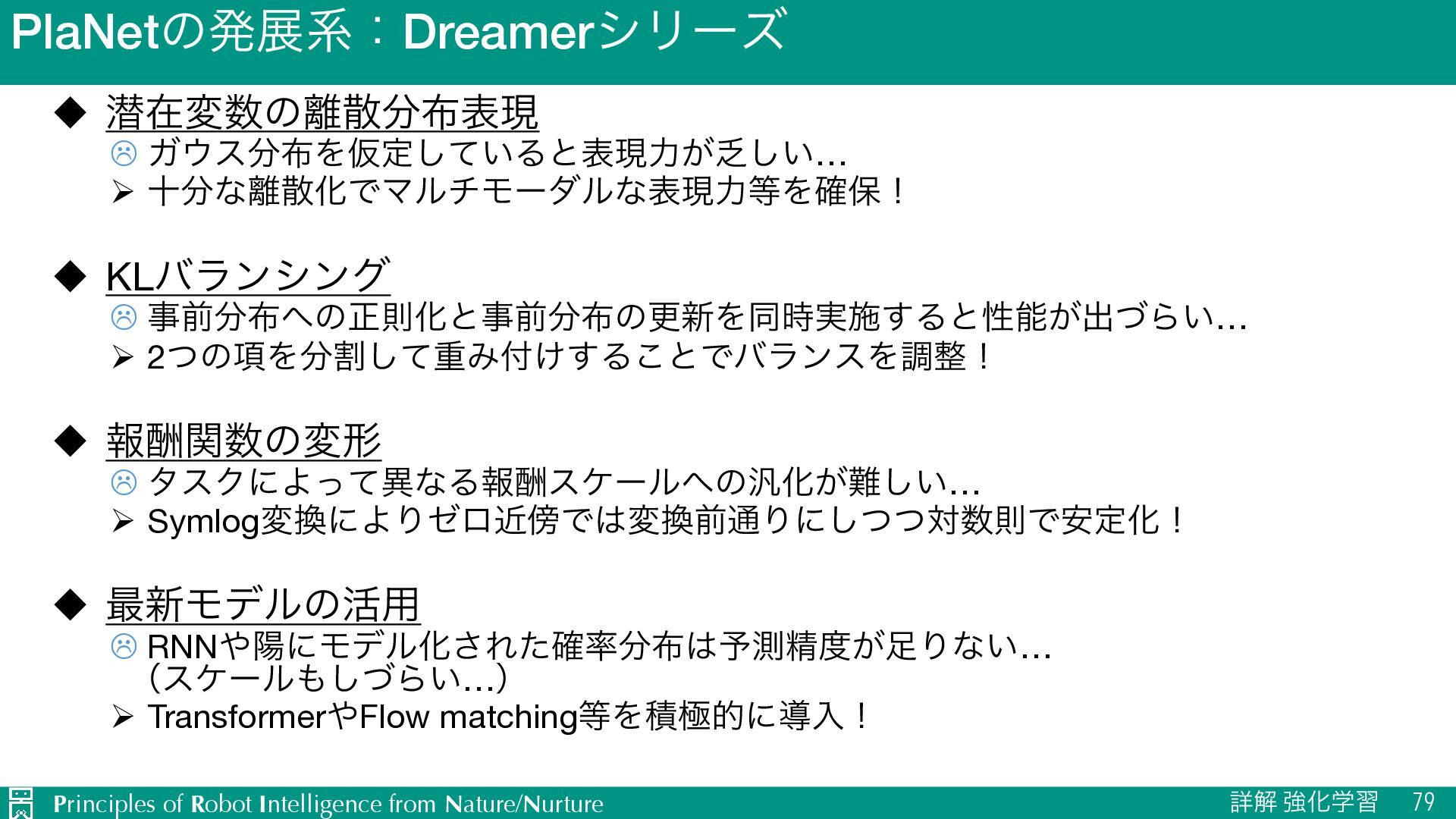
u જࡏมͷࢄදݱ L ΨεΛԾఆ͍ͯ͠Δͱදݱྗ͕͍͠… Ø ेͳࢄԽͰϚϧνϞʔμϧͳදݱྗΛ֬อʂ u KLόϥϯγϯά L ࣄલͷਖ਼ଇԽͱࣄલͷߋ৽Λಉ࣮࣌ࢪ͢Δͱੑೳ͕ग़ͮΒ͍… Ø 2ͭͷ߲Λׂͯ͠ॏΈ͚͢Δ͜ͱͰόϥϯεΛௐʂ u ใुؔͷมܗ L λεΫʹΑͬͯҟͳΔใुεέʔϧͷ൚Խ͕͍͠… Ø SymlogมʹΑΓθϩۙͰมલ௨Γʹͭͭ͠ରଇͰ҆ఆԽʂ u ࠷৽Ϟσϧͷ׆༻ L RNNཅʹϞσϧԽ͞Εͨ֬༧ଌਫ਼͕Γͳ͍… ʢεέʔϧͮ͠Β͍…ʣ Ø TransformerFlow matchingΛੵۃతʹಋೖʂ
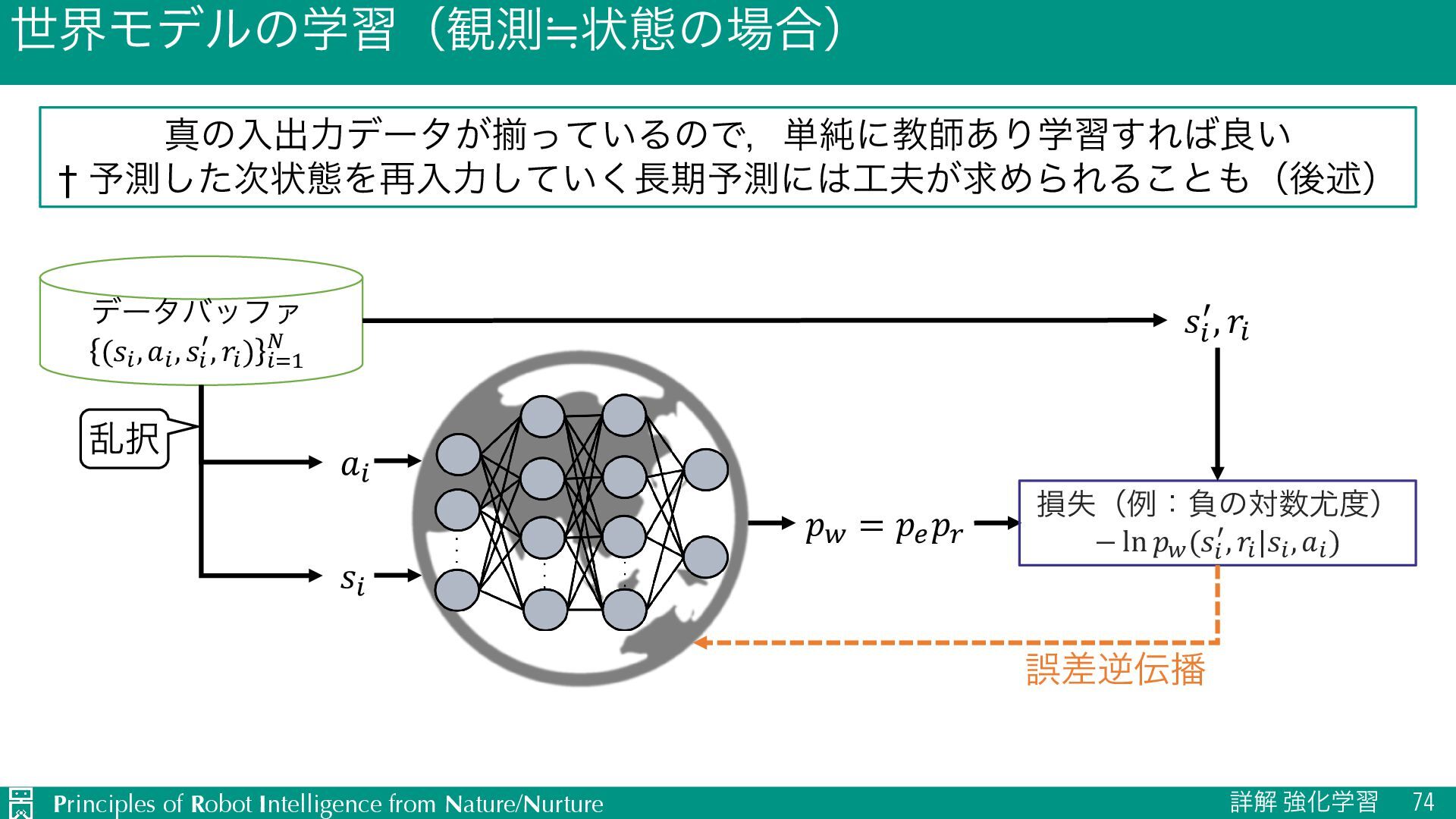
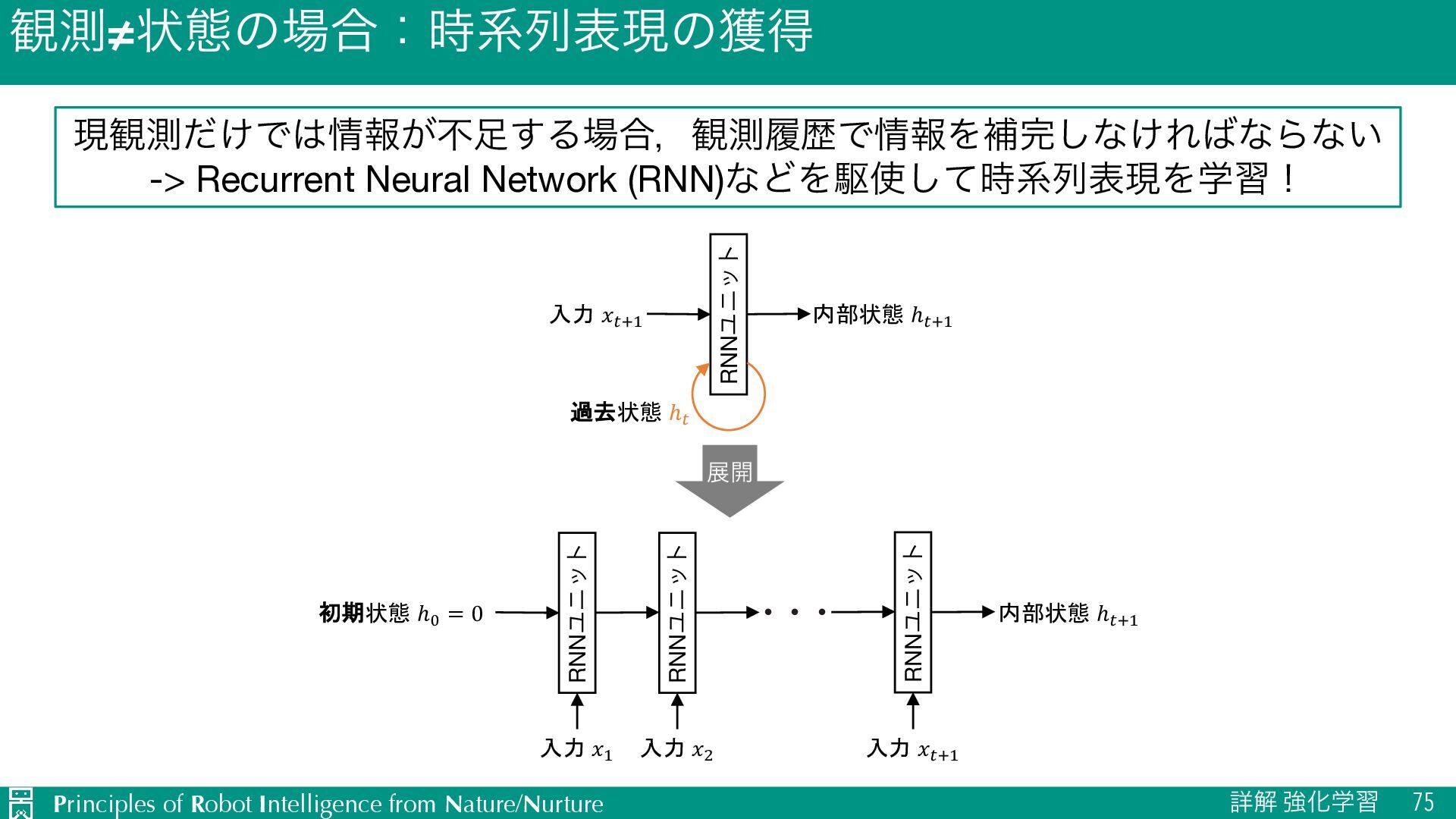
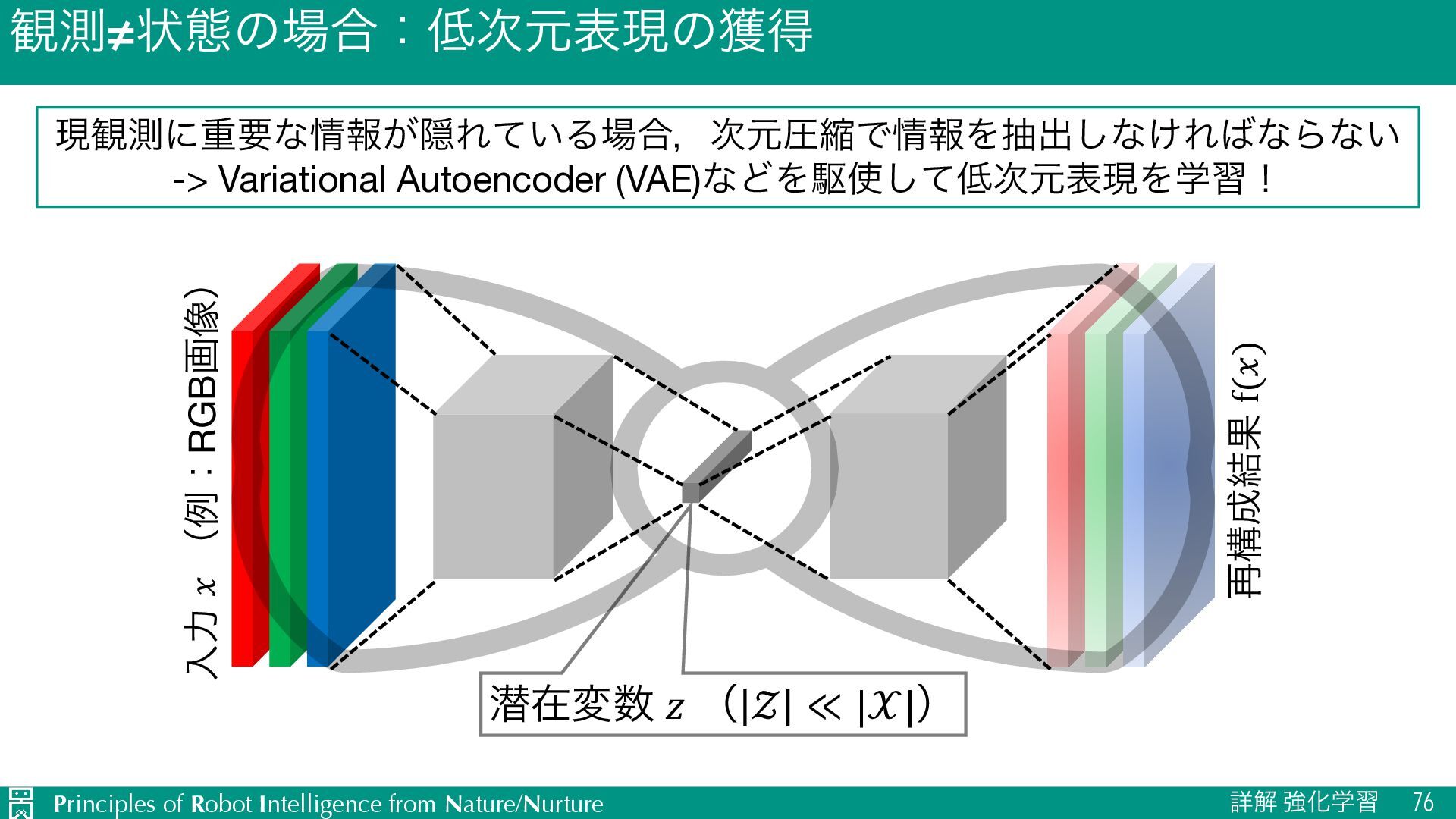
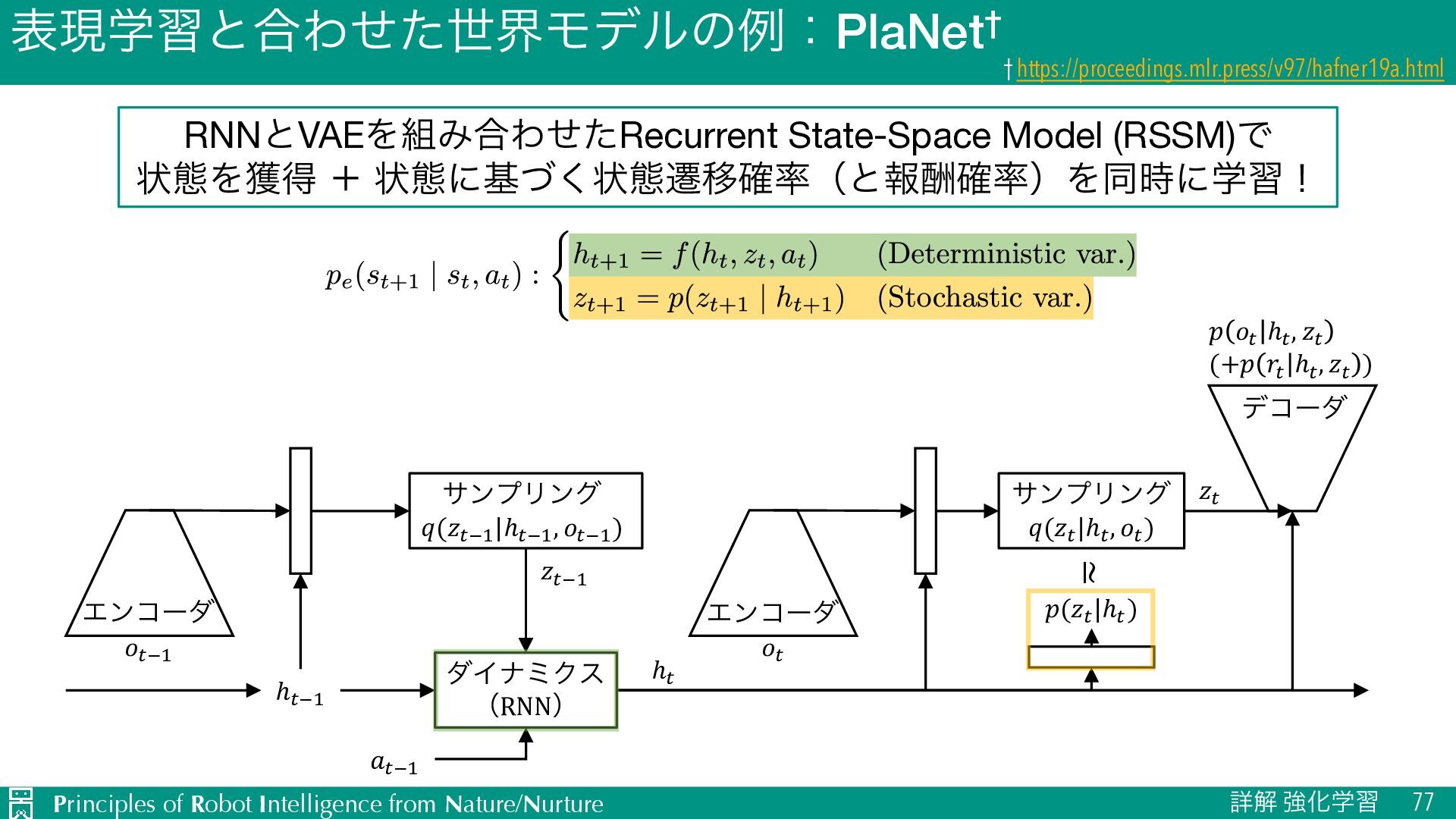
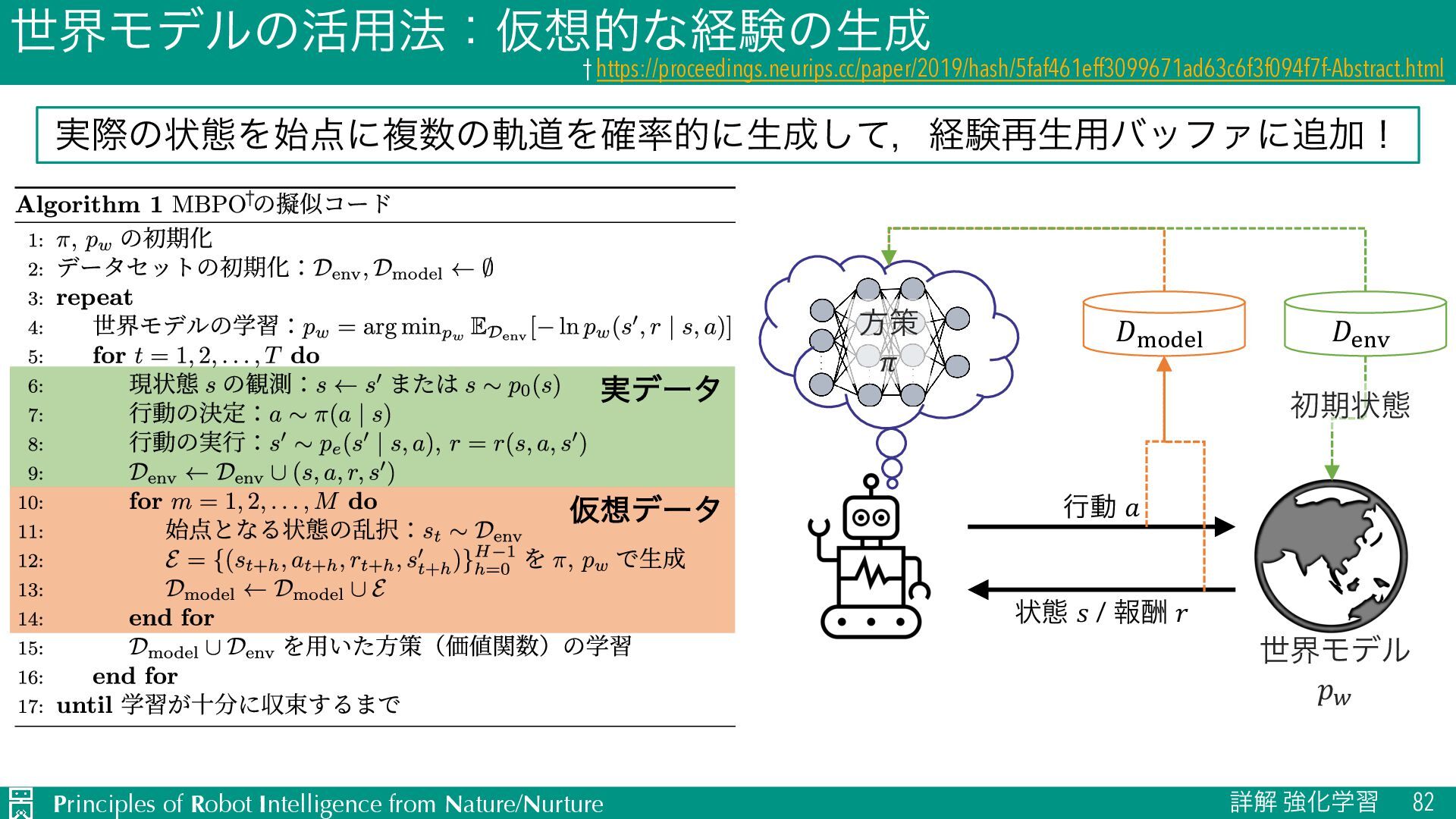
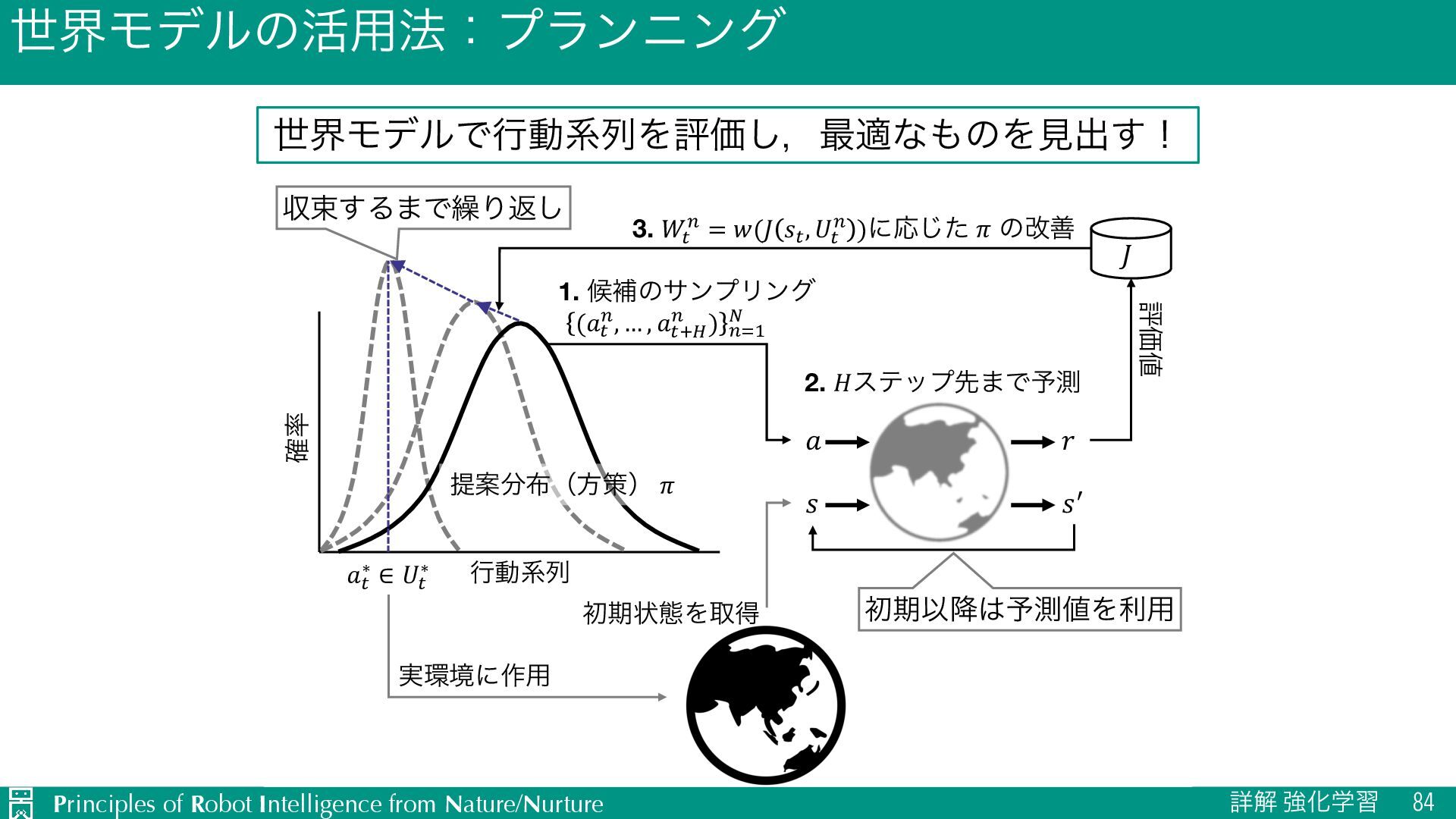
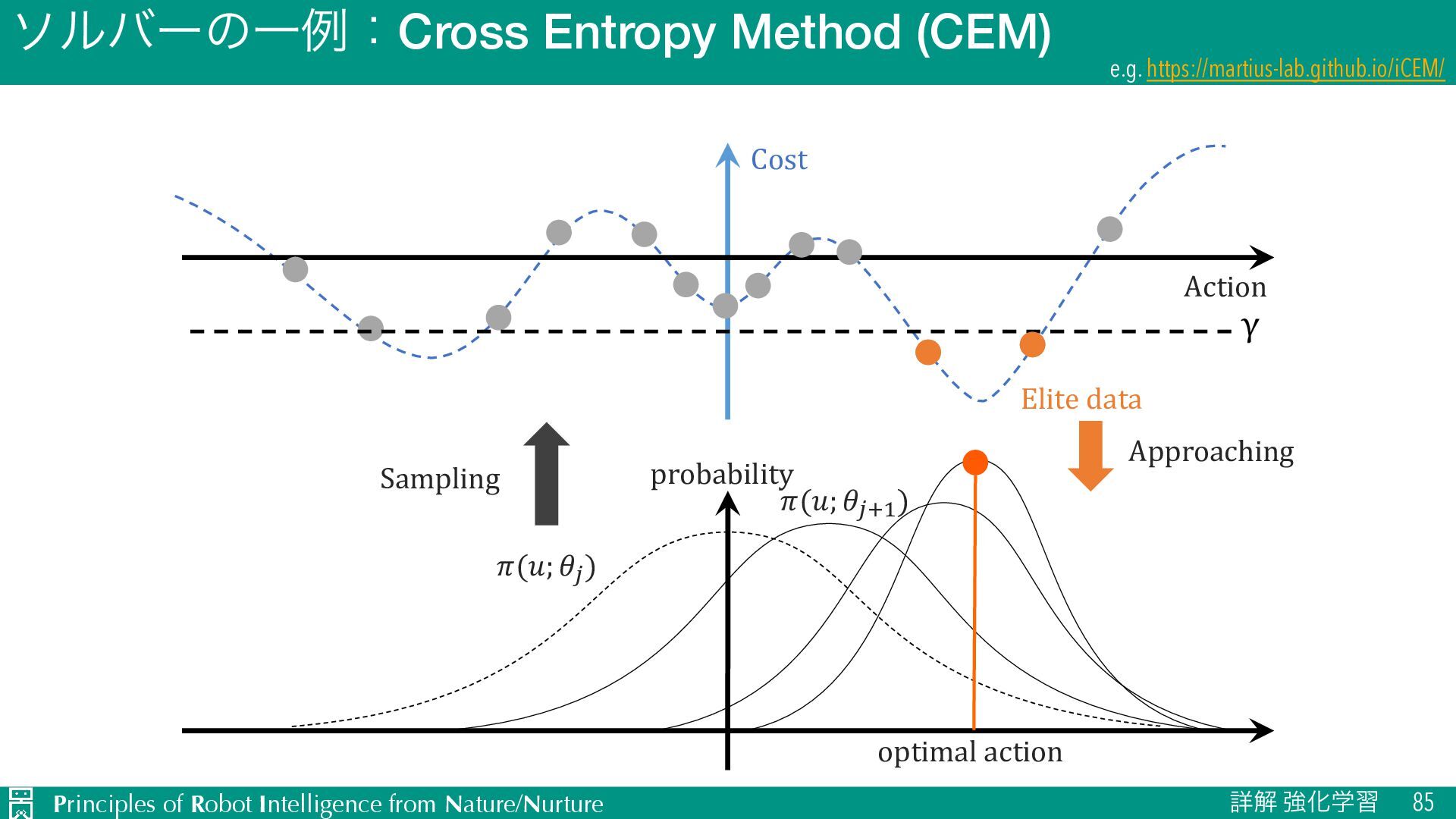
u ऩӹͷਪఆ Ø nεςοϓઌ·ͰͷใुΛ༧ଌͯ͠𝑛εςοϓऩӹͷՁؔΛֶश Ø J TD๏ͱϞϯςΧϧϩ๏ͷඒຯ͍͠ͱ͜औΓΛޮྑ࣮͘ࢪ Ø L ༧ଌޡ͕ࠩྦྷੵ͢ΔͨΊظ༧ଌࠔ u Ծతͳܦݧͷੜ Ø ٖࣅσʔλΛੈքϞσϧΛ௨ͯ͡ੜֶͯ͠शʹར༻ Ø J ૠͰ͋Εɼਫ਼ྑ͘ੜͨ͠σʔλֶ͕शΛଅਐɾ҆ఆԽ Ø L ֎ૠʹରͯ͠ɼޡͬͨσʔλΛੜֶͯ͠शΛ્͢Δةݥ u ϓϥϯχϯά Ø 𝐻εςοϓઌ·ͰͷγϛϡϨʔγϣϯ݁ՌΛجʹ࠷దͳߦಈܥྻΛਪఆ Ø J ՃͰͷՁؔํࡦϞσϧͷֶश͕ෆཁ Ø L ܭࢉίετ͕େ
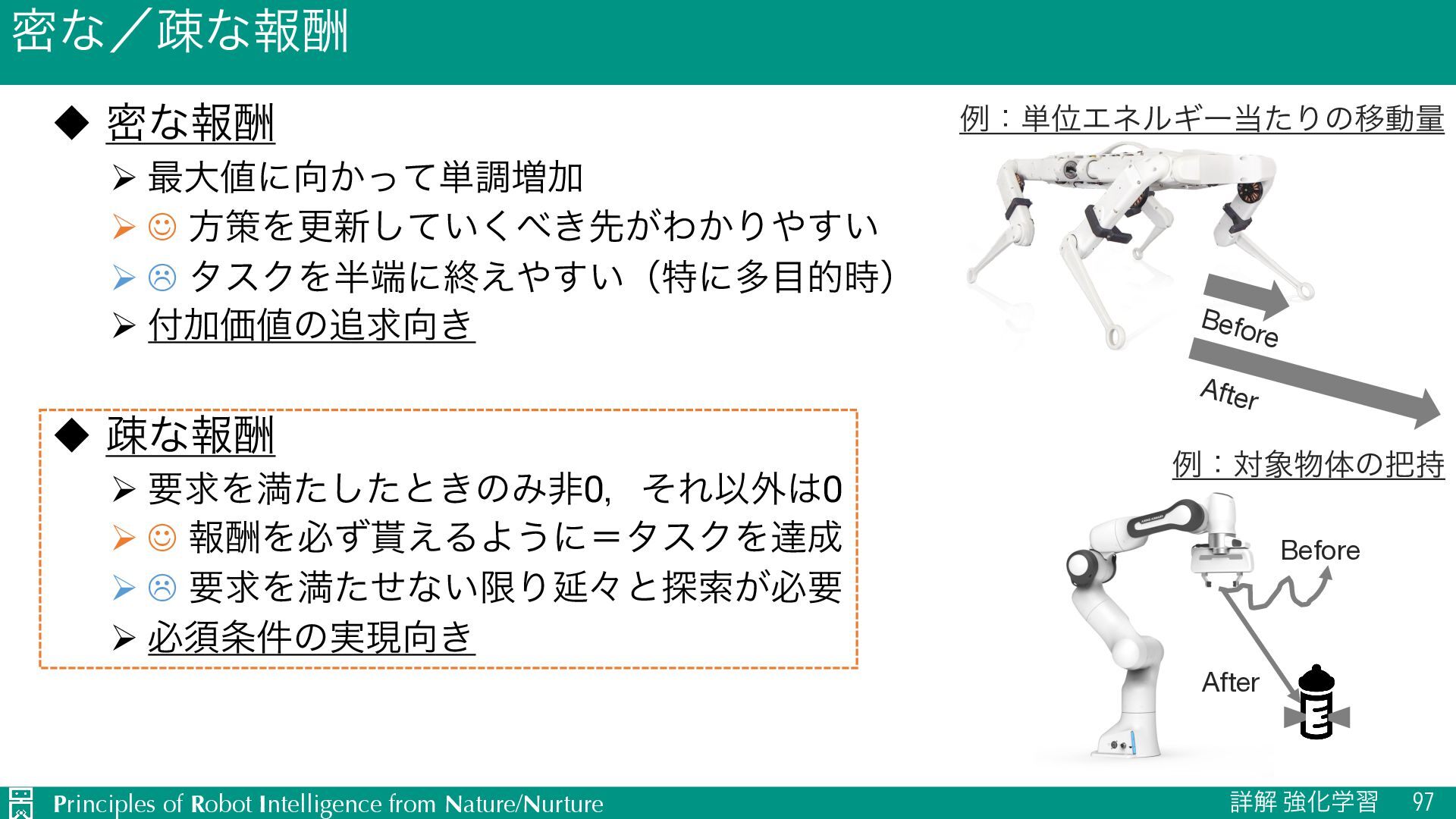
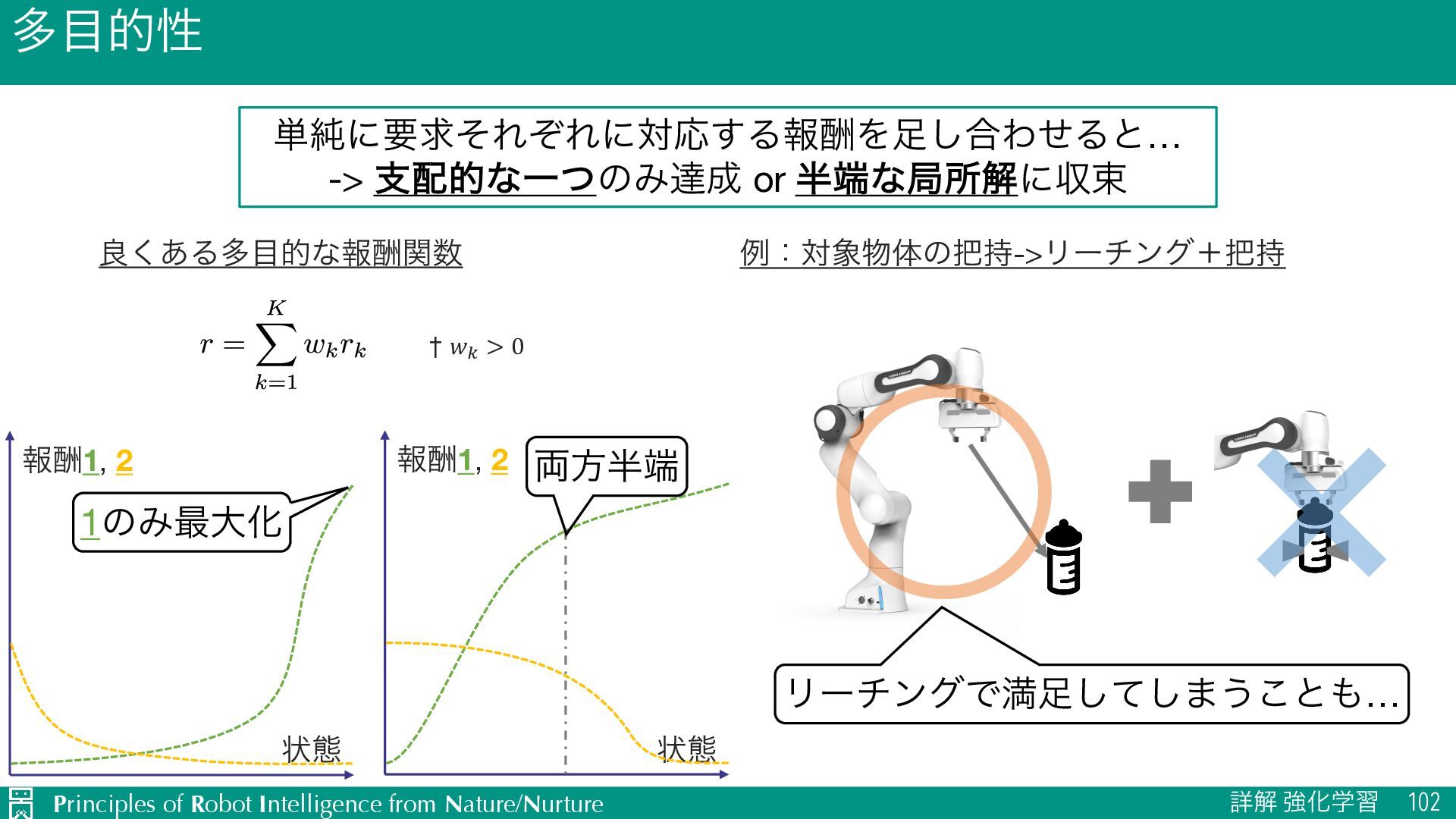
u ີͳใु Ø ࠷େʹ͔ͬͯ୯ௐ૿Ճ Ø J ํࡦΛߋ৽͍͖ͯ͘͠ઌ͕Θ͔Γ͍͢ Ø L λεΫΛʹऴ͍͑͢ʢಛʹଟత࣌ʣ Ø ՃՁͷٻ͖ u ૄͳใु Ø ཁٻΛຬͨͨ͠ͱ͖ͷΈඇ0ɼͦΕҎ֎0 Ø J ใुΛඞͣ͑ΔΑ͏ʹʹλεΫΛୡ Ø L ཁٻΛຬͨͤͳ͍ݶΓԆʑͱ୳ࡧ͕ඞཁ Ø ඞਢ݅ͷ࣮ݱ͖ Before After ྫɿ୯ҐΤωϧΪʔͨΓͷҠಈྔ ྫɿରମͷ࣋ Before After
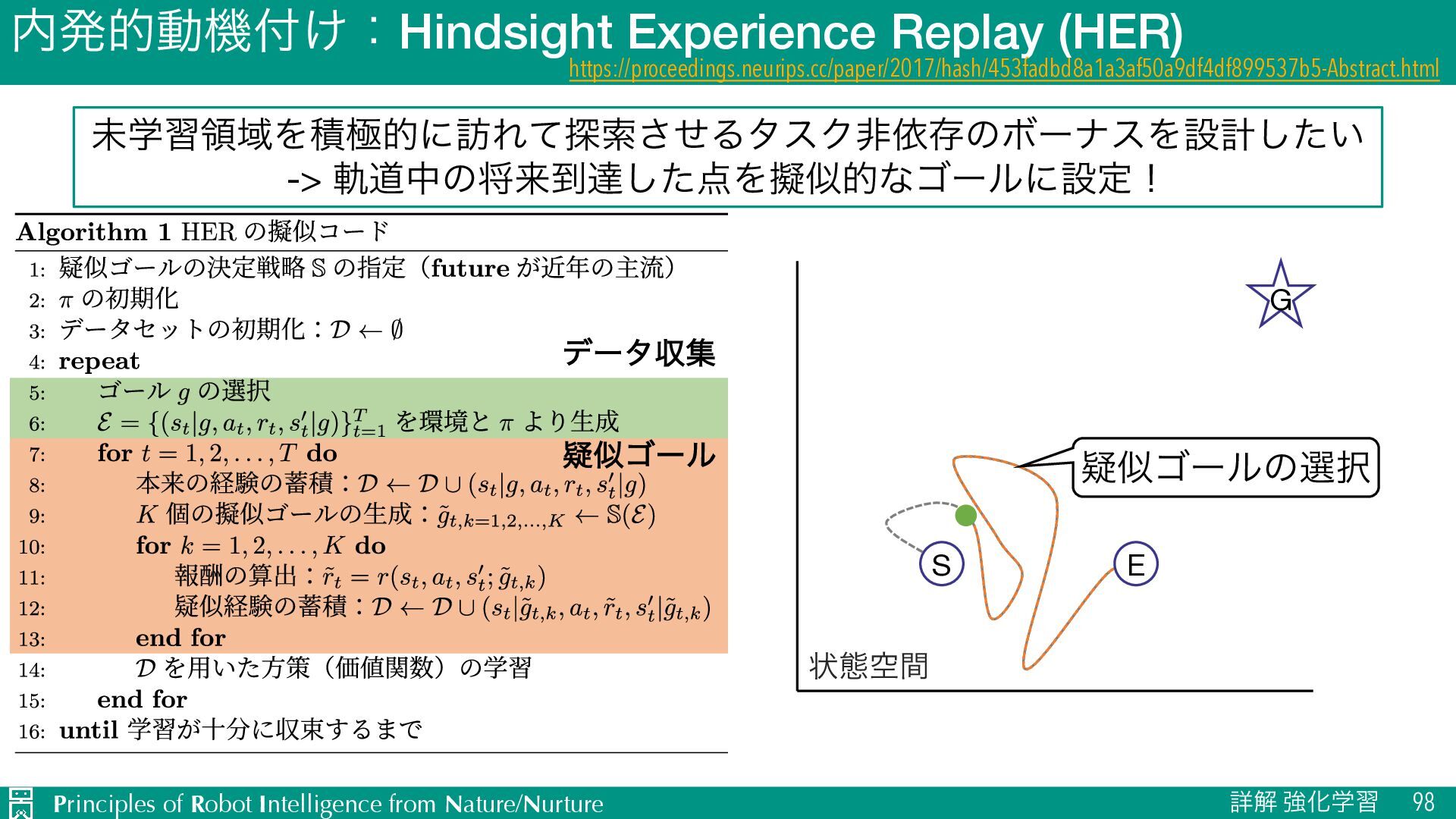
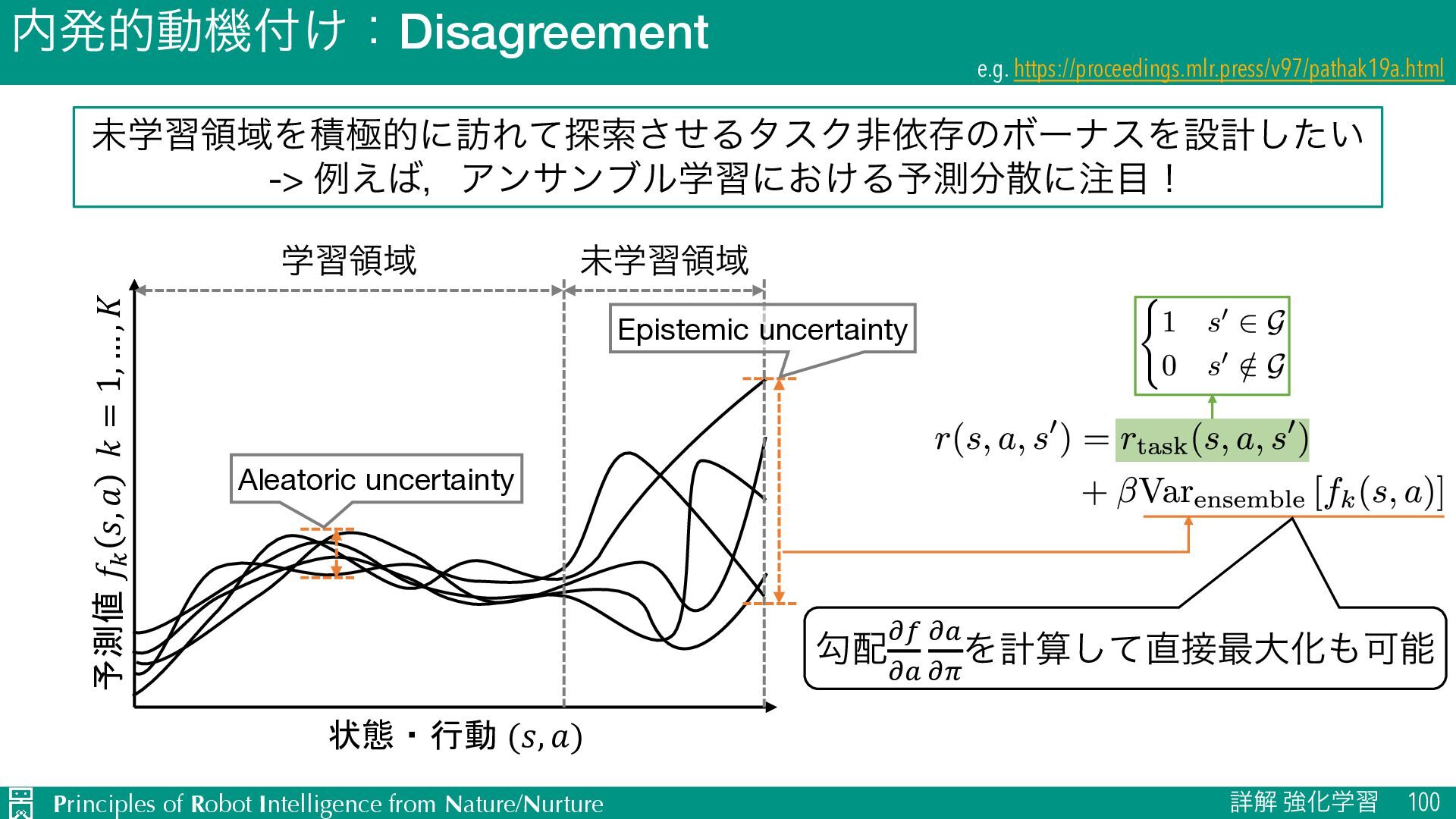
ৄղ ڧԽֶश 98 https://proceedings.neurips.cc/paper/2017/hash/453fadbd8a1a3af50a9df4df899537b5-Abstract.html ະֶशྖҬΛੵۃతʹ๚Εͯ୳ࡧͤ͞ΔλεΫඇґଘͷϘʔφεΛઃܭ͍ͨ͠ -> يಓதͷকདྷ౸ୡͨ͠Λٖࣅతͳΰʔϧʹઃఆʂ σʔλऩू ٙࣅΰʔϧ ঢ়ଶۭؒ S E G ٙࣅΰʔϧͷબ
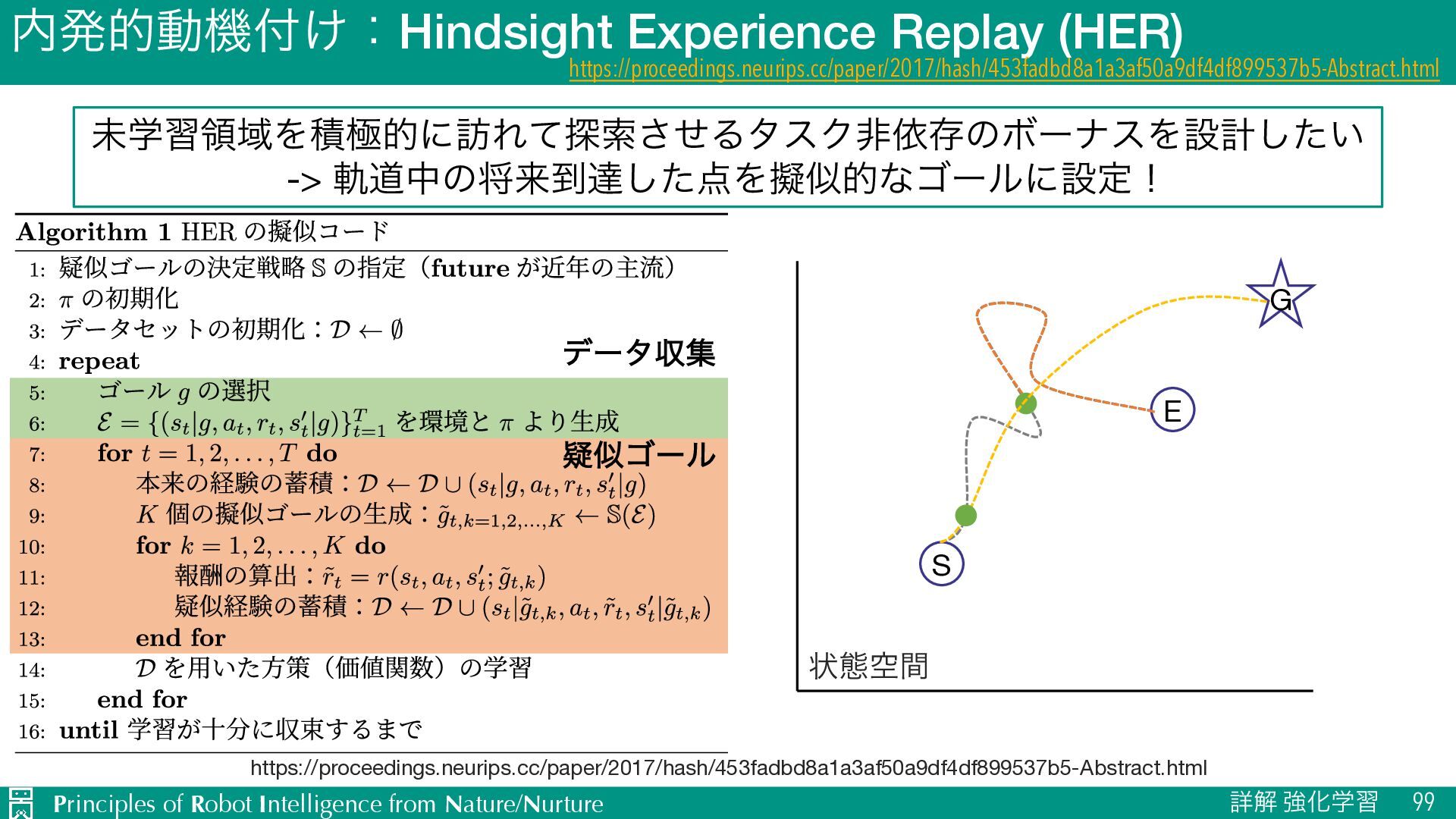
ৄղ ڧԽֶश 99 https://proceedings.neurips.cc/paper/2017/hash/453fadbd8a1a3af50a9df4df899537b5-Abstract.html ະֶशྖҬΛੵۃతʹ๚Εͯ୳ࡧͤ͞ΔλεΫඇґଘͷϘʔφεΛઃܭ͍ͨ͠ -> يಓதͷকདྷ౸ୡͨ͠Λٖࣅతͳΰʔϧʹઃఆʂ σʔλऩू ٙࣅΰʔϧ ঢ়ଶۭؒ S G E https://proceedings.neurips.cc/paper/2017/hash/453fadbd8a1a3af50a9df4df899537b5-Abstract.html
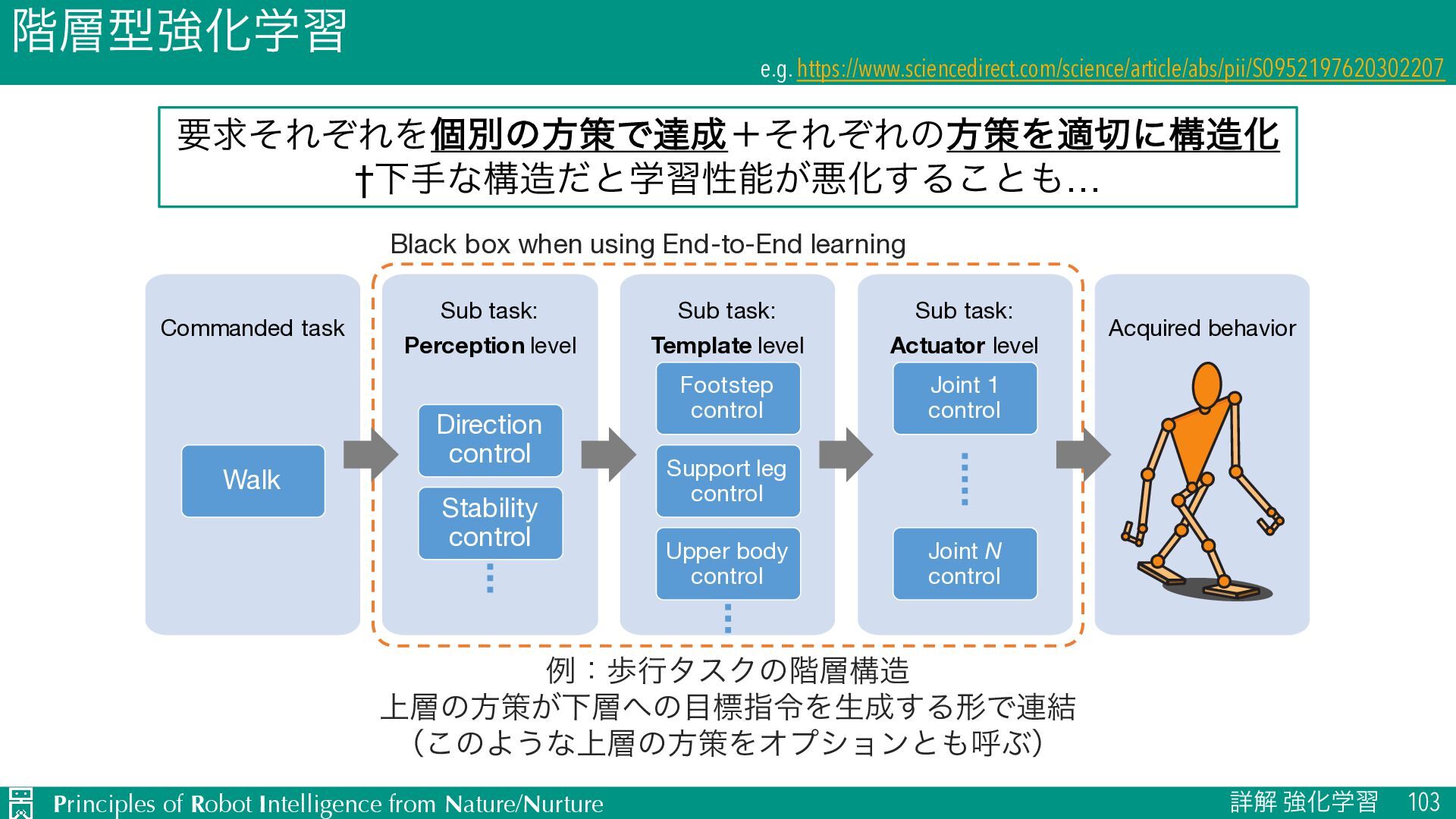
e.g. https://www.sciencedirect.com/science/article/abs/pii/S0952197620302207 ཁٻͦΕͧΕΛݸผͷํࡦͰୡʴͦΕͧΕͷํࡦΛదʹߏԽ †Լखͳߏͩͱֶशੑೳ͕ѱԽ͢Δ͜ͱ… Commanded task Walk Acquired behavior Sub task: Perception level Direction control Stability control Sub task: Template level Footstep control Support leg control Upper body control Sub task: Actuator level Joint 1 control Joint N control Black box when using End-to-End learning ྫɿาߦλεΫͷ֊ߏ ্ͷํࡦ͕ԼͷඪࢦྩΛੜ͢ΔܗͰ࿈݁ ʢ͜ͷΑ͏ͳ্ͷํࡦΛΦϓγϣϯͱݺͿʣ
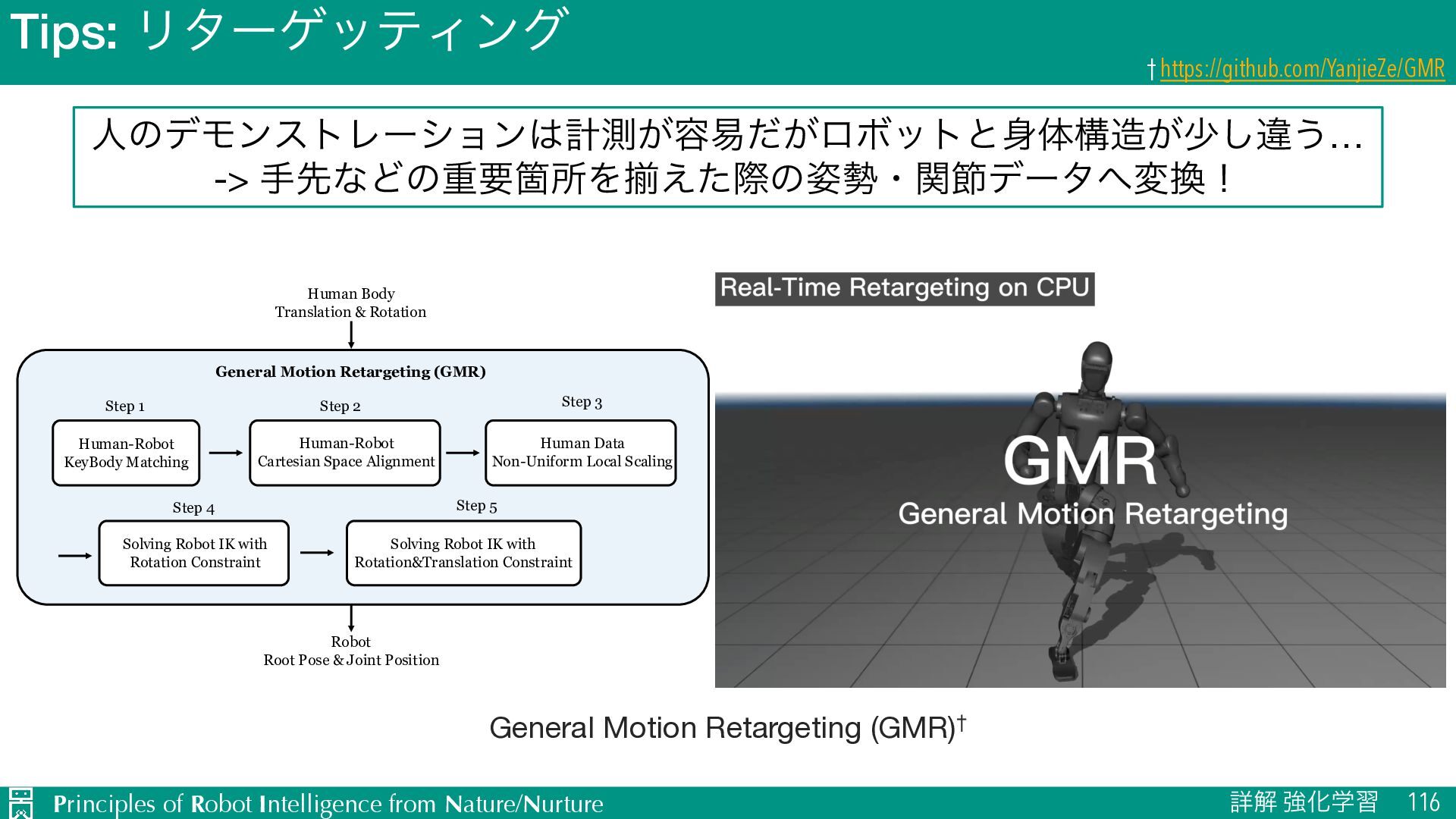
116 † https://github.com/YanjieZe/GMR ਓͷσϞϯετϨʔγϣϯܭଌ͕༰қ͕ͩϩϘοτͱମߏ͕গ͠ҧ͏… -> खઌͳͲͷॏཁՕॴΛἧ͑ͨࡍͷ࢟ɾؔઅσʔλมʂ (a) Reference motion (b) Retarget videos Fig. 1: For the user study, participants were shown videos of the reference motion (a), and asked to choose which retarget video (b) was more similar to it. General Motion Retargeting (GMR) Human-Robot KeyBody Matching Human-Robot Cartesian Space Alignment Human Data Non-Uniform Local Scaling Solving Robot IK with Rotation Constraint Solving Robot IK with Rotation&Translation Constraint Human Body Translation & Rotation Robot Root Pose & Joint Position Step 1 Step 2 Step 3 Step 4 Step 5 Fig. 2: General Motion Retargeting (GMR) Pipeline. The tracking errors are computed for all frames that a policy is alive. General Motion Retargeting (GMR)†
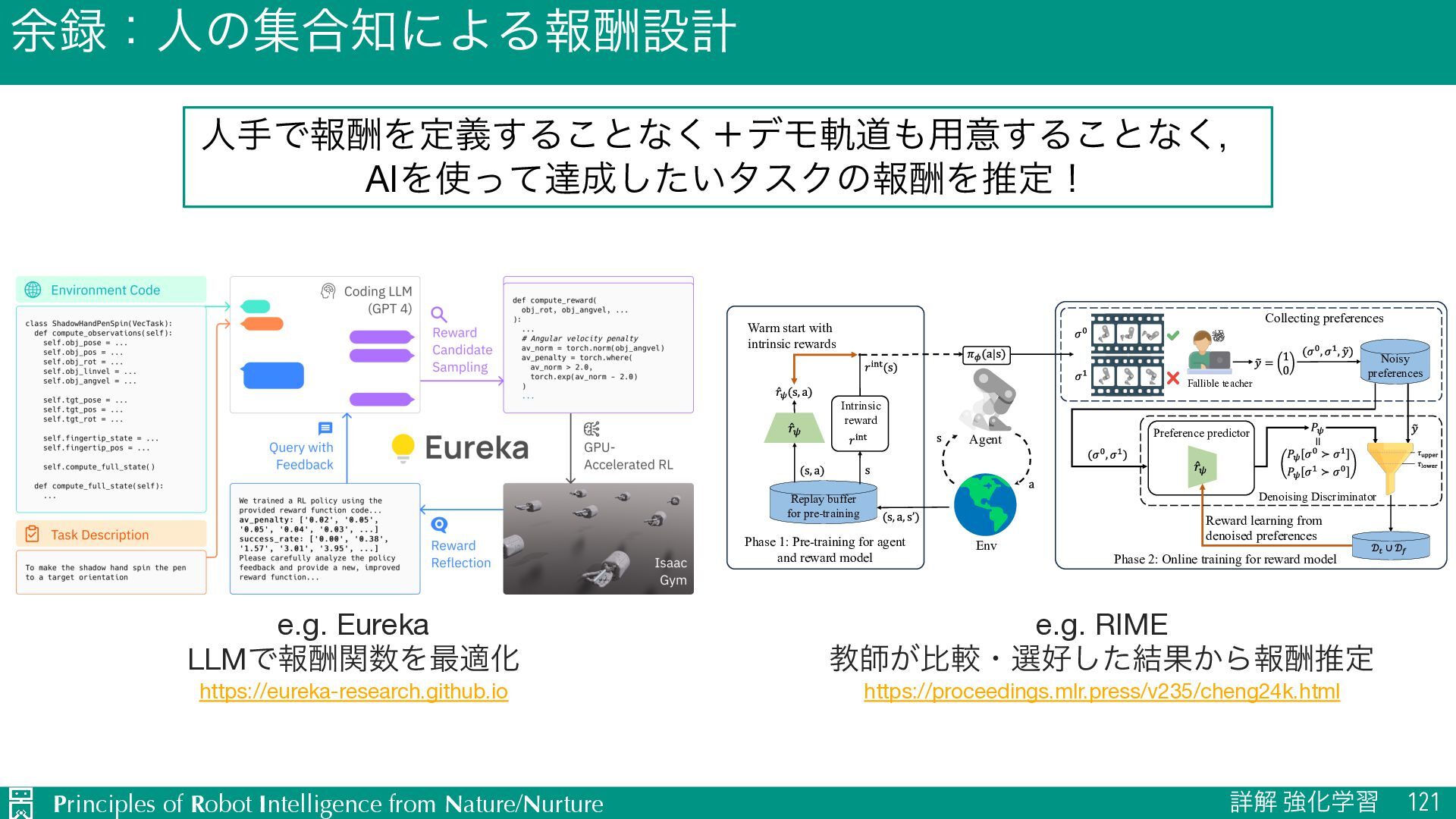
ਓखͰใुΛఆٛ͢Δ͜ͱͳ͘ʴσϞيಓ༻ҙ͢Δ͜ͱͳ͘ɼ AIΛͬͯୡ͍ͨ͠λεΫͷใुΛਪఆʂ Published as a conference paper at ICLR 2024 Figure 2: EUREKA takes unmodified environment source code and language task description as context to zero-shot generate executable reward functions from a coding LLM. Then, it iterates between reward sampling, GPU-accelerated reward evaluation, and reward reflection to progressively improve its reward outputs. domain expertise to construct task prompts or learn only simple skills, leaving a substantial gap in achieving human-level dexterity (Yu et al., 2023; Brohan et al., 2023). On the other hand, reinforcement learning (RL) has achieved impressive results in dexter- ity (Andrychowicz et al., 2020; Handa et al., 2023) as well as many other domains-if the human designers can carefully construct reward functions that accurately codify and provide learning signals e.g. Eureka LLMͰใुؔΛ࠷దԽ https://eureka-research.github.io RIME: Robust Preference-based Reinforcement Learning with Noisy Preferences Preference predictor Fallible teacher Noisy preferences Reward learning from denoised preferences Denoising Discriminator Collecting preferences Phase 1: Pre-training for agent and reward model Replay buffer for pre-training Warm start with intrinsic rewards Phase 2: Online training for reward model Agent Env Intrinsic reward Figure 1. Overview of RIME. In the pre-training phase, we warm start the reward model ˆ rω with intrinsic rewards rint to facilit smooth transition to the online training phase. Post pre-training, the policy, Q-network, and reward model ˆ rω are all inherited as i configurations for online training. During online training, we utilize a denoising discriminator to screen denoised preferences for ro reward learning. This discriminator employs a dynamic lower bound ωlower on the KL divergence between predicted preferences Pω annotated preference labels ˜ y to filter trustworthy samples Dt , and an upper bound ωupper to flip highly unreliable labels Df . vergence between predicted and annotated preference labels to filter samples. Further, to mitigate the accumulated er- ror caused by incorrect filtration, we propose to warm start the reward model during the pre-training phase for a good (Lee et al., 2023), and reinforcement learning (Christ et al., 2017; Ibarz et al., 2018; Hejna III & Sadigh, 20 In the context of RL, Christiano et al. (2017) propos comprehensive framework for PbRL. To improve feedb e.g. RIME ڭࢣ͕ൺֱɾબͨ݁͠Ռ͔Βใुਪఆ https://proceedings.mlr.press/v235/cheng24k.html
ü ڧԽֶशͰϚϧίϑܾఆաఔΛຬͨ͢ઃఆ͕ॏཁ Ø ຬͨͤͳ͍߹ઃܭΛݟͨ͠Γɼ࣌ܥྻใͰิͨ͠Γ ü ਂڧԽֶशͰෳͷޮԽɾ҆ఆԽτϦοΫͷ׆༻͕ॏཁ Ø ͨͩ͠ɼద༻Մೳ݅σϝϦοτ͋ΔͷͰҙ ü ۙͷํࡦޯ๏୳ࡧೳྗͷҡ࣋ߋ৽ɾޯͷΒ͔͕͞ॏཁ Ø ύϥϝʔλ͕ଟ͘ͳ͍ͬͯΔͷͰਪͷར༻͕Φεεϝ ü ࣮ػͰͷࢼߦࡨޡΛݮΒͨ͢ΊʹʢੈքʣϞσϧͷֶशɾ׆༻͕ॏཁ Ø Ϟσϧͷ༧ଌਫ਼Ͳͷ׆༻๏Ͱੑೳʹେ͖͘د༩ ü ࣮Ԡ༻ͰෳࡶʹͳΓ͕ͪͳใुʹద͕ͨ͠ॏཁ Ø ෳͷใु߲Λࠞͥ߹ΘͤΔ͚ͩͰݶք͕͋ΔͷͰҙ p հٕज़ਐ݄าͰվྑ͞Ε͍ͯΔͷͰར༻࣌ʹௐࠪΛΕͣʹ…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
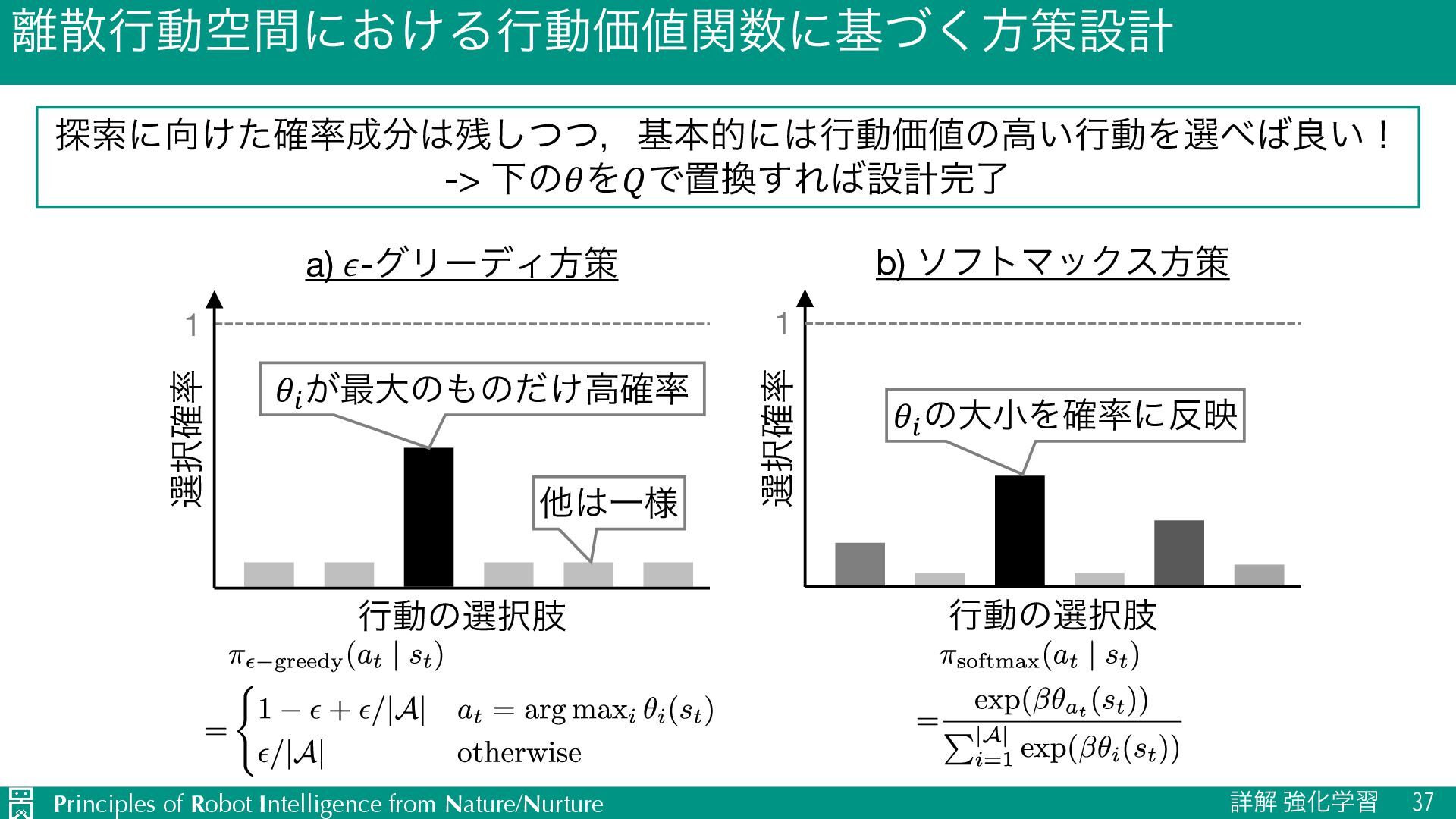{kind=link}
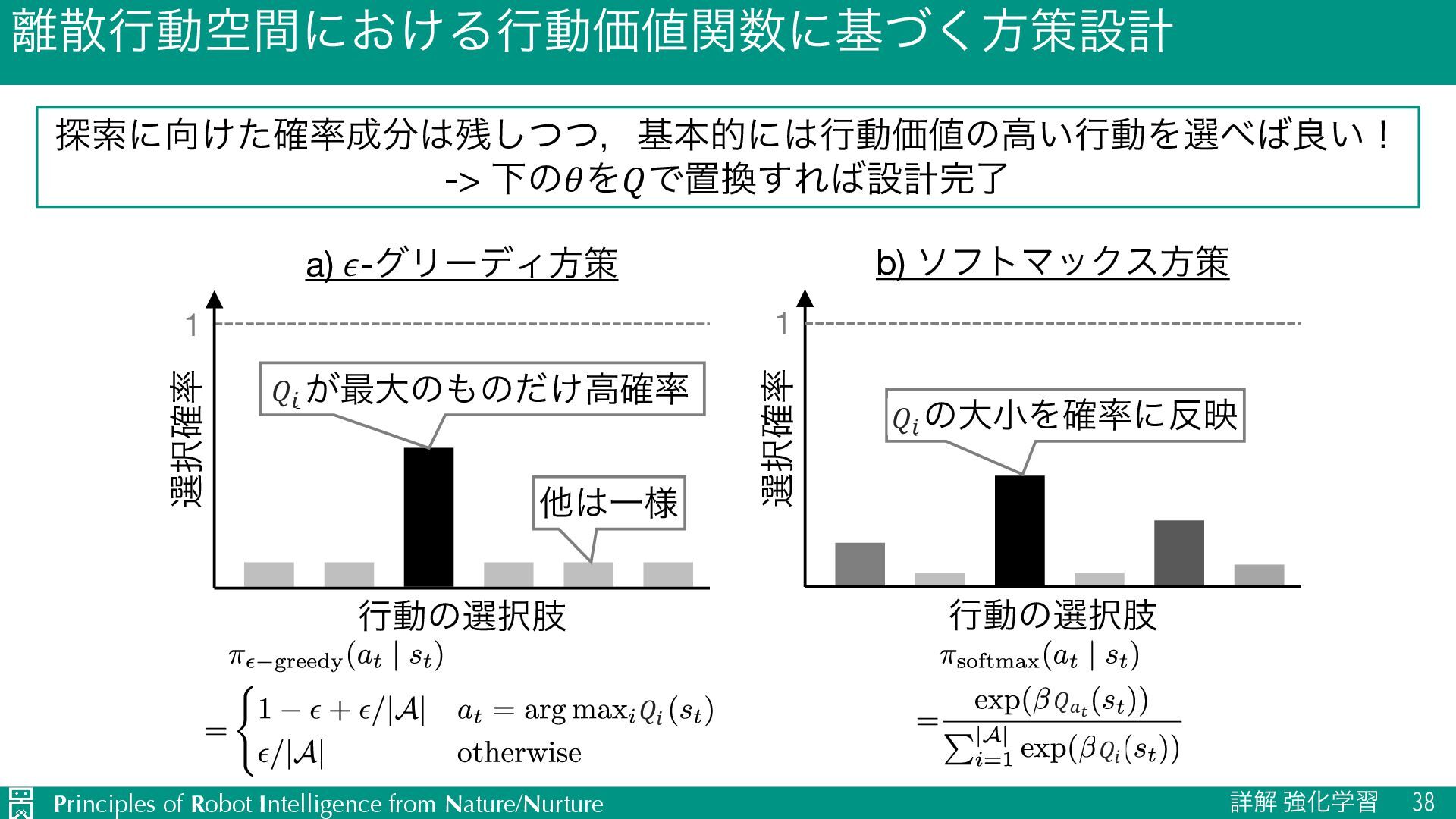{kind=link}
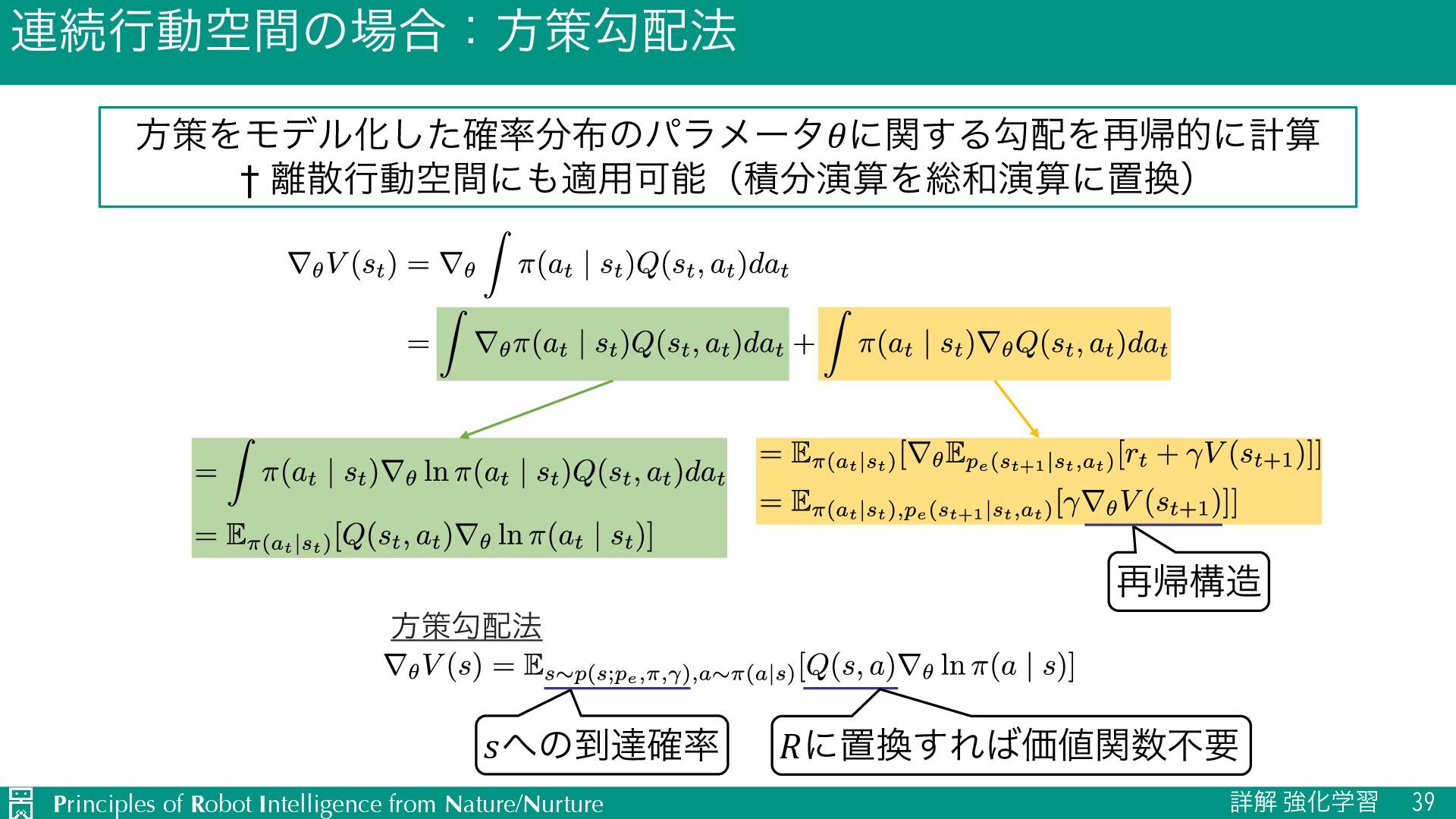{kind=link}
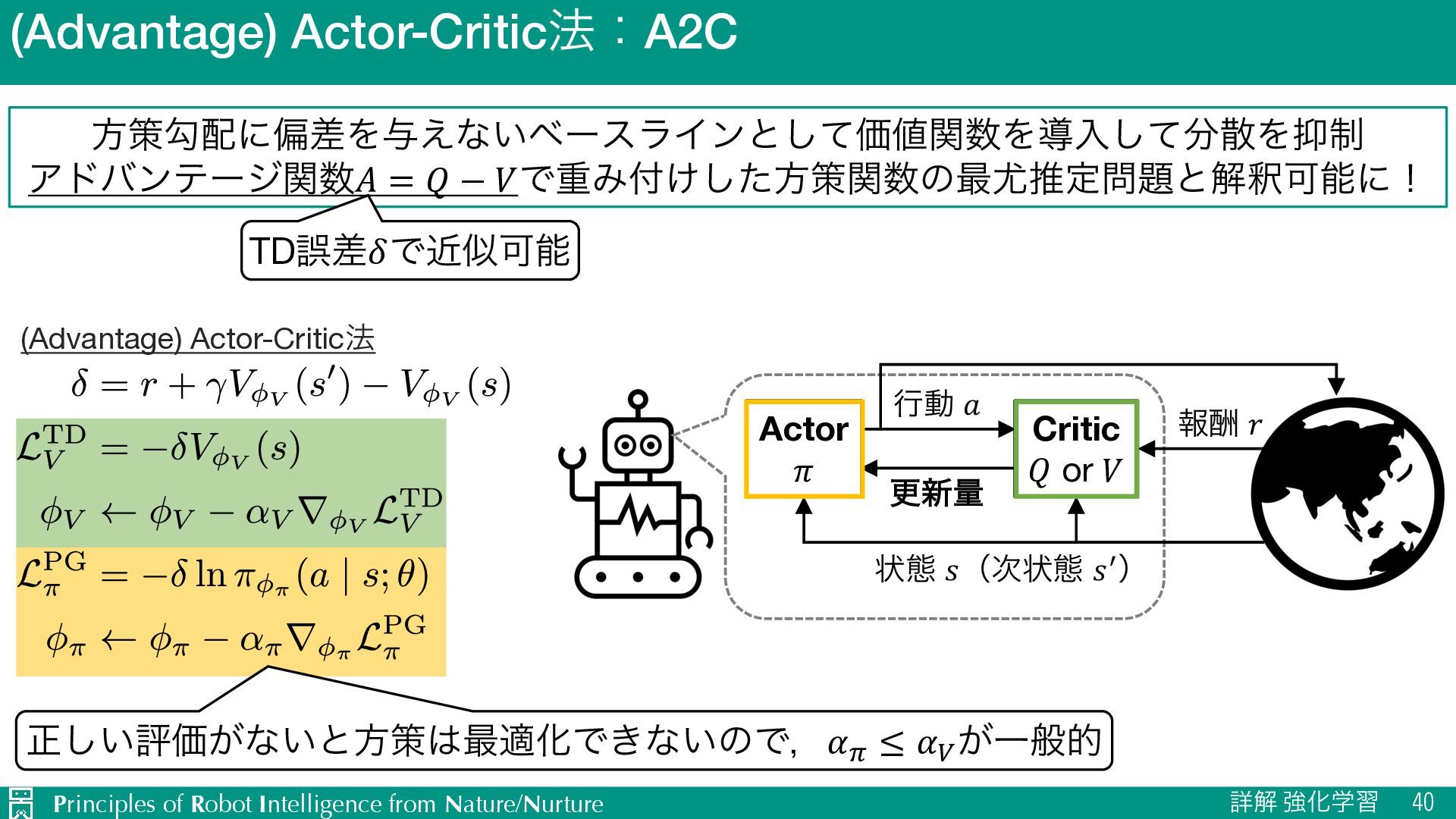{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}