2026/5/14 クラウドネイティブ会議
株式会社hacomono
bootjp /プリンシパルエンジニア(分散システム)
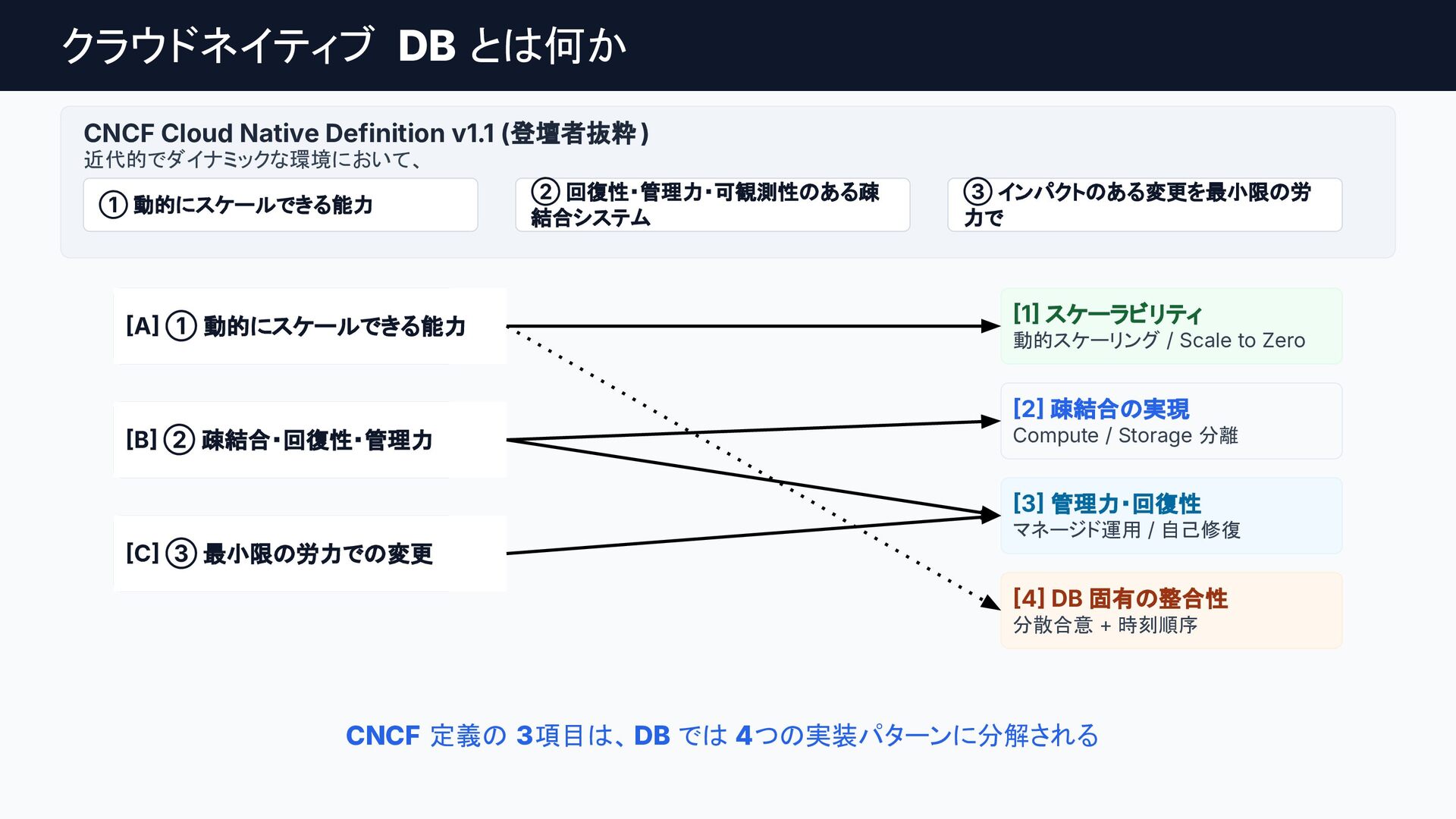
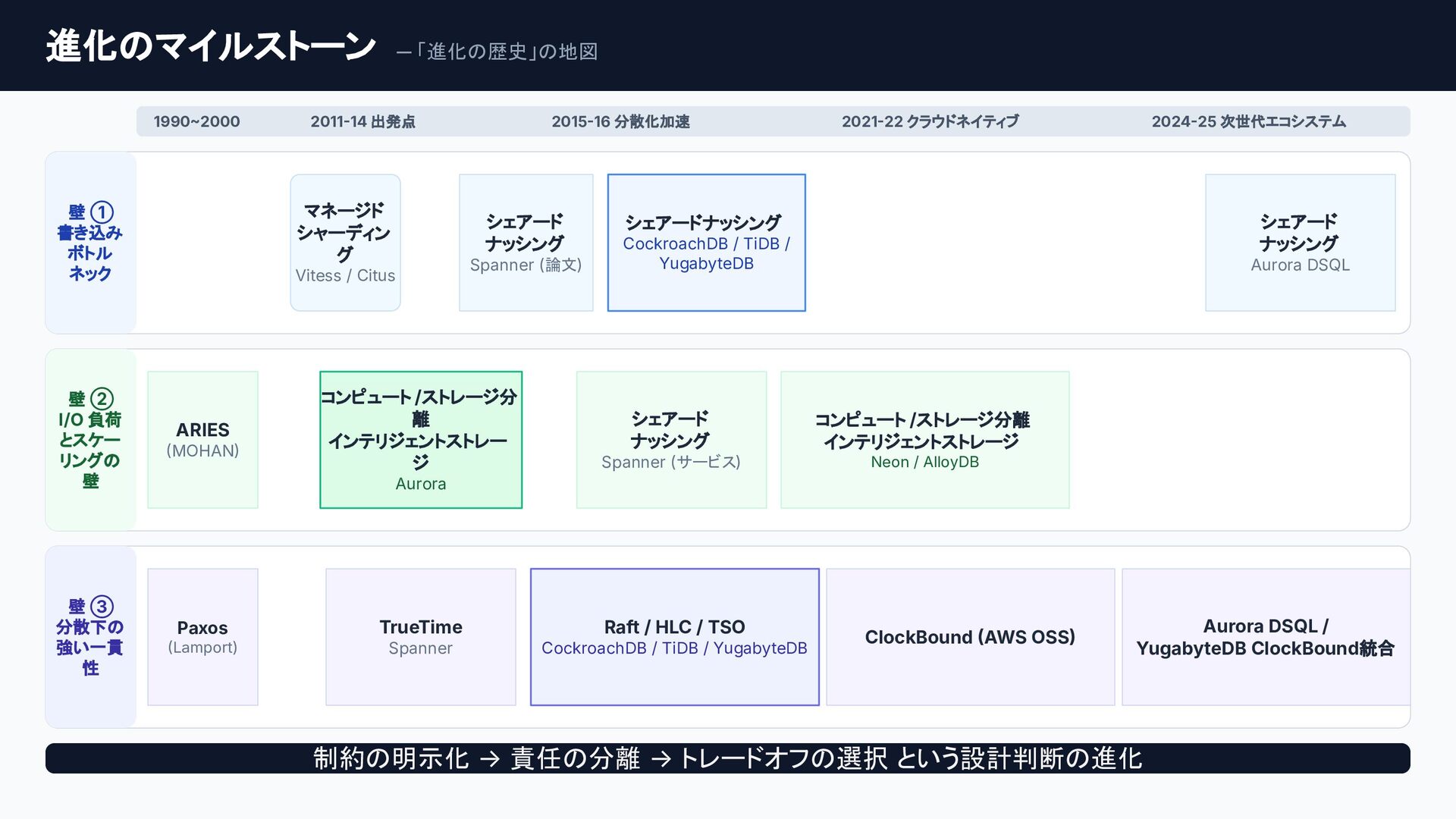
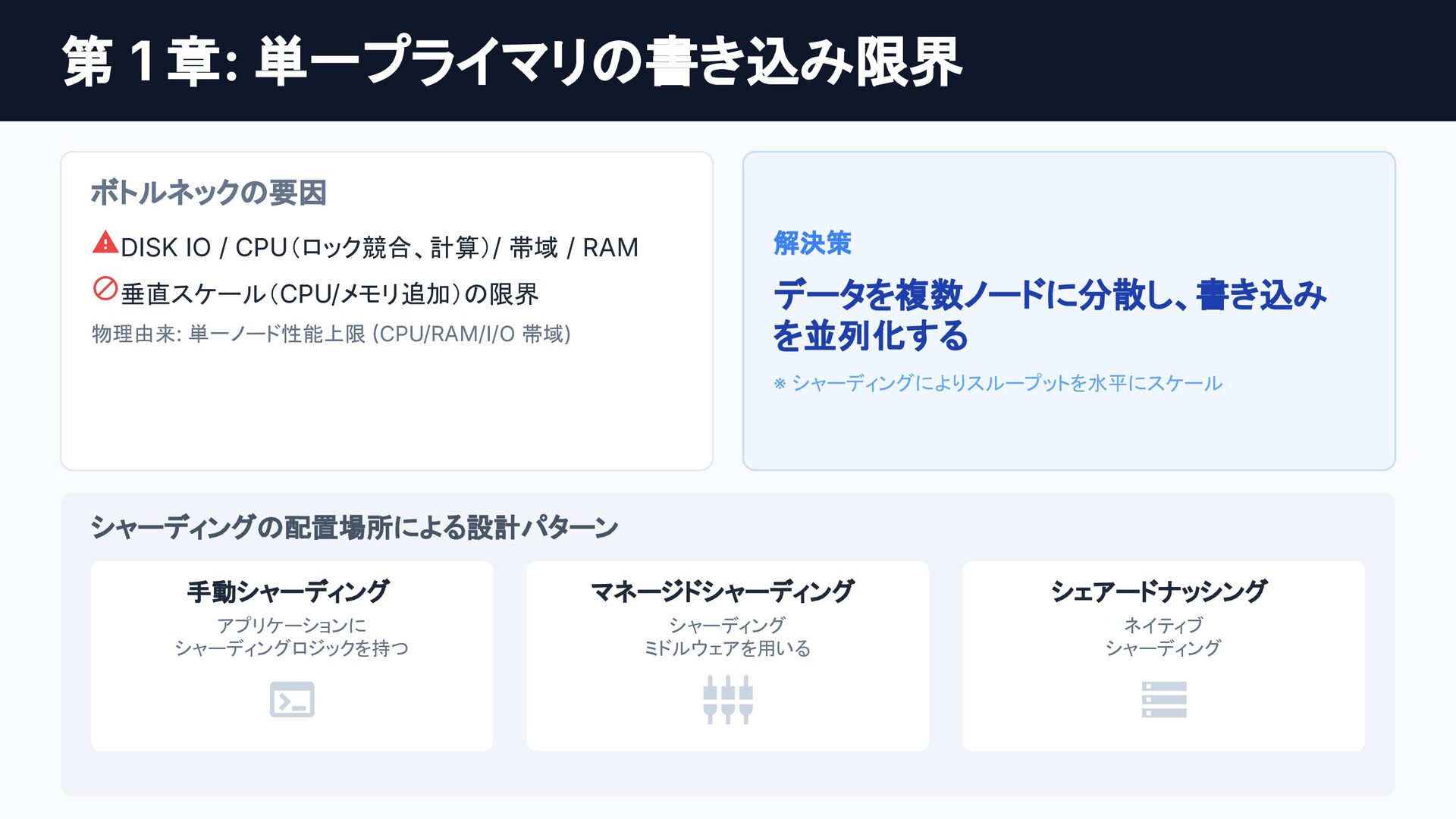
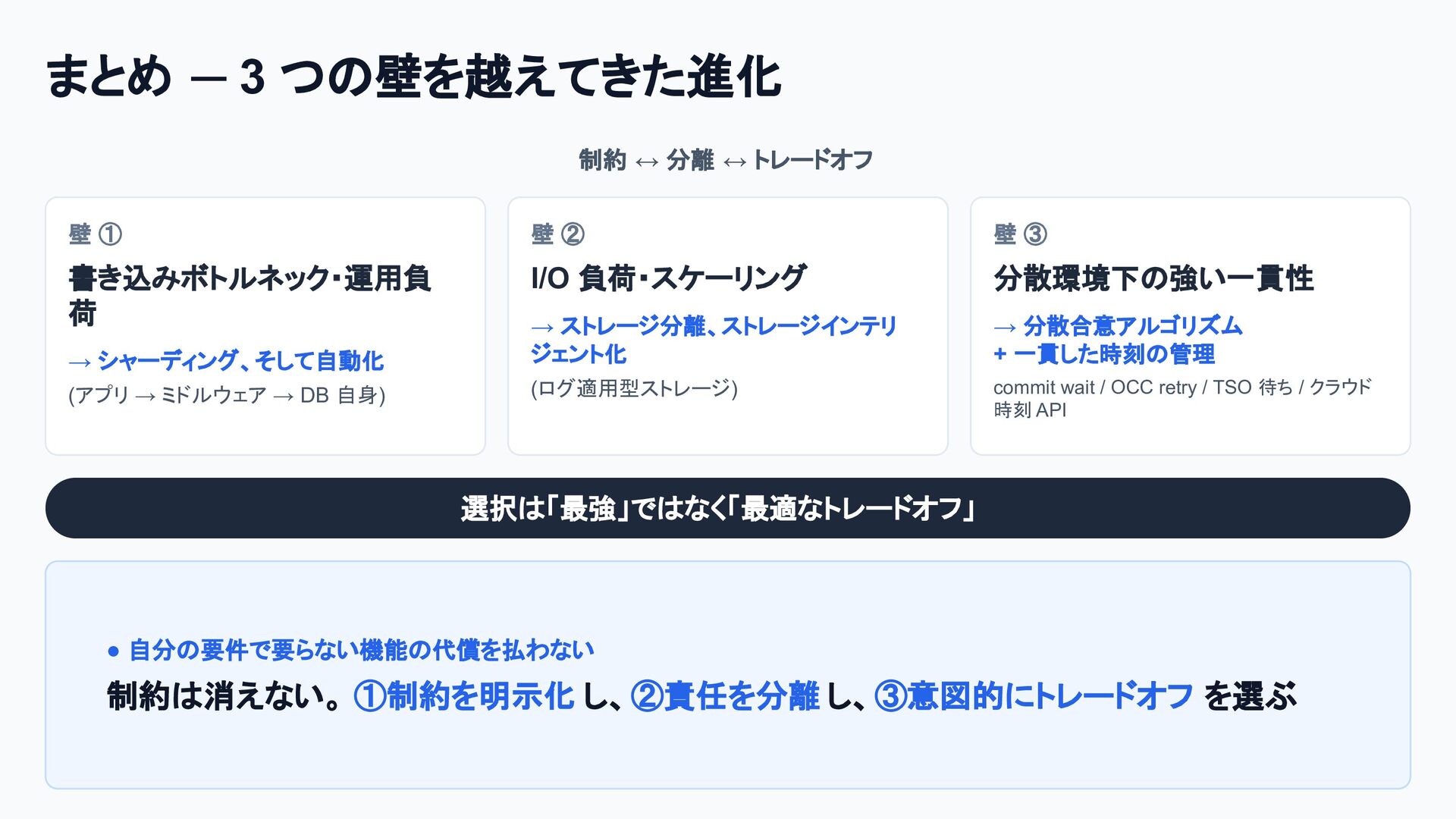
クラウドネイティブなデータベースへの進化の歴史は、そのまま「分散システムにおける物理制約との戦い」であり、スケーラブルなシステム設計の最高の教科書です。
従来のRDBMSはコンピュートとストレージの密結合が限界を生んでいました。これを打開したAmazon Auroraは、「THE LOG IS THE DATABASE」の思想で分離でスケーラビリティを、
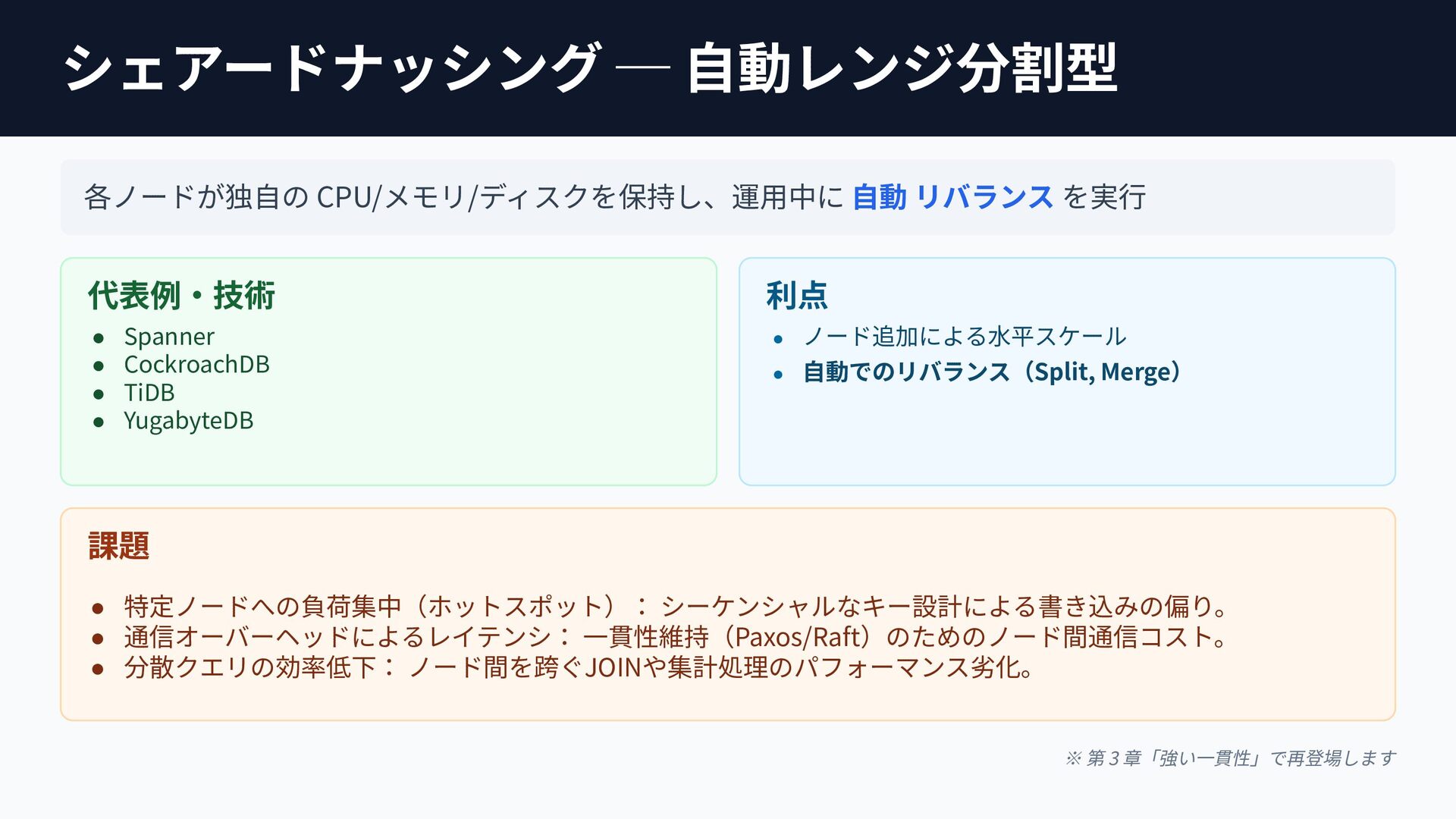
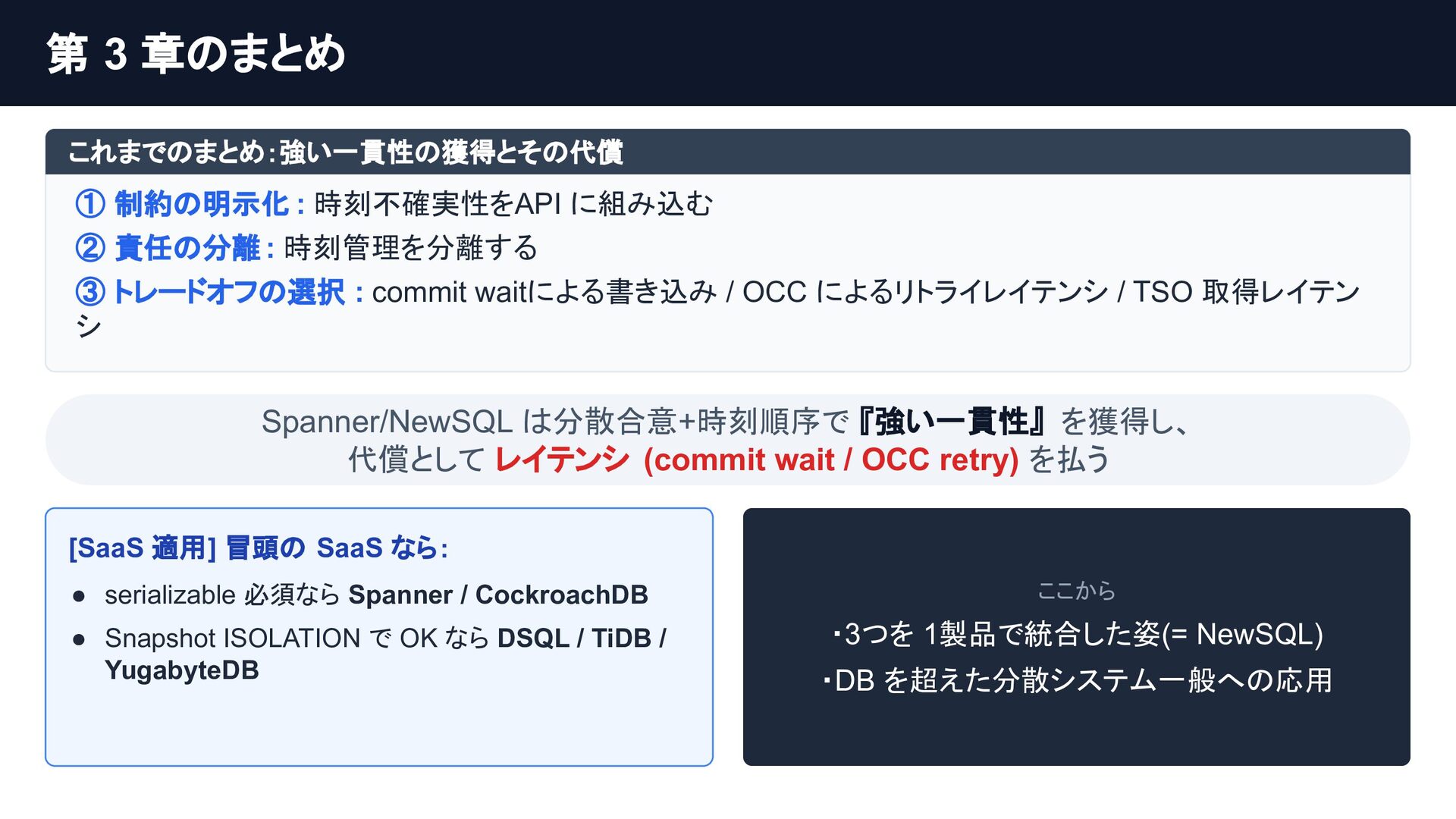
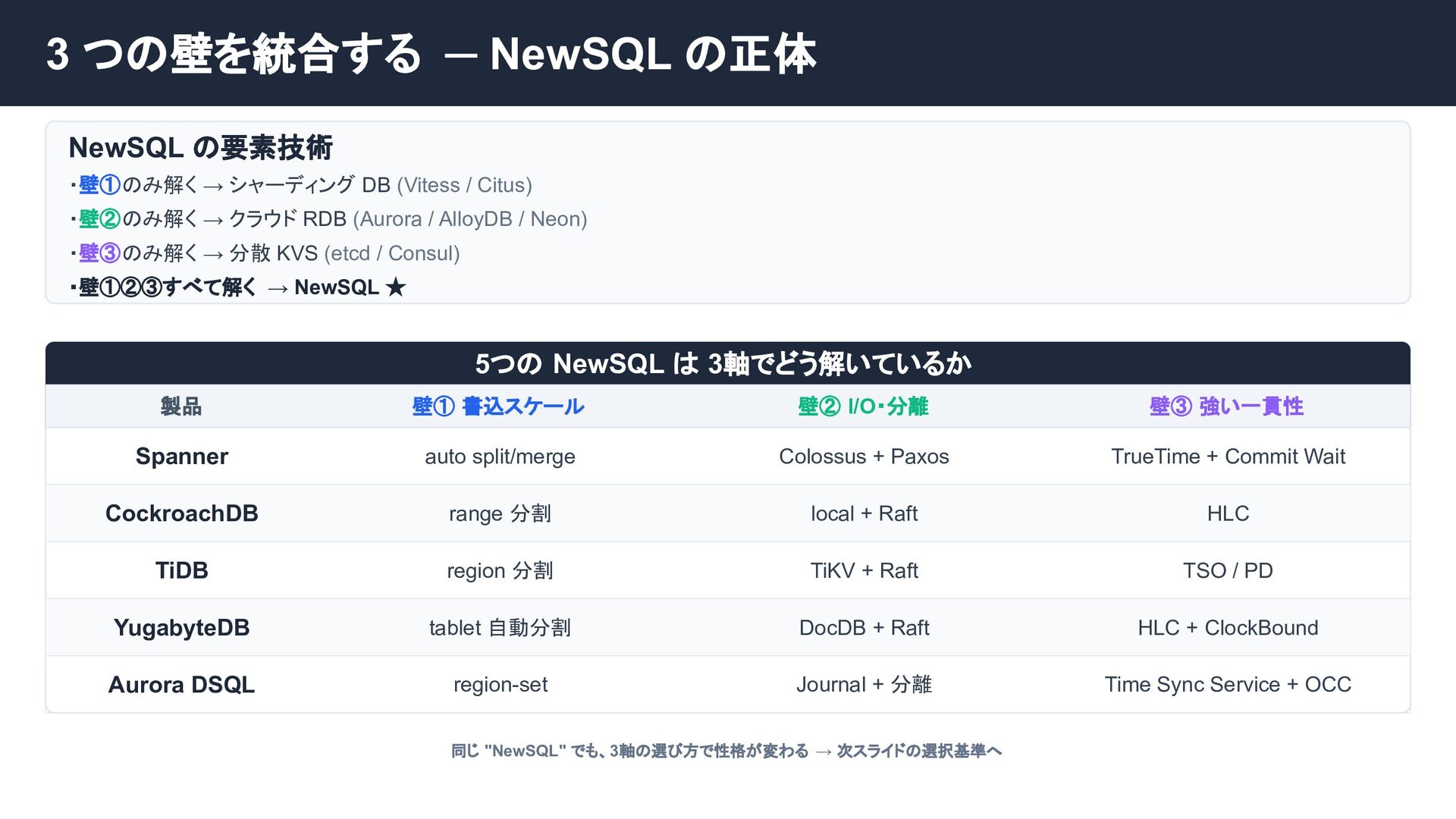
Google SpannerやNewSQLは、TrueTime APIやPaxos/Raftの分散合意アルゴリズムで分散環境の強整合性を獲得し、トレードオフとしてレイテンシーを犠牲にしました。
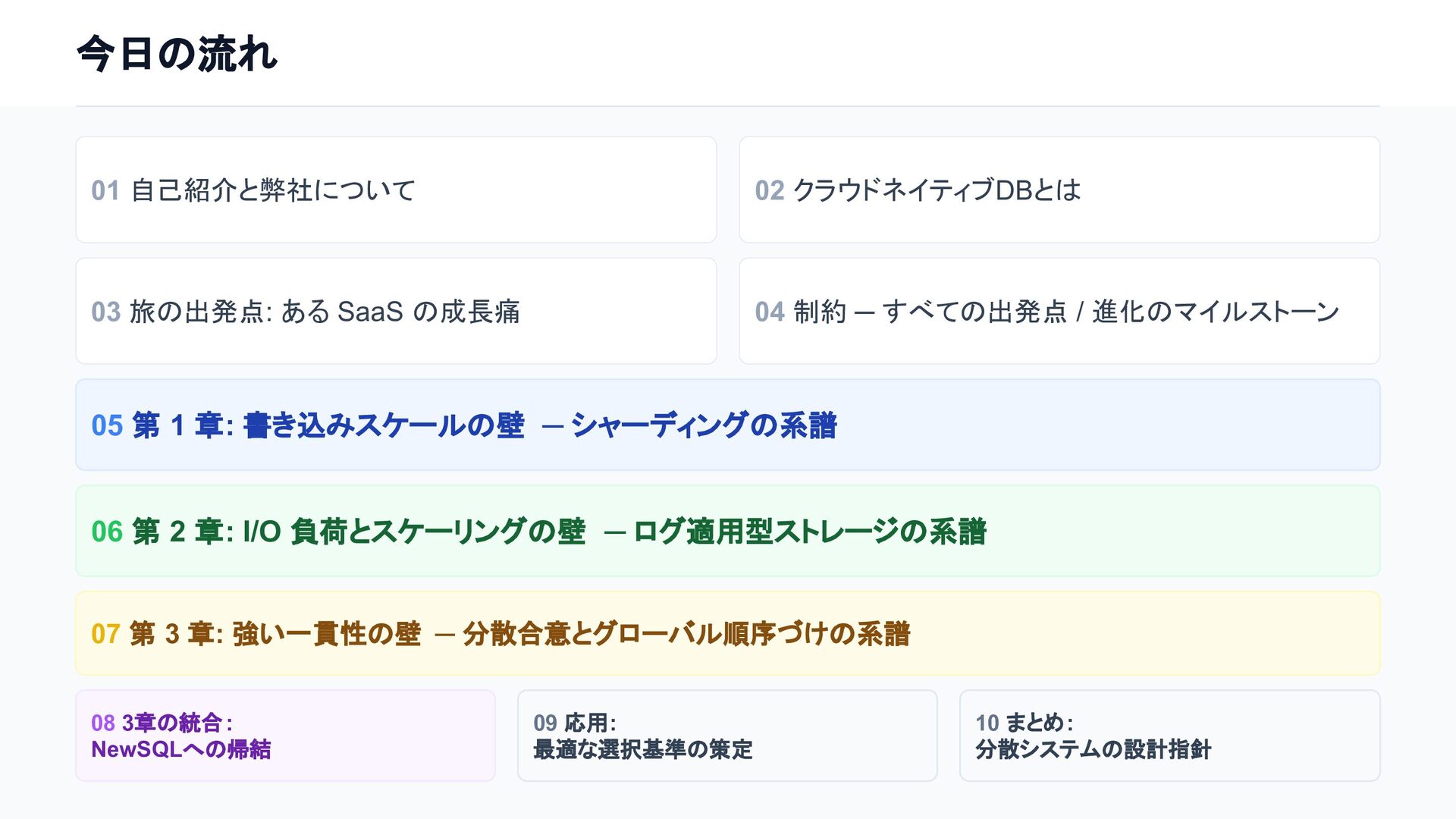
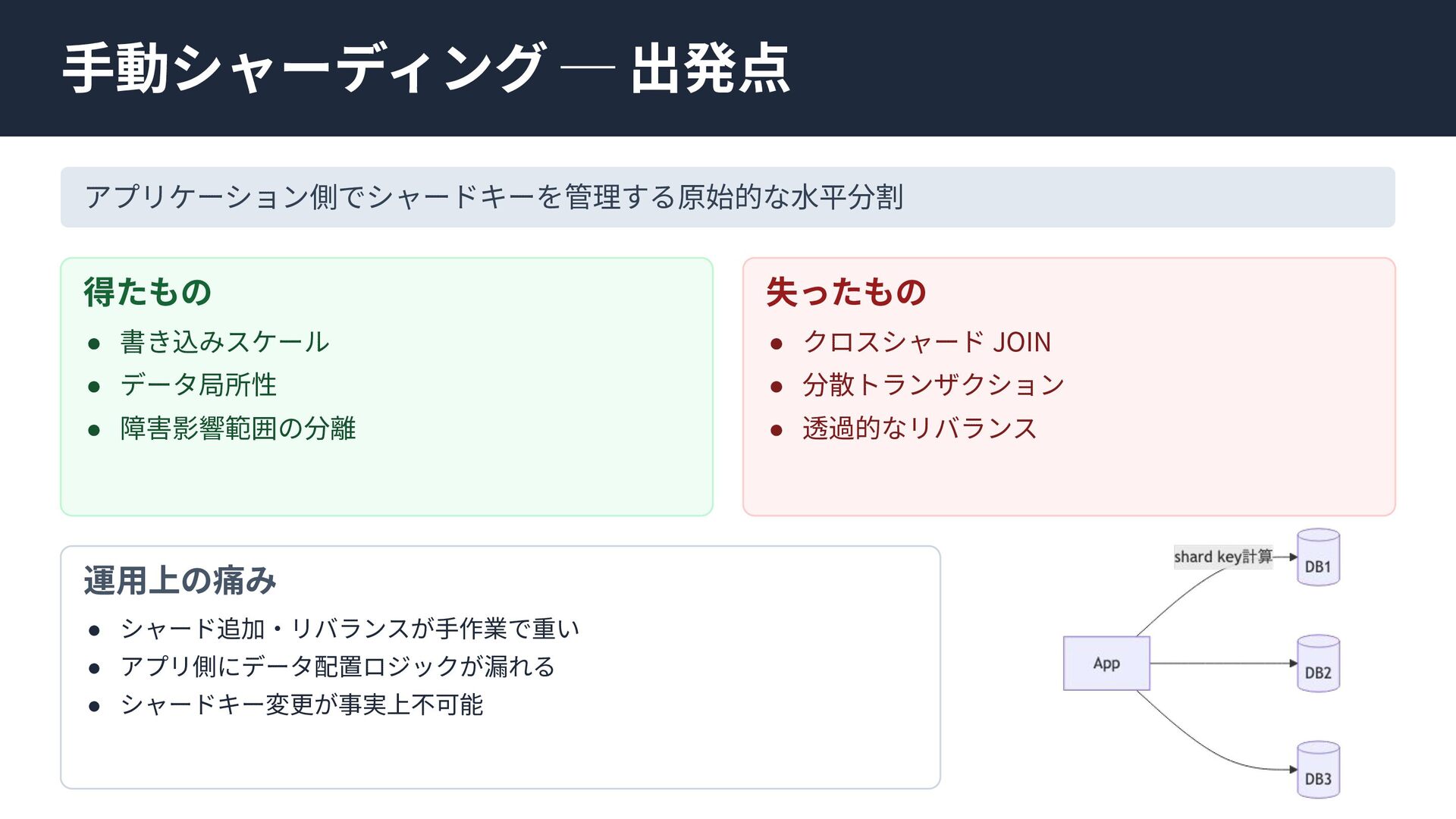
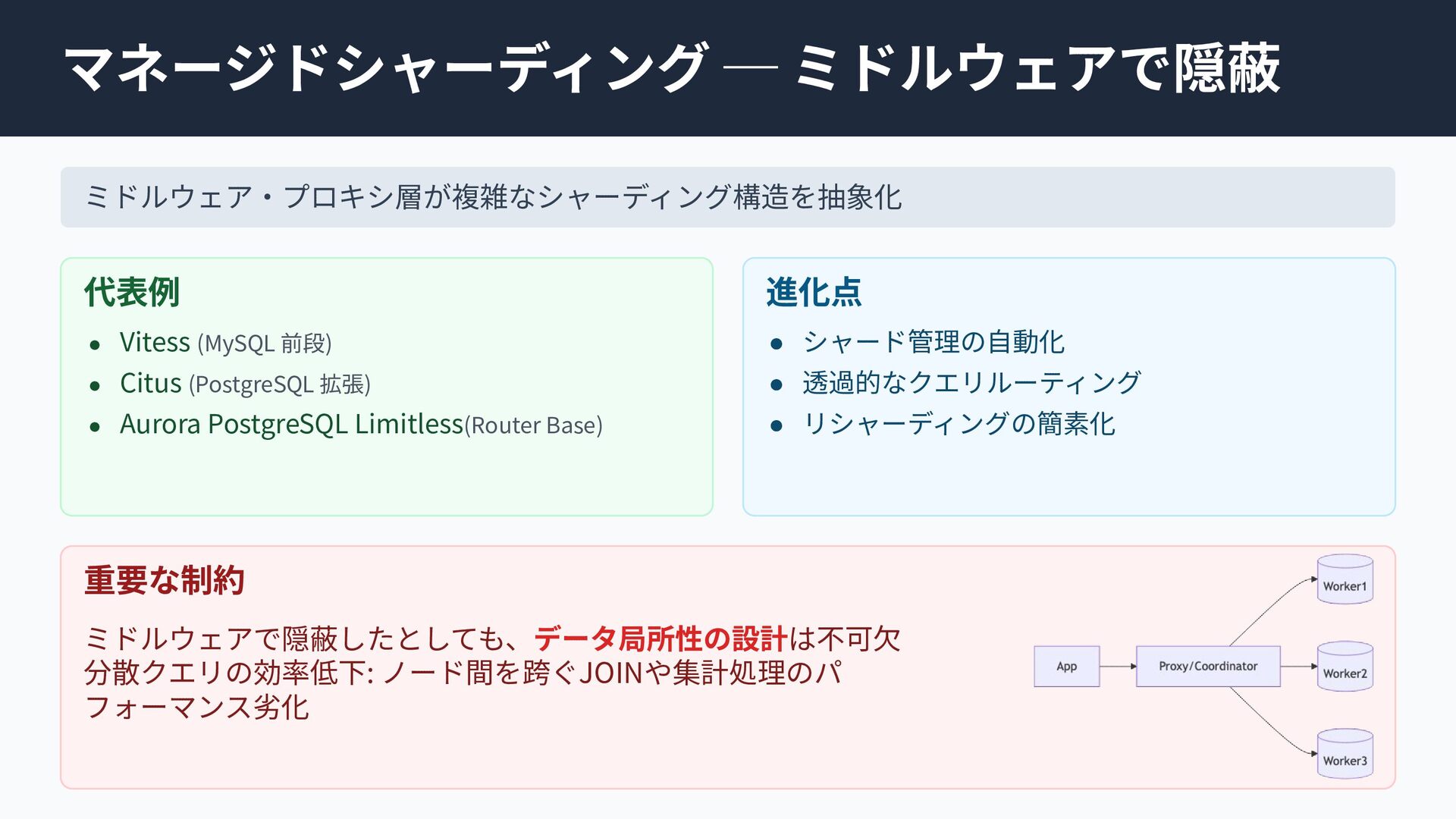
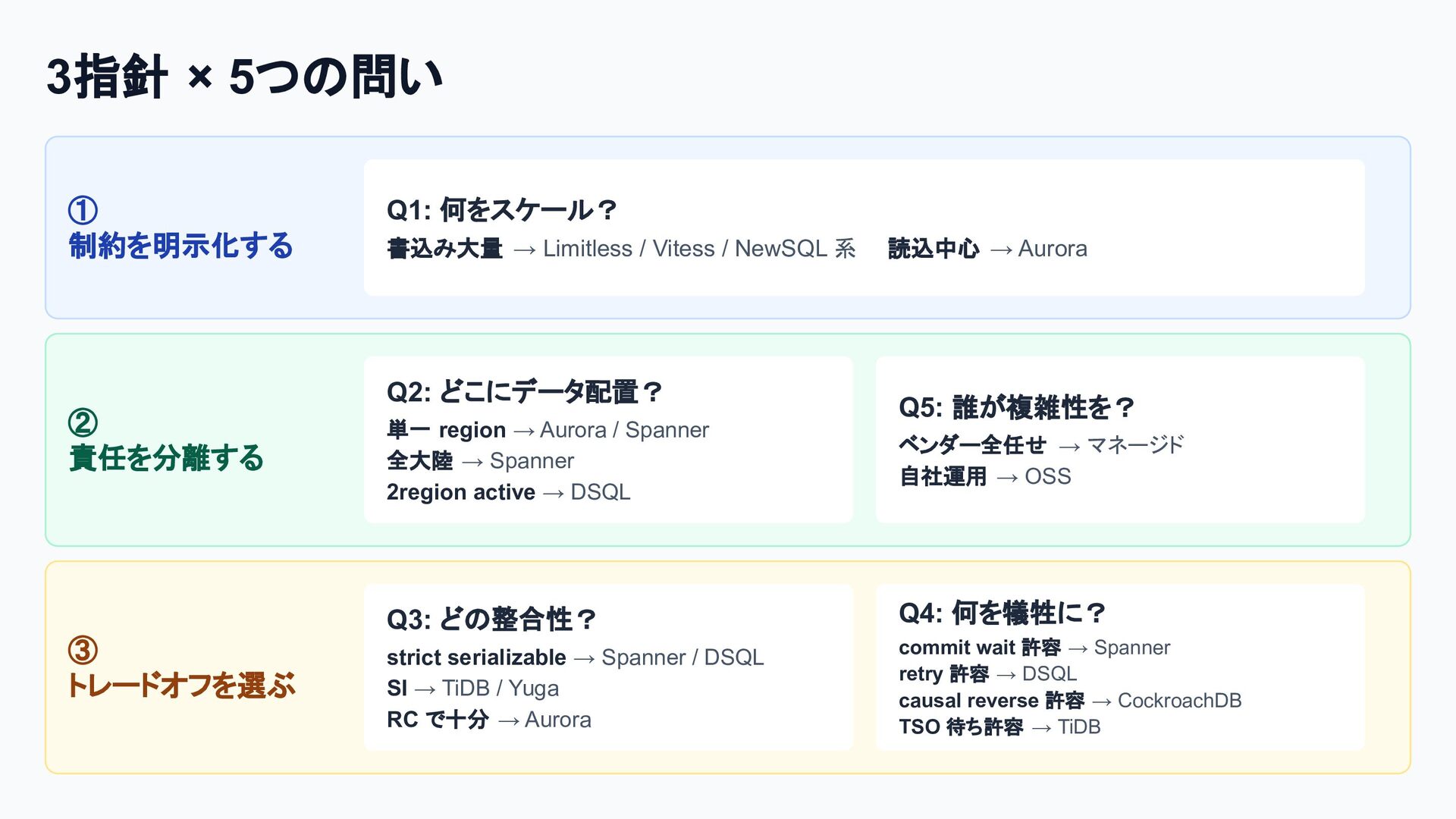
個別の要素技術や論文は知られていても、「どのような課題を乗り越え、結果としてどのようなトレードオフを選び現在に至ったのか」という全体像は意外にも体系化されていません。
本セッションでは点在する論文や技術仕様を線で繋ぎ合わせ、巨大な分散システムがいかに物理制約を克服してきたかDeep Diveします。「なぜスケールし、何を犠牲にするのか」この理解はDB選定の枠を超え、マイクロサービス等あらゆる分散システム設計の指針となるはずです。
https://event.cloudnativedays.jp/cnk/talks/2859
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
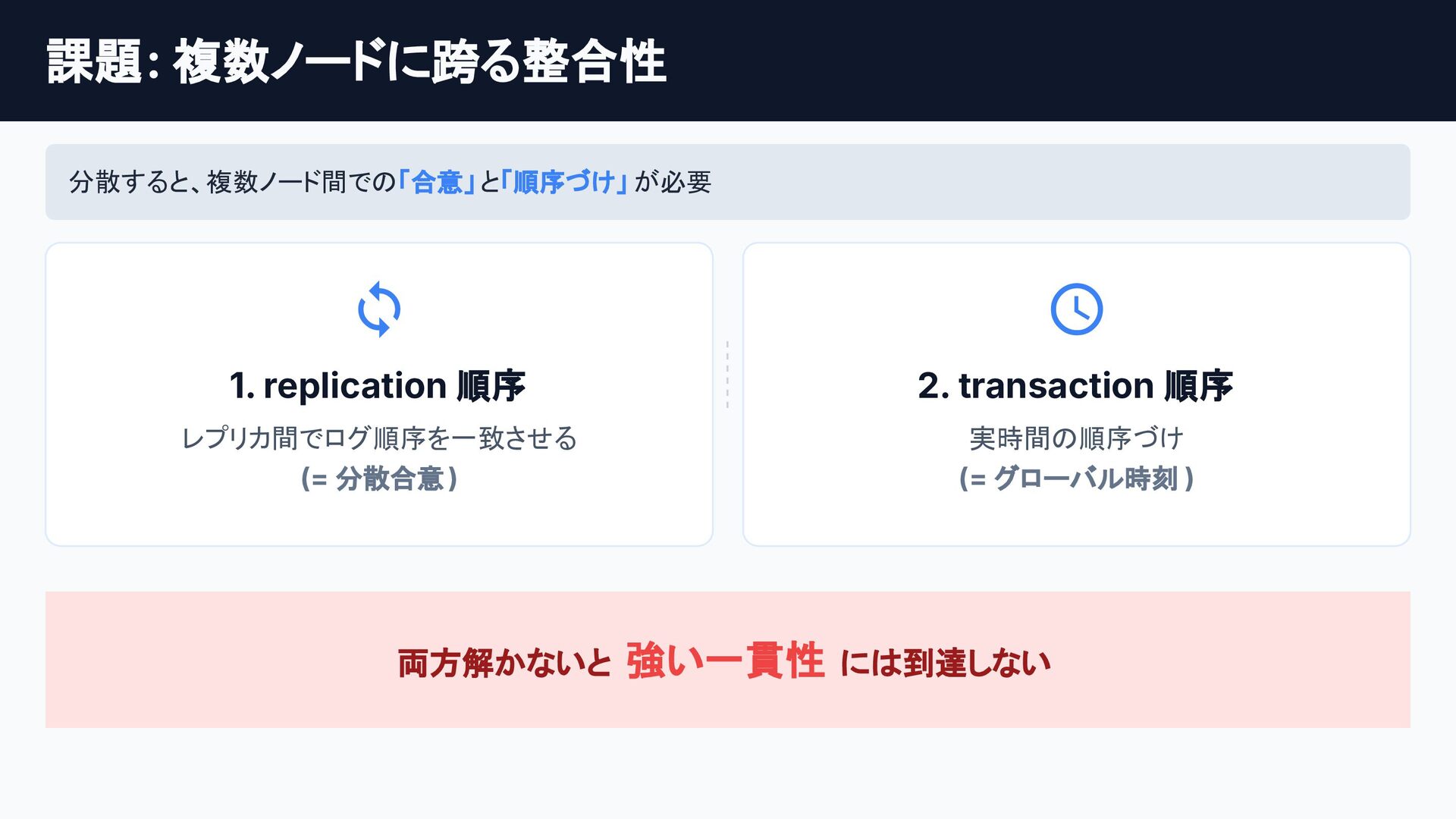
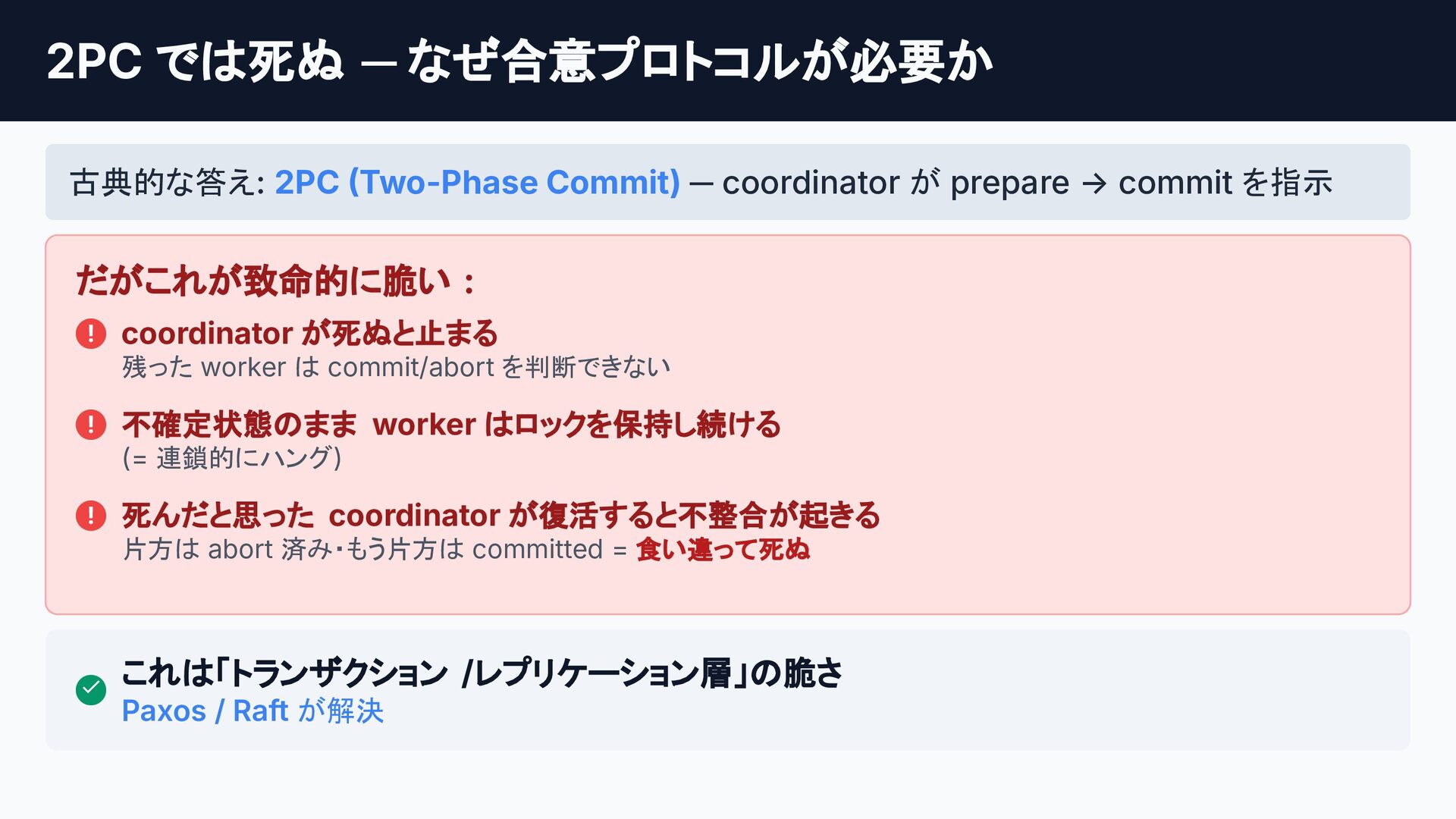
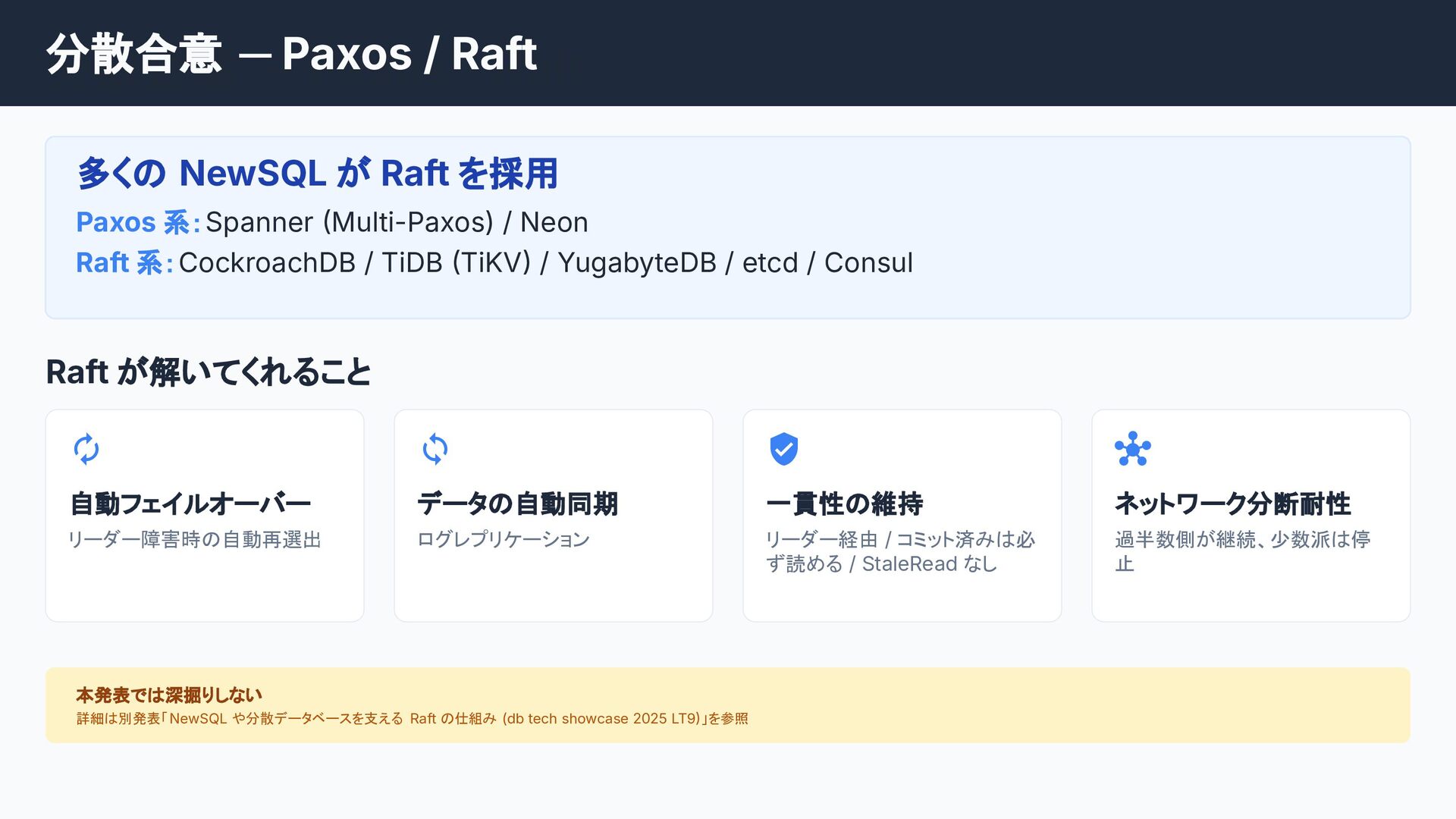
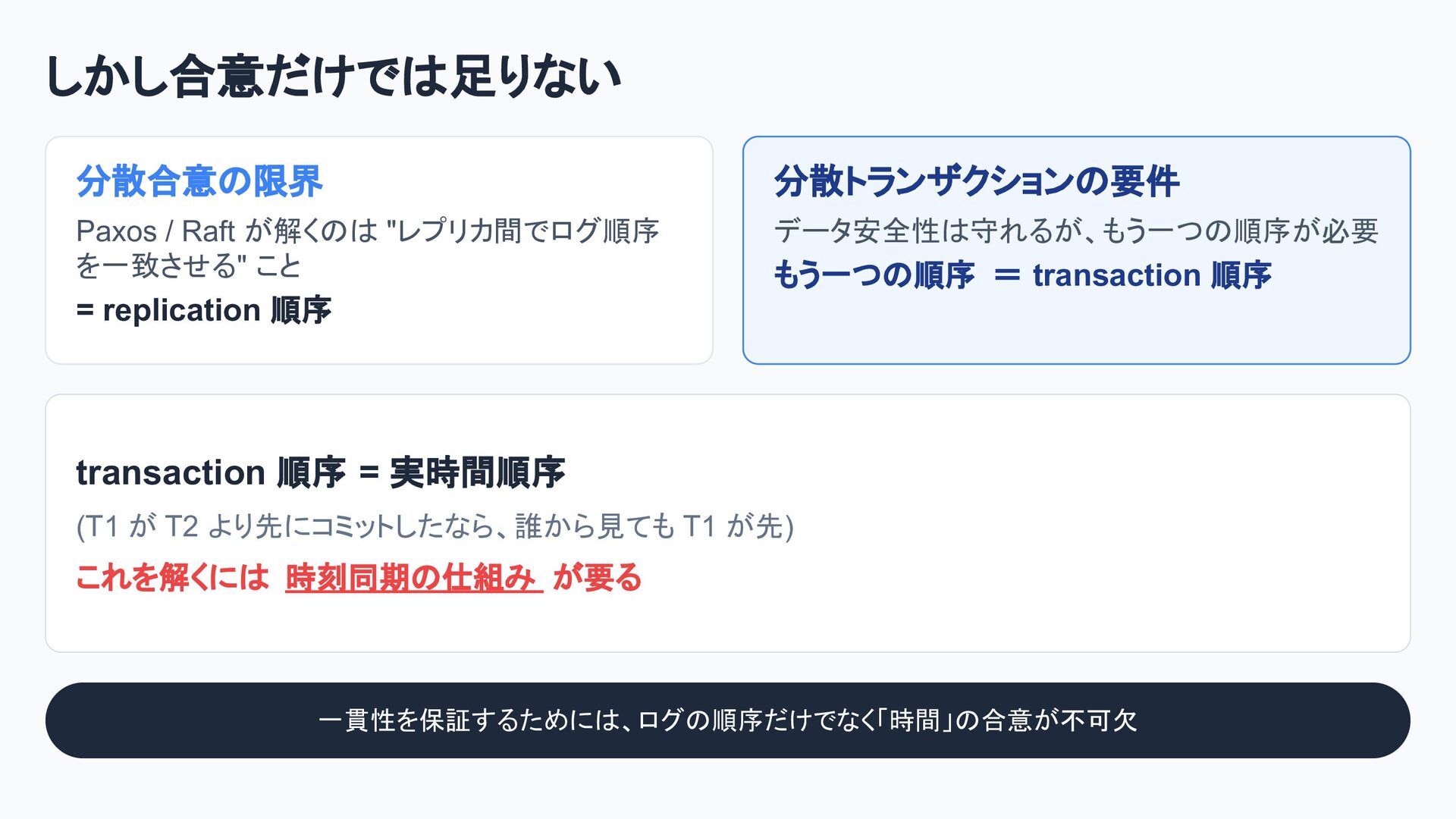
![第 3 章: 強い⼀貫性の壁 [現在地] 第3章のロードマップ STEP 1 課題: 複数ノードに跨る整合性](https://files.speakerdeck.com/presentations/a846f92fee554612ab4668ff957d86a9/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![基本概念: 時刻を「区間」として扱う 時刻を [earliest, latest] の区間として定 義。クロックの不確実性 (ε) を API](https://files.speakerdeck.com/presentations/a846f92fee554612ab4668ff957d86a9/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}