Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
独自アクセスログ基盤の構築
Search
Recruit
PRO
February 27, 2026
Technology
320
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
独自アクセスログ基盤の構築
2026/2/27に、RECRUIT TECH CONFERENCE 2026で発表した山本の資料になります。
Recruit
PRO
February 27, 2026
More Decks by Recruit
See All by Recruit
AIネイティブ時代における 開発組織の役割と拡張の可能性
recruitengineers
PRO
2
120
開発が速く安くなった後の話 AI時代のソフトウェアエンジニアリング組織論 #devsumi
recruitengineers
PRO
39
28k
双方向推薦システムにおける長期的マッチング最大化に向けた代理目的関数の設計と実証
recruitengineers
PRO
1
150
就職⽀援サービスにおけるキャリアアドバイザーのシフトスケジューリング
recruitengineers
PRO
1
200
Model Routerを使った逐次LLM選択による毀損低減効果の検証
recruitengineers
PRO
2
76
ストリーム処理基盤のFlink移行検証と適材適所の実践
recruitengineers
PRO
2
120
AI 時代の Platform Engineering
recruitengineers
PRO
3
500
巨大プラットフォームを進化させる「第3のROI」
recruitengineers
PRO
2
3.7k
データ戦略を加速させる プラットフォーム エンジニアリングと進化的アーキテクチャ
recruitengineers
PRO
3
130
Other Decks in Technology
See All in Technology
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
240
OPENLOGI Company Profile for engineer
hr01
1
74k
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
250
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
3
590
Data + AI Summit 2026 イベントレポート: 「AIがビジネスで意思決定するデータ基盤」へ
nek0128
0
300
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
200
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
480
Amazon Quick 入門!
ysuzuki
2
120
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
280
Jitera Company Deck
jitera
0
250
GoでCコンパイラを作った話
repunit
0
150
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
1
600
Featured
See All Featured
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
Automating Front-end Workflow
addyosmani
1370
210k
Designing for Timeless Needs
cassininazir
1
390
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Context Engineering - Making Every Token Count
addyosmani
9
1k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
WENDY [Excerpt]
tessaabrams
11
38k
Bash Introduction
62gerente
615
220k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
Transcript
RECRUIT TECH CONFERENCE 2026 マッチング技術の進化 独自アクセスログ基盤の構築 インディードリクルートテクノロジーズ 山本 航平
山本 航平 ホラー映画鑑賞 経歴 / Career 2019年にリクルートテクノロジーズ(現リクルート)に キャリア入社。 人材領域のデータ基盤の開発運用を担当しています。 趣味
/ Hobbies (株)インディードリクルートテクノロジーズ HRプロダクト データ データソリューションユニット データエンジニアリング部
今日の内容をざっくり3行で 人材領域で利用しているアクセス解析ツールを、 独自のログ収集基盤にリプレースし、 コスト / 保守性 / データ鮮度の3つが GOOD な状態にしました
Agenda 1. 背景と課題 2. 解決 3. 結果
Agenda 1. 背景と課題 2. 解決 3. 結果
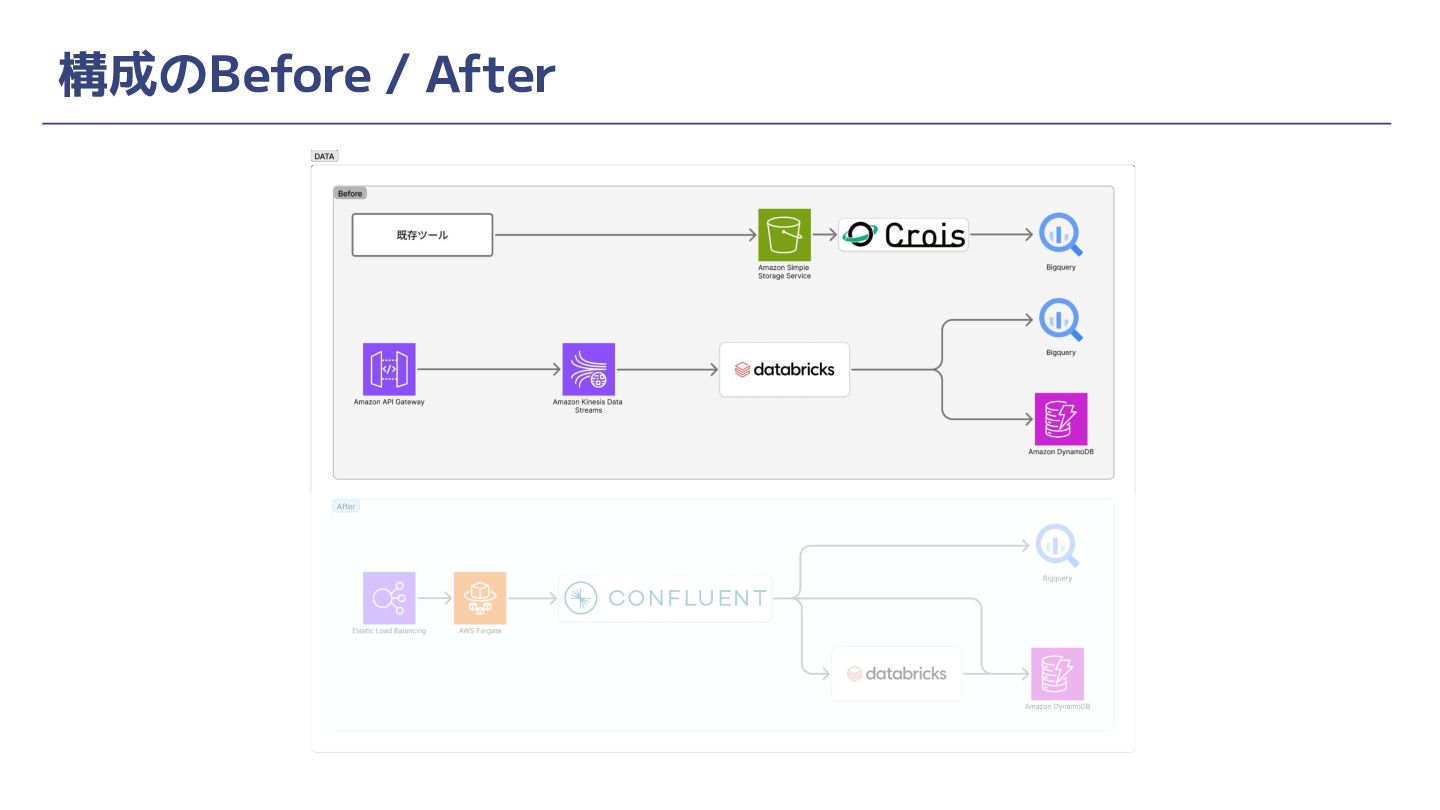
背景と課題 人材領域で生じていたアクセスログの3つの課題 ① ログ設計の管理が横断的にできていない ② データウェアハウスで分析可能になるまでのリードタイムが長い ③ アクセス解析と機械学習でログを二重取得しており効率が悪い
背景と課題 ① ログ設計の管理が横断的にできていない • 施策ごと(ABテストや、画面改修等)にadhocにログ設計と追加をしているため、プロダ クト横断でのログ設計思想がない • 施策担当者やプロダクトごとに設計がブレてしまい、データマートでの利用の都度仕様の キャッチアップと検算から入らなければならない
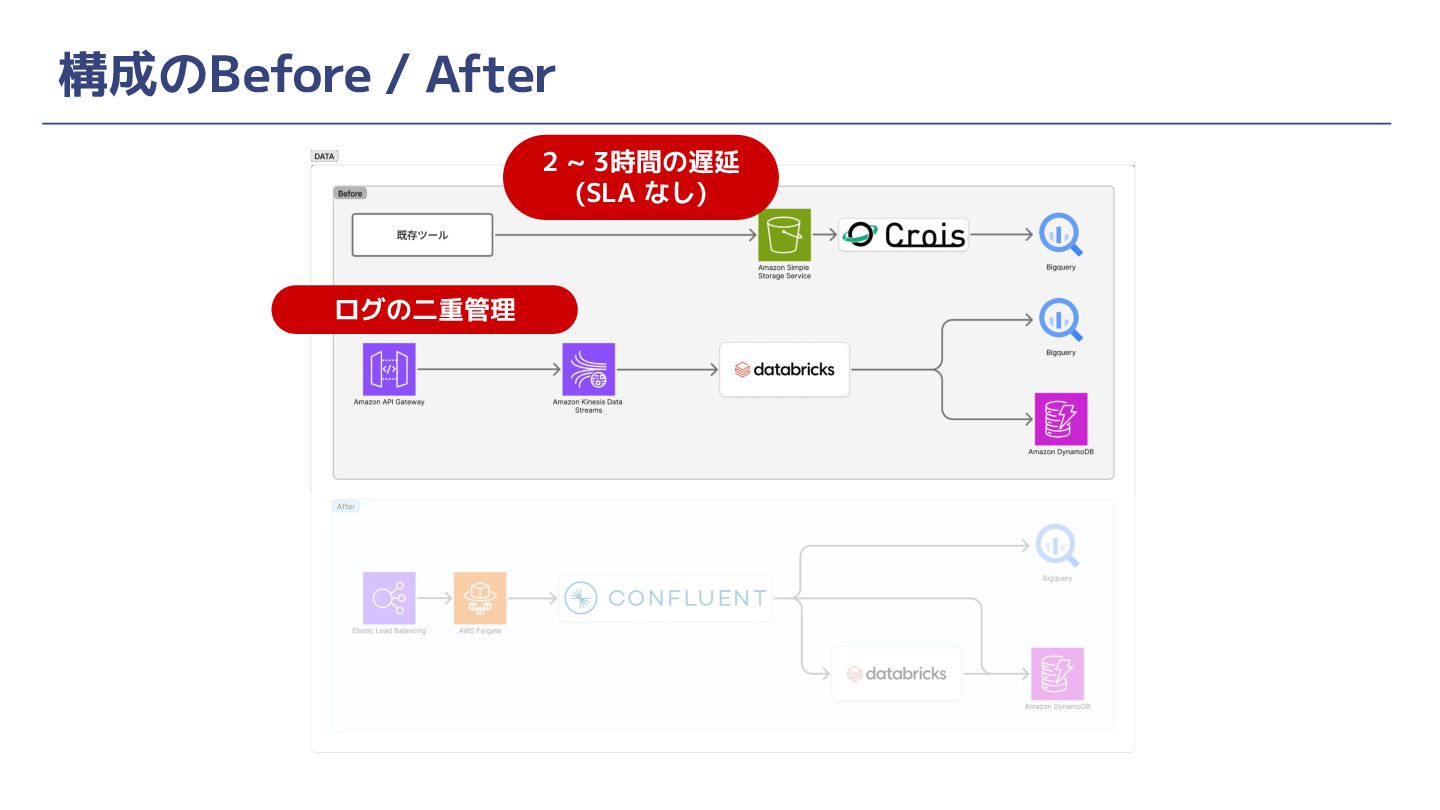
背景と課題 ② データウェアハウスで分析可能になるまでのリードタイムが長い • アクセス解析ツール上ではニアリアルタイムにデータ更新されるが、データウェアハウスに ある他データと組み合わせないとできない分析が多数ある • そのためアクセス解析ツールに付帯しているExport機能を使ってデータをデータウェアハ ウス(BigQuery)に連携して分析利用している •
このExport機能にサービスレベルがなく、だいたい2~3時間後にデータが入ってくるだろ うという経験則での運用になっていた(かつ遅い)
背景と課題 ③ アクセス解析と機械学習でログを二重取得しており効率が悪い • 前ページに記載した制約(2~3hの遅延)があるため、機械学習施策でのニアリアルタイム なデータ活用に対してデータ鮮度が要求を満たさない • 機械学習用の別データパイプラインを構築することになり、結果、アクセスログを二重取得 している状態になっていた
Agenda 1. 背景と課題 2. 解決 3. 結果
解決 基盤刷新とセットでログ設計運用の見直しをする • 課題を同時に解決するため、ログ収集基盤の刷新を決定 • 既存サービスを継続利用することも考えたが、課題③の解決や、インフラコストを大幅に削 減できる見立て(現行の10~20%程度まで下がる)があったため、独自基盤を作る方向と なった • アクセス解析ツールが入っているサービス側のリアーキテクチャが同時期に実行されていた
ため、そことタイミングを合わせることで導入をスムーズにした
構成のBefore / After
構成のBefore / After ログの二重管理 2 ~ 3時間の遅延 (SLA なし)
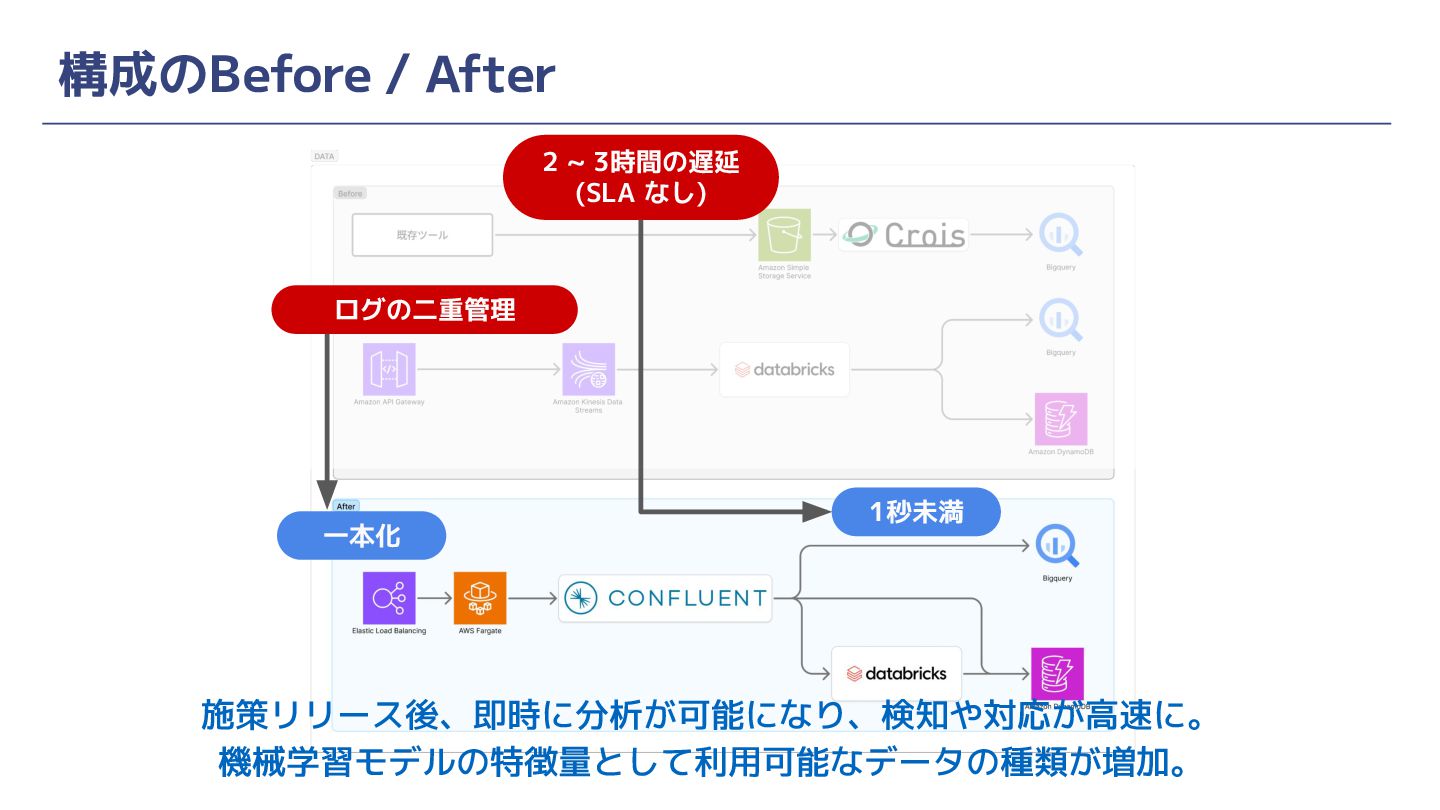
構成のBefore / After ログの二重管理 2 ~ 3時間の遅延 (SLA なし) 1秒未満
一本化 施策リリース後、即時に分析が可能になり、検知や対応が高速に。 機械学習モデルの特徴量として利用可能なデータの種類が増加。
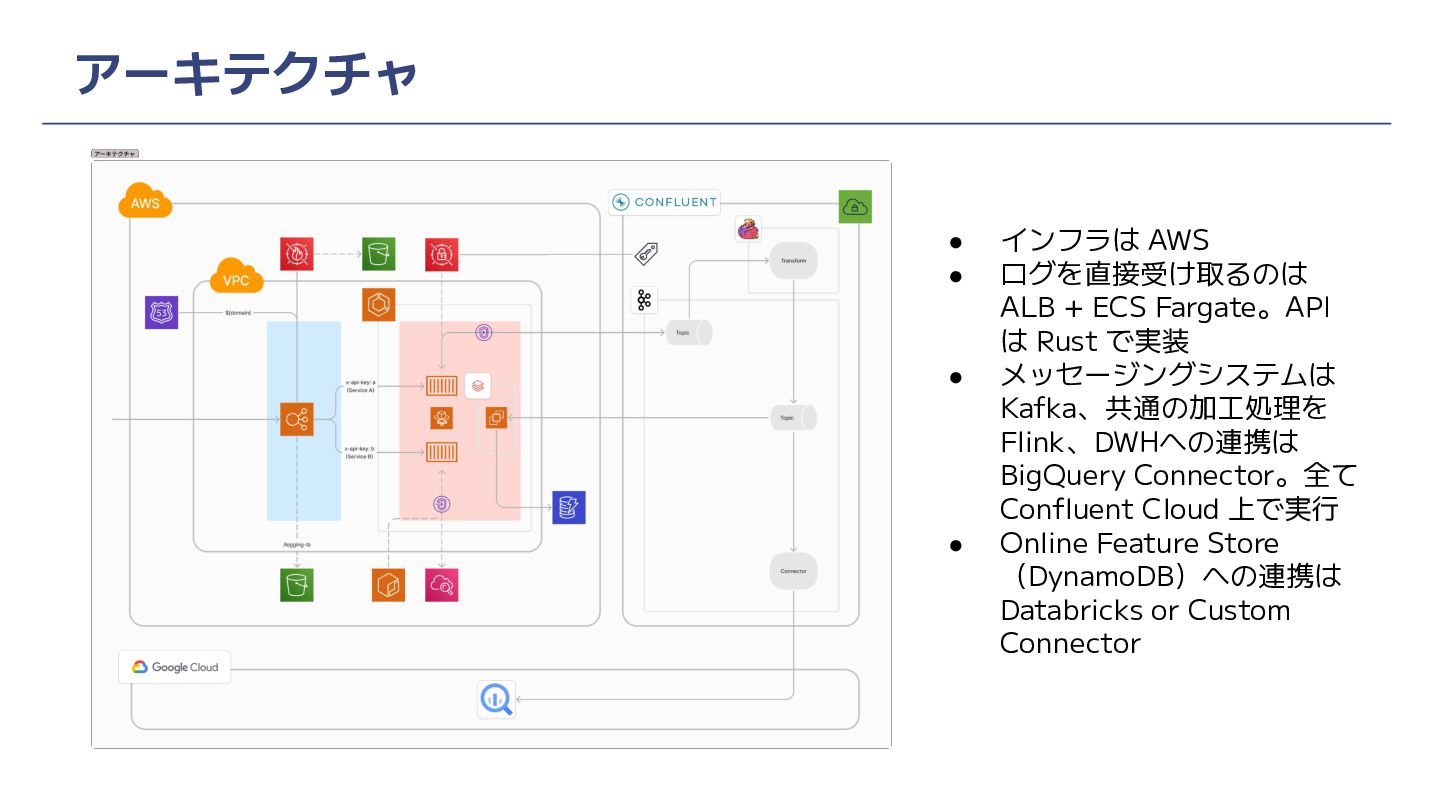
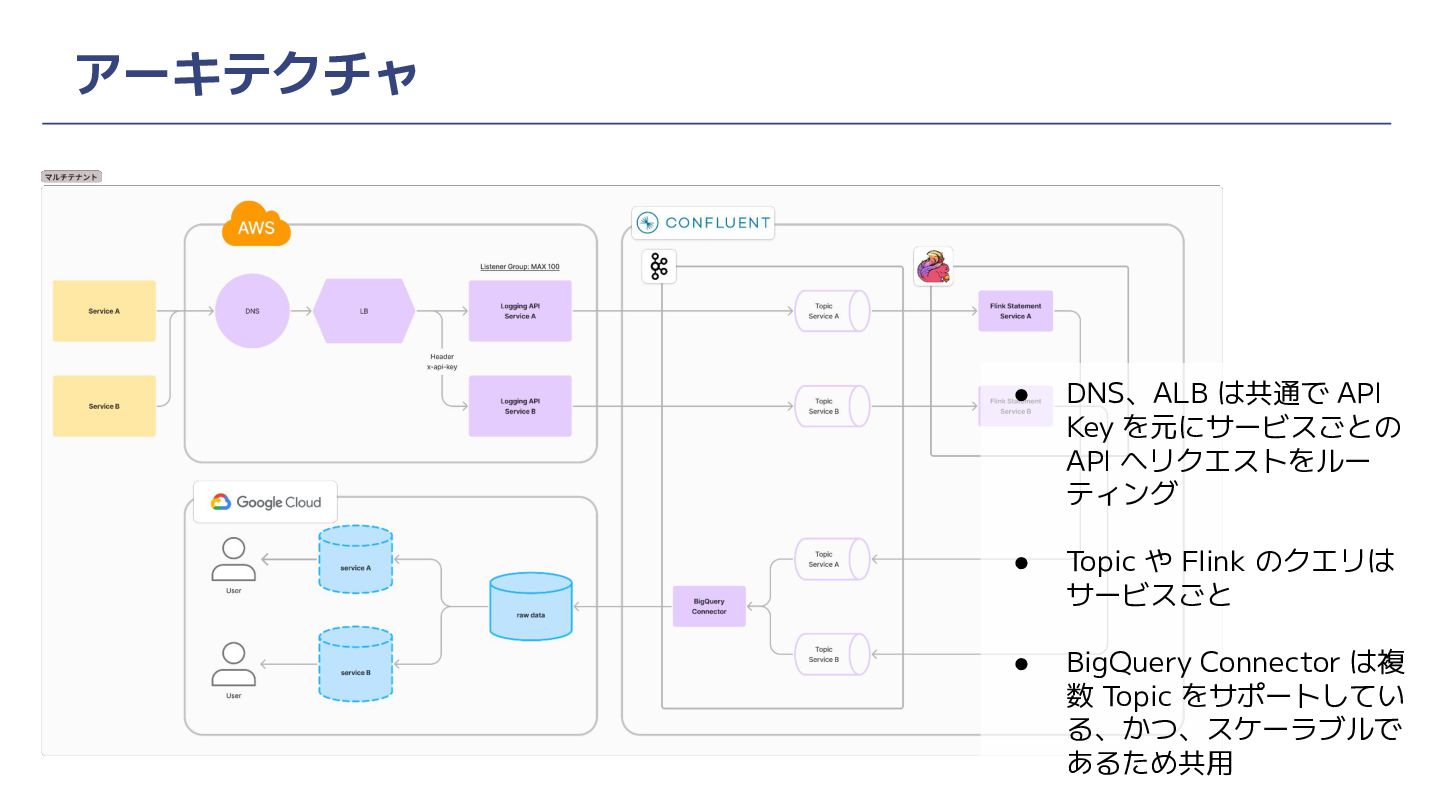
アーキテクチャ • インフラは AWS • ログを直接受け取るのは ALB + ECS Fargate。API
は Rust で実装 • メッセージングシステムは Kafka、共通の加工処理を Flink、DWHへの連携は BigQuery Connector。全て Confluent Cloud 上で実行 • Online Feature Store (DynamoDB)への連携は Databricks or Custom Connector
アーキテクチャ • DNS、ALB は共通で API Key を元にサービスごとの API へリクエストをルー ティング
• Topic や Flink のクエリは サービスごと • BigQuery Connector は複 数 Topic をサポートしてい る、かつ、スケーラブルで あるため共用
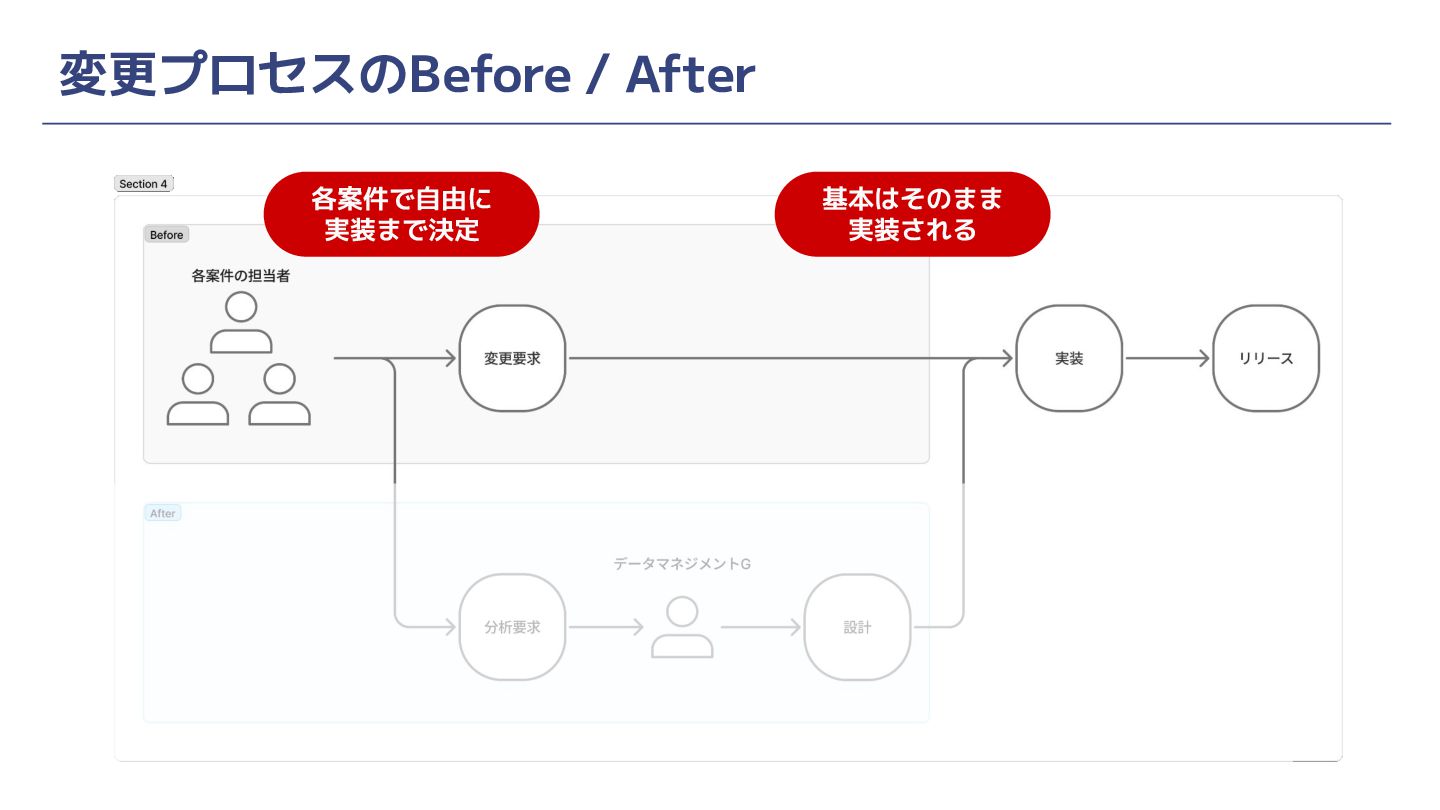
変更プロセスのBefore / After 各案件で自由に 実装まで決定 基本はそのまま 実装される
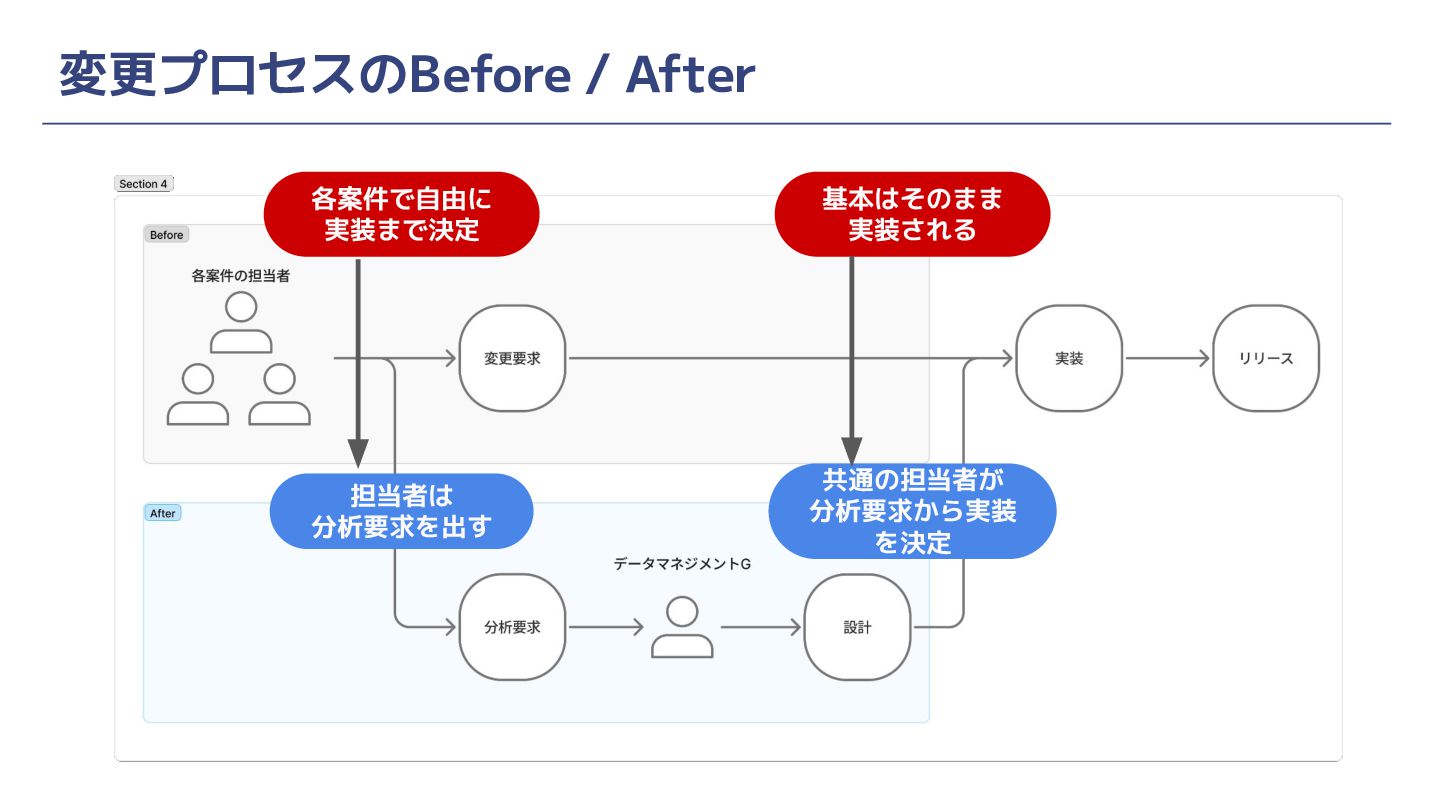
変更プロセスのBefore / After 各案件で自由に 実装まで決定 基本はそのまま 実装される 担当者は 分析要求を出す 共通の担当者が
分析要求から実装 を決定
Agenda 1. 背景と課題 2. 解決 3. 結果
結果 ① ログ設計の管理が横断的にできていない ② データウェアハウスで分析可能になるまでのリードタイムが長い ③ アクセス解析と機械学習でログを二重取得しており効率が悪い 🟢 基盤刷新に合わせてフローを刷新し集約された管理を確立 🟢
一本化して二重取得を撤廃。コスト面も既存の10~20%程度まで圧縮 🟢 2~3h → 数秒まで短縮
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}