10 // type inferred val b = 10 // immutable b = 5 // will throw an error Defining functions def sum(a: Int, b: Int) = a + b def sumOfSquares(x: Int, y: Int) = { val x2 = x * x val y2 = y * y x2 + y2 } (x: Int) => x * x //anonymous function Collections val list = List(1,2,3,4,5) list.foreach(x => println(x)) list.foreach(println) list.map(x => x + 2) list.map( _ + 2 ) list.filter(x => x % 2 == 0) list.filter( _ % 2 == 0) Notebook
to MapReduce - Apply transformations on distributed dataset - In memory computation - Support for both stream and batch jobs - Storage: HDFS, S3, Cassandra - Cluster manager: Standalone, Yarn and Mesos
data - Partitions needn’t fit on a single machine - Resides on the executors - Can be kept in memory - faster execution - Fault tolerant - recomputed on failure - Operations registered in DAG Resilient Distributed Datasets (RDDs)
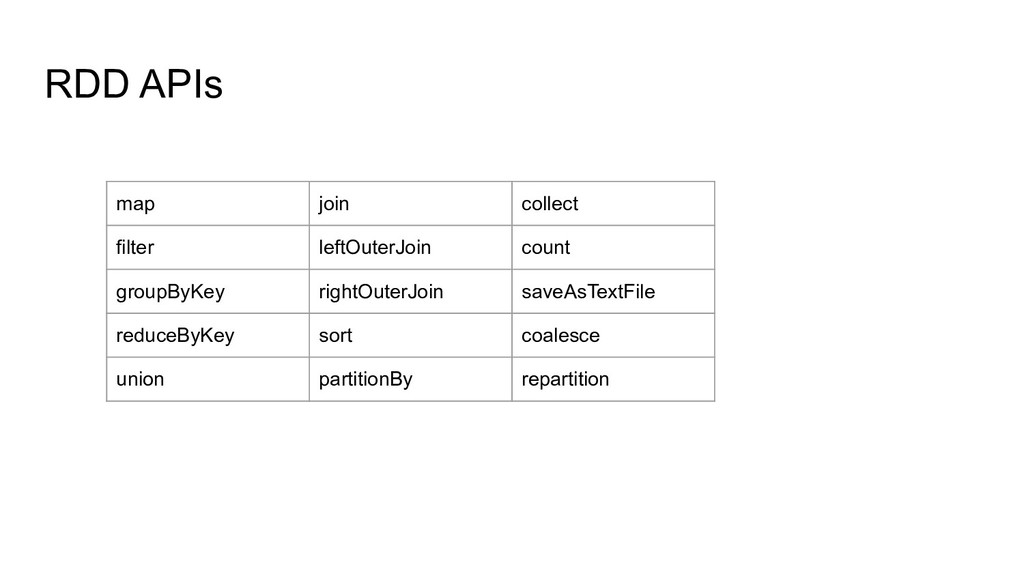
join) - Actions (count, collect, save) - Lazy evaluation rdd .map{ r => r + 2 } .filter{ r => r > 8 } //Doesn’t do two passes over the rdd .saveAsTextFile(“s3://….”)
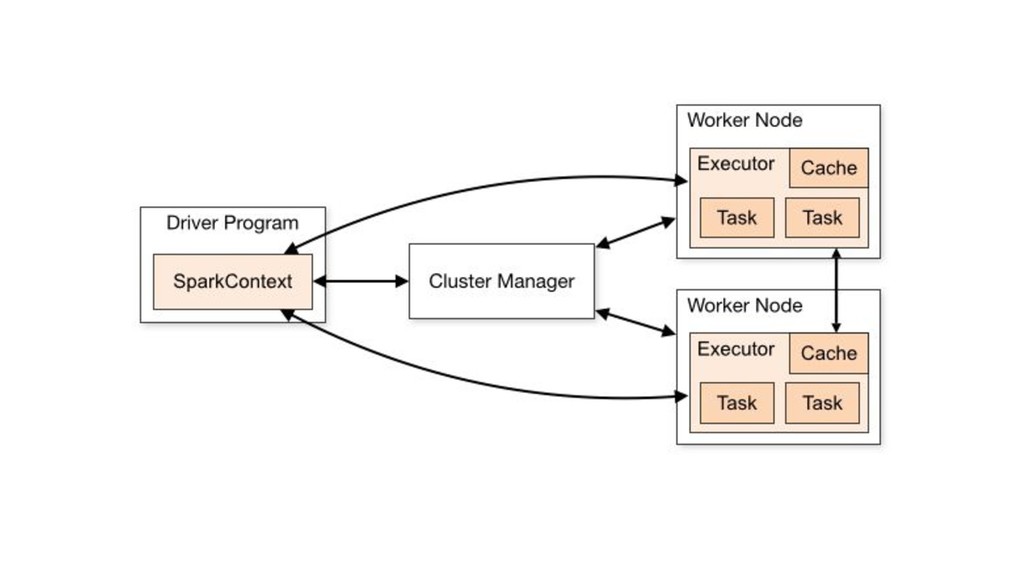
= lines.filter(_.contains("ERROR")) val messages = errors.map(_.split('\t')(2)) messages.cache() messages .filter(_.contains(“parse error”)) // transformation .count() // action - computes the RDD Driver submits tasks Executors read from disk Processes and caches data Results collected at the driver
= lines.filter(_.contains("ERROR")) val messages = errors.map(_.split('\t')(2)) messages.cache() messages.filter(_.contains(“parse error”)).count() messages.filter(_.contains(“read timeout”)).count() Driver submits tasks Executors read and process data from cache Results collected at the driver
lowercase words. (wordCount.txt) b. Take other tokens as separators (, -) (wordCount2.txt) 2. Tweets Analysis with RDDs (donaldTrumpTweets) a. Count the number of tweets with mentions (@user) b. Tweets per year 3. Tweets Analysis (Dataframes) (tweets.json) a. Count the number of tweets per country b. User with the maximum number of tweets c. Find all mentions on tweets d. How many times has each person been mentioned? e. Top 5 mentions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![WordCount Example def wordCount(rdd: RDD[String]) = { val words =](https://files.speakerdeck.com/presentations/89bdeddbb8e649f99371a68e7baf0e2f/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}