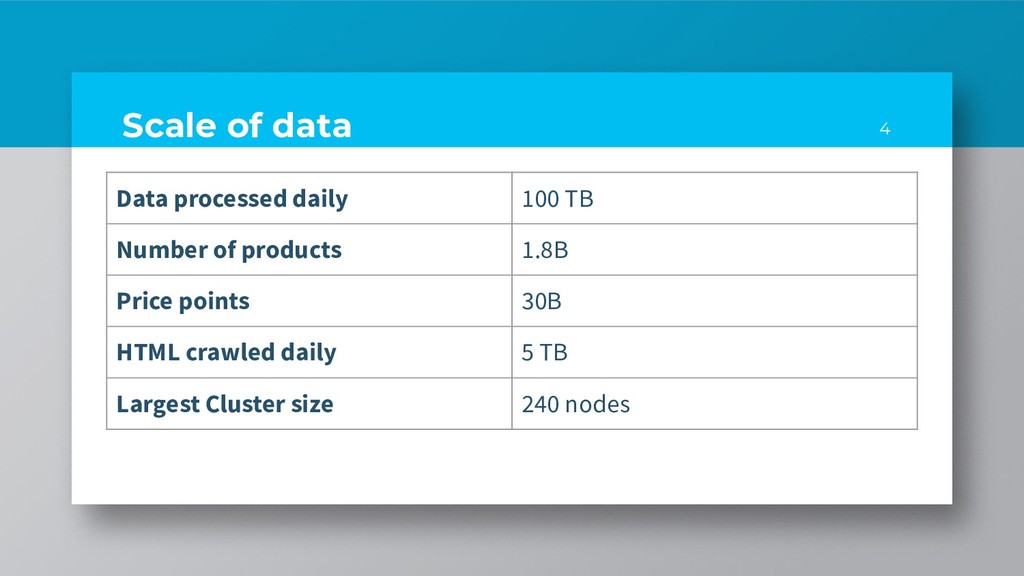
- 100x faster • SQL, MLlib, GraphX • Less disk I/O • Lazy evaluation of tasks - optimises data flow • In-memory caching - when multiple operations/jobs access the same dataset 7 Big Data Processing Engines
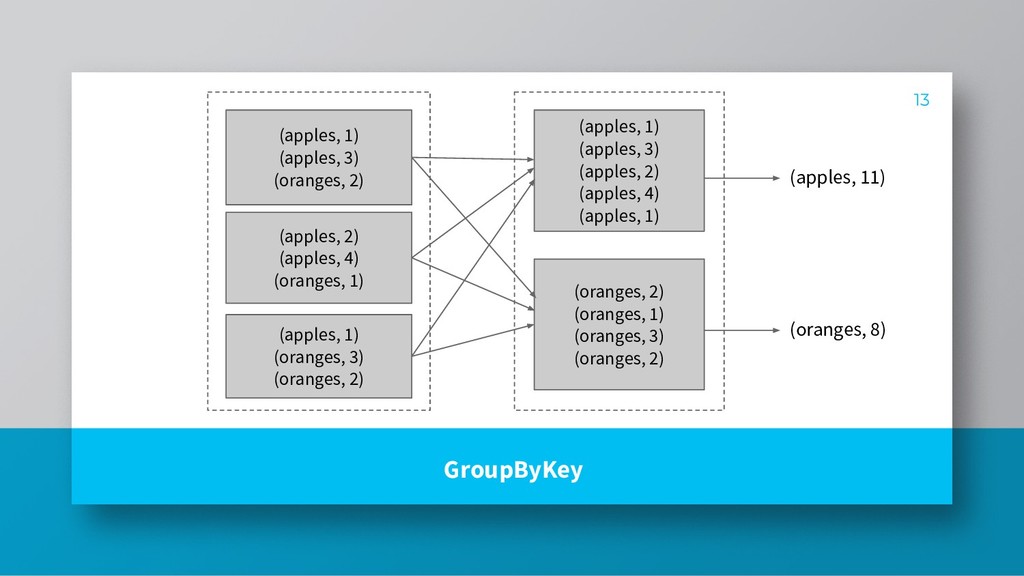
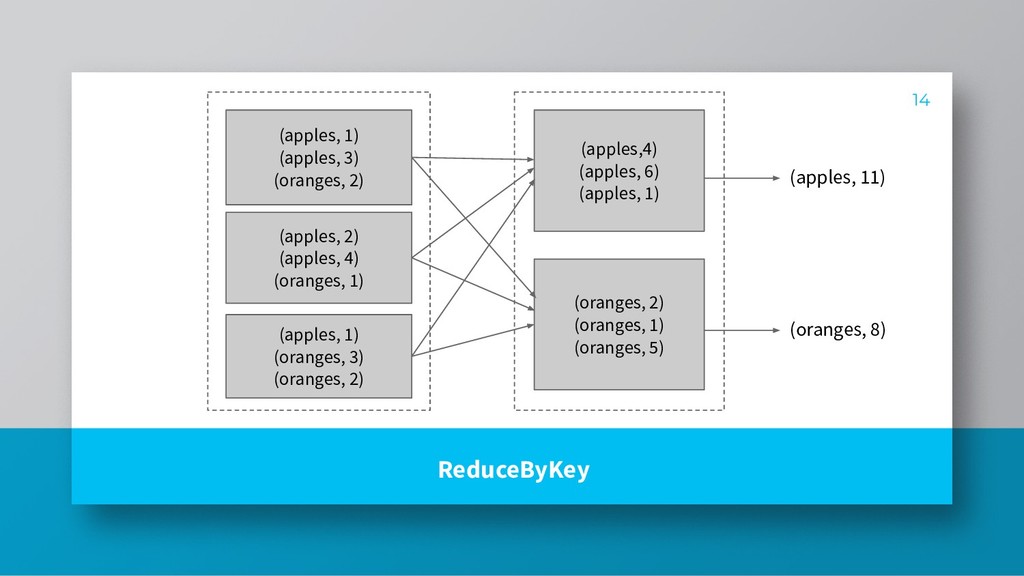
vs wide dependencies » Avoid shuffling wherever possible » Apply filter predicates before shuffle operations to reduce data that goes into the next stage 15 What we learnt
optimization kicks in - Filter pushdowns - Avoids unnecessary projections » Write down partitions by a column (reads will be faster) - products.write.partitionBy(“country”).parquet(...) - /root/country=IN/ - /root/country=US/ 16 Switching to the DataFrame API
average » Push down filters(1.6 onwards) to reduce disk I/O - Filter pushdowns to access only required columns » Use DirectParquetOutputCommitter - Avoids expensive renames 17 Using Parquet as File Format
might have to deal with partitions requiring more memory than what is assigned » Very large partitions may end up with writing blocks greater than two gigabytes (max shuffle block size) » Lot of time spent on GC - data didn’t fit into heap space. Too many objects created and not cleared up. 22
2001 or more partitions (Spark highly compresses data if the number of partitions is greater than 2,000) » Append hashes to keys while joining if you know that one or more keys is likely to have skewed values 24 Increase the number of partitions
GC,G1GC) that is more suitable for your application. » G1GC is more preferable - Higher throughput and lower latency » Take a heap dump to check for large number of temporary objects created. 26 Choose a suitable GC
bring in all the data to the driver - Operations like collect() are unsafe when the driver cannot house all the data in memory » Too many partitions - Large number of map status objects returned by the executors 28
to let the executors write down the output of intermediate files instead of collecting all data to the driver » Do not have too many partitions - lesser map status objects 29 Solutions
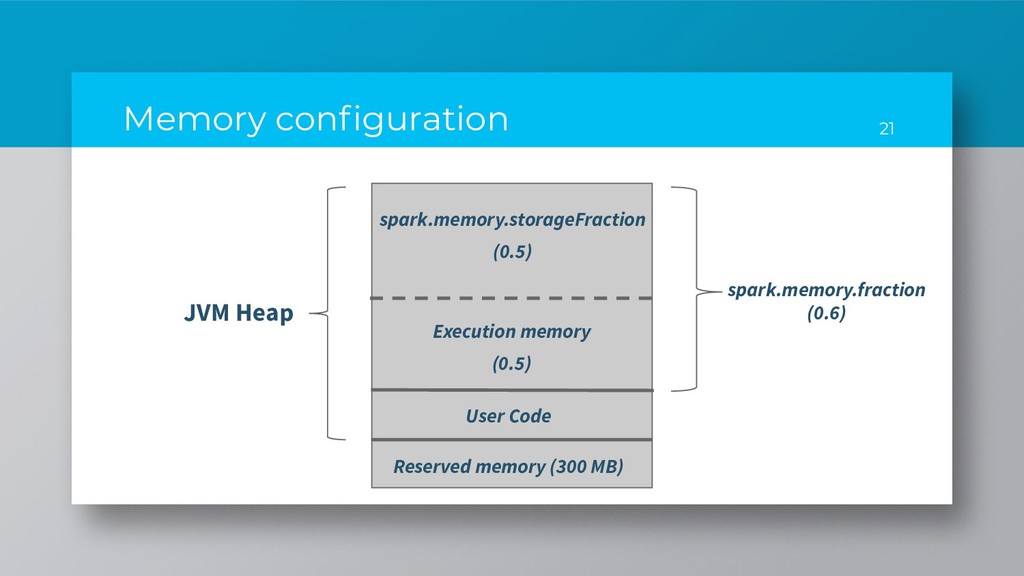
out for: java.io.IOException: No space left on device UnsafeExternalSorter: Thread 75 spilling sort data of 141.0 MB to disk (90 times so far) 30 Job config that you can tweak: - spark.memory.fraction - spark.local.dirs
out for: Only a few tasks running for a long period while the rest complete pretty quickly 33 Job config that you can tweak: None (Application needs tuning) Possible Causes: » Skewed data » Data locality change because of rescheduled tasks
might not apply to the other » But there are certain common parameters or best practices that can always extend across applications » Useful to have a high level understanding of Spark’s internals 35 Key takeaways
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}