with special bonus from Google … Node Container Control Panel Pod Replica StatefulSet Deployment DaemonSet Job … How Kubernetes is created? ? Containers
multi-apps in one container 2.ensure container order by tricky scripts 3.add health check for micro-service group 4.copy files from one container to another 5.connect to peer container across whole network stack 6.schedule super affinity containers in cluster
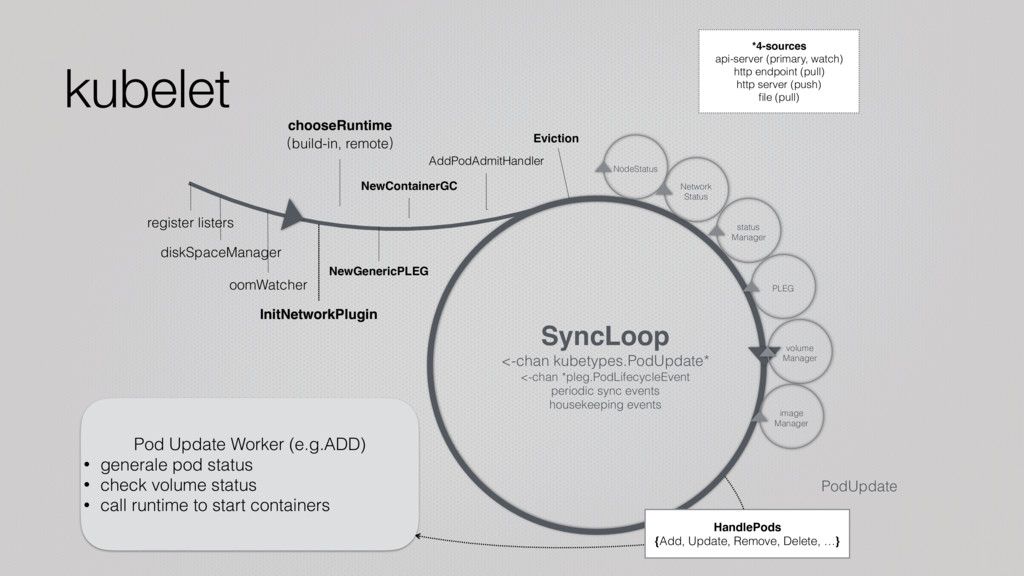
createVolumeSpec(newPod) Cache volumes[volName].pods[podName] = pod • Get mountedVolume from actualStateOfWorld • Unmount volumes in mountedVolume but not in desiredStateOfWorld • AttachVolume() if vol in desiredStateOfWorld and not attached • MountVolume() if vol in desiredStateOfWorld and not in mountedVolume • Verify devices that should be detached/unmounted are detached/unmounted • Tips: 1. -v host:path 2. attach VS mount 3. Totally independent from container management
if the system is under memory pressure and there are no lower priority containers that can be killed. Burstable killed once they exceed their requests and no Best- Effort pods exist when system under memory pressure Best-Effort First to get killed if the system runs out of memory
vary from different runtimes): 1. Create a network NS for sandbox 2. plugin.SetUpPod(NS, podID) to configure this NS 3. Also checkpoint the NS path for future usage (TearDown) 4. Infra container join this network namespace 1. or scanning /etc/cni/net.d/xxx.conf to configure sandbox Pod A B eth0 vethXXX
proposed CRI enhancement cri-containerd (promising default), cri-tools, hypervisor based secure container CPU pin (and update) and NUMA affinity (CPU sensitive workloads) HugePages support for large memory workloads Local storage management (disk, blkio, quota) “G on G”: run Google internal workloads on Google Kubernetes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}