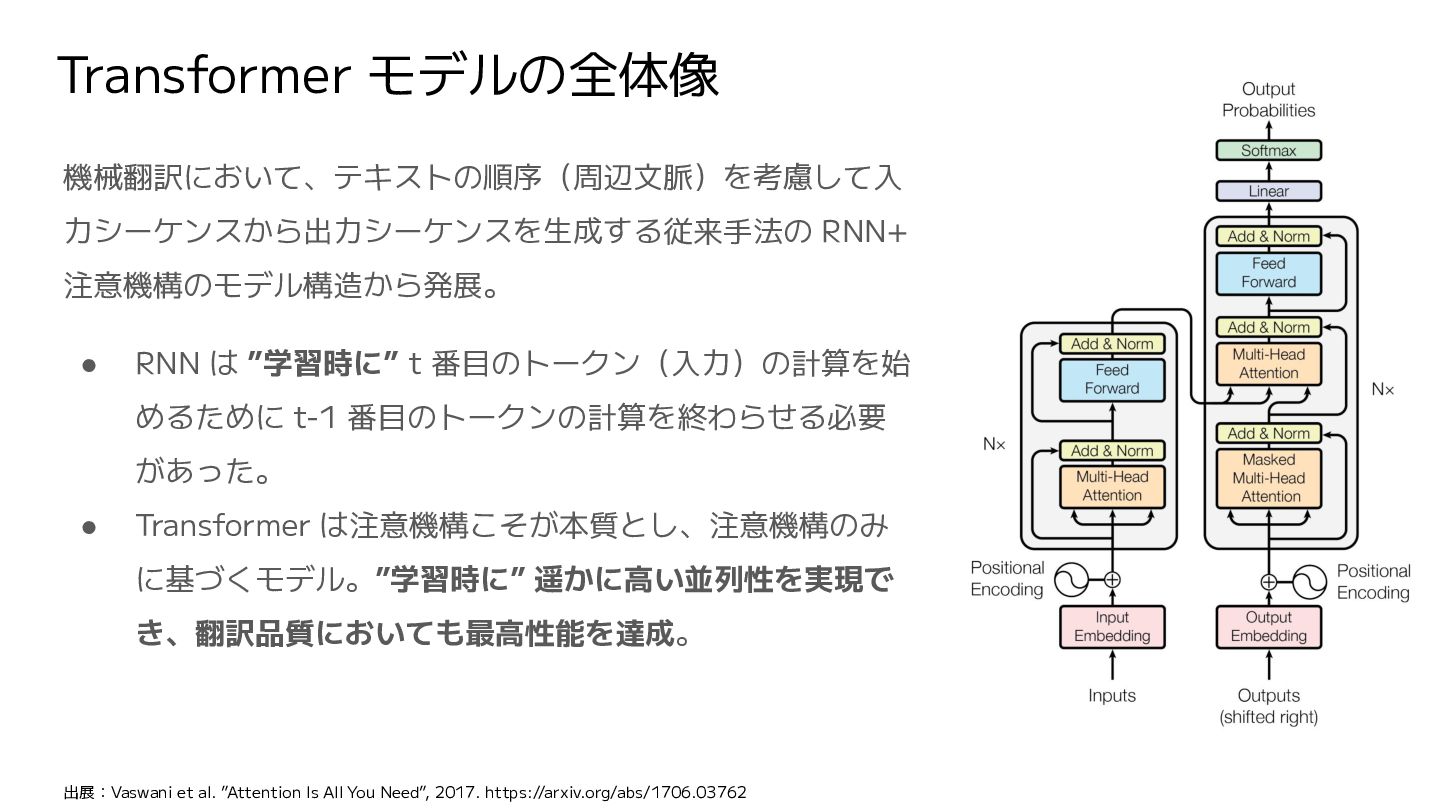
t 番目のトークン(入力)の計算を始 めるために t-1 番目のトークンの計算を終わらせる必要 があった。 • Transformer は注意機構こそが本質とし、注意機構のみ に基づくモデル。”学習時に” 遥かに高い並列性を実現で き、翻訳品質においても最高性能を達成。 出展:Vaswani et al. ”Attention Is All You Need”, 2017. https://arxiv.org/abs/1706.03762
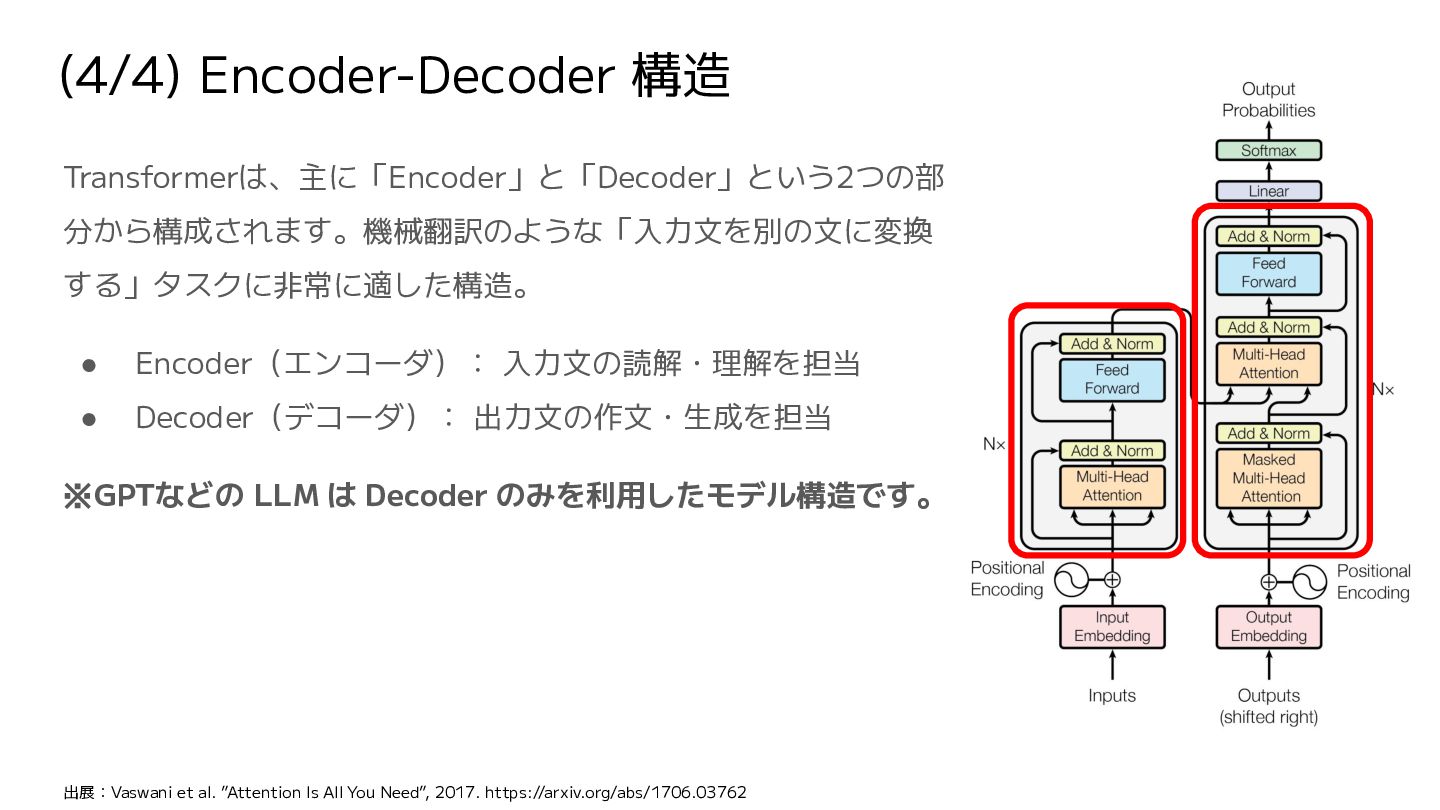
Decoder(デコーダ): 出力文の作文・生成を担当 ※GPTなどの LLM は Decoder のみを利用したモデル構造です。 出展:Vaswani et al. ”Attention Is All You Need”, 2017. https://arxiv.org/abs/1706.03762
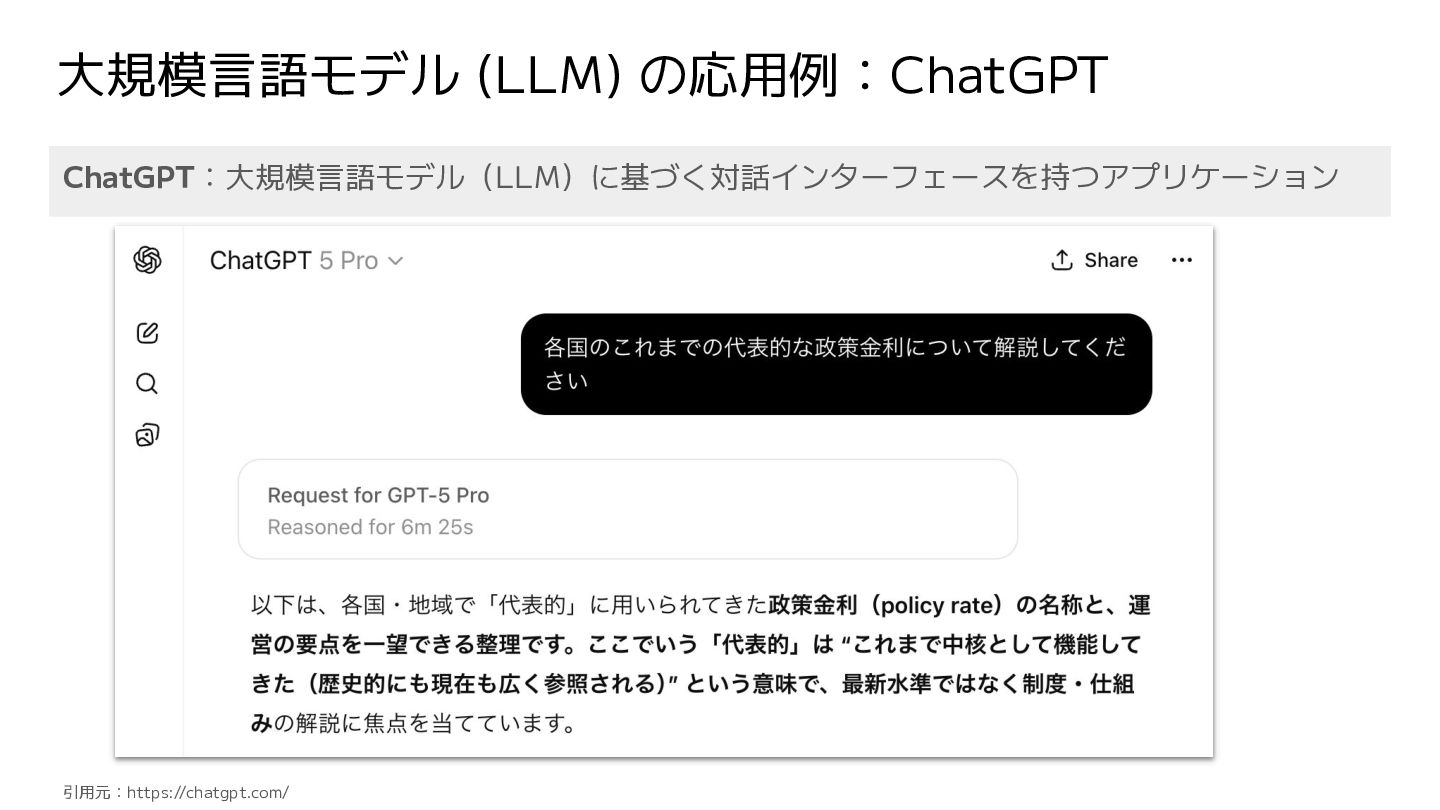
テキストの要約、情報抽出、質疑応答、テキスト分類、言語やコードの翻 訳、コード生成、コードのドキュメント作成や推論など、様々な種類の理解 ・生成タスクを達成するために工夫して使用する 引用元:"5-Day Gen AI Intensive Course with Google", https://www.kaggle.com/learn-guide/5-day-genai
に当面の特定タスクに関連する一般的な質問を検討させる Step2(思考):その一般的な質問への回答を、特定のタスクのための後続のプロンプトに追加 出展:Zheng et al., "Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models", https://arxiv.org/abs/2310.06117
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
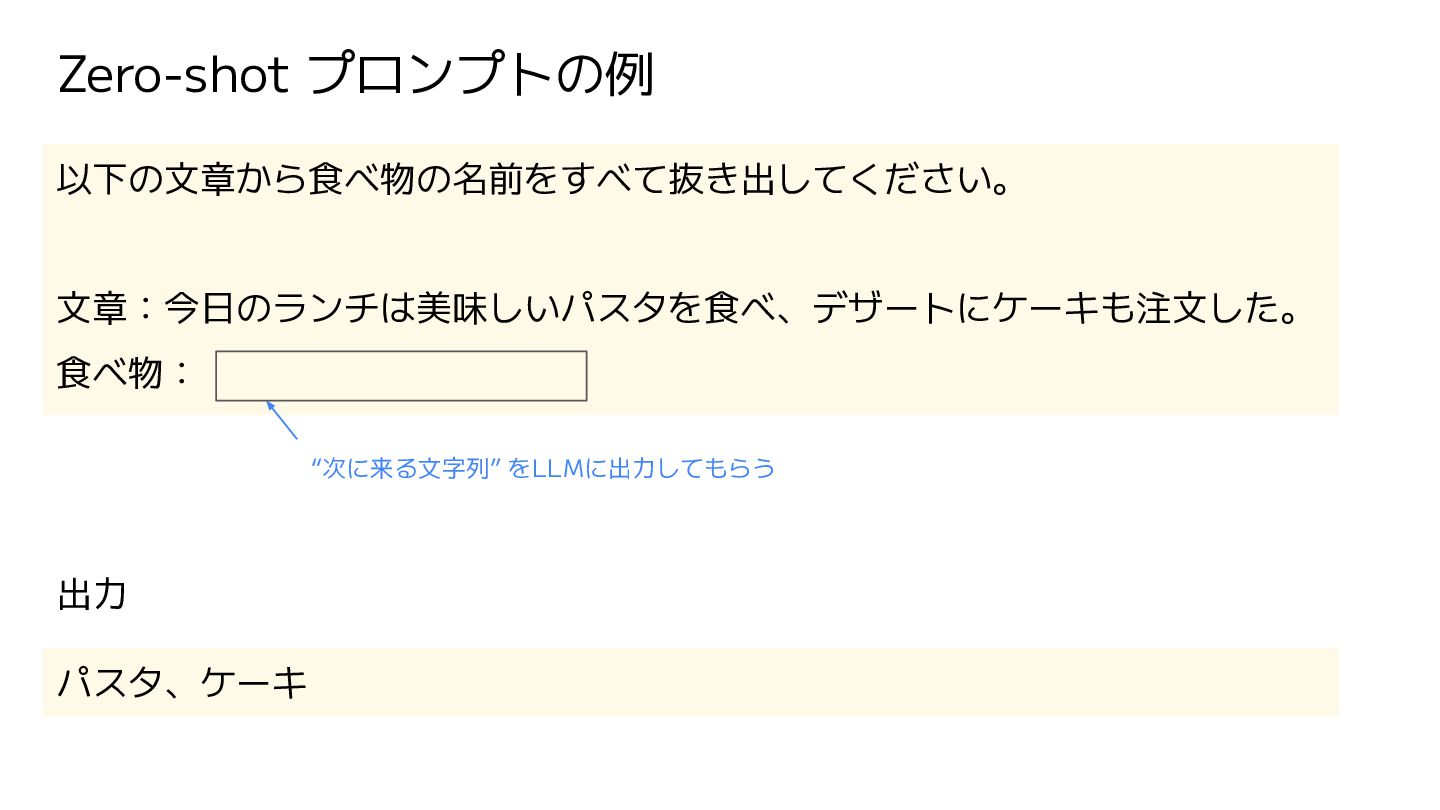{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Chain of Thought (CoT) [Wei+ ‘22]:思考の連鎖 中間的な推論ステップを例示することで、LLM が推論ステップを生成できるよう にガイドする [Wei+](https://files.speakerdeck.com/presentations/03e05e0f2ff84f83ab714e6bfbe761ce/slide_41.jpg){kind=link}
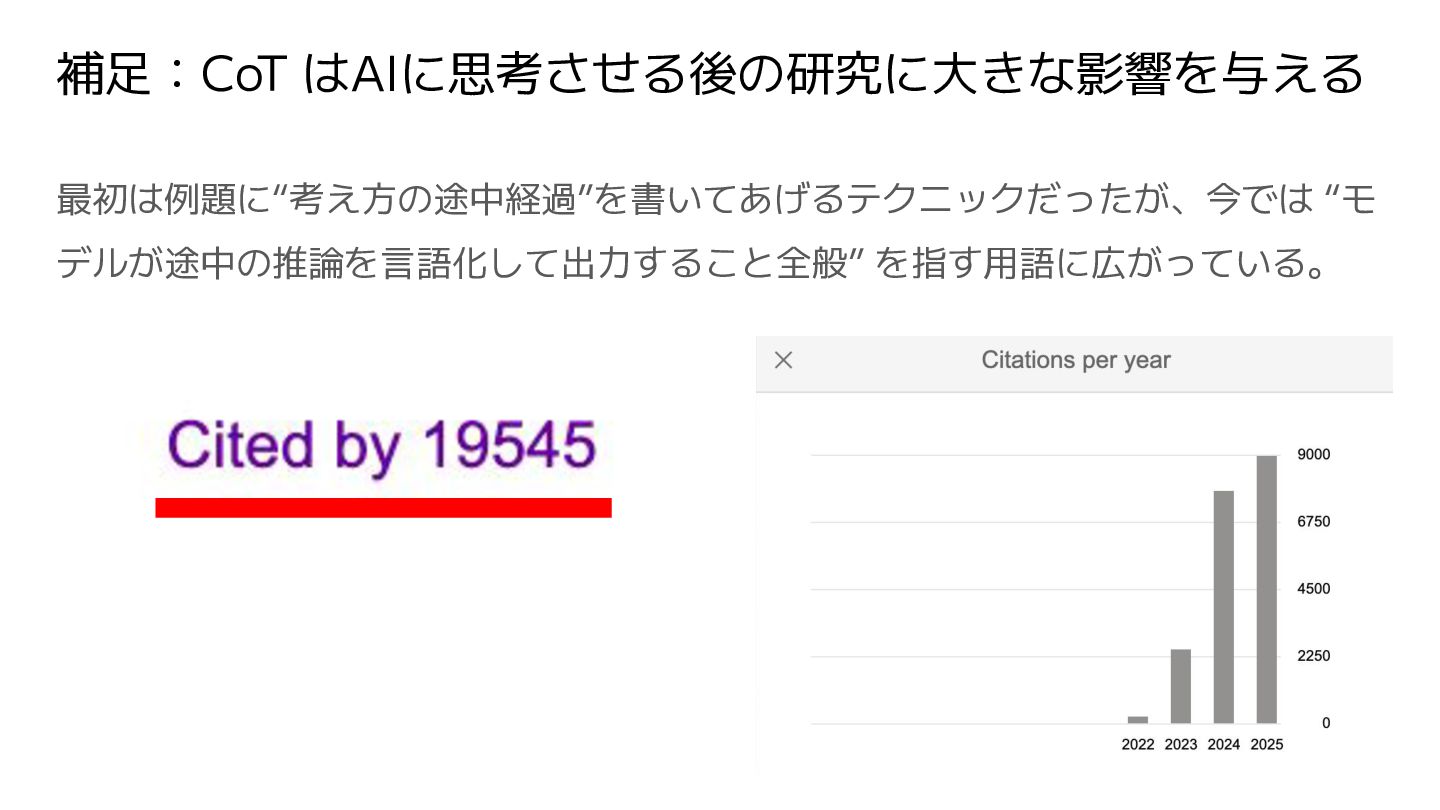{kind=link}
![Step-Back Prompting [Zheng+ ‘24]:一歩引く CoT は中間の推論ステップでの正確性が低いことで失敗する場合がある。“一歩引く” ことで LLM は特定の問題解決を試みる前に、関連する背景知識や推論プロセスを活性化させる手法。 Step1(抽象):LLM](https://files.speakerdeck.com/presentations/03e05e0f2ff84f83ab714e6bfbe761ce/slide_43.jpg){kind=link}
![Step-Back Prompting [Zheng+ ‘24]:一歩引く 例:エステラ・レオポルドは1954年8月から11月の間にどの学校に通っていたか? Chain-of-Thought の場合。 推論ステップでの正確性が低い例 ※「UCBで1950年に修士」と「1955年博士」は どちらも正しいが、博士は別大学の](https://files.speakerdeck.com/presentations/03e05e0f2ff84f83ab714e6bfbe761ce/slide_44.jpg){kind=link}
![Step-Back Prompting [Zheng+ ‘24]:一歩引く 一歩引いた質問:「エステラ・レオポルド」の学歴は何ですか? 質問の回答を得て、最初の質問に追加 例:エステラ・レオポルドは1954年8月から11月の間にどの学校に通っていたか? 出展:Zheng et al.,](https://files.speakerdeck.com/presentations/03e05e0f2ff84f83ab714e6bfbe761ce/slide_45.jpg){kind=link}
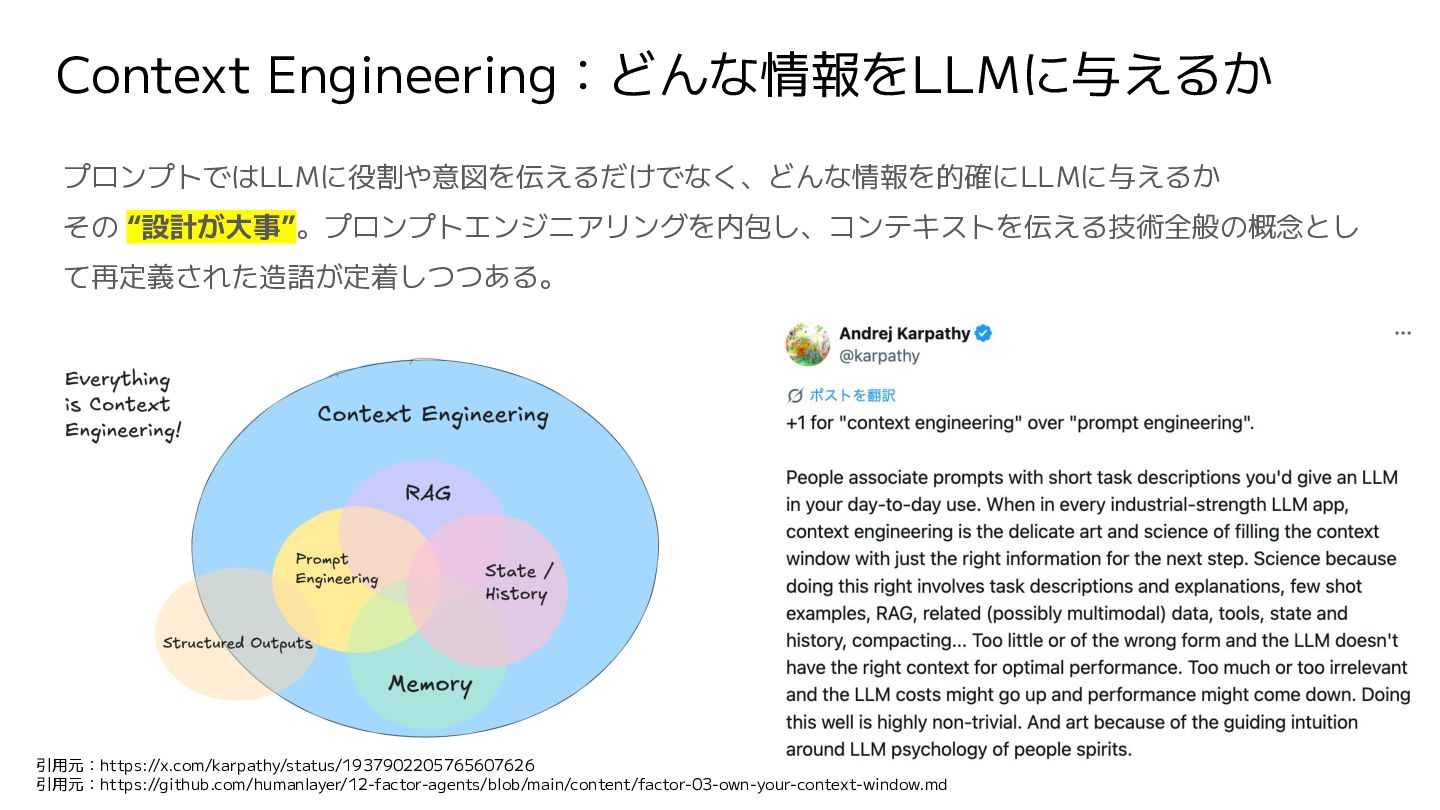{kind=link}
{kind=link}
{kind=link}
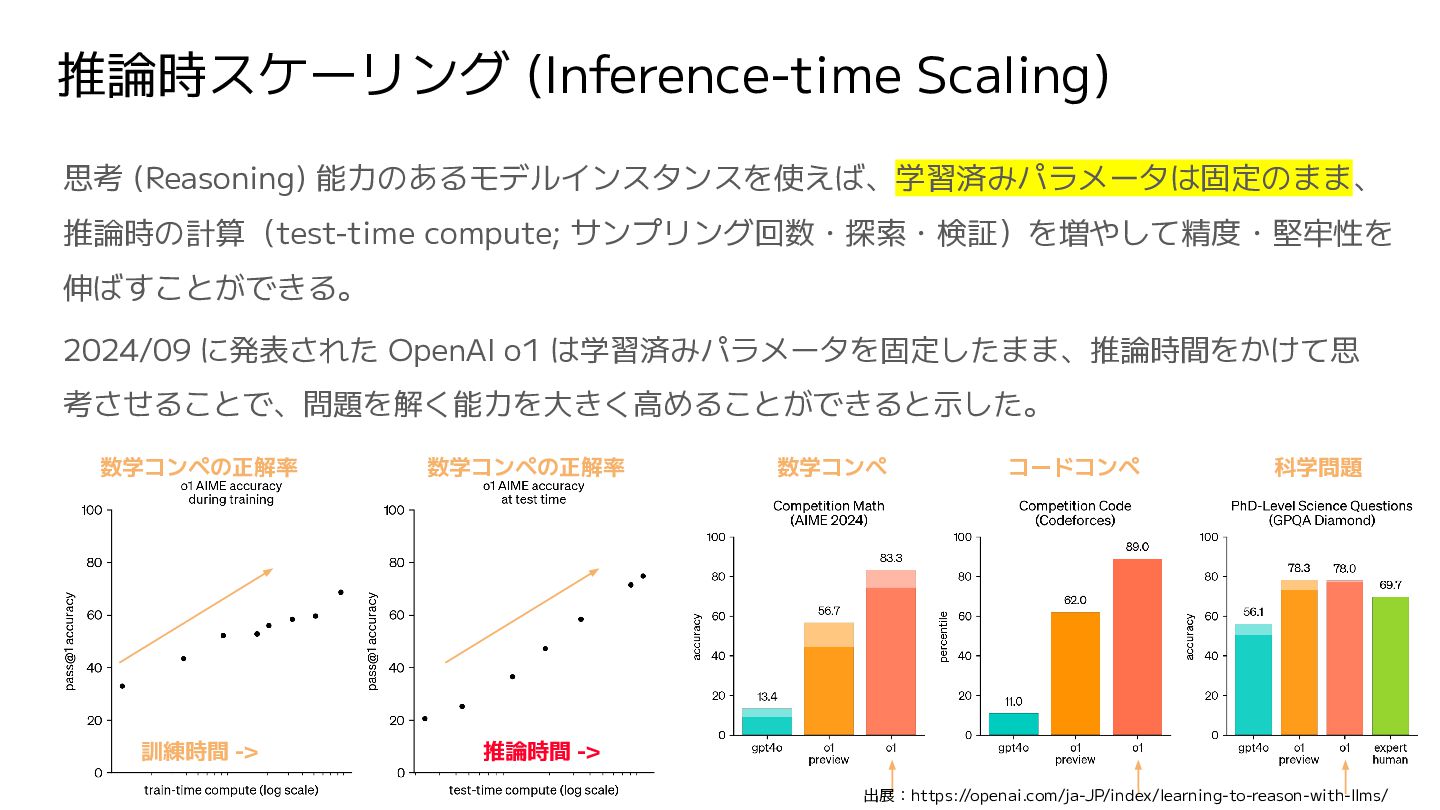{kind=link}
{kind=link}
![難しい問題にだけ余分に計算を配る [Snell+ ‘25] すべての問題に同じだけ “Best-of-N” を計算するのではなく、難しい問題にだけ余分に計算時 間を分配すると効率が良い。 Snell et al,](https://files.speakerdeck.com/presentations/03e05e0f2ff84f83ab714e6bfbe761ce/slide_51.jpg){kind=link}
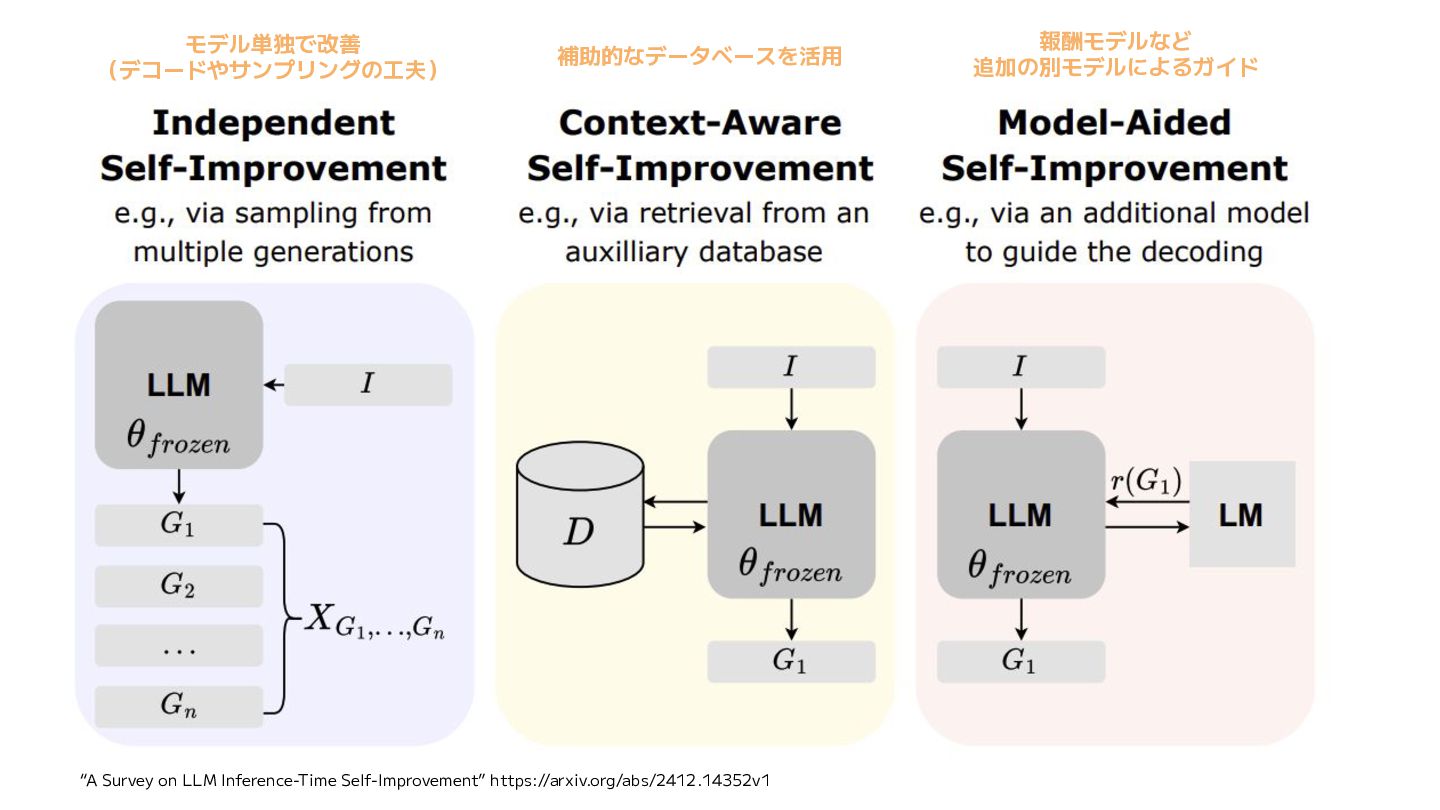{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![AlphaEvolve [Novikov+ ‘25]:進化的コーディングエージェント 大規模言語モデル(LLM)を創造的な核として利用し、進化的計算を組み合わせたコーディング エージェント。科学的およびアルゴリズム的な発見を行う 行列乗算アルゴリズムなどのアルゴリズム設計からGoogleのインフラストラクチャの最適化ま で、広範な領域でSOTAを塗り替える結果を示した。 どのコードから改善していくかの取捨選択 で進化的計算のアイディアを取り入れる アルゴリズムの創造をLLMに頼る](https://files.speakerdeck.com/presentations/03e05e0f2ff84f83ab714e6bfbe761ce/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
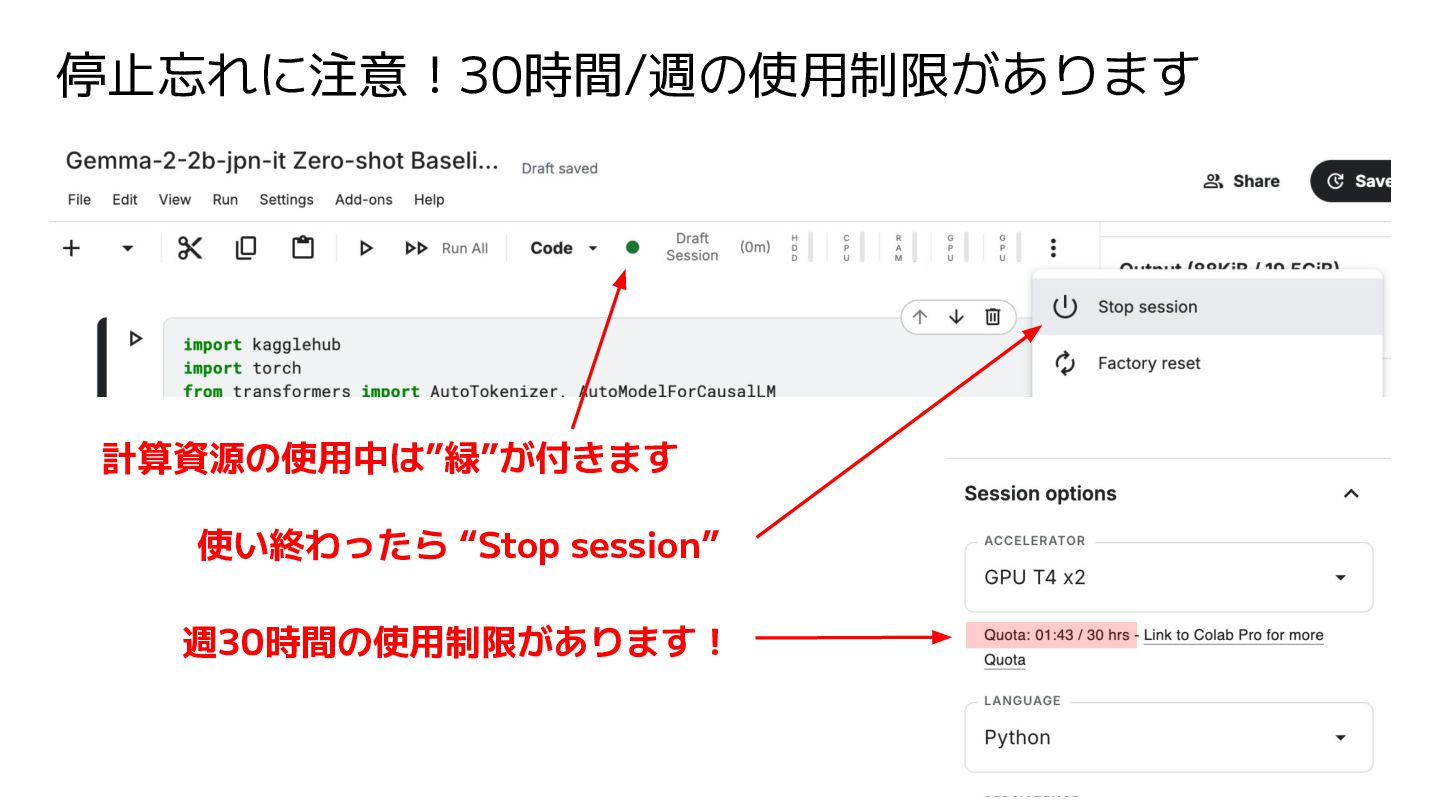{kind=link}