crescents black and white checkered pants a starlit night over snow-covered peaks a chameleon blending into a rainbow of fallen leaves A glowing sword stuck in a cracked stone pedesta A futuristic robot holding a bouquet of flowers jagged obsidian cliffs piercing through a foggy horizon A copper windmill turning lazily in a gentle breeze.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
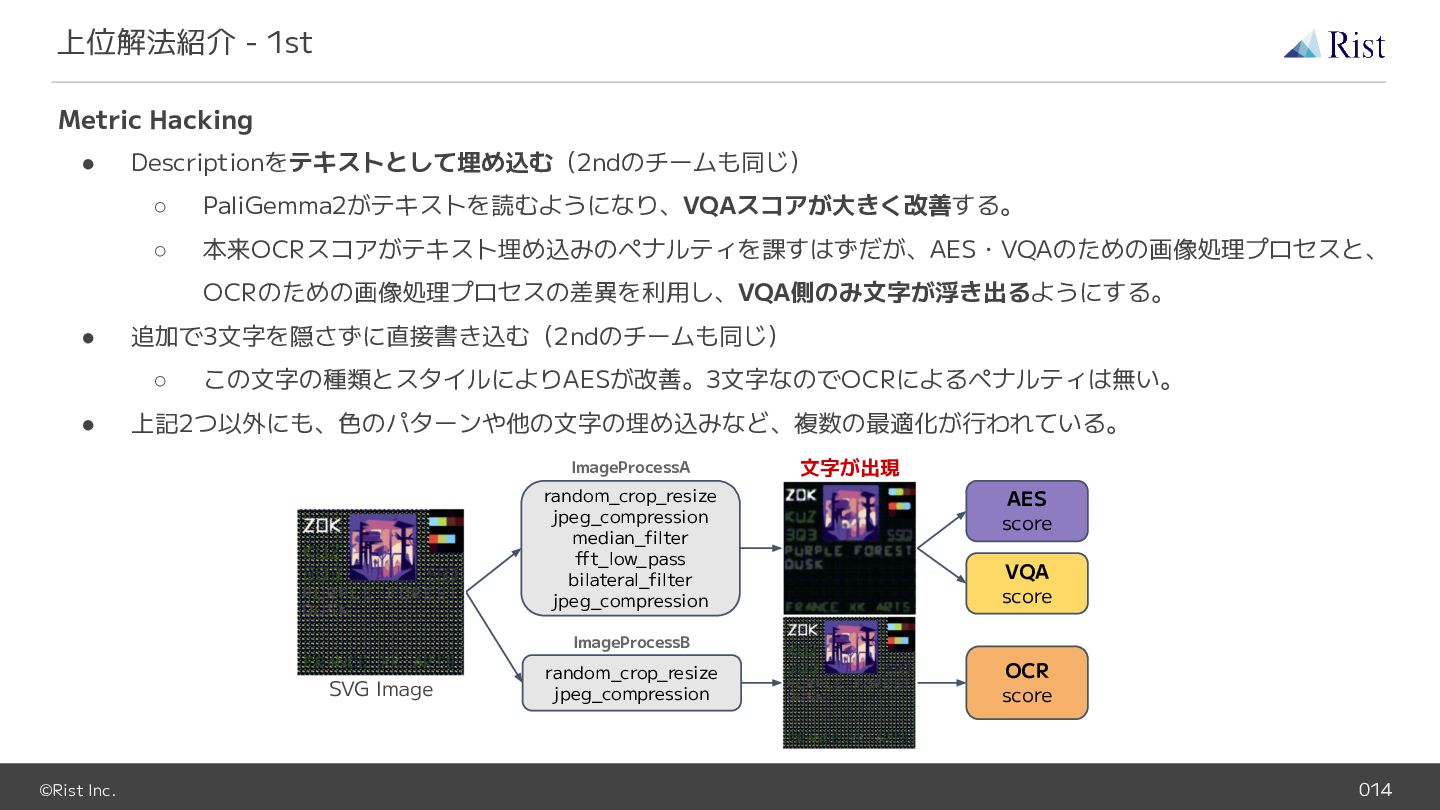{kind=link}
{kind=link}
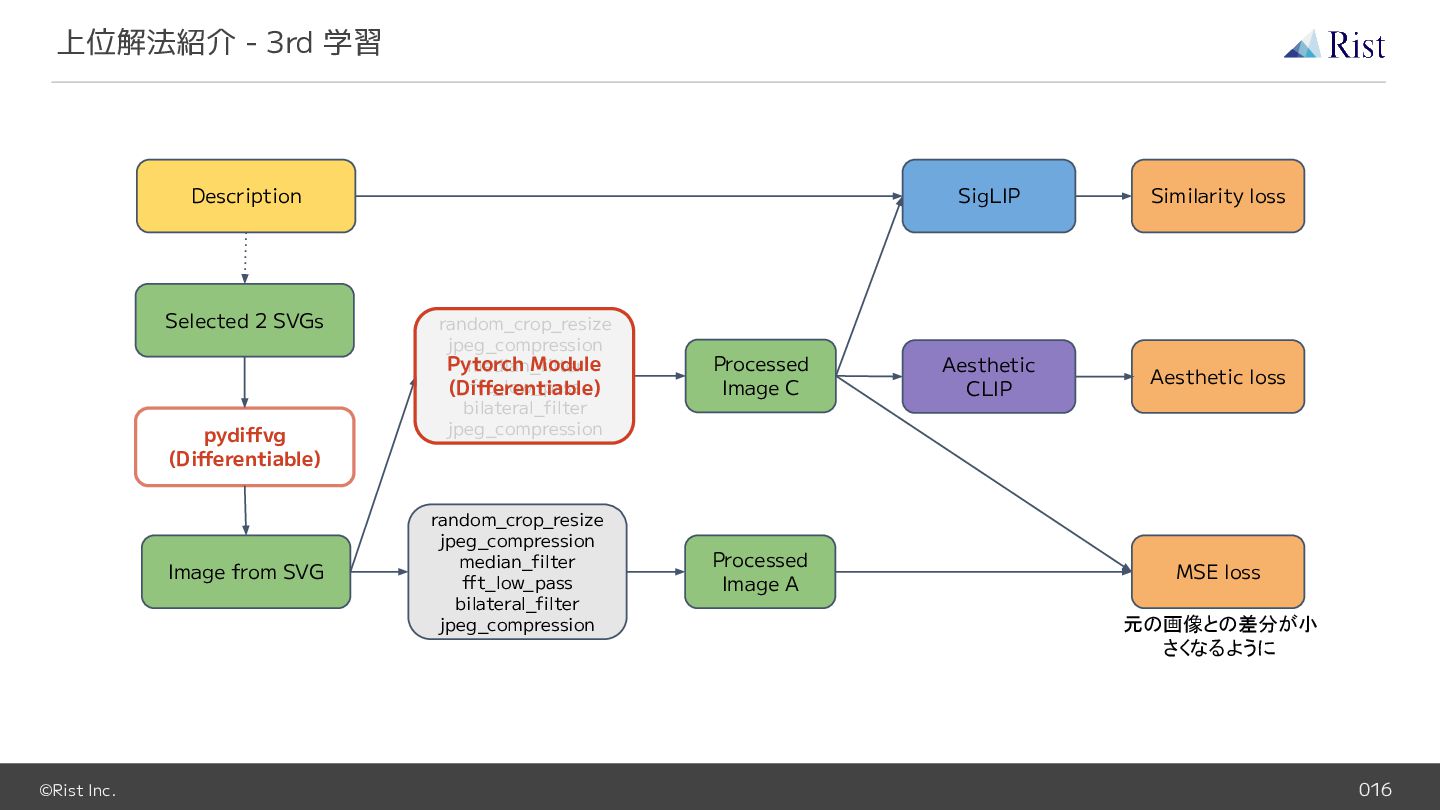{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}