Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
PromptBERT: Improving BERT Sentence Embeddings ...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
hajime kiyama
August 31, 2023
260
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
PromptBERT: Improving BERT Sentence Embeddings with Prompts
Japanese explanation
hajime kiyama
August 31, 2023
More Decks by hajime kiyama
See All by hajime kiyama
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
330
Idiosyncrasies in Large Language Models
rudorudo11
0
63
People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text
rudorudo11
0
280
Analyzing Continuous Semantic Shifts with Diachronic Word Similarity Matrices.
rudorudo11
0
230
Using Synchronic Definitions and Semantic Relations to Classify Semantic Change Types
rudorudo11
0
110
Analyzing Semantic Change through Lexical Replacements
rudorudo11
0
370
意味変化分析に向けた単語埋め込みの時系列パターン分析
rudorudo11
1
210
Bridging Continuous and Discrete Spaces: Interpretable Sentence Representation Learning via Compositional Operations
rudorudo11
0
340
Word Sense Extension
rudorudo11
0
160
Featured
See All Featured
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.7k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
GraphQLとの向き合い方2022年版
quramy
50
15k
Visualization
eitanlees
152
17k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
480
Rails Girls Zürich Keynote
gr2m
96
14k
Designing for Performance
lara
611
70k
sira's awesome portfolio website redesign presentation
elsirapls
0
300
Optimizing for Happiness
mojombo
378
71k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
Context Engineering - Making Every Token Count
addyosmani
9
1k
Transcript
木山朔 M1 論文紹介 EMNLP2022 4/18
Introduction • BERTの学習がうまくいかない原因は異方性と考えられていた ◦ トークンの埋め込みは狭い円錐に偏る • しかし,embedding bias が真の問題である ◦
bias を取り除くことで性能の向上を確認 ◦ 人手で取り除く & 文が短い場合に対応できない • Prompt を用いた文埋め込みの獲得方法を提案 ◦ template から文埋め込みを獲得し対照学習 ◦ 事前学習のみ, 教師あり,教師なしの全手法で使用 ◦ SimCSE と比較し BERT や RoBERTa で精度向上 2
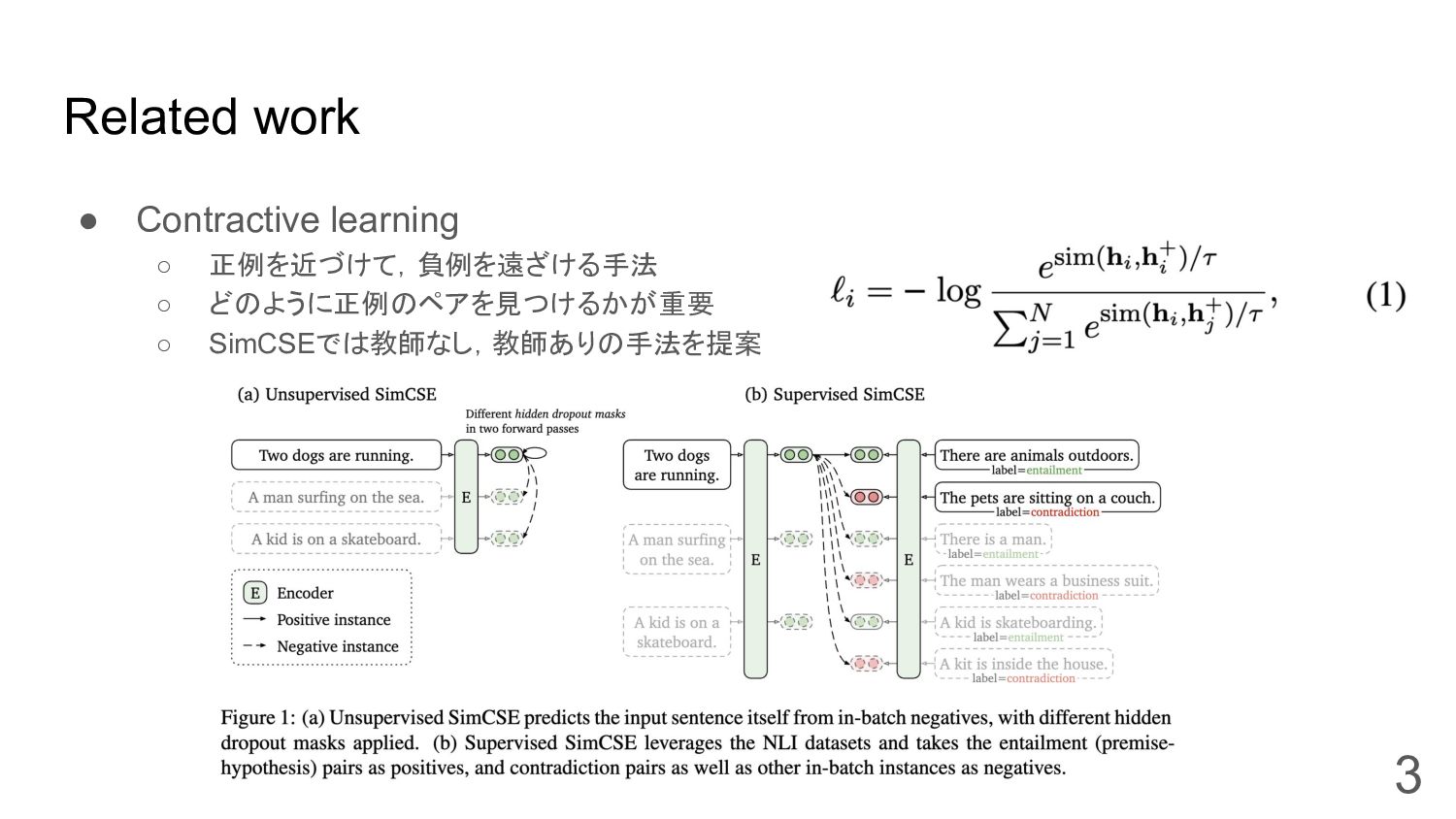
Related work • Contractive learning ◦ 正例を近づけて,負例を遠ざける手法 ◦ どのように正例のペアを見つけるかが重要 ◦
SimCSEでは教師なし,教師ありの手法を提案 3
Original BERT layers fail to improve the performance. • static
token embedding vs last layer ◦ STSタスクにおける事前実験 ◦ コサイン類似度に基づく異方性の尺度 ◦ 小さいとよい • 文埋め込みの性能と異方性 ◦ 異方性が小さくなっても性能は向上しない 4
Embedding biases harms the sentence embeddings performance. • token embedding
は token frequency のバイアスが存在 • 異方性は BERT の token frequency に対して敏感 ◦ 頻度の高いトークンはクラスター化 ◦ 頻度の低いトークンは疎に分布 5 濃いと頻度が多い 薄いと頻度が少ない
Embedding biases harms the sentence embeddings performance. • WordPiece のサブワード
と 大文字、小文字 ◦ これは新たな bias ◦ 赤、青、黄の3つ(2つ)の領域に分かれる ◦ RoBERTa は subword の影響が大きい 6 赤:大文字あり 青:小文字のみ 黄:subword
Embedding biases harms the sentence embeddings performance. • static token
embedding の異方性 ◦ 任意の2つのトークン埋め込み間のコサイン類似度の平均 ◦ bert-base-uncased だけ異方性が高い ◦ roberta は値が小さく等方的に分布 • bias は静的埋め込みによるもので異方性とは無関係では? 7
Embedding biases harms the sentence embeddings performance. • static token
embedding から bias を削除 ◦ bias と考えられる上位のトークンを削除 ▪ Freq : frequency tokens ▪ Sub : subword tokens ▪ Case : uppercase tokens ▪ Pun : punctuation ◦ bias を削除すると性能向上 • 手動で取り除いている点に注意 ◦ 文が短い場合や意味のある単語が省略されるかも 8
Prompt based sentence embedding • Prompt を用いた文埋め込み手法を提案 • 文埋め込みタスクをマスク言語タスクとして再定義 ◦
[MASK] トークンから文を表現することで埋め込みの bias を回避 • MLMで予測されたラベルトークンでなく、文ベクトルが欲しい ◦ 問題1:どのように prompt で文ベクトルを表現するか? ◦ 問題2:どのように文ベクトルに適した prompt を見つけるか? 9
Represent Sentence with the Prompt • 問題1:どのように prompt で文ベクトルを表現するか? ◦
手法1:[MASK]トークンの隠れベクトルを使用 ◦ 手法2:h[MASK]とMLM分類ヘッドを用いてtop-k-tokenを獲得し,確率分布に従いトークンの加重 平均を計算 ▪ W_v は static token embedding を使うため bias が問題 ▪ 重みの平均化により、 BERTは下流タスクで fine-tuning が困難 • よって手法1を採用 10
Prompt search • 問題2:どのように文ベクトルに適した prompt を見つけるか? ◦ 手法1:人手で発見 ▪ 73.44
◦ 手法2:T5 による生成 ▪ 64.75 ◦ 手法3:OptiPrompt による生成 ▪ 80.90 • よって手法3を採用 11
Prompt Based Contrastive Learning with Template Denoising • simCSEと同様に対照学習を実施 ◦
どのように適切な正例を獲得するか? ◦ 異なる template を用いてペアを獲得 ◦ h_i : template 全体を入力し獲得した隠れ表現 ◦ h^_i : template の部分(入力文はpadding的に処理)のみを入力し獲得した隠れ表現 ◦ h_i - h^_i : sentence embedding 12
Dataset and Baseline • Dataset ◦ 7つの STS (Semantic Textual
Similarity) ◦ [0,5]の連続値で意味的な類似度を表す • Baseline ◦ GLoVe ◦ 後処理:BERT-flow, BERT-whitening ◦ fine-tuning : IS-BERT, inferSent, Universal Sentence Encoder, SBERT, simCSE, ConSERT • pretrained and fine-tuned ◦ 事前学習のみ ◦ fine-tuning ▪ 教師なし ▪ 教師あり 13
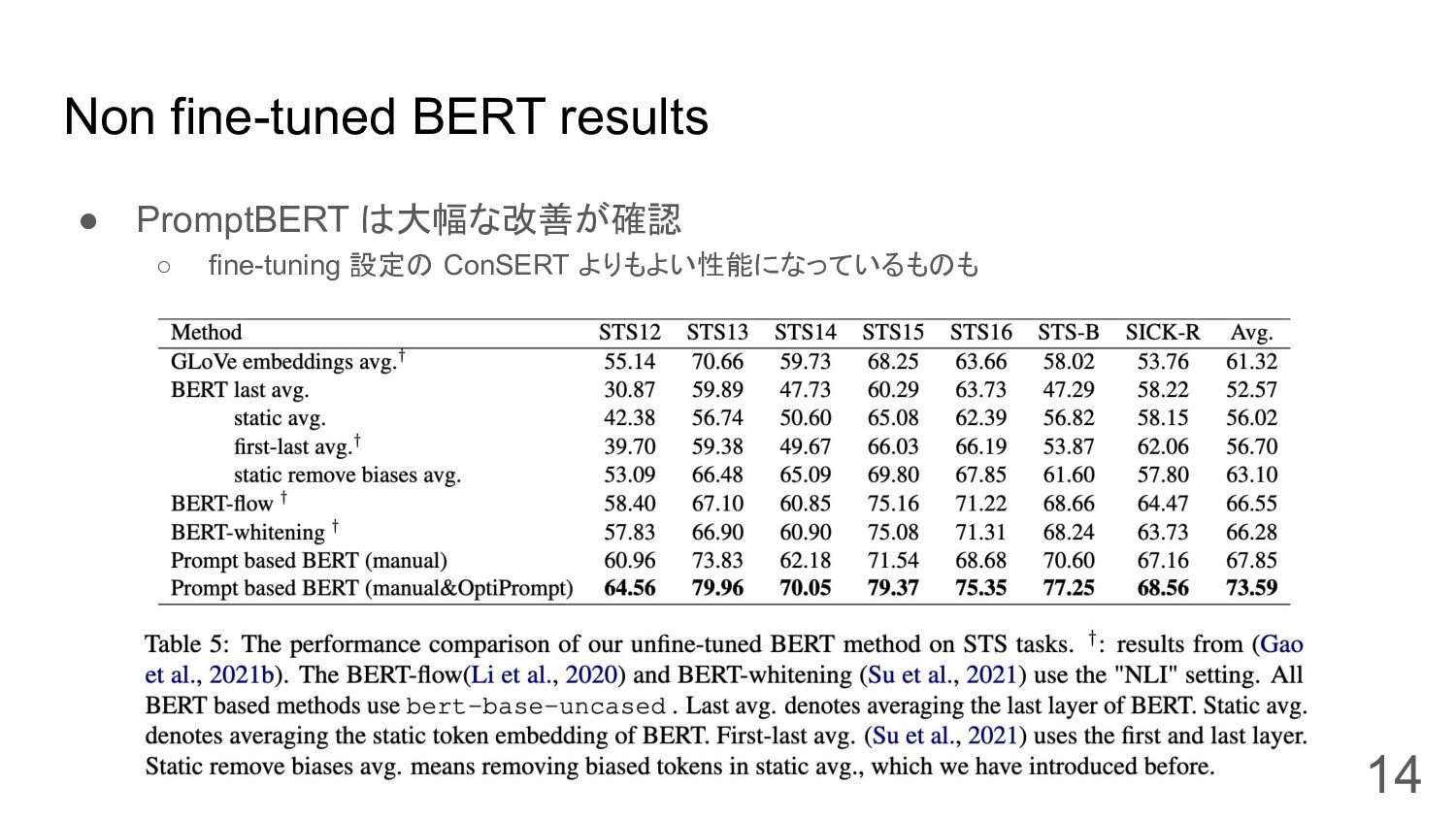
Non fine-tuned BERT results • PromptBERT は大幅な改善が確認 ◦ fine-tuning 設定の
ConSERT よりもよい性能になっているものも 14
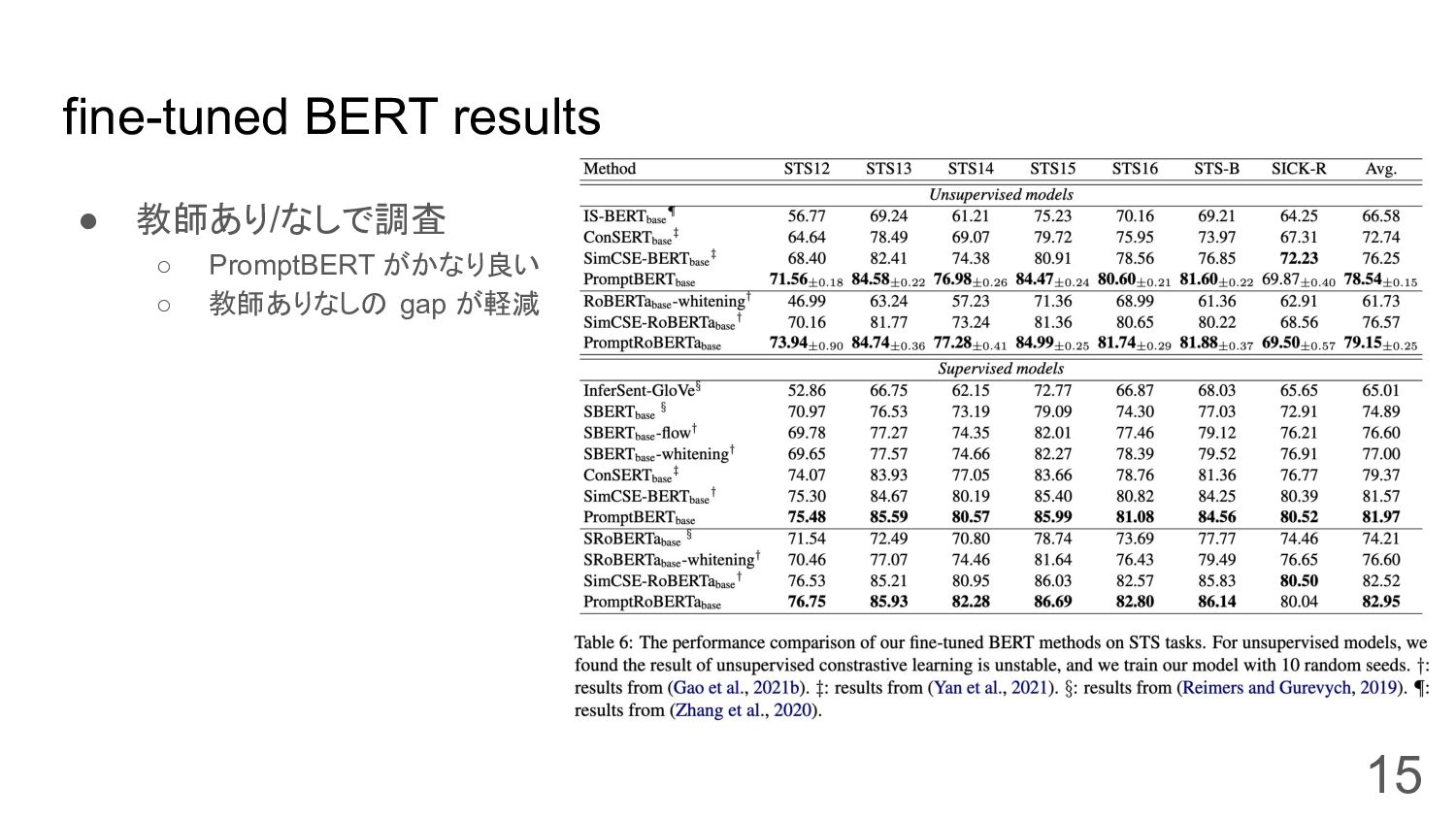
fine-tuned BERT results • 教師あり/なしで調査 ◦ PromptBERT がかなり良い ◦ 教師ありなしの
gap が軽減 15
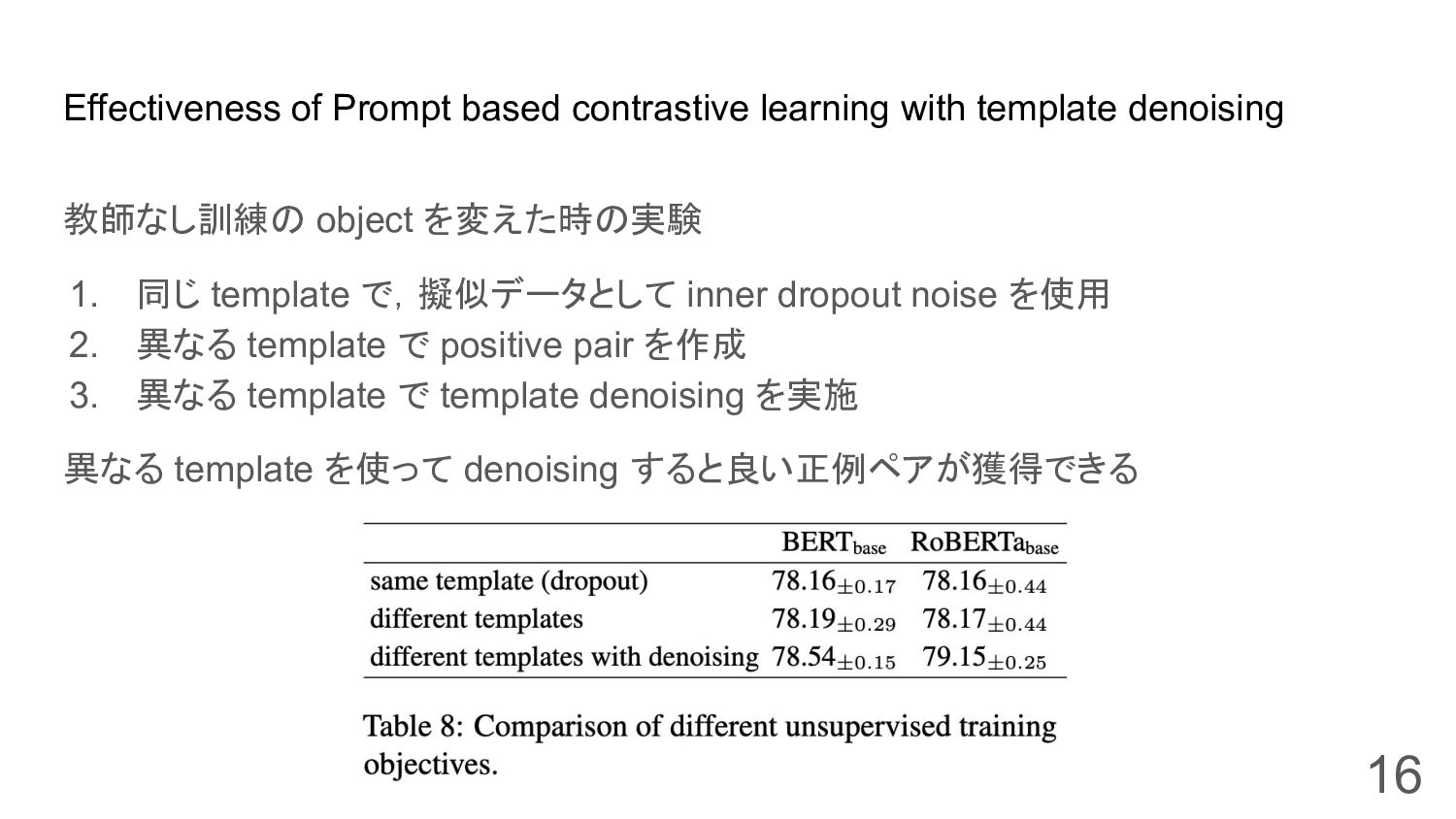
Effectiveness of Prompt based contrastive learning with template denoising 教師なし訓練の
object を変えた時の実験 1. 同じ template で,擬似データとして inner dropout noise を使用 2. 異なる template で positive pair を作成 3. 異なる template で template denoising を実施 異なる template を使って denoising すると良い正例ペアが獲得できる 16
Template denoising • template denoising は top-k 予測に対して有効 ◦ top-5
の性能はかなり向上 ◦ しかし [MASK] tokenを使った時は差が少ない • [MASK] token では同程度 ◦ 対照学習の部分にだけ template denoising を使用 17
Stability in unsupervised contrastive learning • PromptBERT は分散が低い ◦ 安定した手法
18
Conclusion • 文埋め込みにおけるBERTの性能の低さを分析 ◦ static token bias により BERT の知識を生かせていなかった
• Promptによる文埋め込み手法を提案 ◦ fine-tuning 時には template denoise による対照学習を提案 • STSや転移後のタスクで効果的 ◦ 教師あり/なし間の gap がかなり低減 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}