Akama Embulkを使ったバルクロード基盤の開発 ↓ Data teamで社内のデータ基盤の開発・運用 ミッション • 社内のデータ基盤の開発・運用 裏ミッション? • TDのプラットフォーム自体やTD発のOSS(Digdag、Embulk等)のドッグフーディング • 社内や社外コミュニティにフィードバック・知見を広める Data team
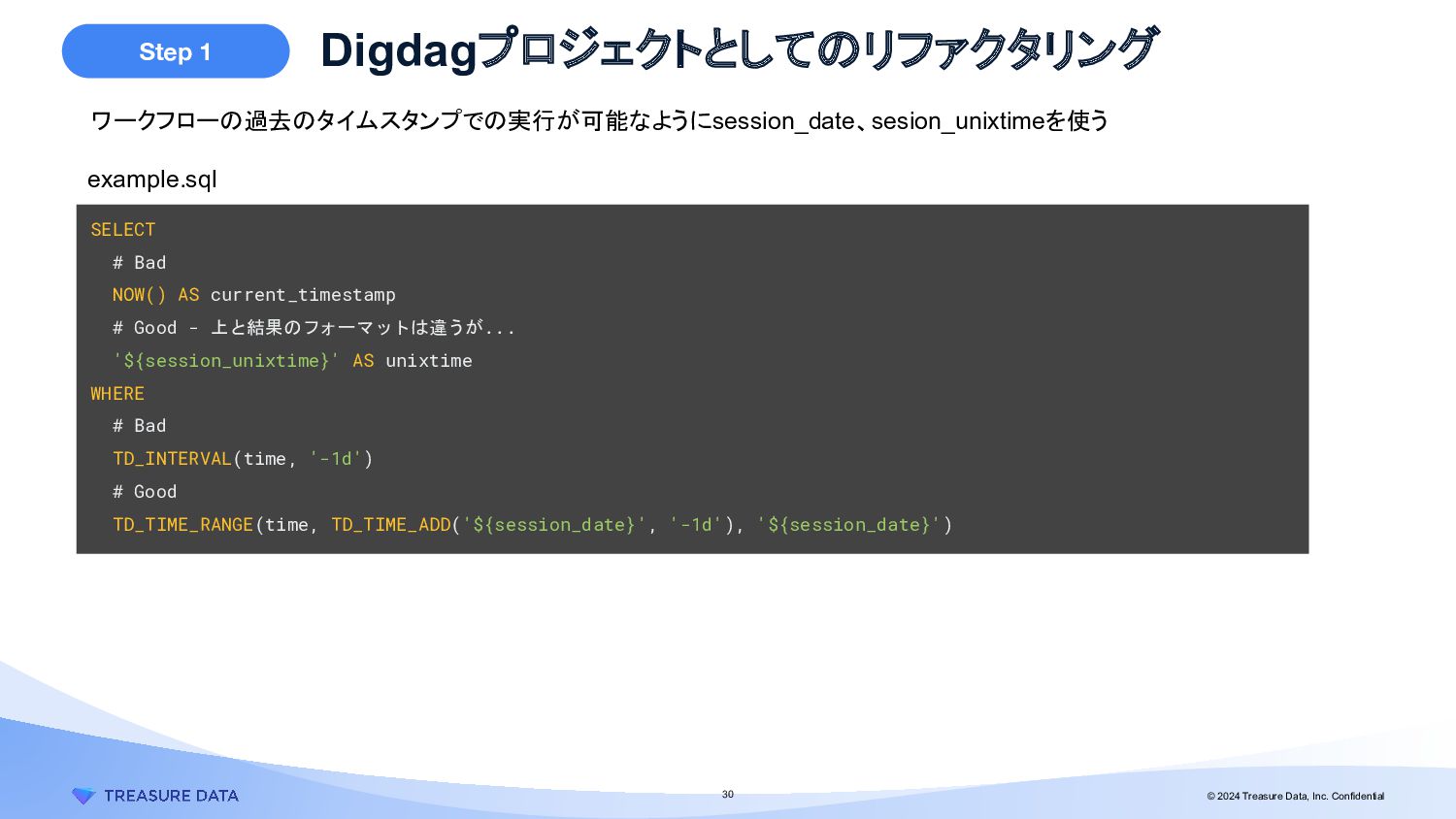
example.sql ワークフローの過去のタイムスタンプでの実行が可能なようにsession_date、sesion_unixtimeを使う SELECT # Bad NOW() AS current_timestamp # Good - 上と結果のフォーマットは違うが... '${session_unixtime}' AS unixtime WHERE # Bad TD_INTERVAL(time, '-1d') # Good TD_TIME_RANGE(time, TD_TIME_ADD('${session_date}', '-1d'), '${session_date}')
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
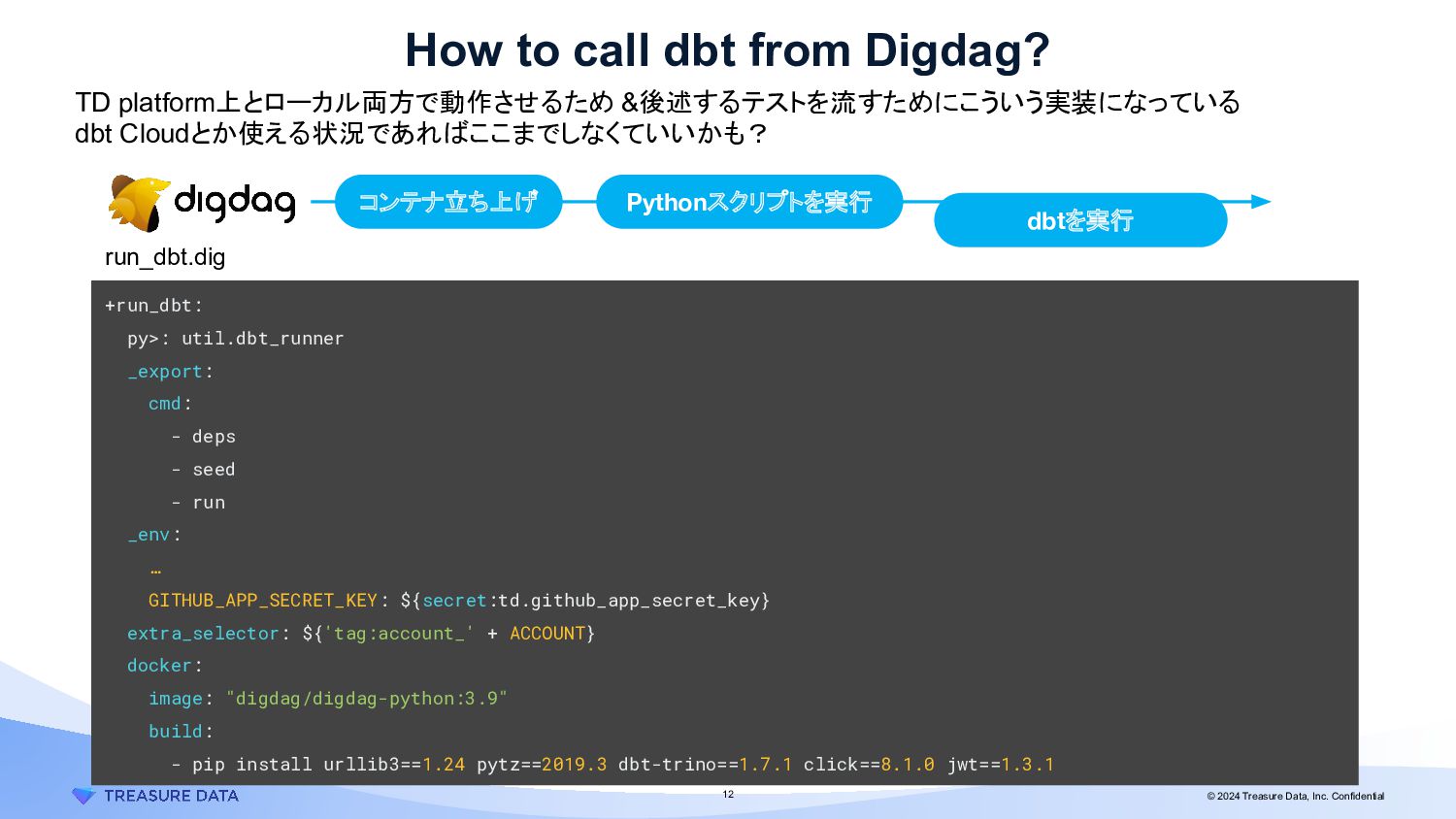{kind=link}
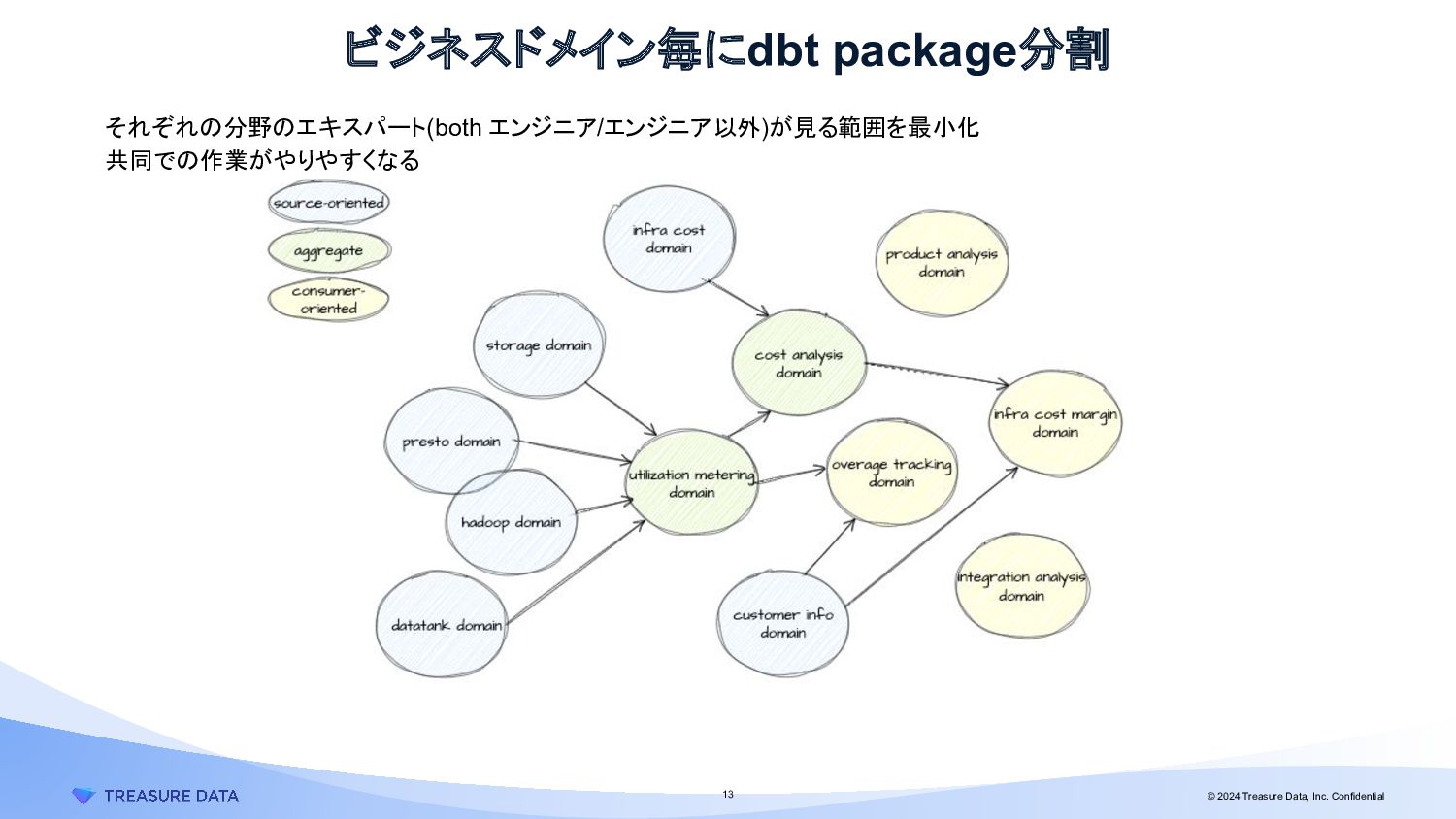{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
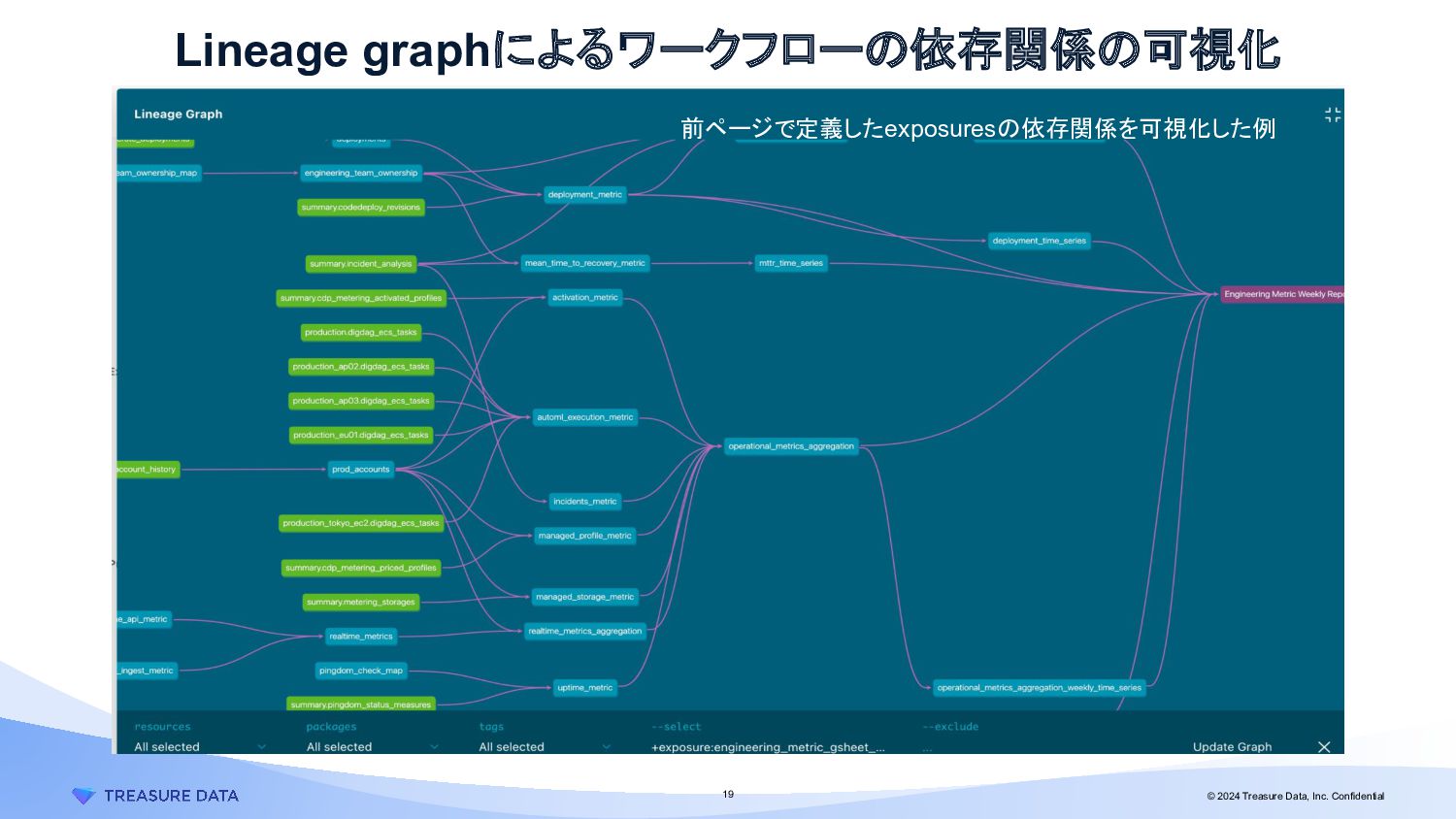{kind=link}
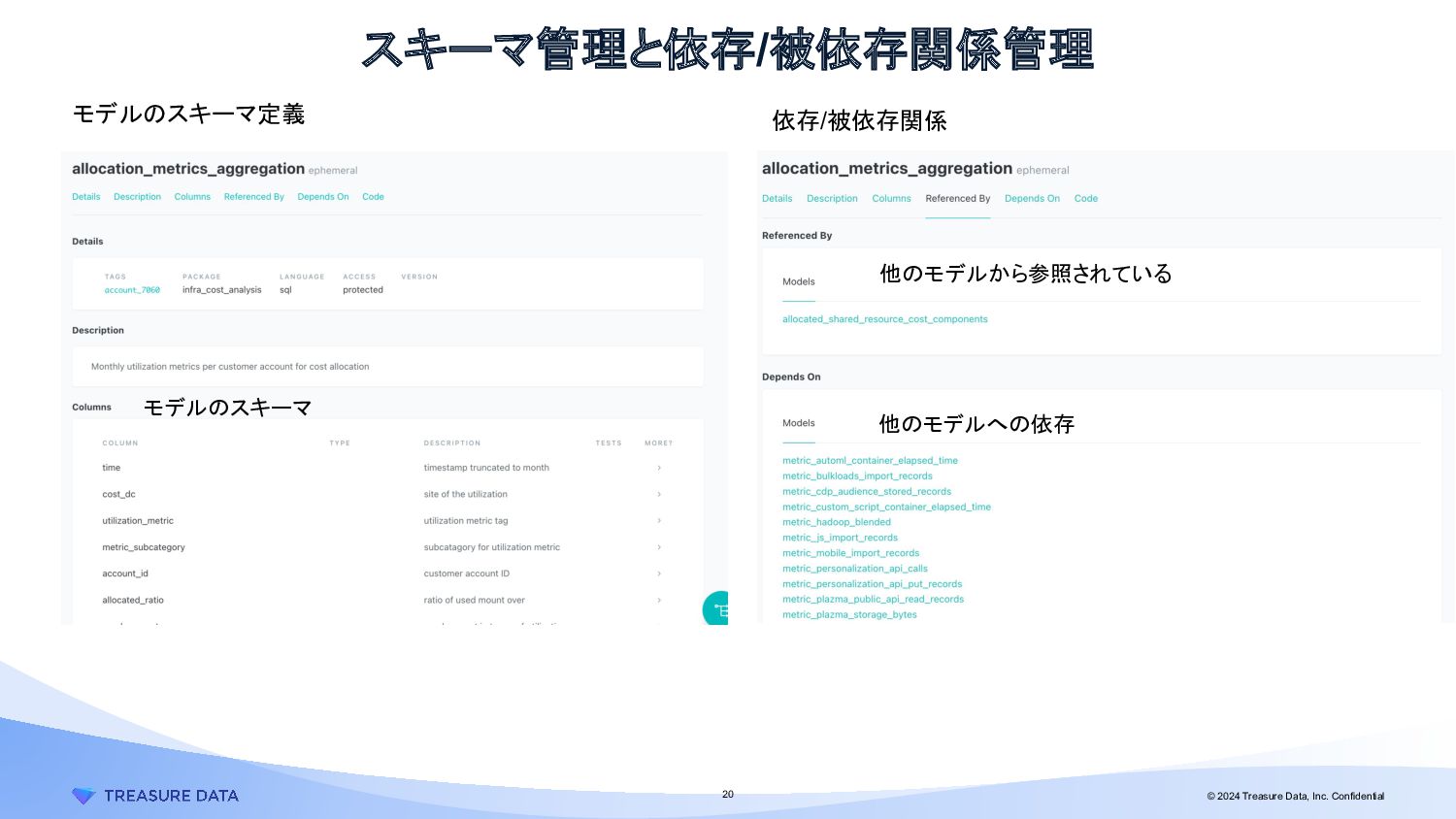{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}