In this talk, we will share the under-the-hood details of our newly re-architected recommender we started building last year.
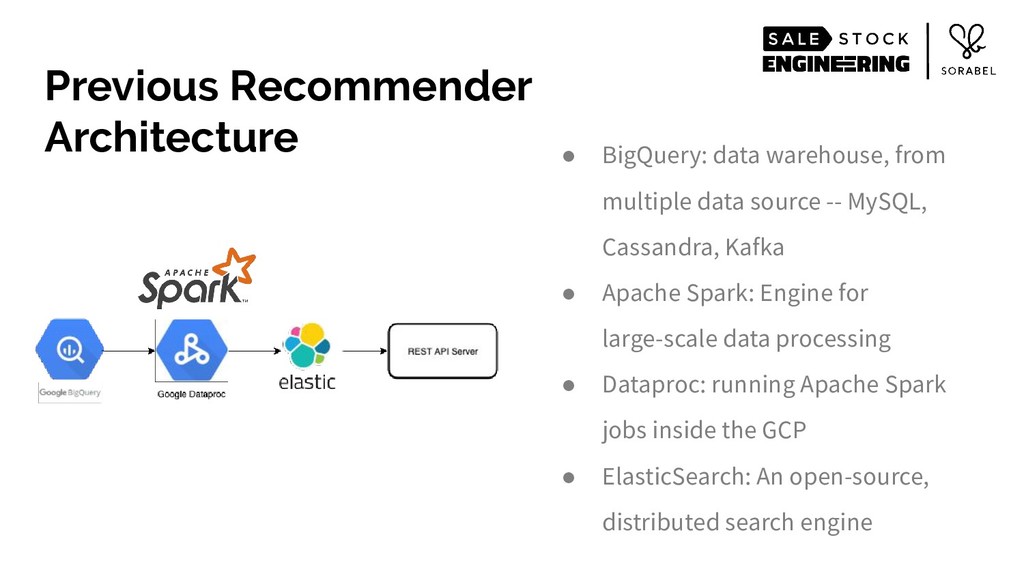
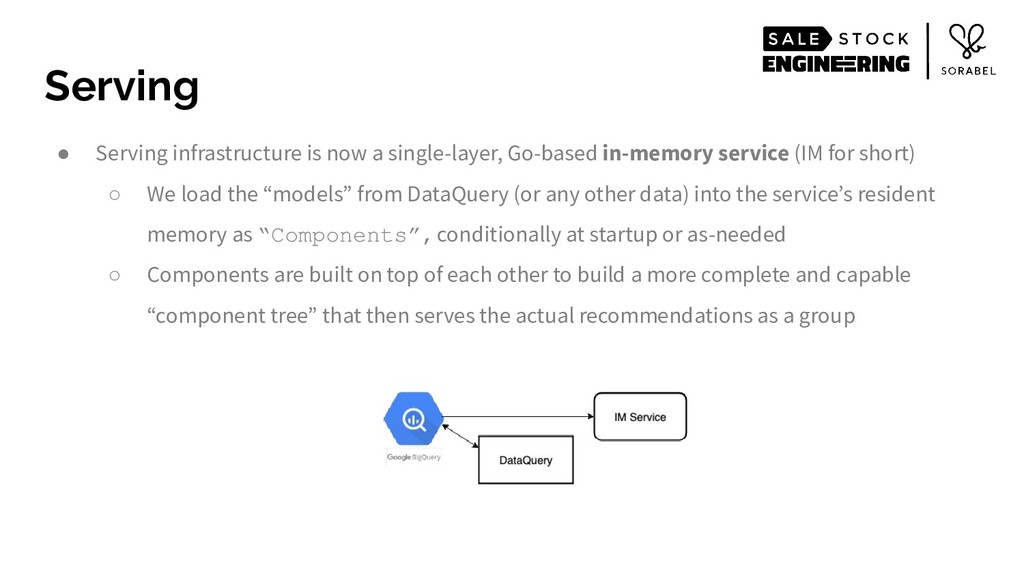
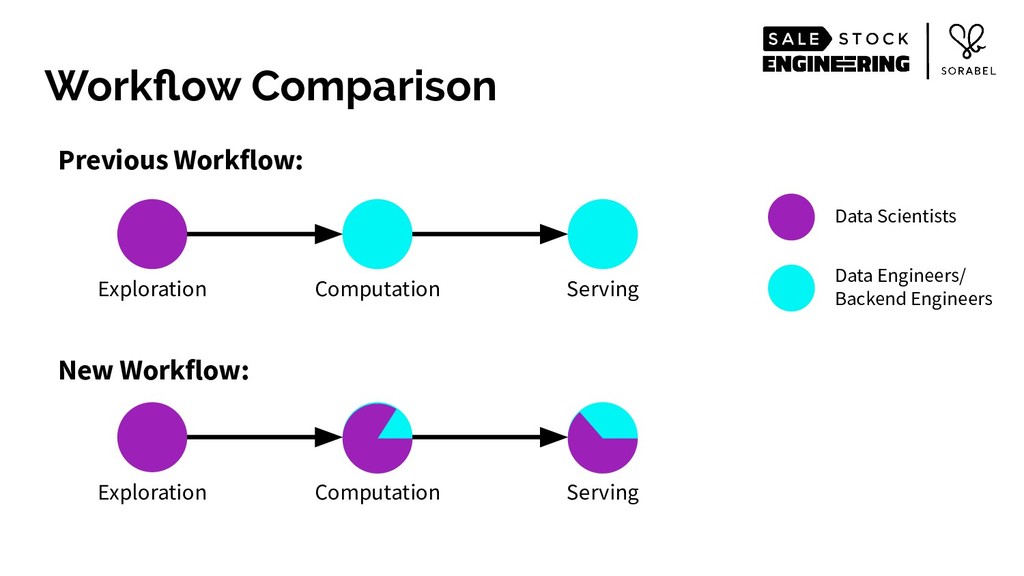
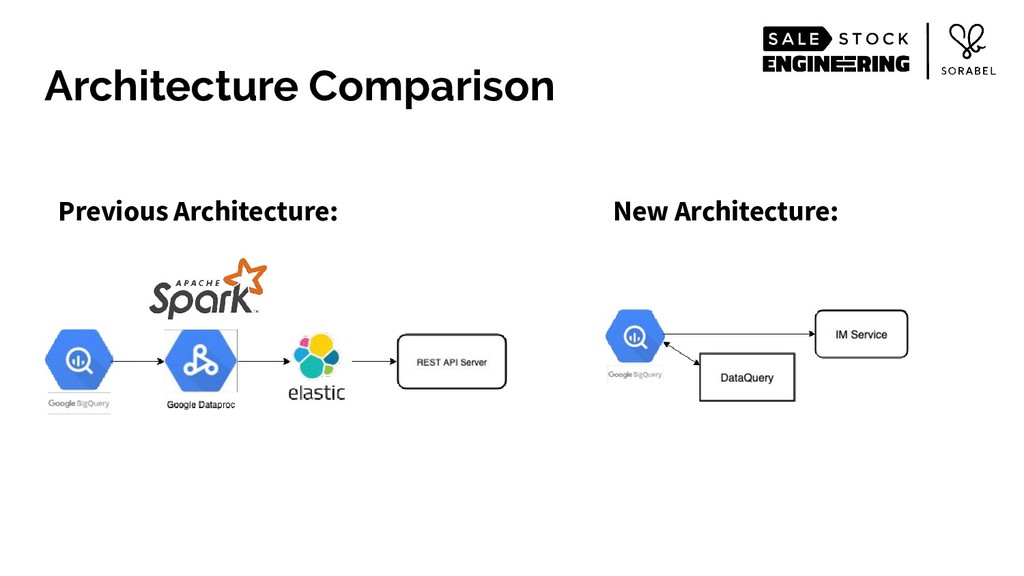
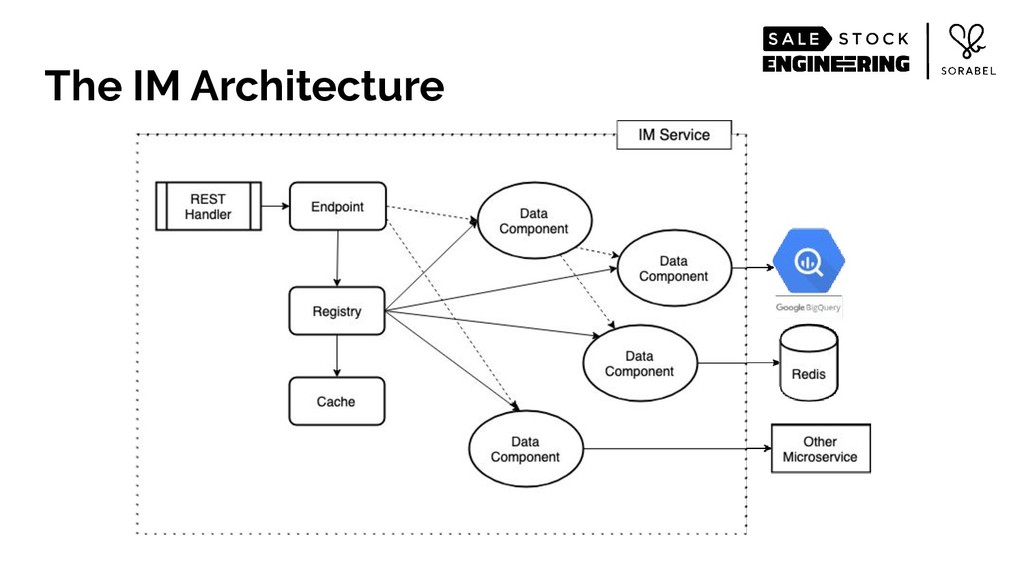
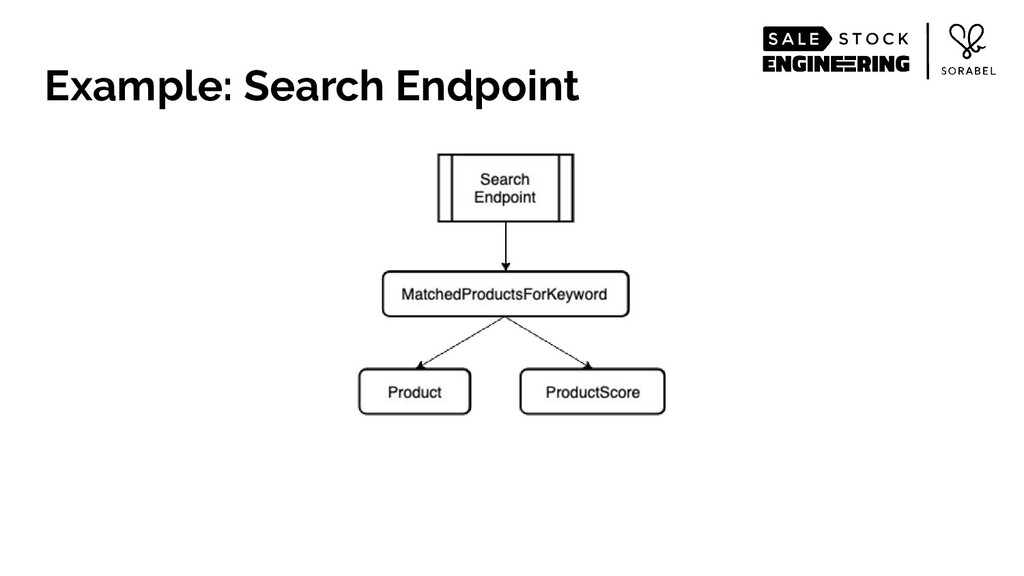
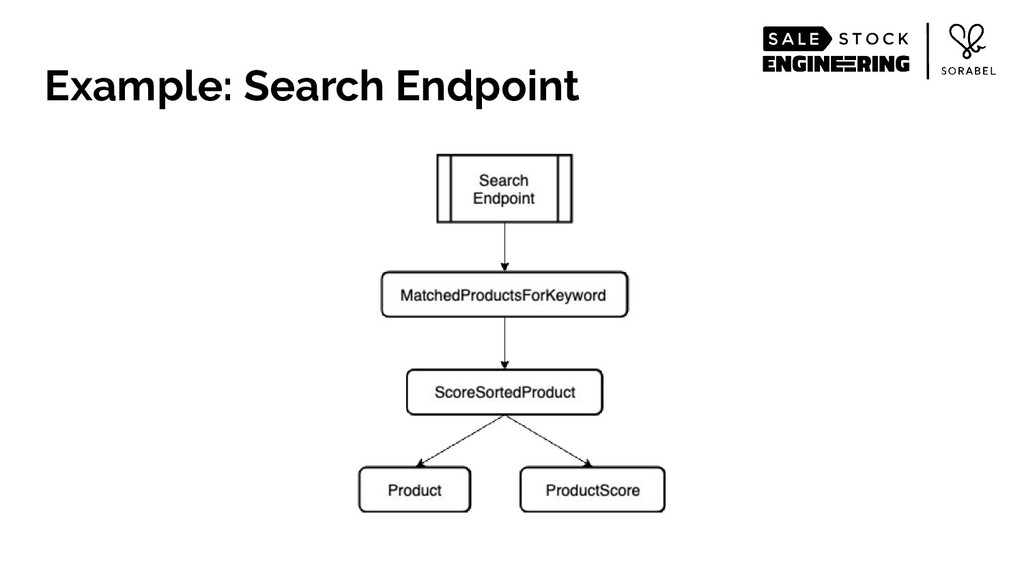
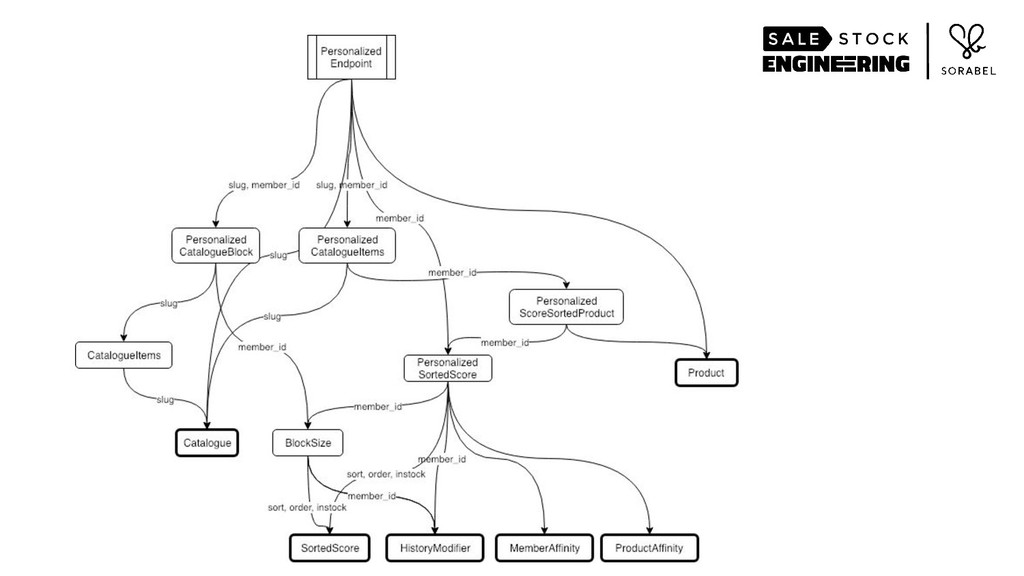
To put it simply: we eschewed all accepted practices of building web-scale services of structuring your service and data in a nicely-divided stateless and stateful layers. Instead, we loaded most of our recommendation-relevant signals — including the entirety of our product catalogue and the complex multi-dimensional data of our user behaviour and other user features that we have engineered — within a single-layer stateful service's resident memory. We then wrapped those data, alongside data science models, in an intelligently-caching, React's virtualdom-like architecture, coupled with on-the-fly, real-time custom logic, all running on Go's runtime.
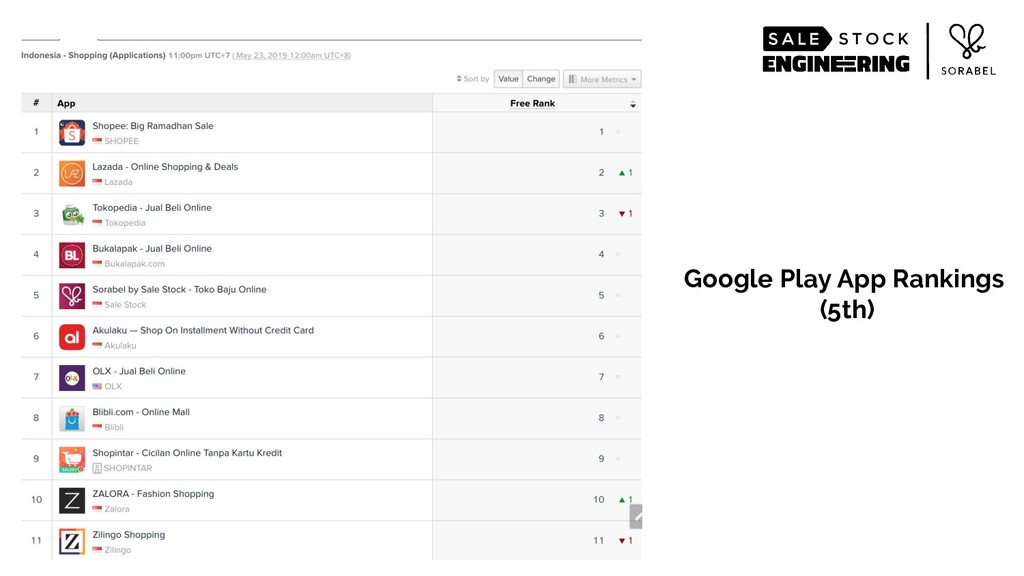
Over the half year it's been up, the new approach has given us a major boost in runtime performance, substantial increase in productivity for both engineers and data scientists, and most importantly, improvements in business metrics across the board — leading to some of the best conversion rates in the industry.
Speaker:
Ahmad Zaky is a senior backend engineer at Sorabel (previously named Sale Stock). He has been there for over two years, previously working on notification service, order gRPC microservice, and customer service system, before joining the recommender team. Before Sale Stock, he had a summer internship in Palantir in 2015, and actively participated in Competitive Programming contests. He currently resides in Bandung, and is organizing Facebook Developer Circle Bandung, monthly meetups of developers in the city.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}