する 具体的には、⼊⼒されたトークン列に対して、それぞれにクラス分類を⾏う 以前は Bidirectional LSTM-CNNs-CRF(Ma et al. 2016) を利⽤ コード例は、ブログに書いていますので、Sansan Builders Blog で BERT と検索してみてください IOB2(Inside-outside-beggining) という表現を利⽤ • B:固有表現の先頭 • I :2トークン以上で構成される固有表現の先頭以外の単語 • O:固有表現以外のトークン B, I に固有表現の種類(組織、⼈名など)を組み合わせて、ひとつのクラスを表現 ⼊⼒ 名刺 管理 サービス の Sansan 株式会社 が 出⼒ O O O O B I O
Satoshi. A survey of named entity recognition and classification. Linguisticae Investigationes, Vol. 30 , No. 1, pp.3-26, 2007. Yadav, Vikas and Steven Bethard. A Survey on Recent Advances in Named Entity Recognition from Deep Learning models. COLING, pp.2145-2158, 2018. 岩倉 友哉, 関根 聡. 実践・⾃然⾔語処理シリーズ 第4巻 情報抽出・固有表 現抽出のための基礎知識
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
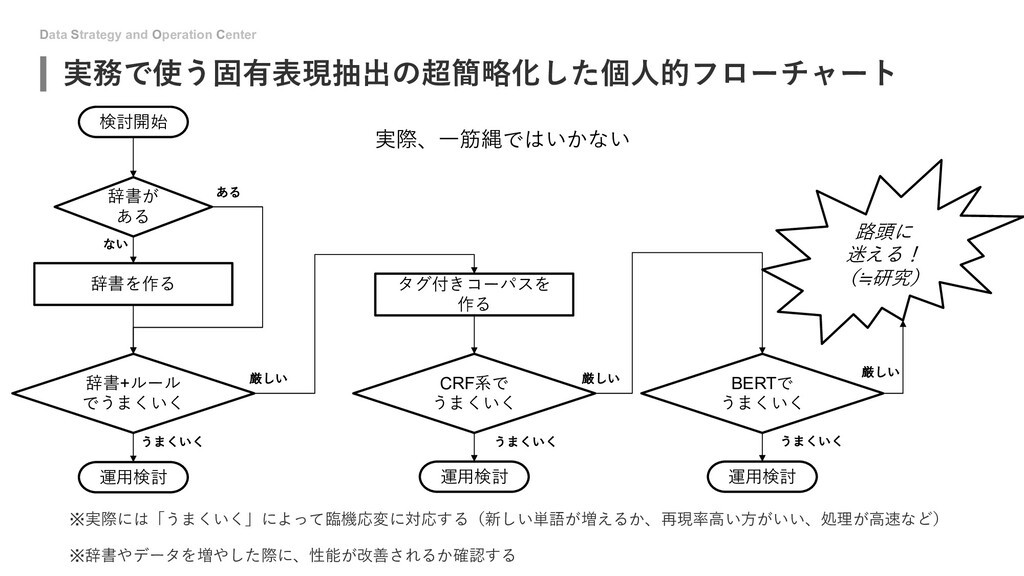{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}