이 발표에서는 2025년 상반기의 AI를 크게 근본적인 패러다임 전환과 지정학적 경쟁의 심화라는 두가지 관점으로 요약해봅니다.
이 발표자료는 2025년 7월 26일 Google I/O Extended 인천의 세션 발표 슬라이드입니다.
This presentation summarizes AI in the first half of 2025 from two main perspectives: fundamental paradigm shifts and the intensification of geopolitical competition.
These slides are from a session presentation at Google I/O Extended Incheon on July 26, 2025.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![스케일 전쟁: 5년간 만 배 [1] “Computing Power and the](https://files.speakerdeck.com/presentations/dde10d39a75a4a2589bfb435afc68e9f/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
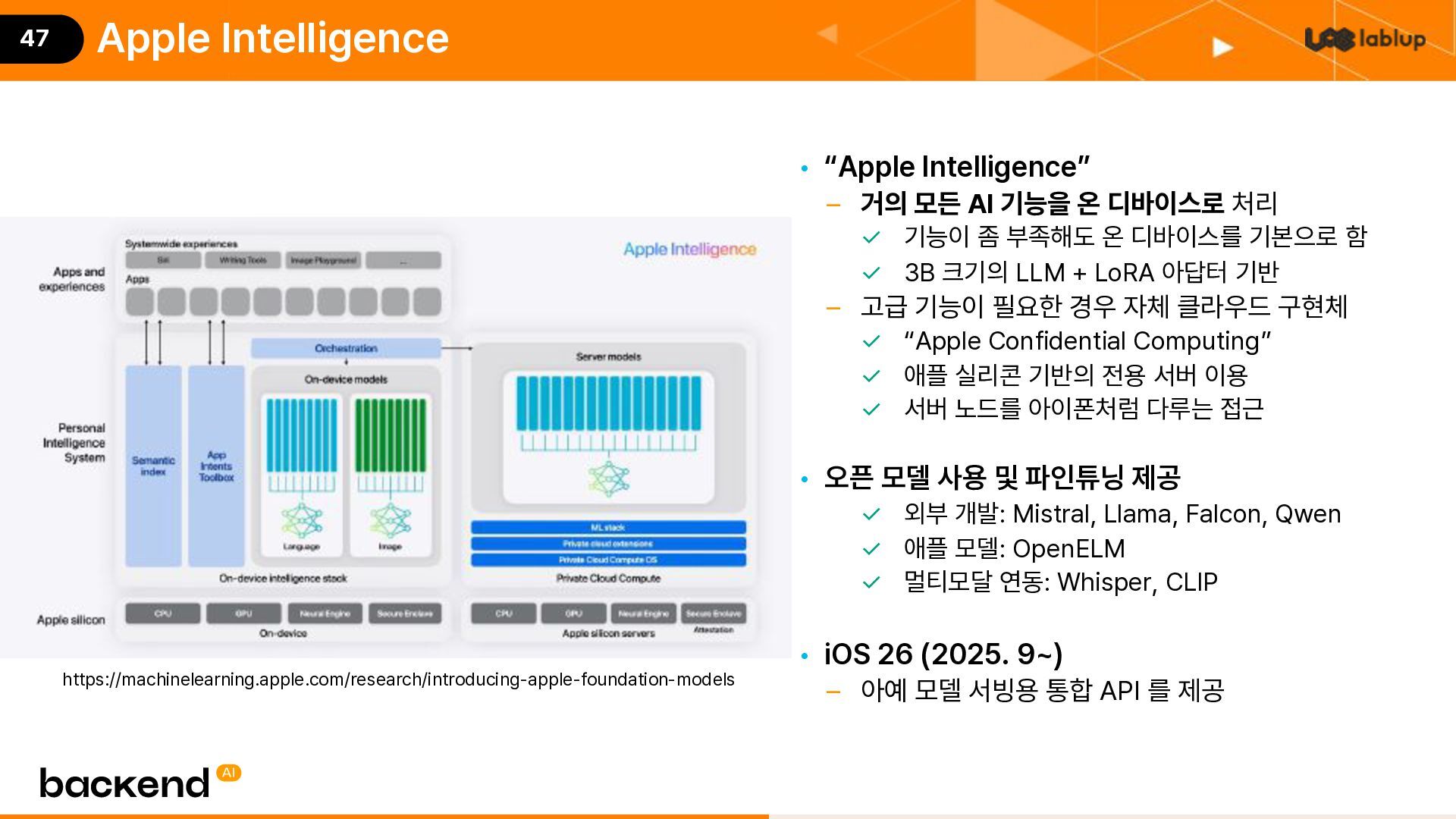{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
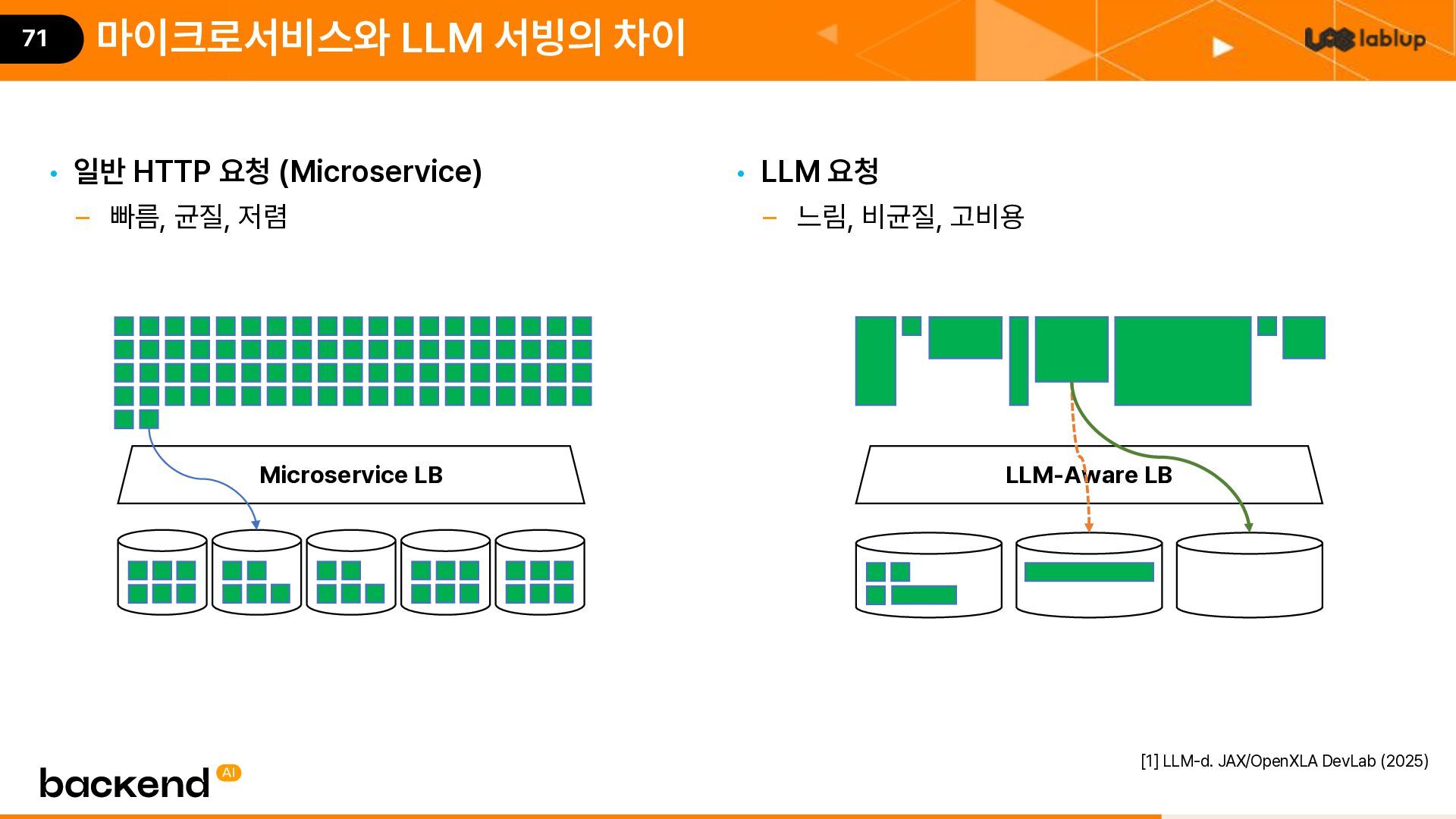{kind=link}
![• KVCache를 효율적으로 관리해보자! – vLLM (PagedAttention) [SOSP'23] ✓ OS의](https://files.speakerdeck.com/presentations/dde10d39a75a4a2589bfb435afc68e9f/slide_71.jpg){kind=link}
![NVIDIA Dynamo [1] NVIDIA Technical Blog 73](https://files.speakerdeck.com/presentations/dde10d39a75a4a2589bfb435afc68e9f/slide_72.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}