Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
OpenAI Serviceの利用料金を細かく見える化するツール作ってみた
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Akira Sato
April 14, 2026
180
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
OpenAI Serviceの利用料金を細かく見える化するツール作ってみた
JAZUG Shizuoka #4にて発表した資料です。
https://jazug.connpass.com/event/383753/
Akira Sato
April 14, 2026
More Decks by Akira Sato
See All by Akira Sato
AzureとAWS、RAGはどう作る?
satodayo
0
49
MS Ignite 2025で発表されたFoundry IQをRecap
satodayo
3
480
AI Red Teaming Agentのご紹介
satodayo
0
160
そのアクセス層の変更本当にお得ですか?
satodayo
0
27
Difyの実行環境について
satodayo
0
27
CosmosDBのベクトル検索をご紹介
satodayo
0
23
明日から使える! プロンプトエンジニアリングのテクニック集
satodayo
0
26
AI技術で簡単にPDFや画像の文字起こし! 「AI Document Intelligence」の紹介
satodayo
0
27
Featured
See All Featured
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
3
380
The World Runs on Bad Software
bkeepers
PRO
72
12k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
310
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
230
Designing for Timeless Needs
cassininazir
1
420
Faster Mobile Websites
deanohume
310
32k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.2k
Become a Pro
speakerdeck
PRO
31
6k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1.1k
How STYLIGHT went responsive
nonsquared
100
6.2k
Transcript
OpenAI Serviceの利用料金を 細かく見える化するツール作ってみた JAZUG Shizuoka 第4回 佐藤 陽
佐藤 陽 / Sato Akira サイオステクノロジー株式会社 Professional Service SL in
静岡 仕事 Azureクラウド構築 生成AIを活用したアプリ開発 ブログ執筆 / 外部登壇 趣味 運動(ロードバイク/ランニング) 音楽(FUJI ROCK FESTIVAL) 読書(森博嗣/有栖川有栖) @satodayo1115 自己紹介
自己紹介 SIOS Tech Lab. 「ツール・ド・Azure」 YouTubeにて配信中
Introduction LLMの利用料金って分かりづらくないですか?
• トークンという謎で予測困難な課金体系 • 続々と出るモデル毎に価格が異なる • 入力と出力でも金額が異なる • キャッシュによると割引サービス • 内部で(勝手に)思考したら料金++
LLM利用料金の分かりづらさ
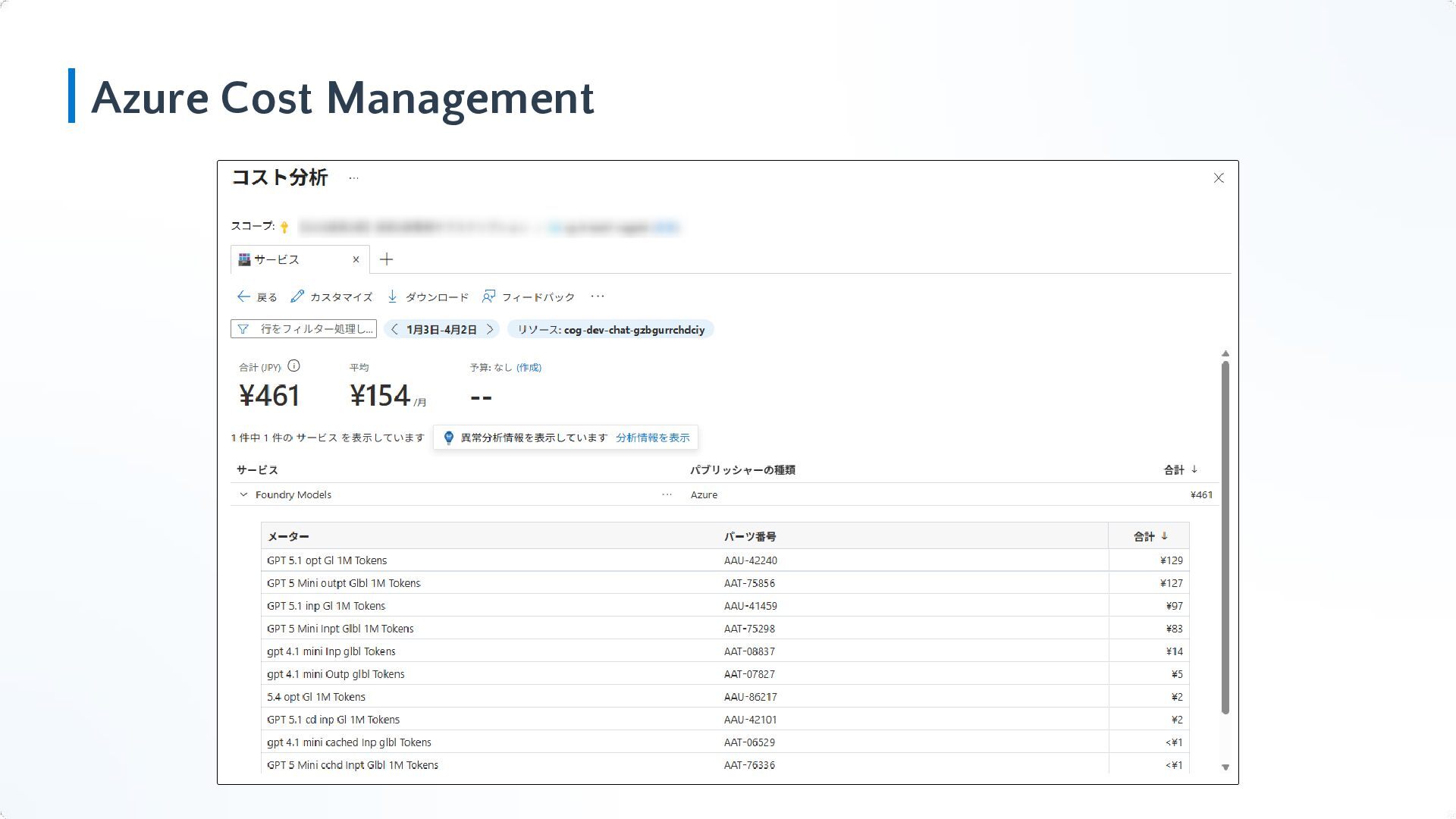
Azure Cost Management
こんな話を受けました。 チャットごとの細かい利用料金を知りたいな。 あと利用部門とかごとの料金を集計したい。 それと出来ればリアルタイムに利用料を監視したいな。 なんか使いすぎてたら即アラート発行するとかさ。 作りました!!!!!
本題 OpenAI Serviceの利用料金を 細かく見える化するツール作ってみた のでご紹介します。
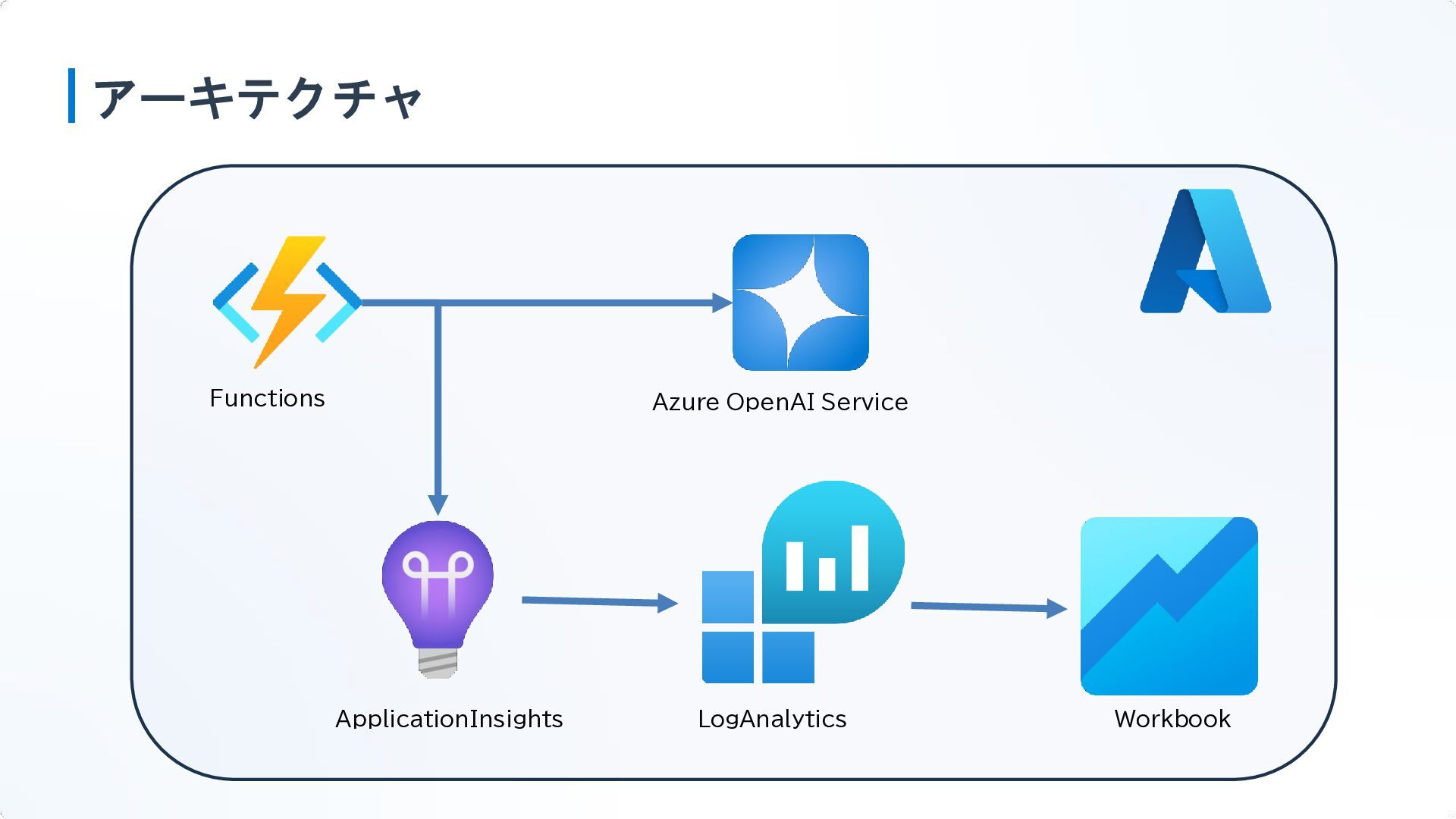
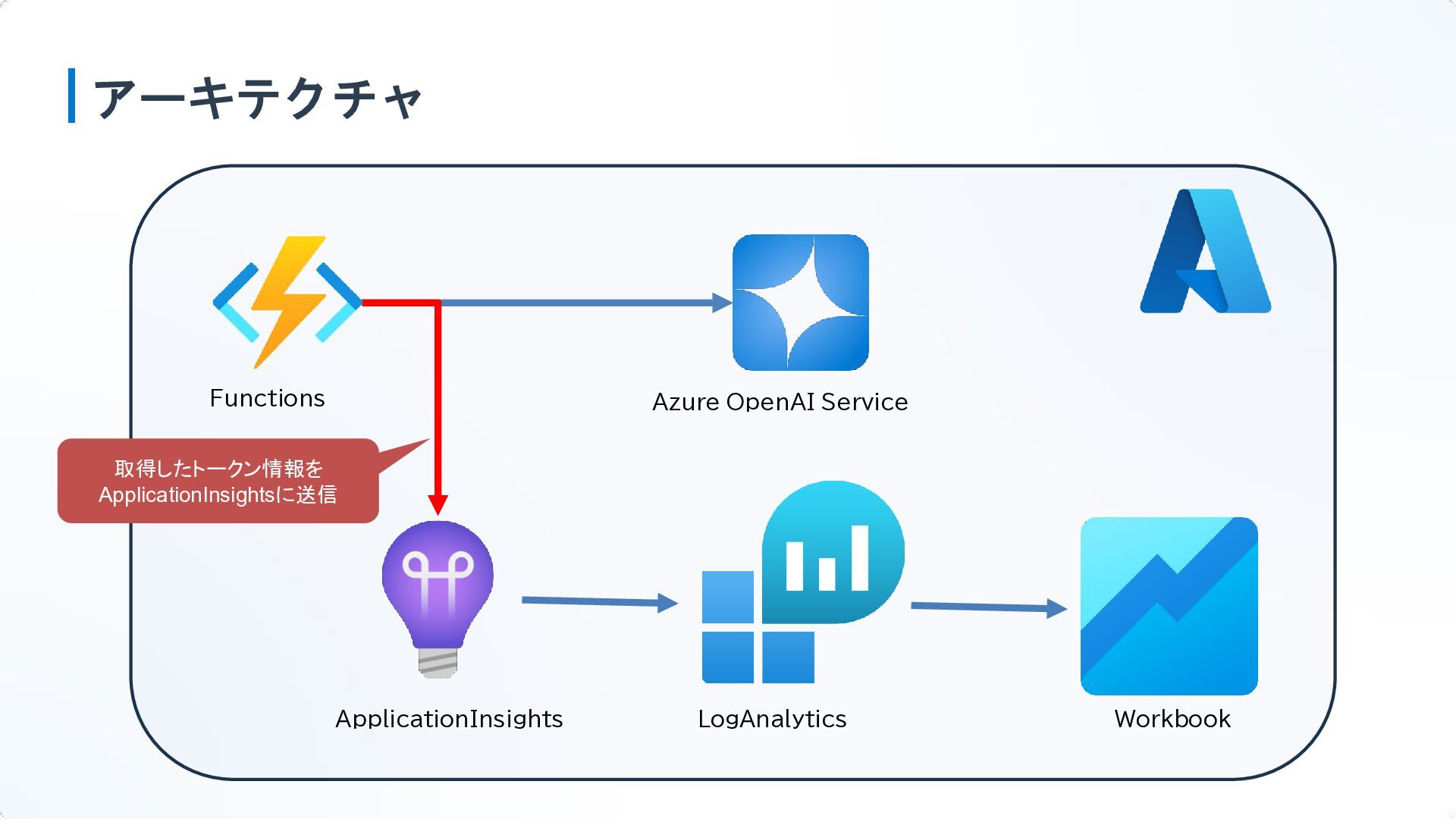
アーキテクチャ Functions Azure OpenAI Service ApplicationInsights LogAnalytics Workbook
アーキテクチャ Functions Azure OpenAI Service ApplicationInsights LogAnalytics Workbook
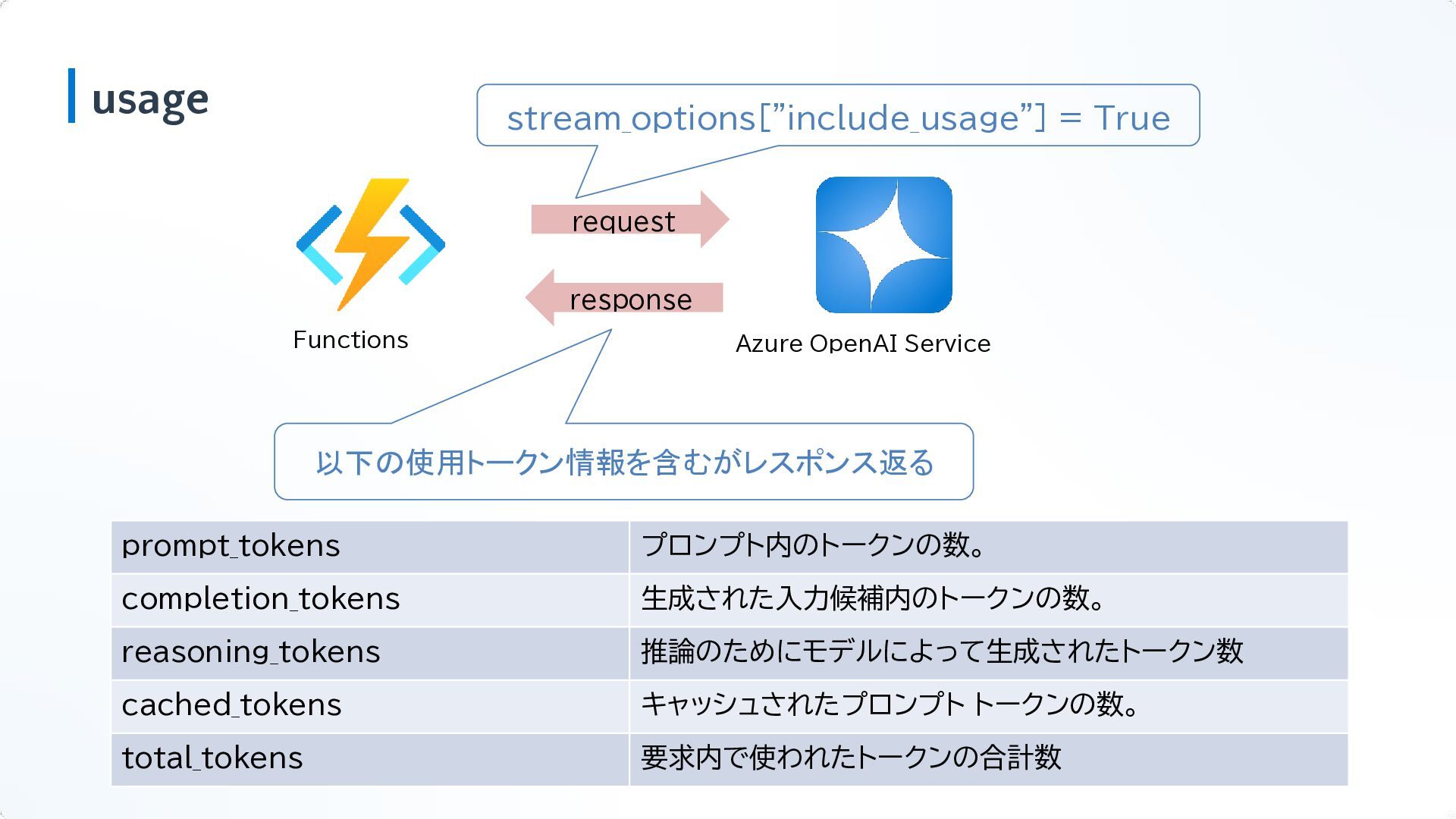
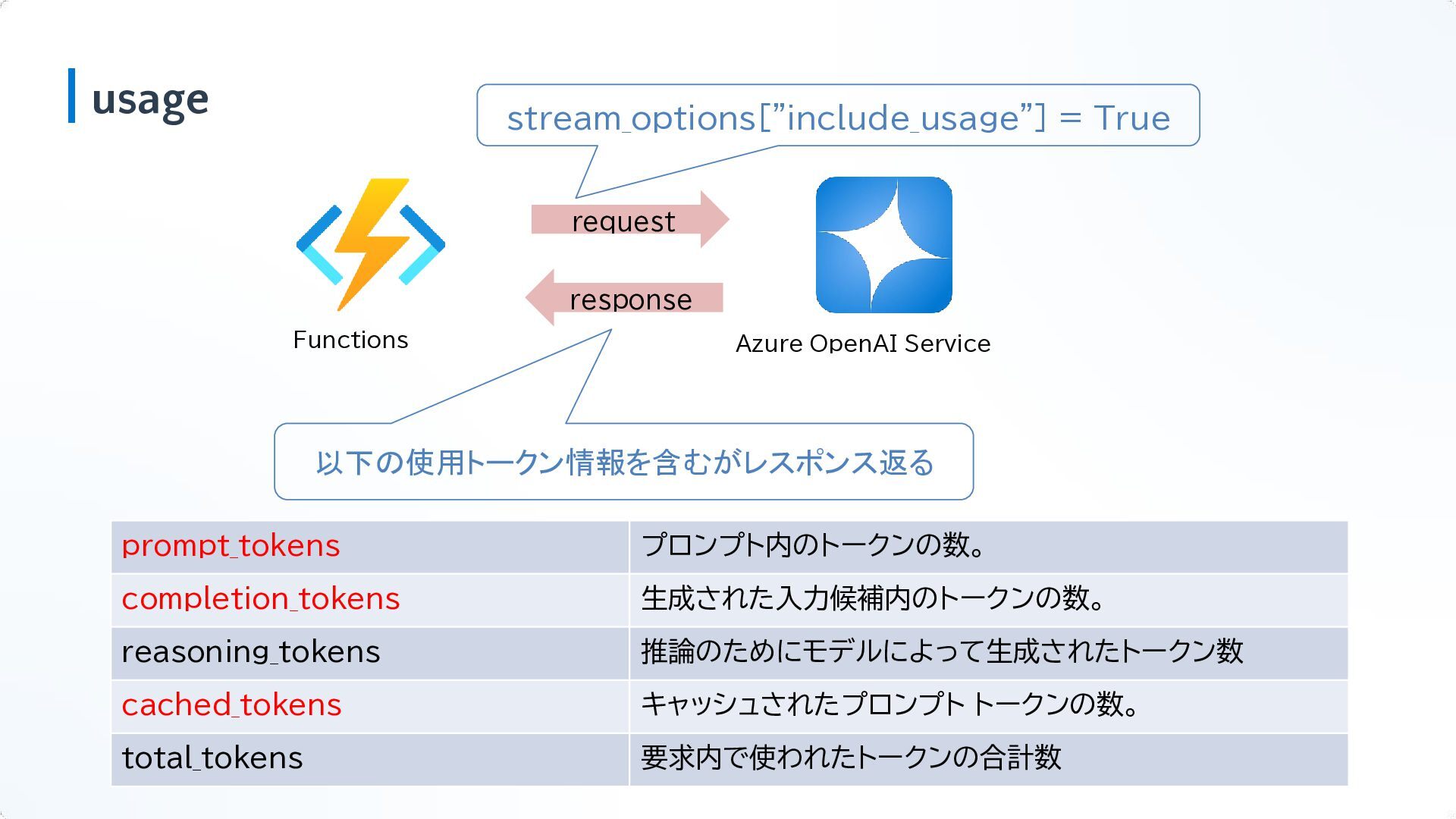
usage Functions Azure OpenAI Service request prompt_tokens プロンプト内のトークンの数。 completion_tokens 生成された入力候補内のトークンの数。
reasoning_tokens 推論のためにモデルによって生成されたトークン数 cached_tokens キャッシュされたプロンプト トークンの数。 total_tokens 要求内で使われたトークンの合計数 以下の使用トークン情報を含むがレスポンス返る response stream_options["include_usage"] = True
usage Functions Azure OpenAI Service request prompt_tokens プロンプト内のトークンの数。 completion_tokens 生成された入力候補内のトークンの数。
reasoning_tokens 推論のためにモデルによって生成されたトークン数 cached_tokens キャッシュされたプロンプト トークンの数。 total_tokens 要求内で使われたトークンの合計数 以下の使用トークン情報を含むがレスポンス返る response stream_options["include_usage"] = True
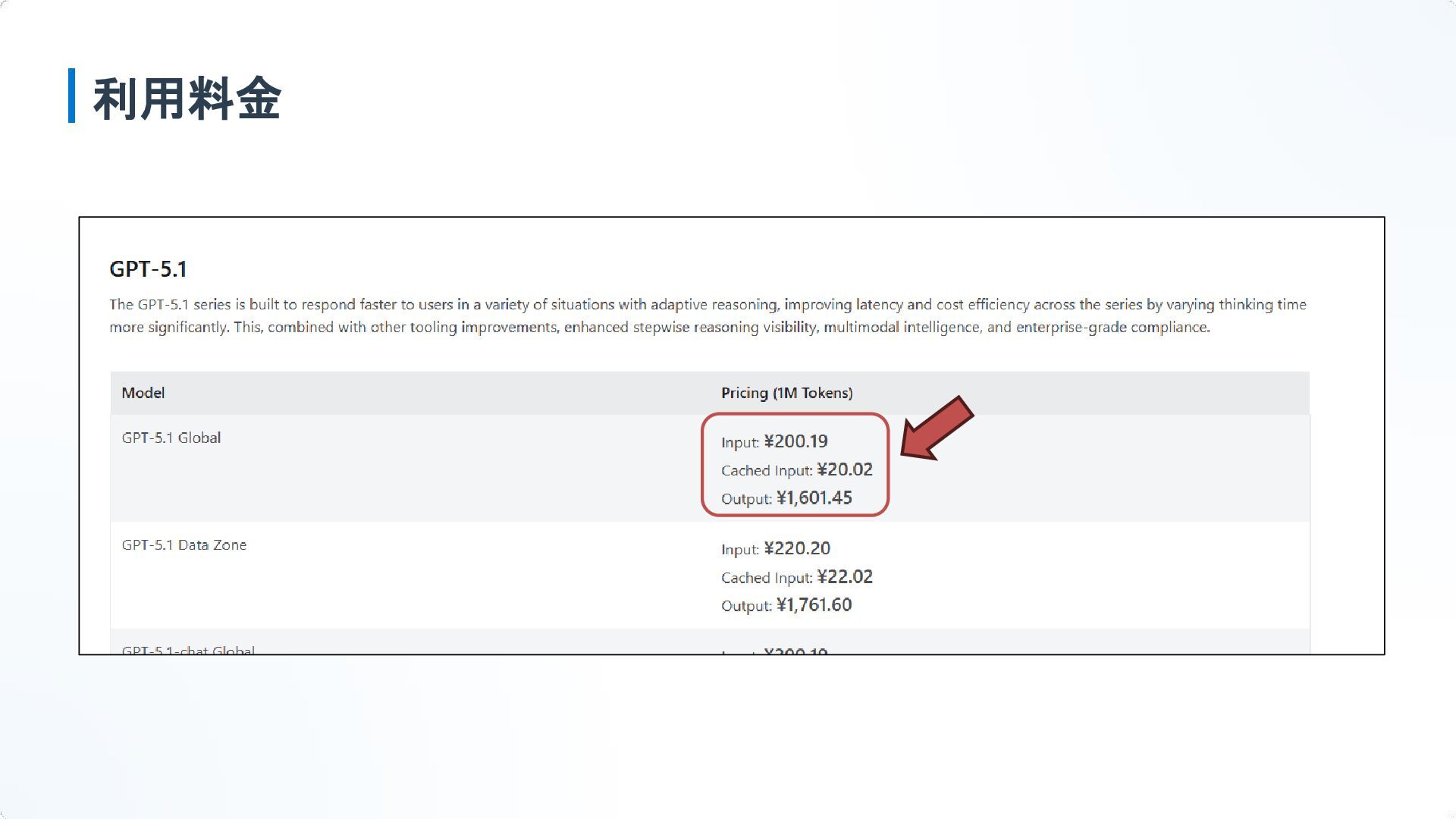
利用料金
クイズタイム プロンプトキャッシュにヒットして、入力トークンが大幅 割引になるための条件は次のうちどれでしょう? 1. Systemメッセージの長さが単体で1,024トークン以上あり、かつその内容が過去のリク エストと完全に一致している。 2. APIに送信するメッセージ配列全体が1,024トークン以上あり、その「先頭から1,024ト ークン」が完全に一致している。 3.
メッセージの長さが1,024トークン以上あり、APIリクエスト時に stream_options: {"prompt_cache": true} を明示的に指定している。
クイズタイム プロンプトキャッシュにヒットして、入力トークンが大幅 割引になるための条件は次のうちどれでしょう? 1. Systemメッセージの長さが単体で1,024トークン以上あり、かつその内容が過去のリク エストと完全に一致している。 →APIに渡す messages 配列の「一番上から数えた文字列全体」が判定対象です。 Systemメッセージが短くても、問題ありません。
2. APIに送信するメッセージ配列全体が1,024トークン以上あり、その「先頭から1,024ト ークン」が完全に一致している。 3. メッセージの長さが1,024トークン以上あり、APIリクエスト時に stream_options: {“prompt_cache”: true} を明示的に指定している。 →プロンプトキャッシュは条件を満たせば自動適用されます。 ◎
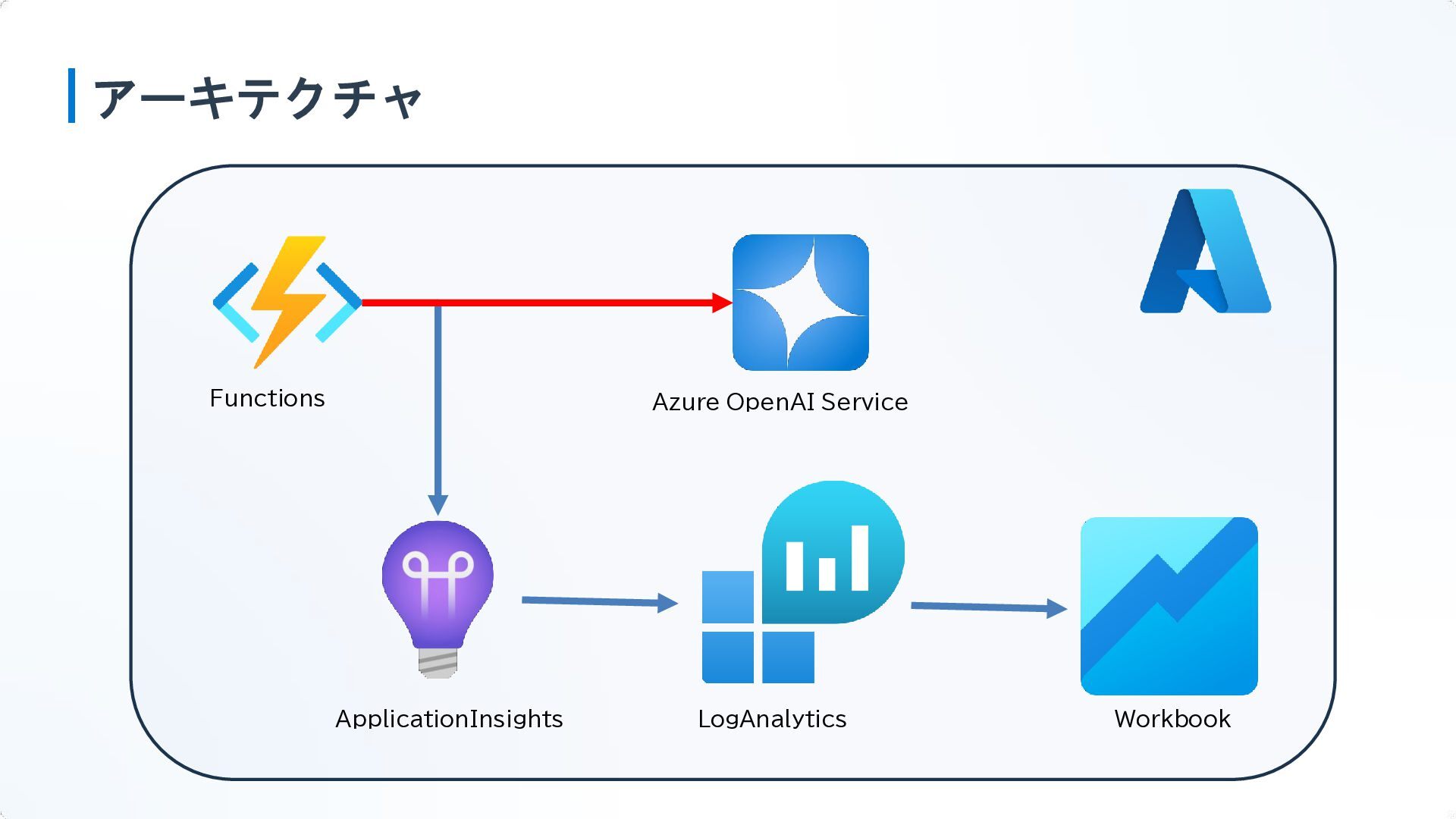
アーキテクチャ Functions Azure OpenAI Service ApplicationInsights LogAnalytics Workbook 取得したトークン情報を ApplicationInsightsに送信
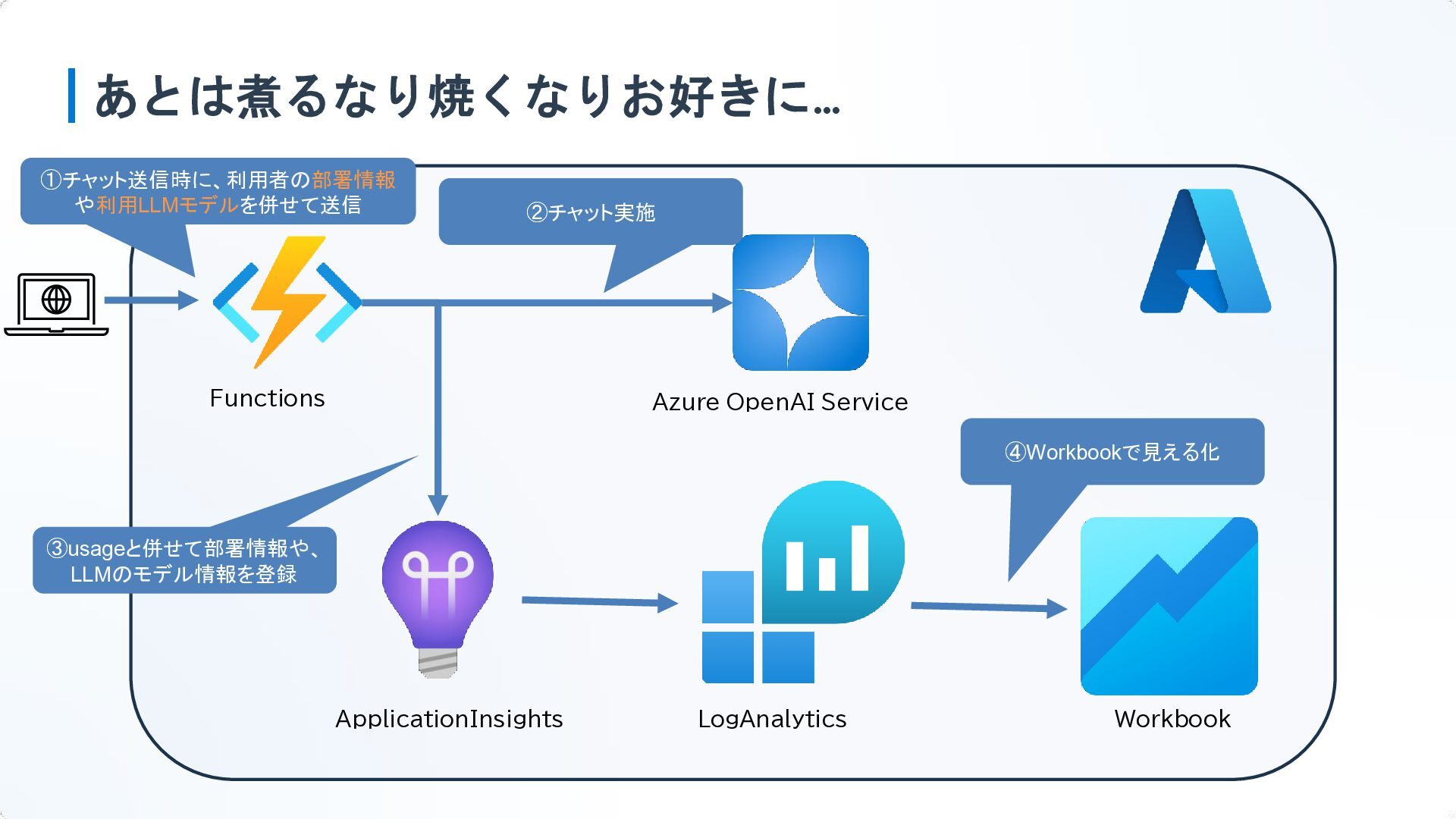
あとは煮るなり焼くなりお好きに… Functions Azure OpenAI Service ApplicationInsights LogAnalytics Workbook ①チャット送信時に、利用者の部署情報 や利用LLMモデルを併せて送信
②チャット実施 ③usageと併せて部署情報や、 LLMのモデル情報を登録 ④Workbookで見える化
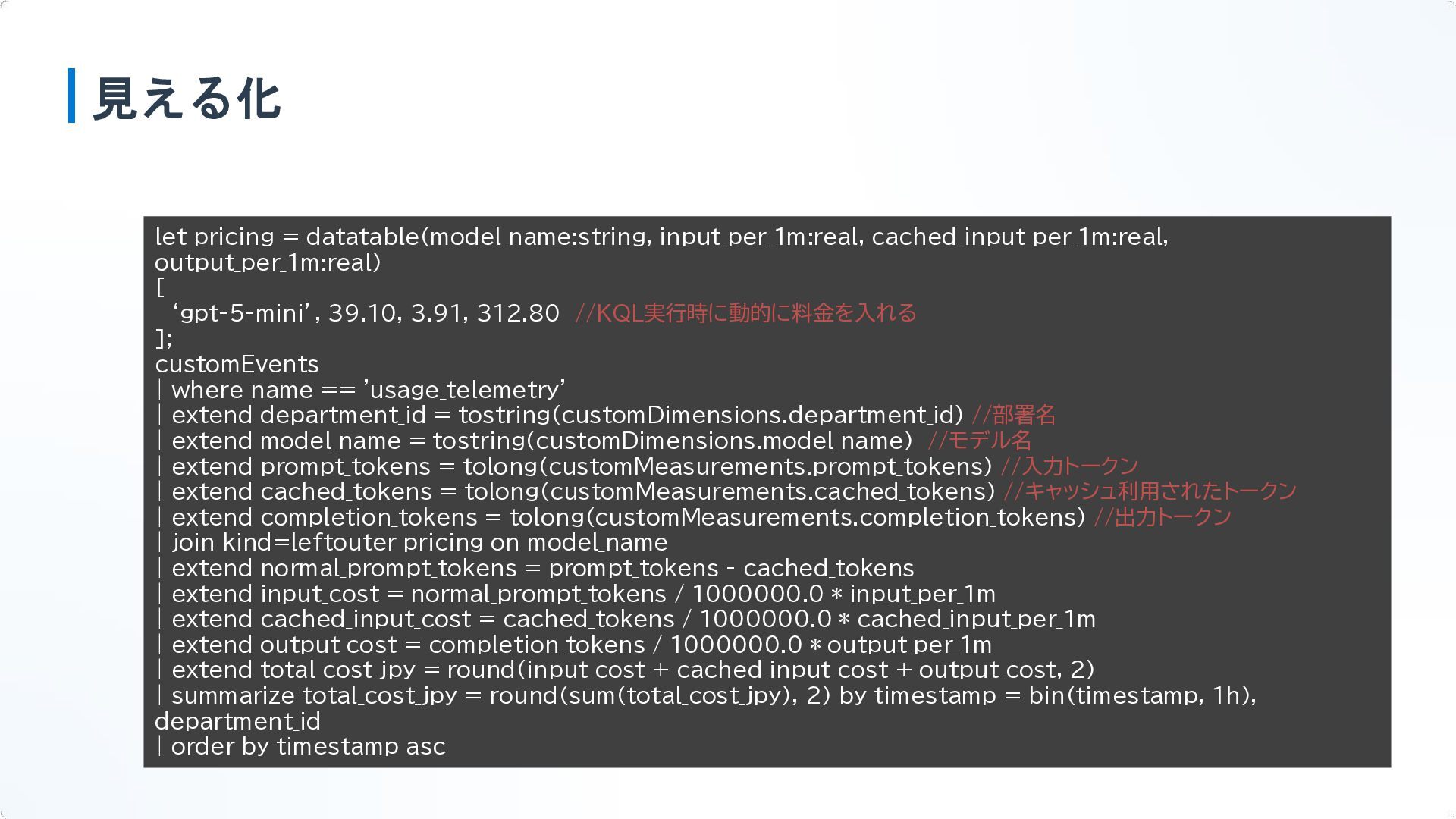
見える化 let pricing = datatable(model_name:string, input_per_1m:real, cached_input_per_1m:real, output_per_1m:real) [ ‘gpt-5-mini’,
39.10, 3.91, 312.80 //KQL実行時に動的に料金を入れる ]; customEvents | where name == 'usage_telemetry' | extend department_id = tostring(customDimensions.department_id) //部署名 | extend model_name = tostring(customDimensions.model_name) //モデル名 | extend prompt_tokens = tolong(customMeasurements.prompt_tokens) //入力トークン | extend cached_tokens = tolong(customMeasurements.cached_tokens) //キャッシュ利用されたトークン | extend completion_tokens = tolong(customMeasurements.completion_tokens) //出力トークン | join kind=leftouter pricing on model_name | extend normal_prompt_tokens = prompt_tokens - cached_tokens | extend input_cost = normal_prompt_tokens / 1000000.0 * input_per_1m | extend cached_input_cost = cached_tokens / 1000000.0 * cached_input_per_1m | extend output_cost = completion_tokens / 1000000.0 * output_per_1m | extend total_cost_jpy = round(input_cost + cached_input_cost + output_cost, 2) | summarize total_cost_jpy = round(sum(total_cost_jpy), 2) by timestamp = bin(timestamp, 1h), department_id | order by timestamp asc
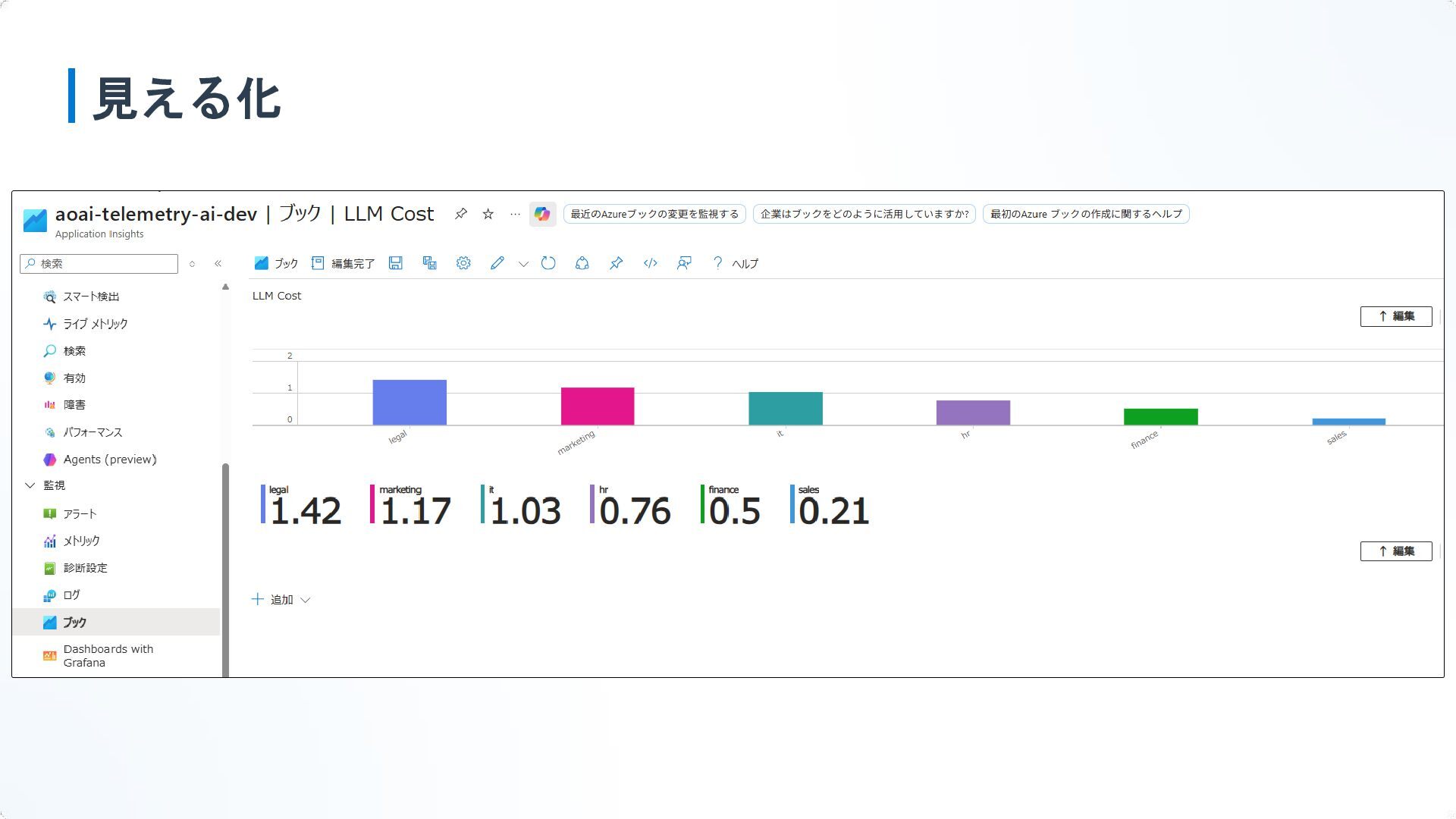
見える化
まとめ 今回作ってみたもの • Functionsでのストリーミングトークン抽出アプリ • KQLを使ったコスト表示ダッシュボード できるようになったこと • Cost Managementの遅延を待たない、秒単位でのコスト把握
• 「アプリ単位・部門単位」での正確なコスト表示 …とはいえ、RAGやエージェントアプリで本格導入を考えると大変 素直にLangSmith や Langfuse などのLLMOpsツールを使った方が良い気がします。
ブログとサンプルアプリ satodayo/azure-openai-usage-telemetry
Thank you!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}