Share
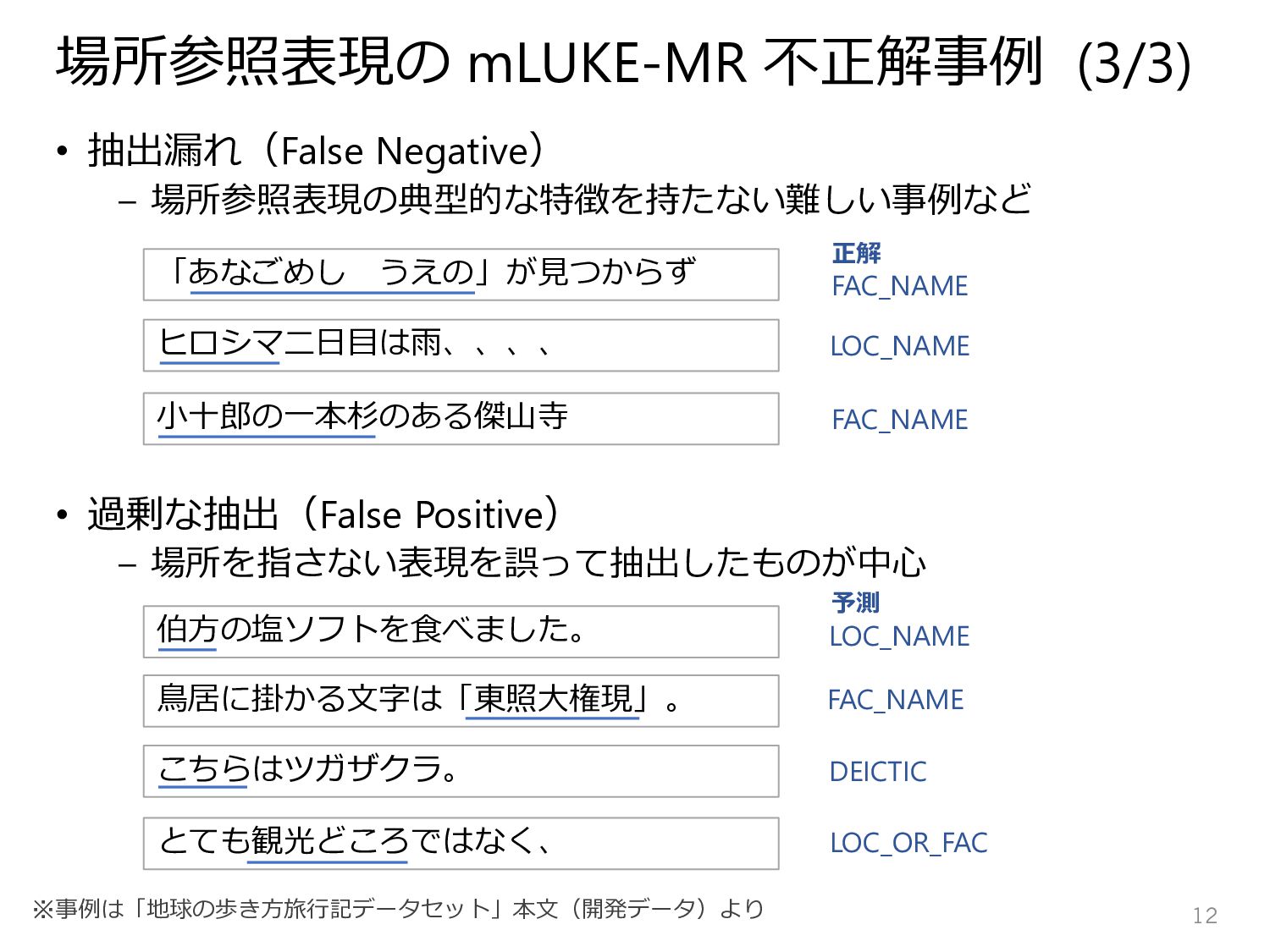
東山翔平,大内啓樹,寺西裕紀,大友寛之,井手佑翼,山本和太郎,進藤裕之,渡辺太郎.「日本語旅行記ジオパージングデータセット ATD-MCL」.言語処理学会第30回年次大会 (NLP2024),2024年3月12日. https://www.anlp.jp/proceedings/annual_meeting/2024/pdf_dir/D4-5.pdf
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}