Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
20260318_AAMT
Search
shigashiyama
March 18, 2026
Research
74
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
20260318_AAMT
「古典日本語の現代語機械翻訳のための評価資源の整備」
第1回AAMT翻訳通訳研究会,2026年3月18日.
shigashiyama
March 18, 2026
More Decks by shigashiyama
See All by shigashiyama
20250706_IPSJ-NL-264
shigashiyama
0
52
Lexical Analysis
shigashiyama
1
330
20241108_CS_LLMMT
shigashiyama
0
810
CADEL@IPSJ-NL-260
shigashiyama
0
190
ATD-MCL@NLP2024
shigashiyama
0
150
Word Segmentation and Lexical Normalization for Unsegmented Languages
shigashiyama
0
520
Character-to-Word Attention for Word Segmentation
shigashiyama
0
250
Other Decks in Research
See All in Research
人間中心の意思決定支援AI
yukinobaba
PRO
7
3.4k
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
220
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
7
3.6k
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
670
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
480
AIで最適化を解けるか?
mickey_kubo
0
140
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
700
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
610
Φ-Sat-2のAutoEncoderによる情報圧縮系論文
satai
4
850
議論 学術ムーブメントを成功させるために何が必要なのだろうか
rmaruy
0
100
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
380
AGI4OPT:自然言語から数理最適化を導くエ ージェントスキル Translating Human Intent into Mathematical Optimization
mickey_kubo
0
160
Featured
See All Featured
Faster Mobile Websites
deanohume
310
32k
GitHub's CSS Performance
jonrohan
1033
470k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Navigating Weather and Climate Data
rabernat
0
370
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Transcript
古典日本語の現代語機械翻訳 のための評価資源の整備 東山 翔平1 大内 啓樹2 橋本 雄太3 藤田 篤1
1情報通信研究機構 2奈良先端科学技術大学院大学 3国立歴史民俗博物館 1 第1回AAMT翻訳通訳研究会(2026/3/18) 日本語の古語 (本研究では平安時代末期 ~江戸時代) 本発表は、以下の発表内容に基づくものです: • 東山 他,「中世・近世日本語資料の現代語機械翻訳における自動評価指標の検証」,じんもんこん2025. • 東山 他,「中世・近世日本語資料の現代語機械翻訳:評価用対訳データセットの構築とLLMの性能評価」,NLP2026.
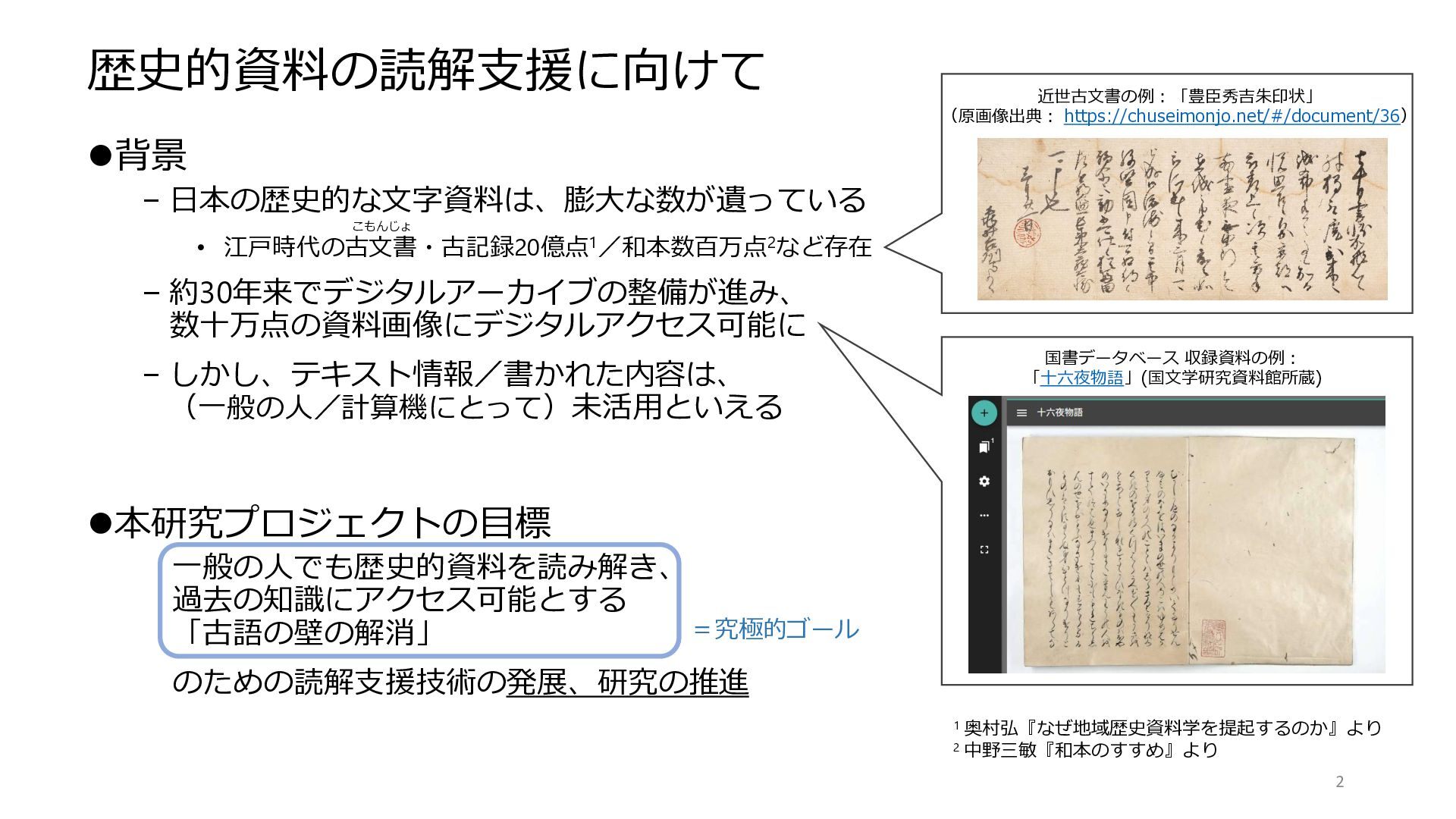
歴史的資料の読解支援に向けて ⚫背景 – 日本の歴史的な文字資料は、膨大な数が遺っている • 江戸時代の古文書・古記録20億点1/和本数百万点2など存在 – 約30年来でデジタルアーカイブの整備が進み、 数十万点の資料画像にデジタルアクセス可能に –
しかし、テキスト情報/書かれた内容は、 (一般の人/計算機にとって)未活用といえる ⚫本研究プロジェクトの目標 一般の人でも歴史的資料を読み解き、 過去の知識にアクセス可能とする 「古語の壁の解消」 のための読解支援技術の発展、研究の推進 2 国書データベース 収録資料の例: 「十六夜物語」(国文学研究資料館所蔵) =究極的ゴール 1 奥村弘『なぜ地域歴史資料学を提起するのか』より 2 中野三敏『和本のすすめ』より 近世古文書の例:「豊臣秀吉朱印状」 (原画像出典: https://chuseimonjo.net/#/document/36) こもんじょ
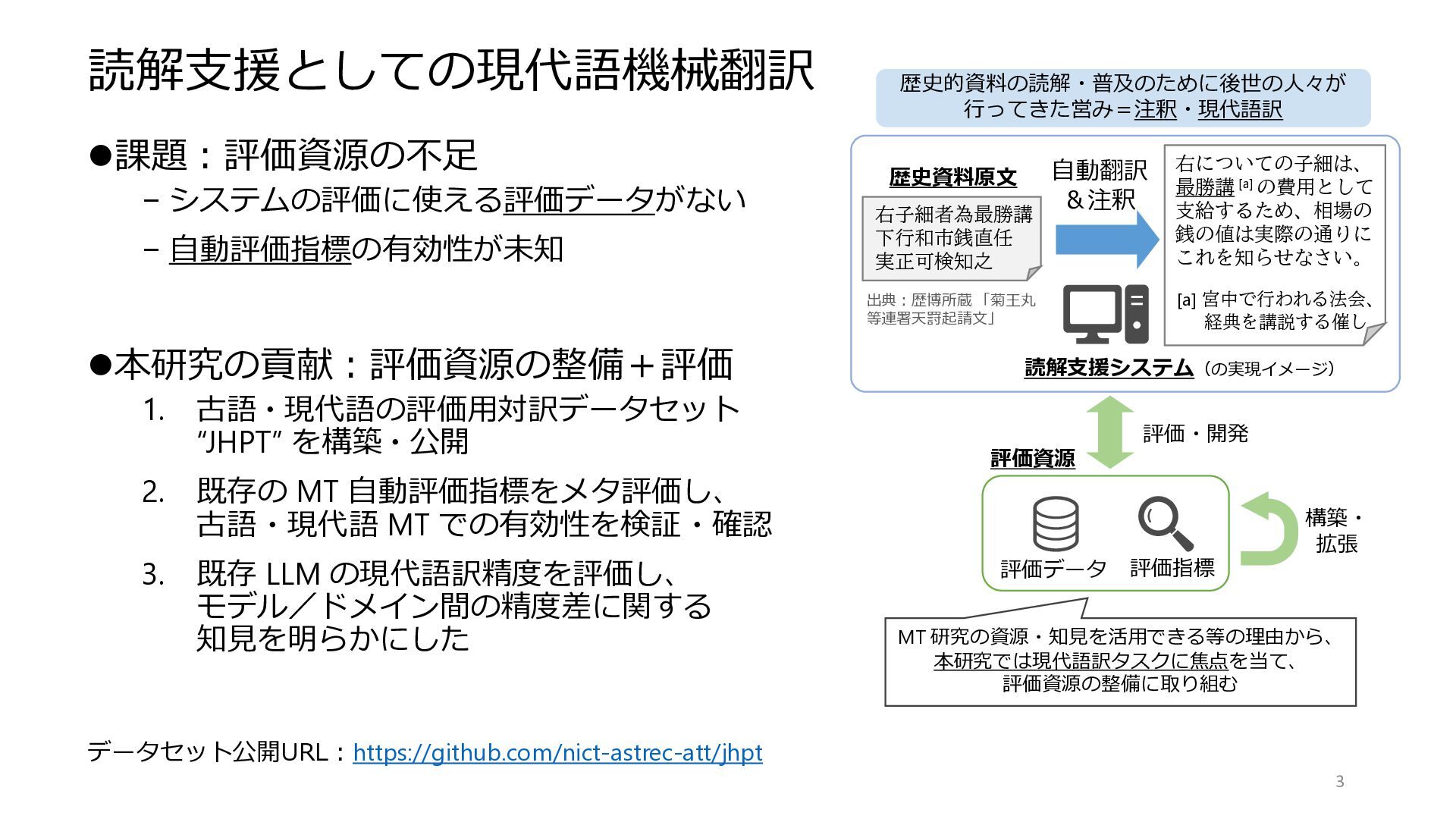
読解支援としての現代語機械翻訳 ⚫課題:評価資源の不足 – システムの評価に使える評価データがない – 自動評価指標の有効性が未知 ⚫本研究の貢献:評価資源の整備+評価 1. 古語 ・
現代語の評価用対訳データセット “JHPT” を構築 ・ 公開 2. 既存の MT 自動評価指標をメタ評価し、 古語・現代語 MT での有効性を検証・確認 3. 既存 LLM の現代語訳精度を評価し、 モデル/ドメイン間の精度差に関する 知見を明らかにした 3 MT 研究の資源・知見を活用できる等の理由から、 本研究では現代語訳タスクに焦点を当て、 評価資源の整備に取り組む データセット公開URL:https://github.com/nict-astrec-att/jhpt 評価データ 評価指標 読解支援システム(の実現イメージ) 歴史資料原文 出典:歴博所蔵 「菊王丸 等連署天罸起請文」 右についての子細は、 最勝講 [a] の費用として 支給するため、相場の 銭の値は実際の通りに これを知らせなさい。 [a] 宮中で行われる法会、 経典を講説する催し 評価資源 評価・開発 自動翻訳 &注釈 構築・ 拡張 歴史的資料の読解・普及のために後世の人々が 行ってきた営み=注釈・現代語訳 右子細者為最勝講 下行和市銭直任 実正可検知之
関連研究 4
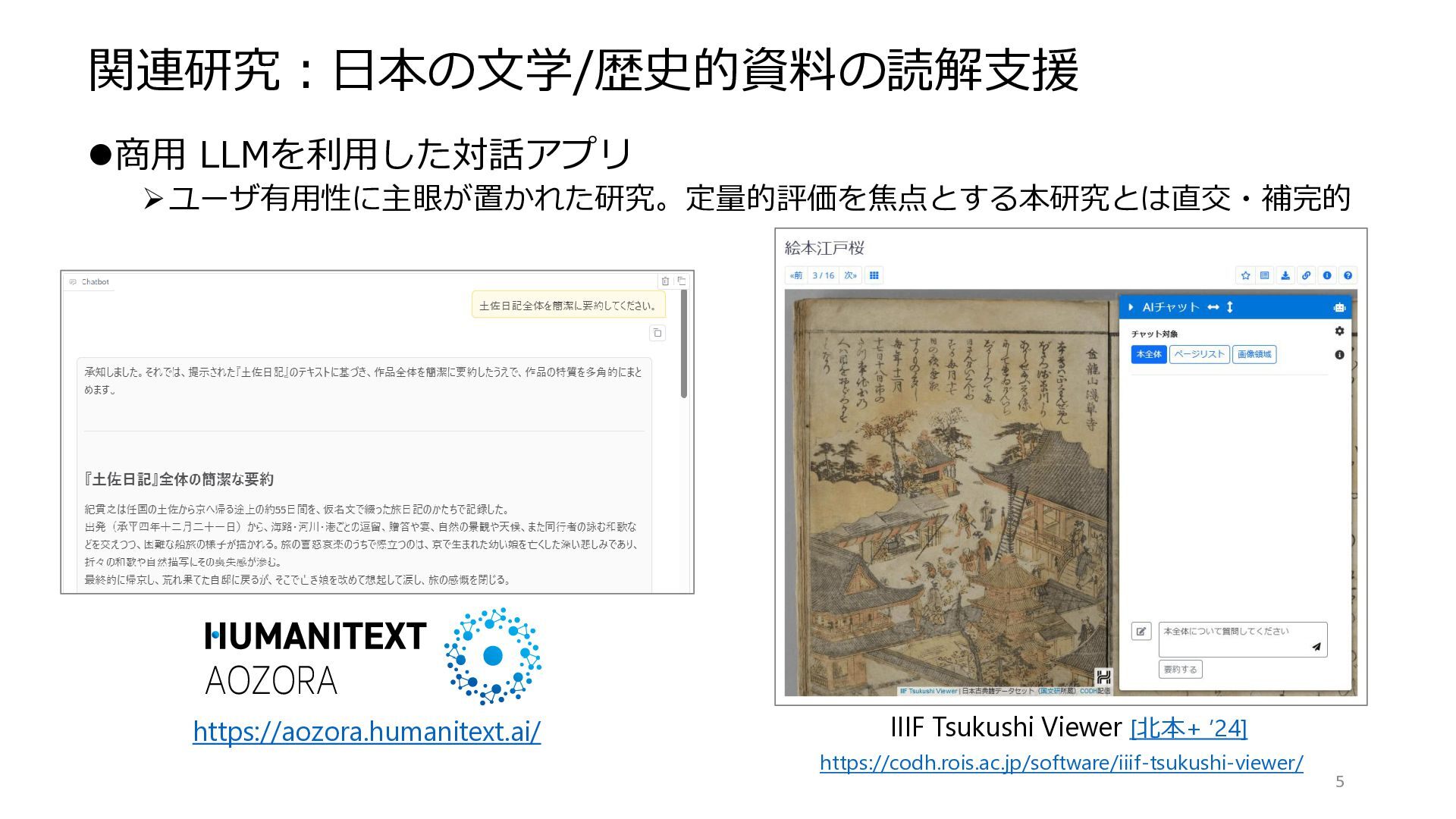
関連研究:日本の文学/歴史的資料の読解支援 ⚫商用 LLMを利用した対話アプリ ➢ユーザ有用性に主眼が置かれた研究。定量的評価を焦点とする本研究とは直交・補完的 5 https://aozora.humanitext.ai/ IIIF Tsukushi Viewer [北本+
’24] https://codh.rois.ac.jp/software/iiif-tsukushi-viewer/
関連研究:古語→現代語の機械翻訳 ⚫ラテン語 [Volk+ ‘24] – 商用 NMT と商用 LLM(GPT-4)の翻訳精度を評価 ⚫仏教漢語(Buddhist
Chinese) [Nehrdich+ ’23; ‘25] – 対訳データ(21万文対)の構築、NMT/LLM の微調整・翻訳精度評価、 自動評価指標のメタ評価、などを実施 ⚫日本の古典文学 [星野+ ’15; Usui+ ‘23] – 非公開コーパス(小学館『新編日本古典文学全集』)から作成された対訳を使用し、 SMT や NMT を学習・評価 ➢ ただし、後続の研究者が同コーパスを利用して研究を行うことや、 成果物を一般公開することは困難 6
関連研究:古語→現代語の機械翻訳 ⚫日本の古文書1 [橋本+ ‘25] – 中世・近世古文書を商用 LLM に現代語訳させ、品質を人手評価(文単位および単語単位) – 人手評価の過程で、既存の/新規に人手作成した現代語訳を利用
7 こもんじょ 橋本ら公開のオリジナルデータ:現代語訳・LLM生成訳・人手評価結果(図では単語単位) 本研究にて活用 • 原文・現代語訳を 対訳データの一部に利用 • LLM 生成訳とともに、 0~1に換算した 人手評価スコアを、 メタ評価に利用 1 「古文書」は、歴史学研究の素材となる文献史料のうち、差出者から受取者へ宛てて書かれたもの(公的/私的な書状)。 差出者・受取者のない文献史料は「古記録」にあたる。
貢献①:対訳データセット構築 8
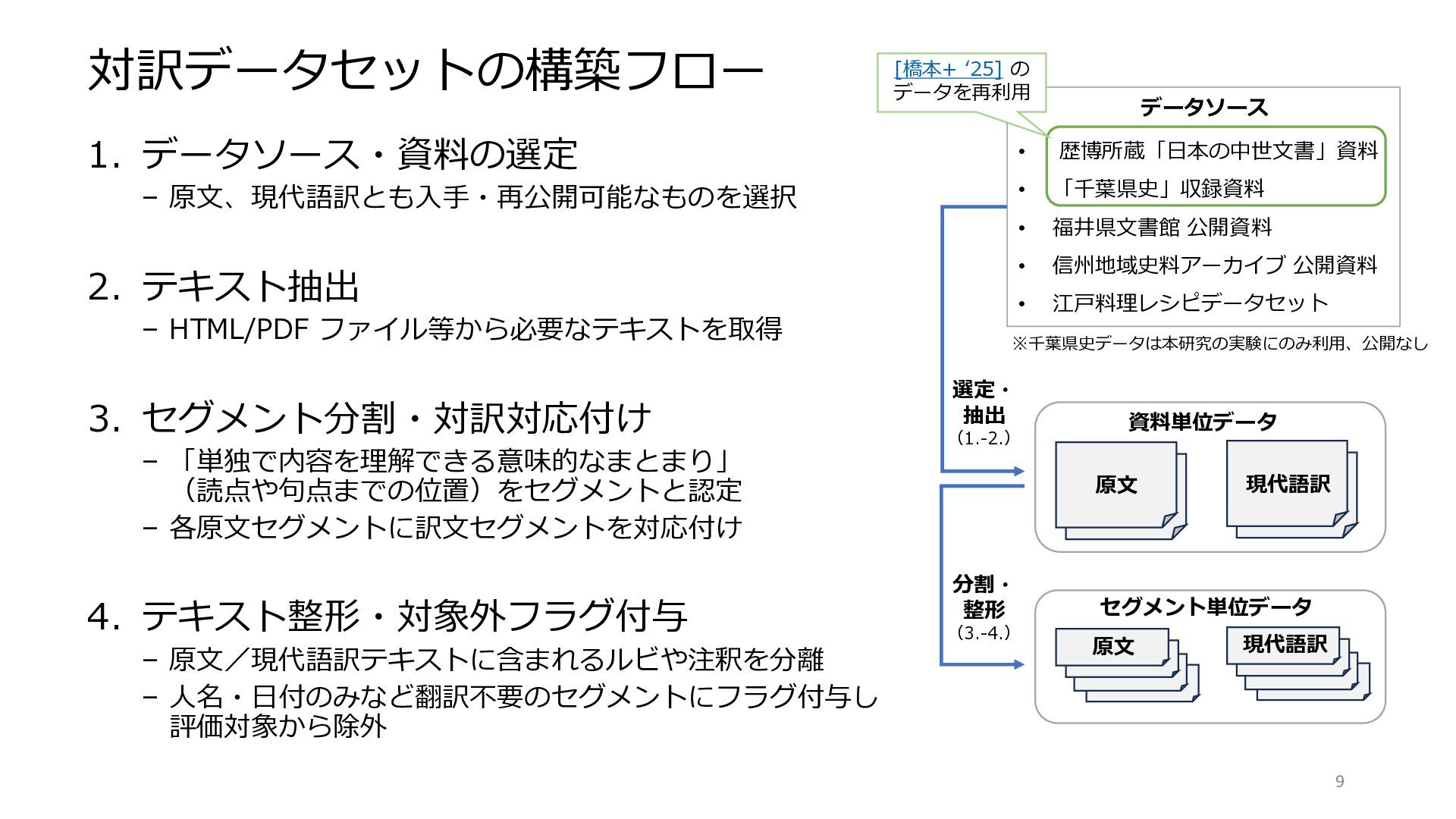
対訳データセットの構築フロー 1. データソース・資料の選定 – 原文、現代語訳とも入手・再公開可能なものを選択 2. テキスト抽出 – HTML/PDF ファイル等から必要なテキストを取得
3. セグメント分割・対訳対応付け – 「単独で内容を理解できる意味的なまとまり」 (読点や句点までの位置)をセグメントと認定 – 各原文セグメントに訳文セグメントを対応付け 4. テキスト整形・対象外フラグ付与 – 原文/現代語訳テキストに含まれるルビや注釈を分離 – 人名・日付のみなど翻訳不要のセグメントにフラグ付与し 評価対象から除外 9 • 歴博所蔵「日本の中世文書」資料 • 「千葉県史」収録資料 • 福井県文書館 公開資料 • 信州地域史料アーカイブ 公開資料 • 江戸料理レシピデータセット 資料単位データ 原文 現代語訳 セグメント単位データ 原文 現代語訳 データソース ※千葉県史データは本研究の実験にのみ利用、公開なし 選定・ 抽出 (1.-2.) 分割・ 整形 (3.-4.) [橋本+ ‘25] の データを再利用
貢献②:機械翻訳自動評価指標の有効性検証 10
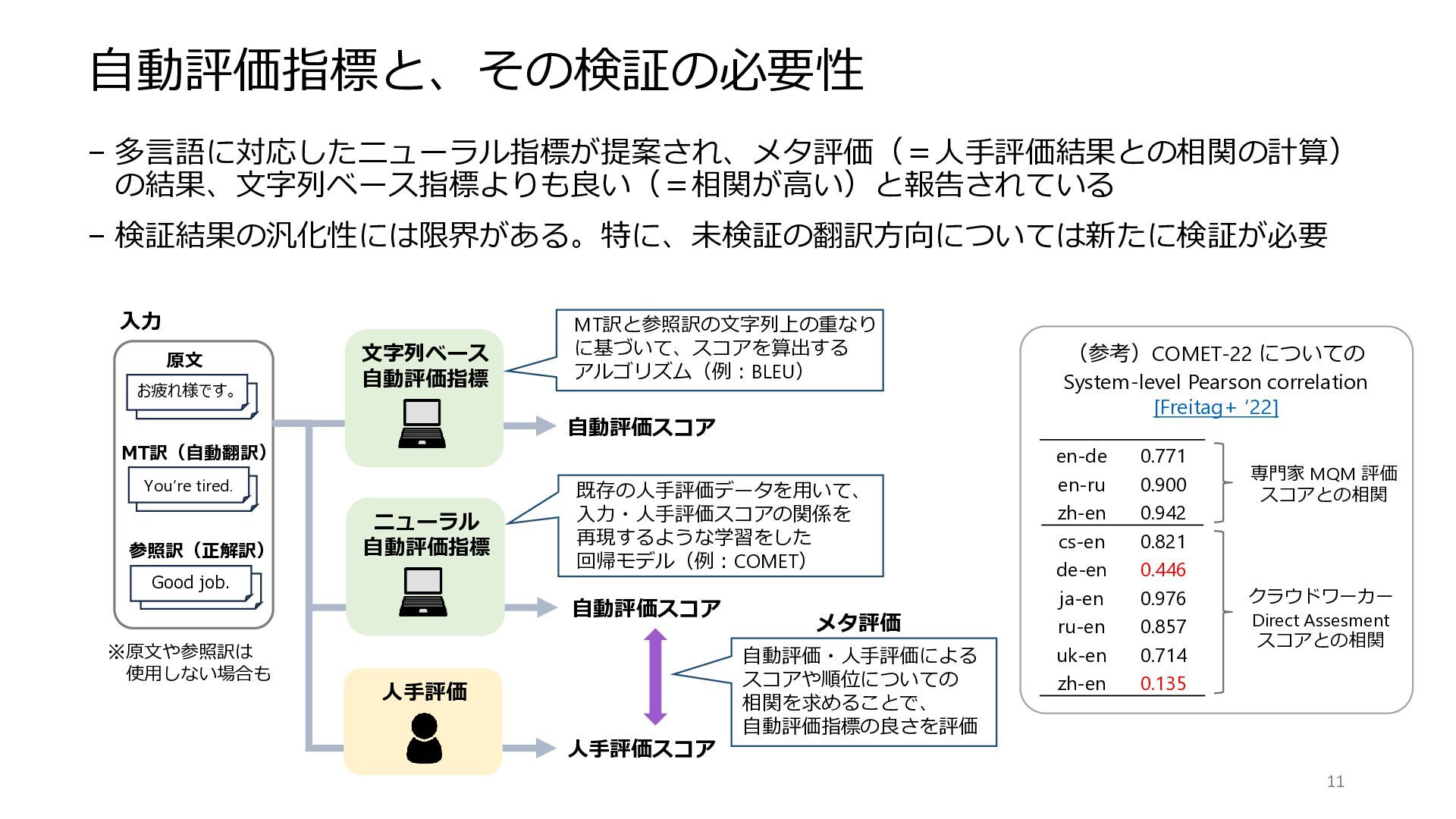
自動評価指標と、その検証の必要性 – 多言語に対応したニューラル指標が提案され、メタ評価(=人手評価結果との相関の計算) の結果、文字列ベース指標よりも良い(=相関が高い)と報告されている – 検証結果の汎化性には限界がある。特に、未検証の翻訳方向については新たに検証が必要 文字列ベース 自動評価指標 自動評価スコア 原文
お疲れ様です。 MT訳(自動翻訳) You’re tired. 参照訳(正解訳) Good job. 自動評価スコア ニューラル 自動評価指標 人手評価スコア 人手評価 既存の人手評価データを用いて、 入力・人手評価スコアの関係を 再現するような学習をした 回帰モデル(例:COMET) MT訳と参照訳の文字列上の重なり に基づいて、スコアを算出する アルゴリズム(例:BLEU) 11 自動評価・人手評価による スコアや順位についての 相関を求めることで、 自動評価指標の良さを評価 (参考)COMET-22 についての System-level Pearson correlation [Freitag+ ‘22] ※原文や参照訳は 使用しない場合も en-de 0.771 en-ru 0.900 zh-en 0.942 cs-en 0.821 de-en 0.446 ja-en 0.976 ru-en 0.857 uk-en 0.714 zh-en 0.135 専門家 MQM 評価 スコアとの相関 クラウドワーカー Direct Assesment スコアとの相関 メタ評価 入力
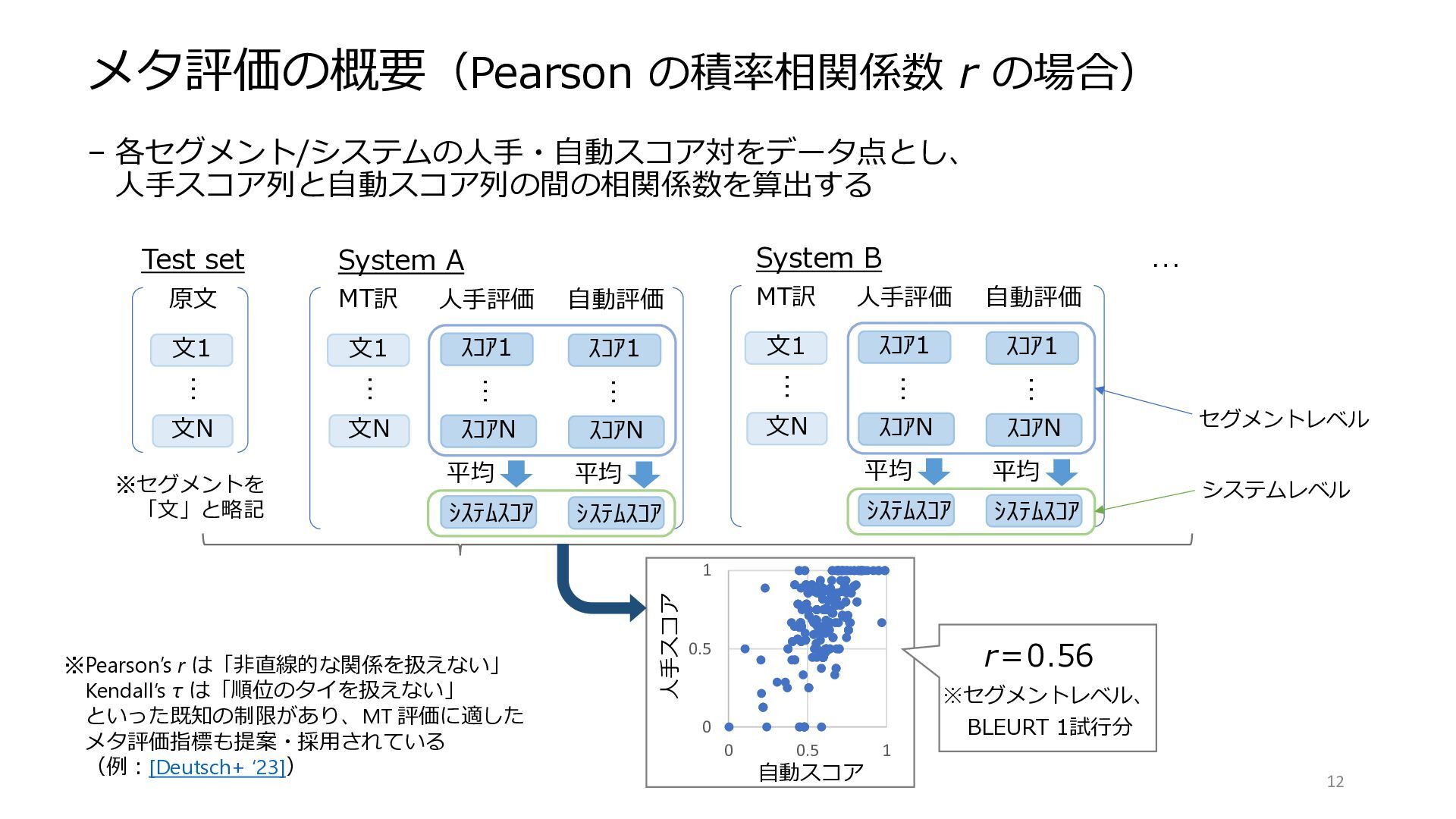
メタ評価の概要(Pearson の積率相関係数 r の場合) – 各セグメント/システムの人手・自動スコア対をデータ点とし、 人手スコア列と自動スコア列の間の相関係数を算出する 12 … 0
0.5 1 0 0.5 1 人手スコア 自動スコア r=0.56 ※セグメントレベル、 BLEURT 1試行分 System A 文1 … 文N スコア1 スコアN 平均 人手評価 MT訳 システムスコア 自動評価 文1 … 文N 原文 … スコア1 スコアN 平均 システムスコア … System B 文1 … 文N スコア1 スコアN 平均 人手評価 MT訳 システムスコア 自動評価 … スコア1 スコアN 平均 システムスコア … Test set ※セグメントを 「文」と略記 ※Pearson’s r は「非直線的な関係を扱えない」 Kendall’s τ は「順位のタイを扱えない」 といった既知の制限があり、MT 評価に適した メタ評価指標も提案・採用されている (例:[Deutsch+ ‘23]) セグメントレベル システムレベル
実験:LLM 4モデルの自動評価結果のメタ評価 ⚫設定 – [橋本+ ‘25] のデータを再利用し、中世・近世古文書資料の原文67セグメントに対する 4システム(Claude Sonnet 3.5,
Gemini 1.5, GPT-4o, DeepSeek-R1)の生成訳を利用 – 「4システム×67セグメント」(Segment level) 、「4システム」(System level) について、 自動評価(6指標のいずれか)と人手評価のスコア/順位間の相関を求める – 67セグメントから復元抽出する(各試行でN事例から重複を許してN事例を抽出) Bootstrap resampling を1000試行行い、相関係数値の平均と95%信頼区間を求めた 13 タイプ 評価指標 ツール/モデル 学習方法 日本語のMT人手評価 データでの微調整 入力 文字列 BLEU SacreBLEU なし - (MT訳, 参照訳) 文字列 chrF SacreBLEU なし - (MT訳, 参照訳) 深層学習 BERTScore tohoku-nlp/bert-base-japanese-v3 事前学習 - (MT訳, 参照訳) 深層学習 BLEURT BLEURT-20 微調整 なし(他の多言語データ) (MT訳, 参照訳) 深層学習 COMET wmt22-comet-da 微調整 日⇔英 人手評価データ使用 (原文, MT訳, 参照訳) 深層学習 CometKiwi wmt22-cometkiwi-da 微調整 日⇔英 人手評価データ使用 (原文, MT訳) メタ評価に用いた6指標
実験:LLM 4モデルの自動評価結果のメタ評価 ⚫結果 – CometKiwi を除き、セグメントレベルでは中程度の相関、システムレベルでは強い相関 ➢ 評価指標によるスコアの勝敗によって、「2セグメント間の優劣を一部判定可能」、 「2システム間の優劣を判定可能」、と解釈できる ➢
5指標について、一定の有効性を確認 – ただし、少ないセグメント数(=67)、僅かなシステム数(=4)での評価のため、 セグメント・システム数を増やしても同様の傾向となるか、 より信頼性の高い結論を得るために追加の検証も必要(今後実施予定) 14
貢献③:既存 LLM の翻訳精度自動評価(+定性的分析) 15
実験:LLM の翻訳精度自動評価 ⚫設定 – データ:構築した対訳データセット全体(726セグメント)を評価に使用 – 指標:メタ評価から、自動評価指標は BLEU、BLEURT を使用 –
モデル:商用 LLM 6モデル、オープン LLM 6モデルを評価 ⚫推論・評価方法 – 忠実な現代日本語訳を求める 右のプロンプトで Zero-shot 推論 (微調整なし) – データセットを5ドメインに分けつつ、 全ドメイン/ドメイン別でそれぞれ評価 16 メタ評価に使用した 67セグメントも含む 6モデル以外にも、Qwenシリーズ、gpt-oss-20b、 Karamaru なども一部評価したが、 顕著な結果は見られなかったため割愛
実験:LLM の翻訳精度自動評価(5ドメイン全体) – 商用 LLM、特に Claude が高精度 • Gemini/GPT で思考レベルを上げると
精度微増 – オープンモデルの中では、 Gemma-2-Llama-Swallow や DeepSeek は健闘し、GPT-5/5.2 に近いスコア 17 LLM 全データ BLEU BLEURT Claude Opus 4.5 28.5 66.6 Claude Sonnet 4.5 26.4 65.5 Gemini 3 Flash (thinking_level: medium) 21.3 66.5 Gemini 3 Flash (thinking_level: minimal) 20.9 65.8 Gemini 2.5 Flash (thinking_budget: 0) 23.9 64.8 GPT-5.2 (reasoning effort: medium) 22.6 64.3 GPT-5.2 (reasoning effort: none) 21.6 63.2 GPT-5 (reasoning effort: minimal) 19.7 62.9 DeepSeek-R1 (thinking: off) 19.7 63.8 Gemma-2-Llama-Swallow-27b-it-v0.1 21.2 62.2 Gemma-2-Llama-Swallow-9b-it-v0.1 19.0 61.2 llm-jp-3.1-13b-instruct4 19.4 57.9 Llama-3-ELYZA-JP-8B 17.5 54.9 Sarashina2.2-3b-instruct-v0.1 15.1 61.3 ドメイン別スコア (次頁)のマクロ平均 参考:メタ評価対象の67セグメントに対する Claude Sonnet 3.5 の評価結果 [東山 ‘25] から、品質は改善の余地ありと想定される。 BLEU BLEURT 人手評価 (文単位) 人手評価 (単語単位) 24.7 66.6 62.7% 81.1%
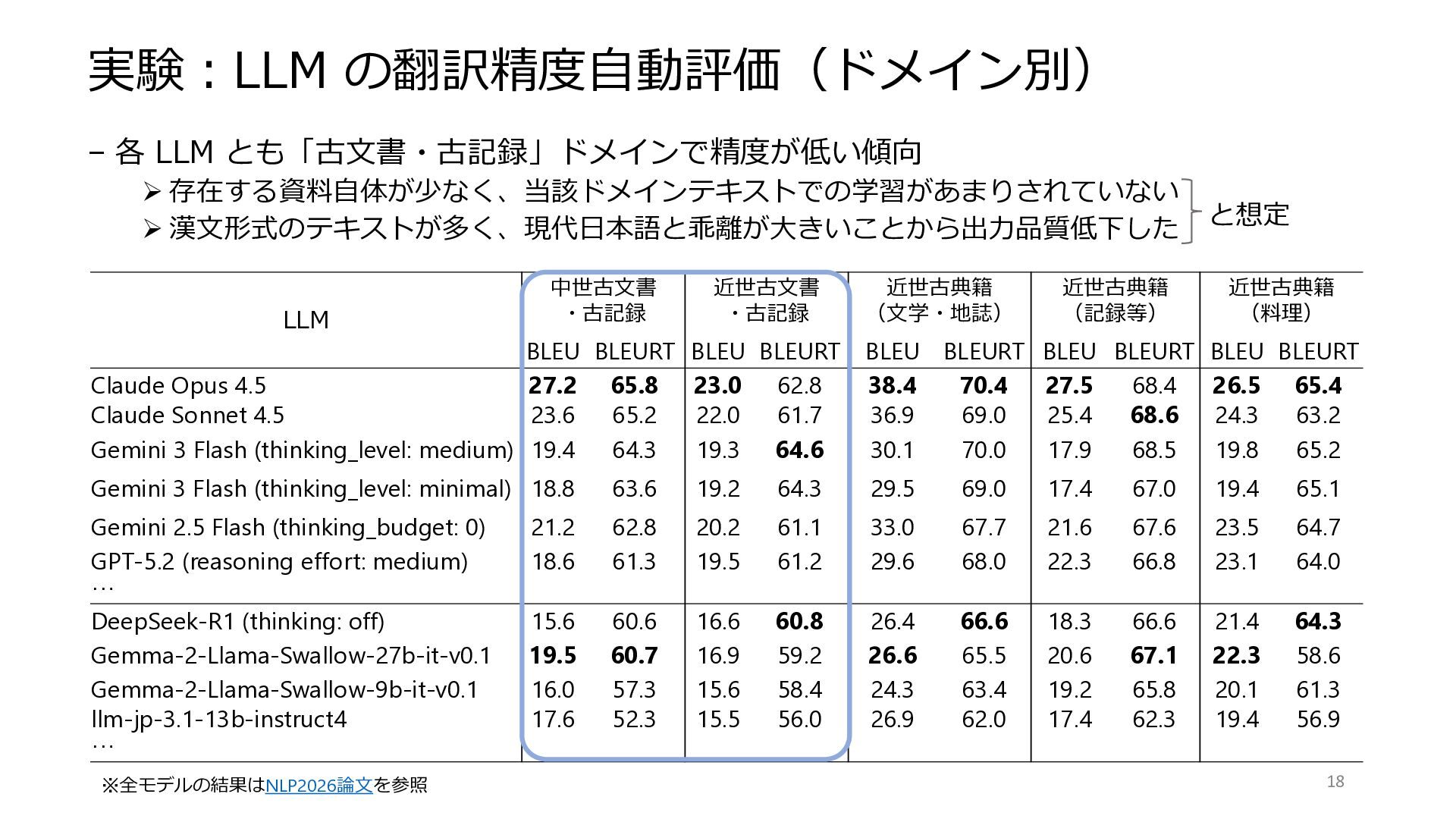
実験:LLM の翻訳精度自動評価(ドメイン別) – 各 LLM とも「古文書・古記録」ドメインで精度が低い傾向 ➢ 存在する資料自体が少なく、当該ドメインテキストでの学習があまりされていない ➢ 漢文形式のテキストが多く、現代日本語と乖離が大きいことから出力品質低下した
LLM 中世古文書 ・古記録 近世古文書 ・古記録 近世古典籍 (文学・地誌) 近世古典籍 (記録等) 近世古典籍 (料理) BLEU BLEURT BLEU BLEURT BLEU BLEURT BLEU BLEURT BLEU BLEURT Claude Opus 4.5 27.2 65.8 23.0 62.8 38.4 70.4 27.5 68.4 26.5 65.4 Claude Sonnet 4.5 23.6 65.2 22.0 61.7 36.9 69.0 25.4 68.6 24.3 63.2 Gemini 3 Flash (thinking_level: medium) 19.4 64.3 19.3 64.6 30.1 70.0 17.9 68.5 19.8 65.2 Gemini 3 Flash (thinking_level: minimal) 18.8 63.6 19.2 64.3 29.5 69.0 17.4 67.0 19.4 65.1 Gemini 2.5 Flash (thinking_budget: 0) 21.2 62.8 20.2 61.1 33.0 67.7 21.6 67.6 23.5 64.7 GPT-5.2 (reasoning effort: medium) 18.6 61.3 19.5 61.2 29.6 68.0 22.3 66.8 23.1 64.0 … DeepSeek-R1 (thinking: off) 15.6 60.6 16.6 60.8 26.4 66.6 18.3 66.6 21.4 64.3 Gemma-2-Llama-Swallow-27b-it-v0.1 19.5 60.7 16.9 59.2 26.6 65.5 20.6 67.1 22.3 58.6 Gemma-2-Llama-Swallow-9b-it-v0.1 16.0 57.3 15.6 58.4 24.3 63.4 19.2 65.8 20.1 61.3 llm-jp-3.1-13b-instruct4 17.6 52.3 15.5 56.0 26.9 62.0 17.4 62.3 19.4 56.9 … と想定 18 ※全モデルの結果はNLP2026論文を参照
翻訳結果事例1(千葉県史 近世古文書資料) – Claude/Gemini は謝罪の中心的な文意を伝えているが、他2モデルでは失敗 19 赤:誤訳,青:その他誤り(Addition=過剰生成/Omission=訳し漏れ/Dependency=係り受け構造誤り) 御番所を通り過ぎた 不始末を謝罪
翻訳結果事例2(料理) – Claude / Gemini は、「よばして」を含む調理工程全体をほぼ適切に訳している。 他2モデルは、「よばして」や他の個所で誤訳あり(下記以外のモデルも軒並み同様)。 20 この文脈では「ふやかす」の意 赤:誤訳,青:その他誤り(Addition=過剰生成)
エラー傾向の印象:モデルにとって未知であろう表現に対し、 その字面や文脈からそれっぽい表現を当てはめて、結果誤っている
まとめと今後の展望 ⚫本研究の貢献 – 中世・近世資料を用いた評価用対訳データセットを構築・公開 – 既存 MT 評価指標について、メタ評価により一定の有効性を確認 – 既存
LLM の評価により、翻訳精度のモデル/ドメイン別傾向を確認 を通じて、「古典日本語の現代語機械翻訳」の研究分野推進のための研究に取り組んだ ⚫今後の展望 – 収録資料の時代・ドメイン・数量の点で、対訳データを拡大 – 低資源の状況での、オープン LLM の翻訳精度向上のための学習方法の検討 – コスト・信頼性・再利用性のバランスが良い人手評価方法の検討と、 自動評価指標のメタ評価や自動エラー検出等への人手評価データの活用 – 英語や他の言語への翻訳方向拡大(に向けた評価資源の整備)を模索 21
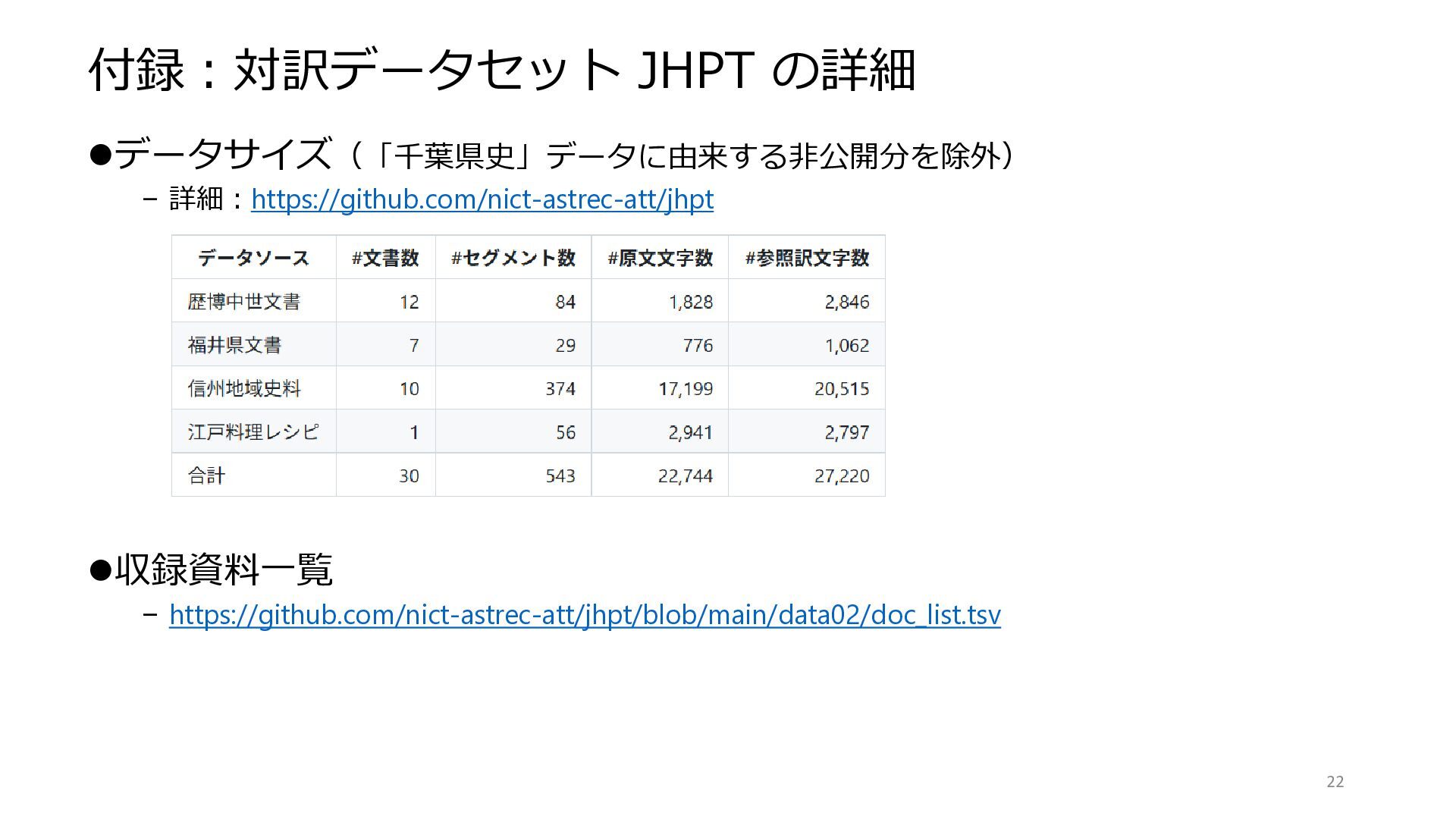
付録:対訳データセット JHPT の詳細 ⚫データサイズ(「千葉県史」データに由来する非公開分を除外) – 詳細:https://github.com/nict-astrec-att/jhpt ⚫収録資料一覧 – https://github.com/nict-astrec-att/jhpt/blob/main/data02/doc_list.tsv 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![関連研究:古語→現代語の機械翻訳 ⚫ラテン語 [Volk+ ‘24] – 商用 NMT と商用 LLM(GPT-4)の翻訳精度を評価 ⚫仏教漢語(Buddhist](https://files.speakerdeck.com/presentations/15e19dfa521b4664bebdd8c059056b87/slide_5.jpg){kind=link}
![関連研究:古語→現代語の機械翻訳 ⚫日本の古文書1 [橋本+ ‘25] – 中世・近世古文書を商用 LLM に現代語訳させ、品質を人手評価(文単位および単語単位) – 人手評価の過程で、既存の/新規に人手作成した現代語訳を利用](https://files.speakerdeck.com/presentations/15e19dfa521b4664bebdd8c059056b87/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験:LLM 4モデルの自動評価結果のメタ評価 ⚫設定 – [橋本+ ‘25] のデータを再利用し、中世・近世古文書資料の原文67セグメントに対する 4システム(Claude Sonnet 3.5,](https://files.speakerdeck.com/presentations/15e19dfa521b4664bebdd8c059056b87/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}