会社向け/勉強会用に作成した資料を折角なので公開
■概要
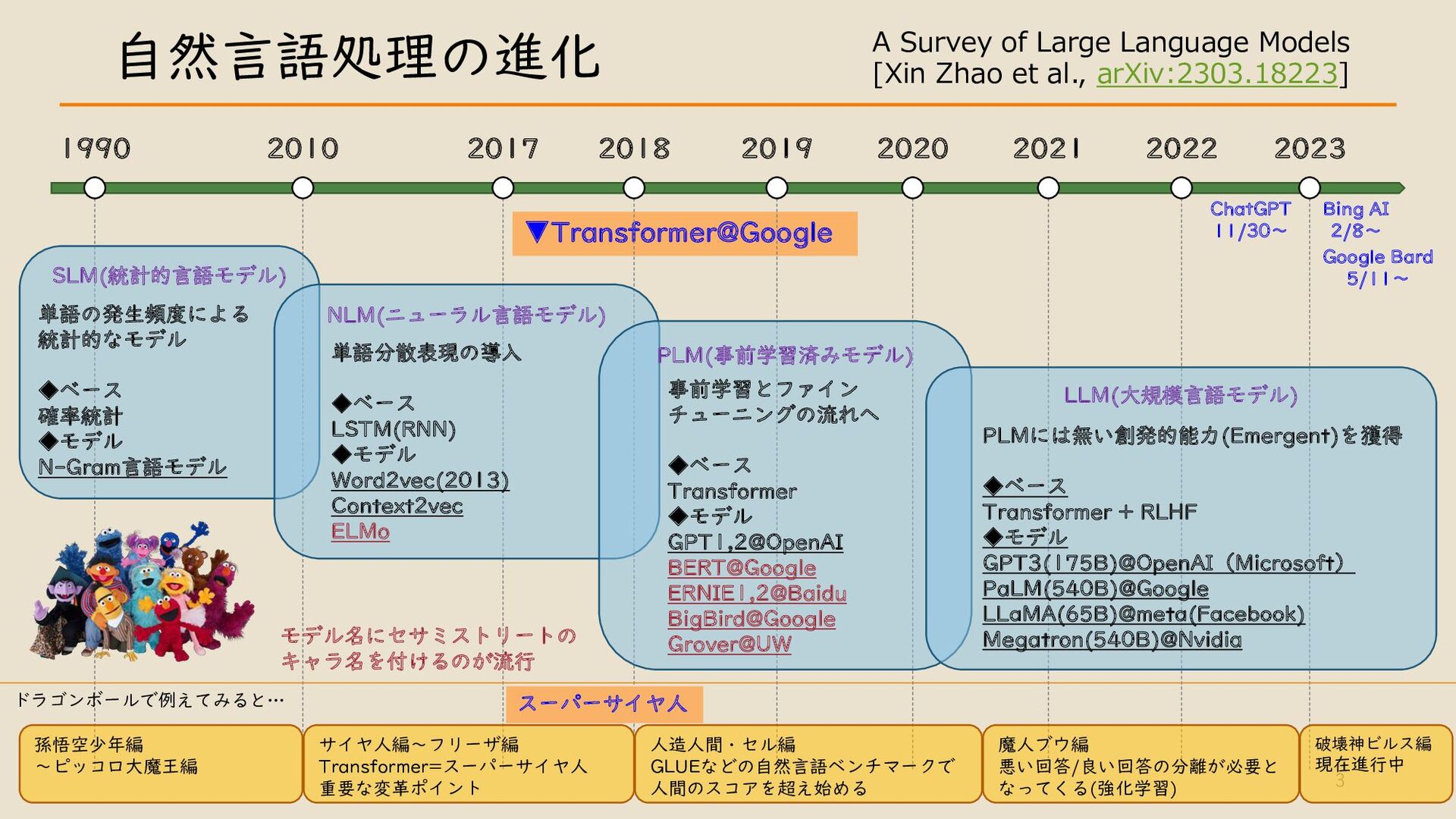
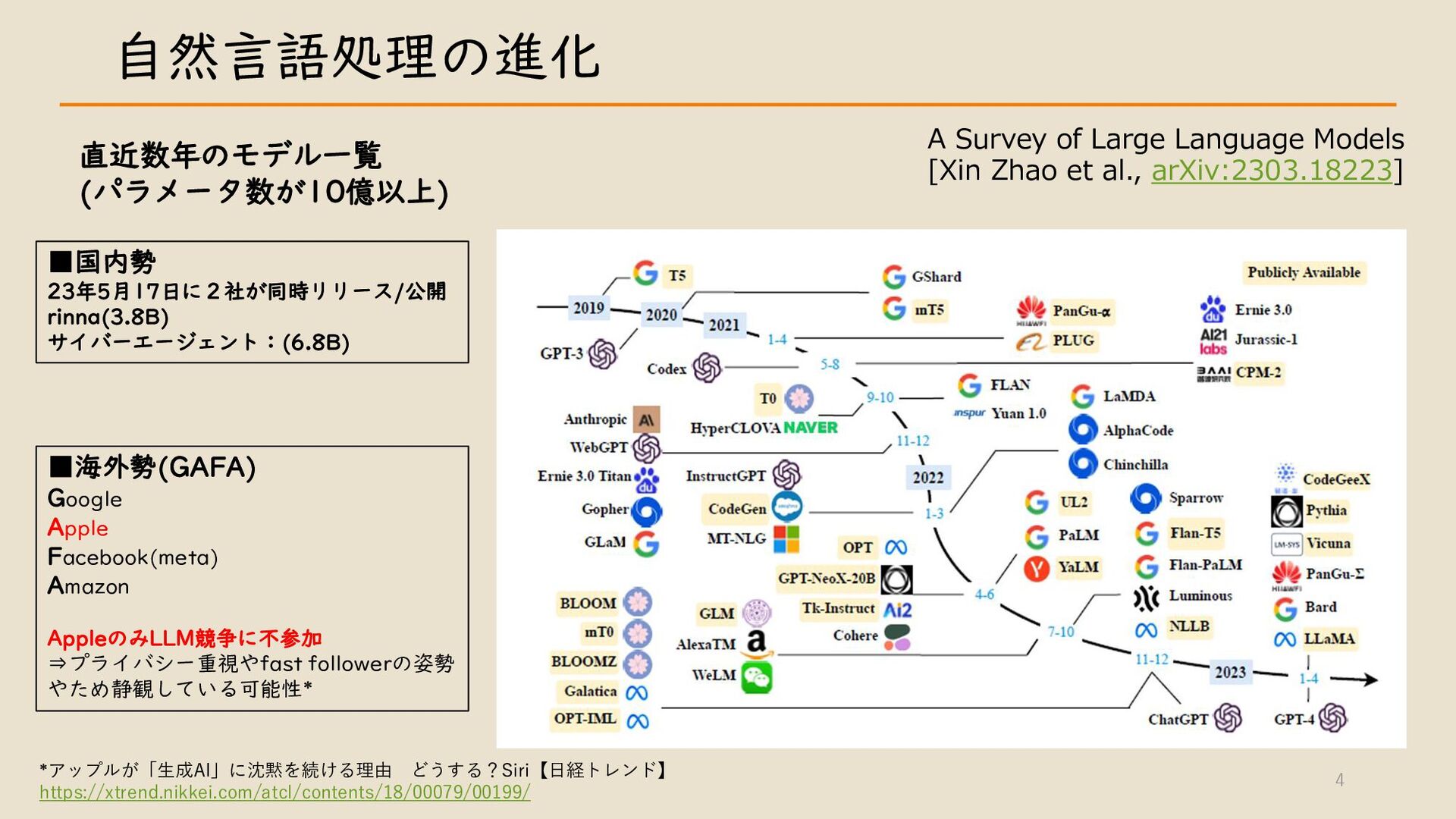
・自然言語処理の進化について (RNN~LSTM~GPT)
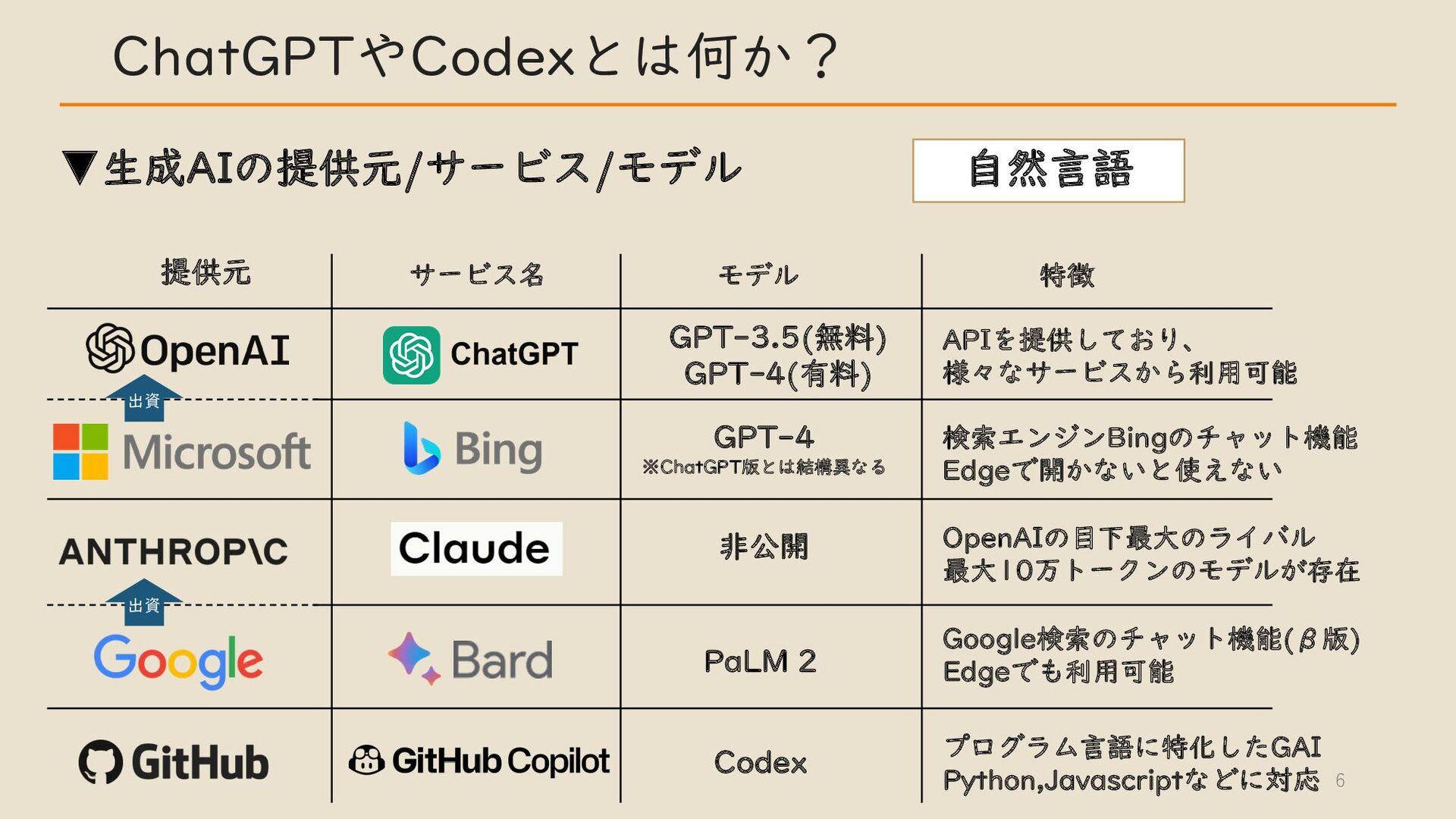
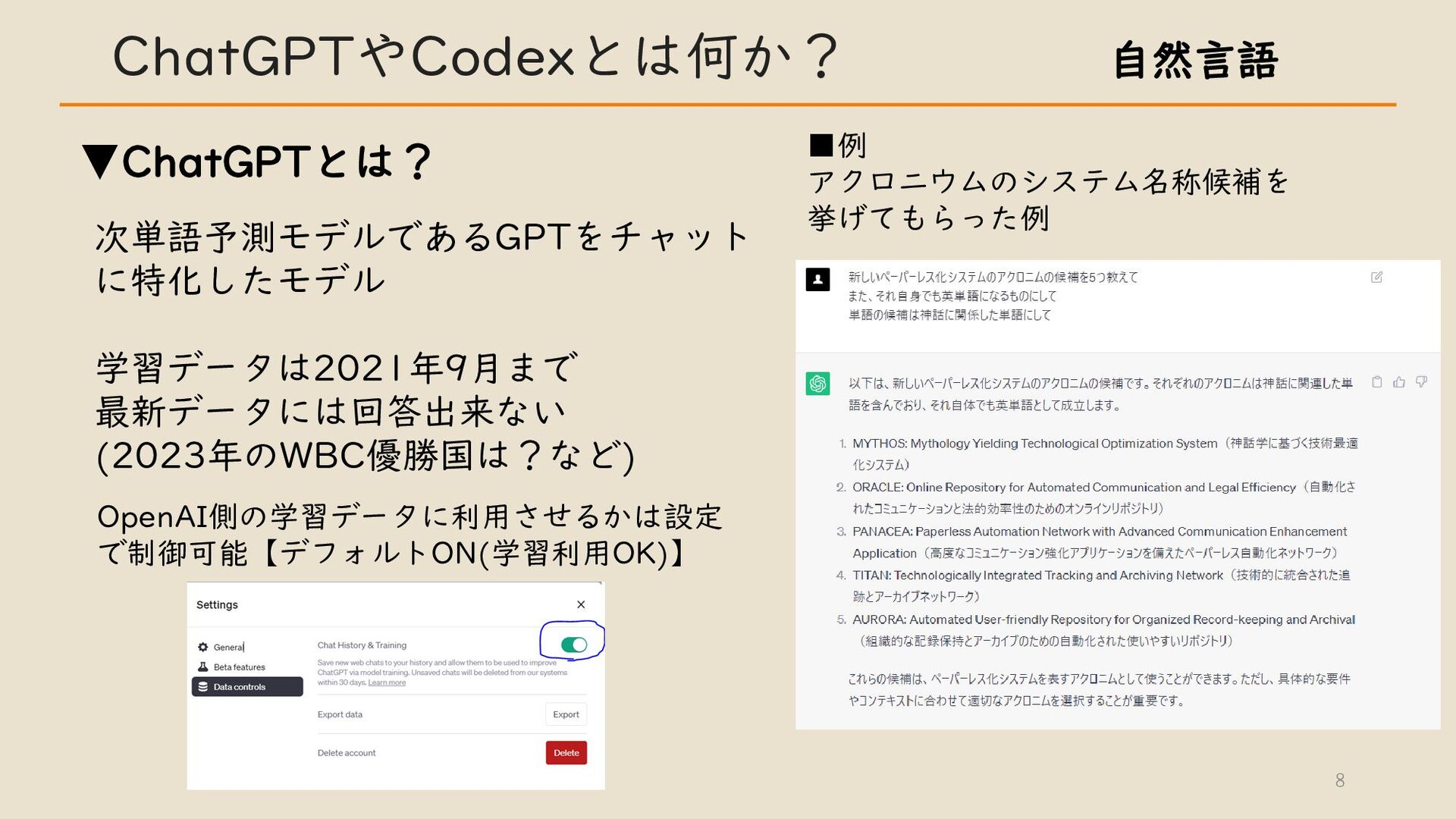
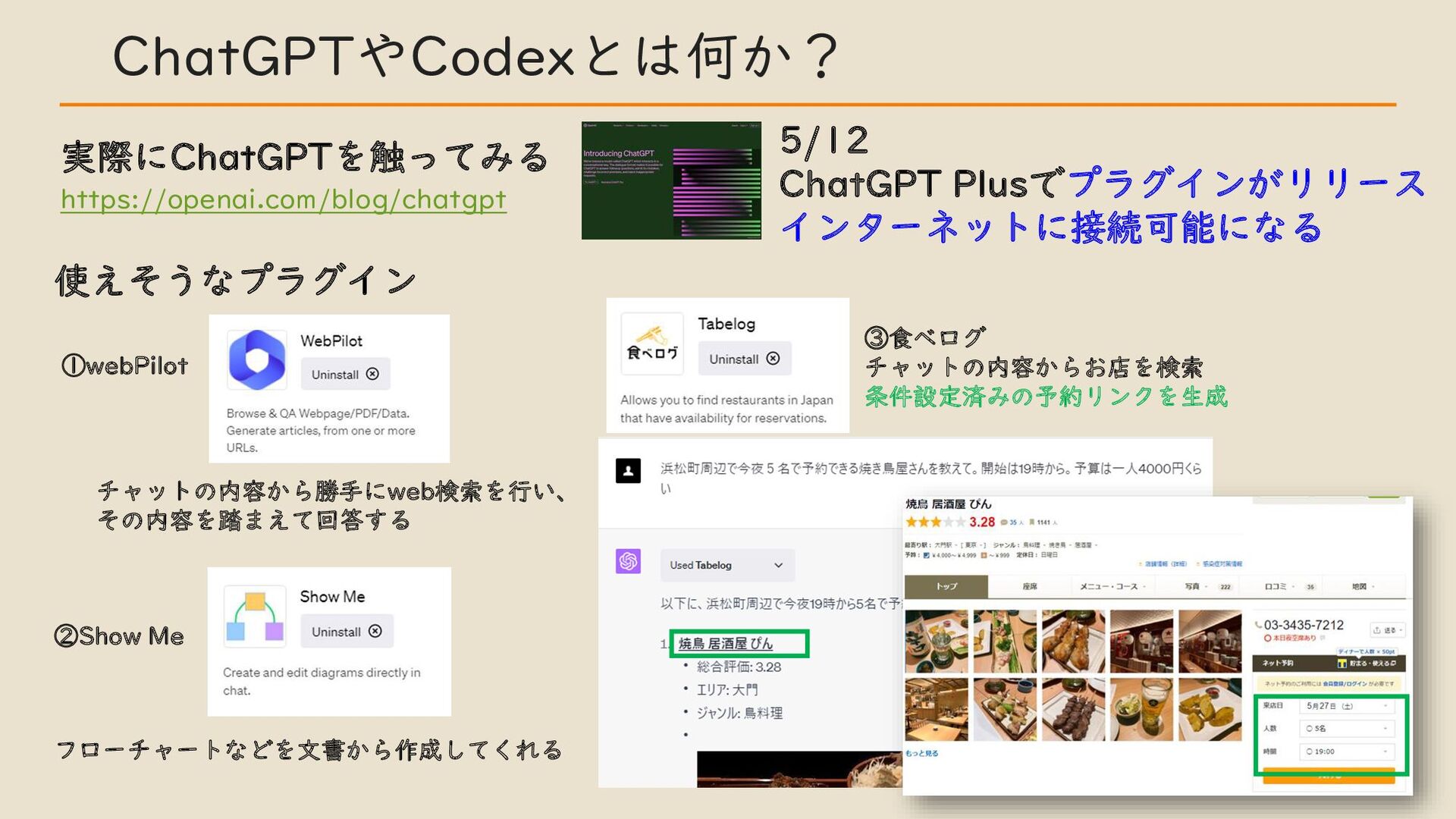
・ ChatGPT や Codex とは何か?
■詳細(要素技術について)
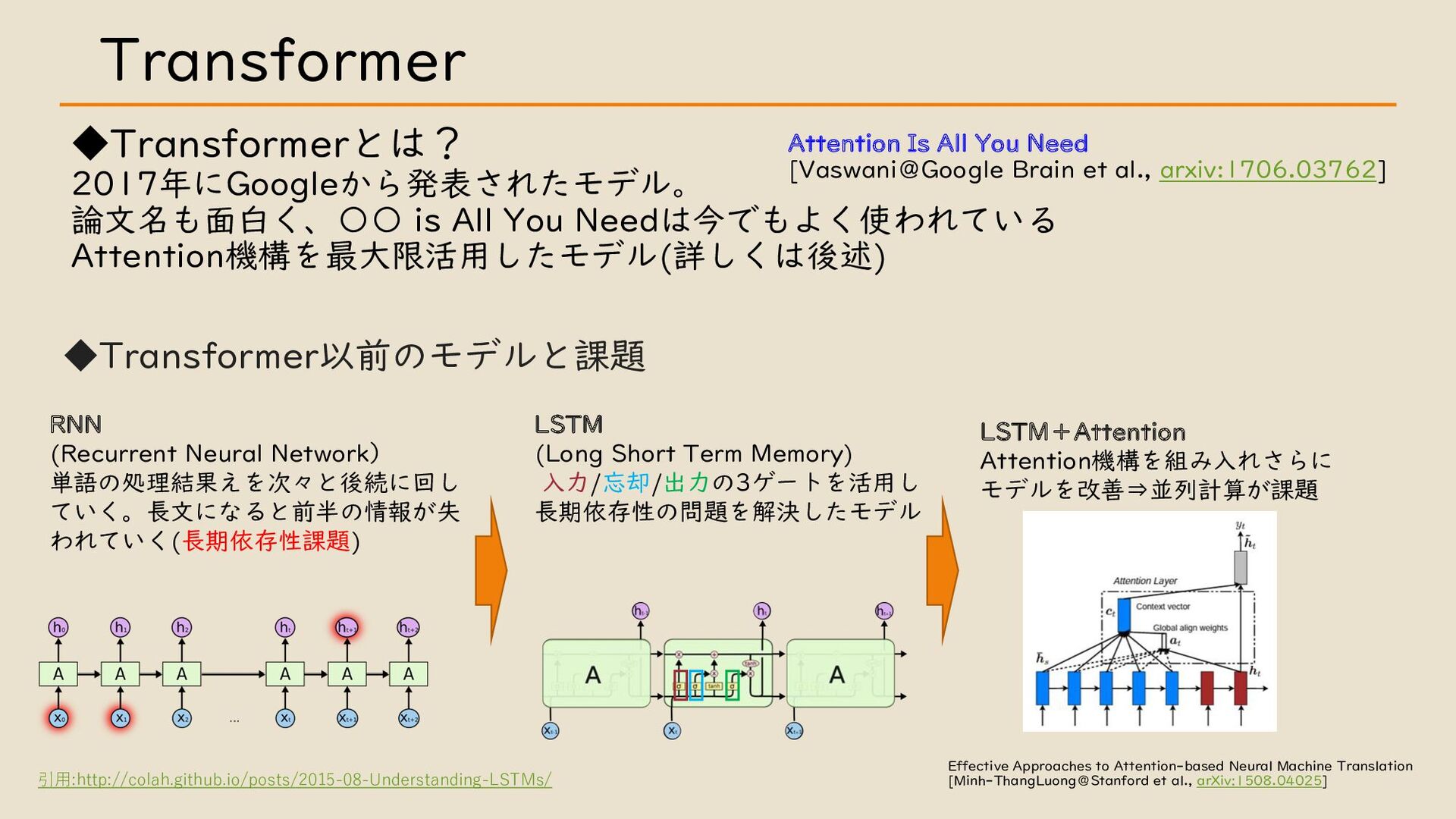
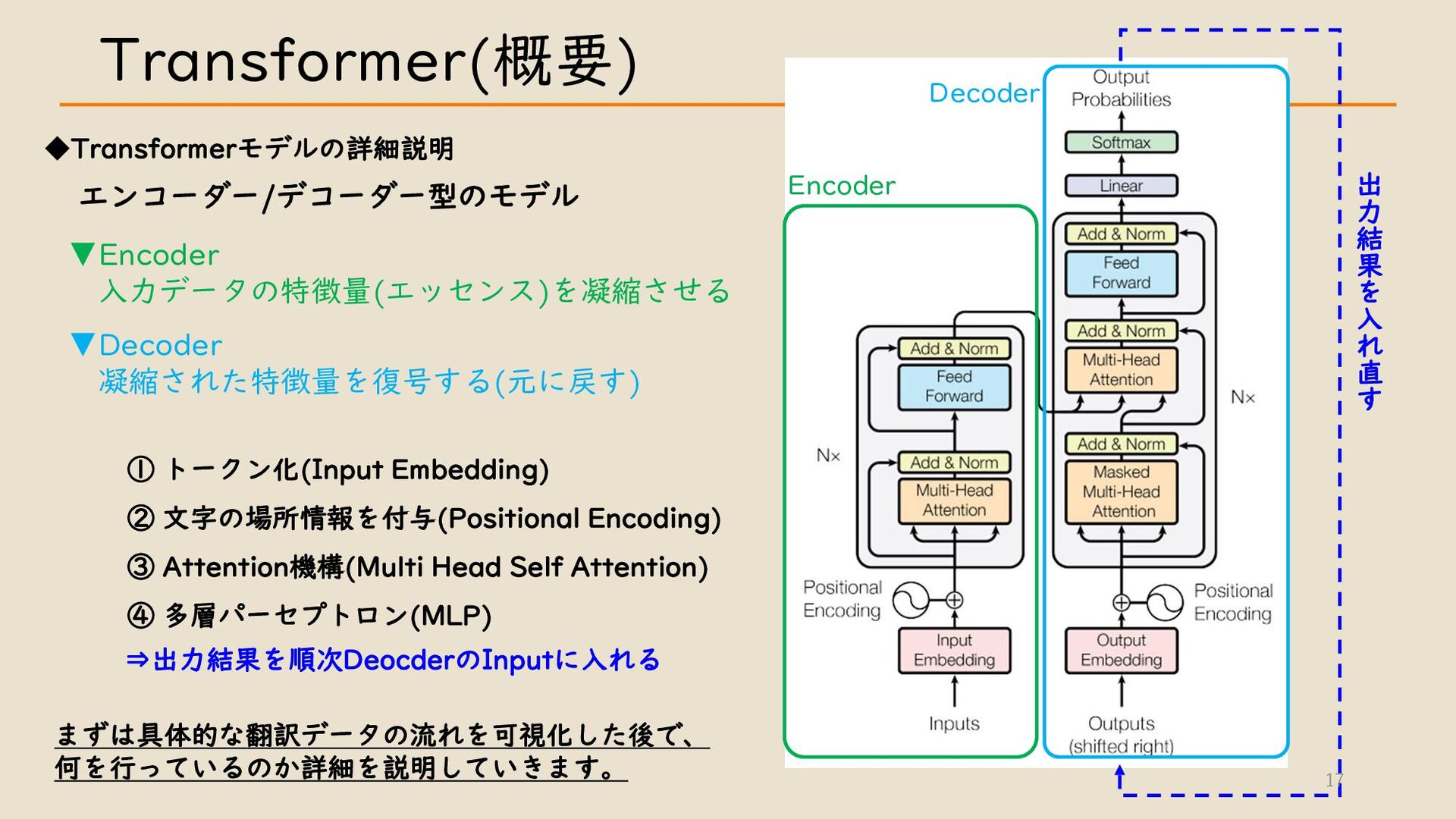
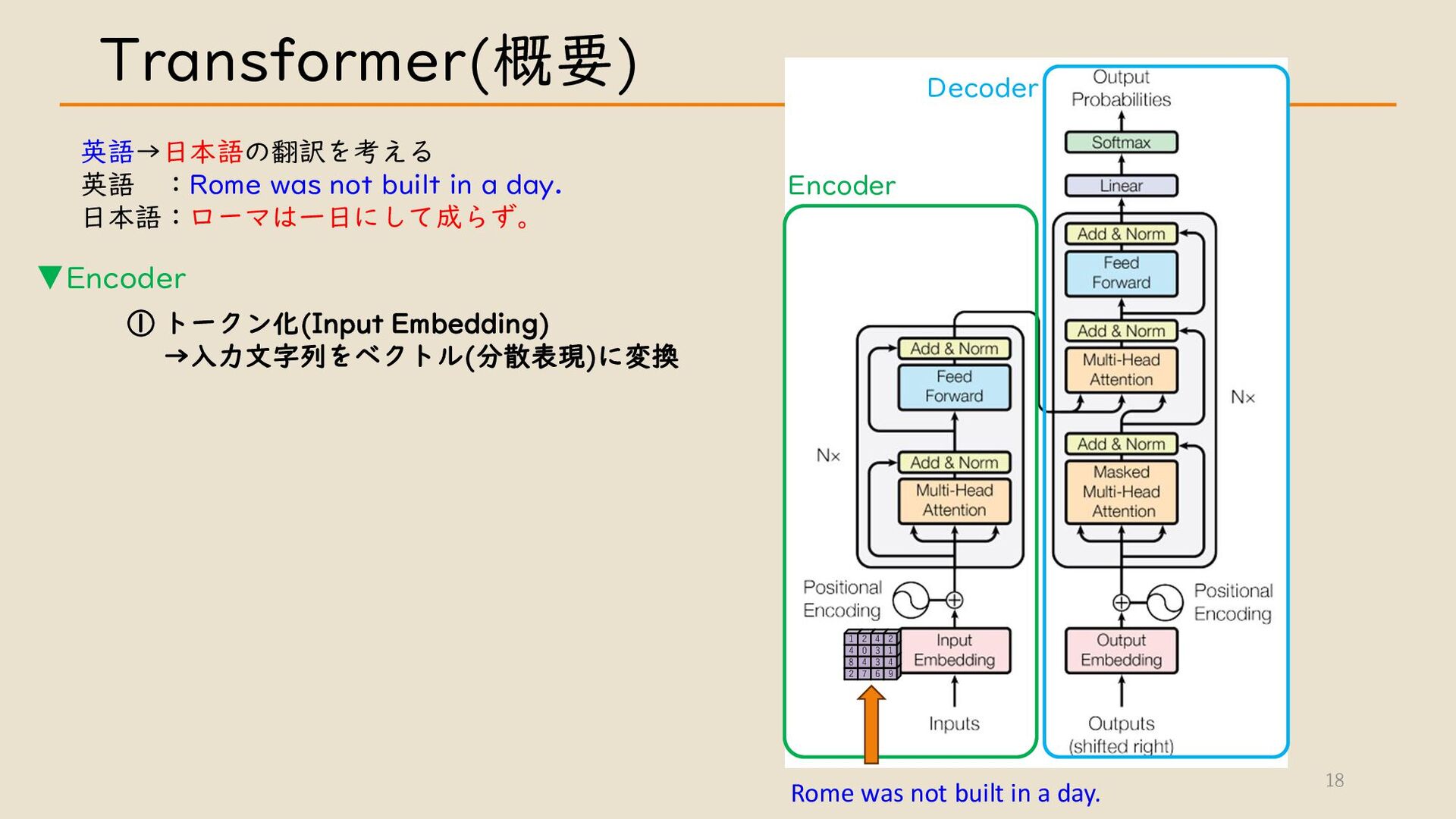
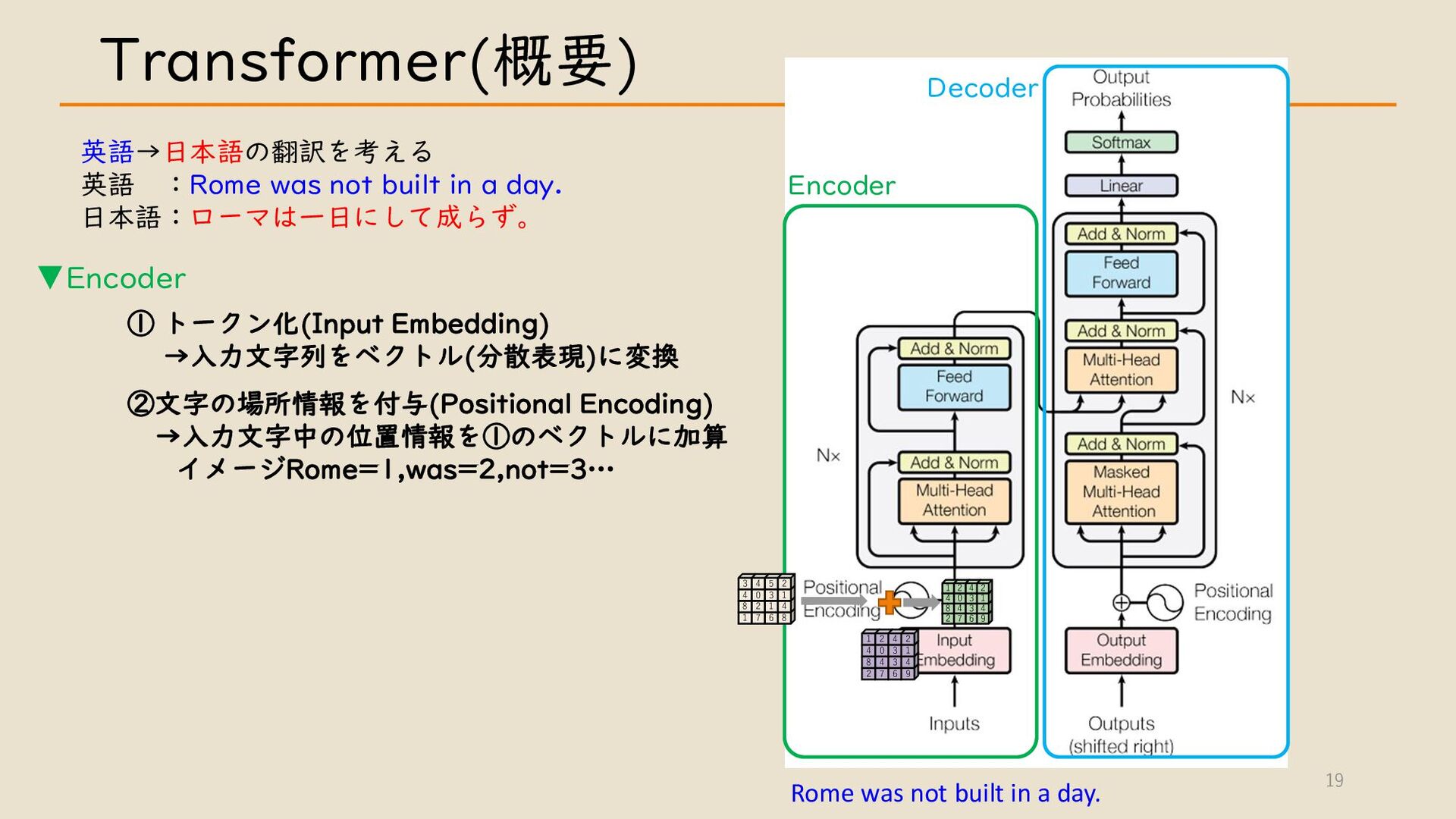
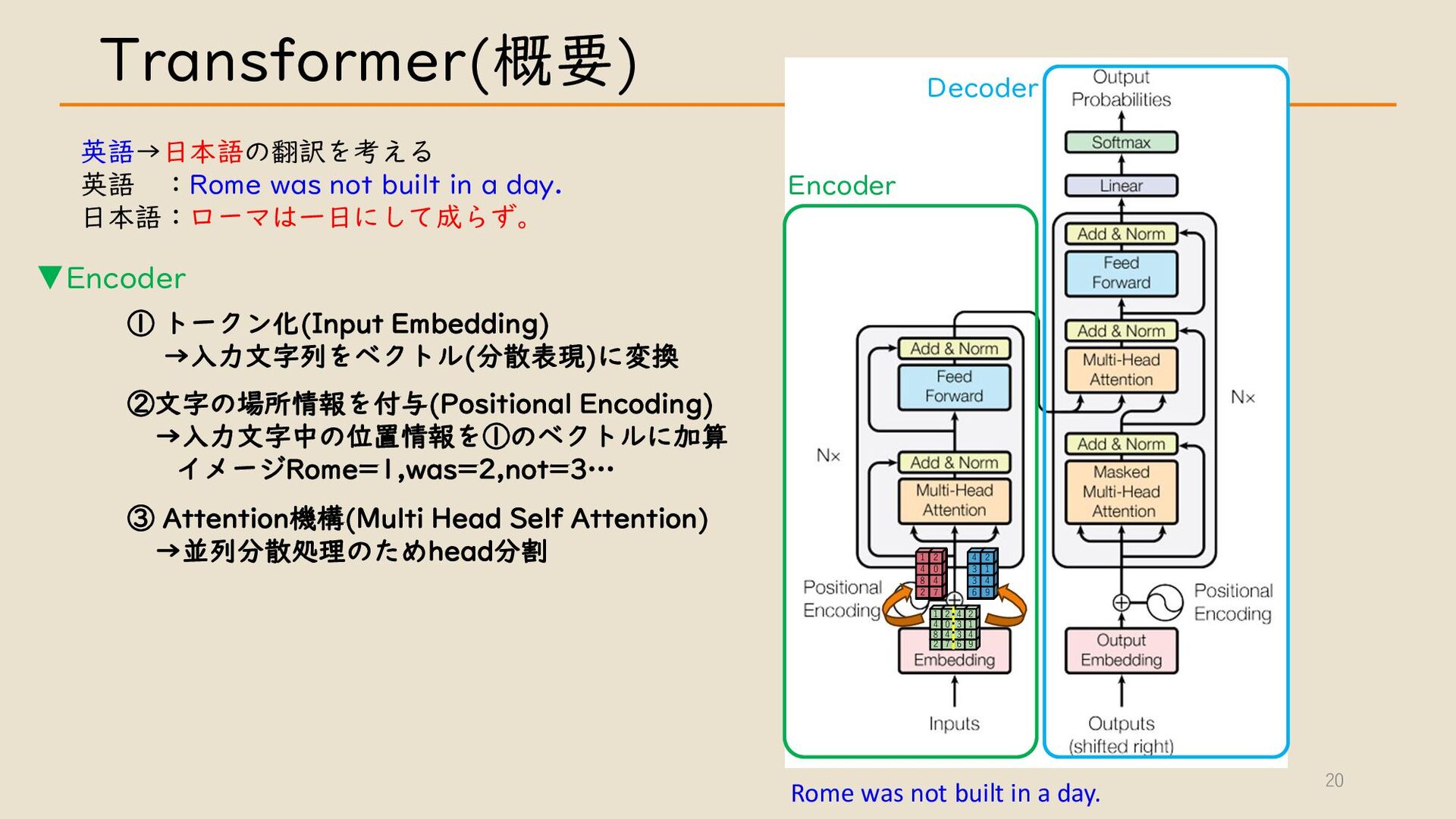
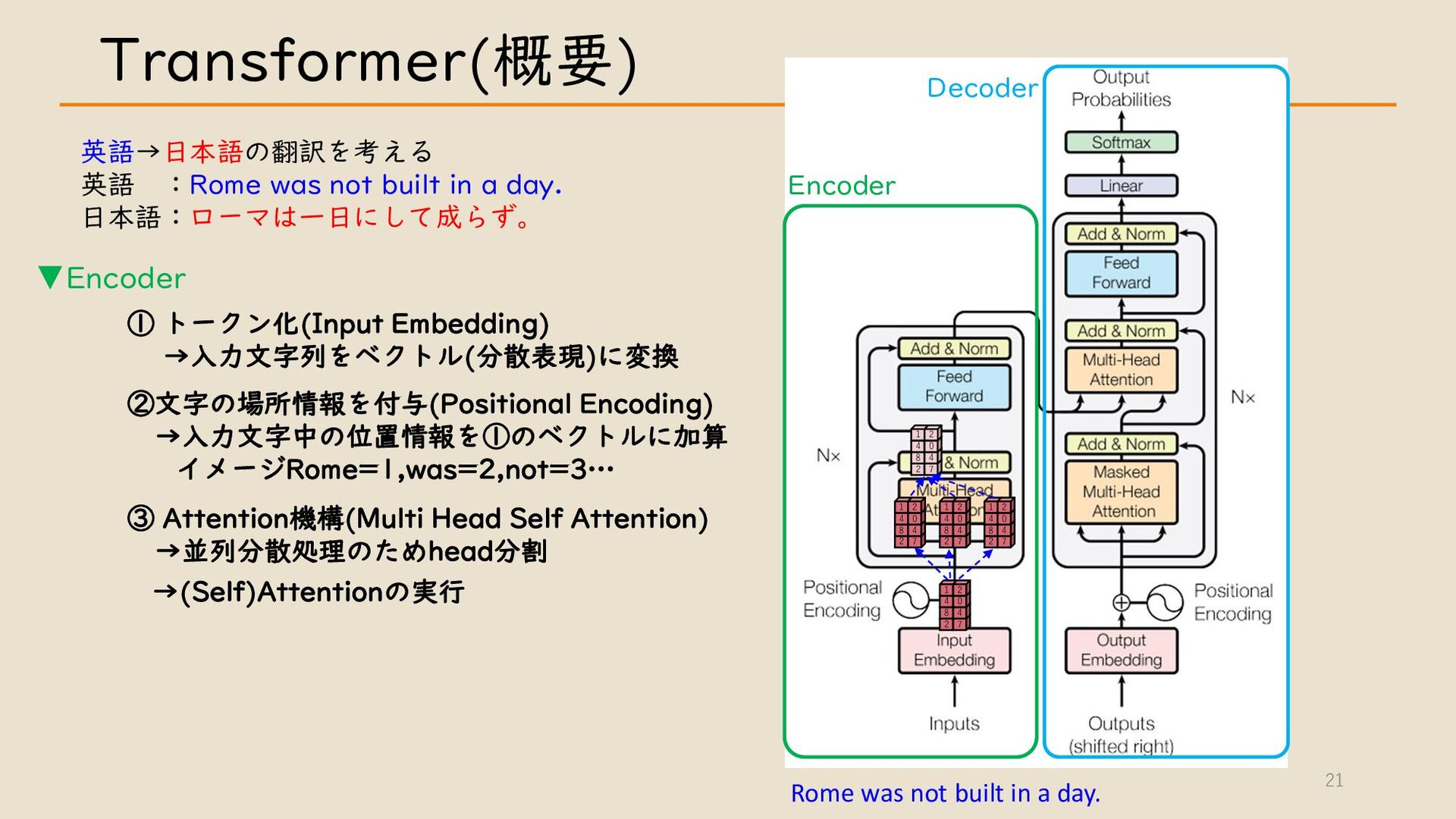
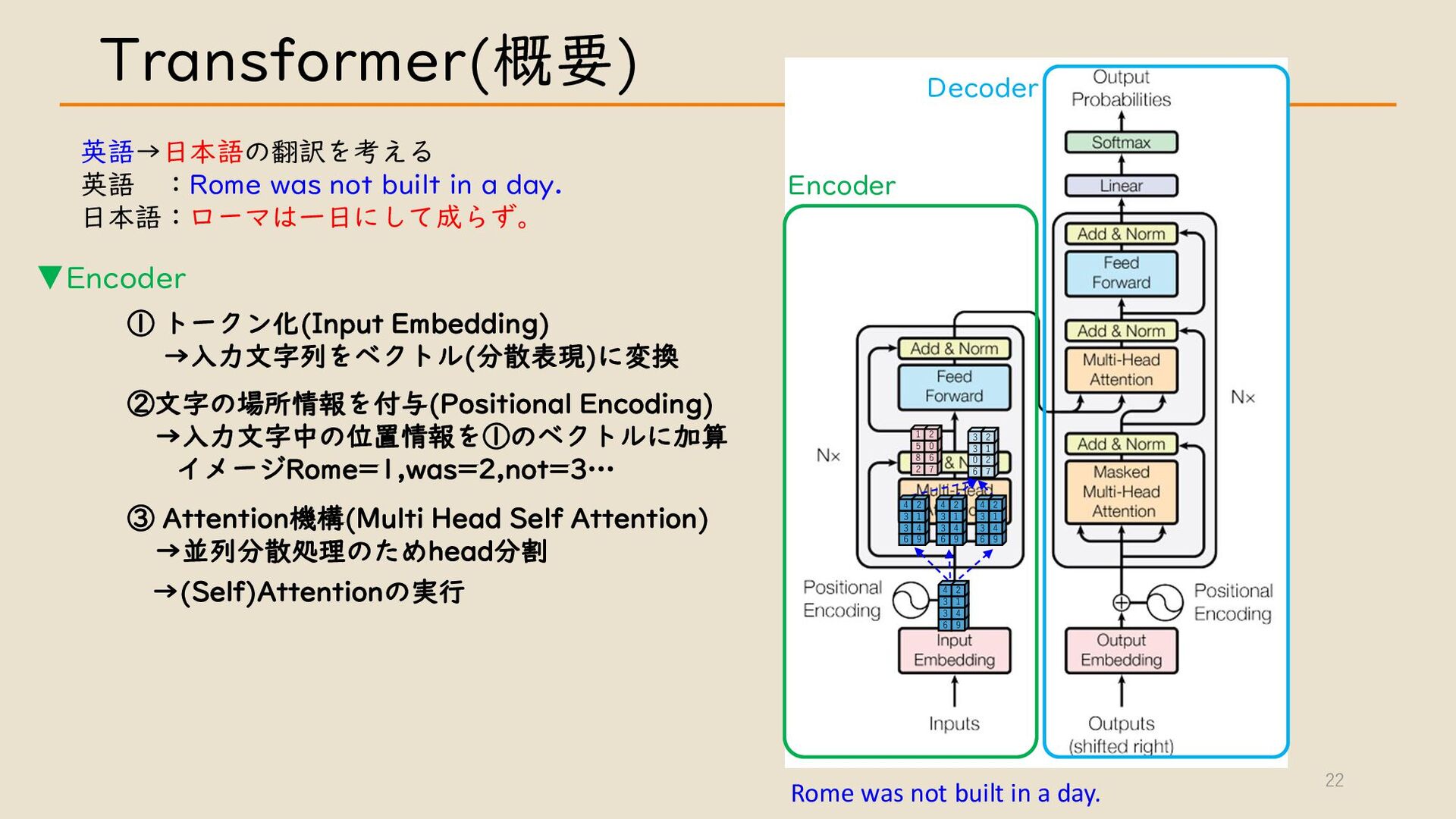
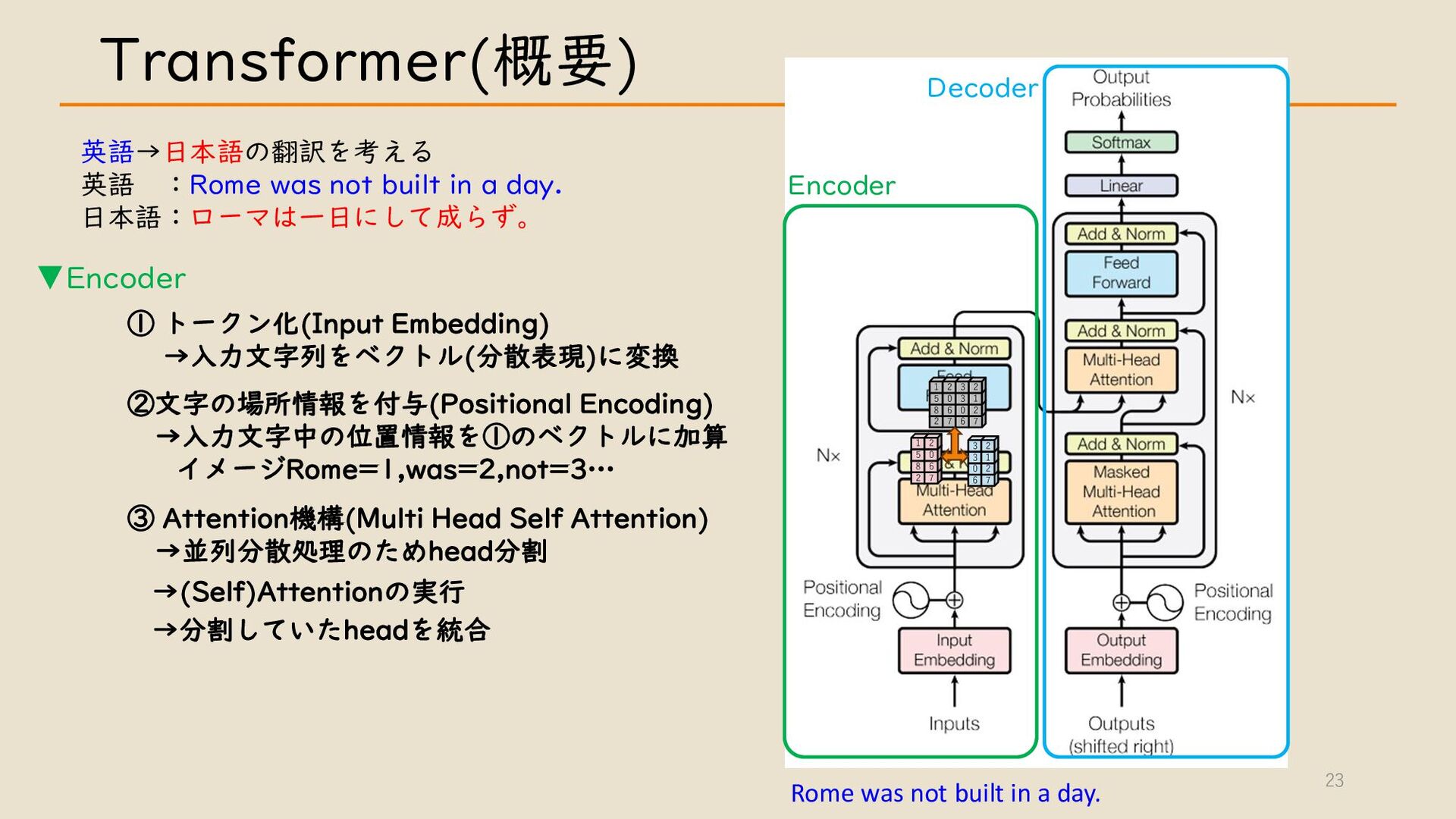
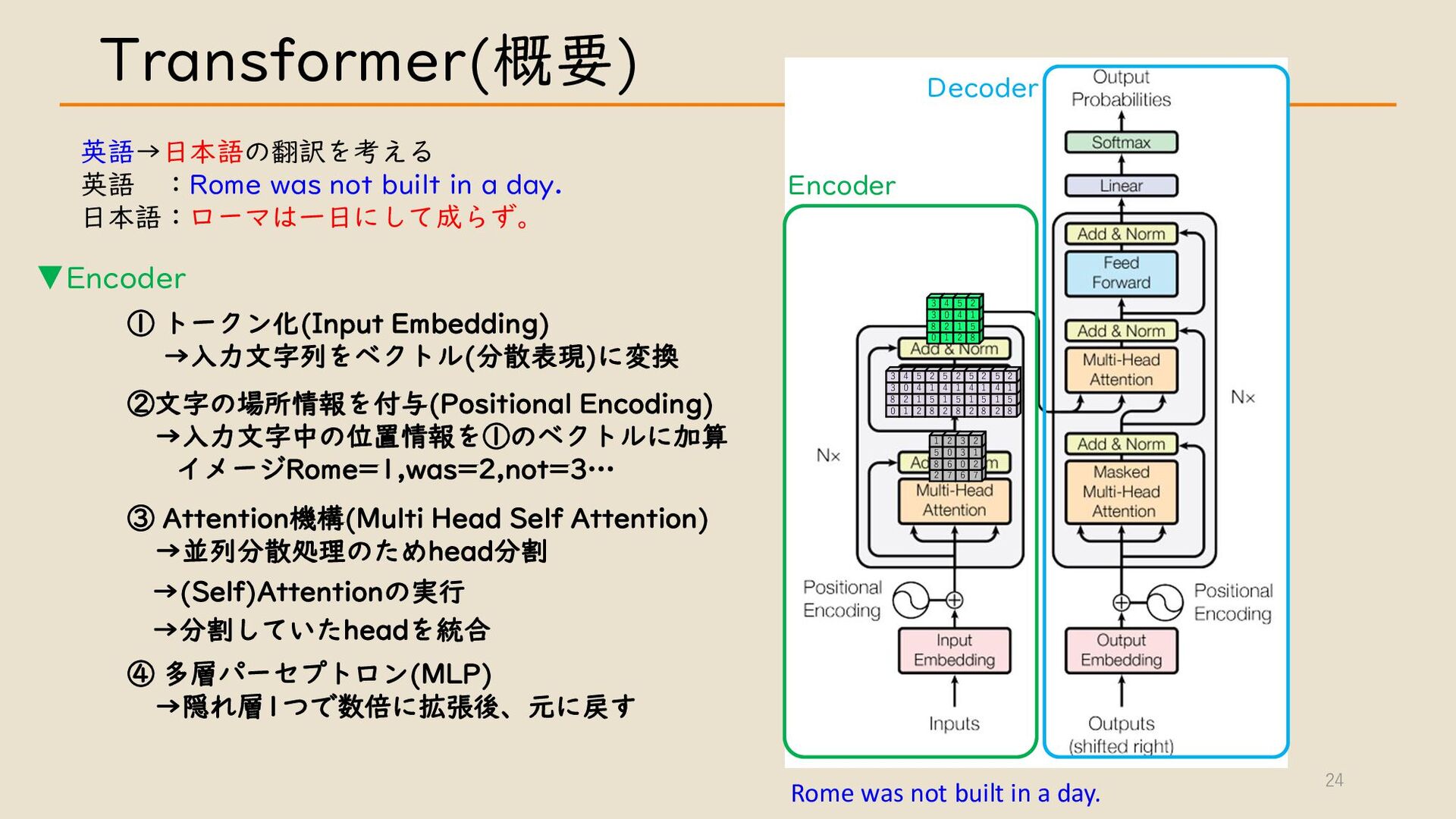
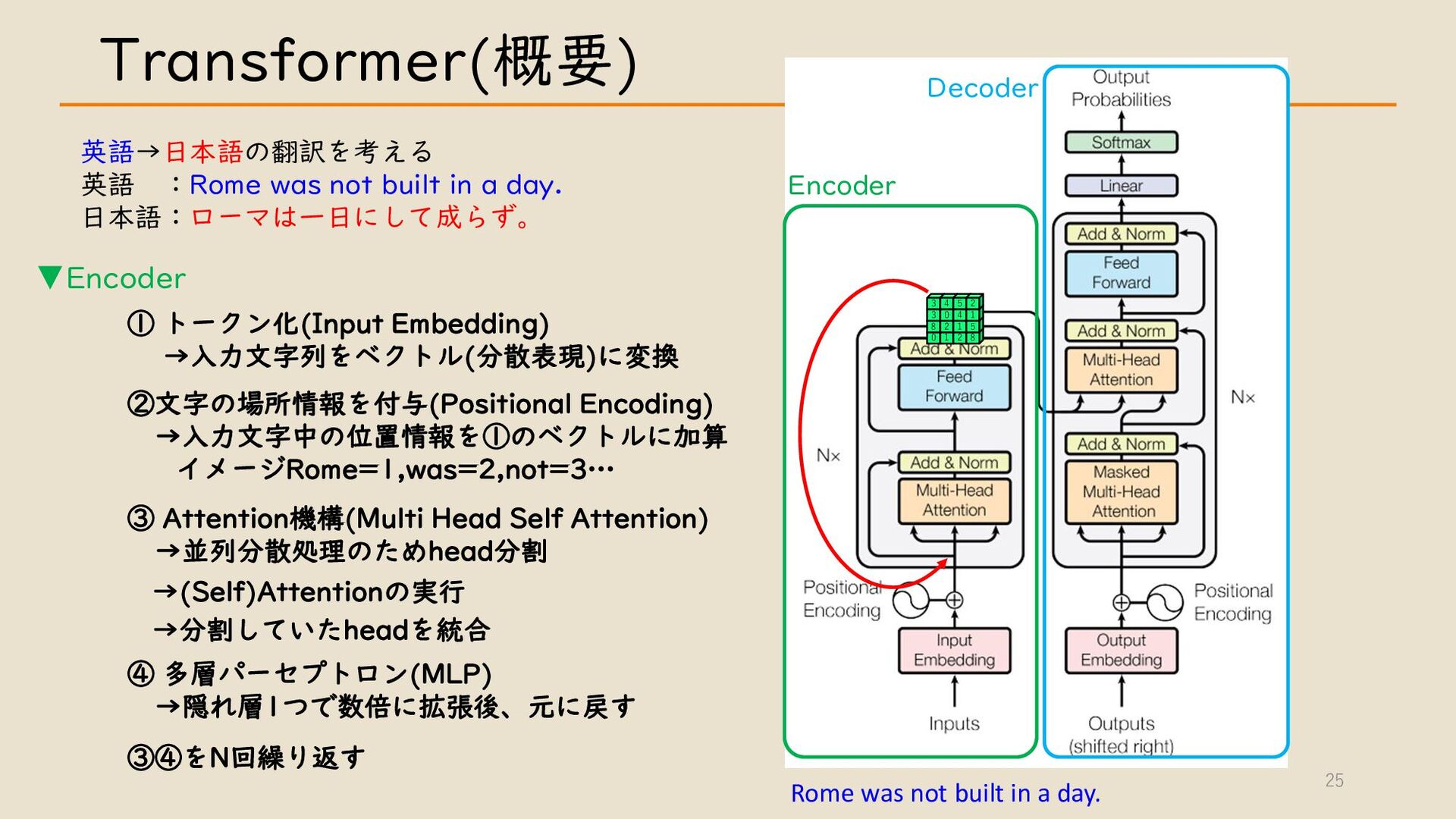
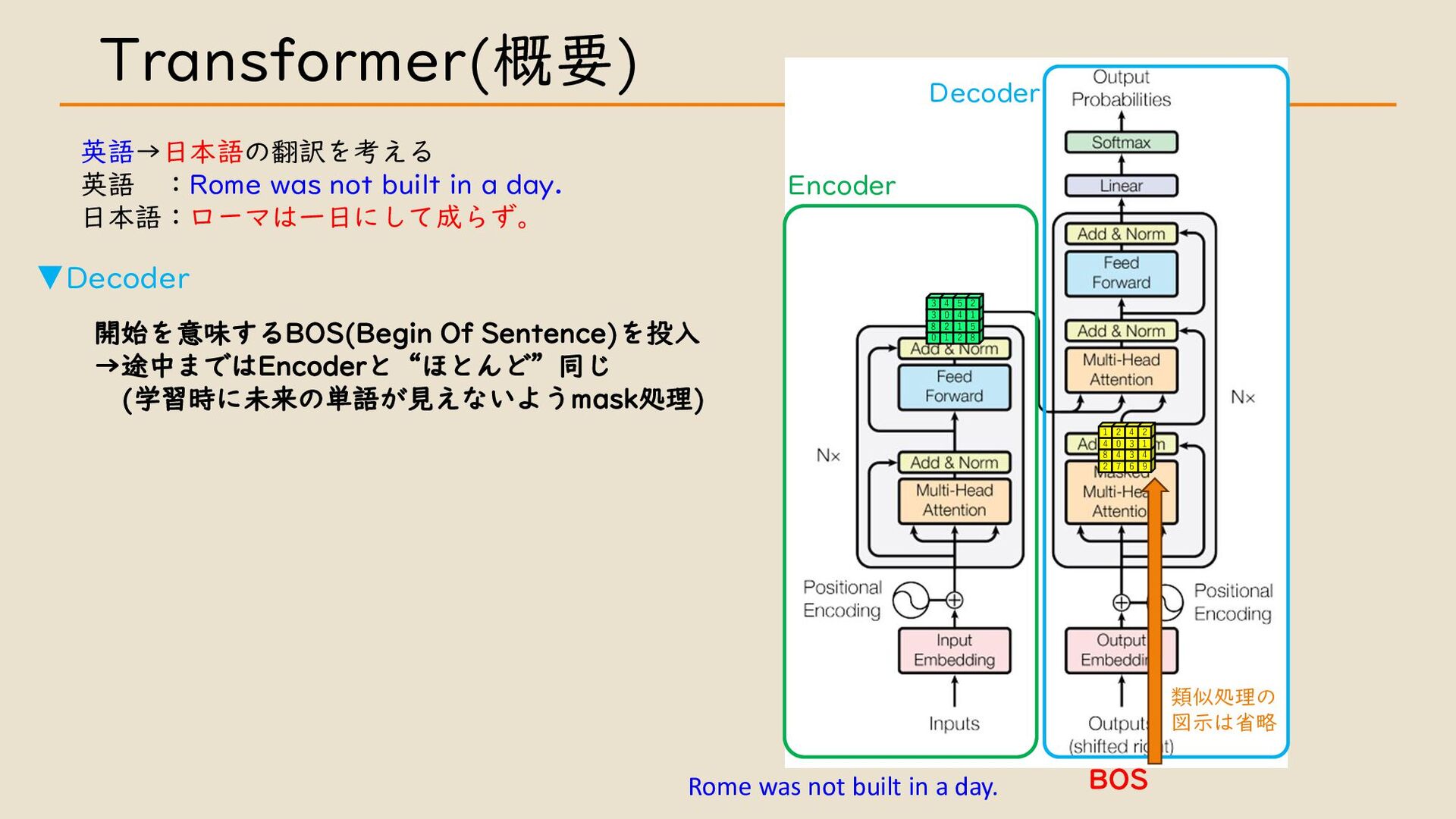
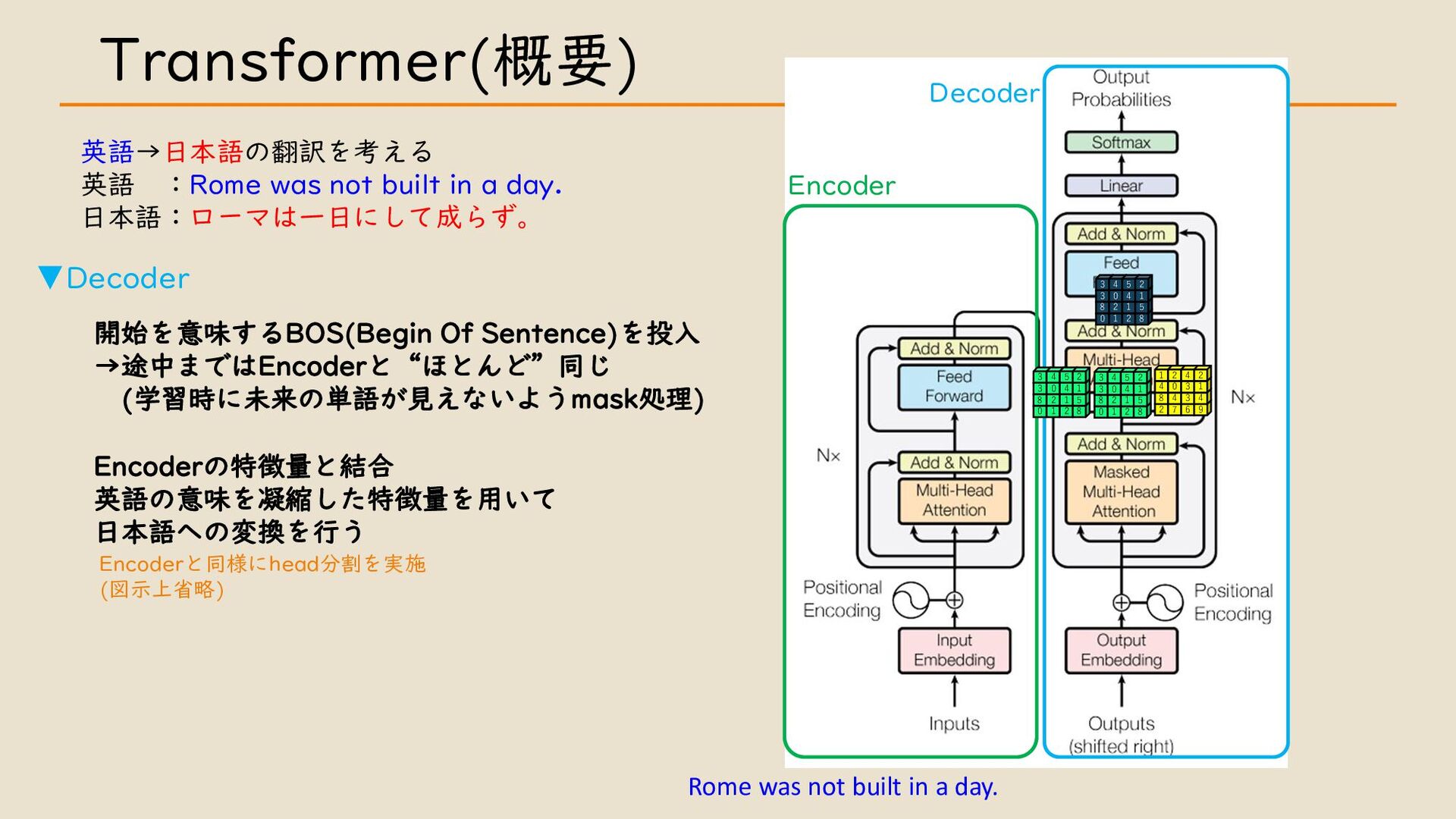
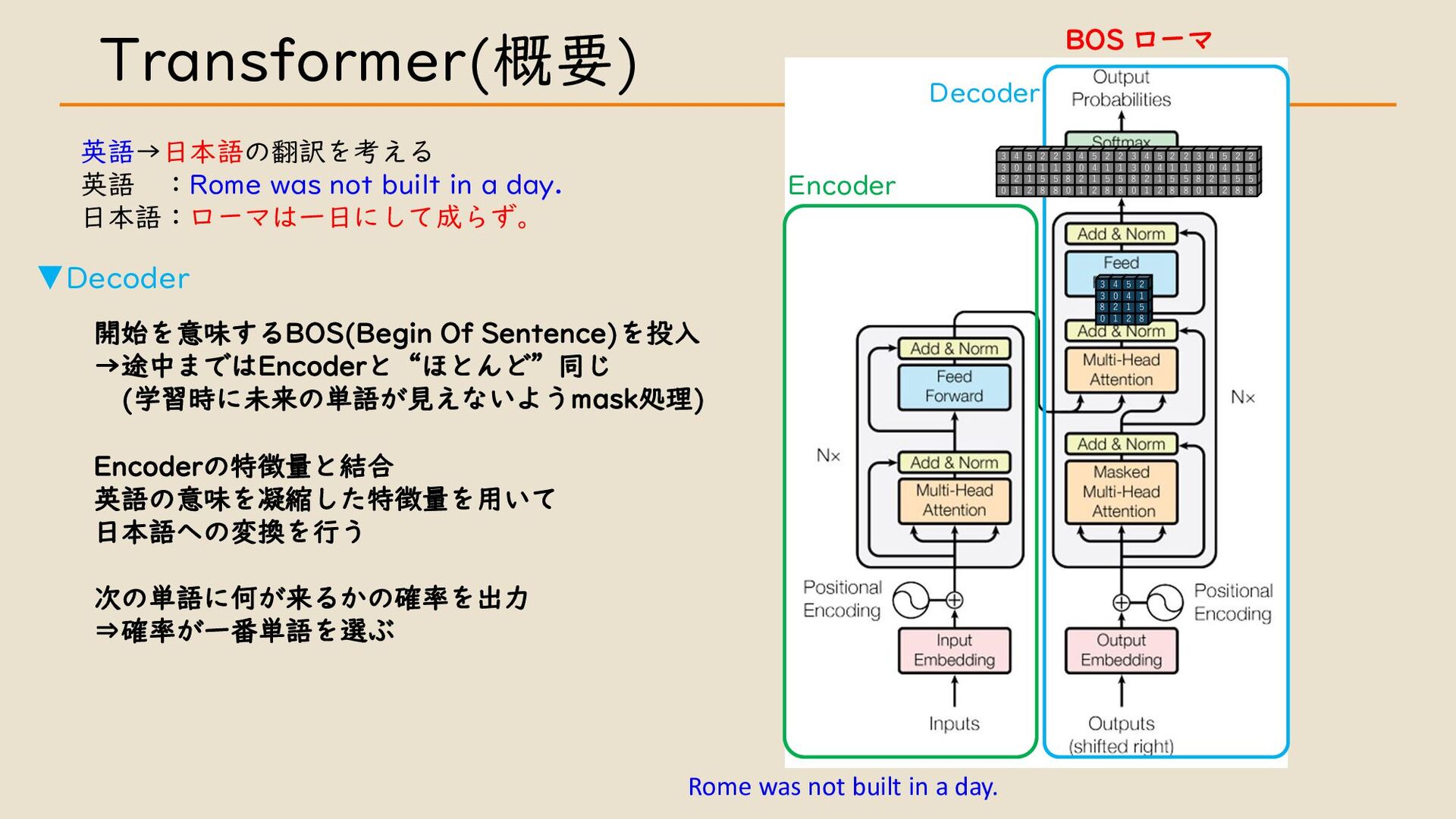
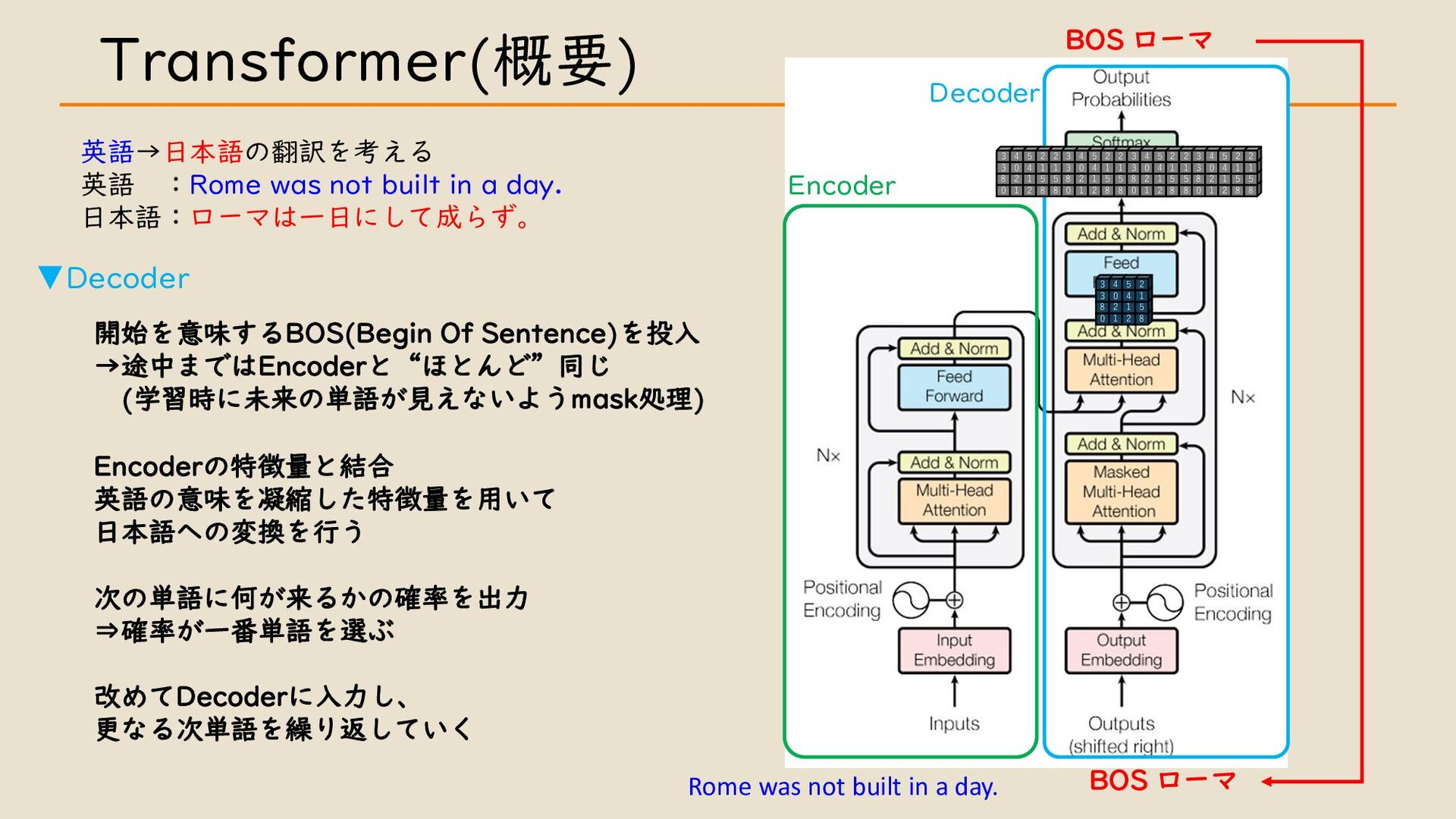
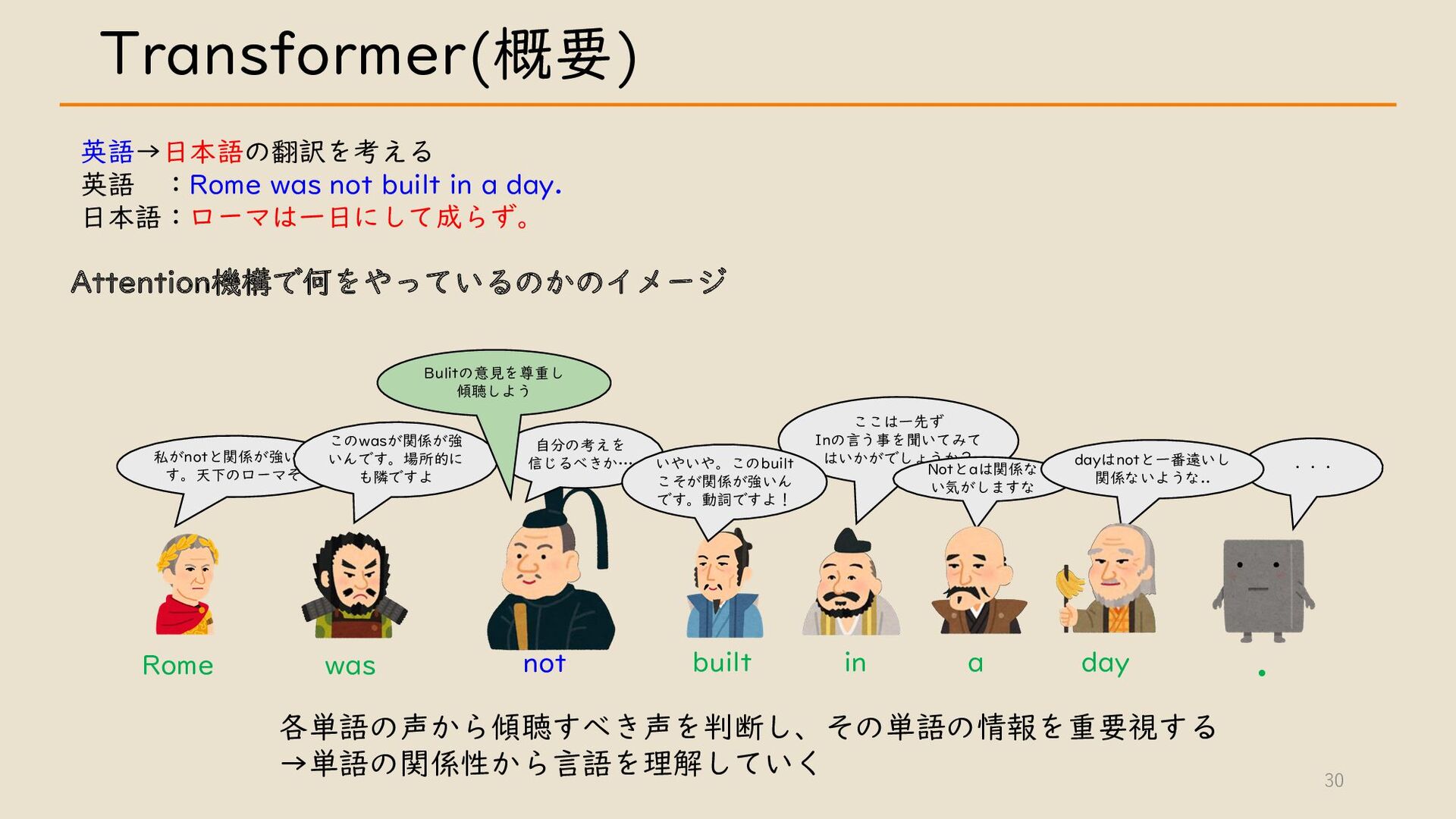
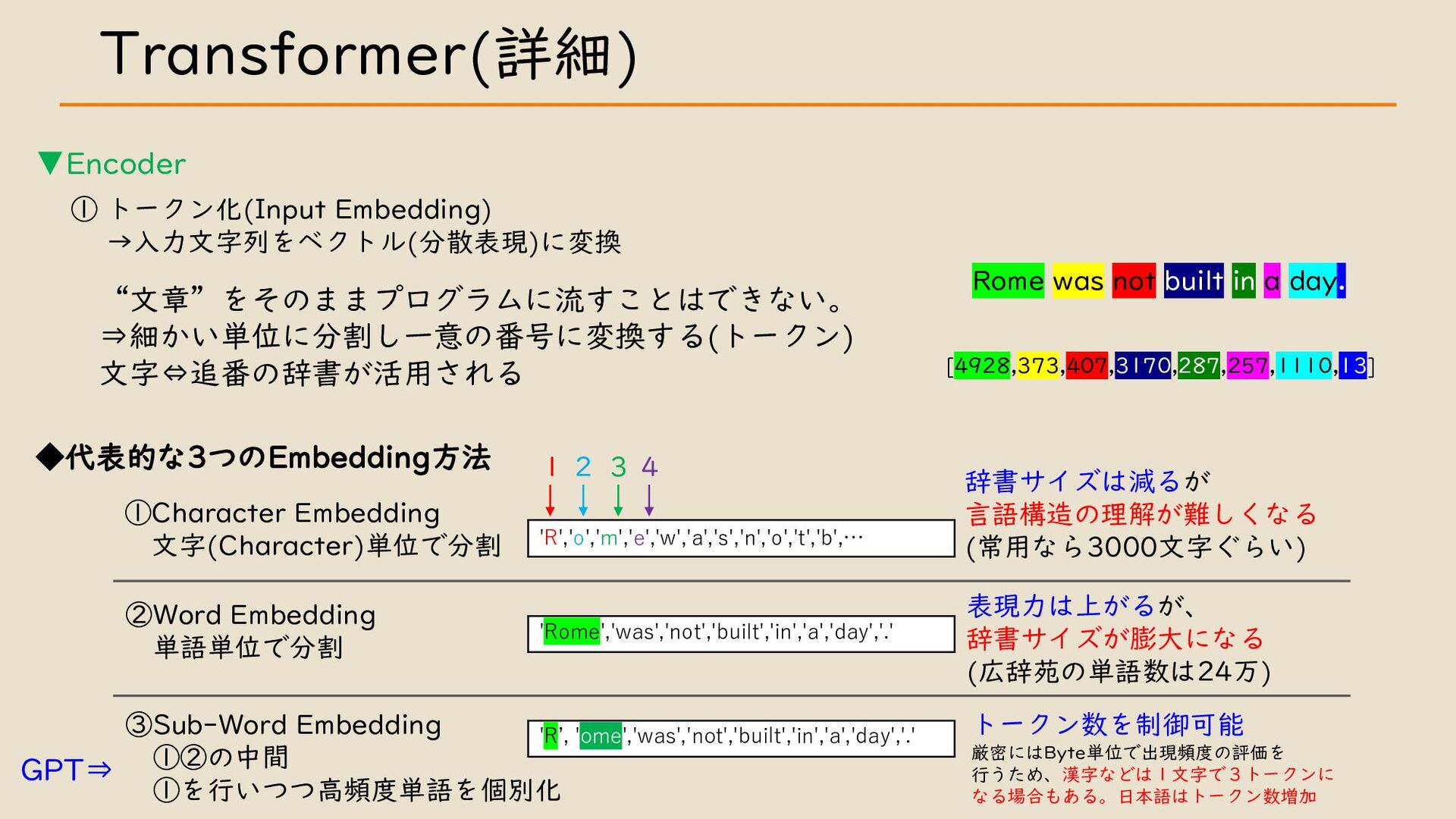
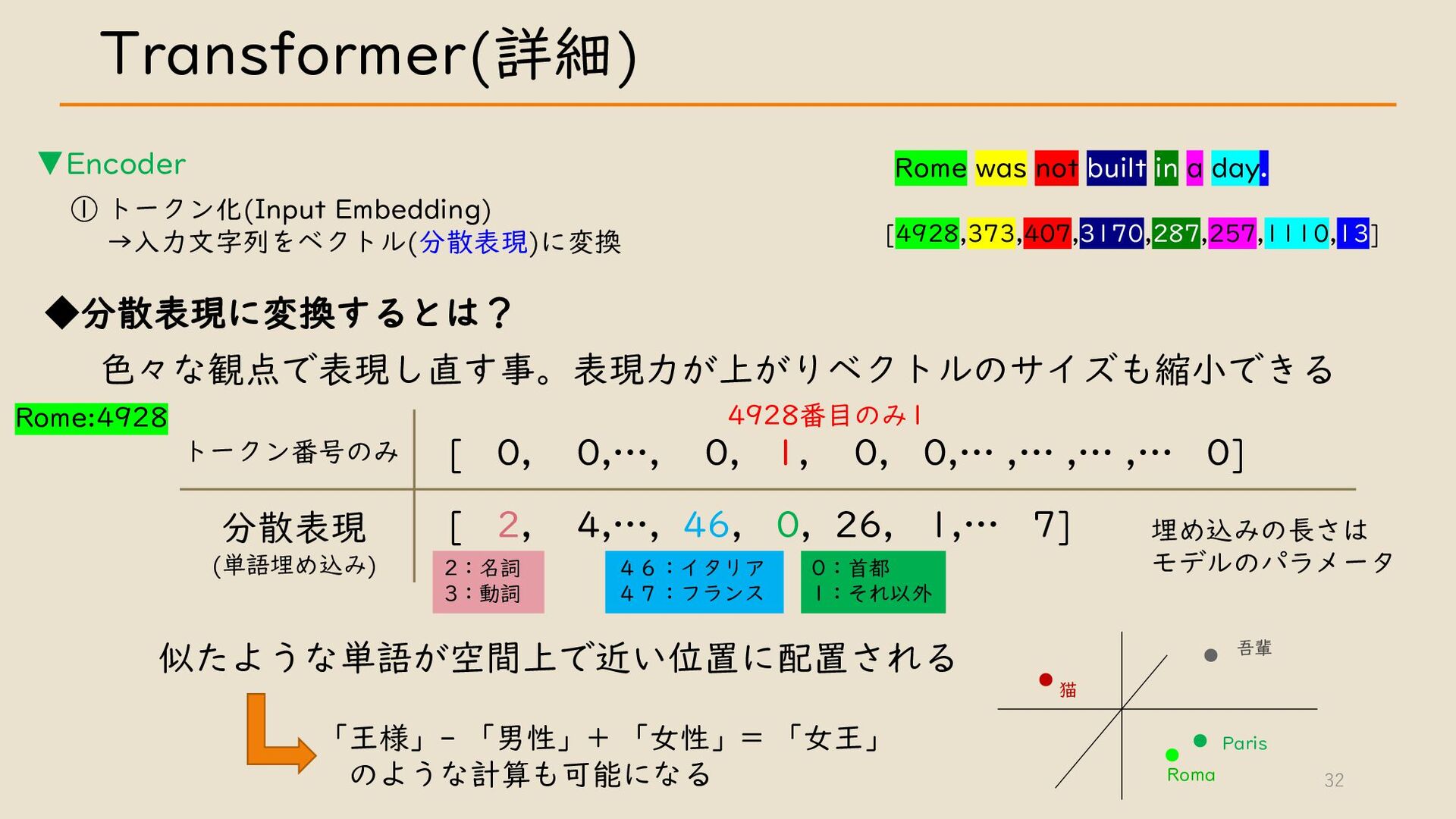
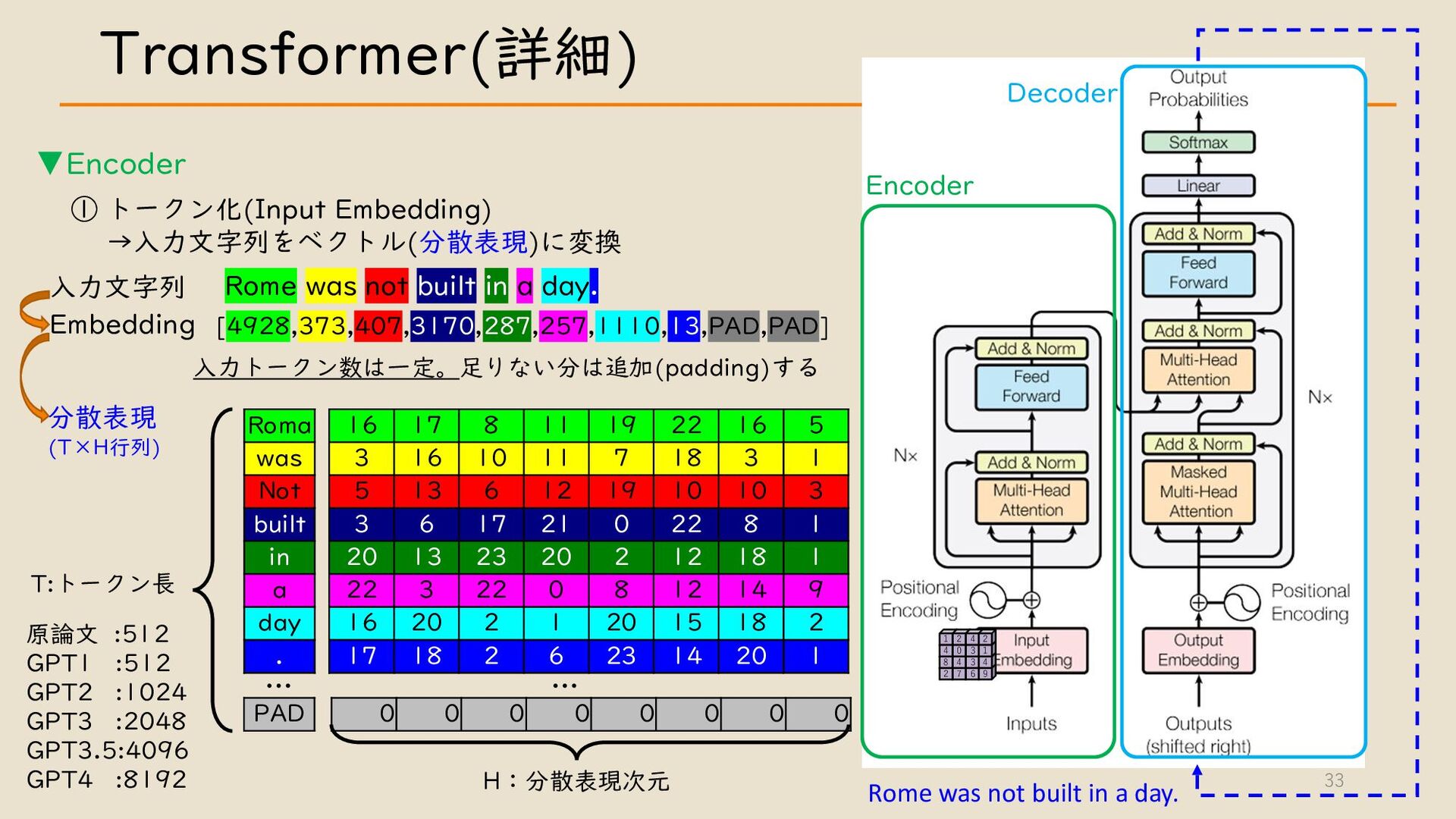
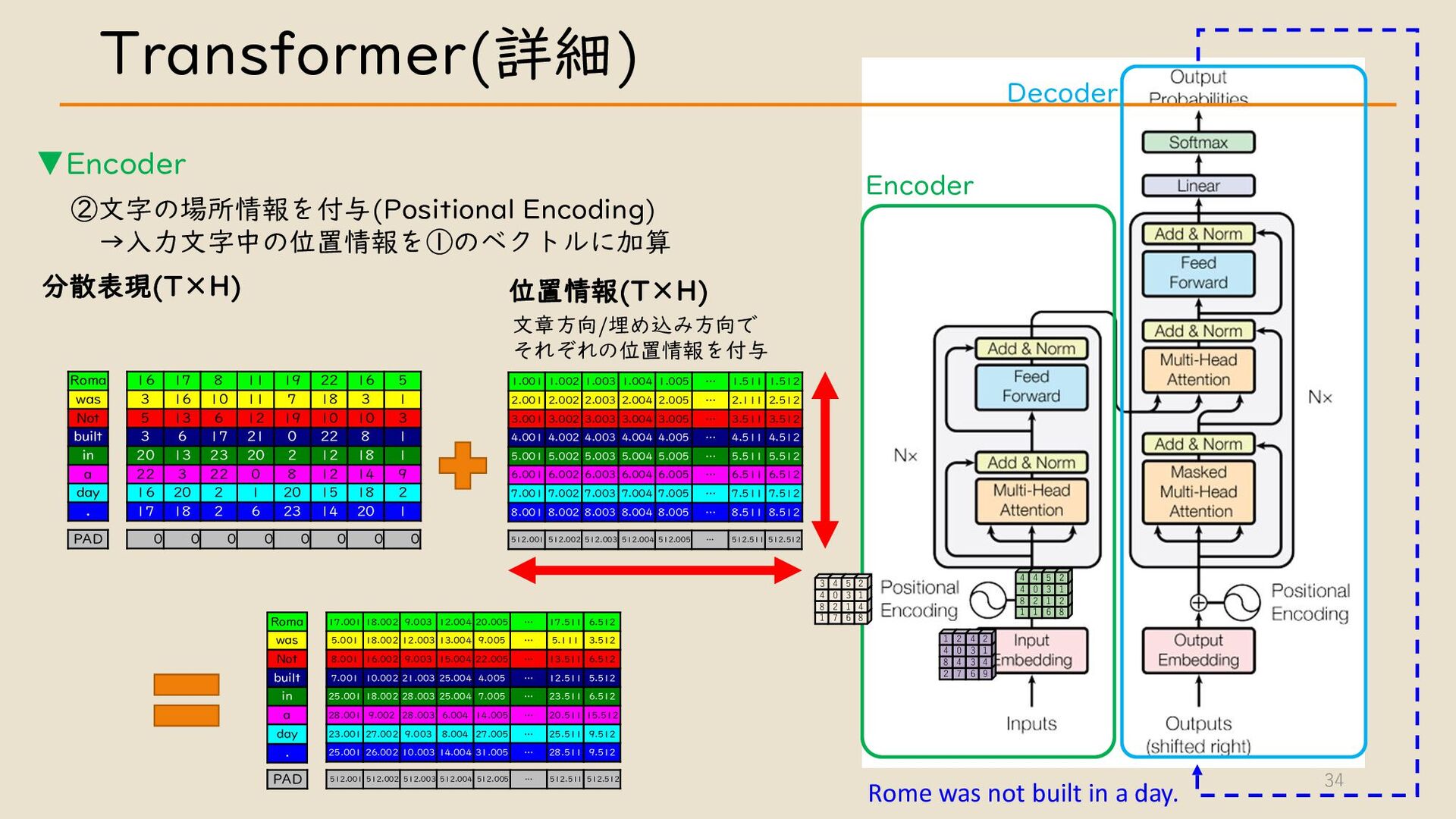
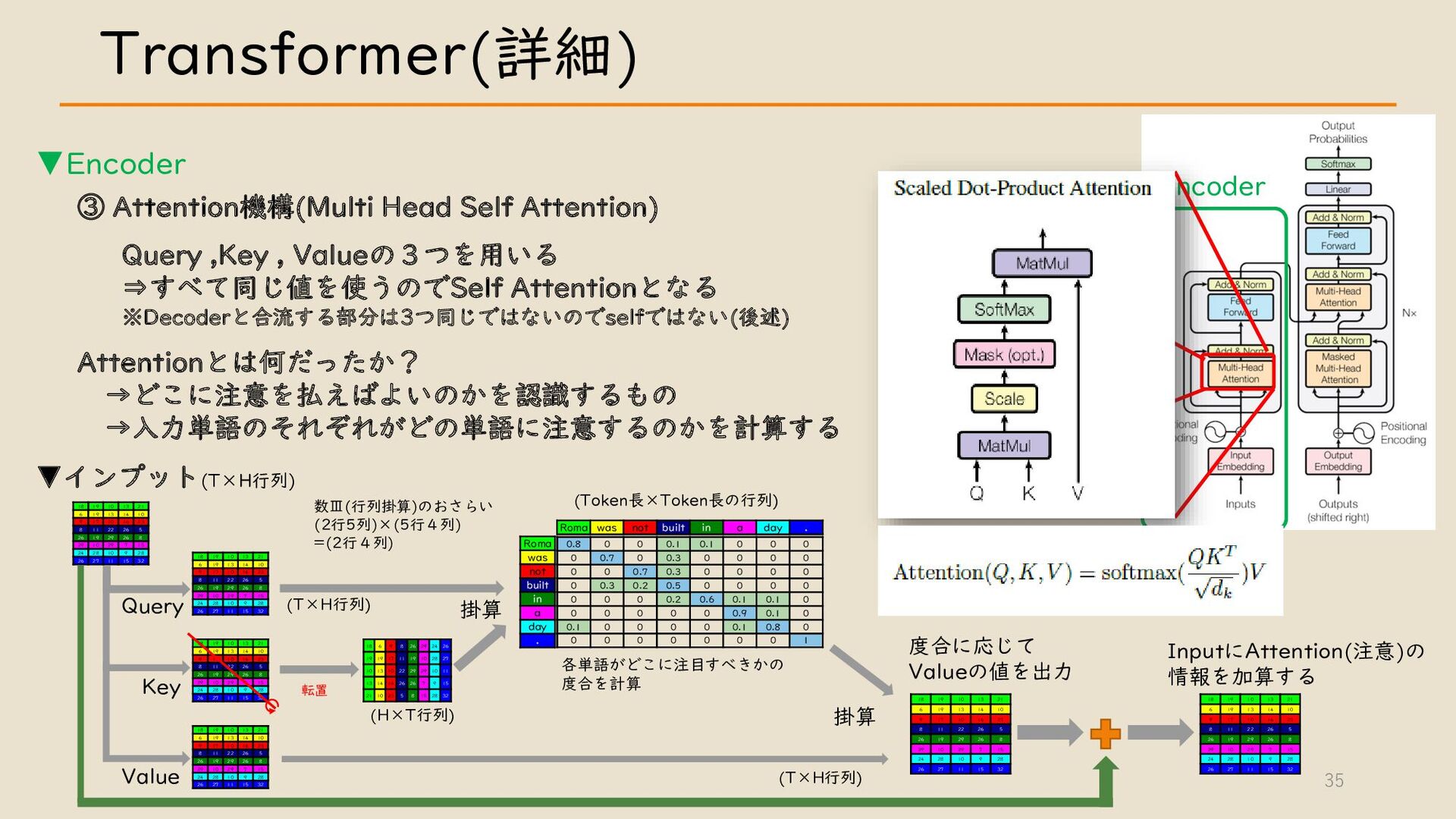
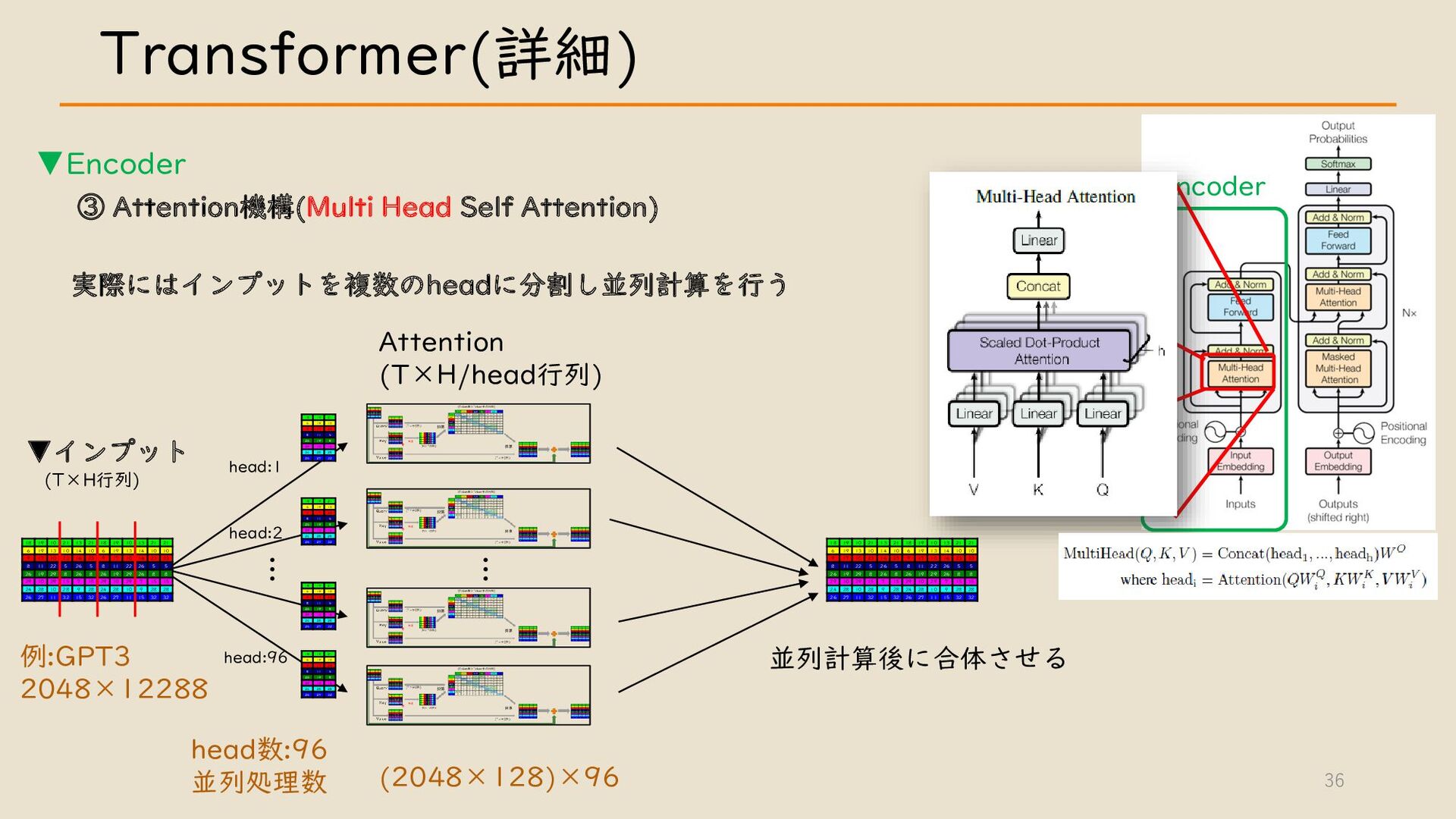
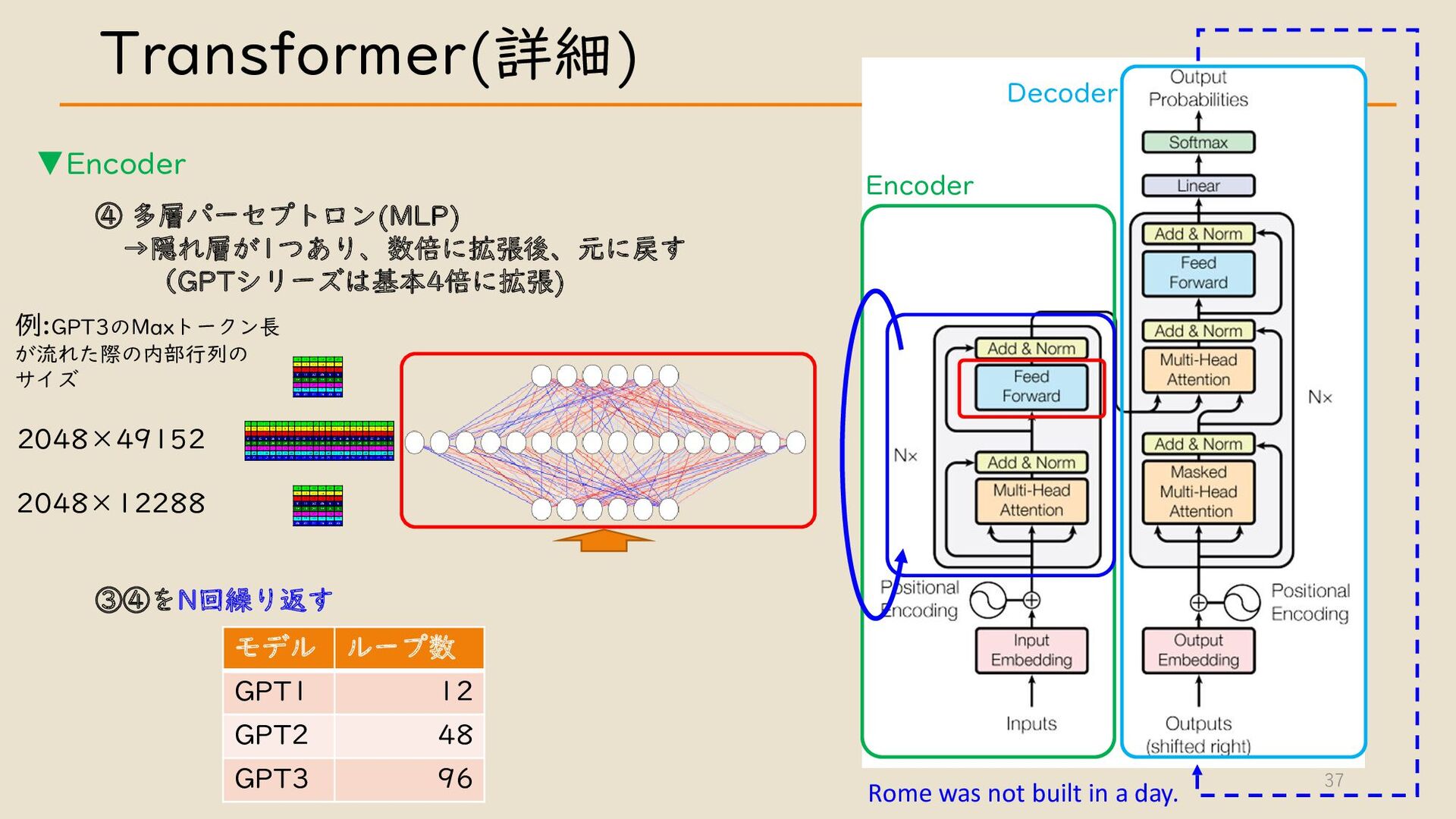
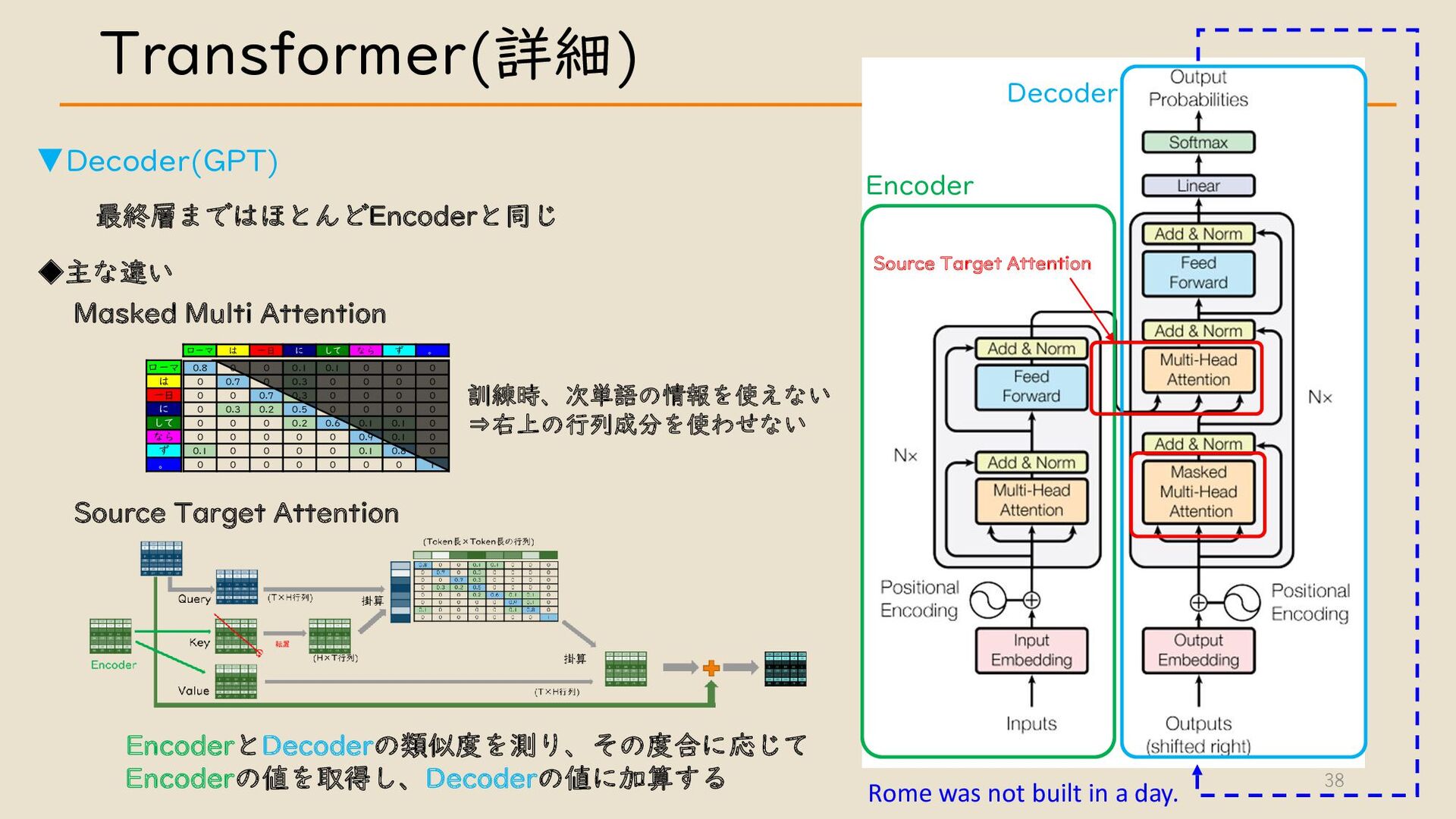
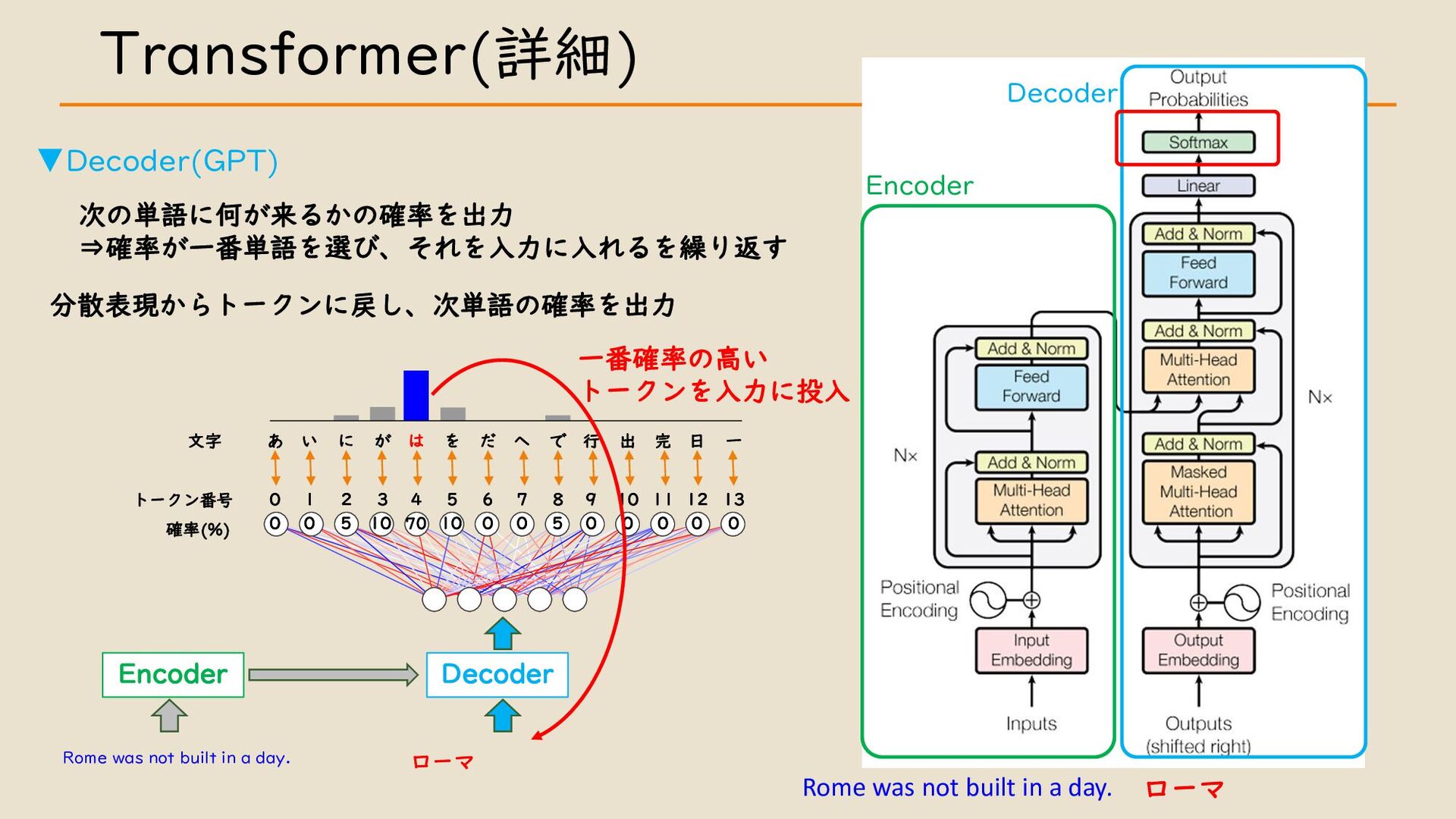
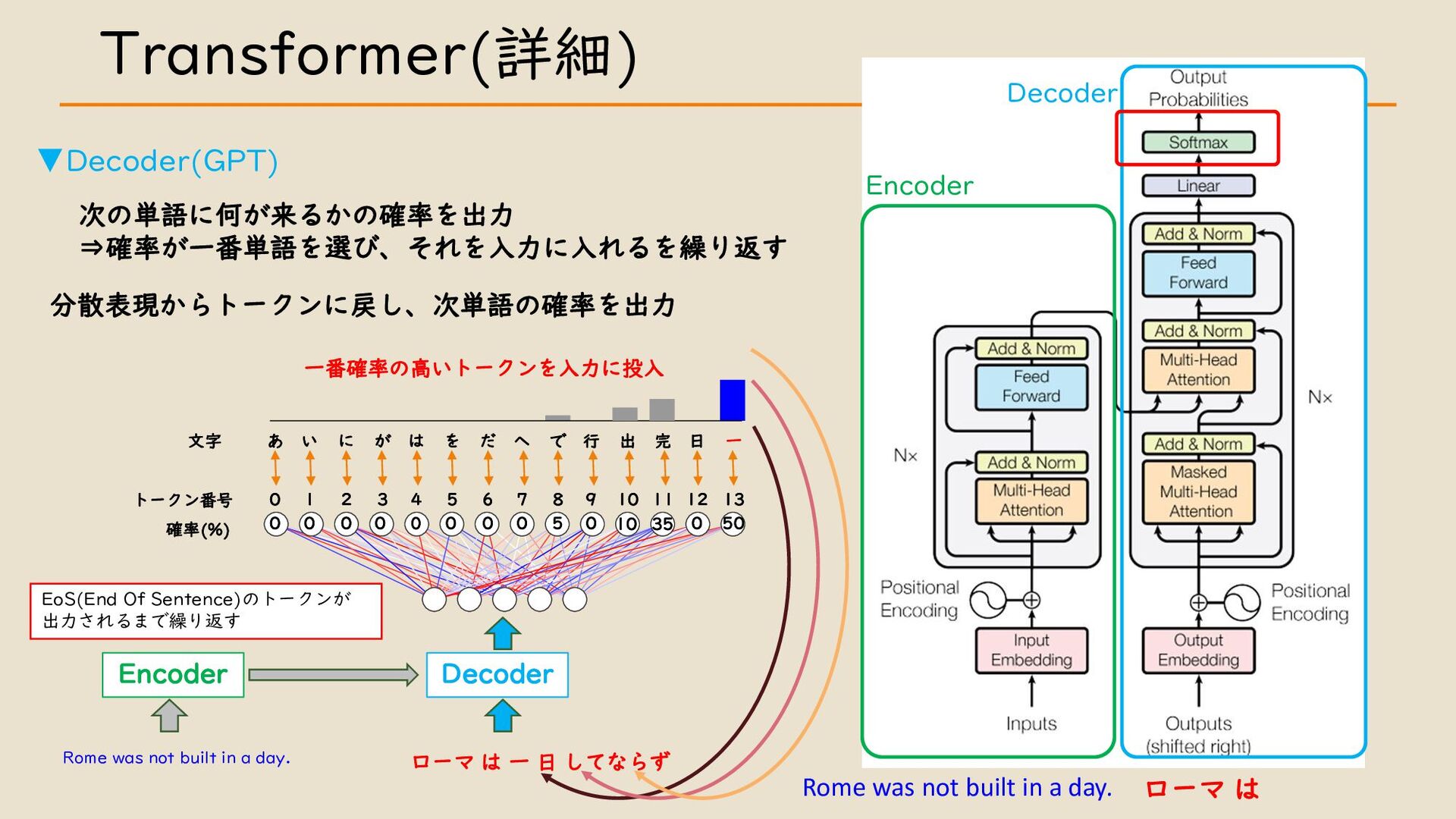
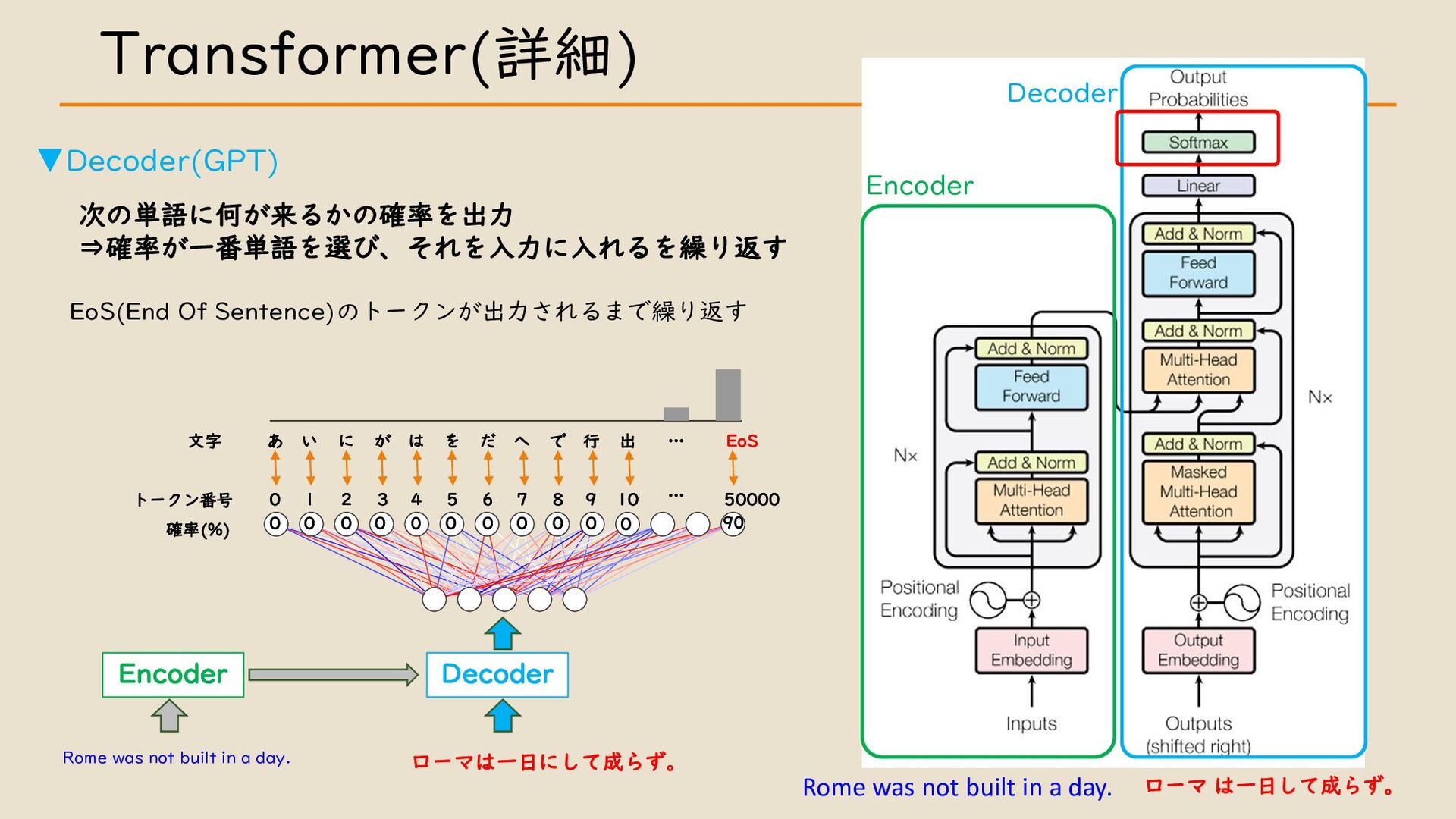
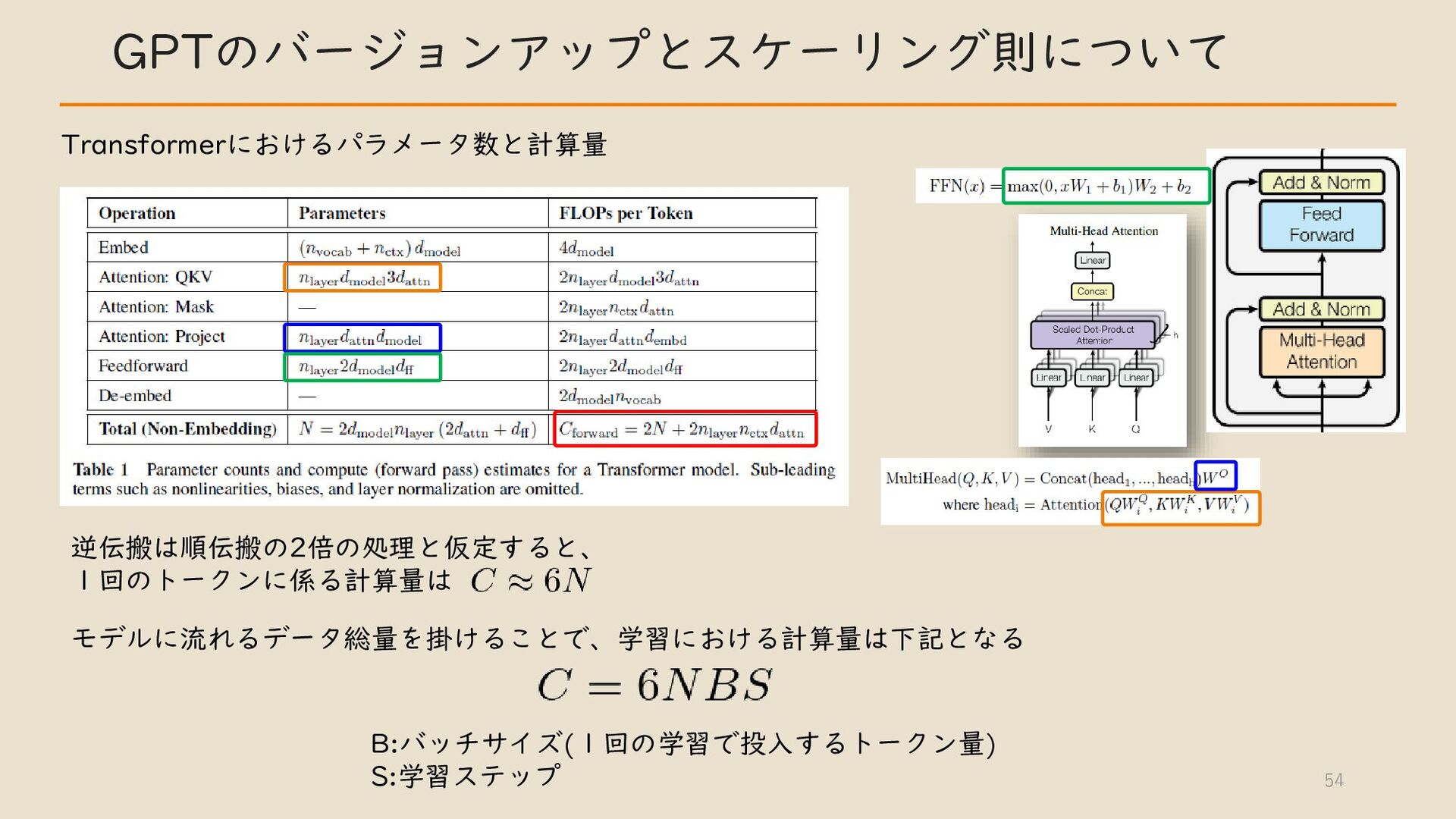
・ Transformer について
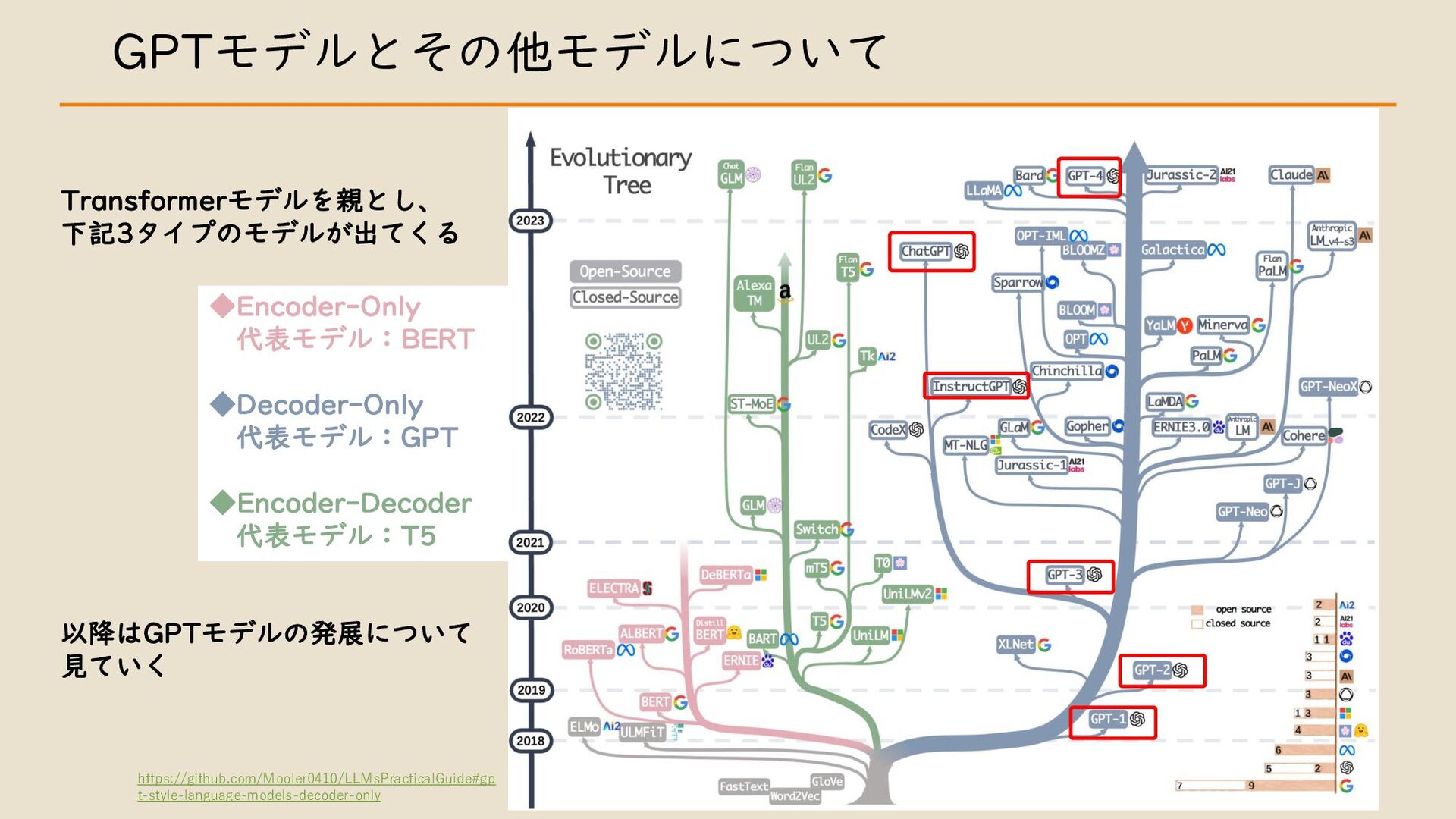
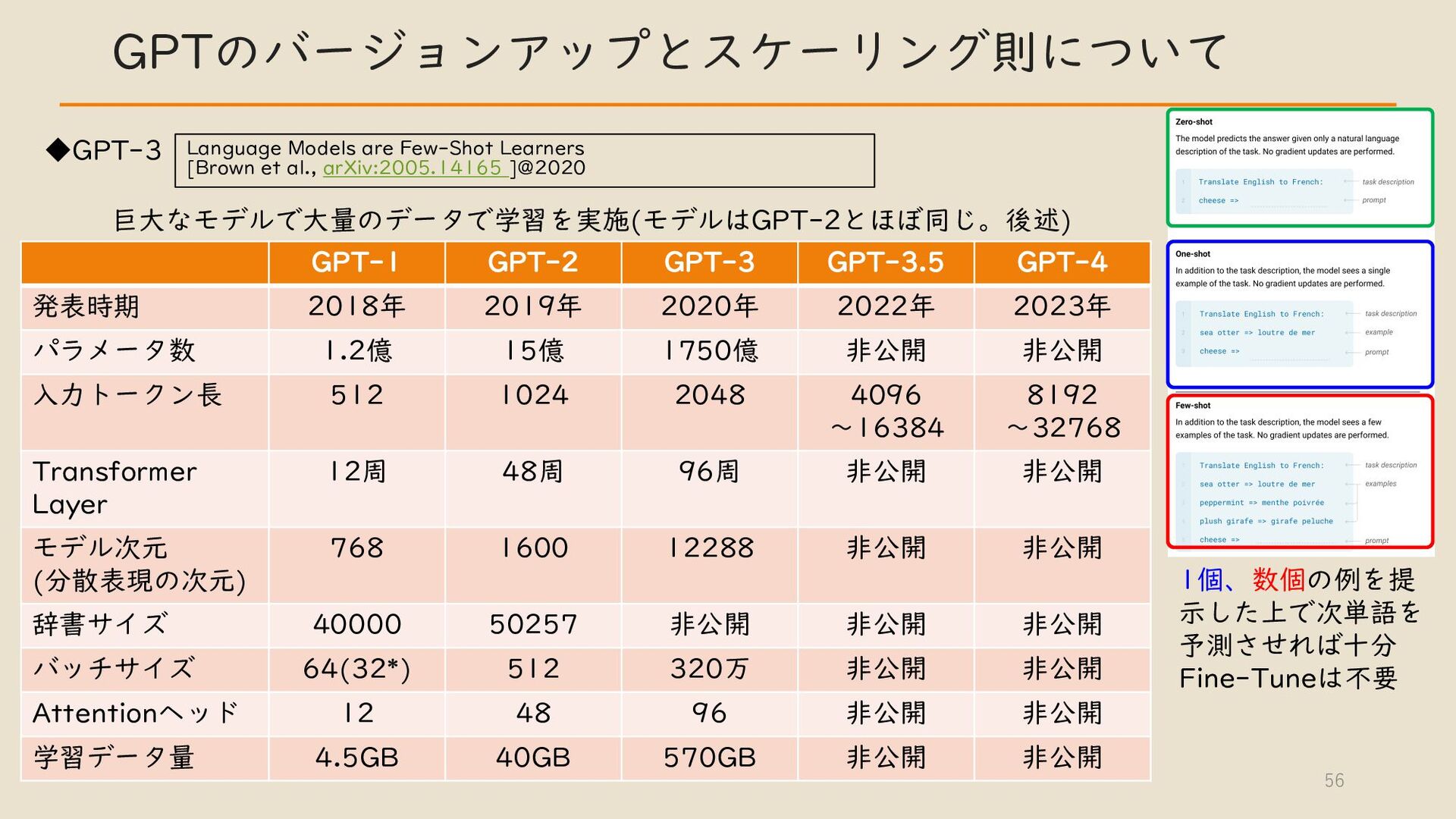
・ GPT モデルとその他モデルについて
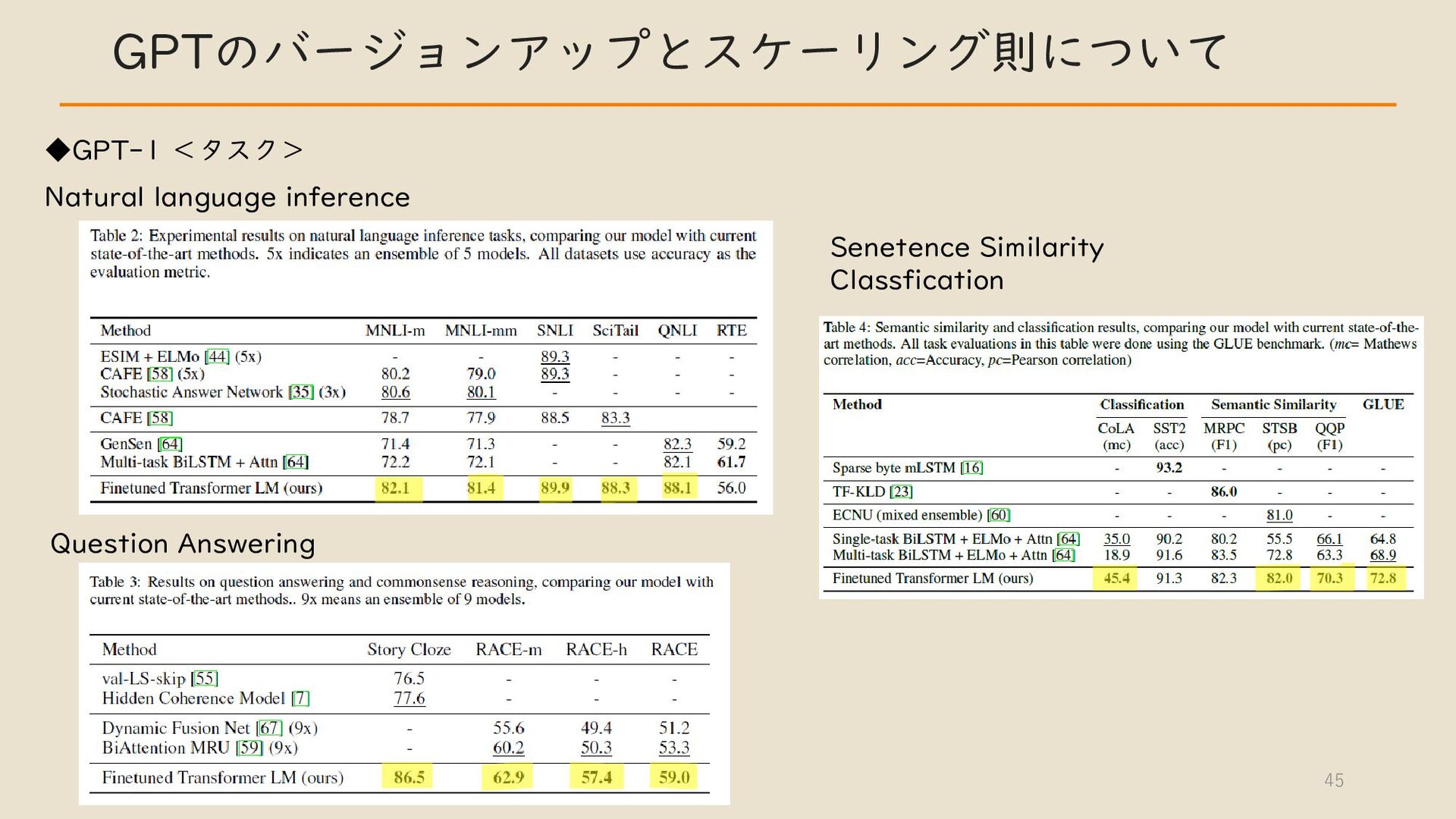
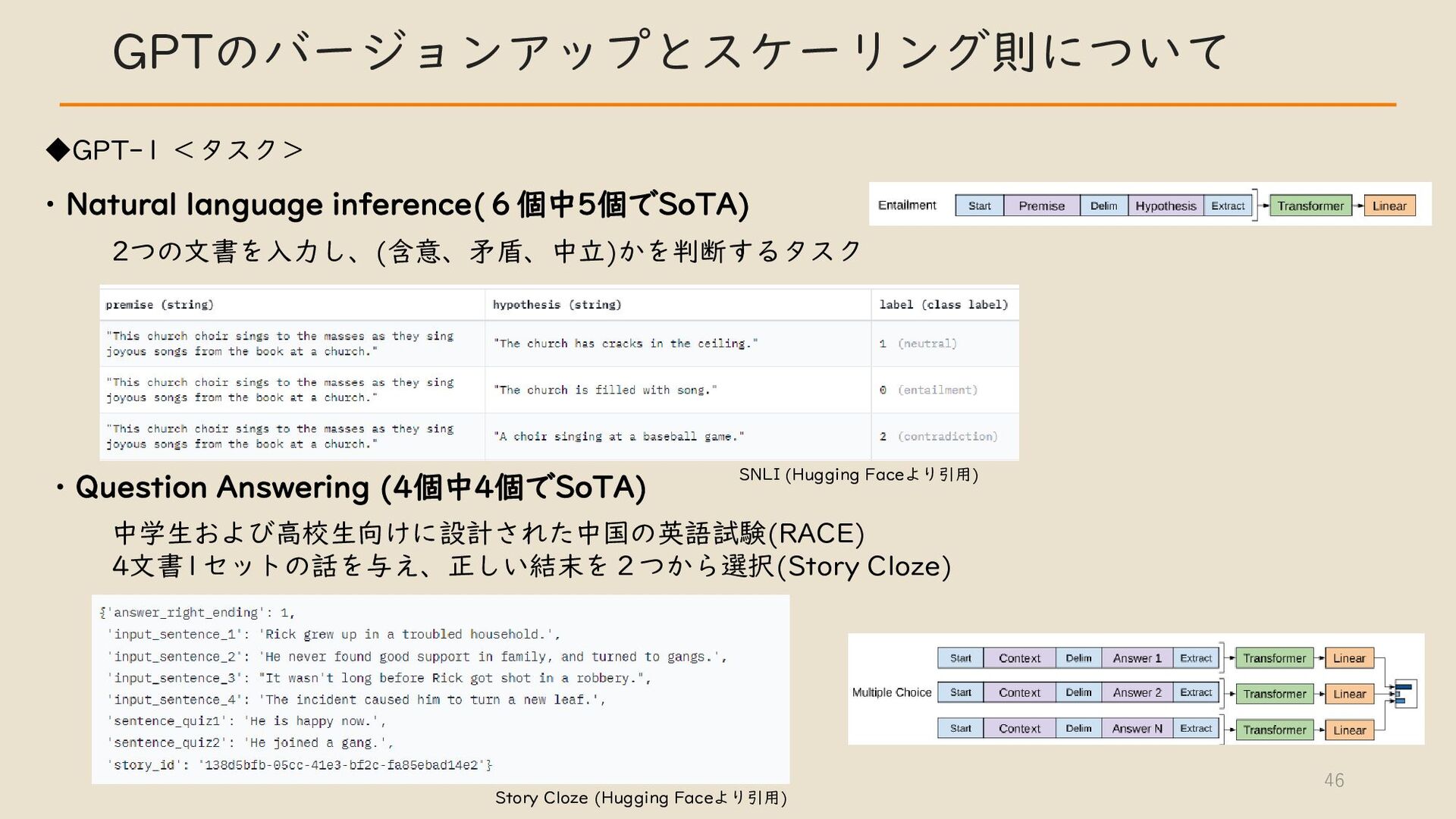
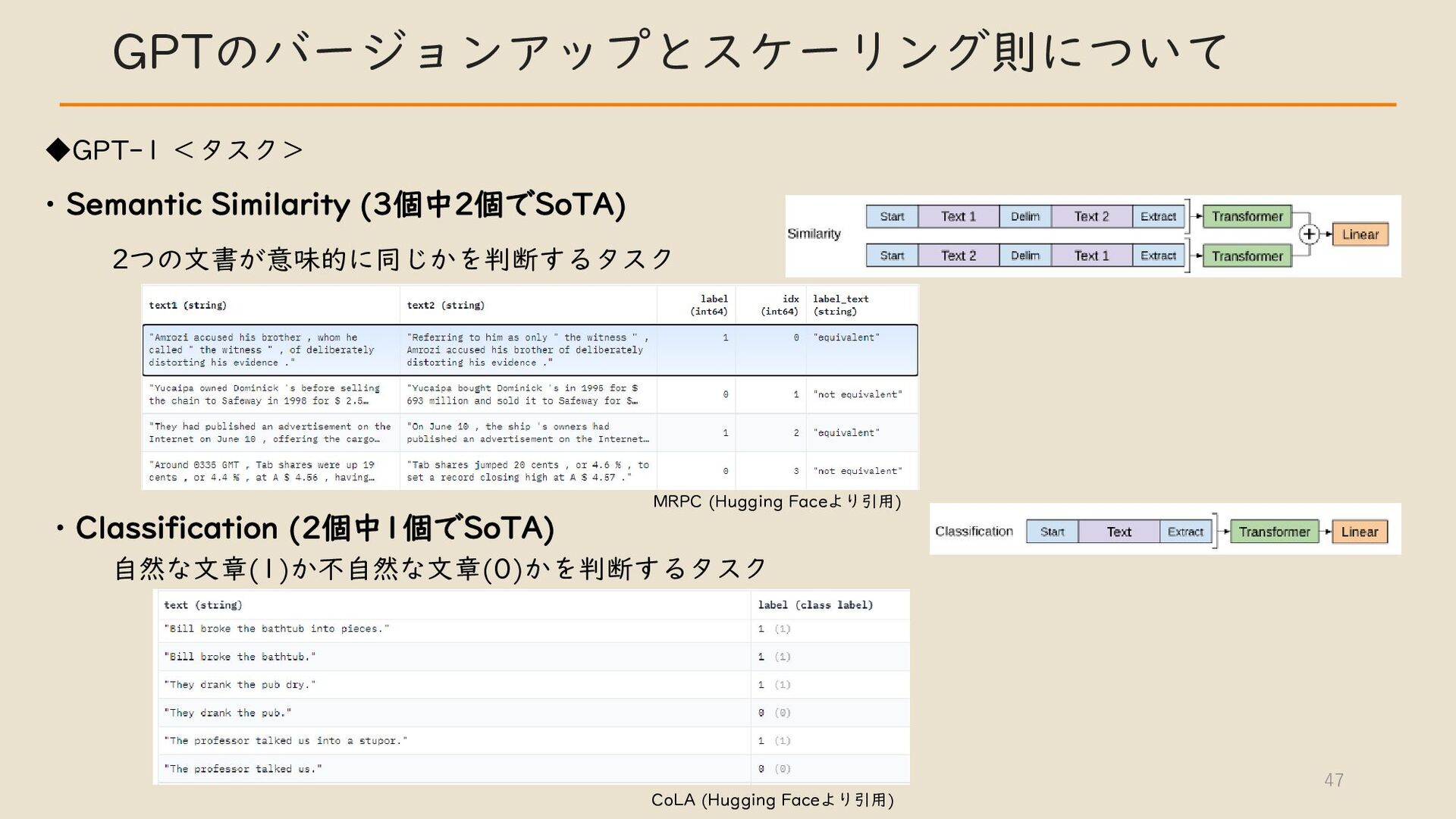
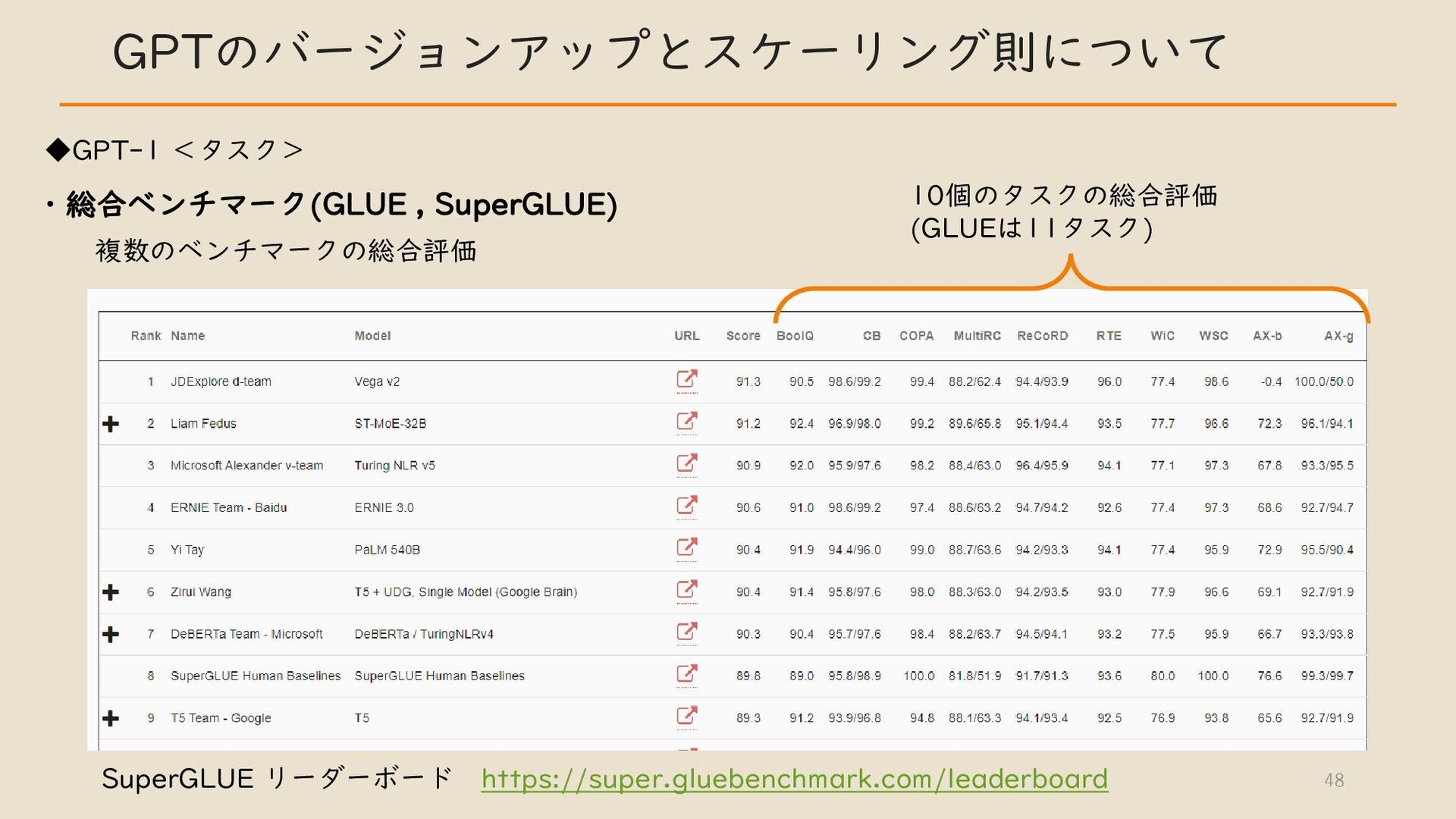
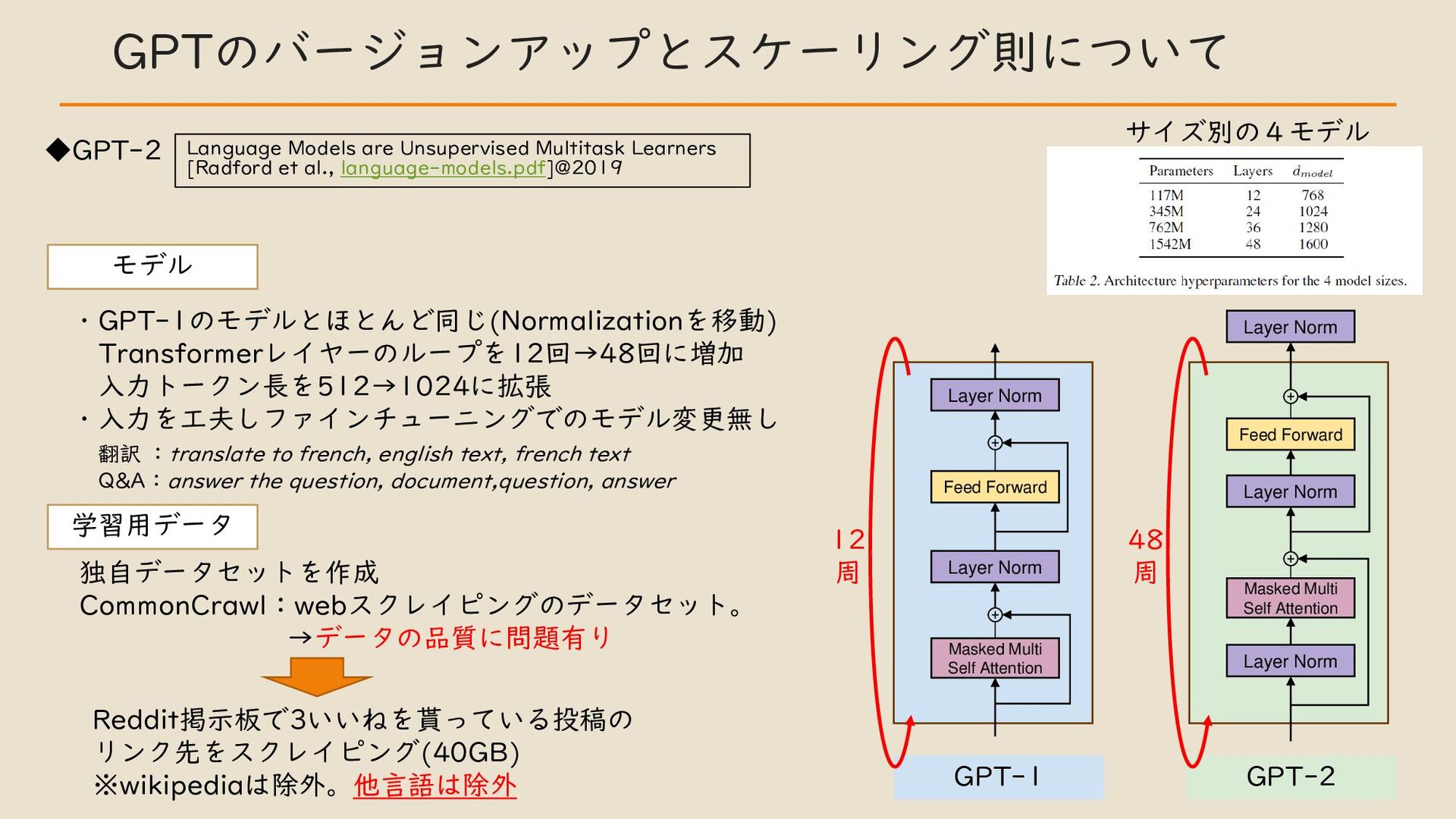
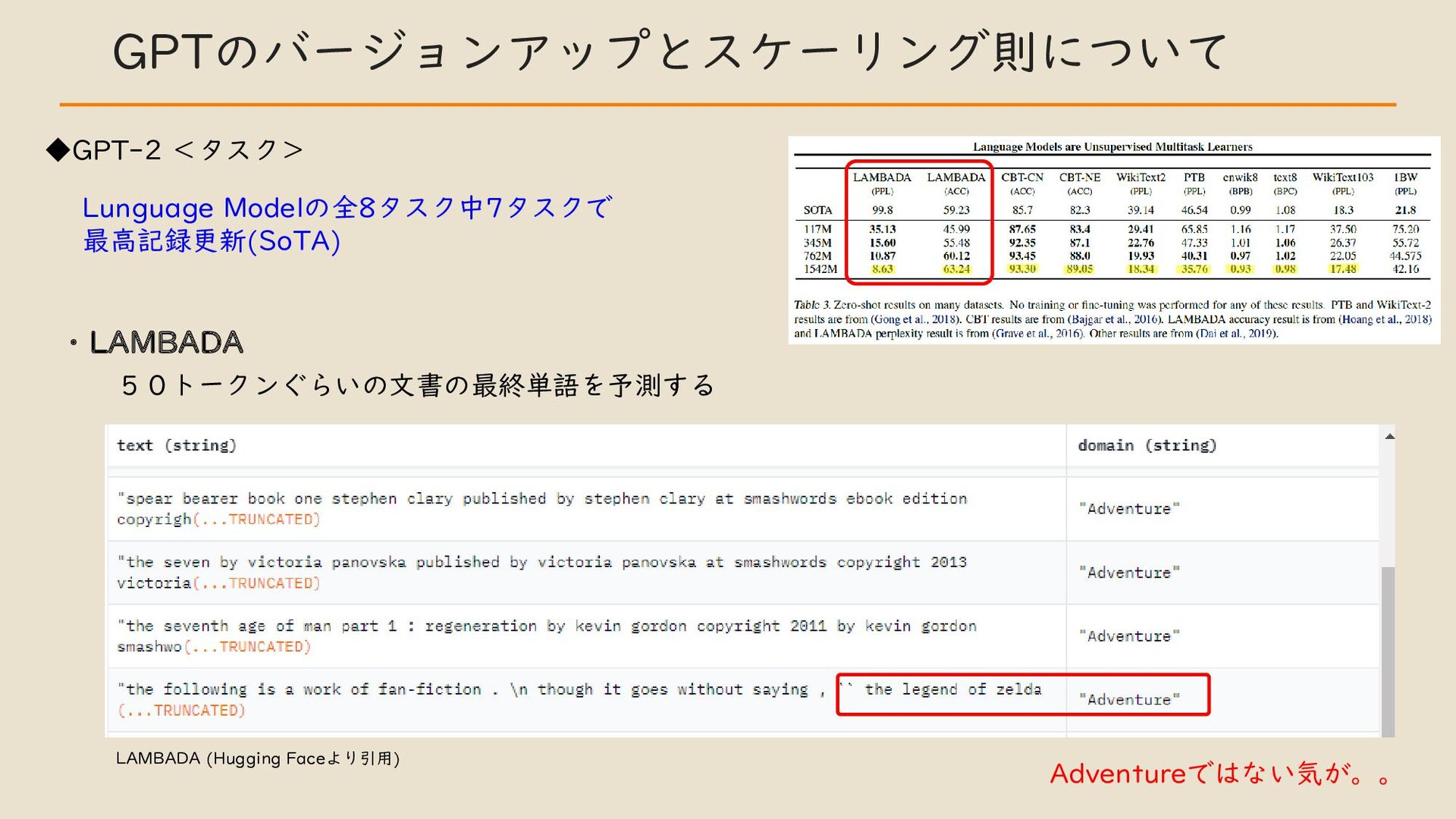
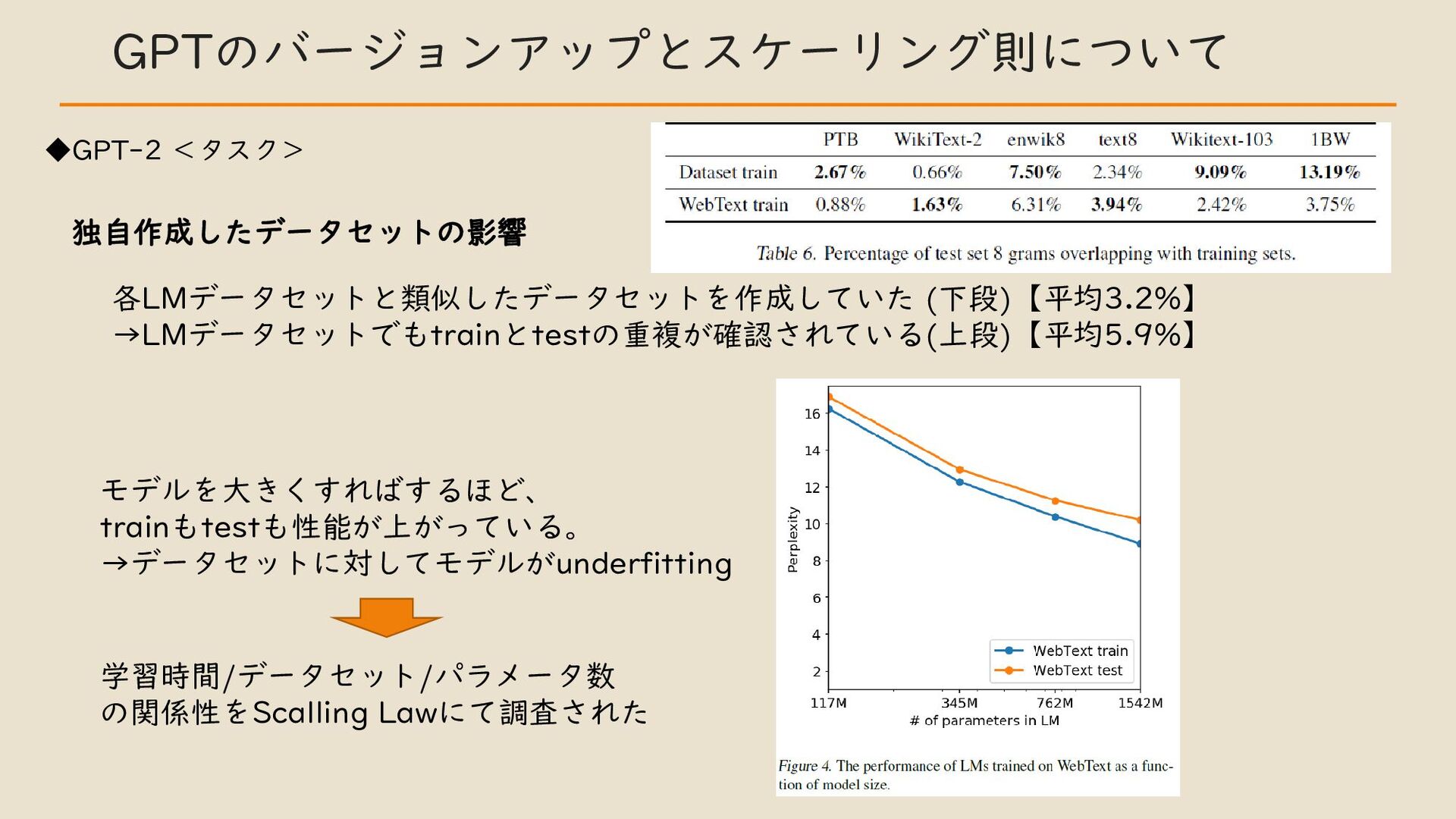
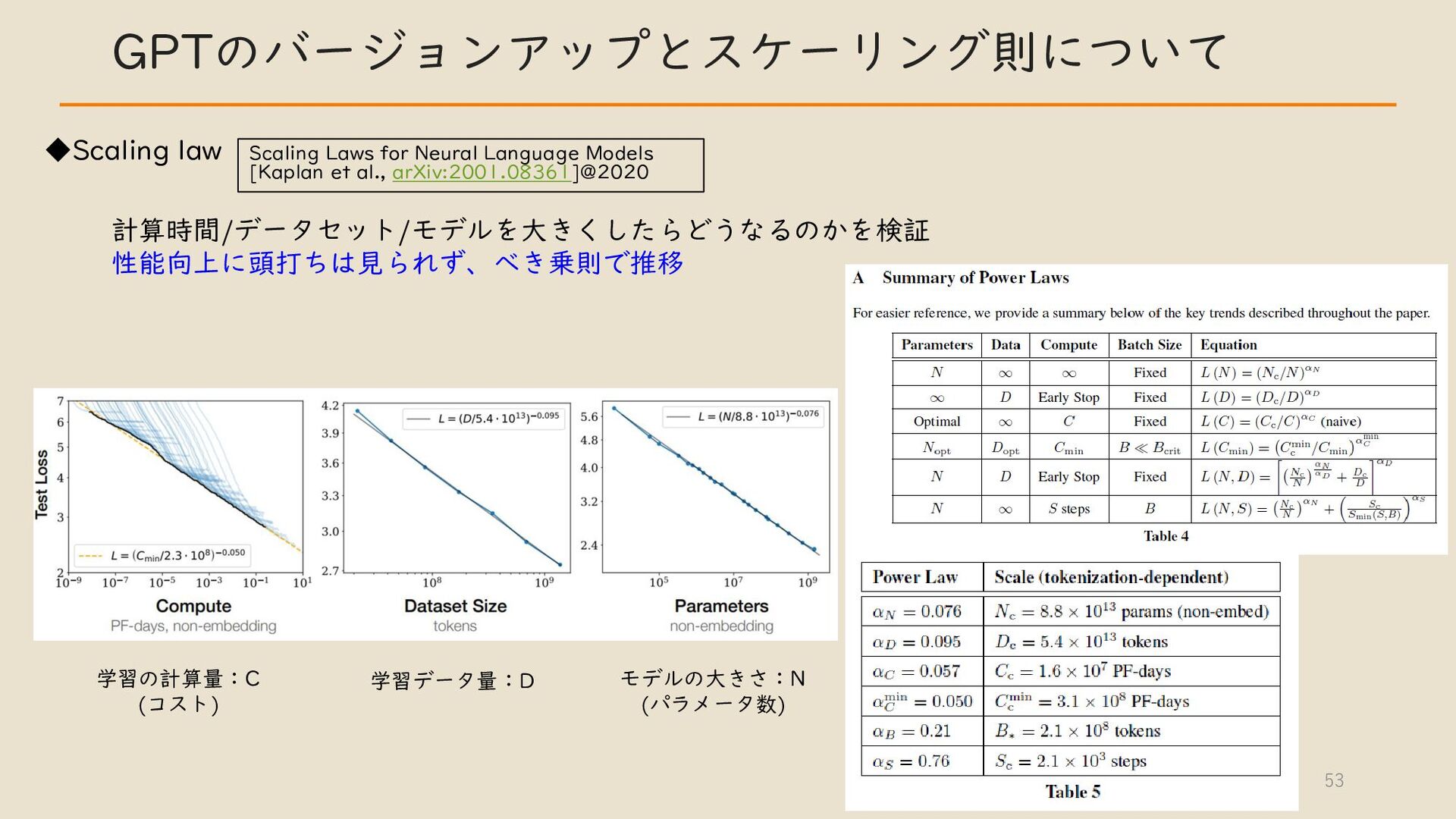
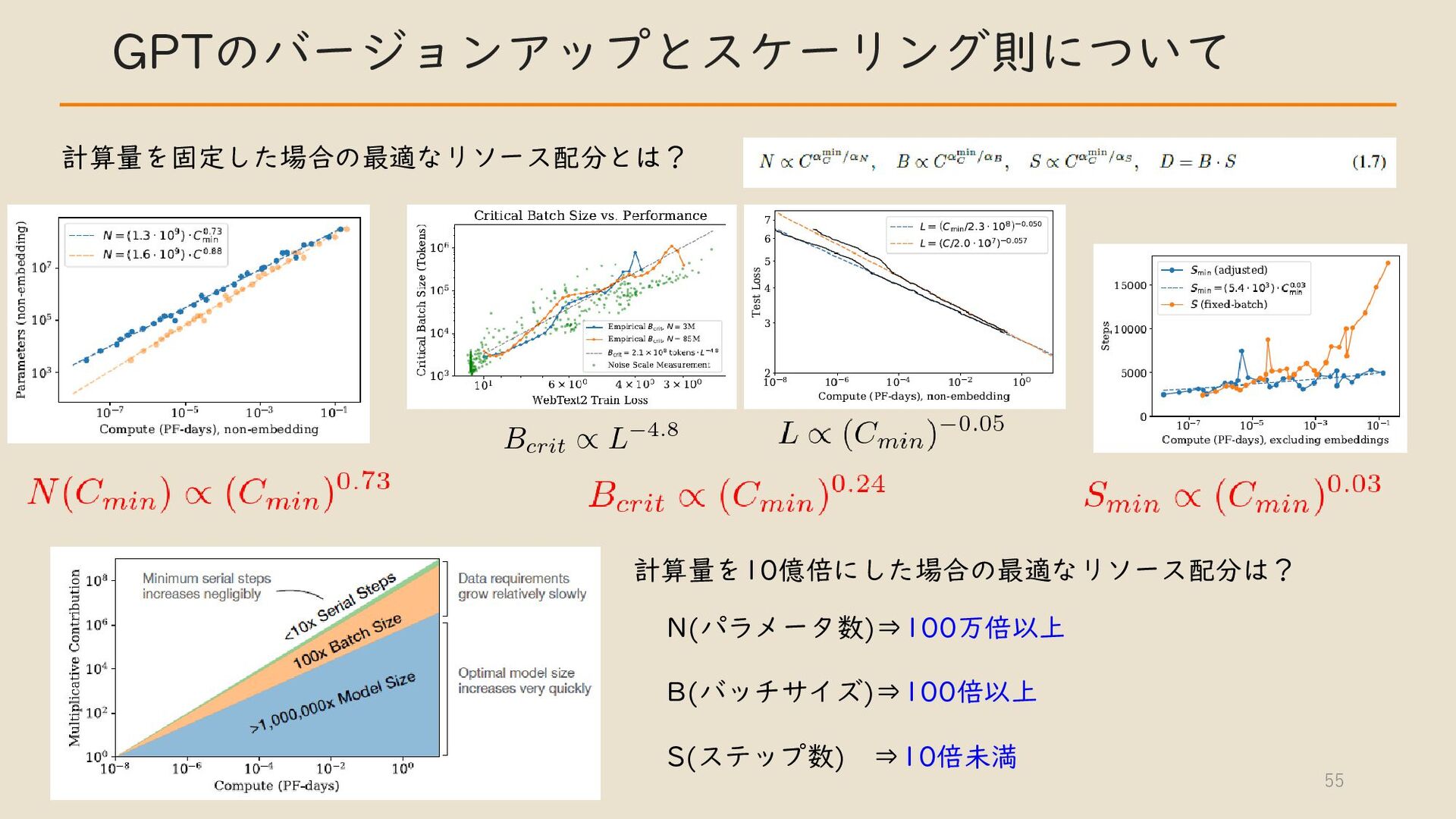
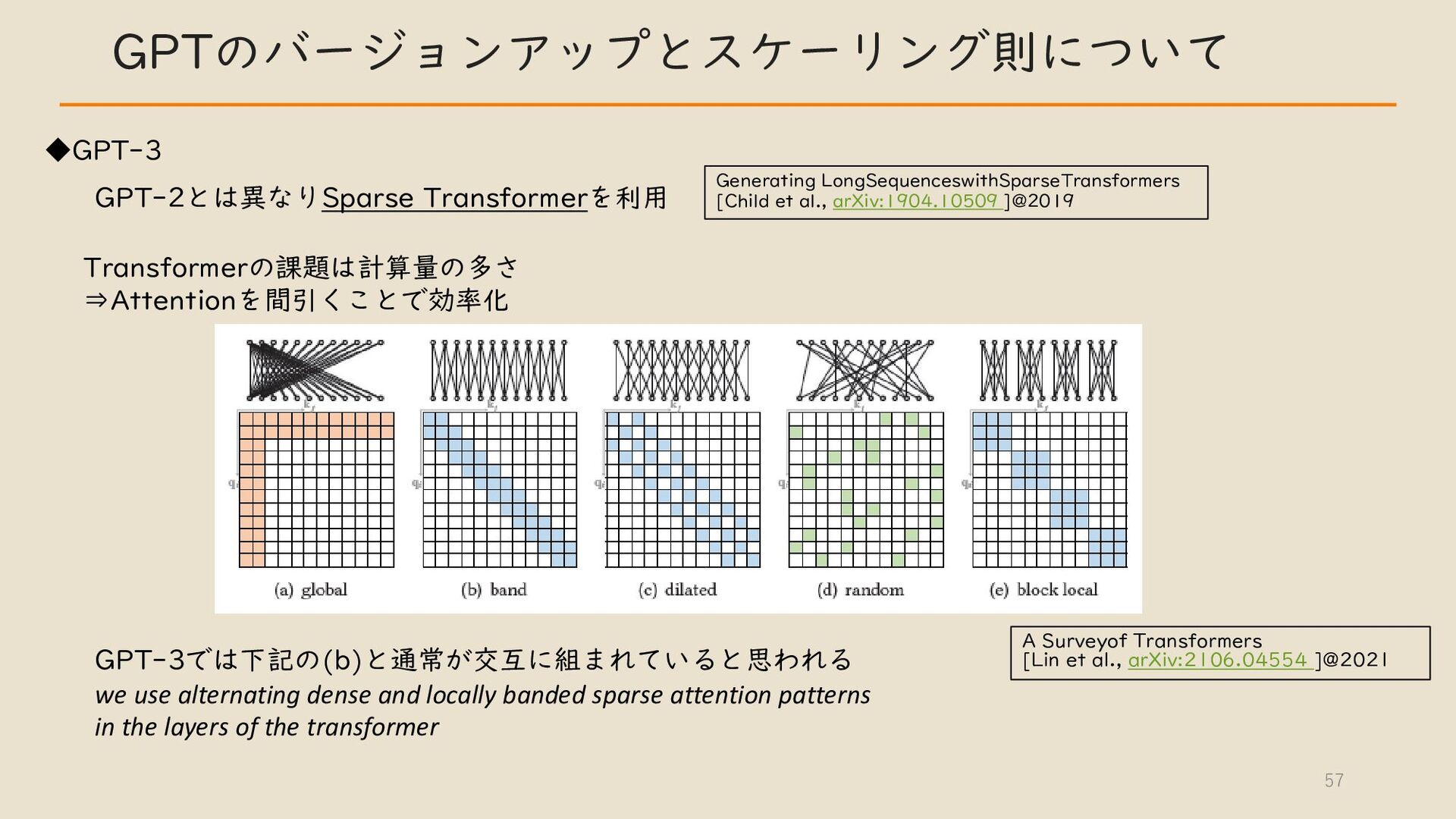
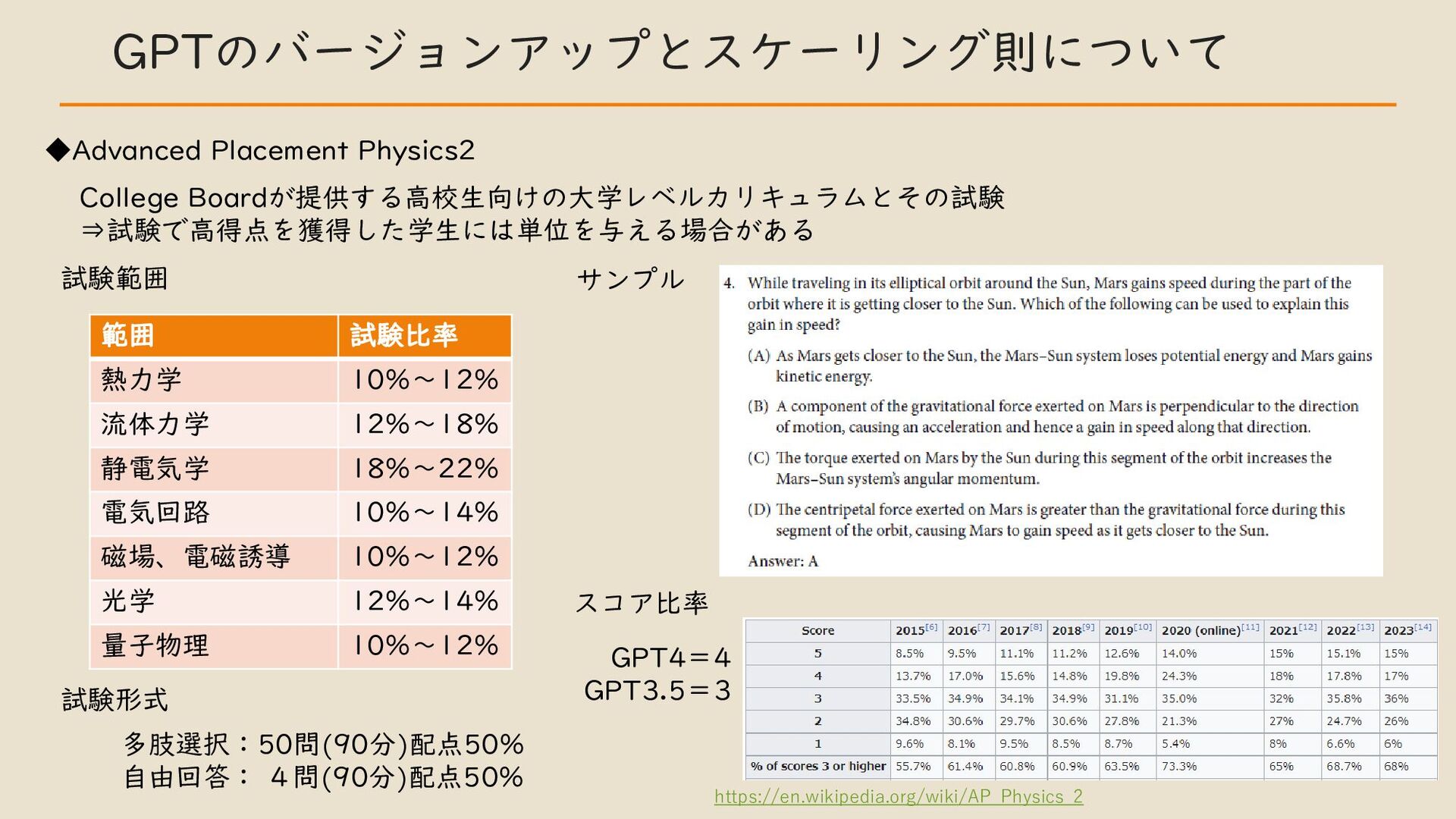
・ GPT のバージョンアップとスケーリング則について
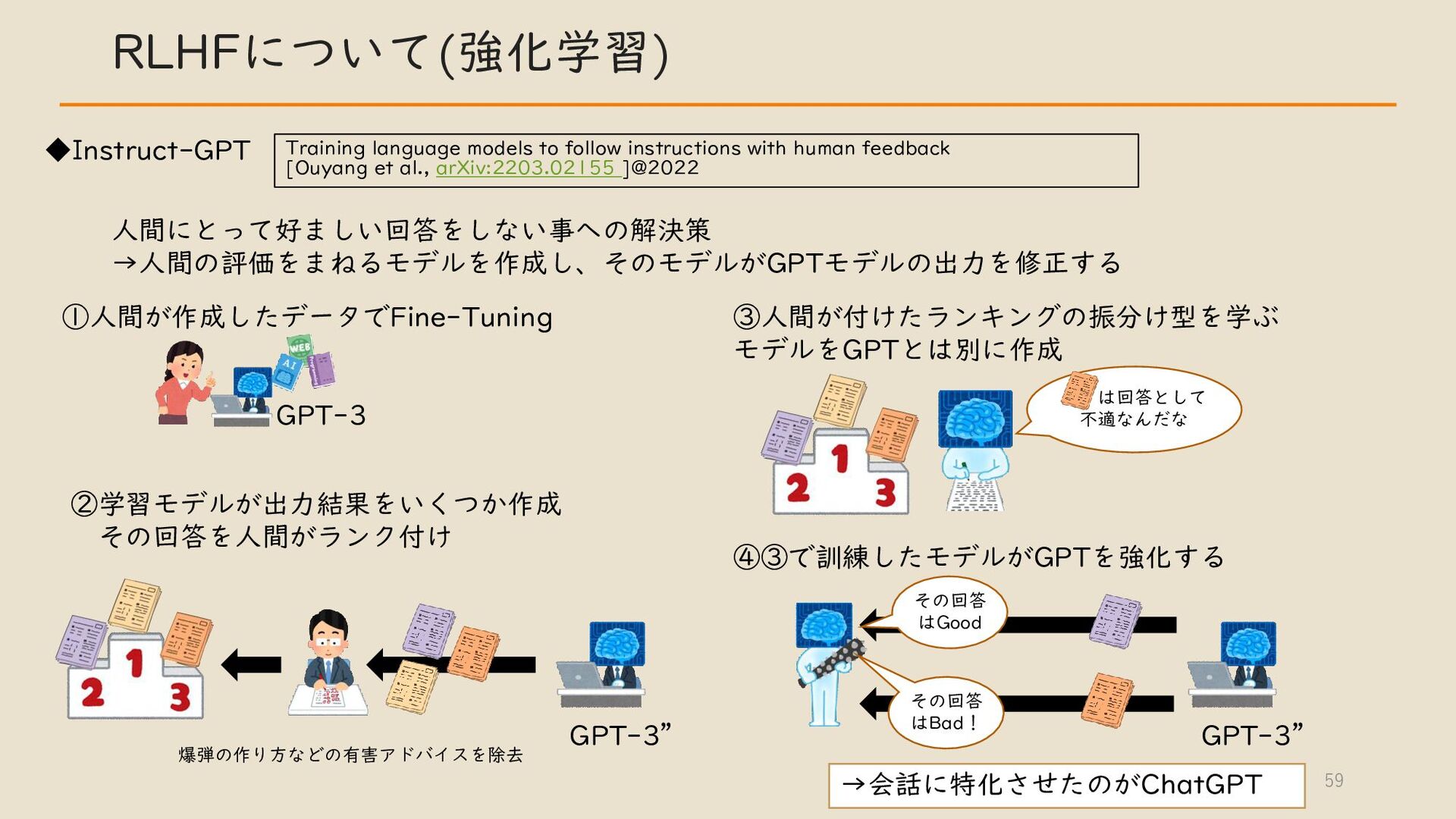
・ RLHF について 強化学習
■その他
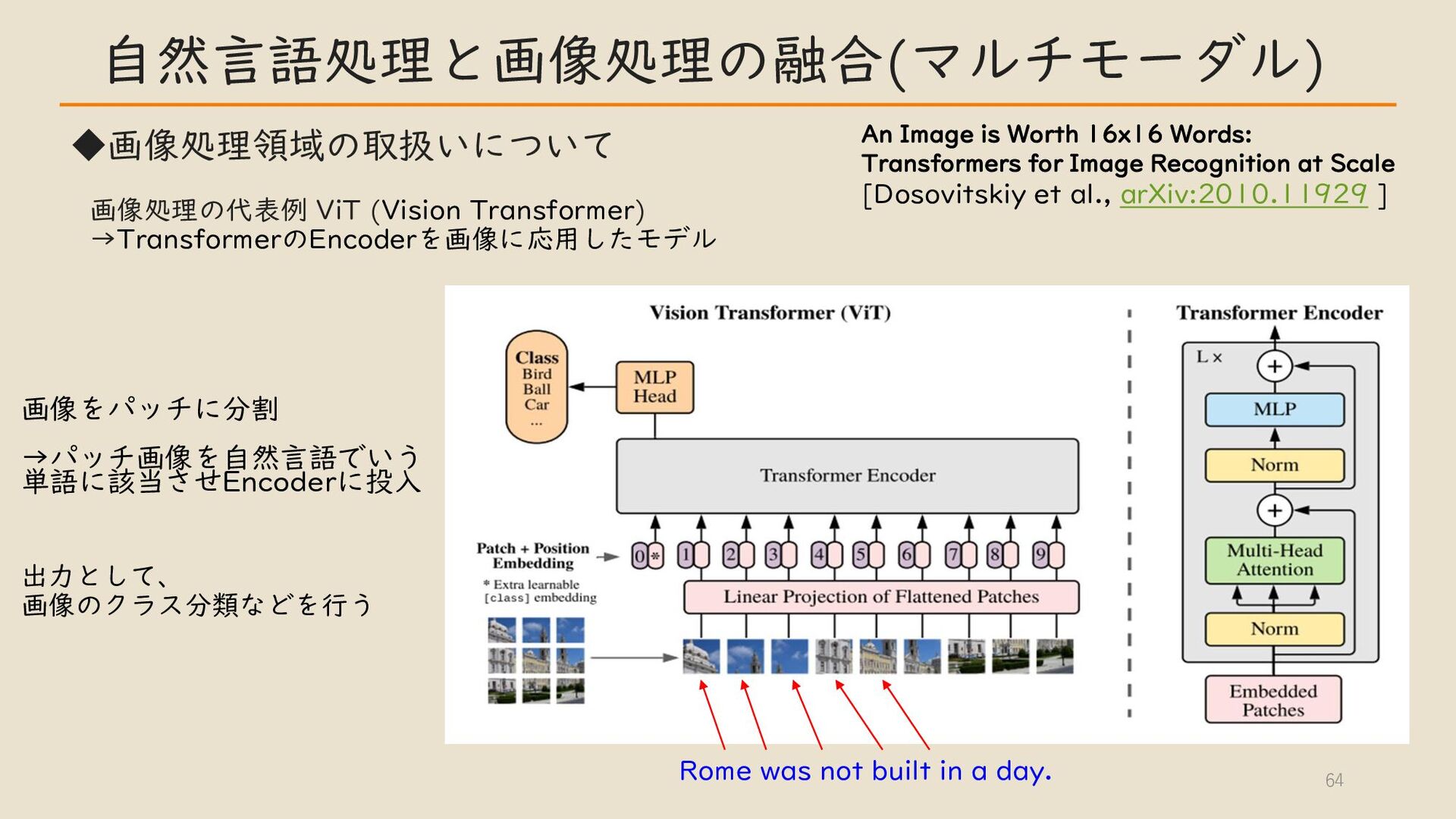
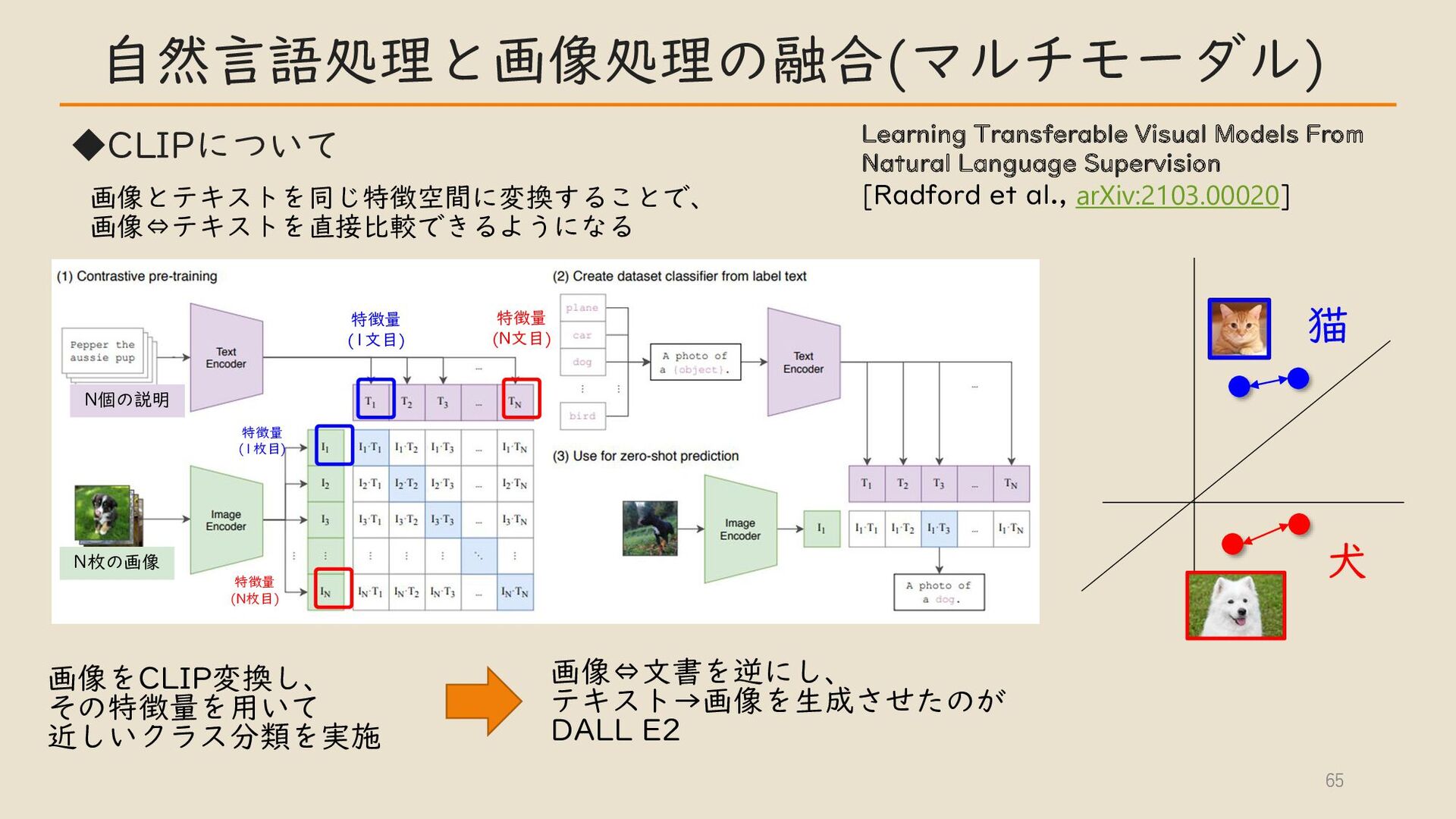
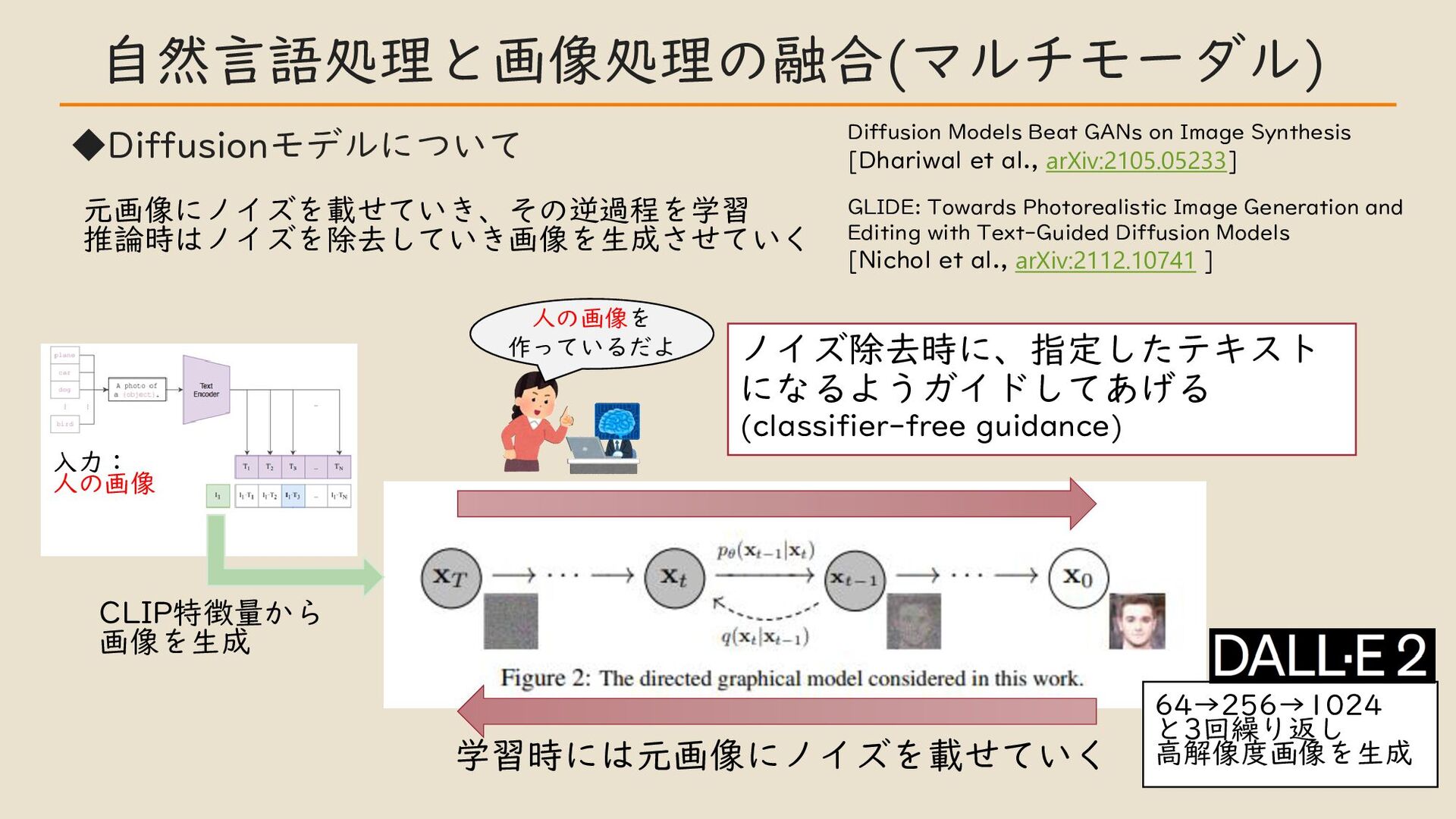
・自然言語処理と画像処理の融合 (マルチモーダル ) CLIP モデルなど
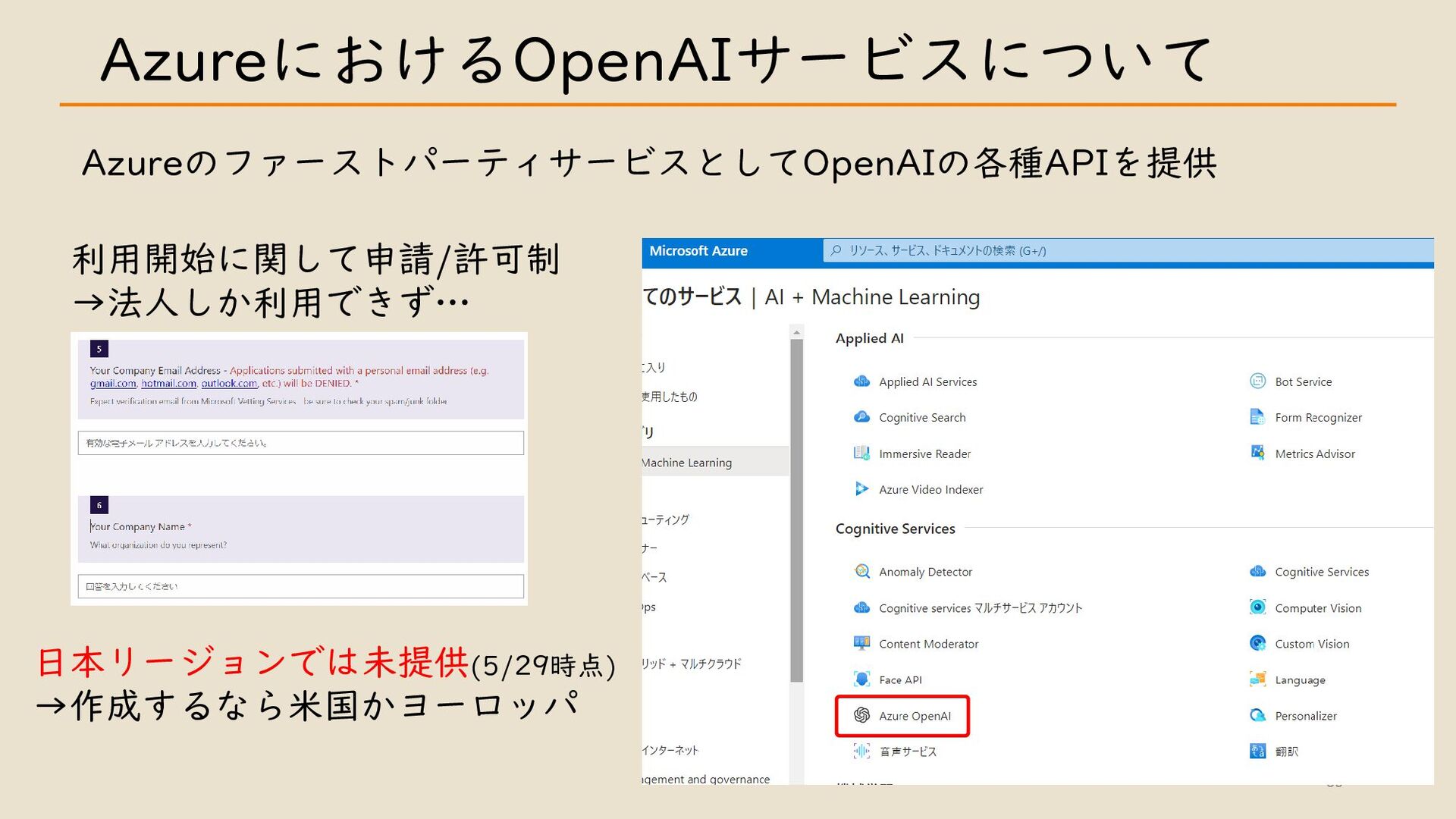
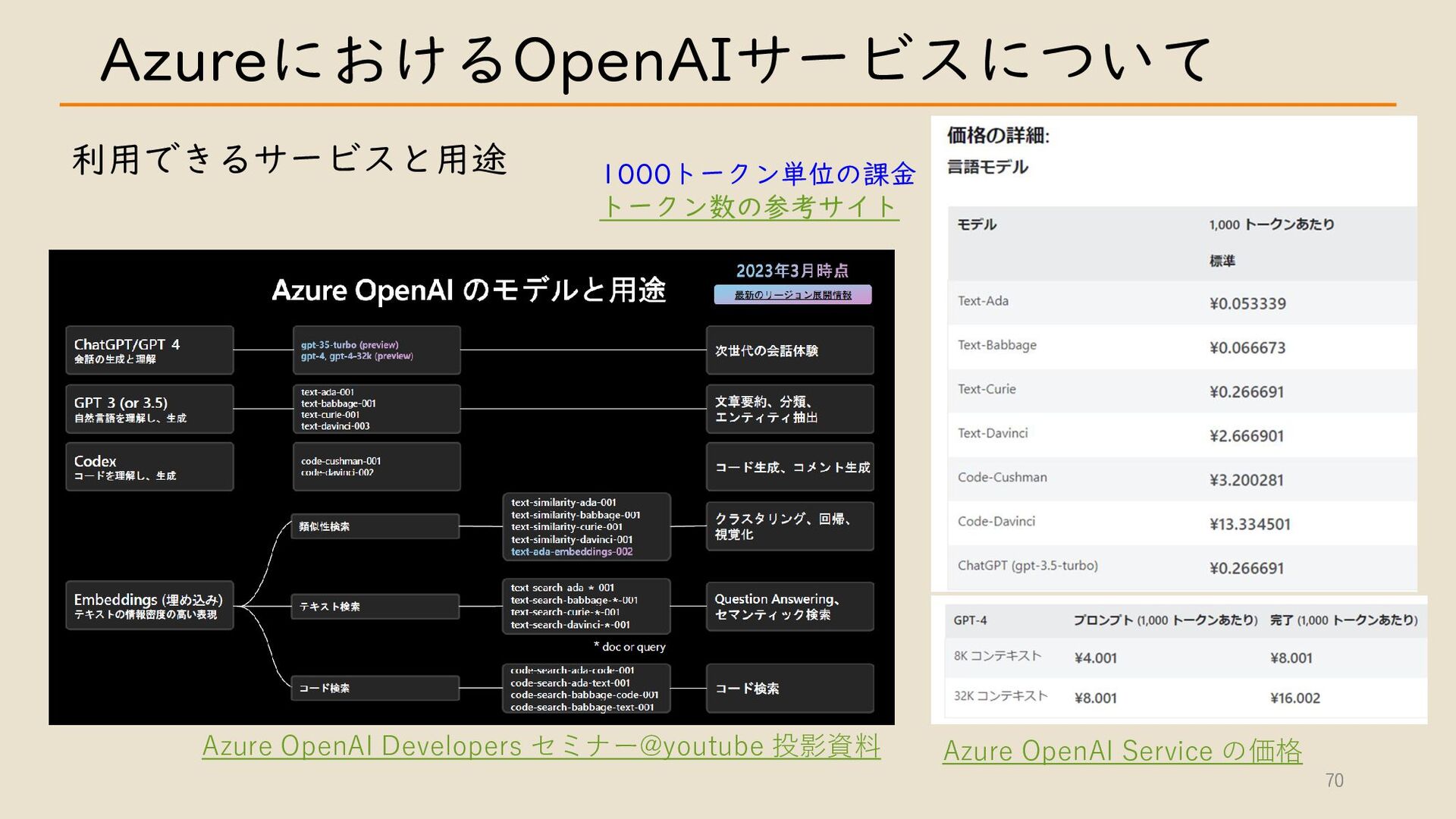
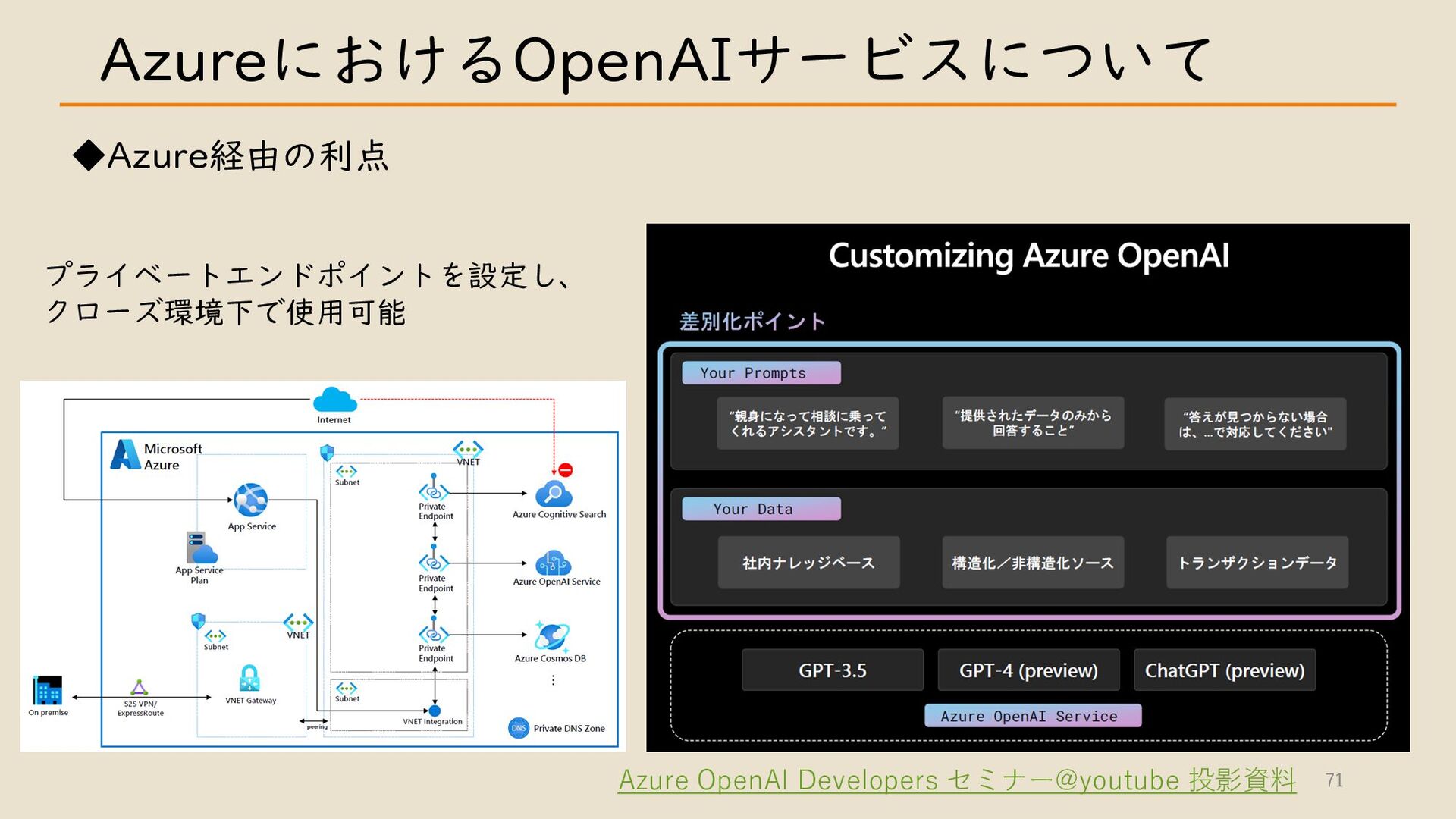
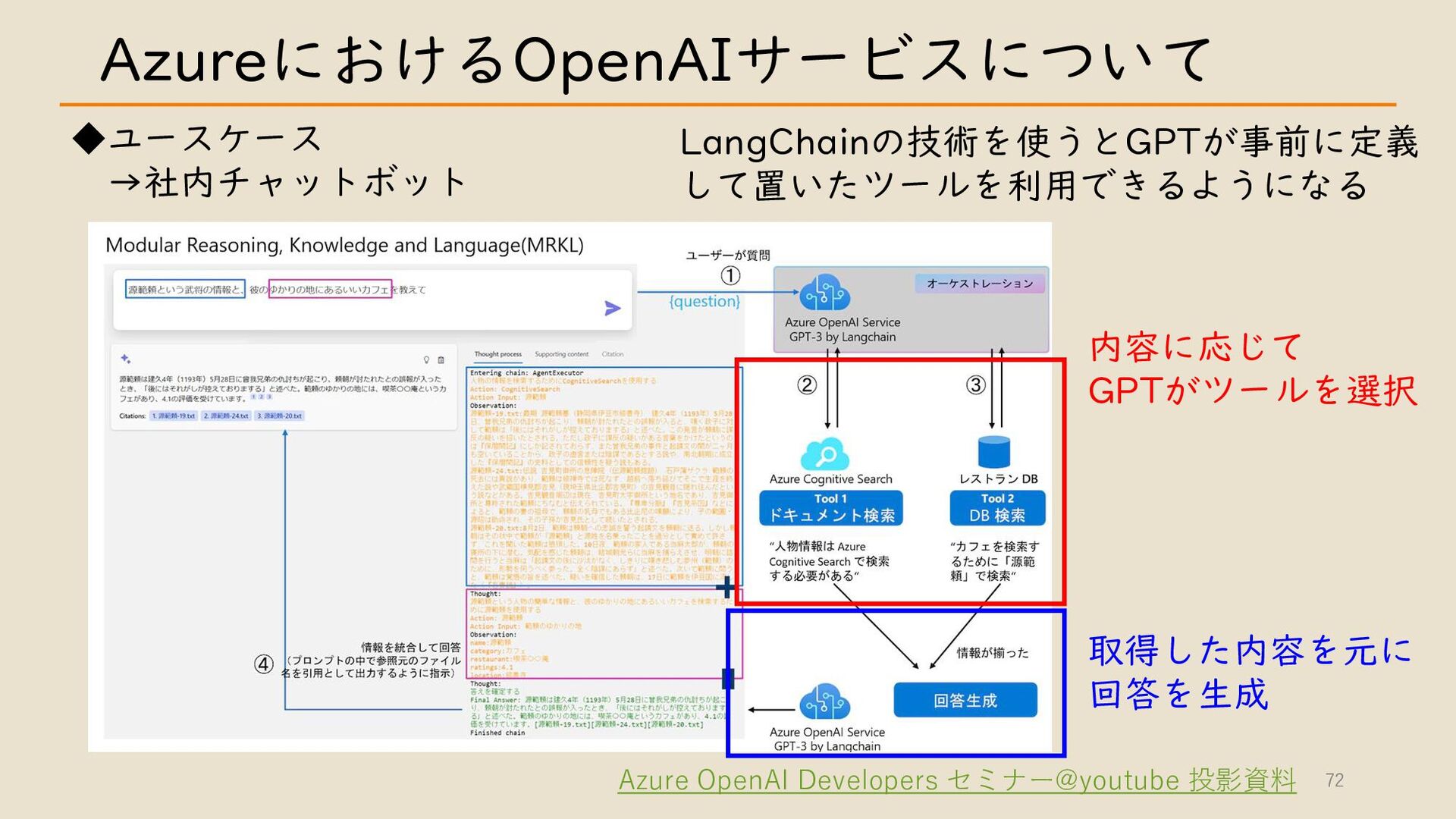
・ Azure における OpenAI サービスについて
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GPTのバージョンアップとスケーリング則について ◆GPT-4 GPT-4 Technical Report [OpenAI arXiv:2303.08774 ]@2023 GPT-3.5のモデルよりも性能向上 特に司法試は上位10%の結果](https://files.speakerdeck.com/presentations/2ba6a9e4a5f743f5a958168856732216/slide_59.jpg){kind=link}
{kind=link}
![GPTのバージョンアップとスケーリング則について ◆GPT-4 GPT-4 Technical Report [OpenAI arXiv:2303.08774 ]@2023 英語以外の言語に関しても GPT-3.5のパフォーマンスを超える](https://files.speakerdeck.com/presentations/2ba6a9e4a5f743f5a958168856732216/slide_61.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}