Share
ACL 2020 オンラインLT会 https://nlpaper-challenge.connpass.com/event/185240/
Knowledge Supports Visual Language Grounding_ A Case Study on Colour Terms
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
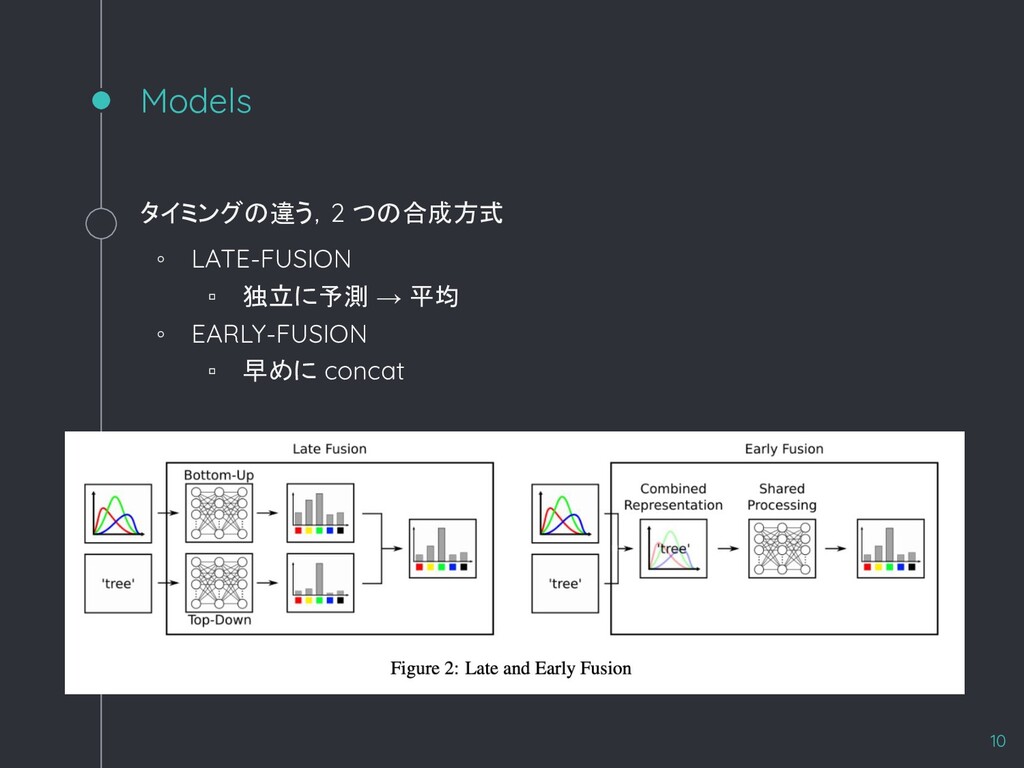{kind=link}
{kind=link}
{kind=link}
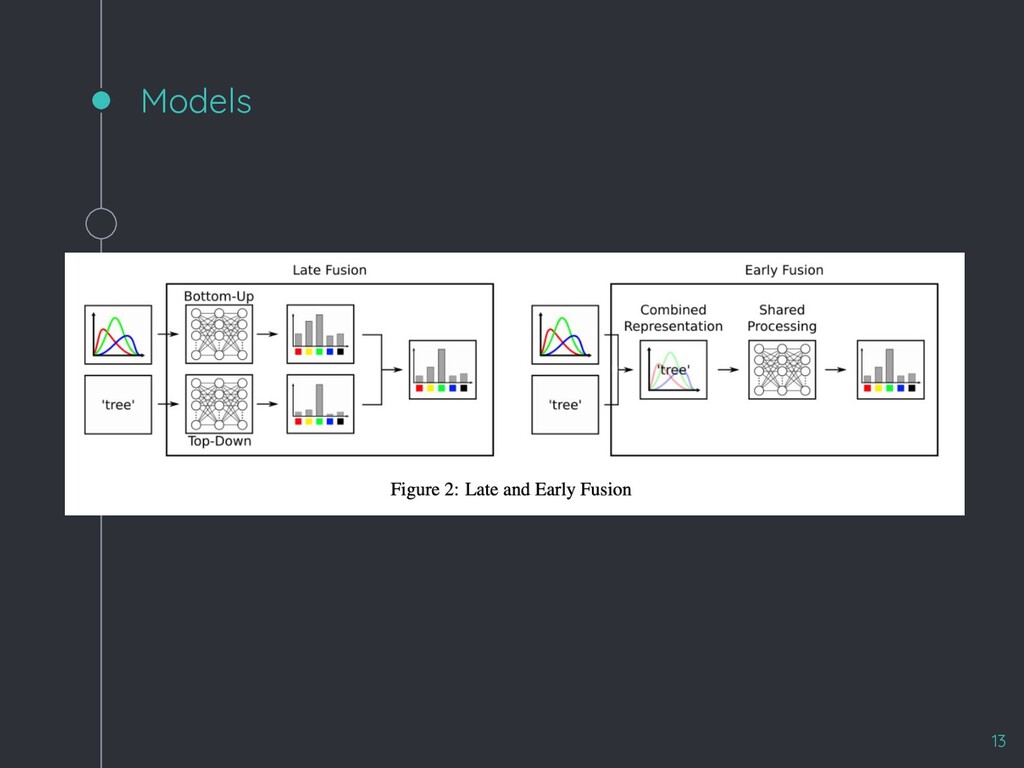{kind=link}
![Experiments Data ◦ VisualGenome [Karishna+ 2016] ◦ (黒,青,茶,灰,緑,橙,桃,紫,赤,白,黄) 色 ◦](https://files.speakerdeck.com/presentations/b4683267723d46b9a448300a7f5696de/slide_13.jpg){kind=link}
{kind=link}
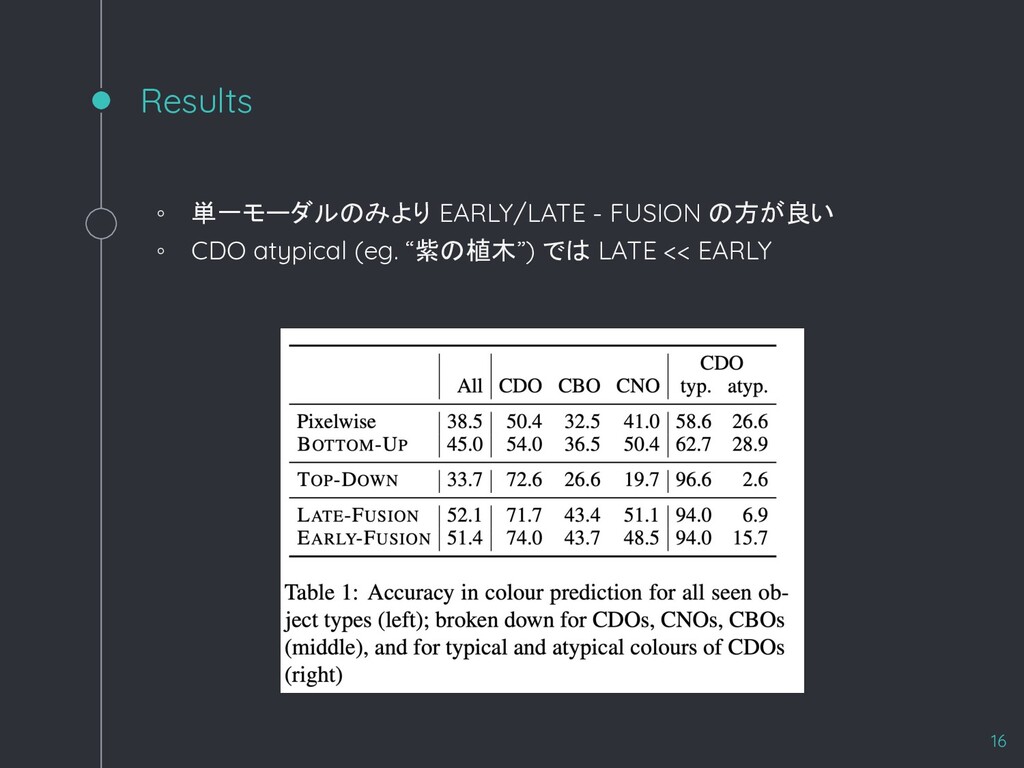{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}