Model Memorization – L2M2 (ACL 2025 workshop) • The Impact of Memorization on Trustworthy Foundation Models – MemFM (ICML 2025 workshop) 暗記 (memorization) への注目 3
✅ 先行研究あり※ • Hirokazu Kiyomaru, et al. A comprehensive analysis of memorization in large language models. In Proc. of the INLG 2024. • 小柳響子ら. LLM の事前学習データ検知法の日英比較. 人工知能学会全国大会論文集 2024.
は高い性能を発揮 • 継続事前学習の設定による影響も調査する必要あり 日本語でのメンバーシップ推論結果の特徴 26 • Weijia Shi, et al. Detecting Pretraining Data from Large Language Models. In Proc. of the ICLR 2024. • Roy Xie, et al. ReCaLL: Membership Inference via Relative Conditional Log-Likelihoods. In Proc. of the EMNLP 2024.
Pre-trained Language Models: A Survey. In Proc. of TrustNLP 2023. • [自然言語処理a] 石原祥太郎ら (2024). 日本語ニュース記事要約支援に向けたドメイン特化事前学習済みモデルの構築 と活用. 自然言語処理, 31巻, 4号. • [記事] 経済情報特化の生成AI、日経が開発 40年分の記事学習 (2024). 日経電子版. • [INLG 2024] Shotaro Ishihara, et al. (2024). Quantifying Memorization and Detecting Training Data of Pre-trained Language Models using Japanese Newspaper. In Proc. of the INLG 2024. • [L2M2 2025] Hiromu Takahashi, et al. (2025). Quantifying Memorization in Continual Pre-training with Japanese General or Industry-Specific Corpora. In Proc. of the L2M2. • [AACL 2022] Shotaro Ishihara, et al. (2022). Semantic Shift Stability: Efficient Way to Detect Performance Degradation of Word Embeddings and Pre-trained Language Models. In Proc. of the AACL-IJCNLP 2022. • [自然言語処理b] 石原祥太郎ら (2024). Semantic Shift Stability: 学習コーパス内の単語の意味変化を用いた事前学習 済みモデルの時系列性能劣化の監査. 自然言語処理, 31巻, 4号. • [人工知能学会全国大会2025] 石原祥太郎 (2025). 生成的推薦の人気バイアスの分析:暗記の観点から. 2025年度人工 知能学会全国大会(第39回)論文集. 紹介した発表文献 29
![日本語新聞記事を用いた 大規模言語モデルの暗記定量化 石原祥太郎 [email protected] 日本経済新聞社 日経イノベーション・ラボ 上級研究員 第 22 回](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![日経電子版などの記事を用いた事前学習済みモデル開発 • 訓練データの文体の模倣:日経電子版 T5 での要約の生成 [自然言語処理a] • 識別タスクの性能改善:日経電子版 BERT での記事カテゴ](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_7.jpg){kind=link}
![サーベイ論文の執筆 [TrustNLP 2023] • 著作権:続きの生成やメンバーシップ推論 [INLG 2024] [L2M2 2025] •](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_8.jpg){kind=link}
![大規模言語モデルの暗記に関する課題のうち,生成の類似性 や訓練データのメンバーシップ推論に焦点を当て事例を紹介 • 著作権:続きの生成やメンバーシップ推論 [INLG 2024] [L2M2 2025] • 健全な性能評価:訓練データの違いによる時系列性能劣化](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![エポック (重複) の増加で,暗記が増加 19 日経電子版を用 いた,フルスク ラッチ事前学習 の設定 [INLG 2024]](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_18.jpg){kind=link}
![モデルサイズが大きいほど,暗記が増加 20 フルスクラッチ 事前学習された 一般的なモデル を比較 [INLG 2024]](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_19.jpg){kind=link}
![日経電子版を用いた,フルスクラッチ事前学習の設定での メンバーシップ推論の性能 (AUC) [INLG 2024] エポック数やプロンプト長に沿って,暗記が増加 21](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_20.jpg){kind=link}
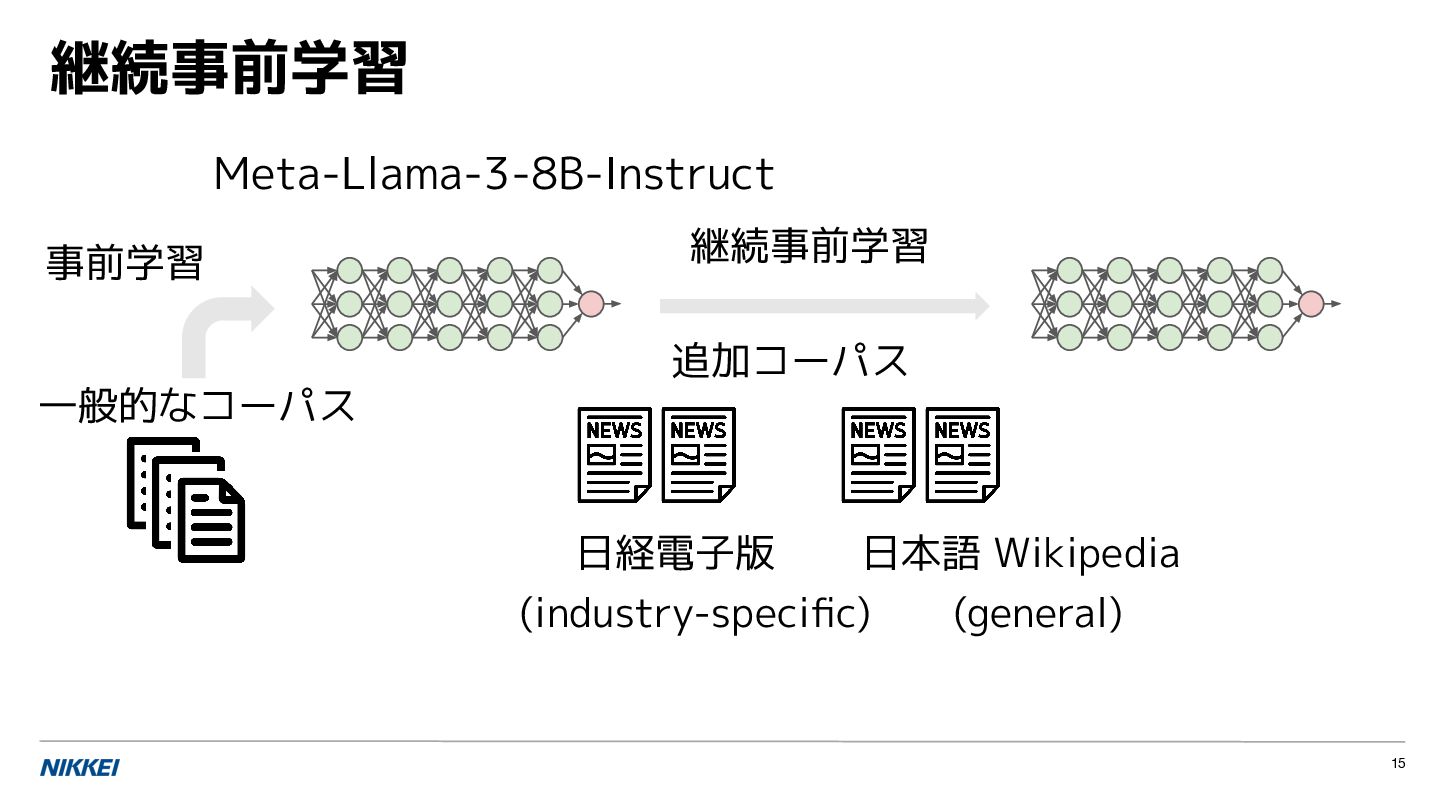
![ドメイン特化のコーパスほど,急速に暗記される 22 日経電子版を用 いた,継続事前 学習の設定 [L2M2 2025] Wikipedia では ほぼ変化なし](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_21.jpg){kind=link}
![継続事前学習の設定 [L2M2 2025] ドメイン特化のコーパスほど,検知されやすい 23](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_22.jpg){kind=link}
![継続事前学習の設定 [L2M2 2025] トークンを絞る Min-K% Prob より LOSS が機能 24](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_23.jpg){kind=link}
![継続事前学習の設定 [L2M2 2025] エポック数やプロンプト長と必ずしも相関せず 25](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
![大規模言語モデルの暗記に関する課題のうち,生成の類似性 や訓練データのメンバーシップ推論に焦点を当て事例を紹介 • 著作権:続きの生成やメンバーシップ推論 [INLG 2024] [L2M2 2025] • 健全な性能評価:訓練データの違いによる時系列性能劣化](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_27.jpg){kind=link}
![• [TrustNLP 2023] Shotaro Ishihara (2023). Training Data Extraction From](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_28.jpg){kind=link}
![付録:その他の研究の概要 30 • 訓練データの文体の模倣:日経電子版 T5 での要約の生成 [自然言語処理a] • 健全な性能評価:訓練データの違いによる時系列性能劣化 の分析と監査](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_29.jpg){kind=link}
![日経電子版 T5 は編集者の見出し・3 行まとめとの一致度合い で,GPT 3.5 などと比較して高い性能 [自然言語処理a] 訓練データの文体の模倣 31](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_30.jpg){kind=link}
![• 訓練データの文体の模倣:日経電子版 T5 での要約の生成 [自然言語処理a] • 健全な性能評価:訓練データの違いによる時系列性能劣化 の分析と監査 [AACL 2022]](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_31.jpg){kind=link}
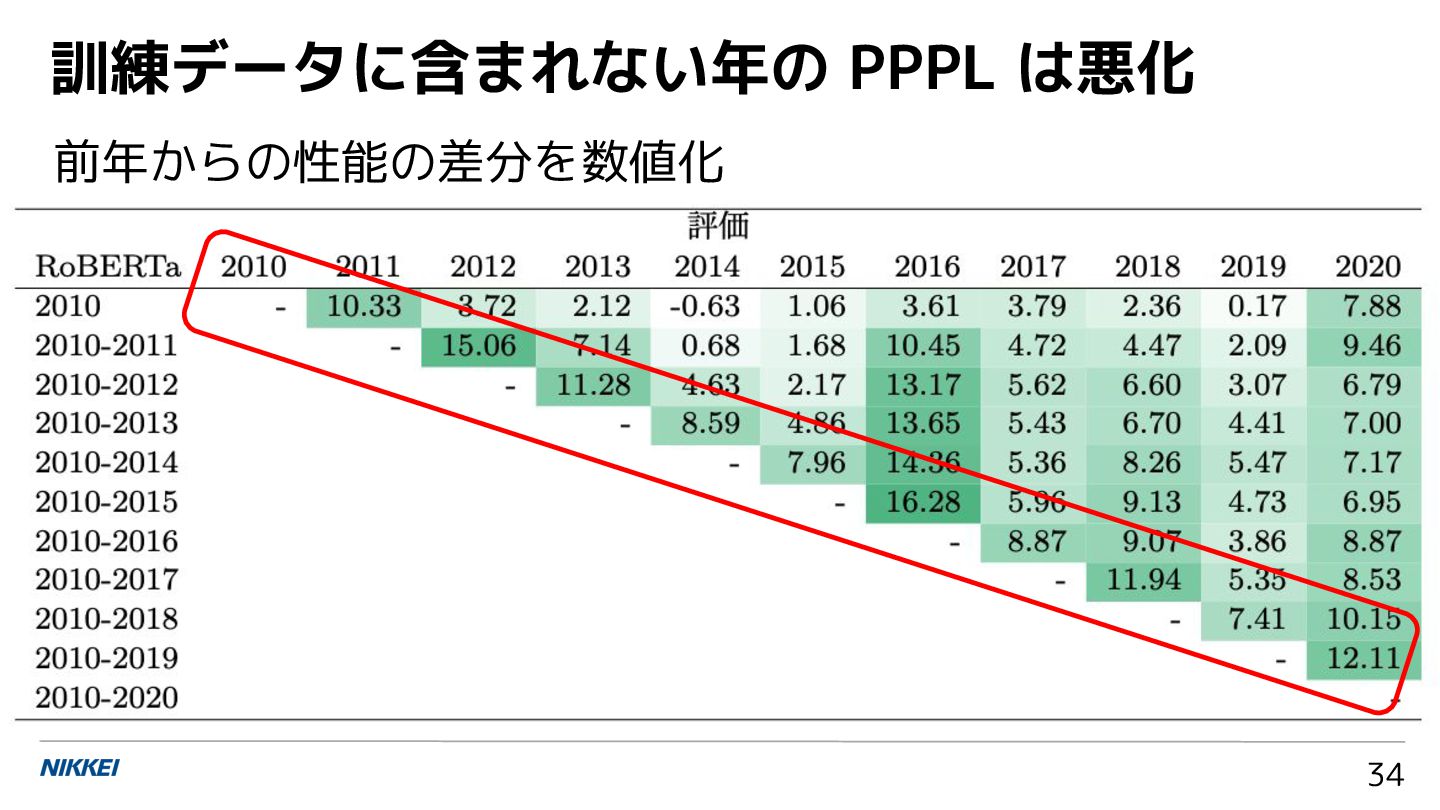
![2010〜2021 年まで,1 年ずつ学習コーパスを増やしながら 12 の RoBERTa を構築 [AACL 2022] [自然言語処理b]](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_32.jpg){kind=link}
{kind=link}
![付録:その他の研究の概要 35 • 訓練データの文体の模倣:日経電子版 T5 での要約の生成 [自然言語処理a] • 健全な性能評価:訓練データの違いによる時系列性能劣化 の分析と監査](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_34.jpg){kind=link}
![暗記の研究の応用可能性 [人工知能学会全国大会2025] • Llama 3 をニュース閲覧履歴でファインチューニングした モデルの生成結果を用い,訓練データ内の文字列の重複数 ・暗記・人気バイアスの関係性を分析した. • 文字列の重複数の偏りがある場合,暗記を介して生成数も](https://files.speakerdeck.com/presentations/3813f4b9e4af4f328a96f2fdb9484bd8/slide_35.jpg){kind=link}