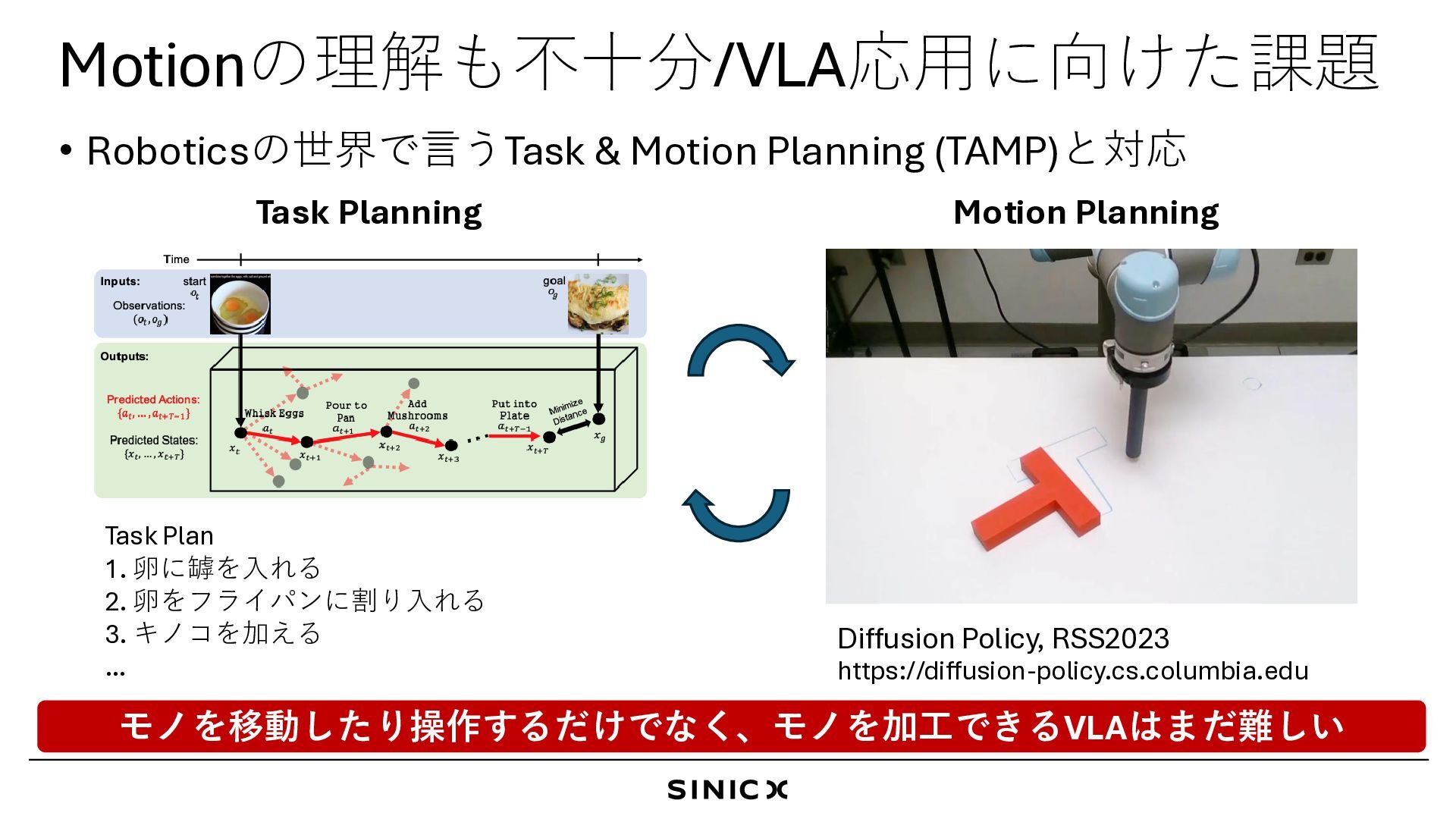
for Robot Task Planning”, ICRA2024 J. Siburian, K. Shirai et al., “Grounded Vision-Language Interpreter for Integrated Task and Motion Planning”, CoRL2025 Workshop 課題: Motion Plannerは 作り込みが必要
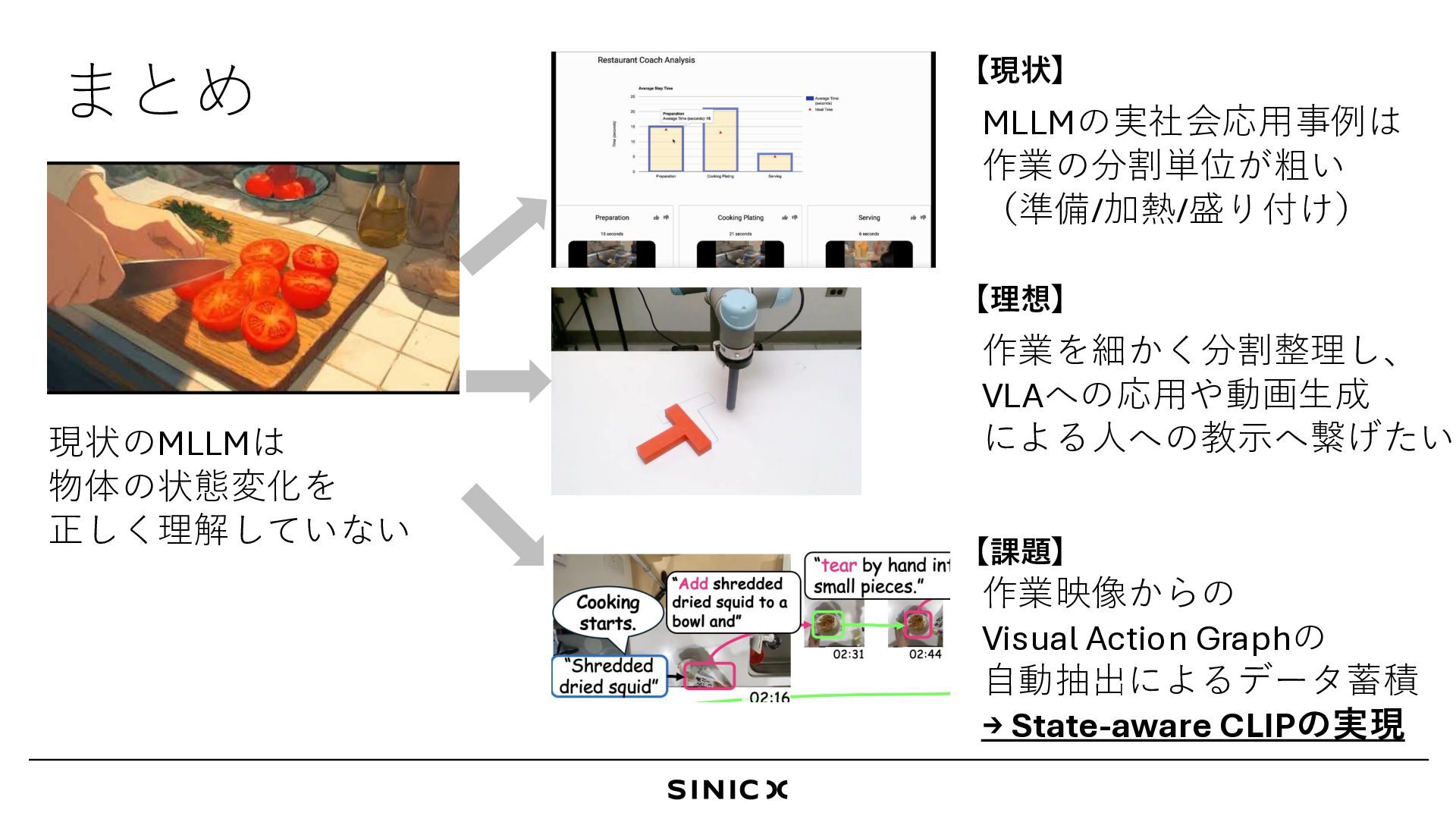
31 “Shredded dried squid” “Kimchi” “tear by hand into small pieces.” “Cut kimchi with scissors,” “add to the squid, and” 02:31 02:44 05:14 07:02 08:09 08:10 09:44 “mix.” “white sesame” 10:00 10:16 10:23 10:29 10:41 10:45 11:42 12:03 “Add shredded dried squid to a bowl and” “top with white sesame.” Before After Dest. “Ingredient” Graph Structure “Action” “Brown sugar” 02:16 “Add brown sugar,” “mix, and” Ready to eat! Cooking starts. [ours] K. Maeda & T. Hirasawa, “COM Kitchens: An Unedited Overhead-view Video Dataset as a Vision-Language Benchmark”, ECCV2024 VAGは動画をHOI単位のTask/Motionに分割→自動抽出によるデータ収集が鍵になる?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MLLMの作業理解ベンチマーキング[ours] S. Takashige et al., “Benchmarking MLLMs on Mistake Recognition](https://files.speakerdeck.com/presentations/85d699efed354ee38351205aa9918c1e/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Multimodal Procedural Planning [ECCV 2020] [ECCV 2020] CY Chang et](https://files.speakerdeck.com/presentations/85d699efed354ee38351205aa9918c1e/slide_21.jpg){kind=link}
![VG-TVP [AAAI2025] / 手順書と動画をペアで生成 課題: 生成動画の質 [AAAI2025] MF. Ilaslan et](https://files.speakerdeck.com/presentations/85d699efed354ee38351205aa9918c1e/slide_22.jpg){kind=link}
{kind=link}
![ViLaIn / ViLaIn-TAMP [ours] K. Shirai et al., “Vision-Language Interpreter](https://files.speakerdeck.com/presentations/85d699efed354ee38351205aa9918c1e/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![COM Kitchens Dataset [ours] Visual Action Graph を145本の動画に付与 (計40時間, 84家庭のキッチン).](https://files.speakerdeck.com/presentations/85d699efed354ee38351205aa9918c1e/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}