MySQL9でのベクトルカラム/ベクトル検索サポートは、PHPアプリケーションにおけるAI活用や類似性検索を大きく変える可能性を秘めています。
プロポーザル提出時は、AWSのRDSで取り扱い可能なバージョンは、8系が最新ですが、特にAWS (RDS/Aurora) 環境での利用が現実味を帯びる中、そのインパクトは計り知れません。
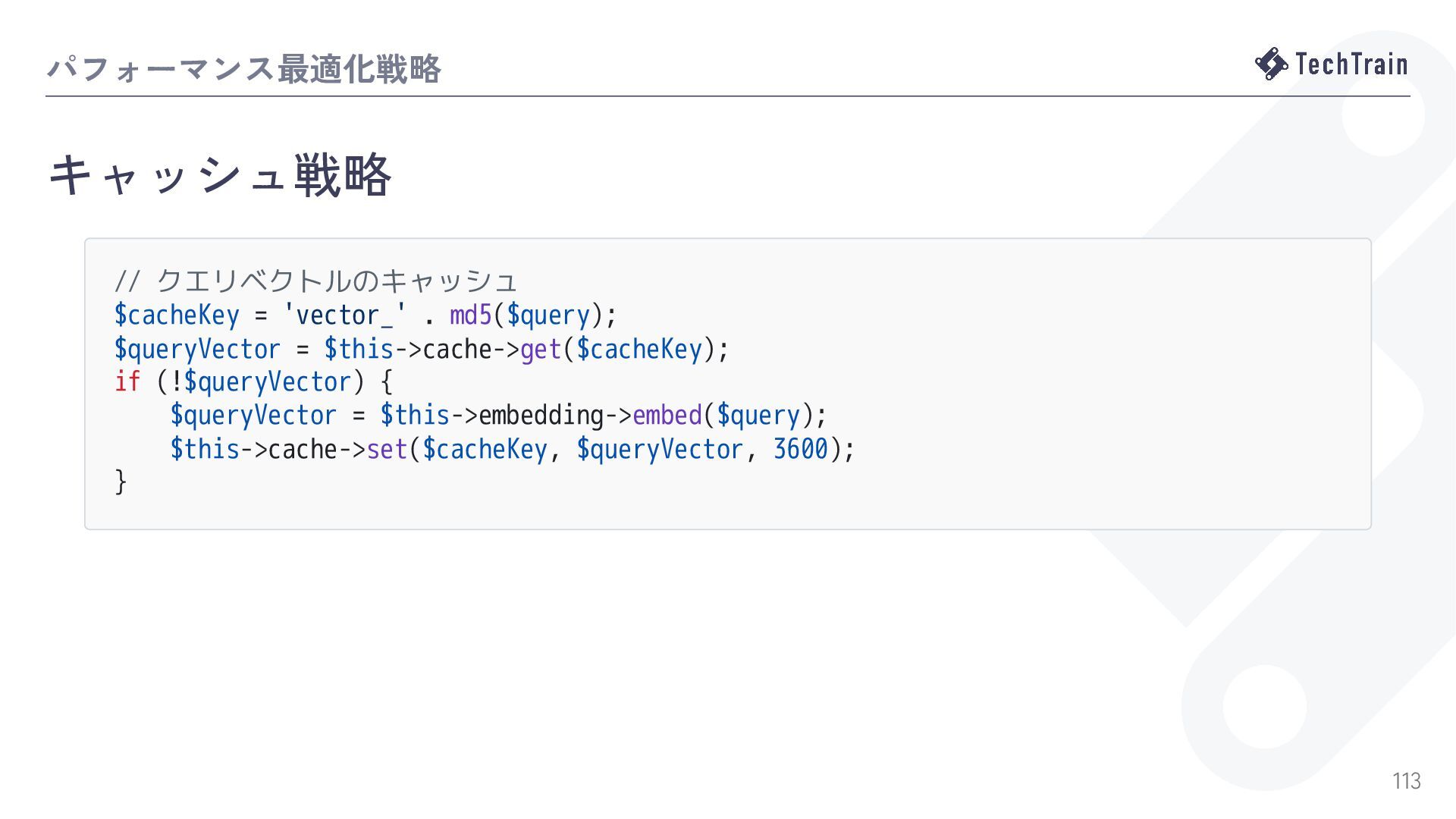
本セッションは、ミドルレベルのPHPエンジニアを対象に、この「ベクトルカラム」導入に焦点を絞ります。ベクトルデータの基本的な概念から、MySQL9で予想されるベクトル型・専用インデックス・検索関数の概要、そしてPHPからこれらをどう扱うか、パフォーマンス考慮点、AWS環境特有の設定や制約についてを説明します。推薦システム、画像検索、セマンティック検索といった機能の実装がどう変化するのか?何を学び、どう備えるべきか? 未来のキラー機能開発に向けた勘所をお伝えします。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
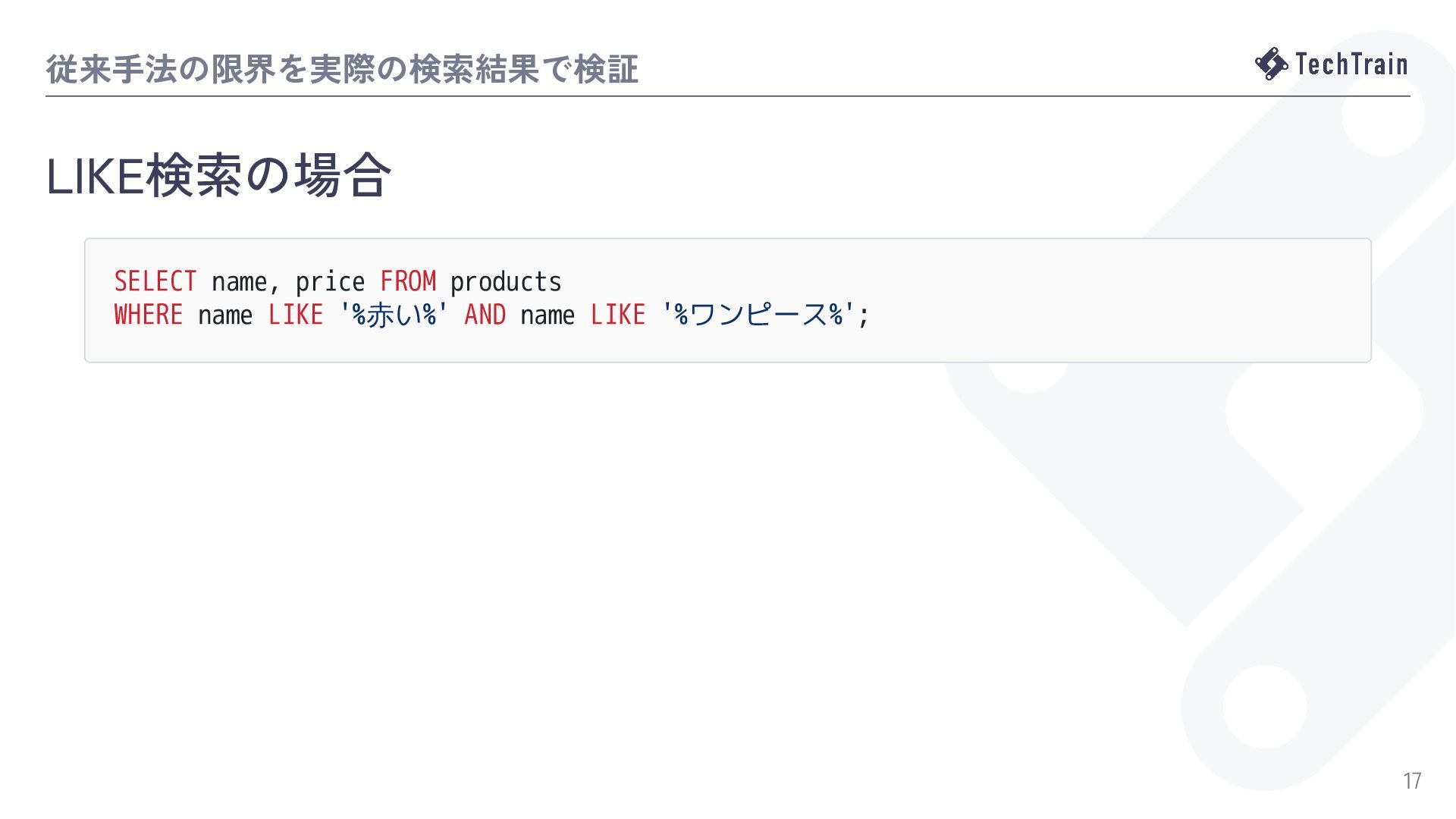{kind=link}
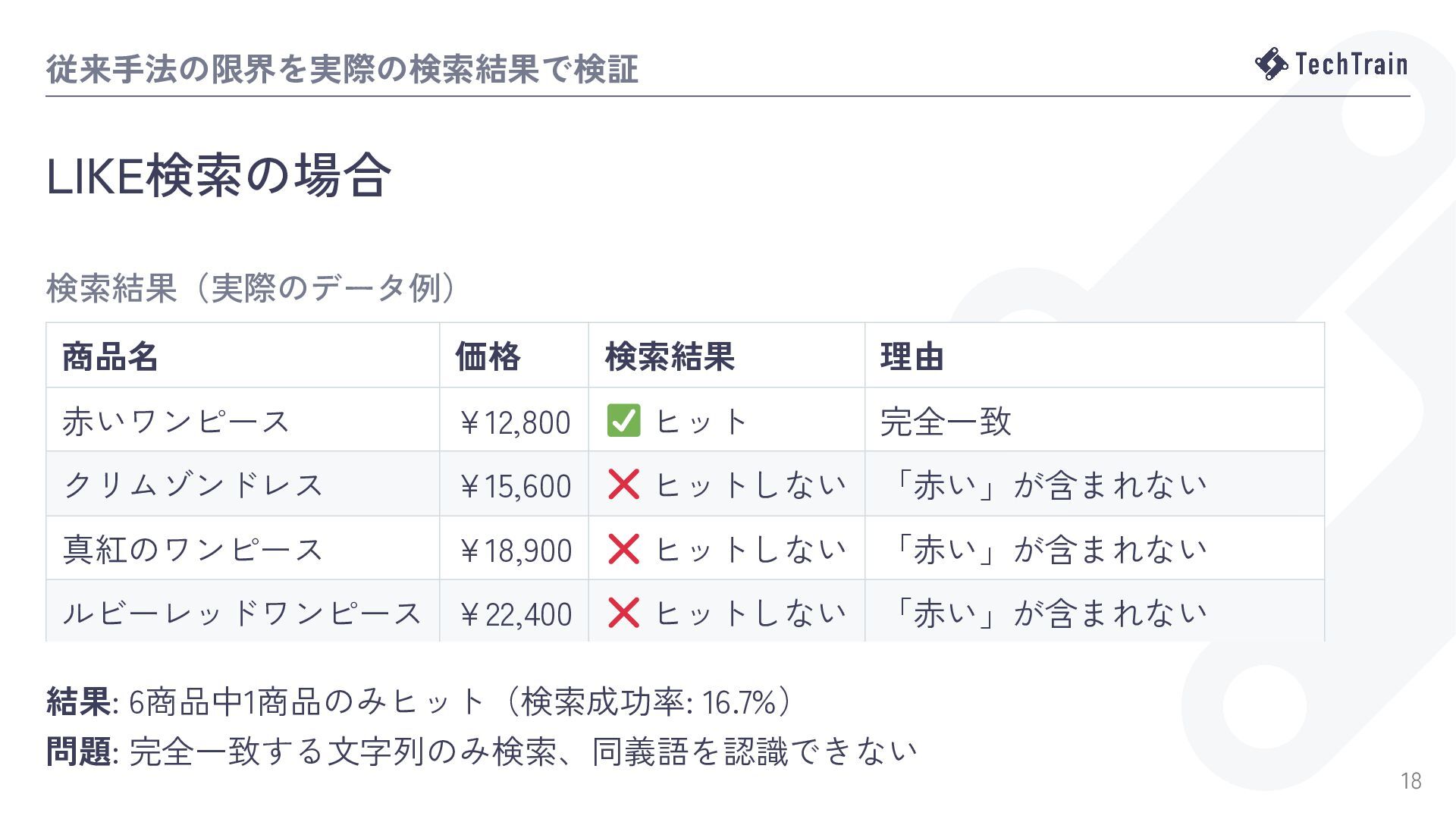{kind=link}
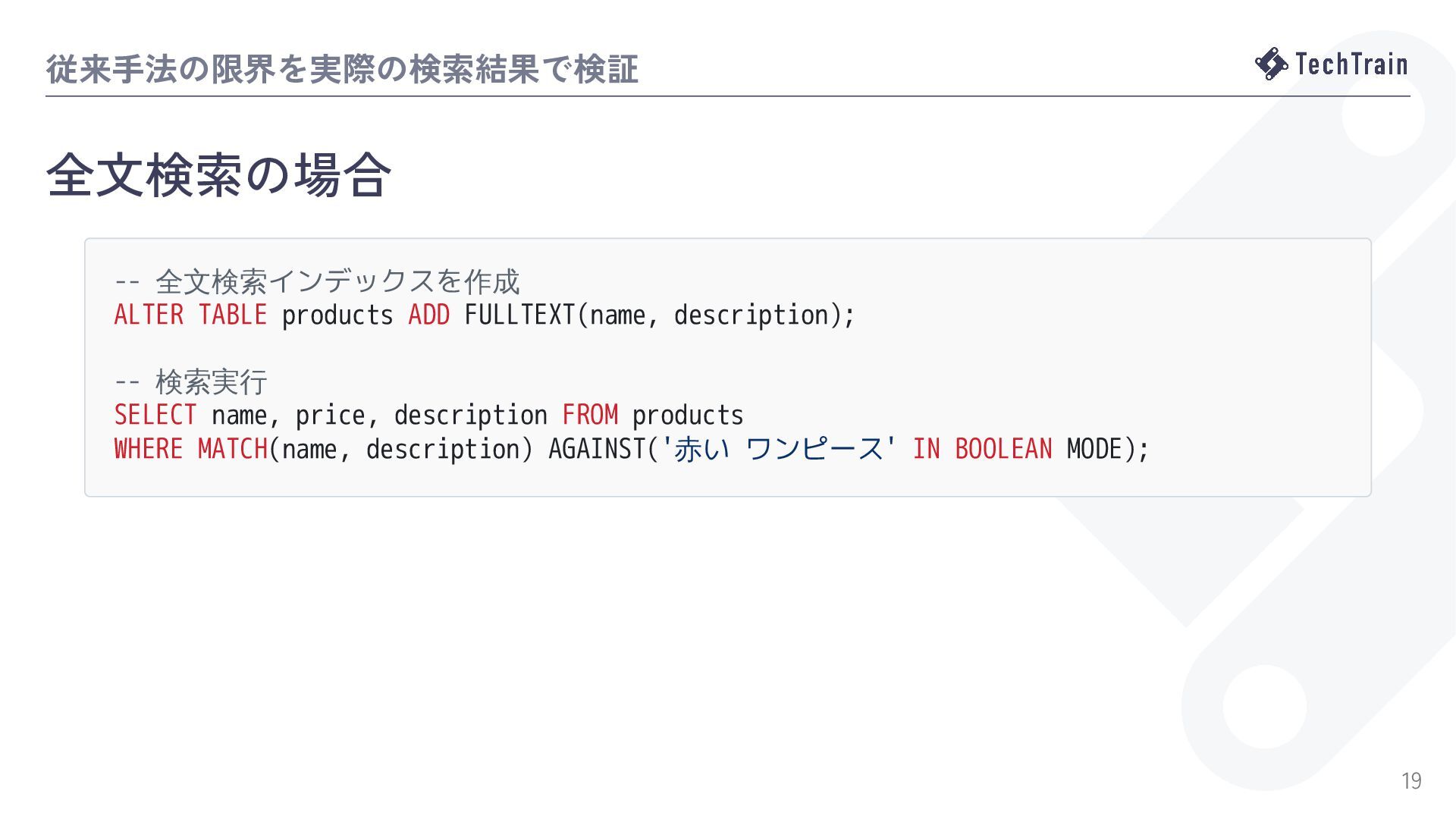{kind=link}
{kind=link}
{kind=link}
{kind=link}
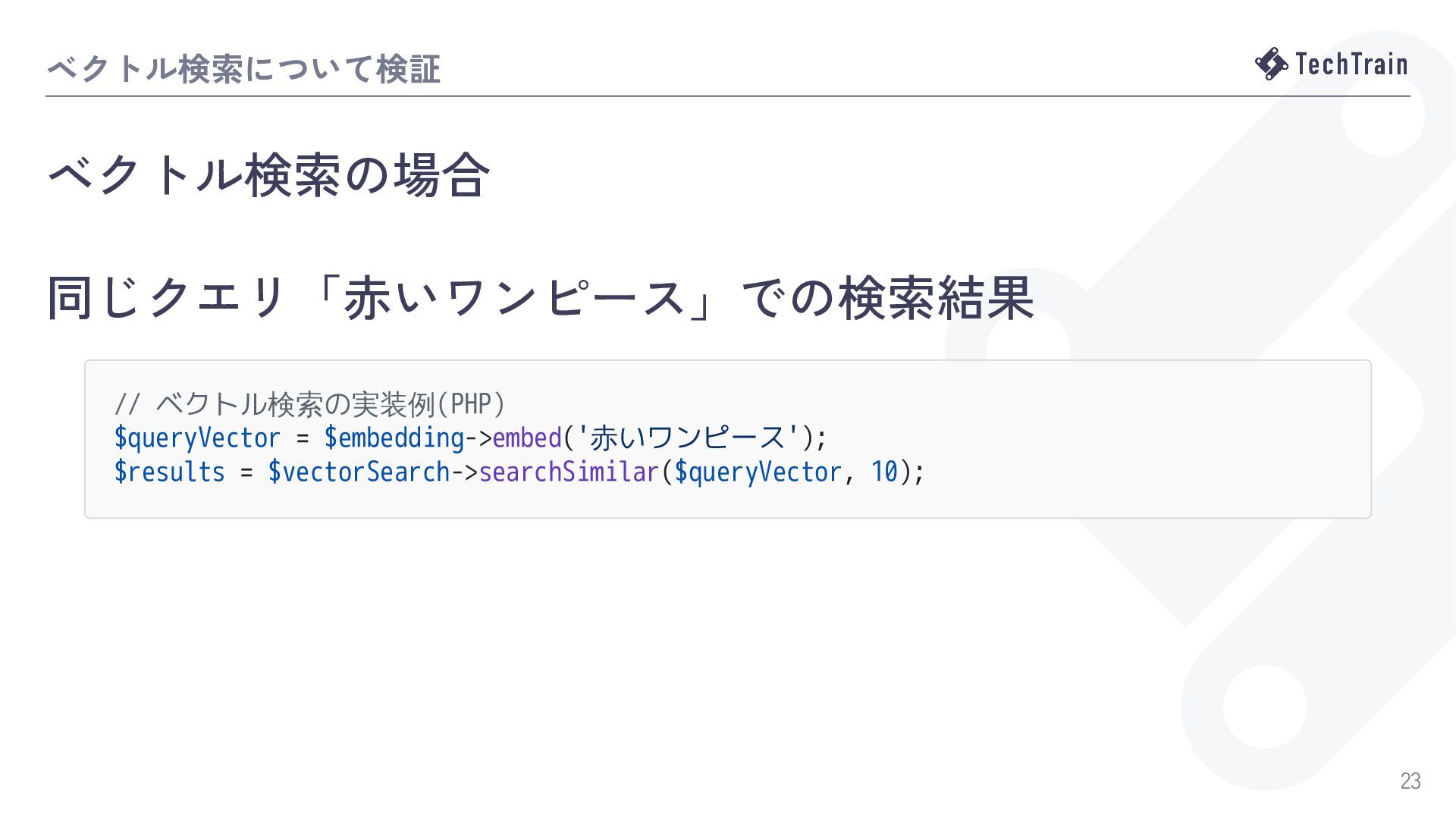{kind=link}
{kind=link}
{kind=link}
![[結果] ユーザーの期待に応えられない検索体験 体験的にベクトルカラムがあった方が良い 26](https://files.speakerdeck.com/presentations/53a075dd091a41a79c0a0a827af78585/slide_25.jpg){kind=link}
{kind=link}
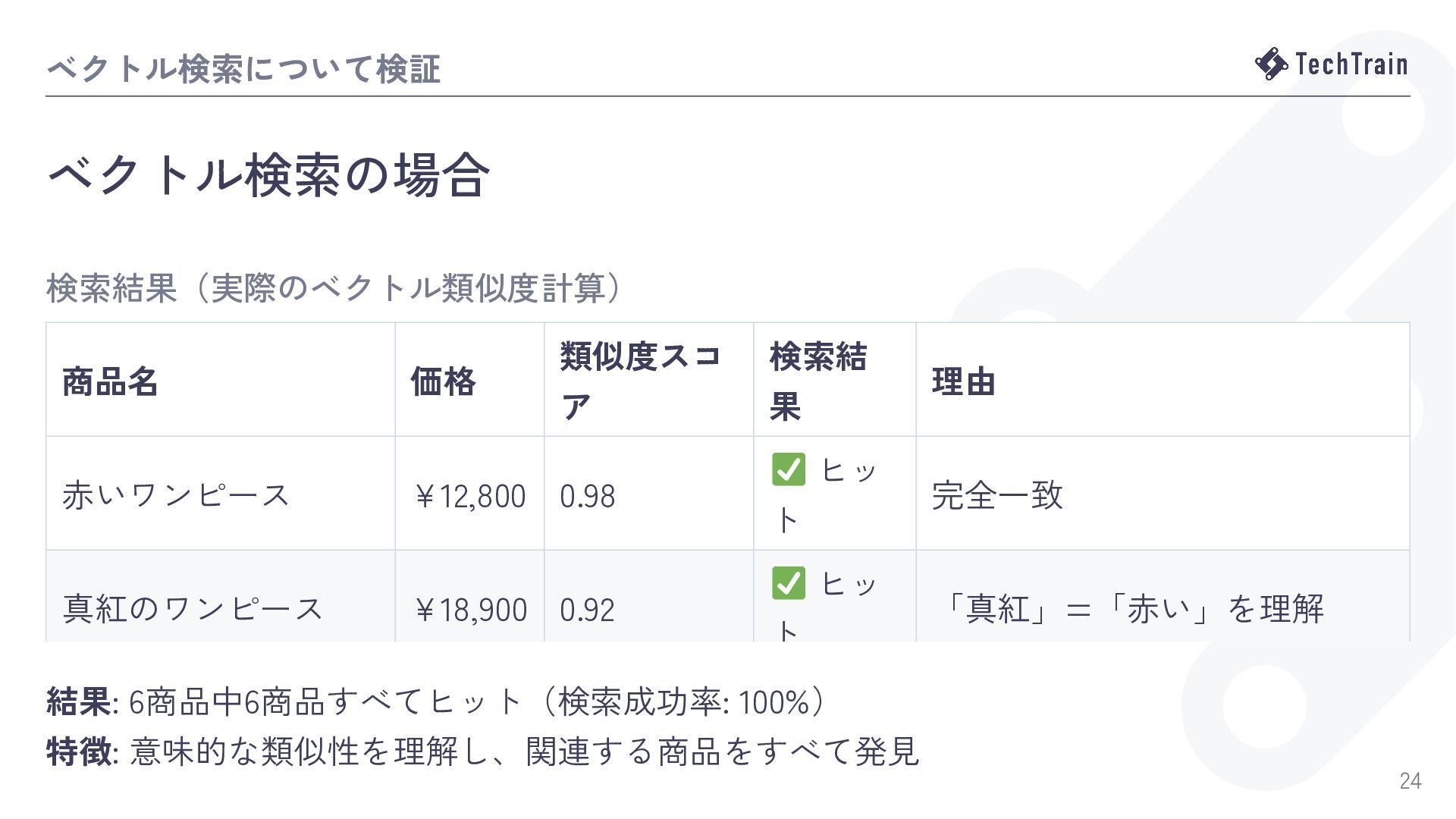
![[検索の場合] 離脱リスクの課題を解決する1つの方法が ベクトル検索 28](https://files.speakerdeck.com/presentations/53a075dd091a41a79c0a0a827af78585/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
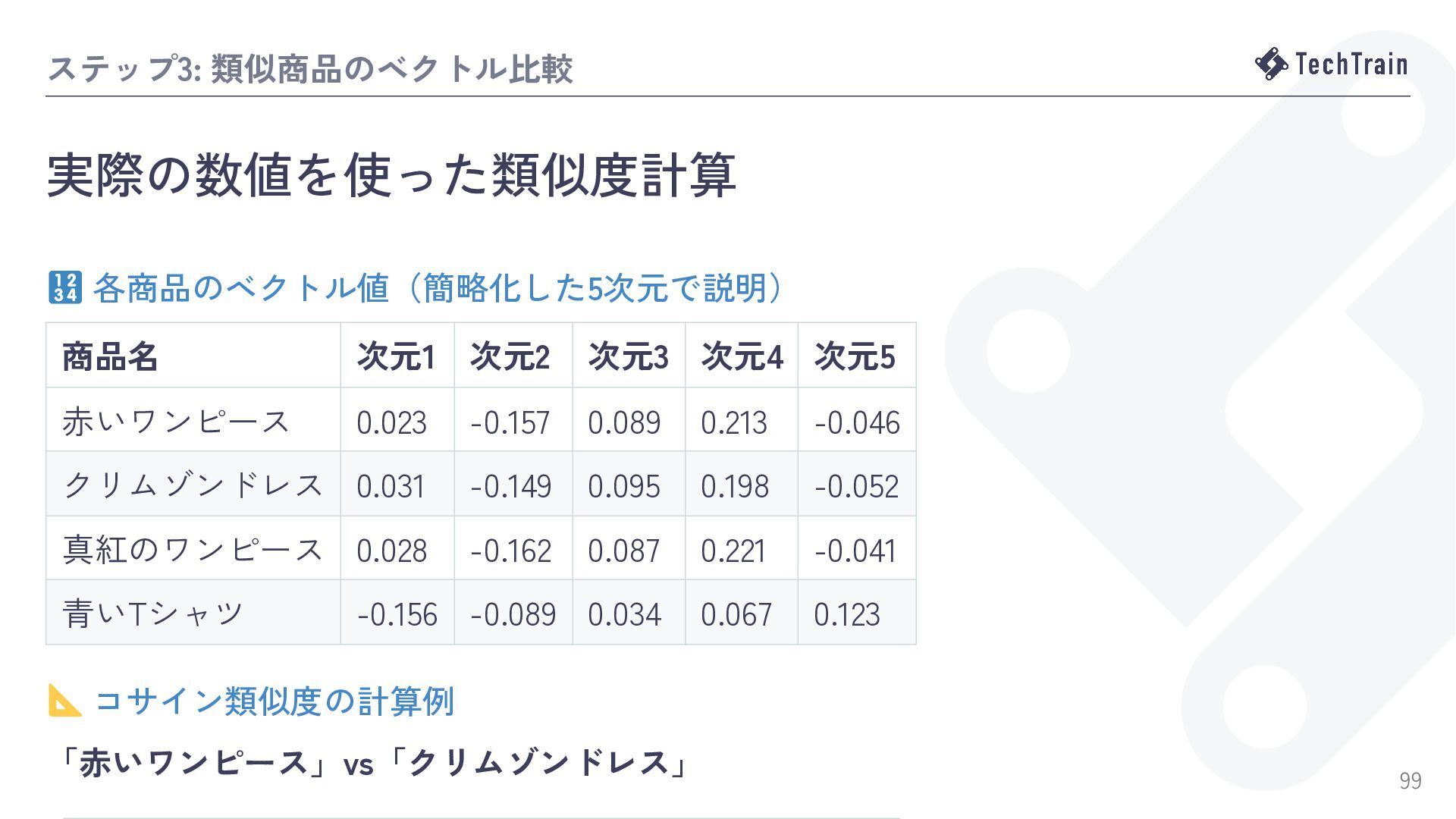
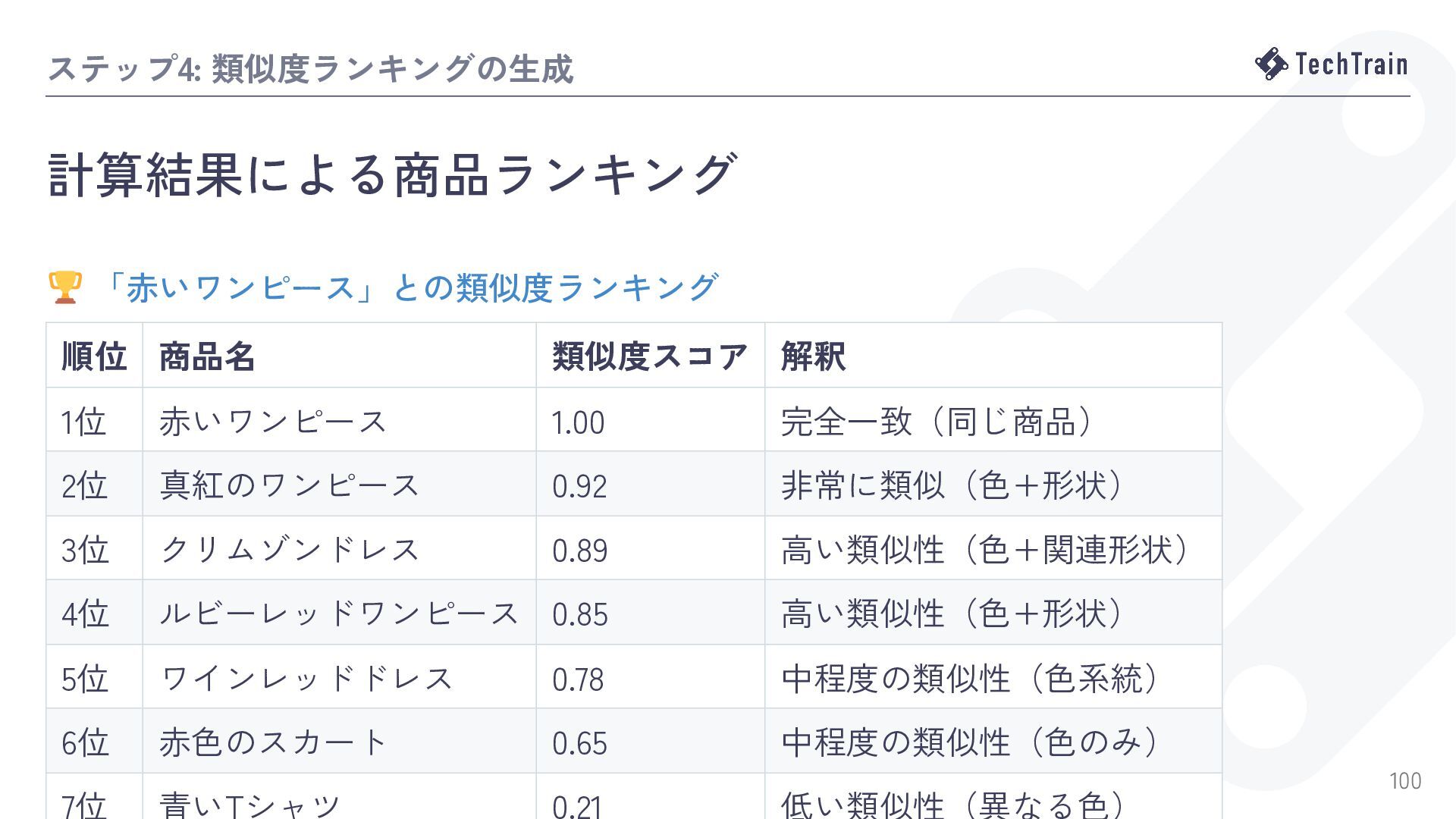
![類似度検索実装(PHPで計算) 2. コサイン類似度の計算とソート // 3. コサイン類似度計算 $similarities = []; foreach](https://files.speakerdeck.com/presentations/53a075dd091a41a79c0a0a827af78585/slide_54.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
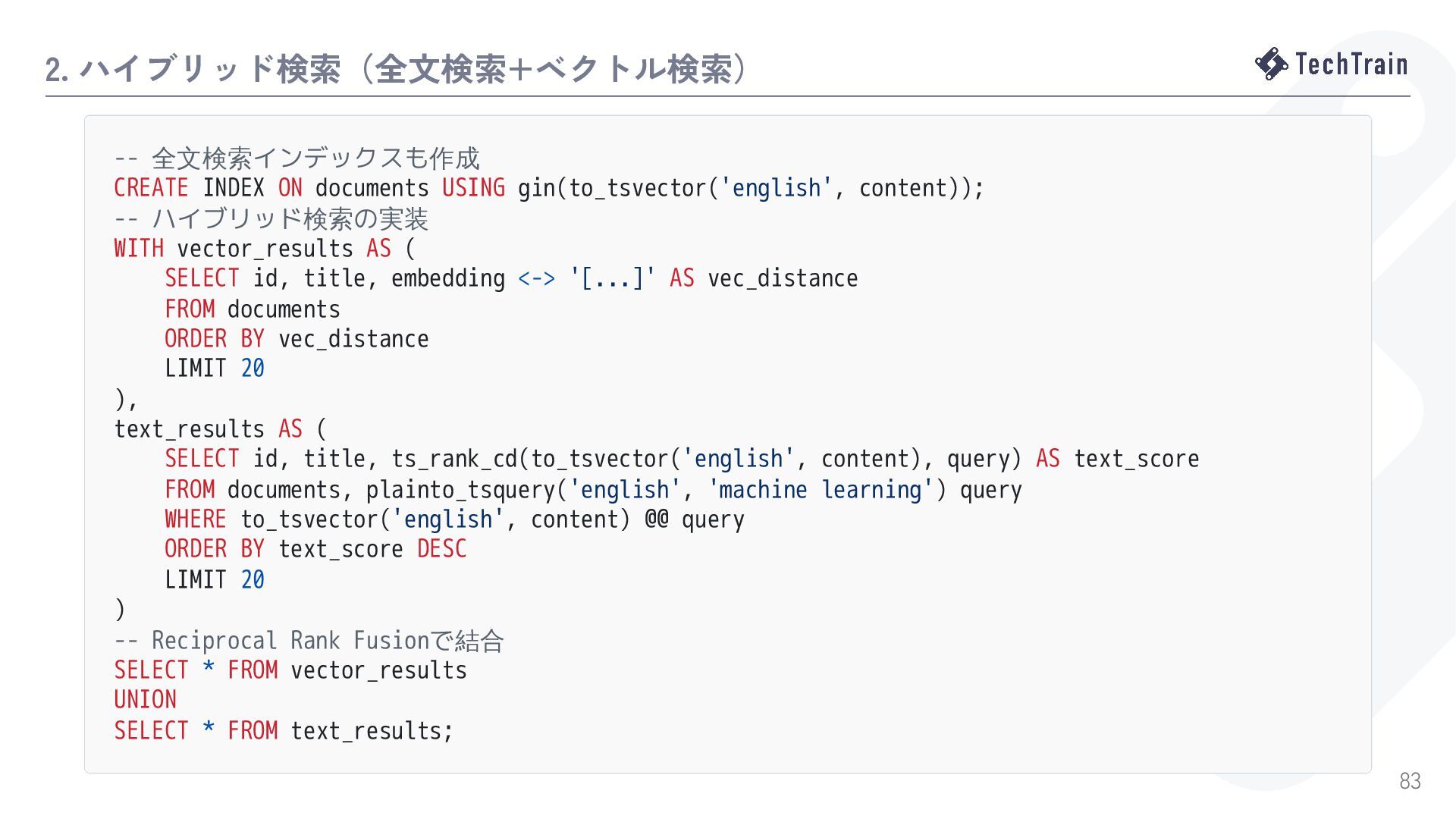{kind=link}
{kind=link}
{kind=link}
{kind=link}
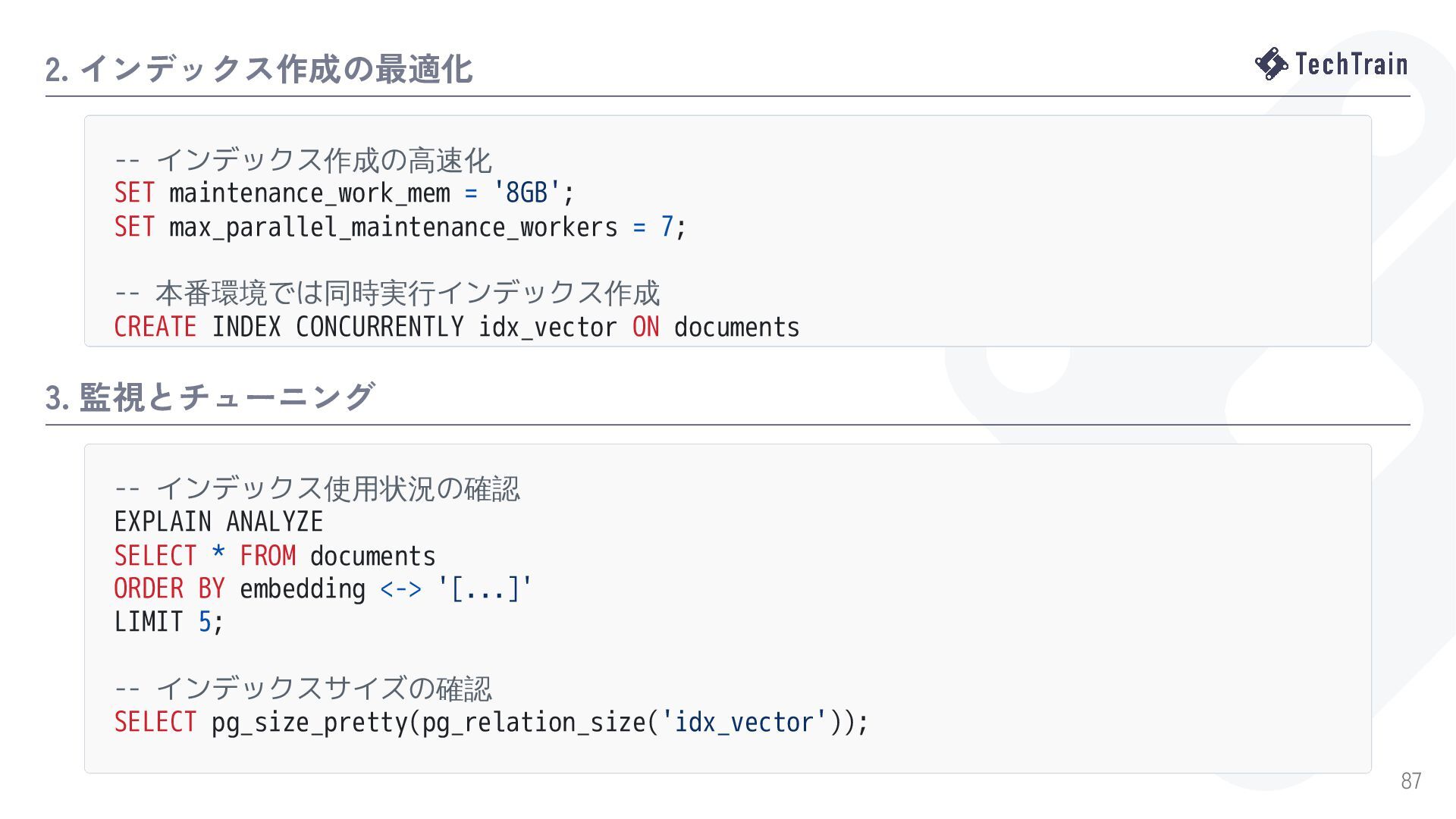{kind=link}
{kind=link}
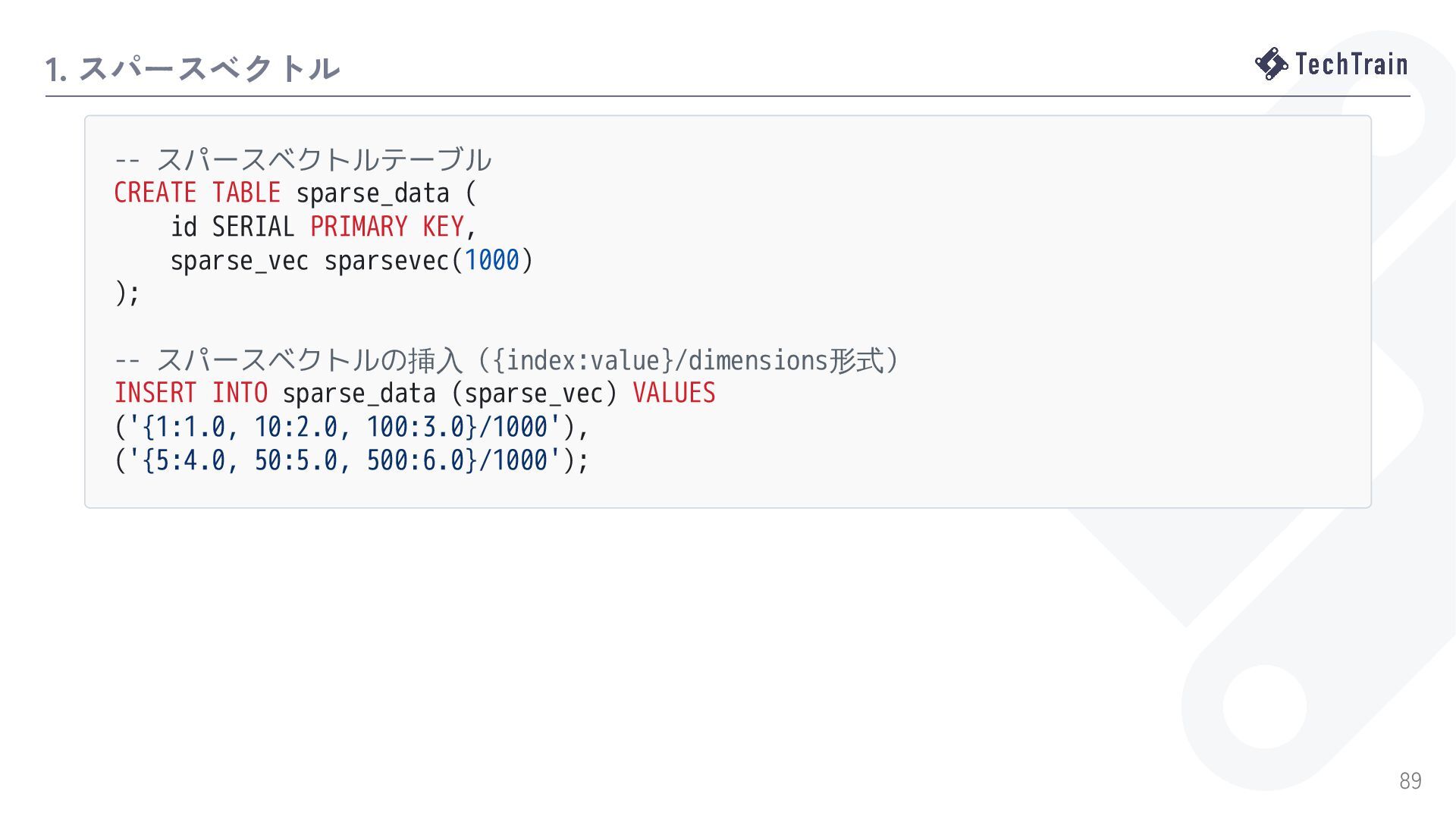{kind=link}
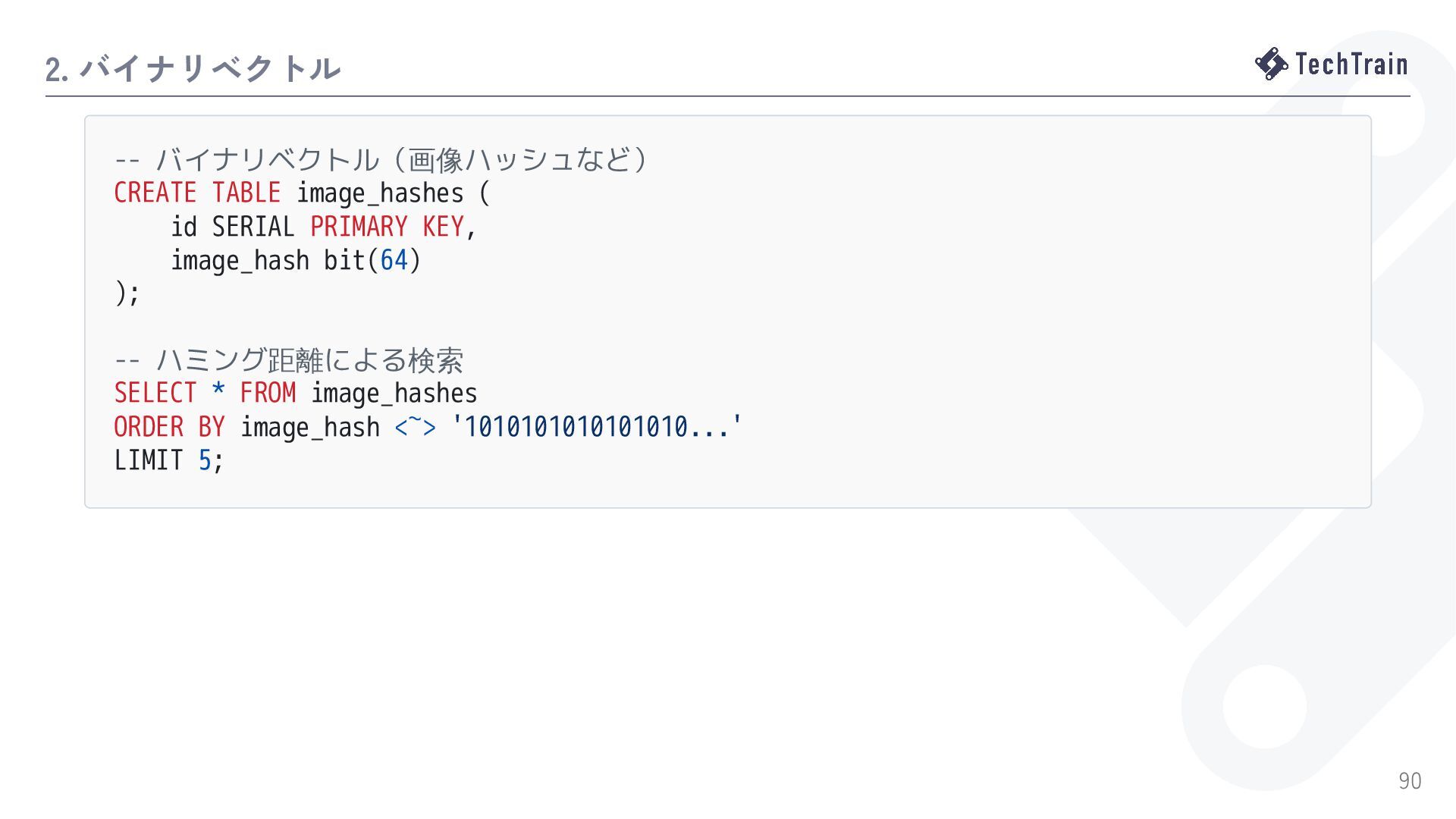{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
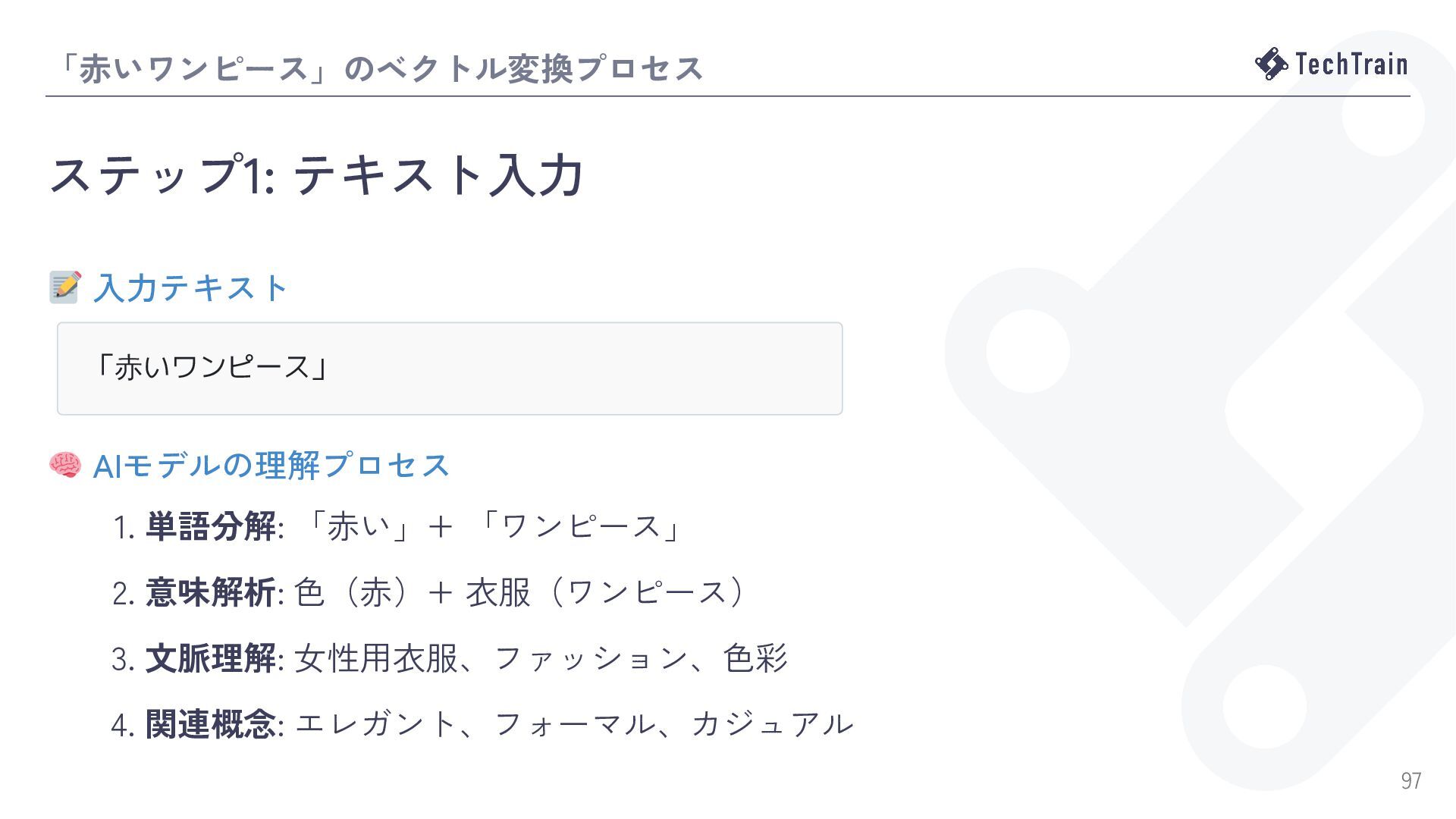
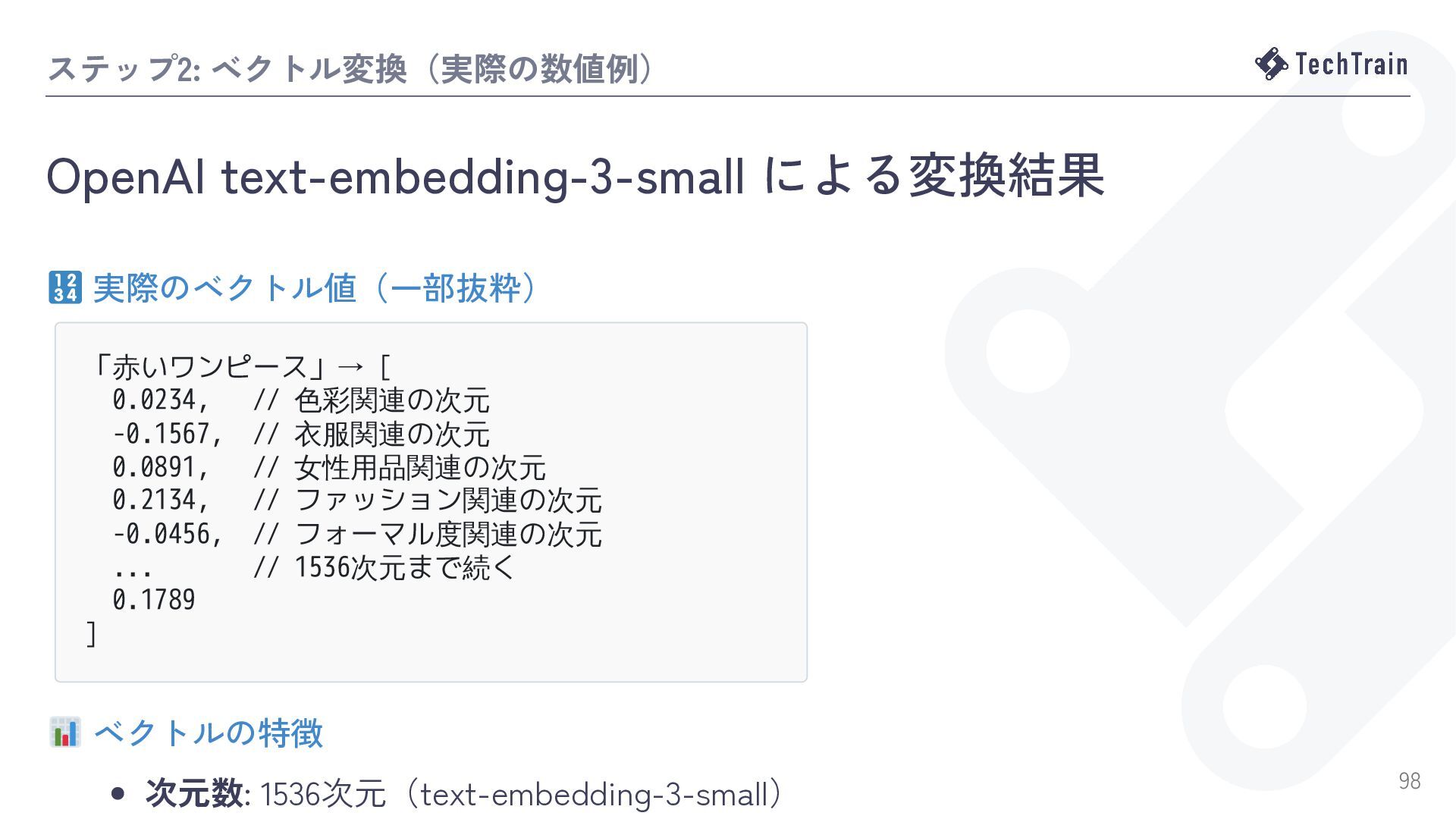
![テキストをベクトルに変換するとは? Embeddingの概念 Embedding(埋め込み) とは、テキストを多次元の数値ベクトルに変換する技術 「赤いワンピース」→ [0.1, -0.5, 0.3, ..., 0.2]](https://files.speakerdeck.com/presentations/53a075dd091a41a79c0a0a827af78585/slide_95.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![バッチ処理で効率化 なぜバッチ処理が重要? 単一リクエスト方式の問題点 graph LR A[商品1] -->|API呼出1| B[ベクトル1] C[商品2] -->|API呼出2|](https://files.speakerdeck.com/presentations/53a075dd091a41a79c0a0a827af78585/slide_104.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}