テキストからの実世界知能の実現に向けて
栗田修平(国立情報学研究所 / 助教)
SUMO.ai #01(2025/07/25)での登壇資料です
https://sumo-ai.connpass.com/event/356533/
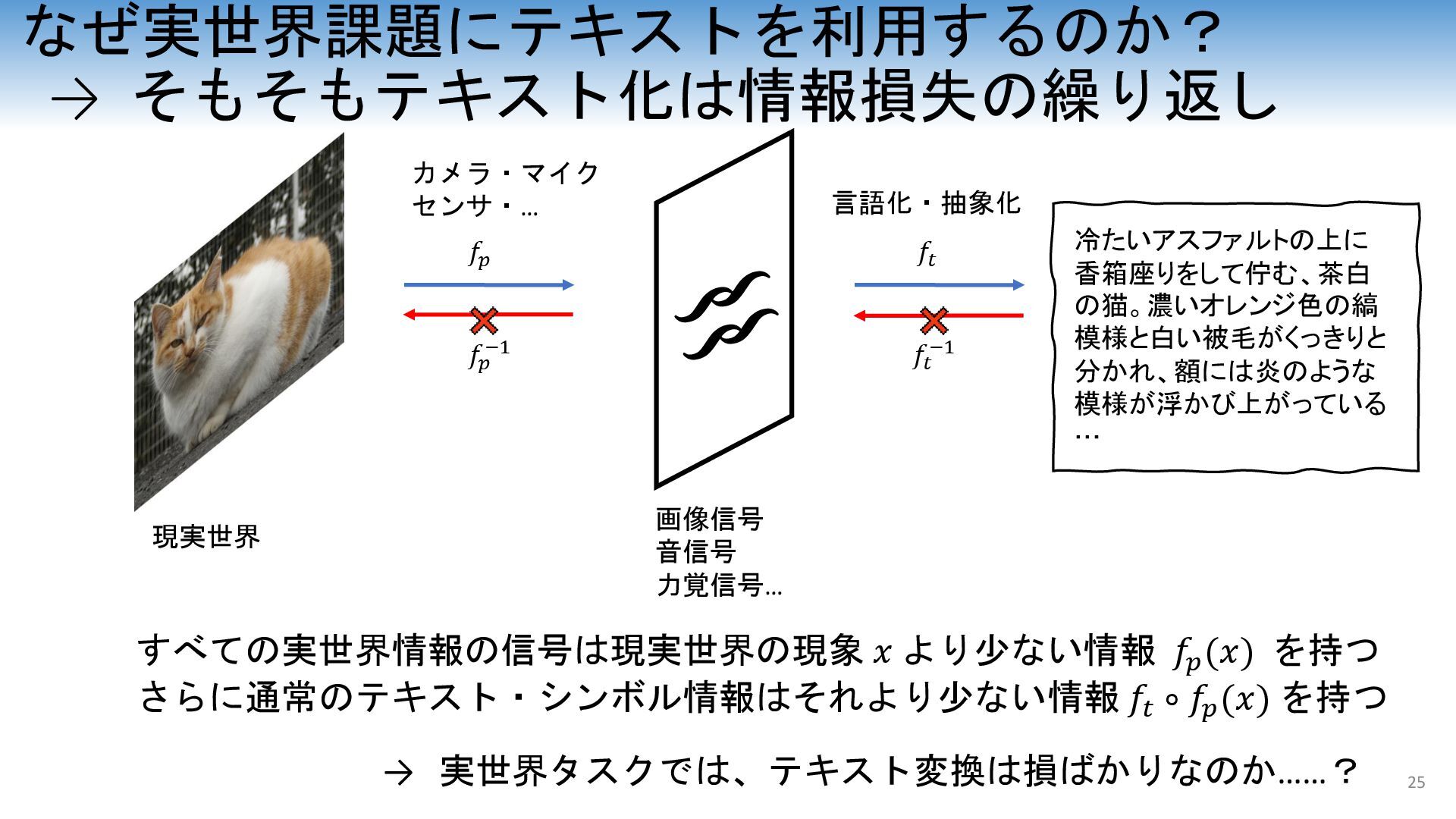
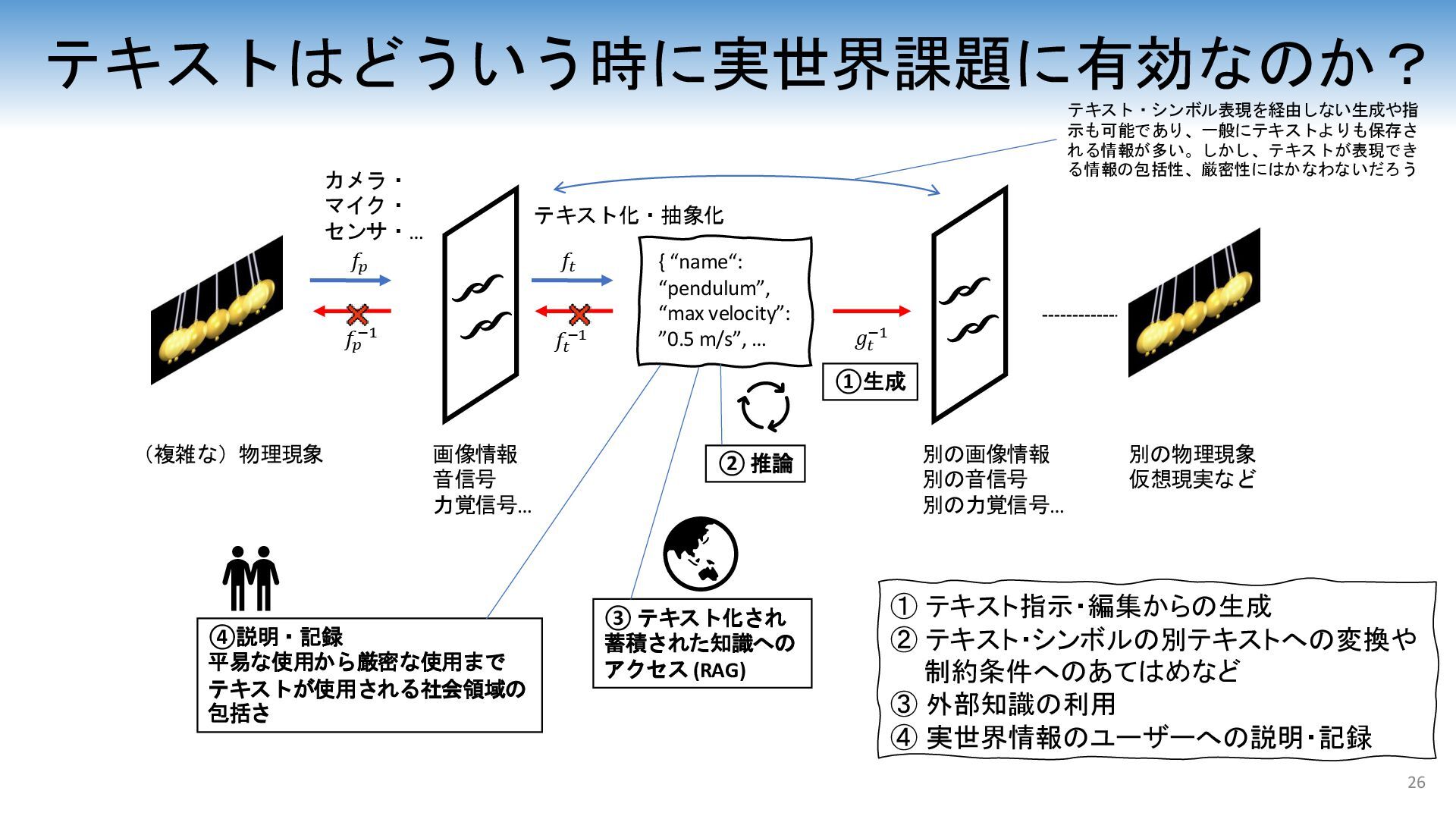
大規模言語モデル (LLM) やマルチモーダル言語モデル (MLLM) の発展により、実世界情報をテキスト的に処理する試みが進んでいる。テキスト情報は、人間がもっとも直感的に使用し、学術的な推論から日常的なコミュニケーション、さらにはユーモアやナンセンスまであらゆる分野を網羅して使用されるほぼ唯一のシンボル情報である。加えて、インターネット時代には画像と並んで膨大なテキスト情報を取得しやすい利点が存在する。一方で、実世界情報の表現としては、テキスト情報はあまりにも情報を保存できていない欠点が存在する。このようなテキストの性質を踏まえながら、本講演ではLLMやMLLM技術、LLMエージェント技術等の応用が見込まれる、3D、ロボット基盤モデル、自動運転のようなトピックに横断的に触れ、テキスト情報が果たす役割および応用について議論する。
2019年に自然言語処理の分野で博士取得後に、実世界・物理世界を理解するための自然言語処理を目指して研究を進める。自然言語処理、機械学習、コンピュータビジョン、ロボティクスなど幅広い分野でトップ会議に採択経験あり。博士(情報学)(京都大学)、その後、理研AIP研究員、JSTさきがけ研究員、ニューヨーク大学訪問研究員などを歴任後に2024年より現職。
{kind=link}
{kind=link}
{kind=link}
![一人称視点動画を利用したロボット用学習データの収集 4 HD-EPIC [Perrett+ Arxiv25] 作業映像,特に一人称視点動画は物体操 作のための重要な情報源となる 作業映像から物体操作の学習に有用な情報を抽出する Challenge -](https://files.speakerdeck.com/presentations/18a6085c1d7447f79124d0a433712c44/slide_3.jpg){kind=link}
{kind=link}
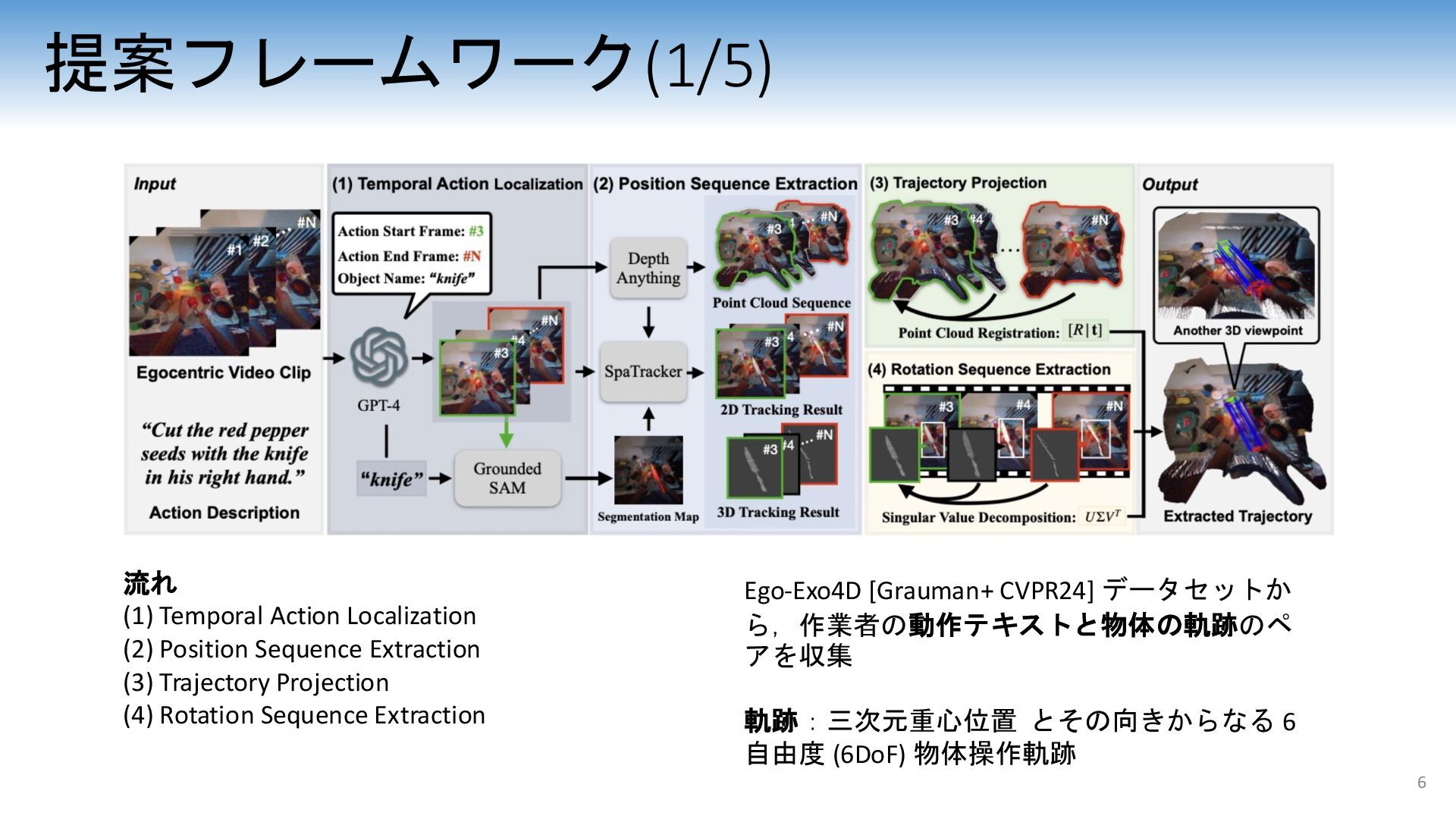{kind=link}
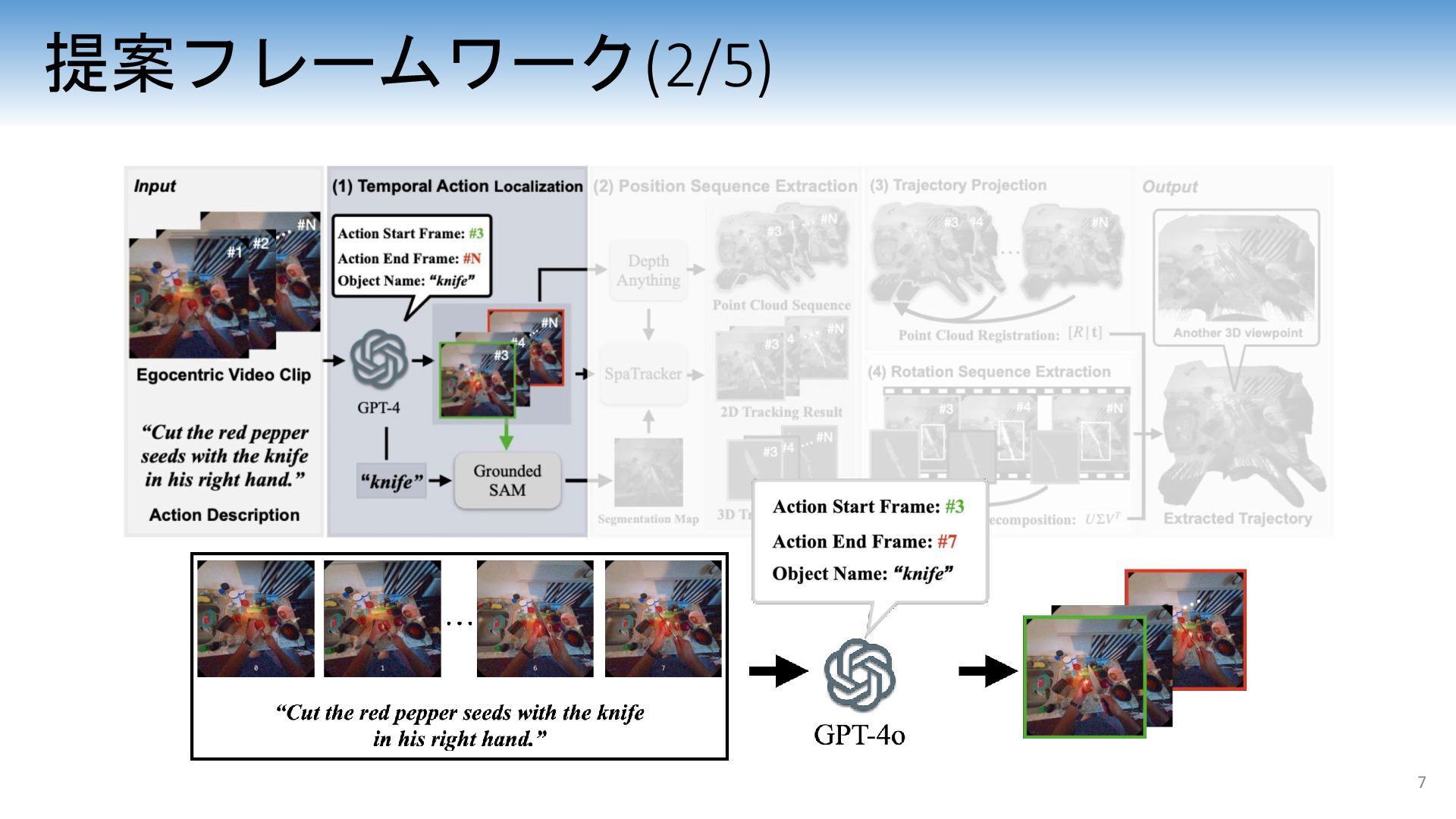{kind=link}
![提案フレームワーク(3/5) 8 2D/3D 追跡結果 Reference - SpaTracker [Xiao+ CVPR24] -](https://files.speakerdeck.com/presentations/18a6085c1d7447f79124d0a433712c44/slide_7.jpg){kind=link}
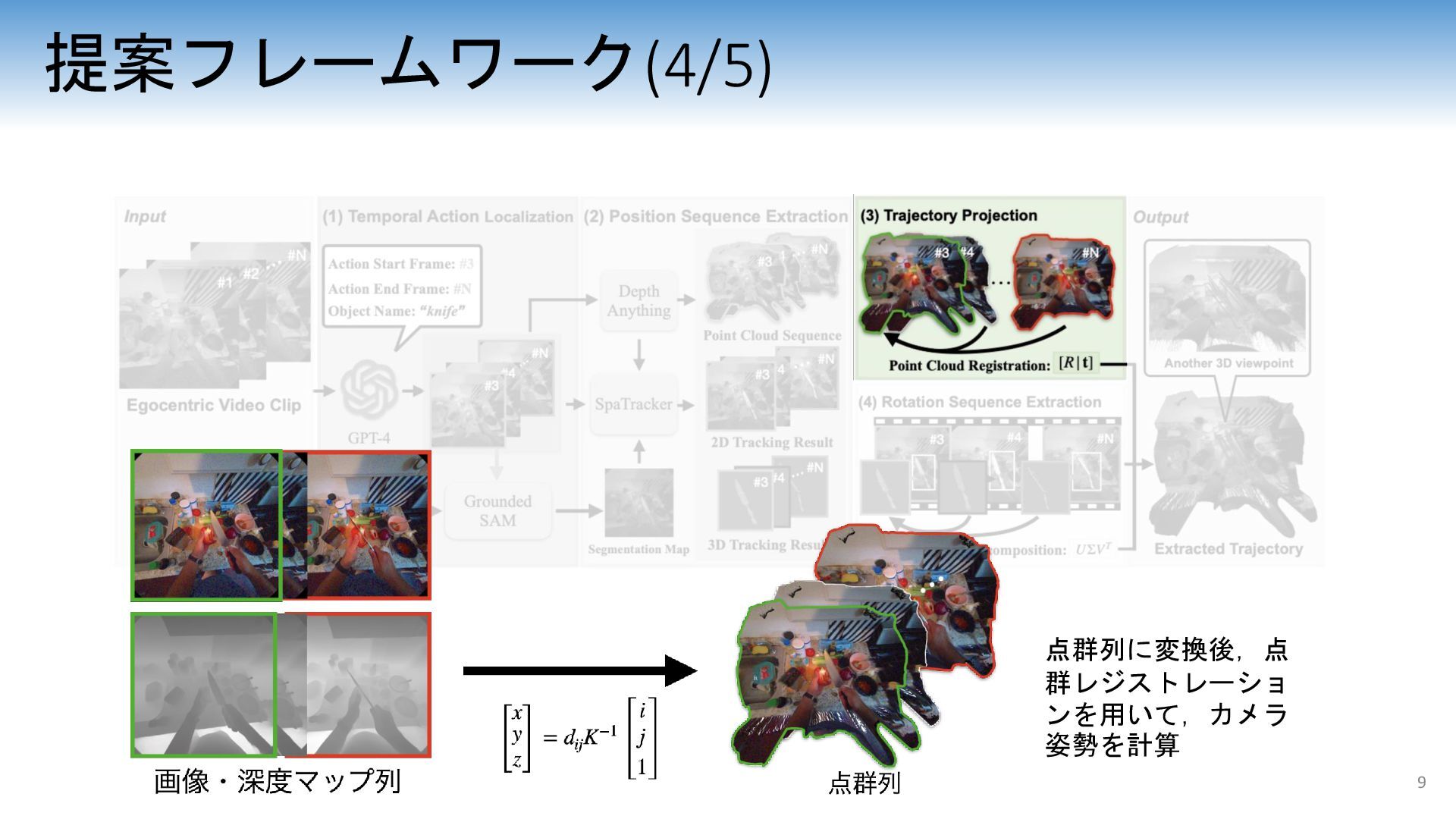{kind=link}
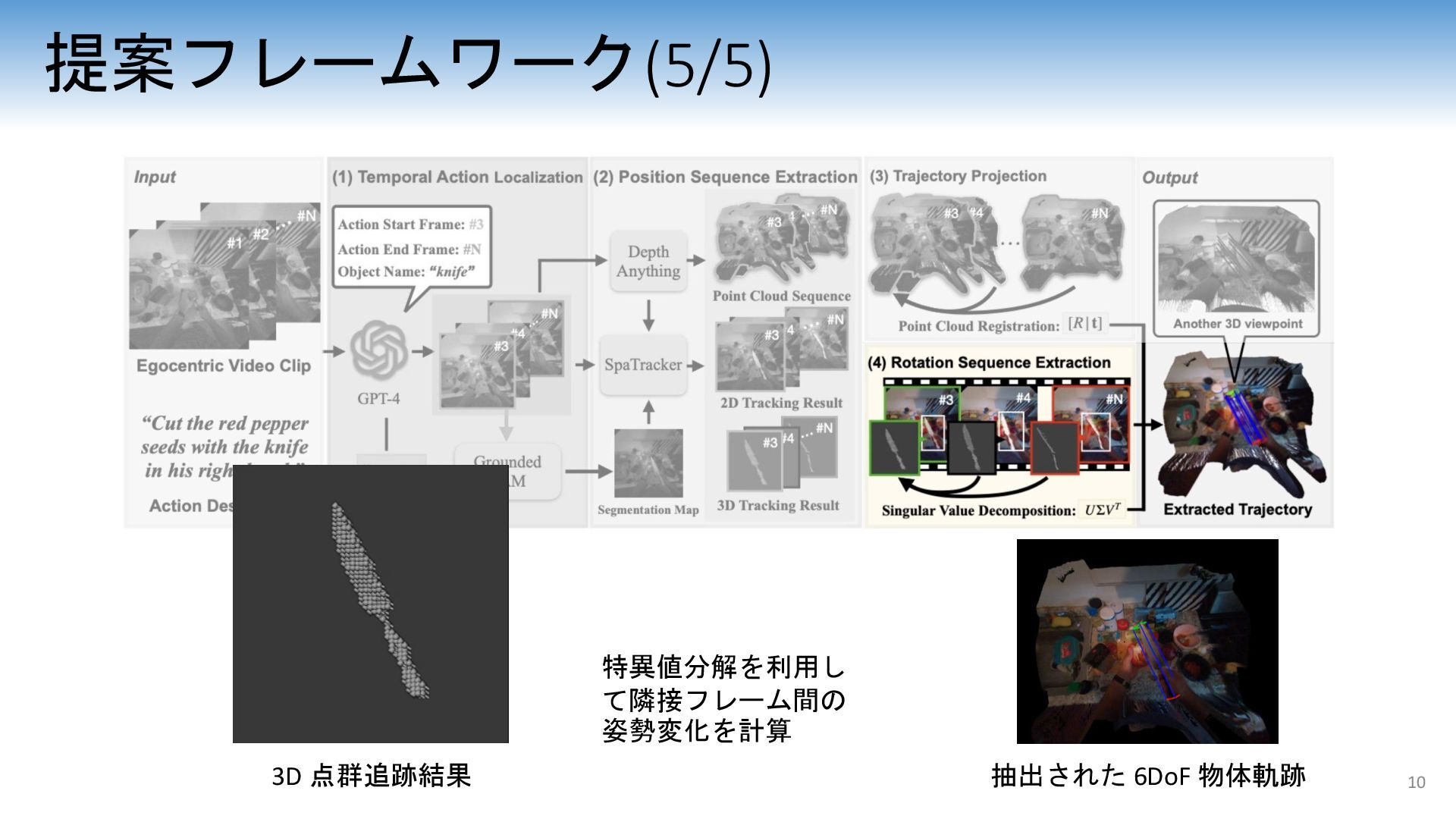{kind=link}
{kind=link}
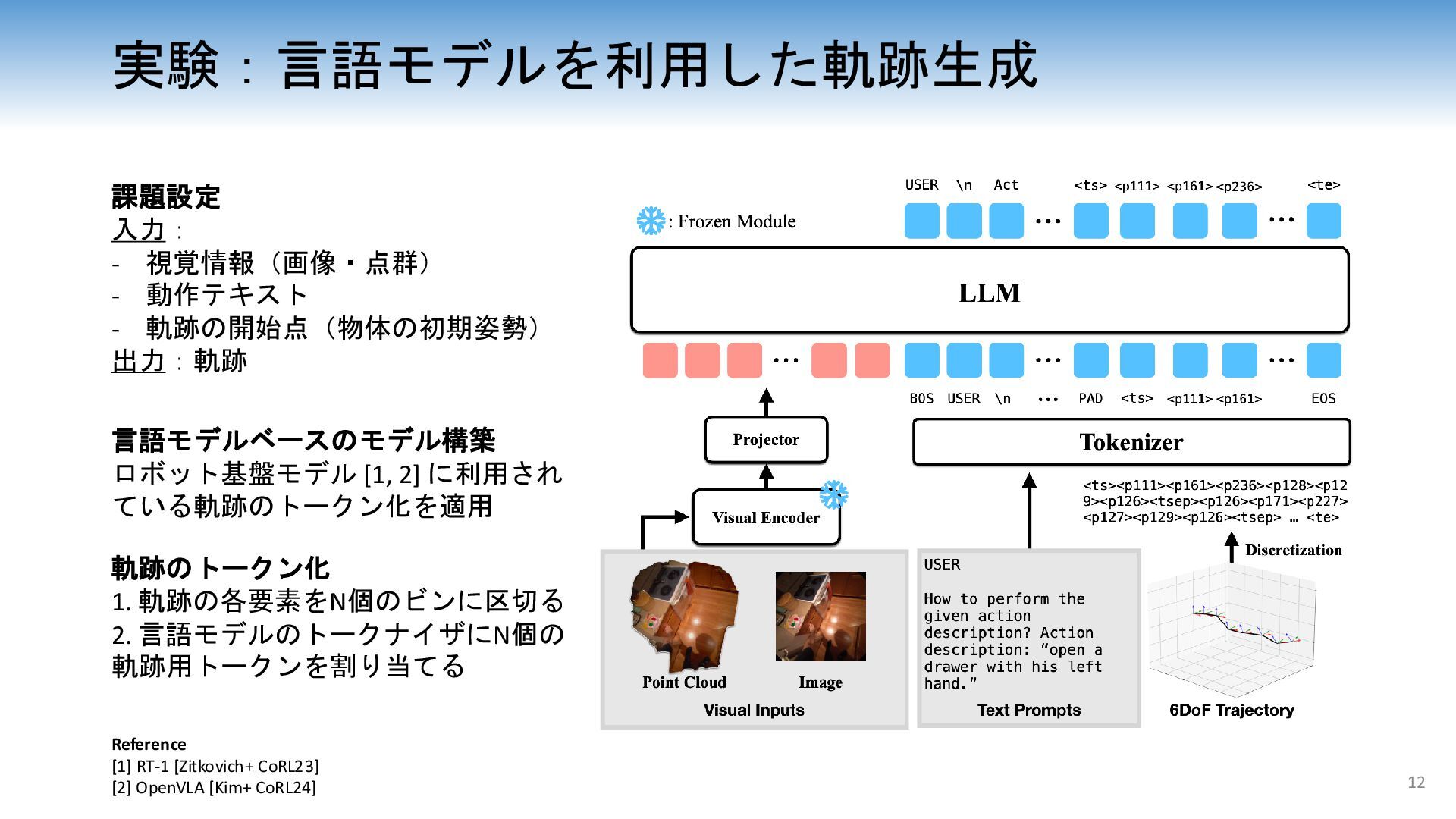{kind=link}
![実験:言語モデルを利用した軌跡生成 13 PointLLM [Xu+ ECCV24] による軌跡生成結果 “Tranfer the wooden spoon](https://files.speakerdeck.com/presentations/18a6085c1d7447f79124d0a433712c44/slide_12.jpg){kind=link}
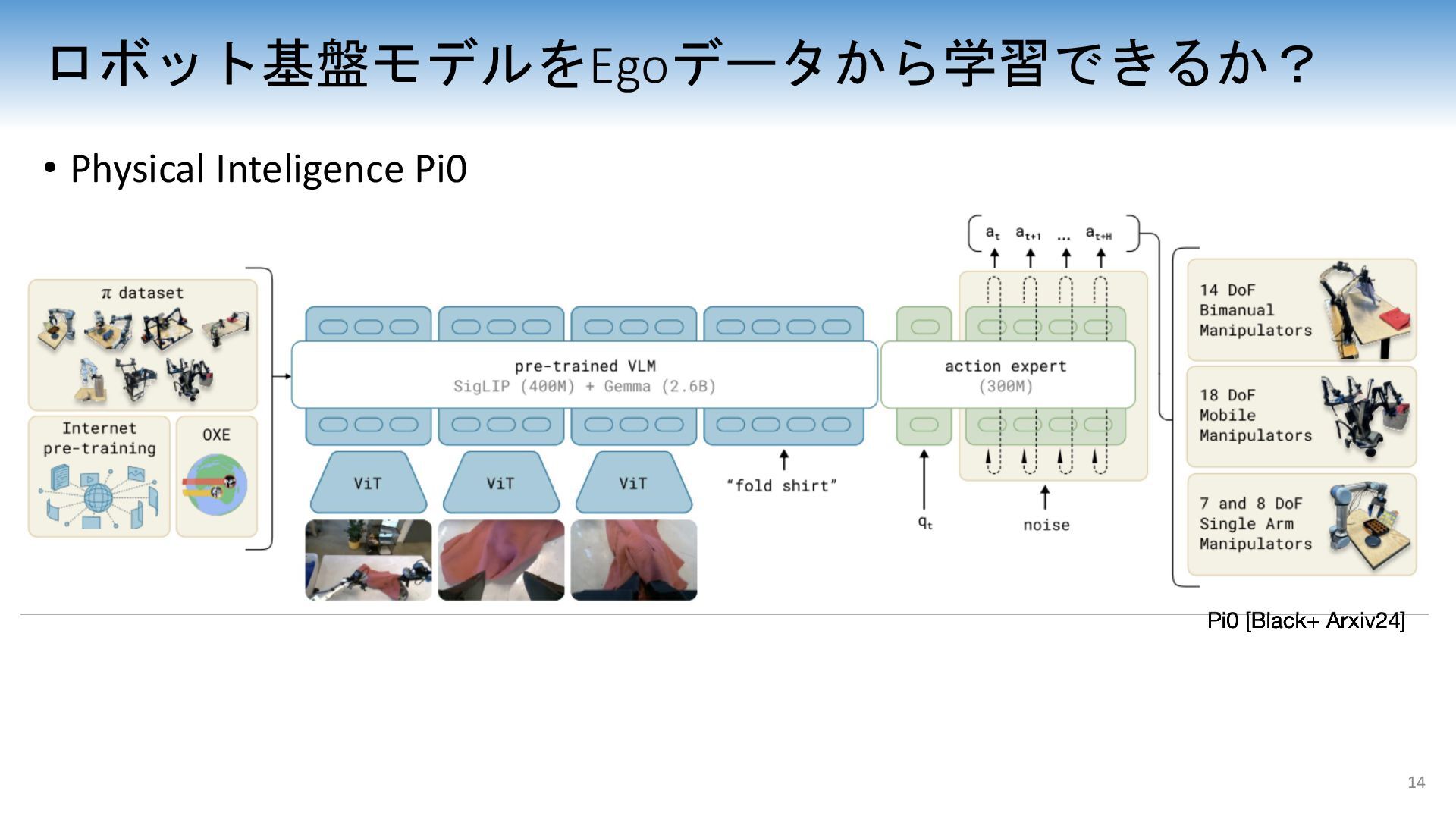{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
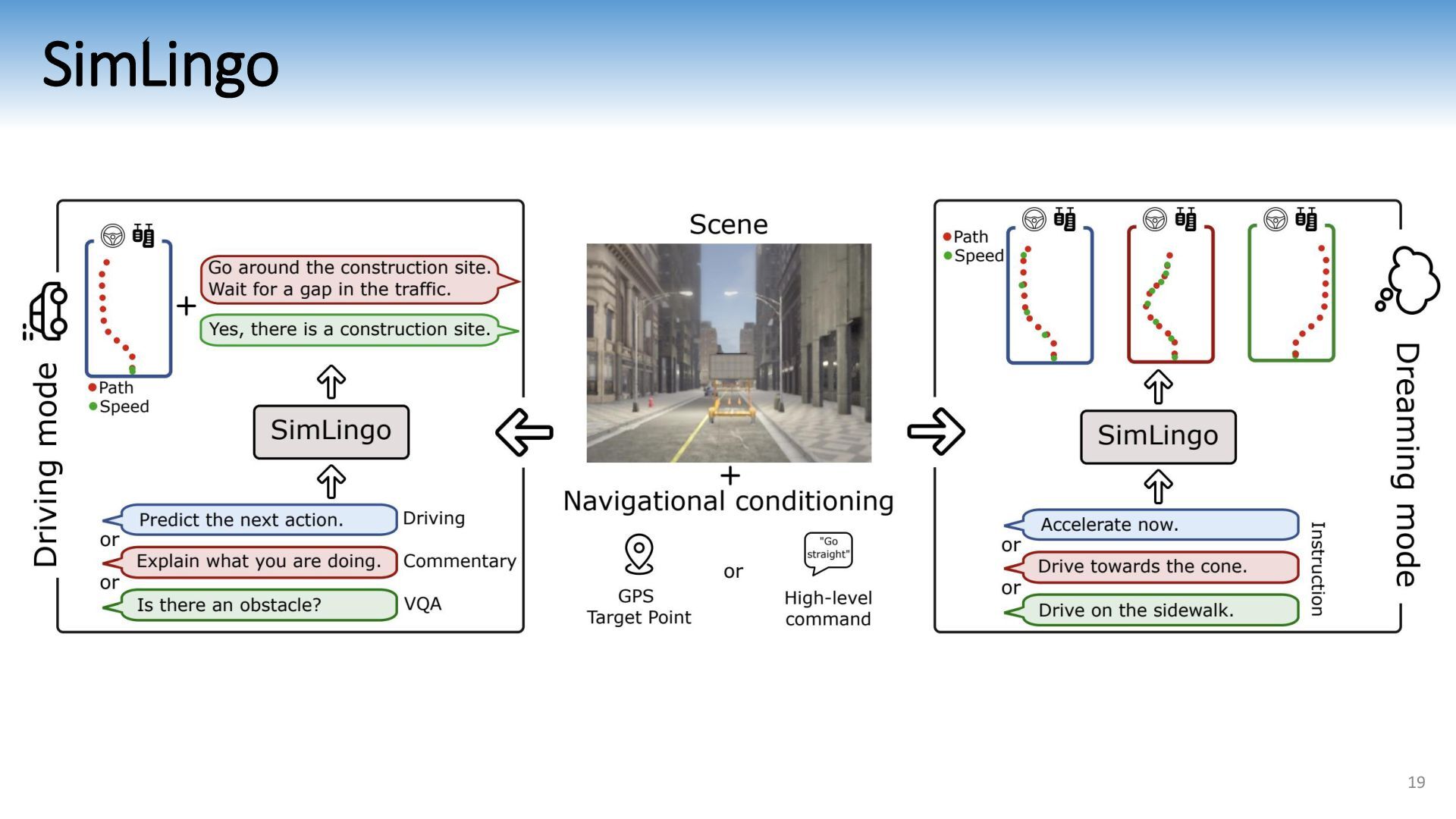{kind=link}
{kind=link}
{kind=link}
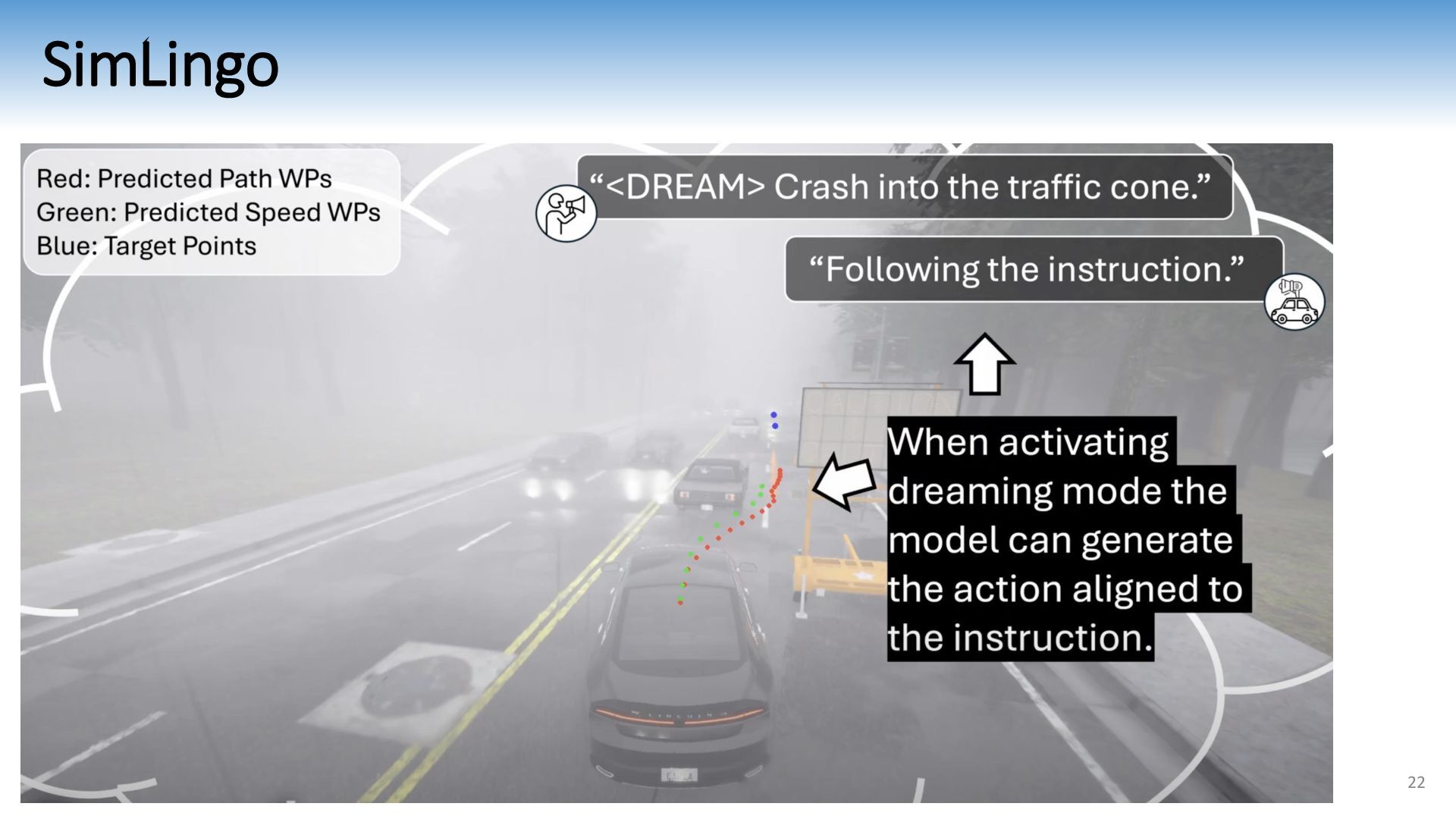{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}