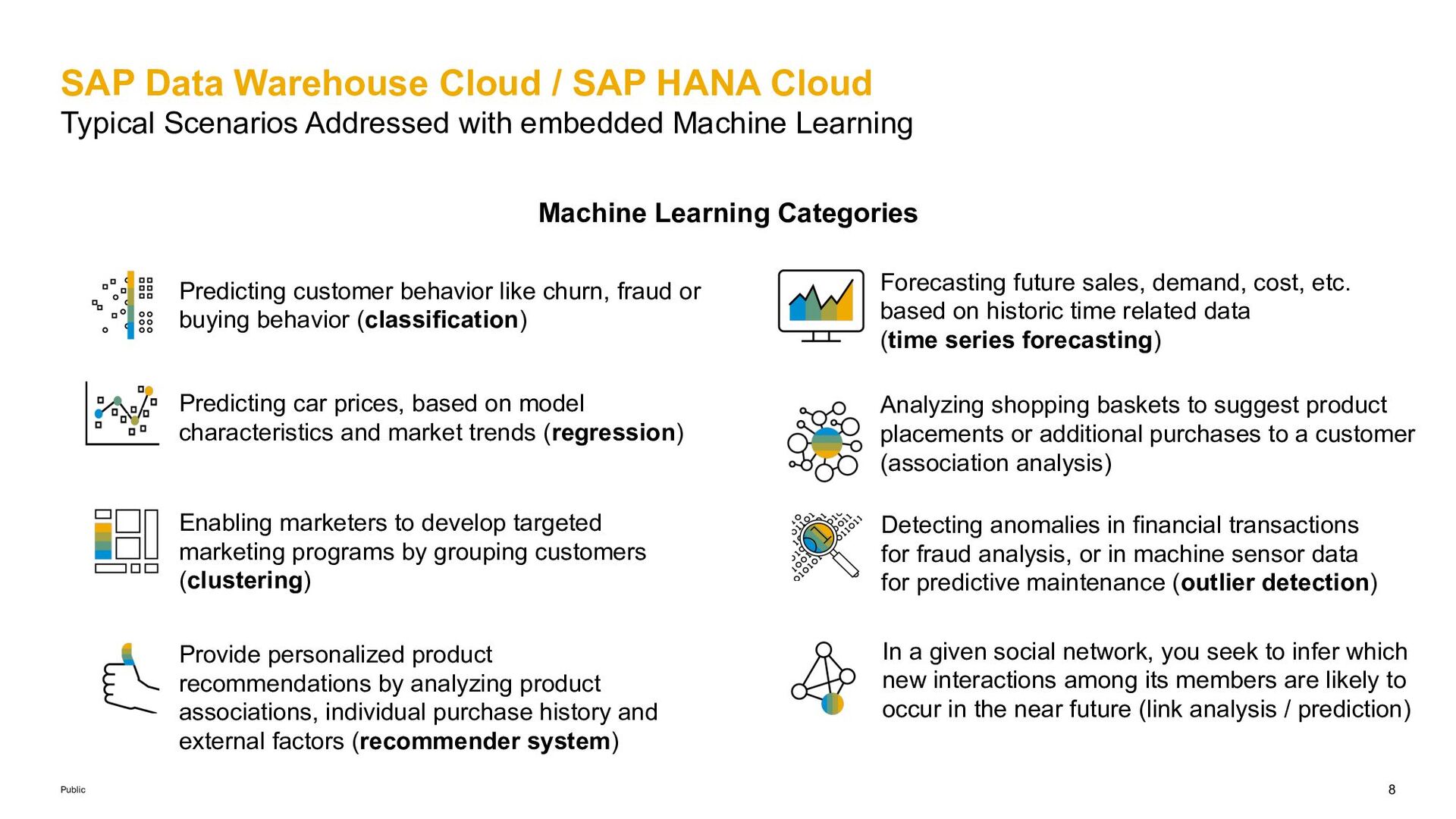
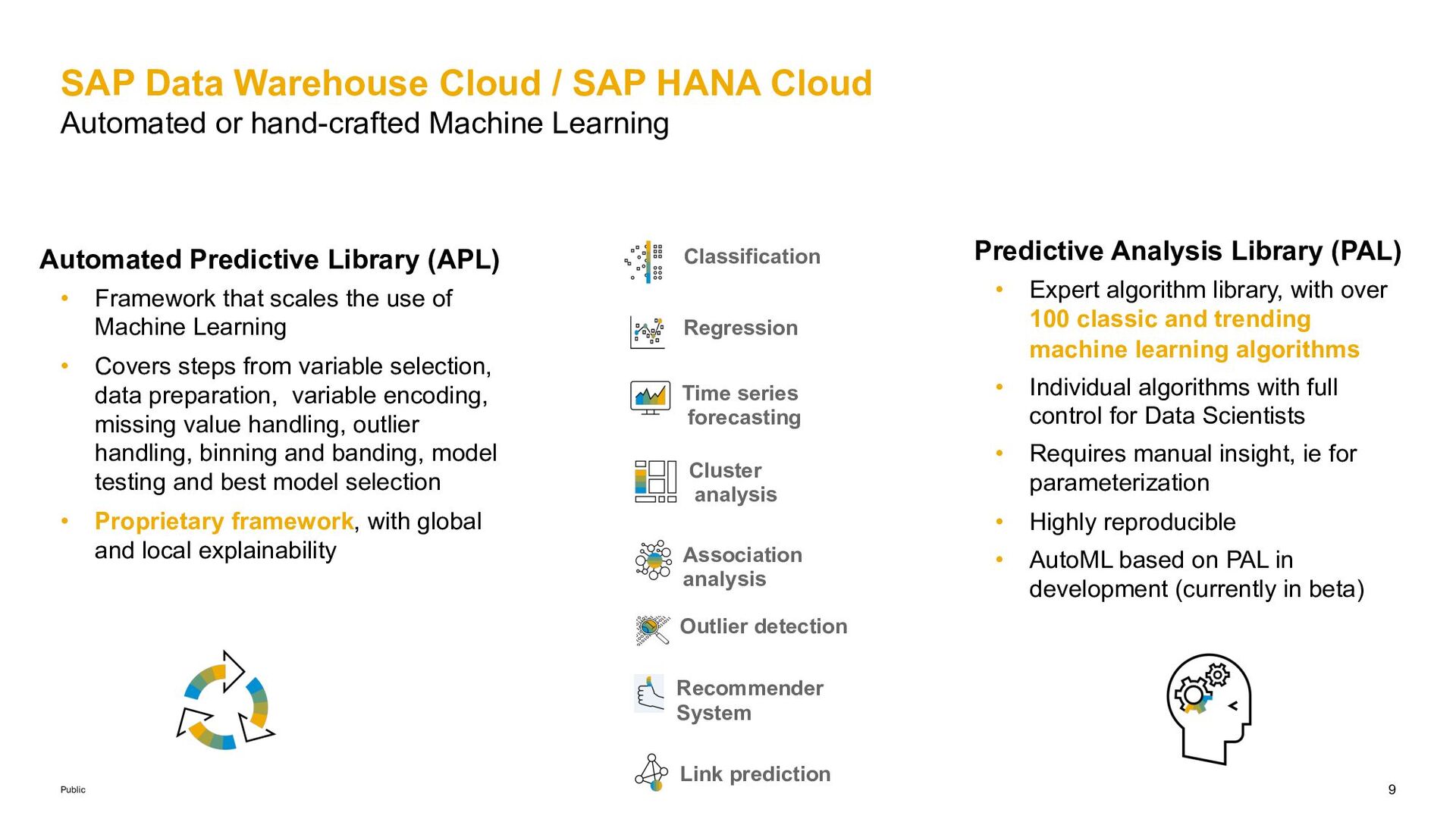
CHAID) , Logistic Regression, Support Vector Machine, K-Nearest Neighbor, Naïve Bayes, Confusion Matrix, AUC, Online multi-class Logistic Regression* § Multilayer Perception (back propagation Neural Network) § Random Decision Trees, Hybrid Gradient Boosting Tree (HGBT)#,, Continuous HGBT* § Unified Classification# incl. explainability, segmented (massive) classification Regression § Multiple Linear Regression, Online Linear Regression* § Polynomial-, Exponential-, Bi-Variate Geometric-, Bi-Variate Natural Logarithmic- Regression § Generalized Linear Model (GLM) § Cox Proportional Hazards Model § Random Decision Trees, Hybrid Gradient Boosting Tree (HGBT) #, Continuous HGBT* § Unified Regression* incl. explainability, segmented (massive) regression Pipeline and AutoML § Pipeline-models, -fit and -predict § AutoML incl. data preprocessing, classi- fication, regression, time series forecasting Association Analysis § Apriori, Apriori Lite, FP-Growth § K-Optimal Rule Discovery (KORD) Discovery, Sequential Pattern Mining Link Prediction § Link Prediction (Common Neighbors, Jaccard’s Coefficient, Adamic/Adar, Katzβ), PageRank Recommender Systems § Factorized Polynomial Regression Models, Alternating least squares, Field-aware Factorization Machines (FFM) Text Processing § Conditional Random Field, Latent Dirichlet Allocation § TF-IDF*, term analysis*, text classification*, get related terms / documents*, get relevant terms / documents*, get suggested terms* Data Preprocessing § Sampling, Partitioning, SMOTE, TomekLink, SMOTETomek# § Binning / Discretize, Missing Value Handling, Scaling, Feature Selection* § Isolation Forest* Statistical & Multivariate Analysis § Univariate Analysis (Data Summary, Mean, Median, Variance, Stand. Deviation, Kurtosis, Skewness, ..) § Kernel Density Estimation, Entropy § Correlation Function (with confidence) § Multivariate Analysis (Covariance Matrix, Pearson Correlations Matrix), Condition Index § Principal Component Analysis (PCA)/PCA Projection, TSNE, Categorial PCA § Linear Discriminant Analysis § Multidimensional scaling, Factor Analysis § Chi-squared Tests: Quality of Fit, Test of Independence, ANOVA, F-test (equal variance test) § One-sample Median Test, T Test, Wilcox Signed Rank Test, Kolmogorov-Smirnov Test* § Inter-Quartile Range, Variance Test, Grubbs Outlier Test , Anomaly Detection (KMeans) § Random Distribution Sampling, Markov Chain Monte Carlo (MCMC)# § Distribution Fitting, Cumulative Distribution Function, Distribution Quantile Misc. Functions § Kaplan-Meier Survival Analysis, Weighted Scores Table, ABC Analysis, Tree model visualization# Cluster Analysis § K-Means, Accelerated K-Means, K-Medoids, K- Medians, Geo- / DBSCAN, Agglomerate Hierarchical Clustering*, Slight Silhouette, Cluster Assignment § Kohonen Self-Organizing Maps, Affinity Propagation, Gaussian Mixture Model § segmented (massive) Unified Clustering#, Spectral clustering* Time Series Analysis § Single-, Double-, Triple-, Brown-, Auto Exponential Smoothing, Unified Exponential Smoothing (incl. massive segmentation)* § Auto-ARIMA, Online ARIMA*, Vector-ARIMA*, ARIMA_EXPLAIN* § Additive Model Analysis#, GARCH*, BSTS* § Croston, Croston TSB*, Linear Regression with damped trend and seasonal adjust, Intermittent Time Series Forecast* § Fast Dynamic Time Warping# , DTW*, Hierarchical Forecasting § FFT, Discrete Wavelet/ Wavelet Packet Transform*, Periodogram* § White Noise-, Trend-, Stationary-*, Seasonality- Test, Change Point Detection, Bayesian Change Point Detection*, Outlier Detection*, TS Imputation*, Forecast Accuracy Measures § LSTM*, Attention*, LTSF* § Segmented (massive) Forecasting* SAP HANA Predictive Analysis Library documentation #SAP HANA 2 SPS05 & HANA Cloud | *SAP HANA 2 SPS06 & HANA Cloud | *New in SAP HANA Cloud | As of SAP HANA Cloud 2022 Q3 (CE2022.30)) SAP Data Warehouse Cloud / SAP HANA Cloud Predictive Analysis Library (PAL)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}