Databricks Inc. — All rights reserved あなたのすべてのデータのためのオープン統合基盤 オープンデータレイク すべての構造化、半構造化、非構造化データ (ログ、テキスト、音声、動画、画像など) ETL & リアルタイム分析 オーケストレーション データウェアハウス データサイエンス & AI Mosaic AI Delta Live Tables Workflows Databricks SQL セキュリティ、ガバナンス、カタログの統合 Unity Catalog 信頼性と共有のための統合データストレージ Delta Lake
<privilege> ON <securable_type> <securable_name> TO `<principal>` GRANT SELECT ON iot.events TO engineers 権限 レベルを選択 お使いのID プロバイダーの グループと同期 ‘テーブル’= S3/ADLSの ファイルの集合 ANSI SQL DCLを使用 UIを使用 ワークロードに対するアクセス権限の付与と集中管理
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
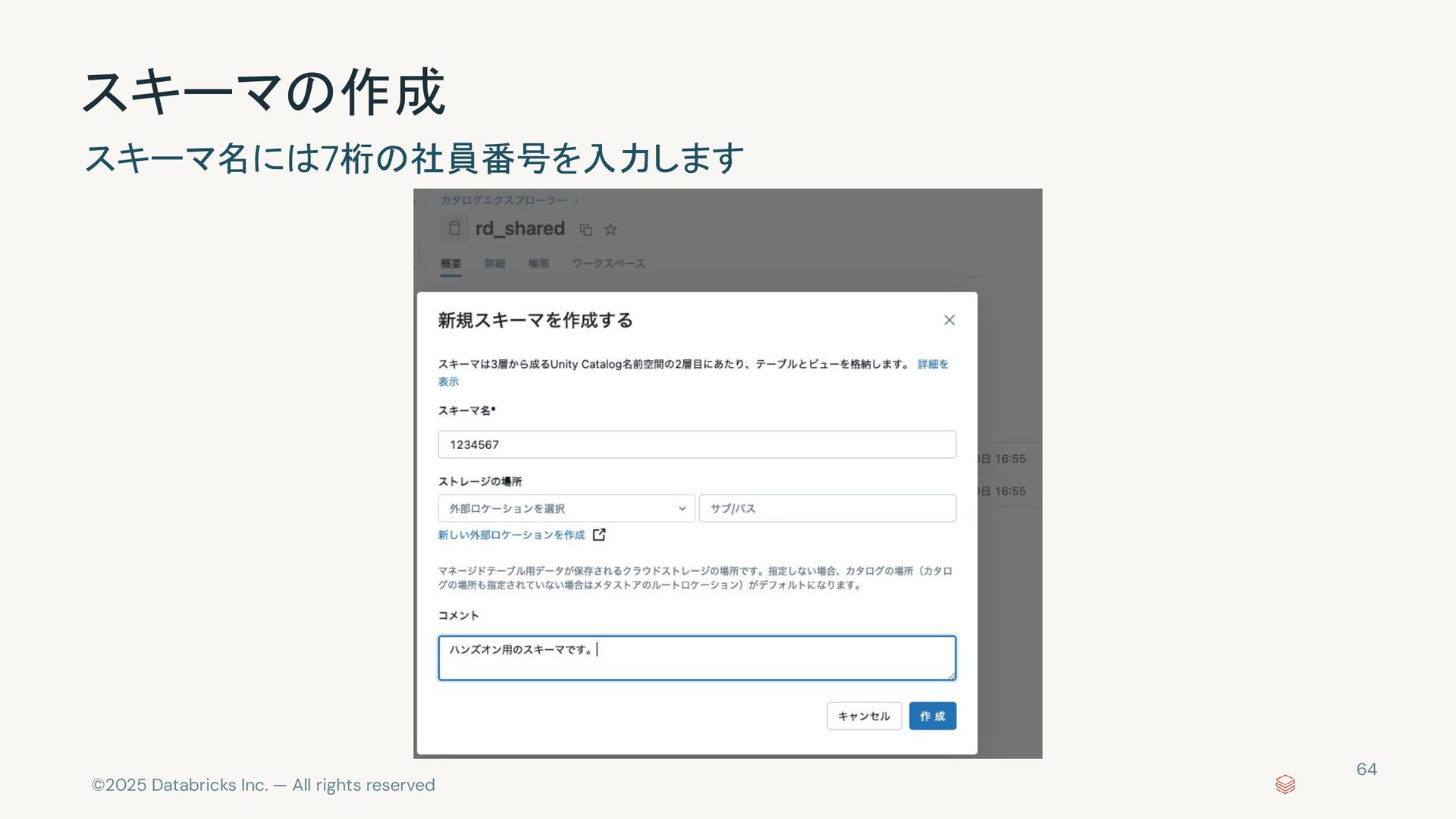{kind=link}
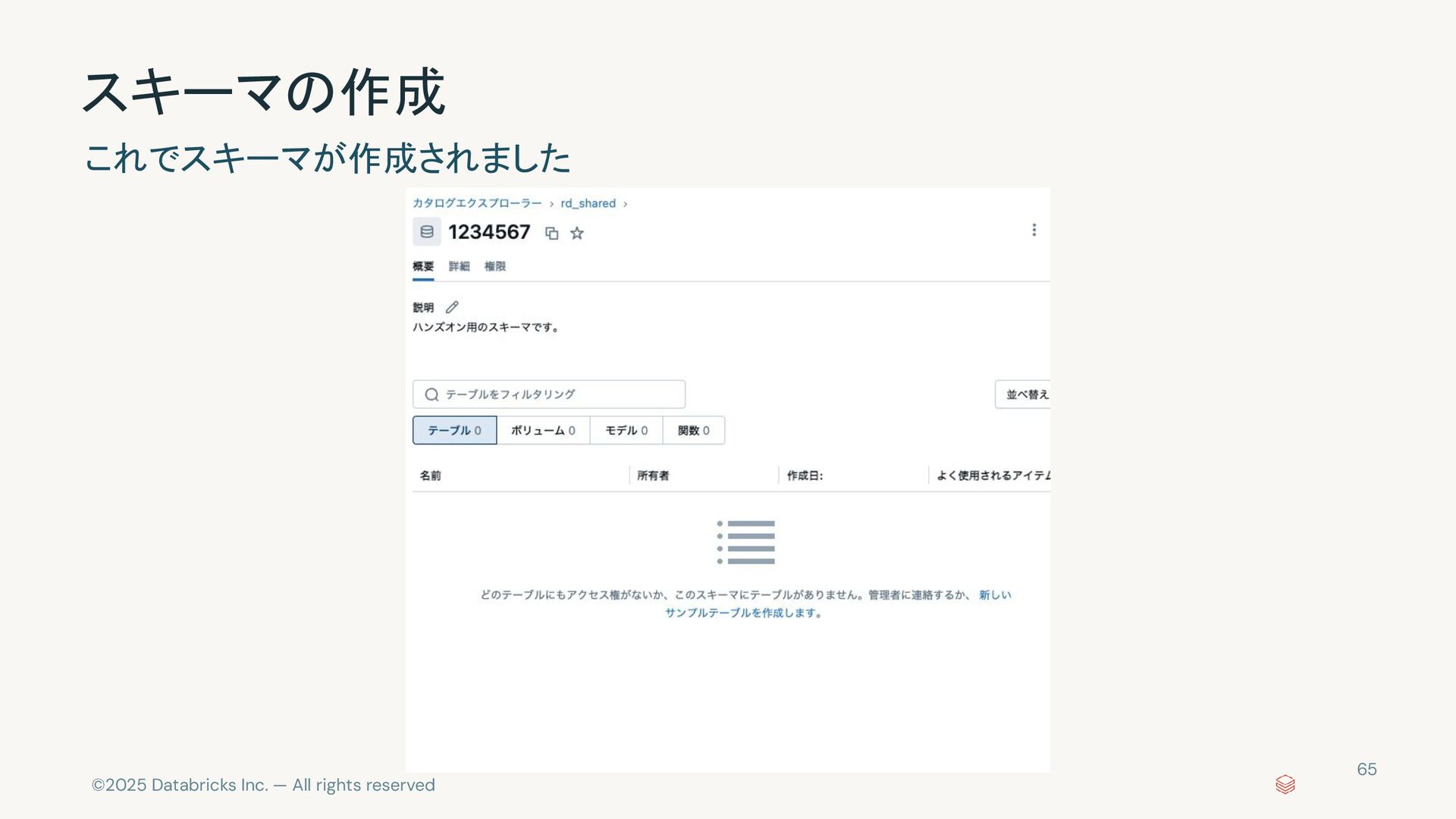{kind=link}
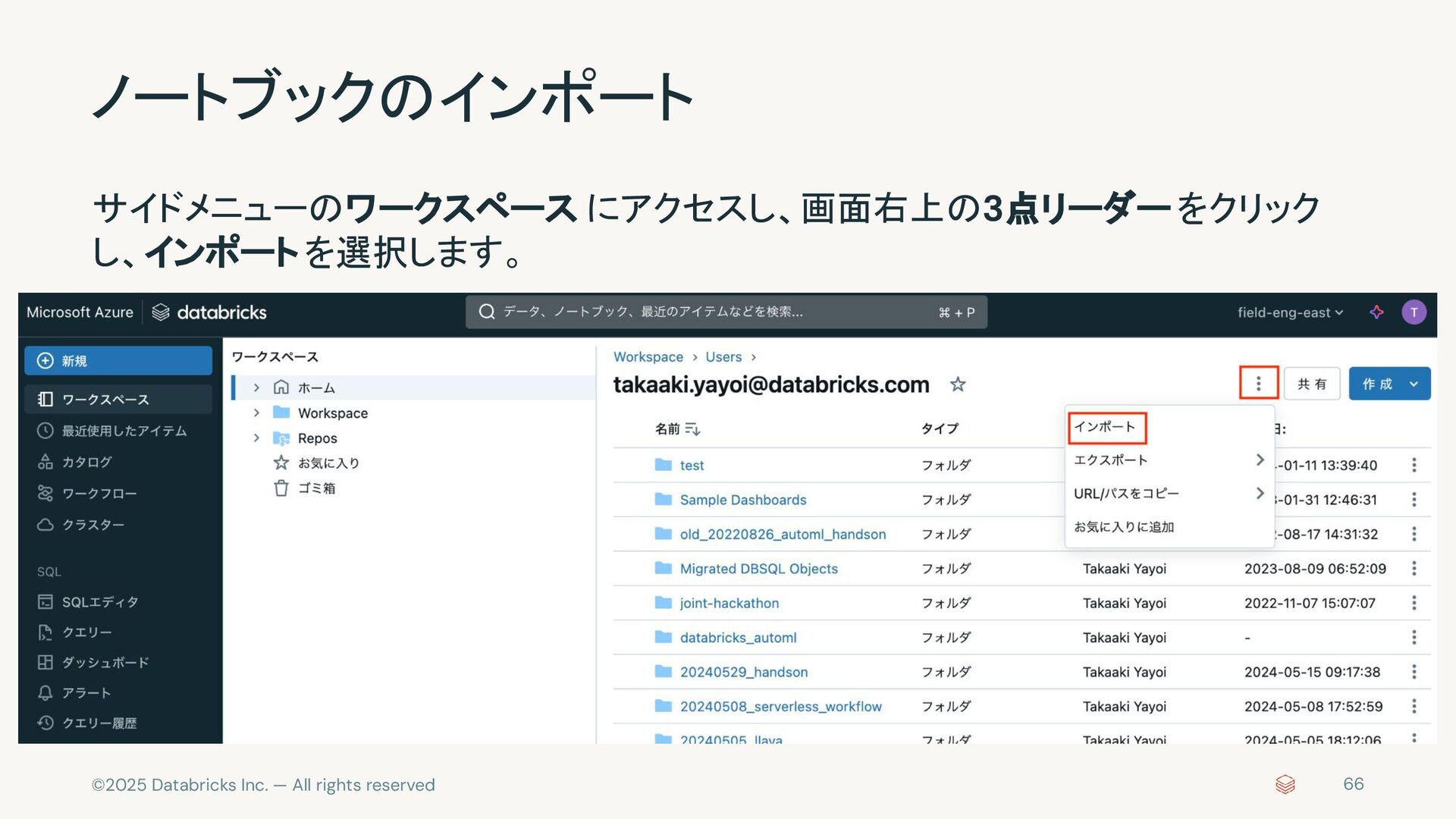{kind=link}
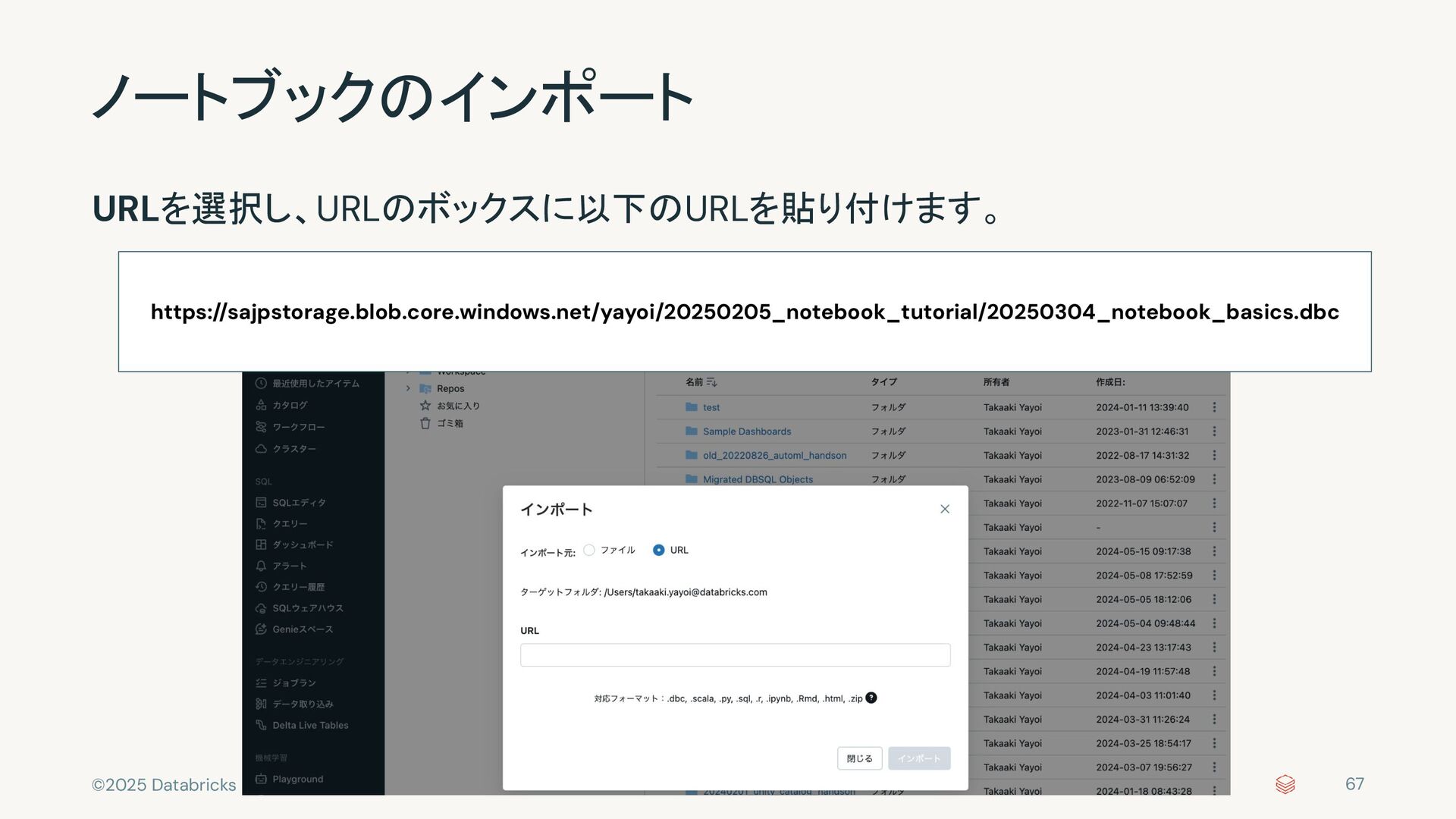{kind=link}
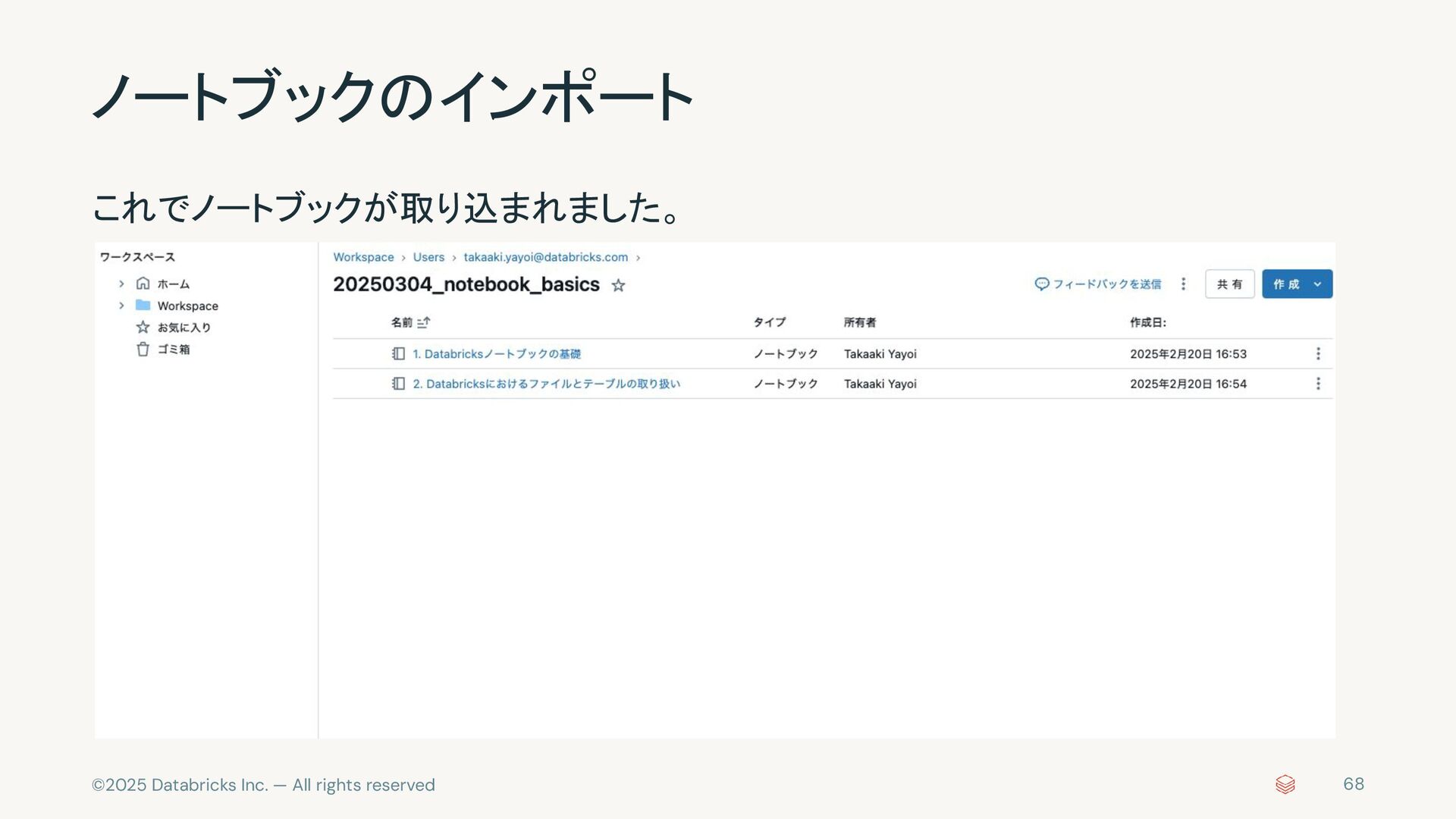{kind=link}
{kind=link}
{kind=link}
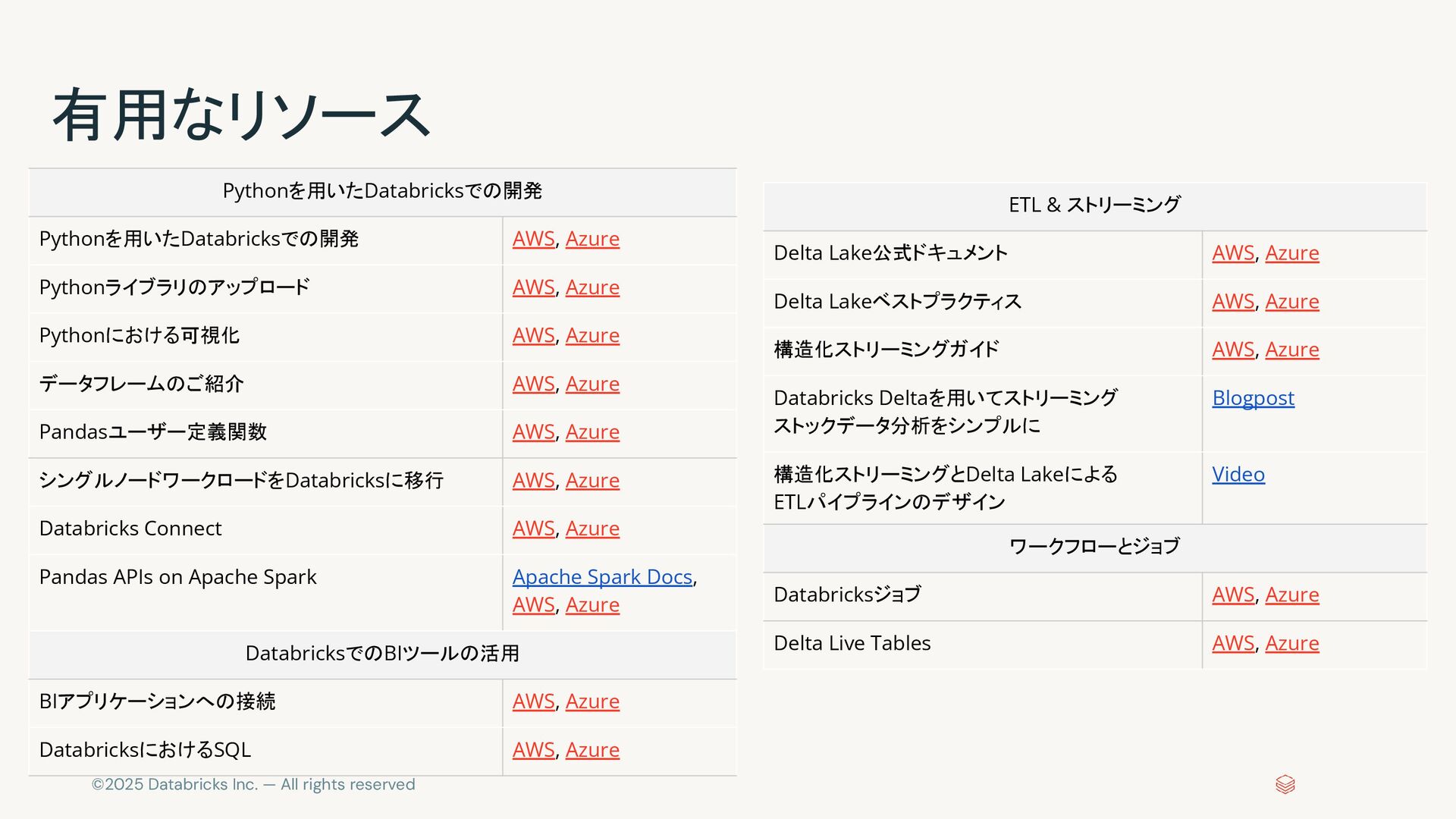{kind=link}
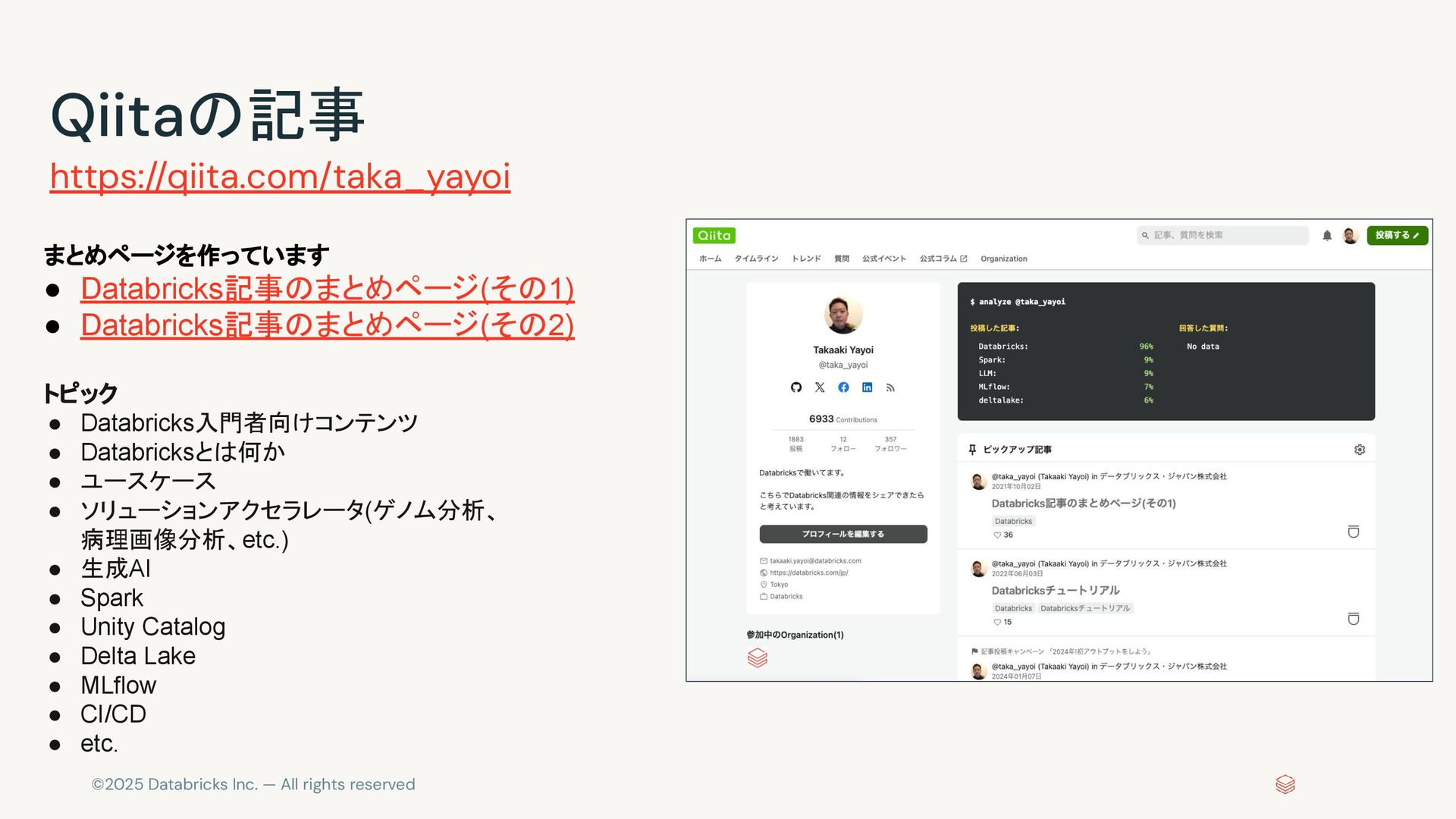{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}