Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
CIBMTR振り返り+敗北から学ぶコンペの取り組み方反省
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Naoya
March 10, 2025
Programming
5.8k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
CIBMTR振り返り+敗北から学ぶコンペの取り組み方反省
2025/3/7 の関西Kaggler会での発表資料です。
Naoya
March 10, 2025
Other Decks in Programming
See All in Programming
継続モナドとリアクティブプログラミング
yukikurage
3
440
Semantic Version 単位で戦略を柔軟に変えて、パッケージアップデートを自動化する
daitasu
1
350
Snowflake Summitでの新機能 CoCo / CoWork / snowflake-summit-2026-overall-what-new-coco
tatsuhiro
1
220
自作OSでスライド発表する
uyuki234
1
3.7k
気圧・高度・GPSを記録&可視化するアプリ「Koudo」を作った話
hjmkth
1
350
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
410
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
15
3k
Signal Forms: Details & Live Coding @enterJS 2026 in Mannheim
manfredsteyer
PRO
0
220
エージェンティックRAGにAWSで入門しよう!
har1101
9
1.9k
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
0
170
Performance Engineering for Everyone
elenatanasoiu
0
260
トークンをケチるな、設計しろ:GitHub Copilotを賢く使うコンテキスト戦略
ochtum
0
300
Featured
See All Featured
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
Why Our Code Smells
bkeepers
PRO
340
58k
4 Signs Your Business is Dying
shpigford
187
22k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
410
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Facilitating Awesome Meetings
lara
57
7k
Designing Powerful Visuals for Engaging Learning
tmiket
1
440
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
890
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Transcript
関西kaggler会 交流会 in Osaka 2025#1 CIBMTR コンペ振り返り +敗北から学ぶコンペの取り組み方反省 2025/03/07 Naoya
LB PB BIG SHAKE これにはちゃんとしたワケが 結果から,
自己紹介 兵庫県立大学大学院 M2 来年から博士後期課程に進学します! 専門分野:電子情報工学 研究分野:医用画像処理 Kaggle は基本画像系に出ています. Kaggle 歴は1年半くらい.
初参加 登山はじめ,運動が好きです. 😁
目次 1. コンペ概要 2. 我々の solution を簡単に • うまくいかなかったこと,その中でも学びになったこと,しくじりを 重点的に
• 上位解法にも触れます 3. しくじりから次にどう生かすか
目次 1. コンペ概要 2. 我々の solution を簡単に • うまくいかなかったこと,その中でも学びになったこと,しくじりを 重点的に
• 上位解法にも触れます 3. しくじりから次にどう生かすか
• テーブルデータコンペ(Notebook <= 9 hours run-time) • タスク • 造血幹細胞移植(HCT)を受ける患者の生存率を予測する.
• 人種間のばらつきを抑える.(メトリックの計算で重要ポイント) コンペ概要
• 基本情報 • 造血幹細胞移植(HCT)に関する59種類の変数 • 移植を受ける患者とドナーの年齢・人種・疾患状態・治療内容 など • ターゲット •
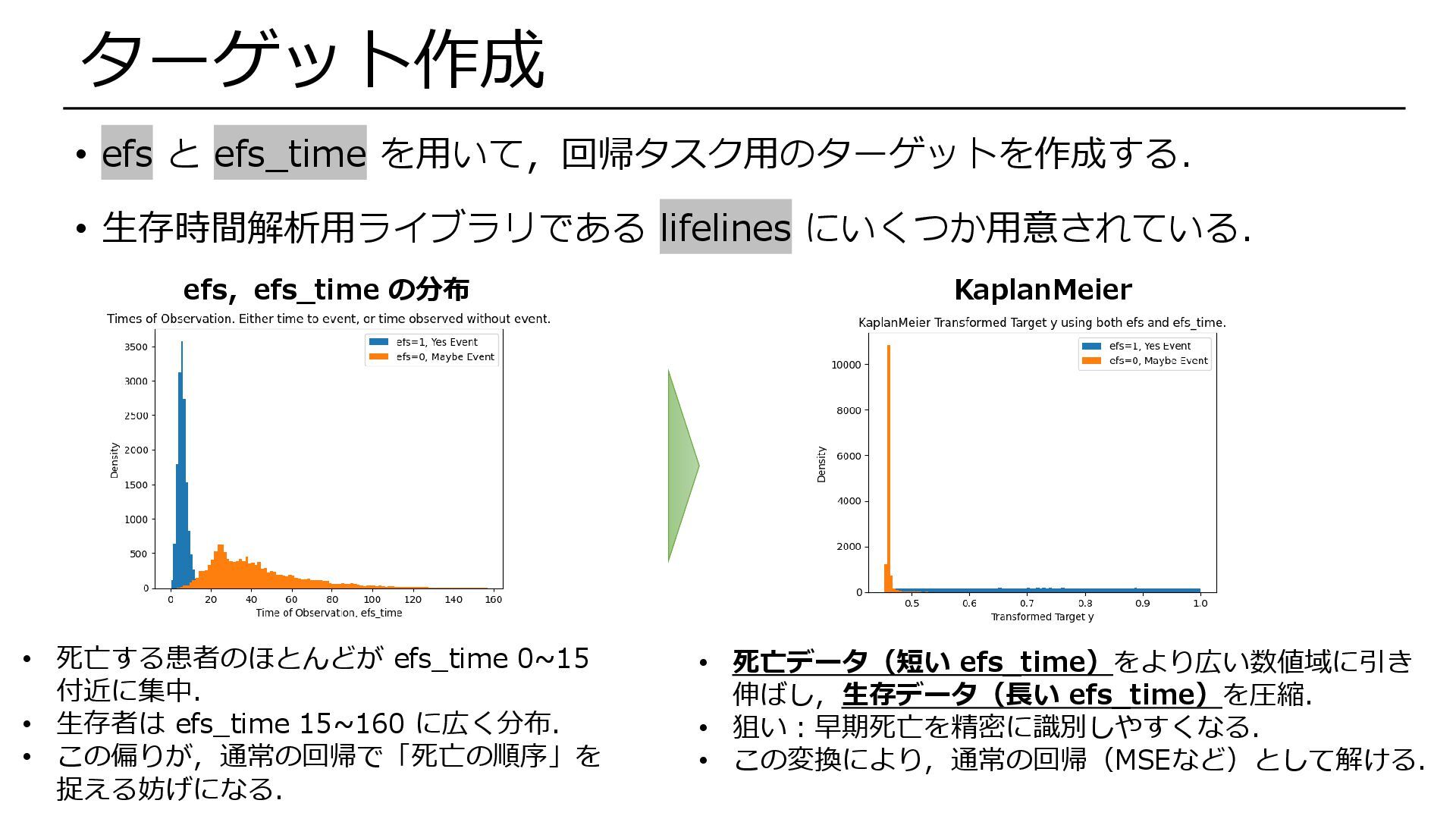
efs:生存(0)したか,死亡(1)したか(約半数ずつ) • efs_time:イベントまでの時間 • efs=1 → 患者が「ちょうどefs_time に死亡」(非検閲データ) • efs=0 → 患者が「efs_time より後に死亡する」ことだけがわかる(検閲データ) • 部分的にしか正解(死亡時刻)がわからないタスク → 死亡時刻をターゲットと した通常の回帰などでは対応しにくい. • efs と efs_time を用いて,回帰タスク用のターゲットを作成する. データ説明
• efs と efs_time を用いて,回帰タスク用のターゲットを作成する. • 生存時間解析用ライブラリである lifelines にいくつか用意されている. KaplanMeier
• 死亡データ(短い efs_time)をより広い数値域に引き 伸ばし,生存データ(長い efs_time)を圧縮. • 狙い:早期死亡を精密に識別しやすくなる. • この変換により,通常の回帰(MSEなど)として解ける. efs,efs_time の分布 ターゲット作成 • 死亡する患者のほとんどが efs_time 0~15 付近に集中. • 生存者は efs_time 15~160 に広く分布. • この偏りが,通常の回帰で「死亡の順序」を 捉える妨げになる.
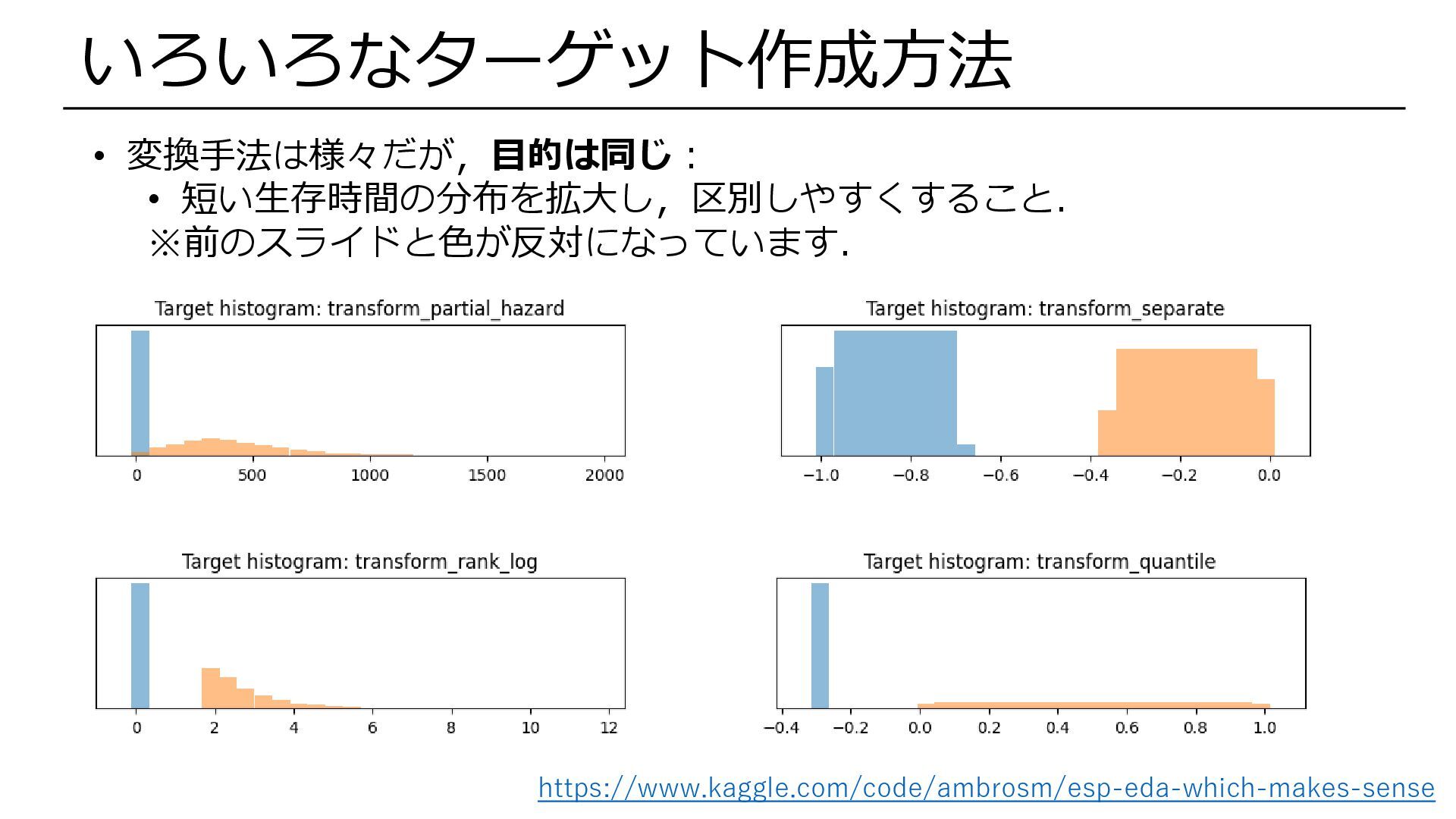
https://www.kaggle.com/code/ambrosm/esp-eda-which-makes-sense いろいろなターゲット作成方法 • 変換手法は様々だが,目的は同じ: • 短い生存時間の分布を拡大し,区別しやすくすること. ※前のスライドと色が反対になっています.
• Concordance Index (C-index) • 生存期間を予測するモデルの「順位付けの正確さ」を表す指標. • 値は 0.0~1.0 の範囲
• 0.5 : ランダム予測と同等 • 1.0 : 完全に正しい順位付け • 0.0 : 完全に逆の順位付け • Stratified C-index(本コンペの評価指標) 1. 人種ごとに C-index を計算 2. それらの平均(mean)ー 標準偏差(std)を最終スコアとする. • 狙い:人種間の公平性の強化 人種の分布はほぼ均等 評価指標
目次 1. コンペ概要 2. 我々の solution を簡単に • うまくいかなかったこと,その中でも学びになったこと,しくじりを 重点的に
• 上位解法にも触れます 3. しくじりから次にどう生かすか
• やったこと • NN モデルの試行錯誤 • 特徴量エンジニアリング • Pseudo-labeling(有効ではなかった) •
アンサンブル • GNN(しかし,取り掛かりが遅かった..) • できていなかったこと • ターゲットのカスタマイズ ・・・ • 合成データ作成論文を読んでいない・・・ • TabM 知らなかった・・・ P しくじりポイント サマリ
• やったこと • NN モデルの試行錯誤 • 特徴量エンジニアリング • Pseudo-labeling •
アンサンブル • GNN(しかし,取り掛かりが遅かった..) • できていなかったこと • ターゲットのカスタマイズ ・・・ • 合成データ作成論文を読んでいない・・・ • TabM 知らなかった・・・ P しくじりポイント サマリ
• 補助ロス • 複数ターゲットを予測するヘッドを導入. • CV は上がるも,LB は下がる.→ わからなくなる. 実験していたシードでCVが上がっていただけだった.5シードくらいの
平均を取ると,有意な差はなかった. そもそもシードによってCVがぶれる(±0.02くらい)ターゲットを疑うべ き.lifelines,公開ノートのターゲットを信じ切ってしまっていた. ロスはどれも下がっていたので,センスとしては良いと勘違いしていた. efs_time ロス quantile ロス KaplanMeier ロス efs ロス (BCE) NN モデルの試行錯誤
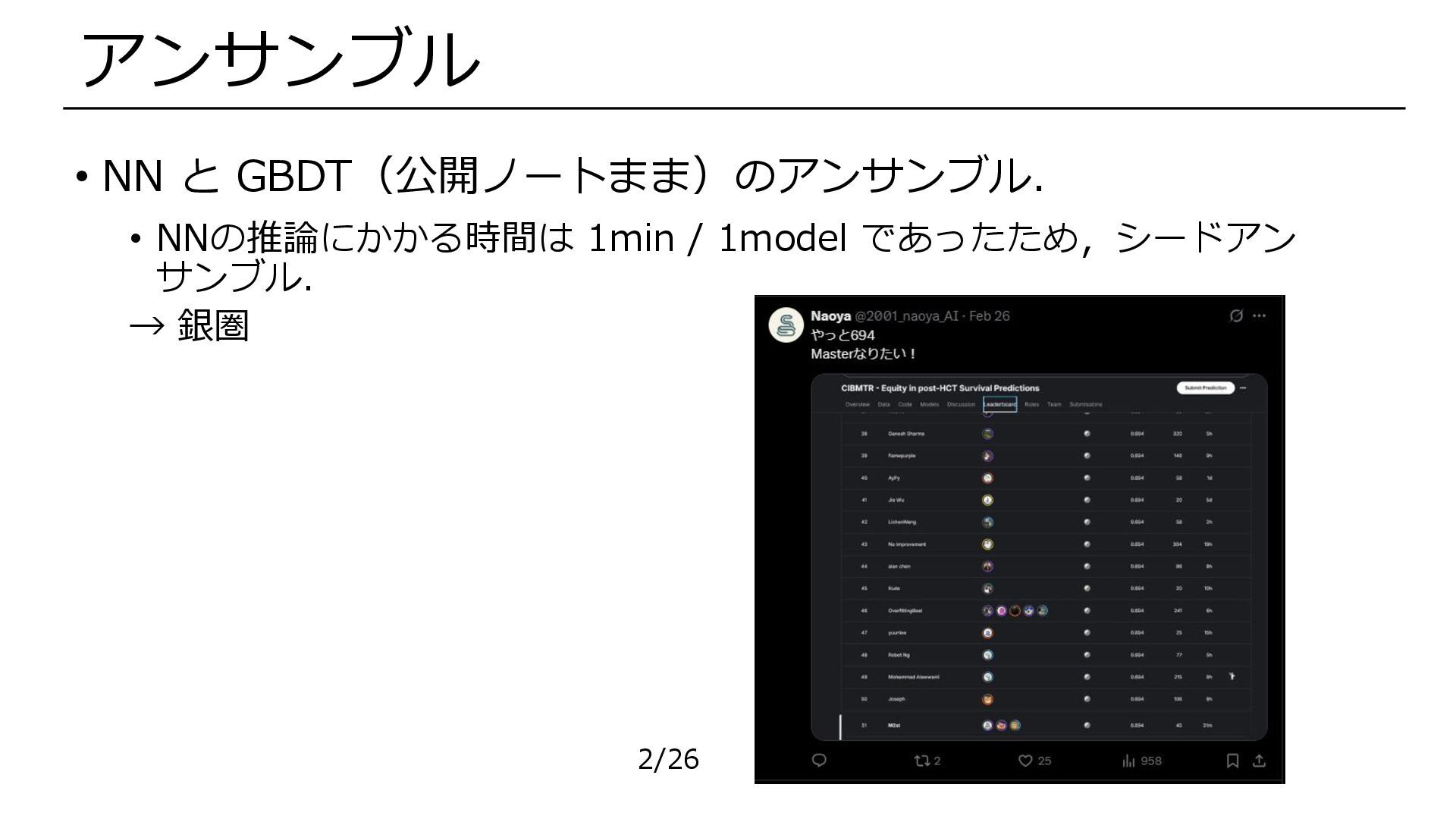
• NN と GBDT(公開ノートまま)のアンサンブル. • NNの推論にかかる時間は 1min / 1model であったため,シードアン
サンブル. → 銀圏 アンサンブル 2/26
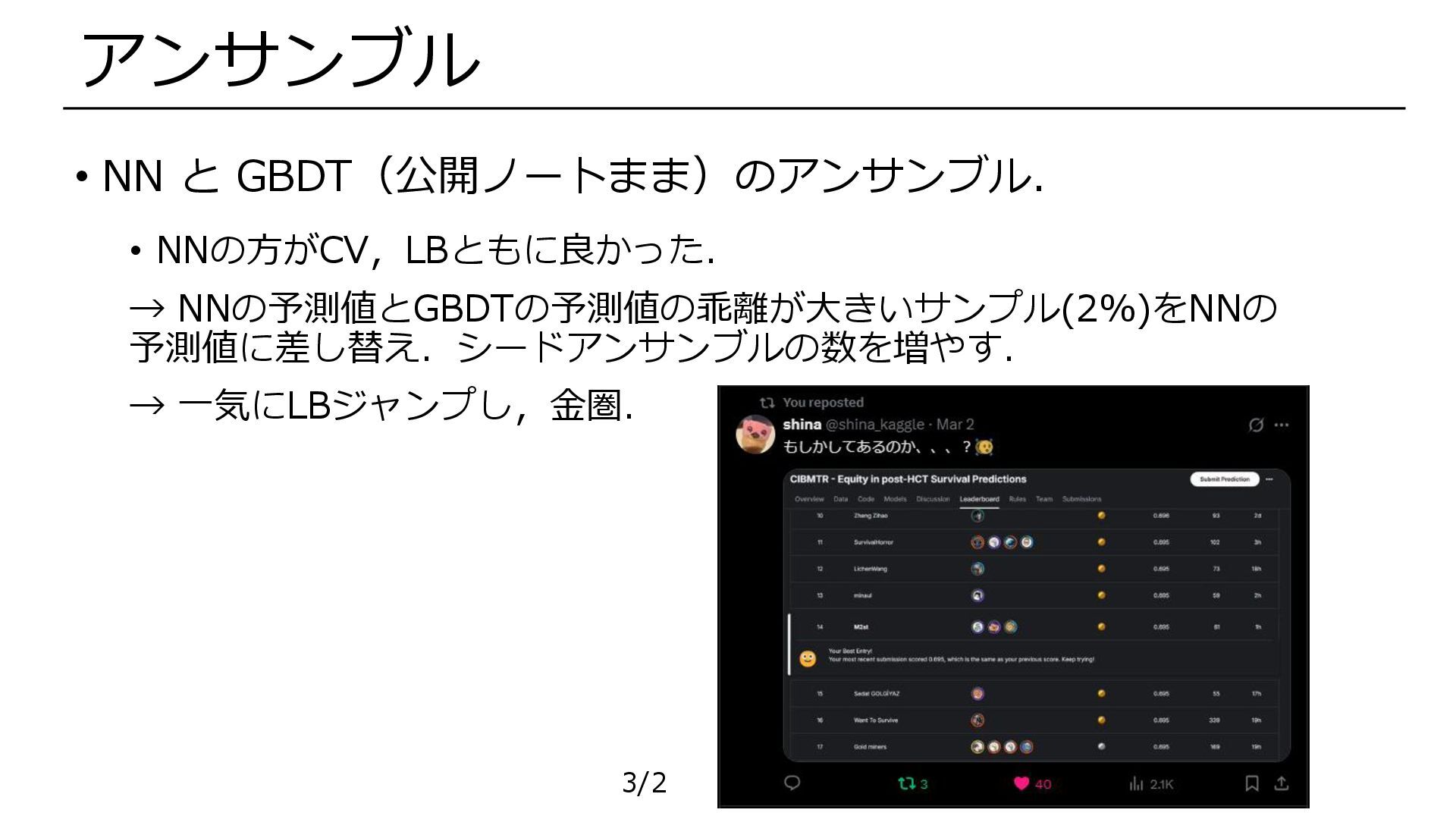
• NN と GBDT(公開ノートまま)のアンサンブル. • NNの方がCV,LBともに良かった. → NNの予測値とGBDTの予測値の乖離が大きいサンプル(2%)をNNの 予測値に差し替え.シードアンサンブルの数を増やす. →
一気にLBジャンプし,金圏. アンサンブル 3/2
• NN と GBDT(公開ノートまま)のアンサンブル. • NNの推論にかかる時間は 1min / 1model であったため,シードアン
サンブル. → 銀圏 • NNの方がCV,LBともに良かった. → NNの予測値とGBDTの予測値の乖離が大きいサンプル(2%)をNNの 予測値に差し替え.シードアンサンブルの数を増やす. → 一気にLBジャンプし,金圏. • アンサンブルゲーか?と判断し,せっせとアンサンブルの種を作る. • 直前に出てた CZII が Trust LB だったこともあり,引っ張られた. アンサンブル
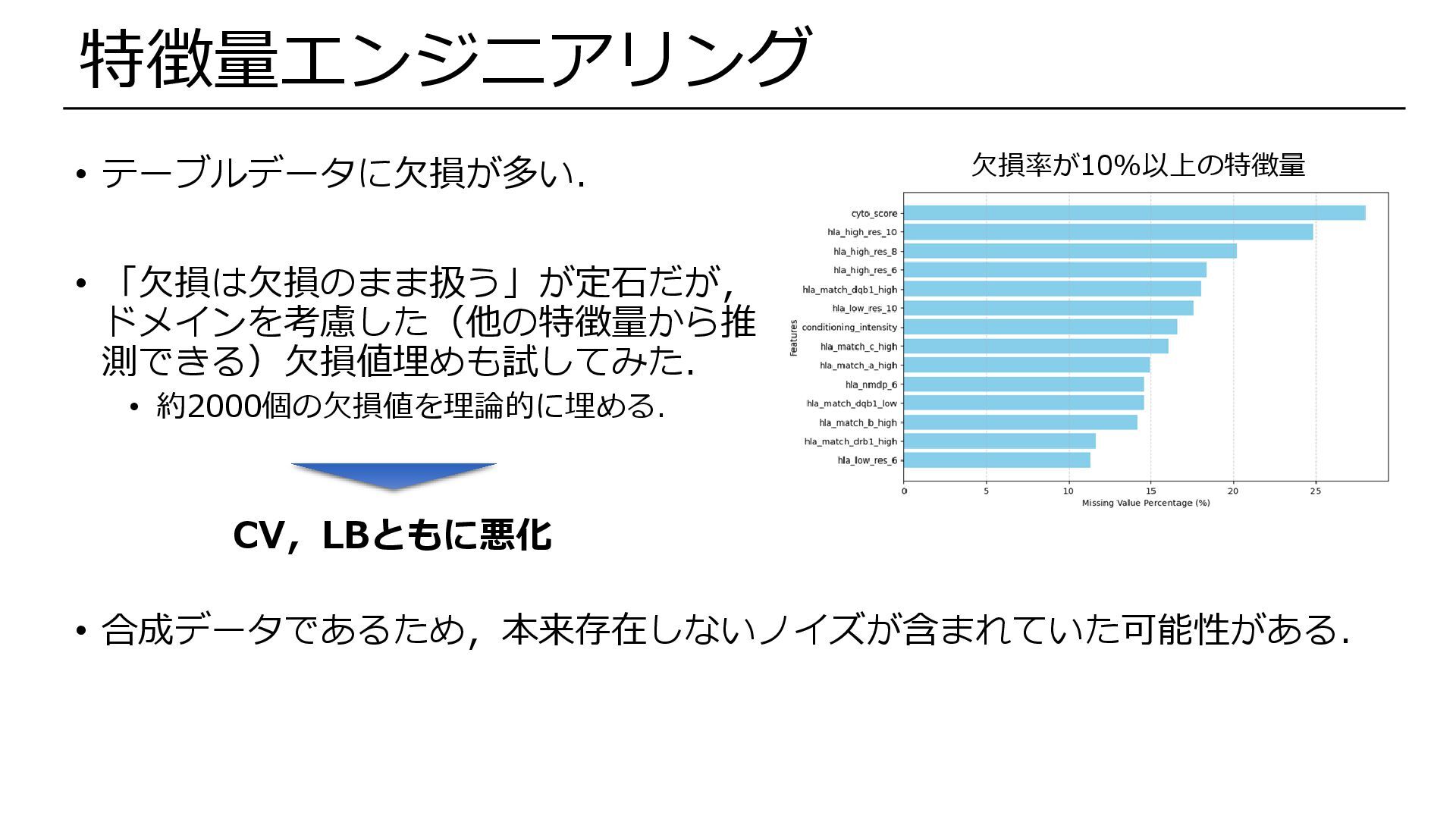
• テーブルデータに欠損が多い. • 「欠損は欠損のまま扱う」が定石だが, ドメインを考慮した(他の特徴量から推 測できる)欠損値埋めも試してみた. • 約2000個の欠損値を理論的に埋める. 欠損率が10%以上の特徴量 特徴量エンジニアリング
CV,LBともに悪化 • 合成データであるため,本来存在しないノイズが含まれていた可能性がある.
• やったこと • NN モデルの試行錯誤 • 特徴量エンジニアリング • Pseudo-labeling •
アンサンブル • GNN(しかし,取り掛かりが遅かった..) • できていなかったこと • ターゲットのカスタマイズ ・・・ • 合成データ作成論文を読んでいない・・・ • TabM 知らなかった・・・ P しくじりポイント サマリ
• 1st, 2nd も含め,上位チームには共通点がある. 1. 2つのタスクに分割 • 分類:efs==1 か efs==0
か • 回帰:efs_time を予測(efs==0 のサンプルも使う,1st ) 2. 2つのモデルの合成 • 2つのモデル出力を統合し,最終のリスクスコア(あるいは順位)を生成. 発想の背景:コンペデータが SurvivalGAN で生成されており,efs==0 のサンプルにも実際の死亡時刻と相関する特徴が残っている.(論文) 「検閲データ=まったく未知」ではなく,分類や回帰の学習材料となり うる. 我々は読めてなかった. ターゲットのカスタマイズ 我々は NN の補助ロス として加えているだけ だった.
• 論文リンク(https://arxiv.org/abs/2410.24210) 2024/10 月発表 • 概要:GBDTで行っているようなアンサンブルをNNで実施することで精度を 高める手法.最終的に複数のモデルが生成される. • 本コンペでは,1st ,4th
などで使われている. • UMコンペの 1st ソリューションで使われている. https://www.kaggle.com/competitions/um-game-playing-strength-of-mcts-variants/discussion/549801 • 他コンペでも,今後は上位ソリューションをチェックしていきたい. • 順位に直結したというわけではないが,選択肢の一つとして覚えておきたい. • GraphSAGE なども初見(2nd ). TabM 知らなかった.
目次 1. コンペ概要 2. 我々の solution を簡単に • うまくいかなかったこと,その中でも学びになったこと,しくじりを 重点的に
• 上位解法にも触れます 3. しくじりから次にどう生かすか ※個人的な意見が多めとなっています.
• ターゲットの決め方が重要と理解していながら,lifelines で提供されている ターゲット変換と公開コードに依存していた. • NN モデルの CV が,シードによってぶれる(±0.02くらい)ことに対する考察を行って いなかった.
• 専用ライブラリだから,「とりあえずこれでいいでしょ」となってしまっていた. • コンペデータを作成した SurvivalGAN の元論文を読んでいなかった. • これは言い訳のしようがない. • “検閲データも,分類や回帰の学習材料となりうる” ことを見逃していた. • アンサンブルで金圏まで上がった(上がってしまった)ため,楽をしようと してしまった. • アンサンブルの種をできるだけ多く推論させるため,コンペ終盤は推論時間を短縮する 実装に時間をかけてしまった. • 直前に出ていたコンペ(CZII)が LB Trust だったため,引っ張られた. 今回のしくじりまとめ
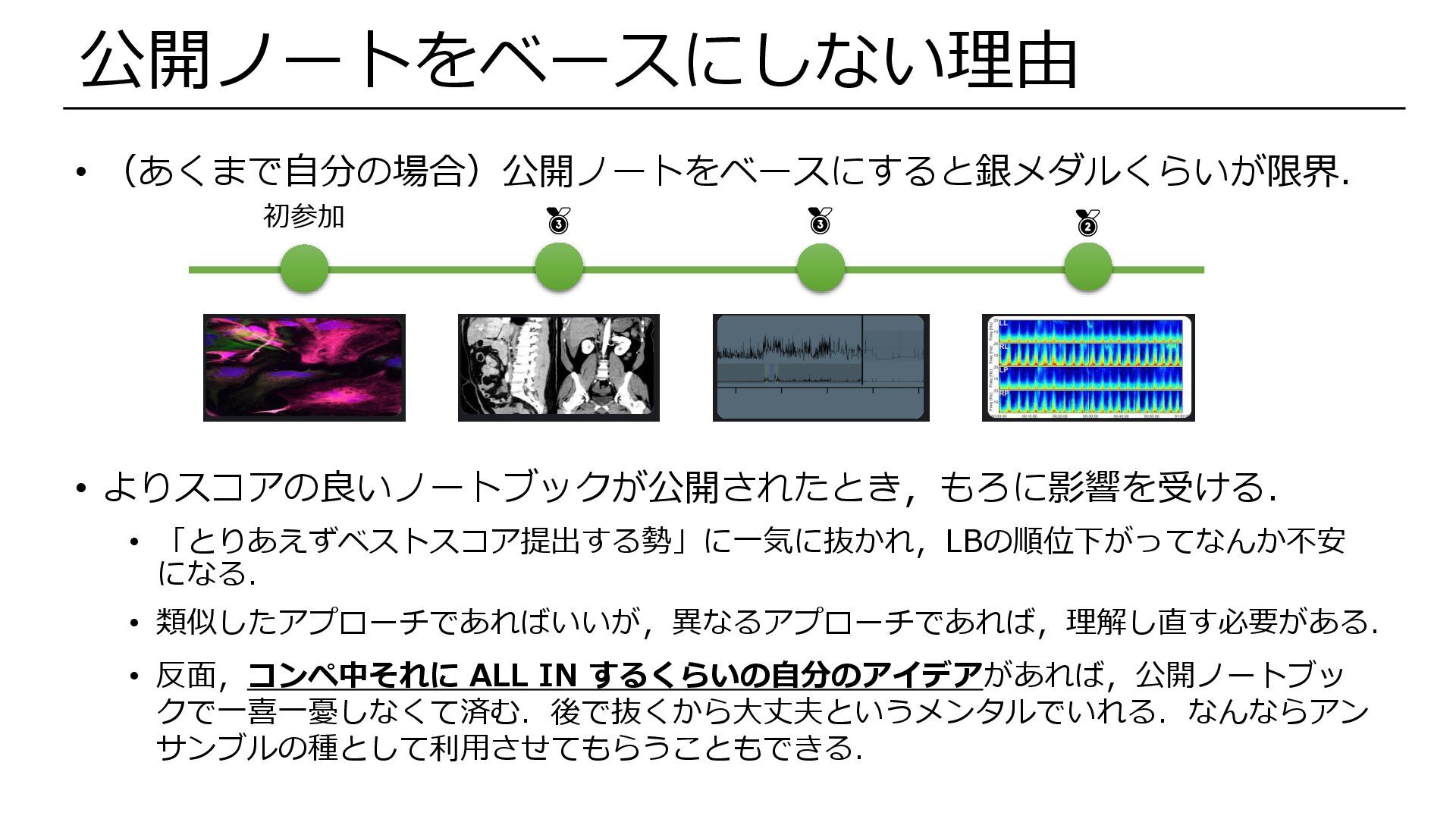
• 金メダルを目指すなら,公開ノートをベースにしない.(自分には向いていない) • 今回のしくじりの多くは,公開ノートをベースにせずにいちからコンペを理解して始めてい れば,防げた可能性が高い. • 今回公開ノートをベースにした理由 1. 参加時(終了約1か月前)の時点でスコアが詰まっており,公開ノートを改善すれば上位 が狙えそう.←
これシンプルに甘い. 2. 生存時間解析はドメイン外で,キャッチアップに時間がかかりそうだったため.← これが 本来のコンペの楽しみでは? あと,学生だし普通に時間は作れた. 3. Master になるという目標にとらわれていた.← 銀メダル以上で Master になれる状況 だったので,公開ノートをベースに楽して Master になろうとしてしまった. 同じしくじりをしないために 詰まっているということは,特にトリックがない?
• (あくまで自分の場合)公開ノートをベースにすると銀メダルくらいが限界. • よりスコアの良いノートブックが公開されたとき,もろに影響を受ける. • 「とりあえずベストスコア提出する勢」に一気に抜かれ,LBの順位下がってなんか不安 になる. • 類似したアプローチであればいいが,異なるアプローチであれば,理解し直す必要がある. •
反面,コンペ中それに ALL IN するくらいの自分のアイデアがあれば,公開ノートブッ クで一喜一憂しなくて済む.後で抜くから大丈夫というメンタルでいれる.なんならアン サンブルの種として利用させてもらうこともできる. 公開ノートをベースにしない理由 初参加 🥉 🥉 🥈
• RSNA 2024 コンペでは,Code・Discussion を見ずに,序盤から自分たちの アイデアを信じ切ったことで,金メダル獲得につながった. • もちろんクリティカルに効いてくる情報を逃したくはないので, Code・Discussion に
はざっと目を通してはいた. • まともなスコアが出るまでは結構大変(我々は数か月かかった)だが,うまく軌道に乗っ てくるとさらなるスコアの向上までが早い.submission の作り方などは公開ノートを参 考にさせていただいた. • もちろん終盤の yyama さん,yumeneko さんとのチームマージも大きな要因.チーム マージ時にも,独自の手法であればあるほどアンサンブルするだけでスコアが向上する可 能性が高い.実際に結構伸びた. • 公開ノートを参考にして負けたとき,悪い意味であまり悔しくなれない. • アイデア勝負で負けたのであればちゃんと悔しいはず. 公開ノートをベースにしなかった成功体験
• 金圏くらいのスコアが出るまでおとなしく late sub します. • チームで CIBMTR 振り返り会を 3/14(金)20:00~21:00
で 行う予定 (google meet) なので,もし参加したい方いれば話しかけてください!どな たでも大歓迎です! Next Action
上位解法を簡単に
① Classifier • ターゲット:efs=0 の確率 • 目的:「まだ死亡イベントが確定していない」サンプル(右検閲)を判別. • 使用モデル:XGBoost, LightGBM,
CatBoost, NN, GNN, TabNet, TabM など多種 ② Regressor • ターゲット:efs_time を (efs==1), (efs==0) 各グループでランク ⇒ 正規化 • 目的:「死亡 (efs==1) の時刻」を正しく順位付け ⇒ 短期死亡リスクを明確に • 最終合成 • 両モデル出力を モデルマージ(非線形合成)で統合 • Optuna で3つのパラメータを最適化. 1st place solution:分類+回帰の二軸アプローチで検閲を最大活用 https://www.kaggle.com/competitions/equity-post-HCT-survival-predictions/discussion/56655
① Classifier (efs=0/1) • 使用モデル:RealMLP,HistGBM,CatBoost など ② Regressor (efs_time |
efs=1) • 目的:死亡確定サンプルの死亡時刻を推定 • 使用モデル:XGBoost,HistGBM(特徴量に efs を追加) • 推論時の工夫:すべてのサンプルに対して efs=1 と仮定し,「もし死ぬなら何か月 目?」を回帰 • リスクスコアの計算 • 合成式:𝑅 = 𝑝 𝑒𝑓𝑠 = 1 × 𝜎(− 回帰予測 ) • 死亡確率が高く,かつ死亡時刻が近いほどリスクが高い. • Stratified C-index を直接近似する NN を別途学習. 2nd place solution:分類+回帰の二軸,リスクスコアのNN回帰 https://www.kaggle.com/competitions/equity-post-HCT-survival-predictions/discussion/566522
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}