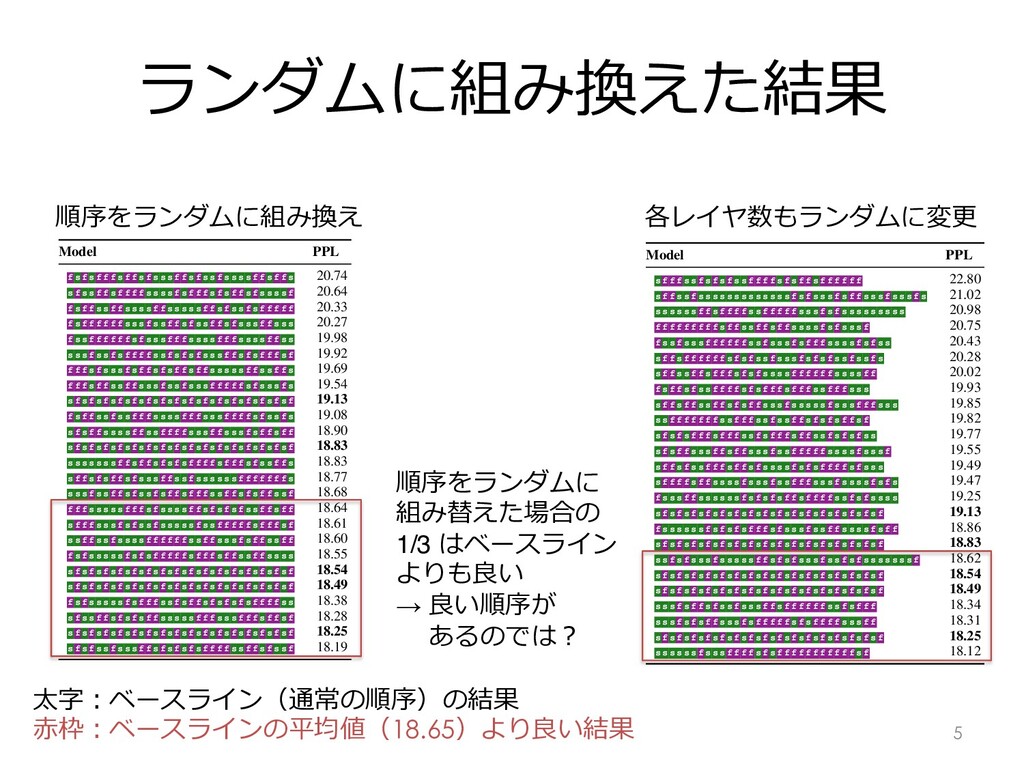
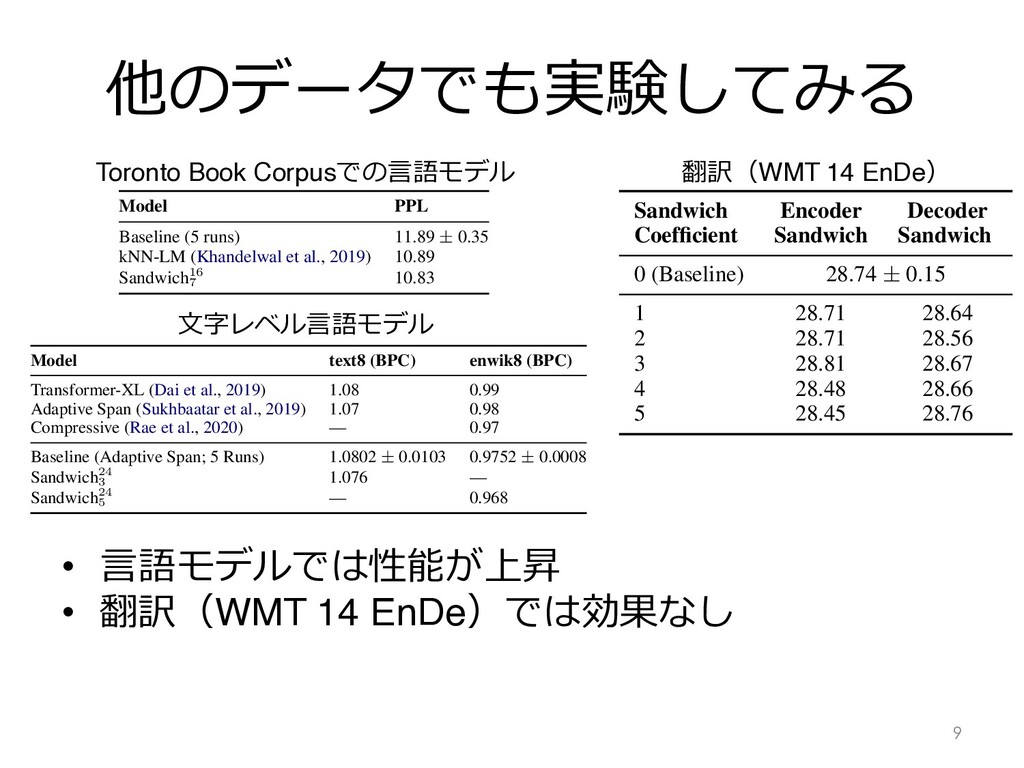
Baseline (5 runs) 11.89 ± 0.35 kNN-LM (Khandelwal et al., 2019) 10.89 Sandwich16 7 10.83 Table 4: Performance on the Toronto Books Corpus lan- guage modeling test set. The baseline model (Baevski and Auli, 2019) is trained over 5 random seeds. The sandwich coefficient is tuned on the validation set and we run our model on the test set only once. 5.1 Books-Domain Language Modeling We first apply sandwich transformers to a differ- ent domain, while retaining the other architectural aspects and hyperparameter settings from Baevski and Auli (2019). Specifically, we use the Toronto Books Corpus (Zhu et al., 2015), which has previ- ously been used to train GPT (Radford et al., 2018) and also BERT (Devlin et al., 2019) (combined with Wikipedia). The corpus contains roughly 700M tokens. model learns to control each attention head’s maxi- mal attention span, freeing up memory in the bot- tom layers (which typically need very short atten- tion spans) and applying it to the top layers, allow- ing the top-level attention heads to reach signifi- cantly longer distances. The adaptive span model’s efficient use of attention also results in a significant speed boost. We tune the sandwich coefficient on the devel- opment set for k 2 {1, . . . , 8} (the baseline model has 24 transformer layers). We do not modify any hyperparameters, including the number of training epochs. Table 5 compares the baseline model’s performance with the sandwich transformer’s. On text8, the sandwich transformer performs within the baseline’s random seed variance. On enwik8, the sandwich transformer gains an improvement of about 0.007 bits-per-character, matching the state of the art results obtained by the Transformer- XL-based Compressive Transformer of Rae et al. (2020). Toronto Book Corpusでの⾔語モデル Model text8 (BPC) enwik8 (BPC) Transformer-XL (Dai et al., 2019) 1.08 0.99 Adaptive Span (Sukhbaatar et al., 2019) 1.07 0.98 Compressive (Rae et al., 2020) — 0.97 Baseline (Adaptive Span; 5 Runs) 1.0802 ± 0.0103 0.9752 ± 0.0008 Sandwich24 3 1.076 — Sandwich24 5 — 0.968 mance on character-level language modeling, evaluated on the enwik8 and text8 test sets. The Sukhbaatar et al., 2019) is trained over 5 random seeds. The sandwich coefficient is tuned on each idation set, and we run our model on the test only once. s) and cross-attention (c) sublay- hem as a single unit for reordering For example, a three layer decoder ) with a sandwiching coefficient of be: scscfscff. We apply the Sandwich Encoder Decoder Coefficient Sandwich Sandwich 0 (Baseline) 28.74 ± 0.15 1 28.71 28.64 2 28.71 28.56 ⽂字レベル⾔語モデル Sandwich24 5 — 0.968 e 5: Performance on character-level language modeling, evaluated on the enwik8 and text8 test sets ine model (Sukhbaatar et al., 2019) is trained over 5 random seeds. The sandwich coefficient is tuned o hmark’s validation set, and we run our model on the test only once. attention (s) and cross-attention (c) sublay- and treat them as a single unit for reordering oses (sc). For example, a three layer decoder fscfscf) with a sandwiching coefficient of 1 would be: scscfscff. We apply the wich pattern to either the encoder or decoder rately, while keeping the other stack in its orig- interleaved pattern. eriment Setting As a baseline, we use the e transformer model (6 encoder/decoder layers, edding size of 1024, feedforward inner dimen- of 4096, and 16 attention heads) with the hy- arameters of Ott et al. (2018). We also follow setup for training and evaluation: we train he WMT 2014 En-De dataset which contains M sentence pairs; we validate on newstest13 and Sandwich Encoder Decoder Coefficient Sandwich Sandwich 0 (Baseline) 28.74 ± 0.15 1 28.71 28.64 2 28.71 28.56 3 28.81 28.67 4 28.48 28.66 5 28.45 28.76 Table 6: BLEU on newstest2014 En-De. Our en (decoder) sandwich model keeps the decoder (en unmodified. We train the baseline model (Transf large with the hyperparameters of Ott et al., 20 times with different random seeds. mance degradation. Since the sandwich p naively groups self- and cross-attention sub together, it is also possible that a reorderin 翻訳(WMT 14 EnDe)
{kind=link}
![概要 • Transformer [Vaswani+ 17] の Self-attention(s) FeedForward(f)部分の順序を組み替えてみる • ⾔語モデルでは](https://files.speakerdeck.com/presentations/61970620efba4a18b64f5c750043ccb2/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}