Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
snlp2024_multiheadMoE
Search
Sho Takase
August 25, 2024
Research
720
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
snlp2024_multiheadMoE
Sho Takase
August 25, 2024
More Decks by Sho Takase
See All by Sho Takase
snlp2025_prevent_llm_spikes
takase
0
510
snlp2023_beyond_neural_scaling_laws
takase
0
450
snlp2023_rogue_scores
takase
0
450
[SNLP2022] ABC: Attention with Bounded-memory Control
takase
0
450
SNLP2020_mixtext
takase
0
370
SNLP2020_sandwich
takase
0
370
ニューラル言語モデルの 研究動向(NL研招待講演資料)
takase
12
5.3k
Other Decks in Research
See All in Research
GLIM とMegaParticles:正規分布近似の限界とタイトカップリング&パーティクルフィルタの進展 / GLIM and MegaParticles : Progress of the distribution representation in SLAM
koide3
0
500
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
270
医療LLMの現在地〜最新研究から社会実装までを考える〜
kento1109
1
1.5k
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
130
Spatial Active Noise Control Based on Sound Field Interpolation Incorporating Physical Constraints
skoyamalab
0
120
Scalable dynamic origin-destination demand estimation enhanced by high-resolution satellite imagery data
satai
3
320
IA for theory
gpeyre
0
240
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
6
2.4k
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
kobayashi31
1
160
正規分布と最適化について
koide3
1
290
第66回コンピュータビジョン勉強会@関東 Epona: Autoregressive Diffusion World Model for Autonomous Driving
kentosasaki
0
650
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
1k
Featured
See All Featured
My Coaching Mixtape
mlcsv
0
170
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Navigating Weather and Climate Data
rabernat
0
280
Building Adaptive Systems
keathley
44
3.1k
Technical Leadership for Architectural Decision Making
baasie
3
430
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Paper Plane
katiecoart
PRO
1
52k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Transcript
Multi-Head Mixture-of-Experts Xun Wu, Shaohan Huang, Wenhui Wang, Furu Wei
読む⼈︓⾼瀬翔(SB Intuitions) 2024/8/25 1
Mixture-of-Experts(MoE)とは(1/2) • 通常︓任意のタスクを1つのモデルで解く – MoE の⽂脈では Dense と呼ばれる 2 Denseモデル︓
1つの(巨⼤な) モデルですべて解く
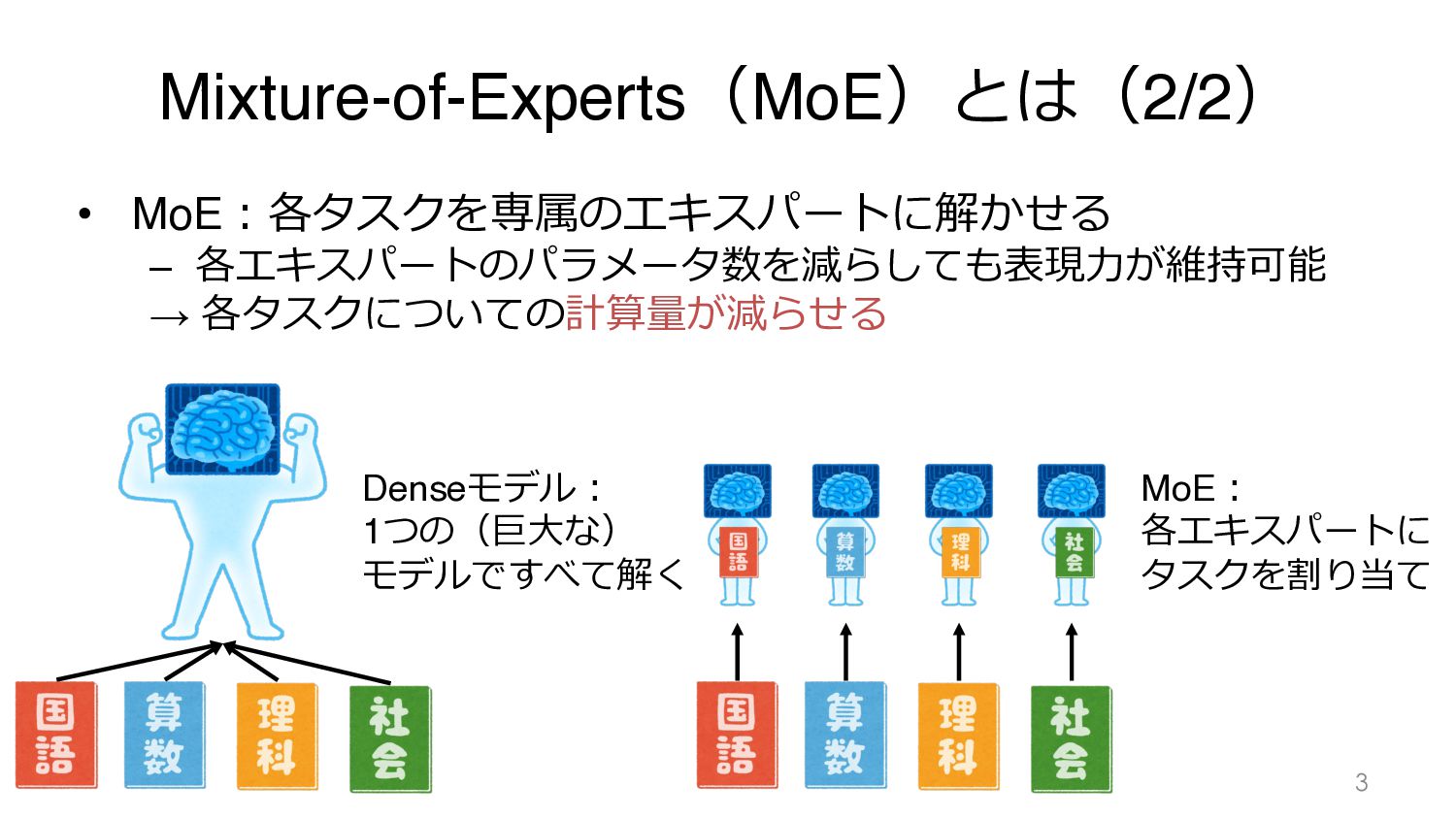
Mixture-of-Experts(MoE)とは(2/2) • MoE︓各タスクを専属のエキスパートに解かせる – 各エキスパートのパラメータ数を減らしても表現⼒が維持可能 → 各タスクについての計算量が減らせる 3 Denseモデル︓ 1つの(巨⼤な)
モデルですべて解く MoE︓ 各エキスパートに タスクを割り当て
Transformer に導⼊する場合 • FFN層をエキスパートとして複数⽤意 – N 個のエキスパートから k 個を使う •
⼊⼒トークンごとにエキスパートを使い分ける – Router が確率を付与,確率上位 k の重み付き和を出⼒ 4 Attn Router FFN1 FFN2 FFN3 0.4 0.5 0.1 MoE を含んだ場合の Transformer 層 (N = 3, k = 2) 出⼒︓0.4 × FFN1 + 0.5 × FFN2 確率の低い FFN3 は計算しない
LLM における MoE 流⾏のきざし • GPT-4 が MoE を採⽤しているという噂 •
Mixtral 8×7BがLlama2 70B,GPT-3.5と同等の性能 • Denseモデルよりも常に良いという報告 [Clark+ 22, Krajewski+ 24] • ⽇本での動き – LLM-jp が⼤規模パラメータのモデルに採⽤予定 – PFN が 1Tパラメータ規模の MoE モデルを学習・検証 • 三上さんのPFNブログ記事︓https://tech.preferred.jp/ja/blog/pretraining-1t/ • MoE を使っていく⽅向性が妥当なのだろうか︖という疑問も – MoE による巨⼤モデルの実現という⽅針⾃体、⾒直す必要があるのか もしれません。(上記ブログ記事より) 5
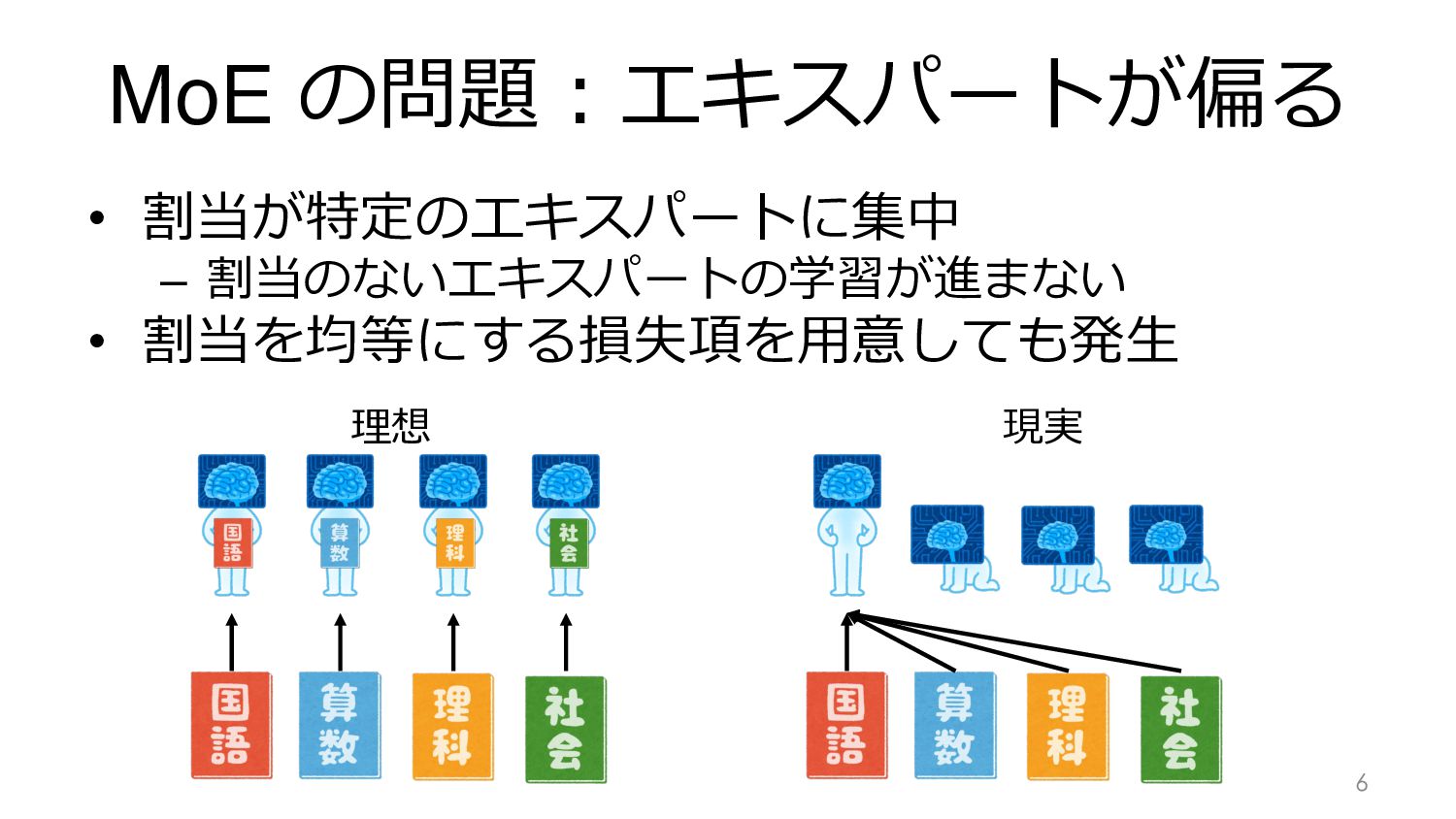
MoE の問題︓エキスパートが偏る • 割当が特定のエキスパートに集中 – 割当のないエキスパートの学習が進まない • 割当を均等にする損失項を⽤意しても発⽣ 6 理想
現実
エキスパートの偏りへの対処 • 割当を均等にする損失項(load balancing loss)を使⽤ – ただし,使っても発⽣すると報告されている • 均等になるよう強制する –
系列全体で各エキスパートの使⽤が均等になるよう調整 [Zhou+ 22] – 学習を⾏わず,⼊⼒トークンのハッシュ値を元に割当 [Roller+ 21] • エキスパートの表現⼒を調整する [Dai+ 24] – 強すぎるエキスパートの存在が偏りを発⽣させるという仮定 – 各エキスパートのパラメータ数を減らし,表現⼒を減らす – エキスパートの数と割当数(N と k)を増やして全体の表現⼒維持 – 本論⽂(Multi-head MoE)もこの思想 7
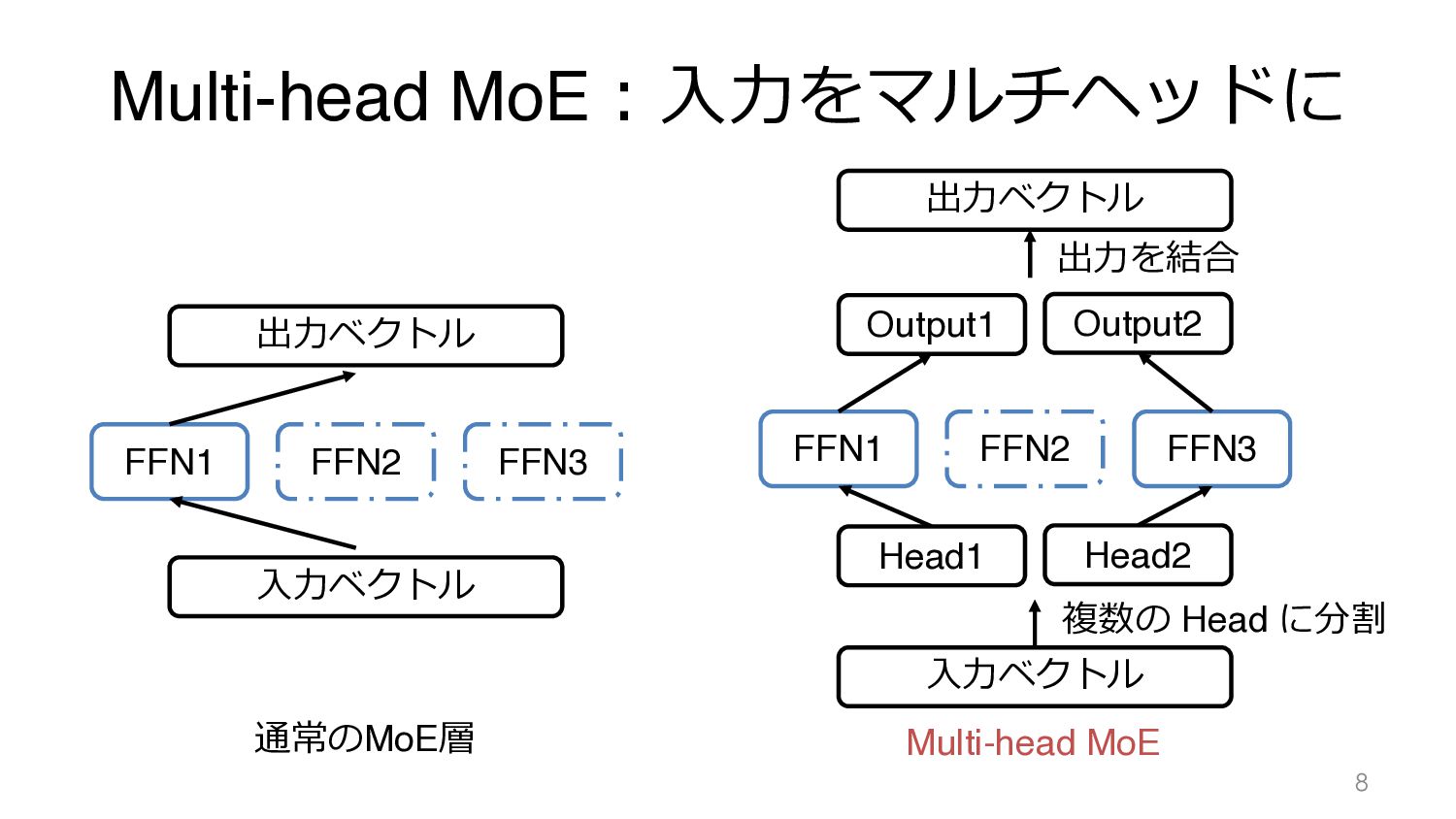
Multi-head MoE︓⼊⼒をマルチヘッドに 8 FFN1 FFN2 FFN3 ⼊⼒ベクトル 出⼒ベクトル FFN1 FFN2
FFN3 ⼊⼒ベクトル 出⼒ベクトル Head1 Head2 Output1 Output2 通常のMoE層 複数の Head に分割 出⼒を結合 Multi-head MoE
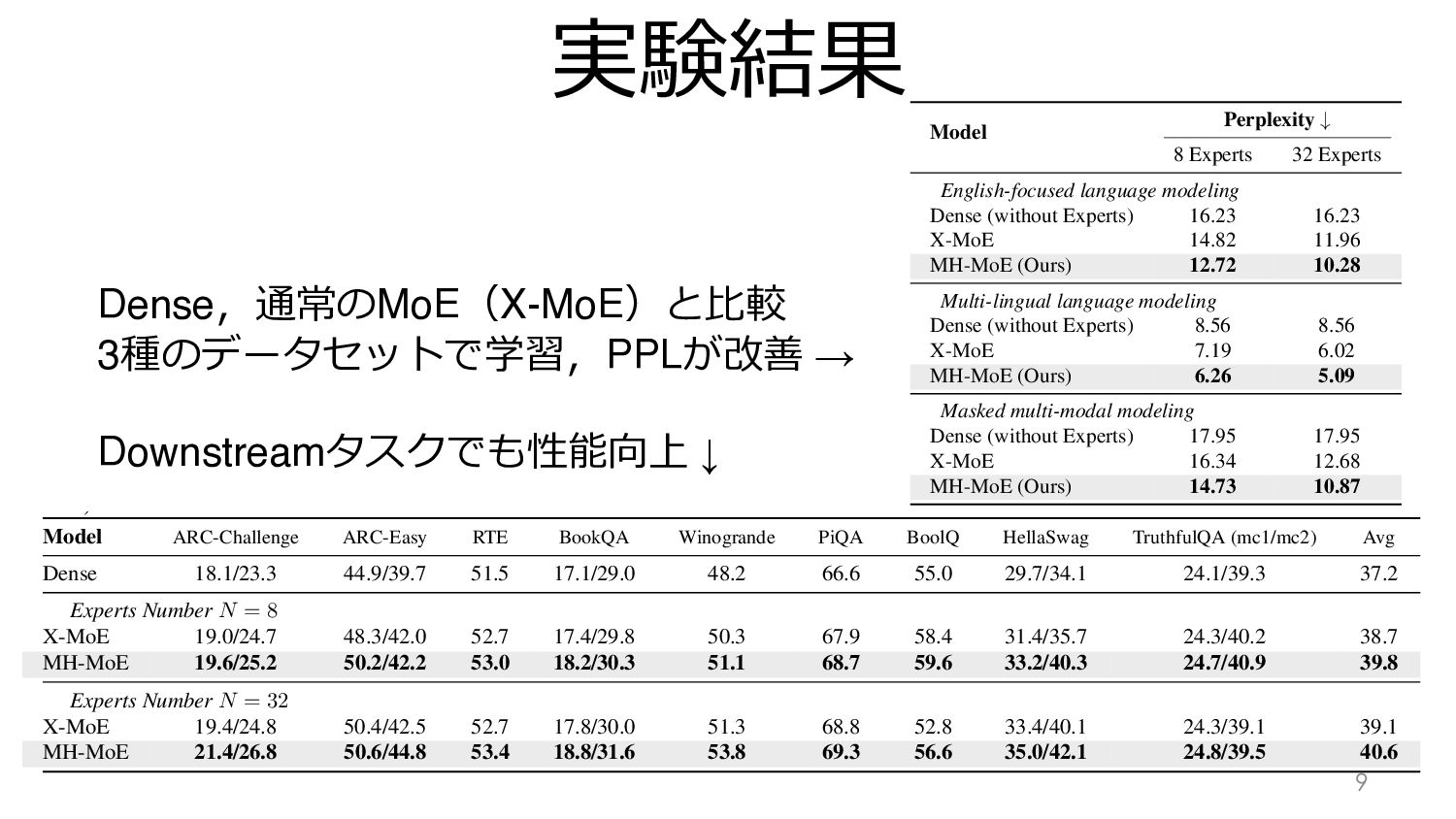
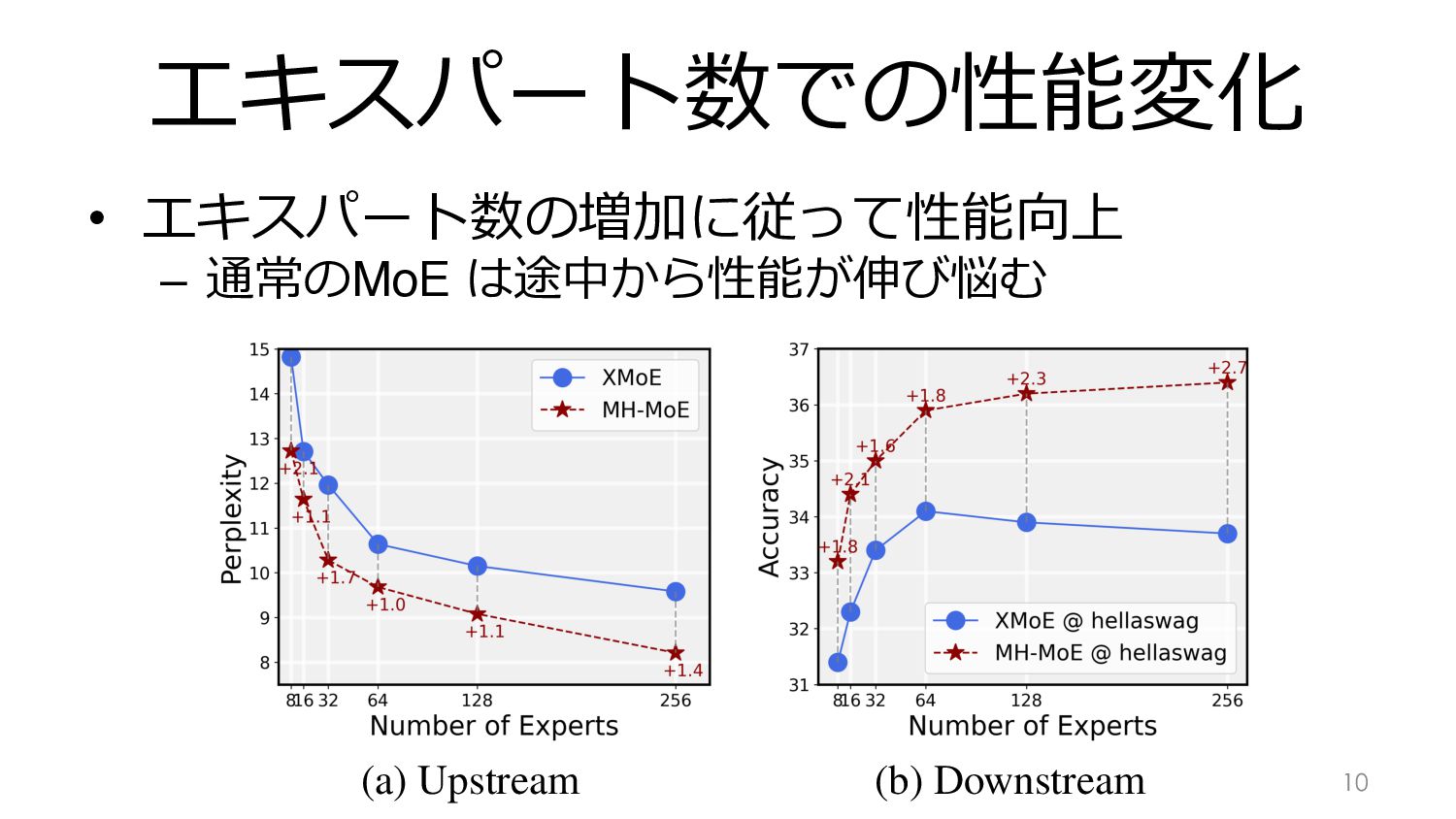
実験結果 9 Multi-Head Mix Table 1. Results of upstream perplexity
evaluation. We report the validation perplexity cross two setting: 8 experts and 32 experts. Model Perplexity # 8 Experts 32 Experts English-focused language modeling Dense (without Experts) 16.23 16.23 X-MoE 14.82 11.96 MH-MoE (Ours) 12.72 10.28 Multi-lingual language modeling Dense (without Experts) 8.56 8.56 X-MoE 7.19 6.02 MH-MoE (Ours) 6.26 5.09 Masked multi-modal modeling Dense (without Experts) 17.95 17.95 X-MoE 16.34 12.68 MH-MoE (Ours) 14.73 10.87 efits from enhanced representation learning capabilities as more experts are incorporated. These results collectively demonstrate the superiority of MH-MoE in terms of learn- ing efficiency and language representation across multiple pre-training paradigms. 4.3. Downstream Evaluation For each pre-training task, we conduct corresponding downstream evaluation to validate the efficacy of MH- MoE. Multi-Head Mixture-of-Experts Table 2. Accuracy / accuracy-normalization scores for language understanding tasks using the LLM Evaluation Harness (Gao et al., 2023). Model ARC-Challenge ARC-Easy RTE BookQA Winogrande PiQA BoolQ HellaSwag TruthfulQA (mc1/mc2) Avg Dense 18.1/23.3 44.9/39.7 51.5 17.1/29.0 48.2 66.6 55.0 29.7/34.1 24.1/39.3 37.2 Experts Number N = 8 X-MoE 19.0/24.7 48.3/42.0 52.7 17.4/29.8 50.3 67.9 58.4 31.4/35.7 24.3/40.2 38.7 MH-MoE 19.6/25.2 50.2/42.2 53.0 18.2/30.3 51.1 68.7 59.6 33.2/40.3 24.7/40.9 39.8 Experts Number N = 32 X-MoE 19.4/24.8 50.4/42.5 52.7 17.8/30.0 51.3 68.8 52.8 33.4/40.1 24.3/39.1 39.1 MH-MoE 21.4/26.8 50.6/44.8 53.4 18.8/31.6 53.8 69.3 56.6 35.0/42.1 24.8/39.5 40.6 Table 3. Accuracy / accuracy-normalization scores on multilingual understand- Dense,通常のMoE(X-MoE)と⽐較 3種のデータセットで学習,PPLが改善 → Downstreamタスクでも性能向上 ↓
エキスパート数での性能変化 • エキスパート数の増加に従って性能向上 – 通常のMoE は途中から性能が伸び悩む 10 X-MoE - -
14.82 MH-MoE 2 384 12.87 4 192 12.72 6 128 12.41 8 96 12.95 12 64 13.28 Model MLP TSM Dense 7 7 Densew/ MLP 3 7 X-MoE 7 7 X-MoEw/ MLP 3 7 MH-MoEw/o TS 3 7 MH-MoEw/o MLP 7 3 MH-MoE 3 3 (a) Upstream (b) Downstream 100k Figure
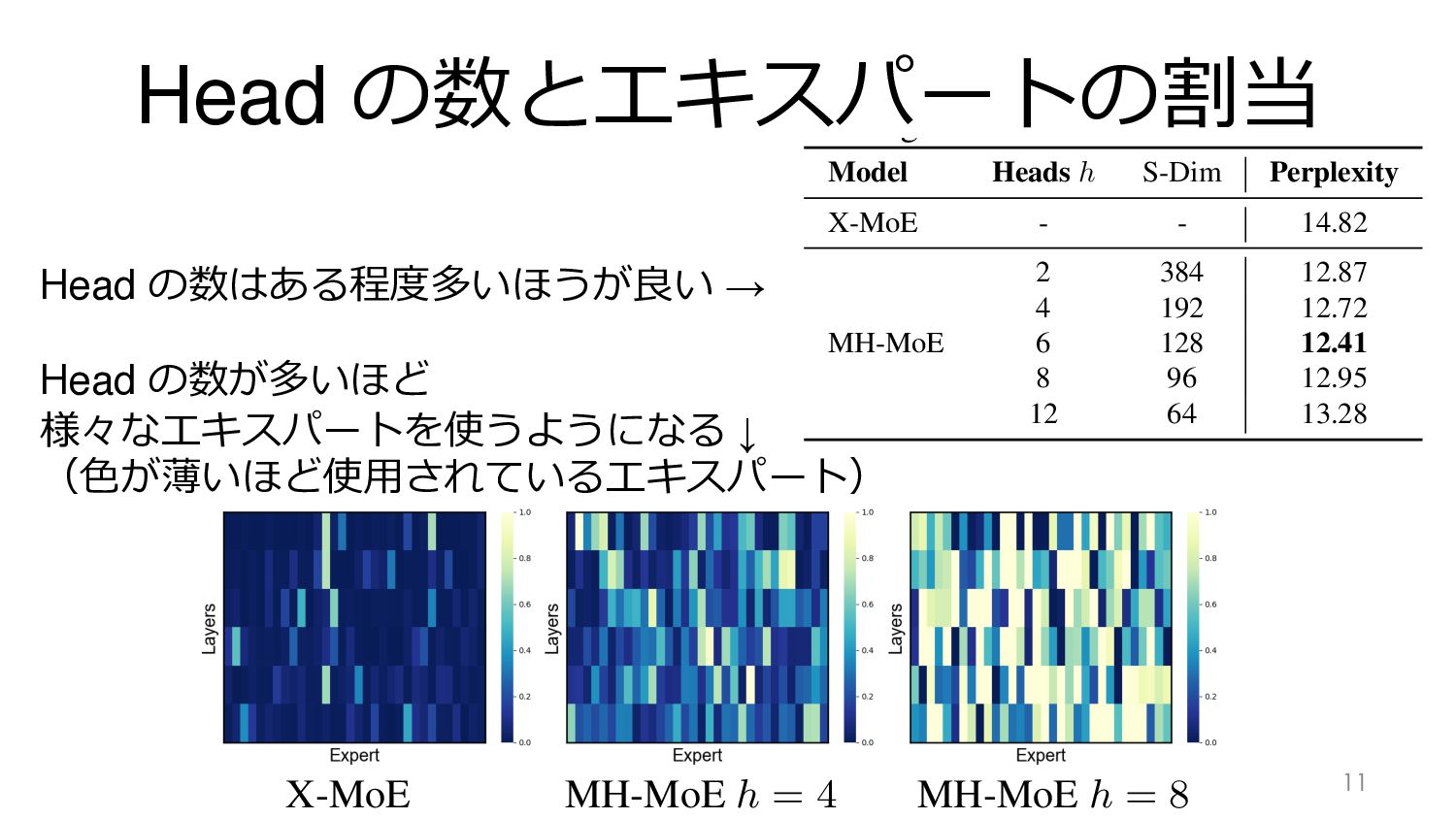
Head の数とエキスパートの割当 11 Table 5. Comparison results for different head
number h. S-Dim denotes the dimen- sion length of sub-tokens. Model Heads h S-Dim Perplexity X-MoE - - 14.82 MH-MoE 2 384 12.87 4 192 12.72 6 128 12.41 8 96 12.95 12 64 13.28 T p S o X-MoE 33.9 33.4 33.4 37.3 33.3 35.9 34.5 35.0 33.5 33.6 33.4 34.2 33.3 33.2 34.1 MH-MoE 34.4 33.2 33.9 40.1 34.0 36.4 34.6 35.2 33.8 34.4 33.3 34.7 34.6 33.5 34.7 Experts Number N = 32 X-MoE 34.5 34.5 33.4 39.6 33.1 35.3 34.1 35.4 33.6 34.7 33.7 33.6 34.5 33.3 34.5 MH-MoE 35.8 35.6 34.1 40.7 33.9 36.7 34.4 36.3 34.3 36.0 34.1 34.3 35.2 33.6 35.3 Harness XNLI X-MoE MH-MoE h = 4 MH-MoE h = 8 crease in hanceme both ML pothesiz of MLP, merging abrupt in ability to effective different Head の数はある程度多いほうが良い → Head の数が多いほど 様々なエキスパートを使うようになる ↓ (⾊が薄いほど使⽤されているエキスパート)
本論⽂のまとめ • MoE ではエキスパートへの割当が偏る • 対処法として Multi-head MoE を提案 •
Multi-head MoE により性能向上・割当も改善 – 総計算量は変わらないので悪い点がない – 実装も簡単なのでとりあえず導⼊すると良さそう 12
おまけ︓学習効率改善の技術 • Dense モデルのパラメータの活⽤(Upcycling)[Komatsuzaki+ 23] • 個別に学習して結合︓Branch-Train-Mix [Sukhbaatar+ 24] –
データを N 個に分割し,N 個の LLM を個別に学習 – それぞれの FFN層をエキスパートとみなして MoE層を構築 • 1つの LLM に結合する場合︓Branch-Train-Merge [Li+ 22] 13 Attn FFN 通常の Transformer (Dense)を学習 Attn FFN2 FFN3 FFN1 = = FFN 層を複製して MoE 層を構築
まとめ • MoE の概要とMulti-head MoEの紹介 • MoE は Dense モデルよりも効率が良い
– LLM や基盤モデルの構築で流⾏りつつある • MoE の問題︓エキスパートの割当が偏る – 割当を均等にする研究が盛ん – Multi-head MoE も割当を均等にする効果あり 14
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![おまけ︓学習効率改善の技術 • Dense モデルのパラメータの活⽤(Upcycling)[Komatsuzaki+ 23] • 個別に学習して結合︓Branch-Train-Mix [Sukhbaatar+ 24] –](https://files.speakerdeck.com/presentations/e3aa23b90fbb4d4bb9c9a1bb56ce6a9c/slide_12.jpg){kind=link}
{kind=link}