Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
20240827_LLM発表
Search
takeofuture
August 29, 2024
300
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
20240827_LLM発表
takeofuture
August 29, 2024
More Decks by takeofuture
See All by takeofuture
MarineGym 水中シミュレータ
takeofuture
0
68
BLUVIC(SportへのAI活用)ハッカソン発表資料
takeofuture
0
23
Forklift Goal Condition Reinforcement Learning by Gazebo + ROS2 topic
takeofuture
0
110
ROSAというLLM使ったROSエージェントをおもちゃに実装してみた話
takeofuture
0
250
2025/11/14 ロボセミでの発表資料
takeofuture
0
130
Featured
See All Featured
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
670
Building the Perfect Custom Keyboard
takai
2
820
Are puppies a ranking factor?
jonoalderson
1
3.7k
Embracing the Ebb and Flow
colly
88
5.1k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.2k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
Tell your own story through comics
letsgokoyo
1
1k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.2k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
4k
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
340
Between Models and Reality
mayunak
4
380
Transcript
LLM(+RAG)で数表処理ができるか試してみた? (期待した結果でず 💦) 2024年8月
自己紹介 職歴や経験分野 ▪ SEとして20年近く汎用的なシステム開発 ▪ 先端科学技術と情報技術の融合に興味あり ▪ 現在は本業データサイエンス ▪ 個人プロジェクトで識別
AI、生成AIを5年ほど ▪ 統計や機械学習も少し 柴田 たけお ▪ 愛知県名古屋市生まれ豊田市育ち ▪ 大学は仙台過ごし、大学院は 米国カリフォルニアバークレにて地球物理学専攻 ▪ 現在アメリカカリフォルニア州在住(ロス近郊) ▪ 愛知県の豊田市にある空家に年数回滞在 基本情報 趣味 ▪ キャンプやハイキング、野宿旅行 ▪ 自転車旅行 ▪ 18切符での鈍行列車旅 ▪ 最近は日本の田舎の古民家探 写真
AIでやってきたこと遊んだこと(興味本位のプロジェクトも含む) • 音声認識システム(2018~2021) 議事録などを音声から自動文字起こしと要約 **当時KALDI + 東工大レシピやESPNETを使用、今はWISPHER…. • 笑顔+笑声 検知システム(2018~2021) 会議での参加者の笑顔を検知して会議に進んだかどうかの顔認識と 音声の笑声の検知をAIと音響工学勉強してスペクトルのパターンを AI分析(波はとても奥が深い。)
• SNS評価システム (2021 ~ 2023) SNSでのコメントや評価を自動で採点して評価を見極めるシステム **この時期はポジネガ判定程度で感動❣ • 災害管理システム案(個人的趣味でPOC) 自治体向けに災害管理(SNSのコメント画像、リモートセンシング画像のAI解析) • 農産物管理のため衛星画像リモートセンシングシステム(個人的趣味でPOC) 衛星画像から農業の育成状況をチェックして農産物市場価格の影響をアセスメント • 顔認証システム (2023 ~) 顔認証システムを使い本人特定をする ★ フリーなチャットおよび独自文書回答のチャットボット (2024 ~) 今回の発表テーマ!! 独自文書から OPENAIと公開言語モデルを利用してチャットボット ただしデータ解析のアシスタントして生成 AIが現状どこまで使えるか少し厳しく探求 **今回はフリーに統計問題と数表をよませた RAGをOpenAIのCHATGPTのAPIだけでなく 日本語モデル ELYZAと比較しながらデモ
LLMと数表処理、なぜこのテーマを選んだか 高性能なLLMはPROGRAMの生成でかなり役立つアシスタントとして活用できることは実感、 毎回ではないが…。 では実際にいろいろな中途半端に整形された数表やデータで回答ができるだろうか、 あるいは補助TOOLとして利用できるのだろうか? 世の中には中途半端な整形データが多い、 (場合によっては見栄えを意識してわざわざ整形データを壊してしまうのをよく見る) これをRAGなどで正しく解析するお手伝いしてくれればすごく助かる。 (データクレンジング作業の軽減) 論文などでも結構重要なポイントが表で記述+数値のテーブルで書かれている
最終的にはこういった十分整形されていない数表からデータクレンジングをやってくれるLLMが あればすごく助かると思ったから 最初はオープンソースモデルのLLMを使ったRAGを普通に発表するつもりだったけど、進めていくうちに 自分がもっとAIに助けてほしいことをテーマにしたいと思い軌道修正
使用モデル •デモサイト(クラウド上のLLM) 最新でパラメータ最多であろうサイトで 統計問題小手調べ https://elyza.ai/lp/elyza-llm-for-jp (比較のためChatGPT4oもテスト) •LOCAL LLM (+ OpenAI API) 整形しきってない数表を与えたRAGで実験 Llama-3-ELYZA-JP-8B-q4_k_m.gguf on
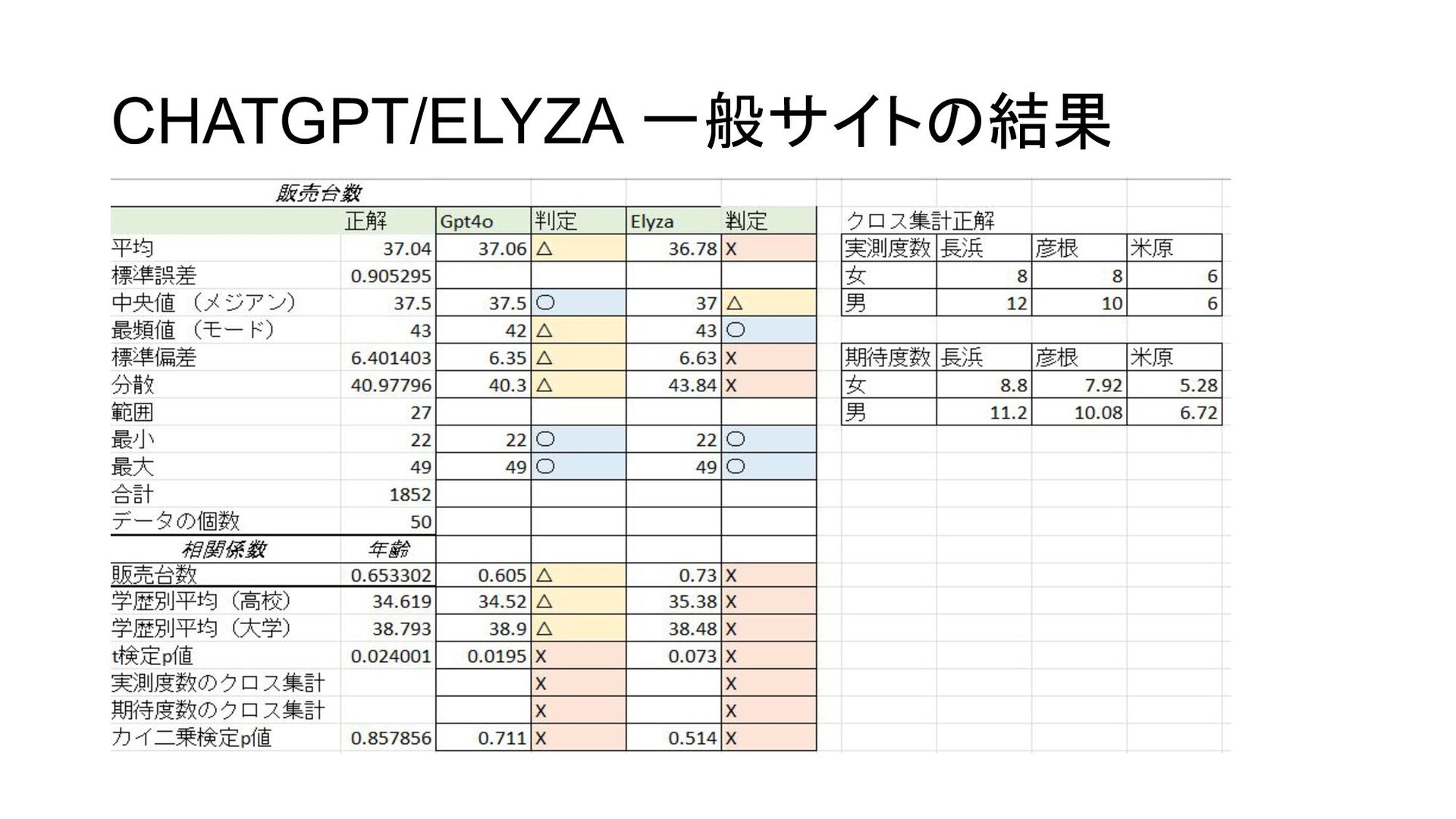
Ollama (比較のためChatGPT gpt-3.5-turbo のAPIもテスト) テスト内容 右のような 50のデータを与えて質問した. 1) 以下のCSVのデータから販売台数の 最大値、最小値、平均値、中央値、最頻値、分散、標準偏差を求めてください 2) 年齢と販売台数の相関係数を求めてください 3) 学歴別(大学、高校)の販売台数の平均を求めて各平均をください またt検定を実施してその平均の差が有意かどうかをみるためにp値を求めてくださ い 4) 性別と担当地区のクロス集計表を作成してください また期待度数のクロス集計表も作成してください また性別と担当地域が偏向なく独立に選ばれているか カイ2乗検定をおこない p値を求めてください
CHATGPT/ELYZA 一般サイトの結果
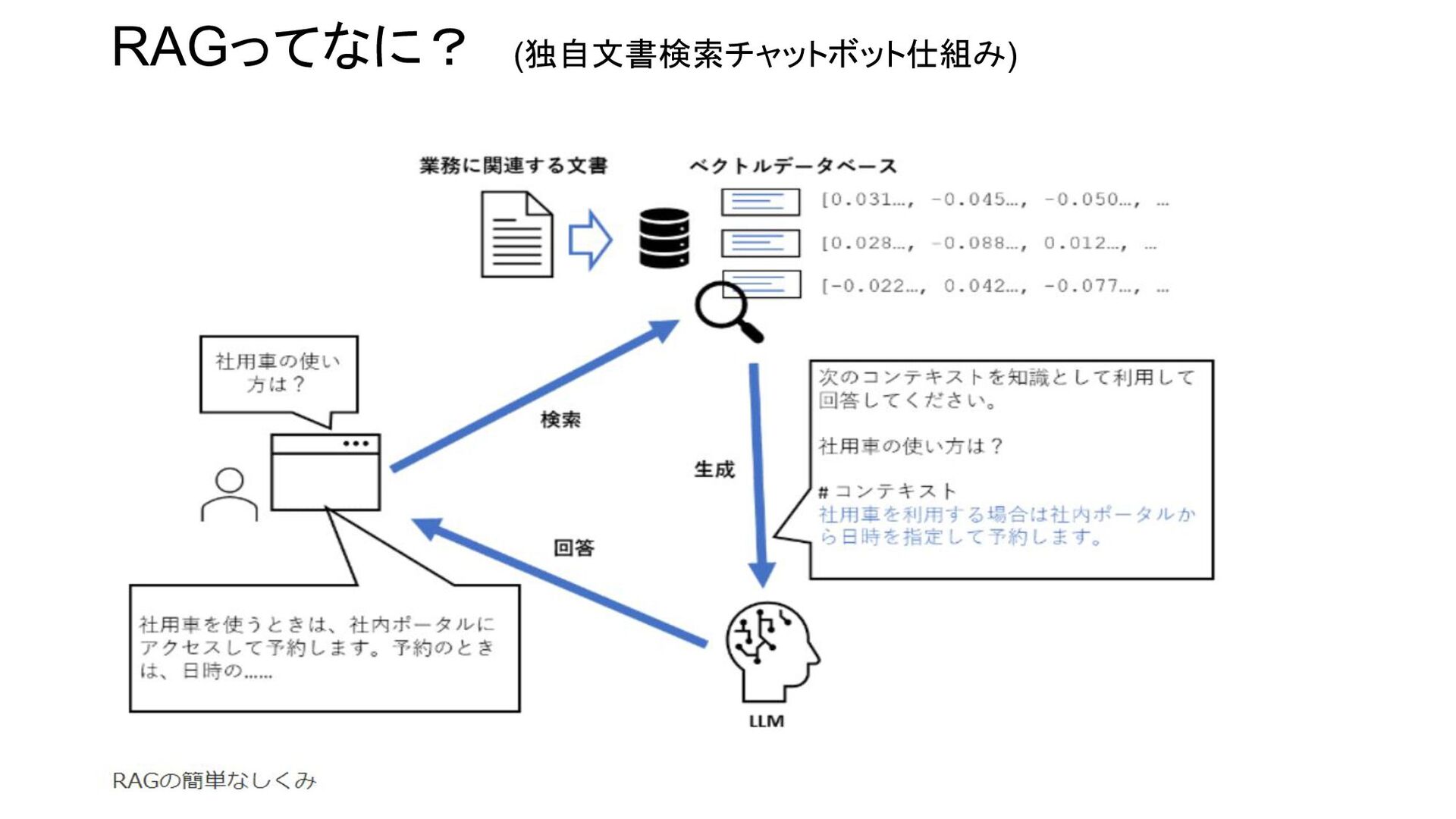
RAGってなに? (独自文書検索チャットボット仕組み)
RAGでの実行環境とサンプルデータ概要 [LOCALでの実行環境 ]: AWS EC2 g4dn • NVIDIA Tesla T4 16GB
MEMORY • 4 vCPU 16 GB RAM • Ubuntu 24.04 CUDA 12.5 使用ライブライりやフレームワーク LLM本体 • OLLAMA • Llama-3-ELYZA-JP-8B-q4_k_m.gguf RAG用 VectorIndex保存 • llama-index フロントエンド • Streamlit RAGでの使用データ 日本食品成分表2024 八訂 添付PDFからEXCELに変換してもの 本当は高い精度で機械的にRDBに格納したいが中途半端な整形状態でテーブルに いれるために整形するのははかなり整形が大変そう =>RDB+SQL(+過酷なデータクレンジングと整形) ではなくRAG+日本語PROMPTで 検索回答ある程度いけるだろうか?
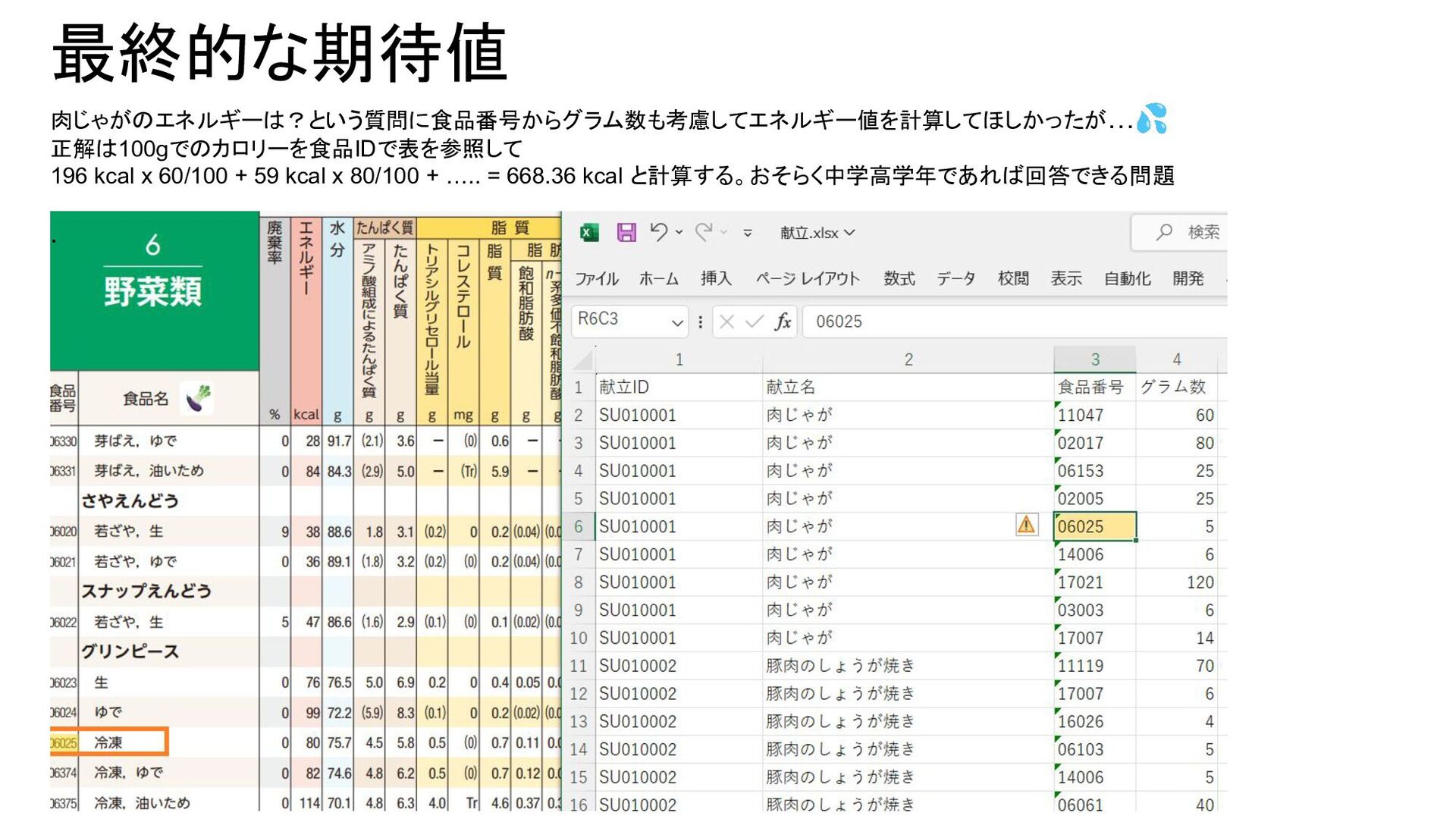
最終的な期待値 肉じゃがのエネルギーは?という質問に食品番号からグラム数も考慮してエネルギー値を計算してほしかったが…💦 正解は100gでのカロリーを食品IDで表を参照して 196 kcal x 60/100 + 59 kcal
x 80/100 + ….. = 668.36 kcal と計算する。おそらく中学高学年であれば回答できる問題 .
所感および今後のどのようなアプローチが必要か 今後のアプローチ案 : - PROMPTをもっと工夫する、VECTOR DBにCHROMADBやFAISSなど検討 - Document AIの技術を調査、導入検討 -もっと最適なチャンクサイズ方法を工夫
- FINETUNINGやRAGを工夫やってみる(初級記述統計の本を参照させる?) - モデルの開発1:自然言語と数表からPROGRAMに翻訳して実行して答えるLLMモデル - モデルの開発2: 数表+自然言語の処理に特化したLLMモデル - アプローチを変える(LLMという手段をいったん忘れる。) 所感: - LLMは数学がやはり苦手? そもそも知性があるわけではないので自分期待しすぎ? ちなみにCHATGPTだといったんPROGRAM(PYTHON)に 翻訳してそれを実行して答えようとしている。 - LLMは文系問題に強いが理系問題にはまだまだ弱い - 今の仕組み(膨大な線形式+非線形式+強化学習)ではまだまだ厳しいが今後の発展に期待 - とはいえ膨大な書類や論文の中にある重要な表などは正しく数理的にはまとめてほしいとは思う
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![RAGでの実行環境とサンプルデータ概要 [LOCALでの実行環境 ]: AWS EC2 g4dn • NVIDIA Tesla T4 16GB](https://files.speakerdeck.com/presentations/868bda74b61a4e1190c742b58300838f/slide_7.jpg){kind=link}
{kind=link}
{kind=link}