A., Kacorri, H., Takagi, H., & Asakawa, C. (2025, April). Beyond Omakase: Designing Shared Control for Navigation Robots with Blind People. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems (pp. 1-17). [Stanescu+, ISMAR’23] Stanescu, A., Mohr, P., Kozinski, M., Mori, S., Schmalstieg, D., & Kalkofen, D. (2023, October). State-Aware Configuration Detection for Augmented Reality Step-by-Step Tutorials. In 2023 IEEE International Symposium on Mixed and Augmented Reality (ISMAR) (pp. 157-166). IEEE. [Yagi+, IJCV'25] Yagi, T., Ohashi, M., Huang, Y., Furuta, R., Adachi, S., Mitsuyama, T., & Sato, Y. (2025). FineBio: a fine-grained video dataset of biological experiments with hierarchical annotation. International Journal of Computer Vision, 1-16. [Nair+, CoRL’22] Nair, S., Rajeswaran, A., Kumar, V., Finn, C., & Gupta, A. (2022, August). R3M: A Universal Visual Representation for Robot Manipulation. In 6th Annual Conference on Robot Learning. [Kareer+, ArXiv'24] Kareer, S., Patel, D., Punamiya, R., Mathur, P., Cheng, S., Wang, C., ... & Xu, D. (2024). Egomimic: Scaling imitation learning via egocentric video. arXiv preprint arXiv:2410.24221. [Shi+, ICRA‘25] Shi, J., Zhao, Z., Wang, T., Pedroza, I., Luo, A., Wang, J., ... & Jayaraman, D. (2025). ZeroMimic: Distilling Robotic Manipulation Skills from Web Videos, ICRA. [Yang+, Arxiv’25] Yang, R., Yu, Q., Wu, Y., Yan, R., Li, B., Cheng, A. C., ... & Wang, X. (2025). EgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos. arXiv preprint arXiv:2507.12440. [Luo+, ArXiv’25] Luo, H., Feng, Y., Zhang, W., Zheng, S., Wang, Y., Yuan, H., ... & Lu, Z. (2025). Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos. arXiv preprint arXiv:2507.15597. [Bahl+, CVPR'23] Bahl, S., Mendonca, R., Chen, L., Jain, U., & Pathak, D. (2023). Affordances from human videos as a versatile representation for robotics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 13778-13790). [Hoque+, ArXiv'25] Hoque, R., Huang, P., Yoon, D. J., Sivapurapu, M., & Zhang, J. (2025). EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video. arXiv preprint arXiv:2505.11709. [Singh+, WACV’16] Singh, K. K., Fatahalian, K., & Efros, A. A. (2016, March). Krishnacam: Using a longitudinal, single-person, egocentric dataset for scene understanding tasks. In 2016 IEEE Winter Conference on Applications of Computer Vision (WACV) (pp. 1-9). IEEE. [Yang+, CVPR'25] Yang, J., Liu, S., Guo, H., Dong, Y., Zhang, X., Zhang, S., ... & Liu, Z. (2025). Egolife: Towards egocentric life assistant. In Proceedings of the Computer Vision and Pattern Recognition Conference (pp. 28885-28900). [Chatterjee+, ICCV’25] Chatterjee, D., Remelli, E., Song, Y., Tekin, B., Mittal, A., Bhatnagar, B., ... & Sener, F. (2025). Memory-efficient Streaming VideoLLMs for Real-time Procedural Video Understanding. ICCV. 109
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![映像からの人物行動認識 YouTubeやTV/映画映像を用いた引きの映像の行動理解に焦点 8 NTU RGB+D [Shahroudy+, CVPR’16] ActivityNet [Heilbron+, CVPR’15]](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![一人称視点映像記録の歴史 12 1945 [Bush, ‘45] 1991 ©Steve Mann 2023 https://www.projectaria.com/](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![なぜ一人称視点映像なのか? 20 我々は自分の身体を持ち、物体操作・会話など、一人称視点を通して世界と 関わっている 受動的にしか動けないネコは縞模様を認識できない [Held & Hein, ’63] [Held](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
![一人称視点映像の特徴 23 手操作 自己運動(ego-motion) 視線(gaze) [Huang+, ECCV’18] [Zimmermann+, ICCV’17] [Zhou+,](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_21.jpg){kind=link}
{kind=link}
![視線はタスク依存である [Yarbus, ‘67] 同じ視覚刺激であっても、対象中の何に注目するかによって視線の軌跡 (gaze scanpath)は変化する 25 Free view Age](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_23.jpg){kind=link}
![物体探索タスクにおける視線軌跡推定 [Yang+, CVPR’20] 逆強化学習を用いた物体探索中の視線軌跡推定 粗い画像を入力として「注視」した領域のみの高解像度画像を繰り返し得る 設定で次にどこに視線を向けるかを予測(例:食器らしい領域にまず注目) 26 視線軌跡(黄枠は探索対象) 予測された視線軌跡 注視回数](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_24.jpg){kind=link}
{kind=link}
![一人称視点映像からの視線推定 [Huang+, ECCV’18] 一人称視点映像から視線センサなしで視線位置を推定 28](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_26.jpg){kind=link}
![自己運動(ego-motion) 身体に装着されたカメラの3次元移動軌跡、あるいはその画像に反映された 見かけ上の2次元運動のこと 自己運動は固定カメラでは発生しない問題(物体追跡、モーションブラー)を 生み出す一方、装着者の行動・属性に関するユニークな情報を持つ 29 自己運動からの個人識別 [Poleg+, ACCV’14] 入力フレーム](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_27.jpg){kind=link}
{kind=link}
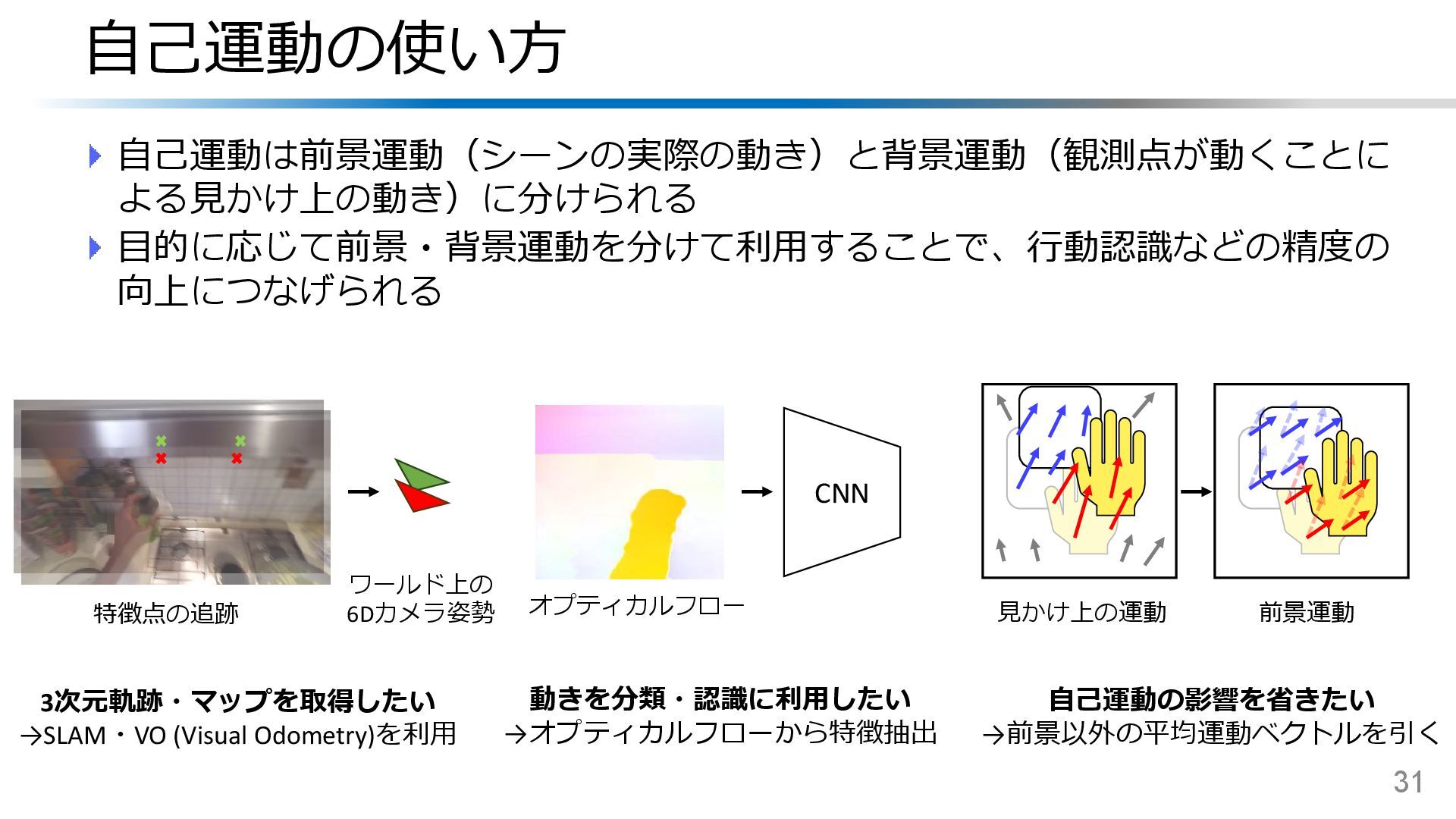{kind=link}
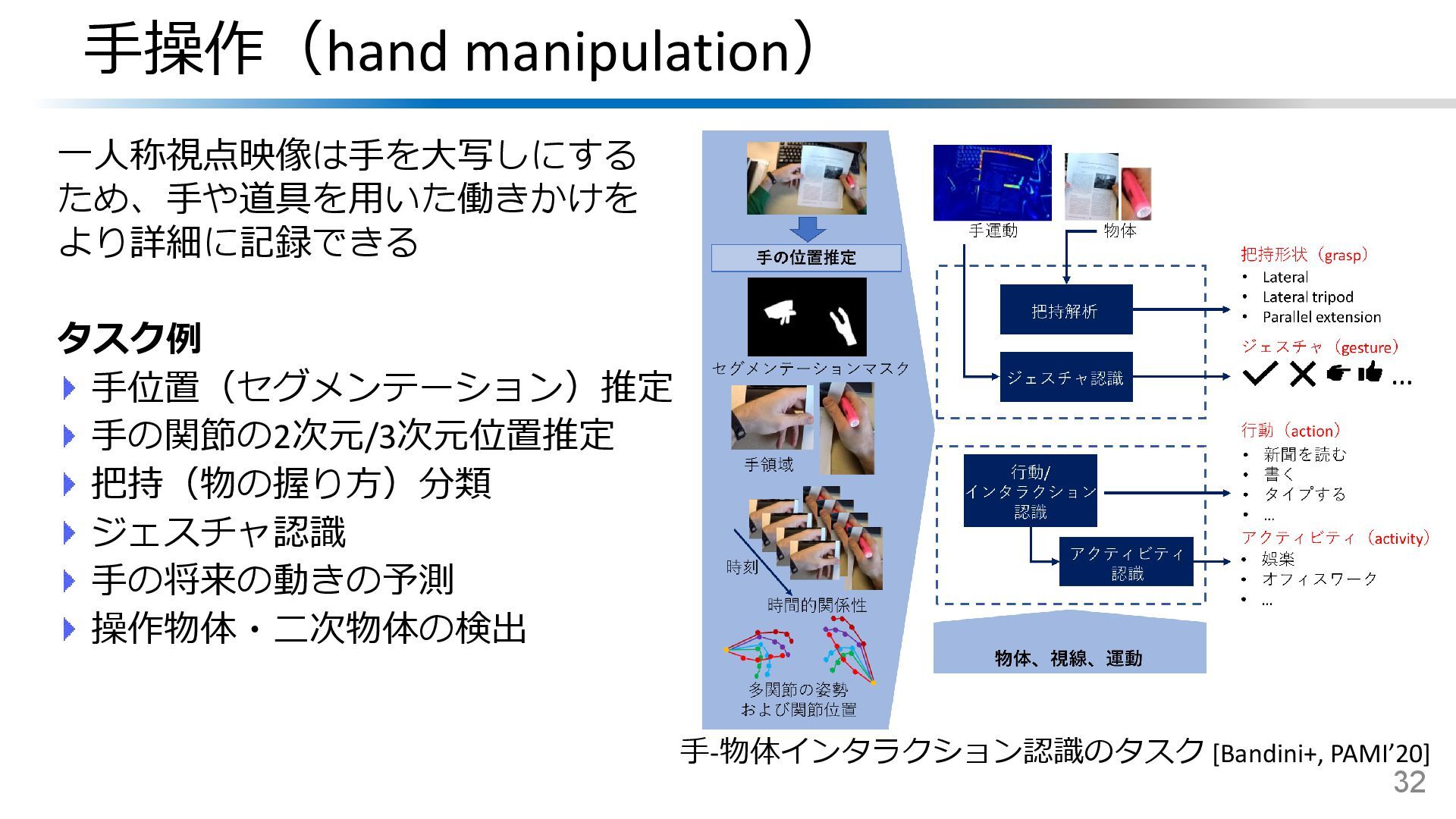{kind=link}
![3次元手姿勢の推定 映像中に映る手の手首を起点とした各関節点の位置の推定 AR・VRデバイスに取り付けられたカメラからのジェスチャ・行動認識に有用 指の位置が自身・物体によって隠れるためいかに真値を得るかに課題 33 GANeratedHands [Mueller+’, CVPR’18] 単眼RGB映像からの手姿勢推定 →物体や他の手との相互作用に課題](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_31.jpg){kind=link}
{kind=link}
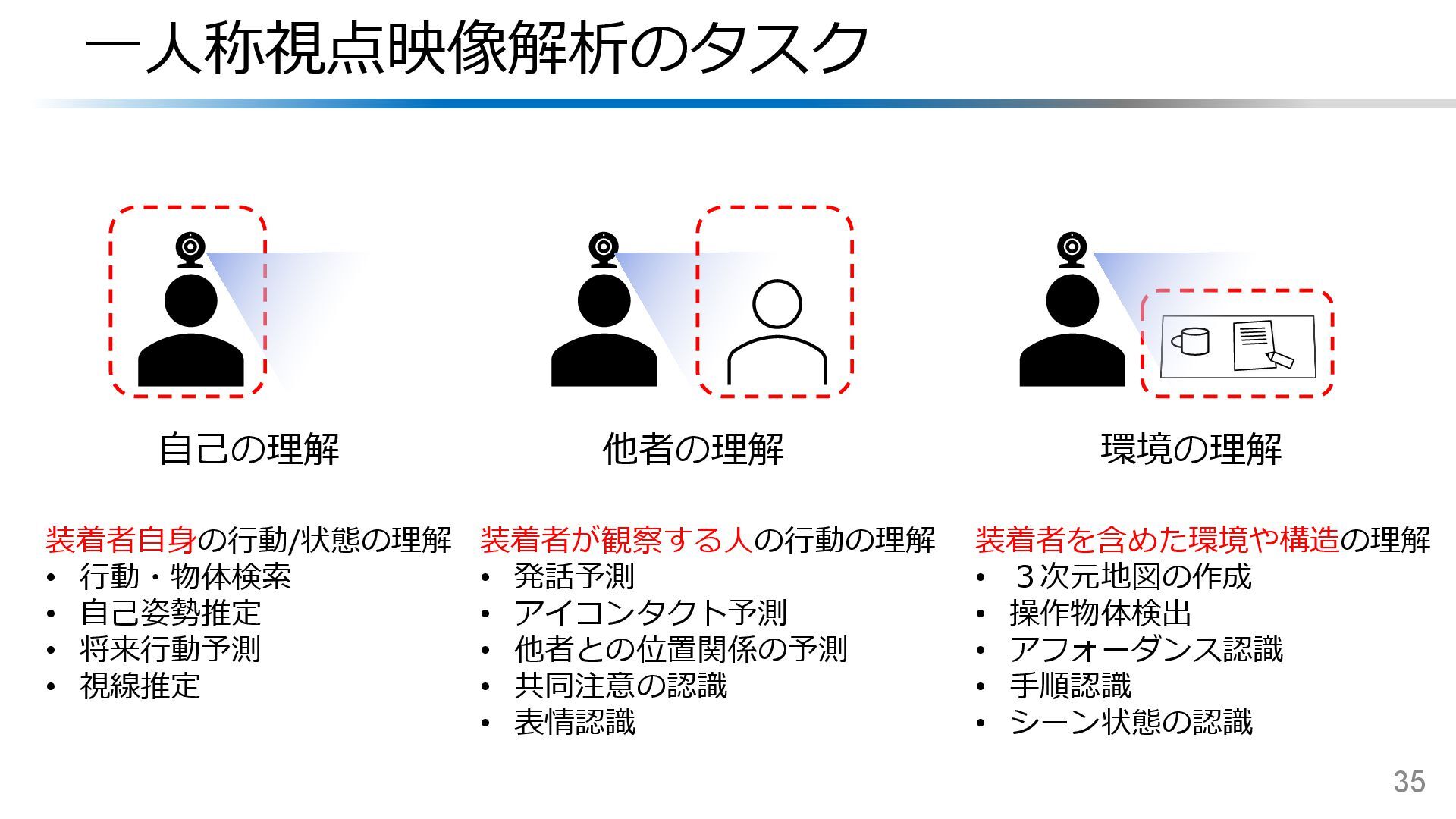{kind=link}
![自己の理解:装着者の行動・エピソードの理解 一人称視点映像からの個人の経験に関するエピソードの理解 例:過去の行動・物体の種類や位置など 36 Ego4D Episodic Memory Benchmark [Grauman+, CVPR’22]](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_34.jpg){kind=link}
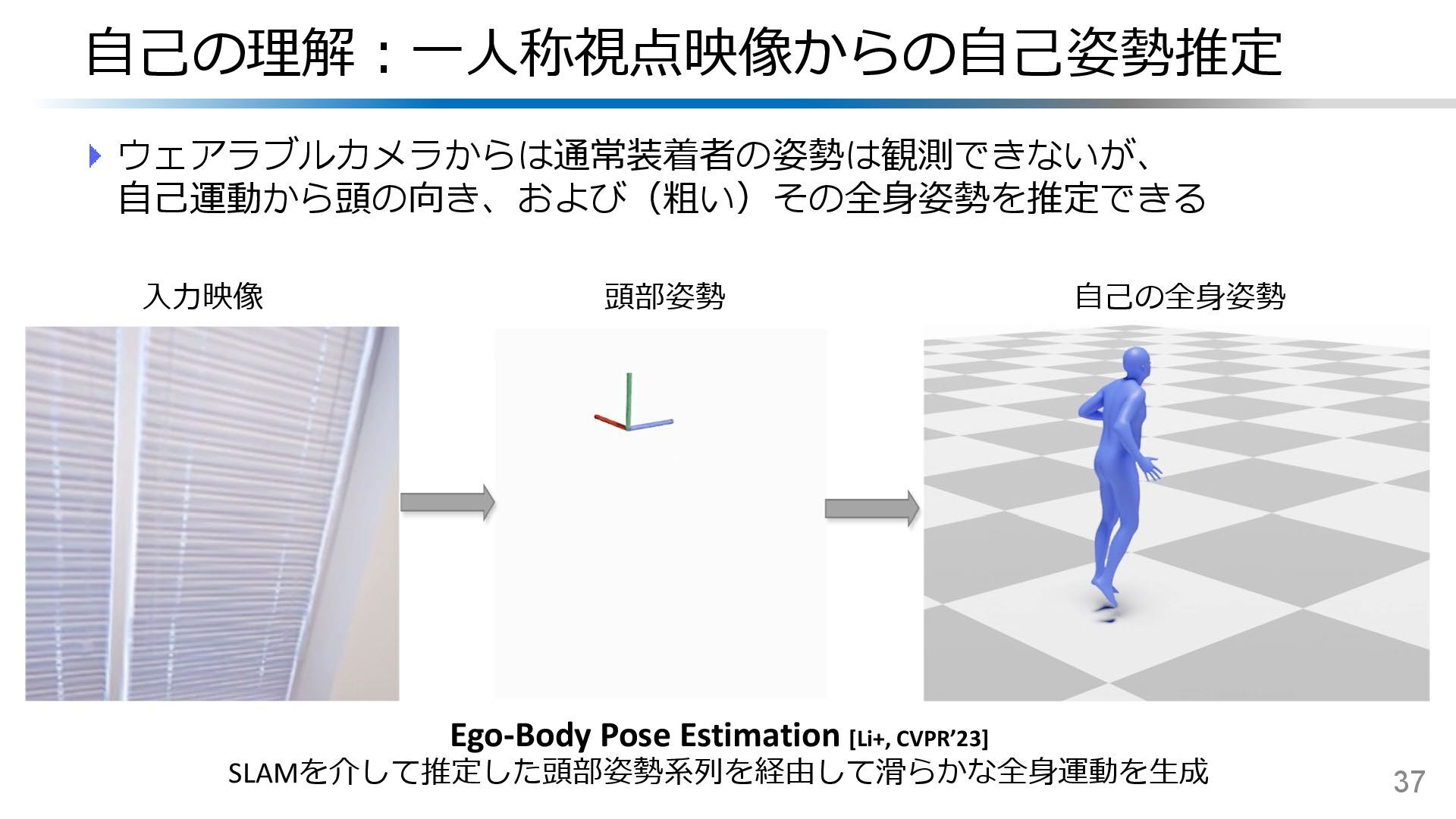{kind=link}
![近年はHMDを想定した下向きカメラからのより正確な全身姿勢推定や マルチモーダル全身運動の生成が取り組まれている 38 自己の理解:一人称視点映像からの自己姿勢推定 REWIND [Lee+, CVPR’25] HMDに搭載された下向きカメラ映像 からの全身+手指姿勢推定 Ego4o](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_36.jpg){kind=link}
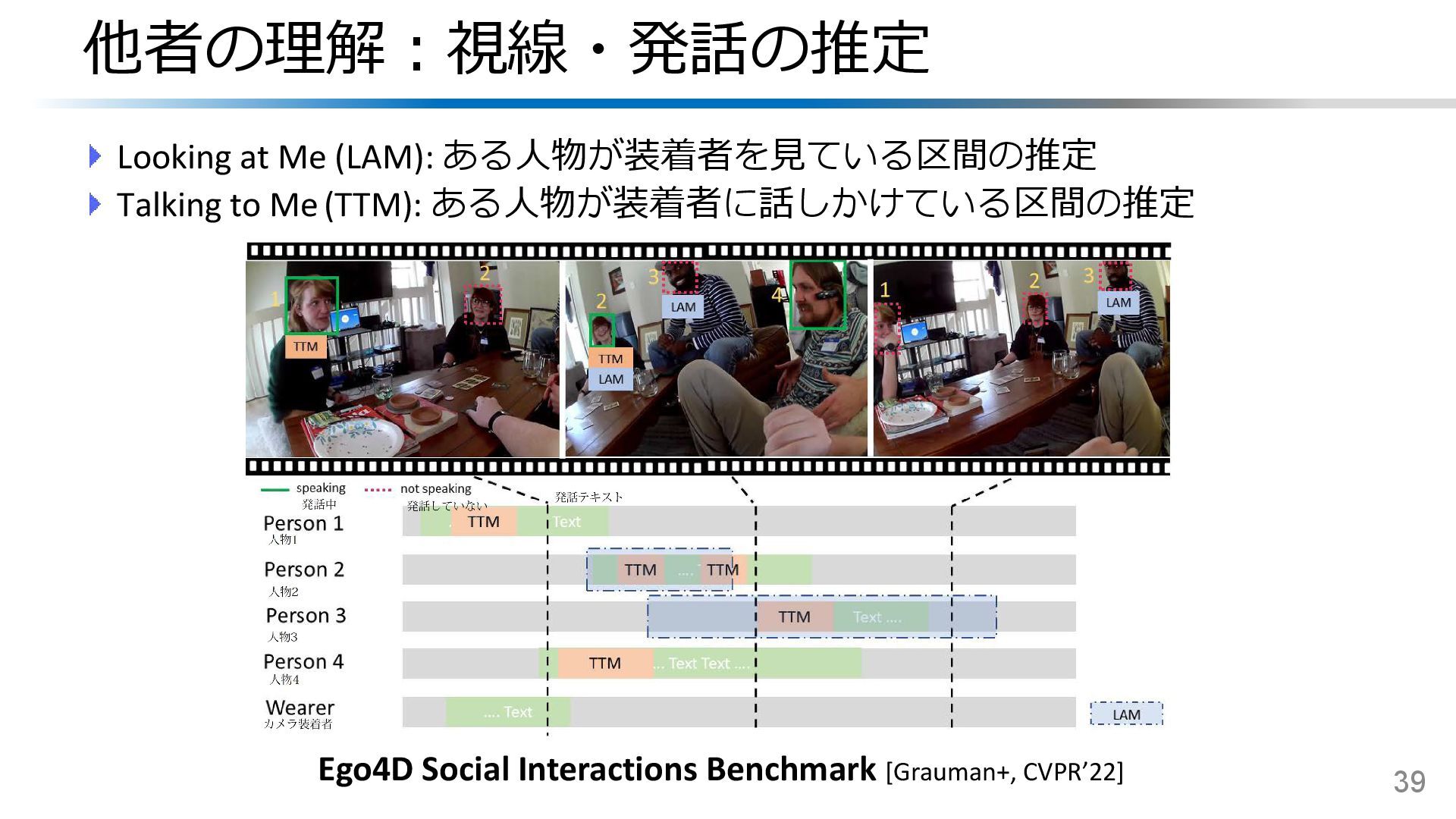{kind=link}
![他者の理解:アイコンタクトの推定 固定/頭部装着カメラからアイコンタクトがあるかどうかを教師なしで推定 40 Everyday Eye Contact Detection [Zhang+, UIST’17] https://youtu.be/ccrS5XuhQpk](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_38.jpg){kind=link}
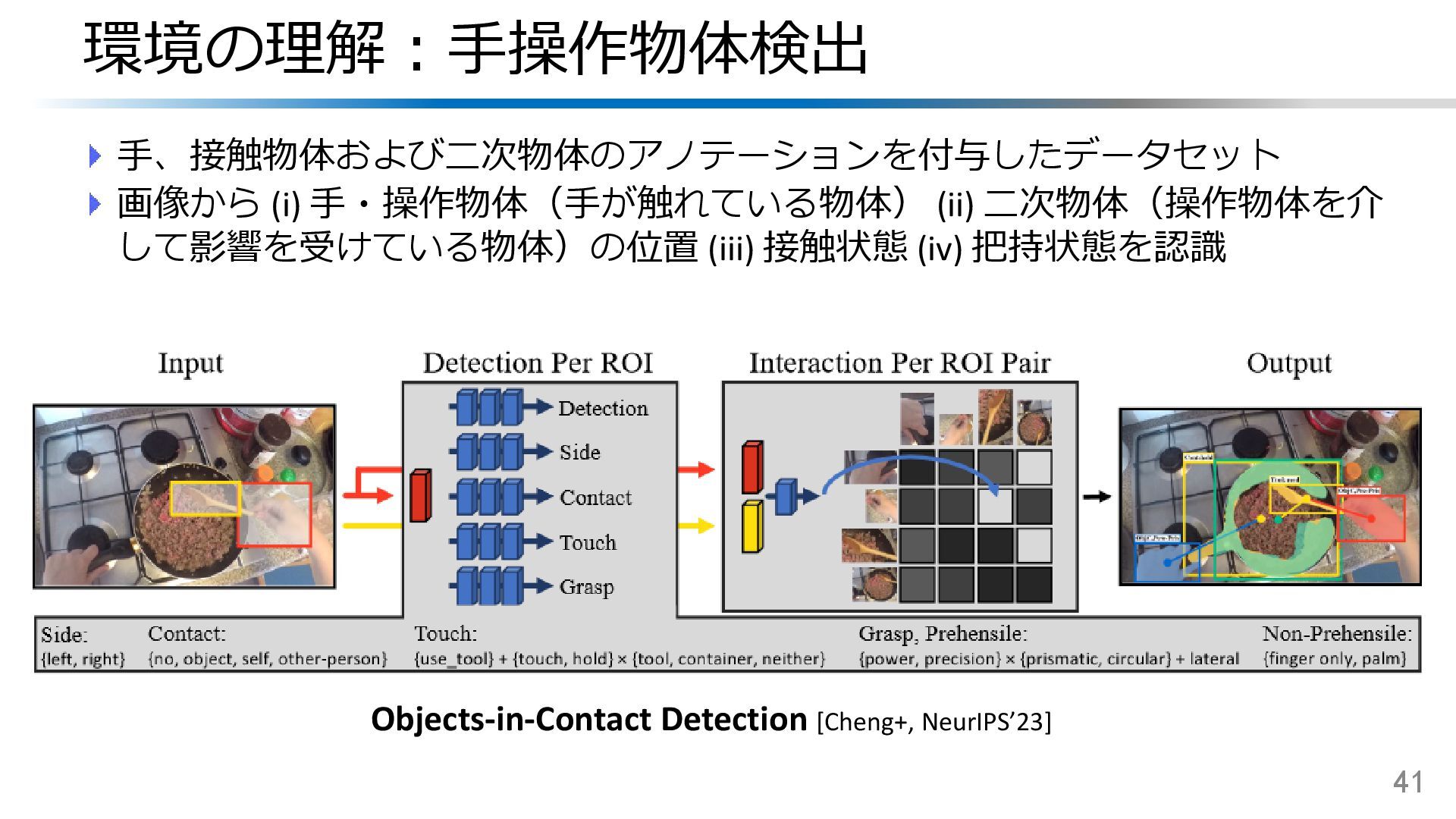{kind=link}
![環境の理解:一人称視点物体追跡 長時間の映像に出現する同一物体の追跡は難しい 小物体、視点変化、再出現、変形など 42 EgoTracks [Tang+, NeurIPS’23 D&B] 例:ガスバーナー(blowtorch)の追跡](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_40.jpg){kind=link}
{kind=link}
![環境の理解:一人称視点映像からの手順構造の認識 作業映像はgoal・step・atomic actionからなる階層構造を持つ 製造現場などでのタスクの実行状況のモニタリングに有用 44 Ego4D Goal-Step [Song+, NeurIPS’23] 手順を含む一人称視点映像からの階層行動認識データセット](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
![一人称視点映像のデータセット インターネット上に登場しないデータのため、独自に収集する必要がある 近年、多組織連携を通じてより大規模かつ網羅的な映像データセットが整備 47 EPIC-KITCHENS [Damen+, ECCV’18;IJCV’22] Ego4D [Grauman+, CVPR’22]](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_45.jpg){kind=link}
![EPIC-KITCHENS:一人称視点調理映像データセット 2ヶ国、45地点、100時間分の調理映像データセット 語彙が統制された行動(verb)および物体(noun)アノテーションを密に提供 48 EPIC-KITCHENS [Damen+, ECCV’18]](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_46.jpg){kind=link}
![EPIC-KITCHENS:一人称調理映像データセット 物体セグメンテーション 、環境音認識、物体追跡などの様々なベンチマークの ベースとして広く使用 49 VISOR [Darkhalil+, NeurIPS’22] EPIC-SOUNDS [Huh+,](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
![地理的多様性 52 [Grauman+, CVPR’22] より引用・翻訳](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_50.jpg){kind=link}
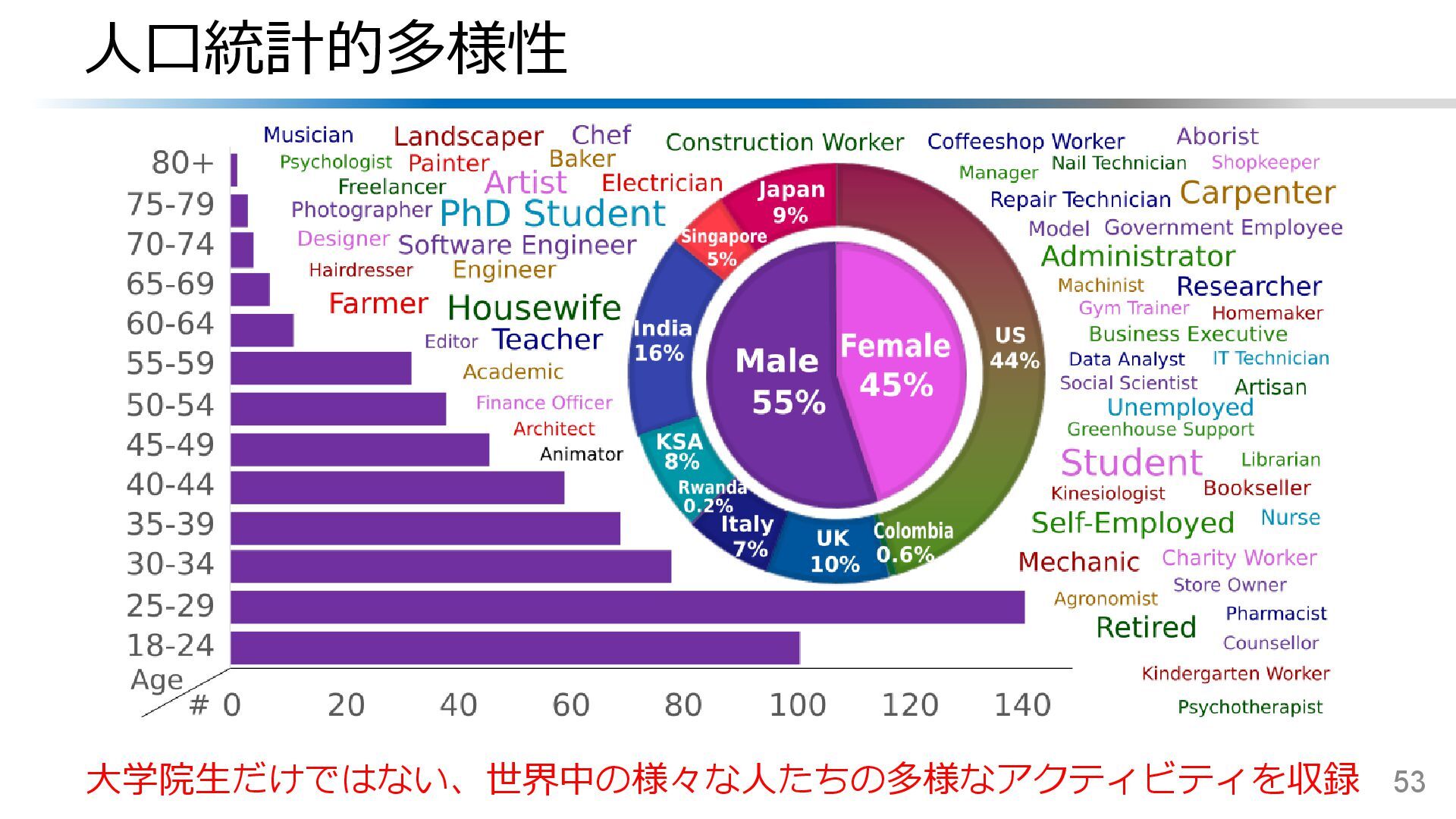{kind=link}
{kind=link}
{kind=link}
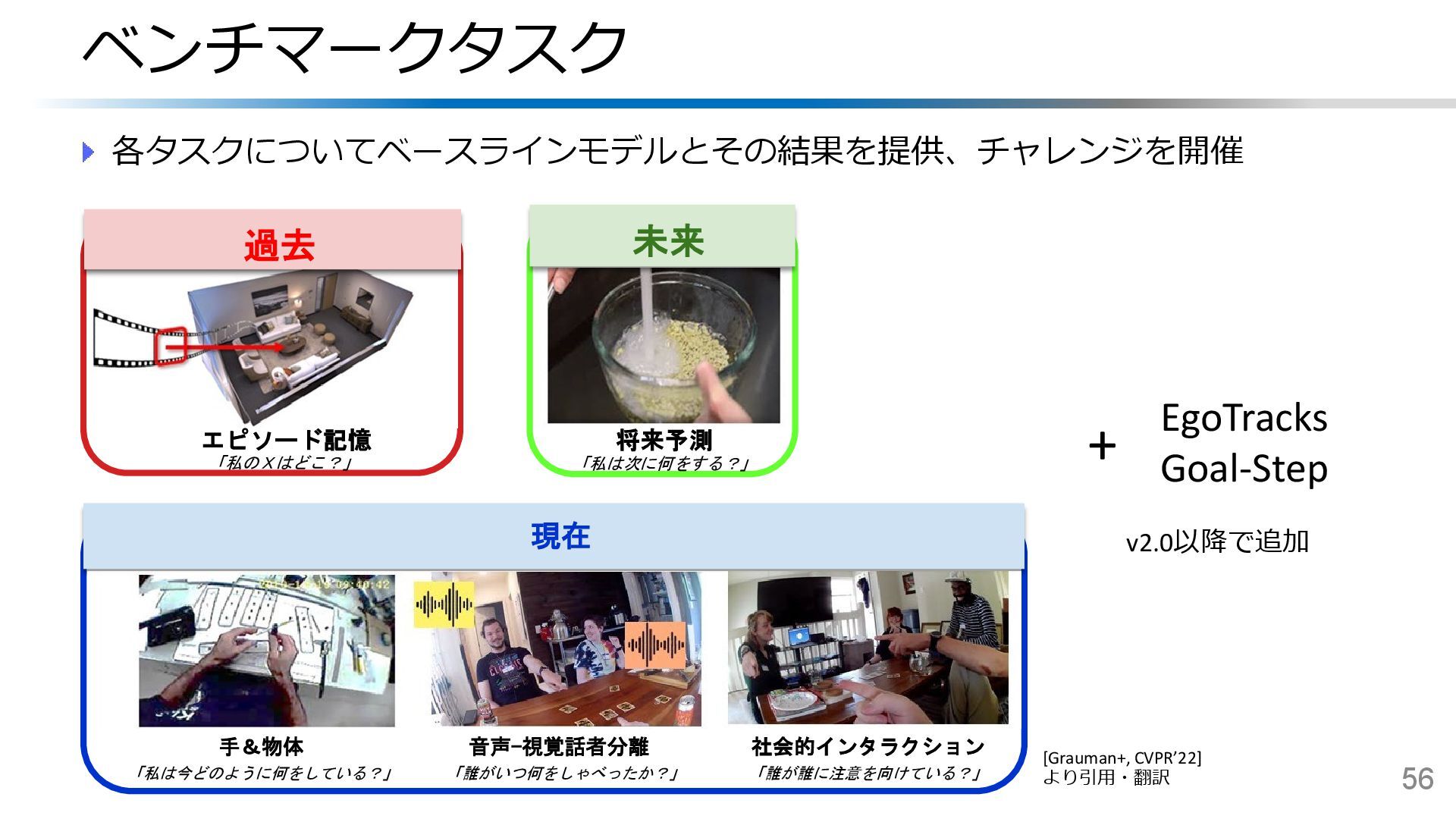{kind=link}
![Ego-Exo4D:技能理解のためのマルチモーダル多視点映像DB 技能活動(サッカー/料理/音楽等)における一人称-三人称間の視点遷移に注目 一人称/三人称視点映像および音声・加速度・視線・カメラ姿勢などを記録 57 Ego-Exo4D [Grauman+, CVPR’24]](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_55.jpg){kind=link}
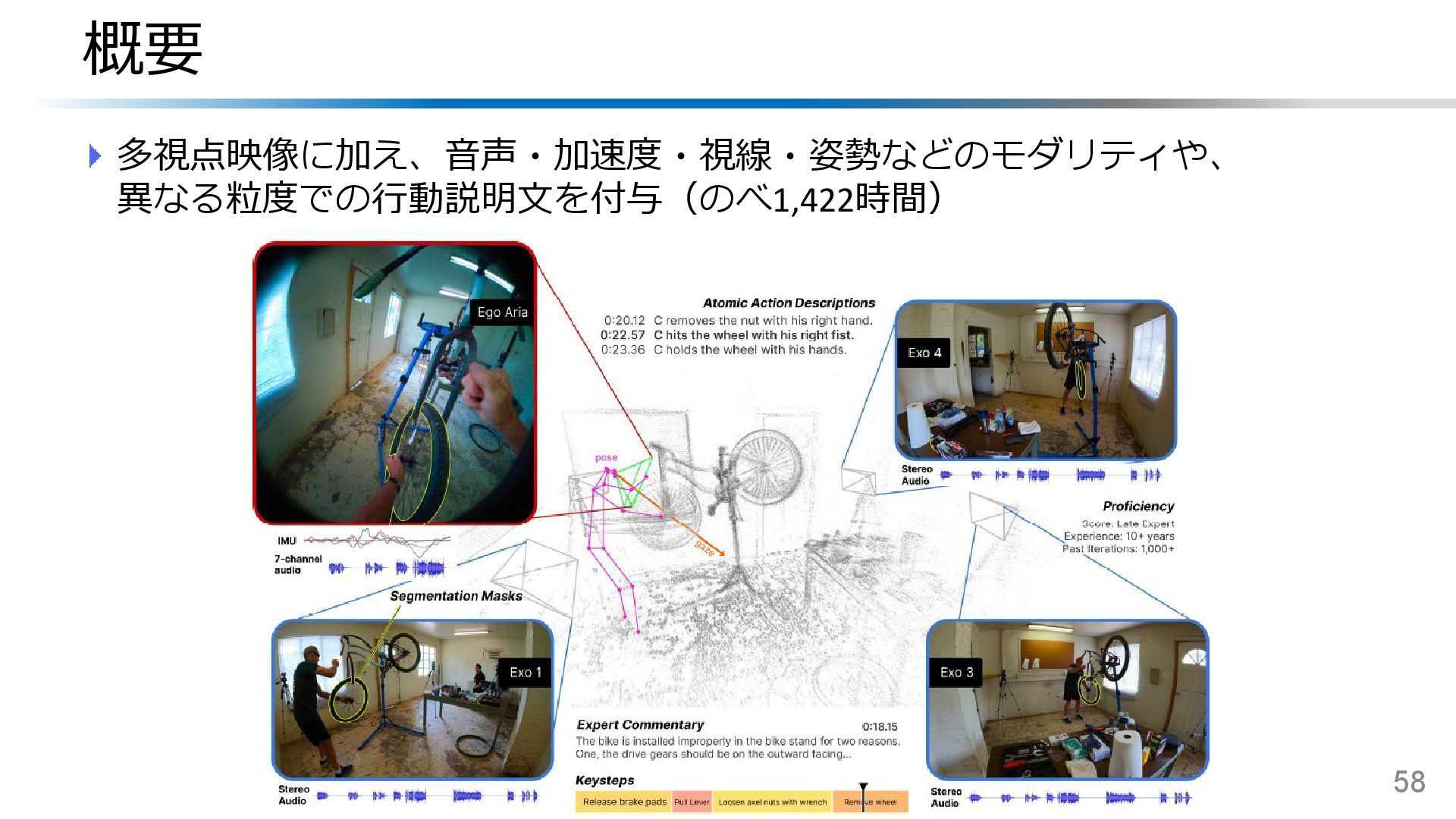{kind=link}
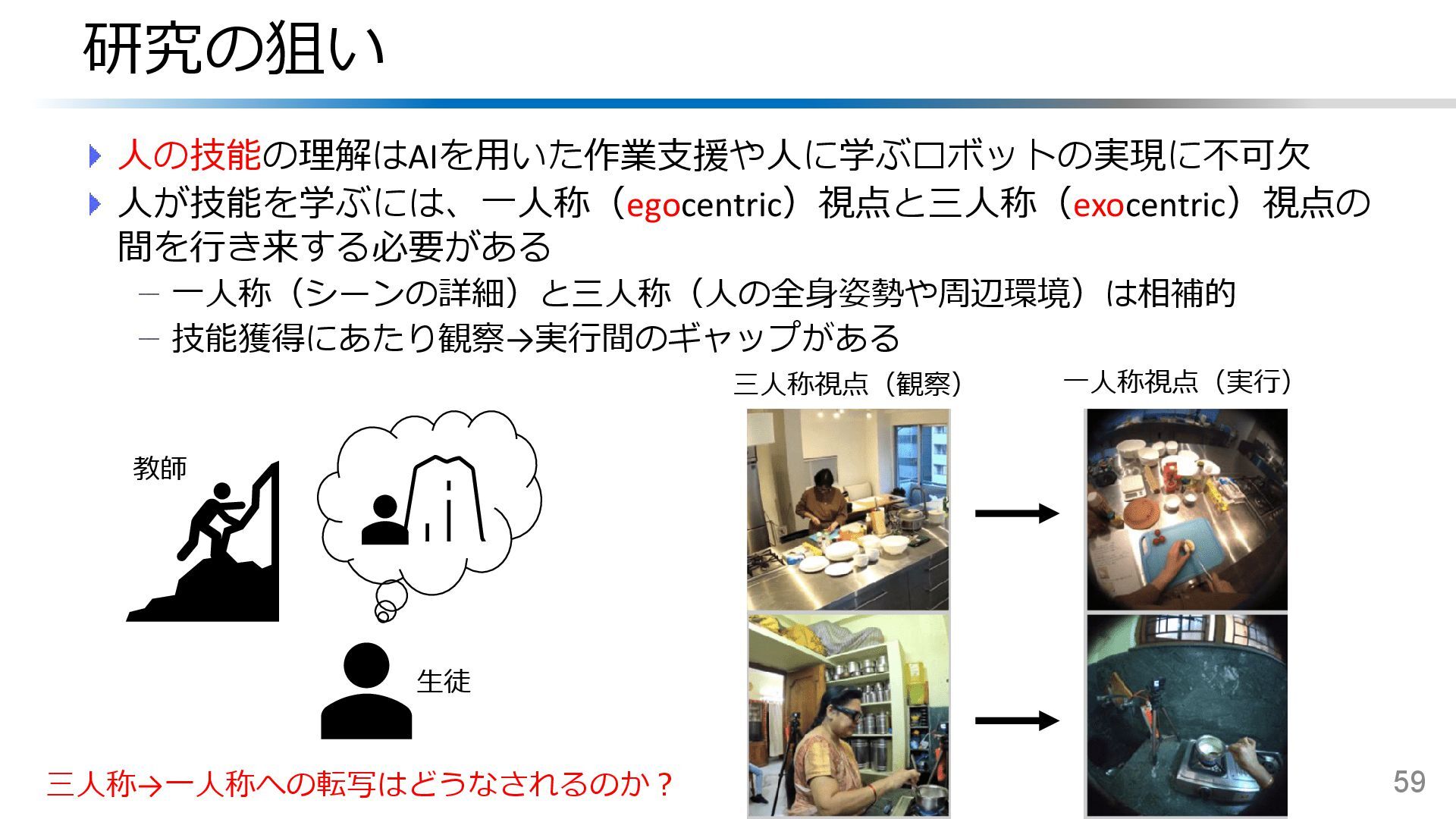{kind=link}
{kind=link}
{kind=link}
{kind=link}
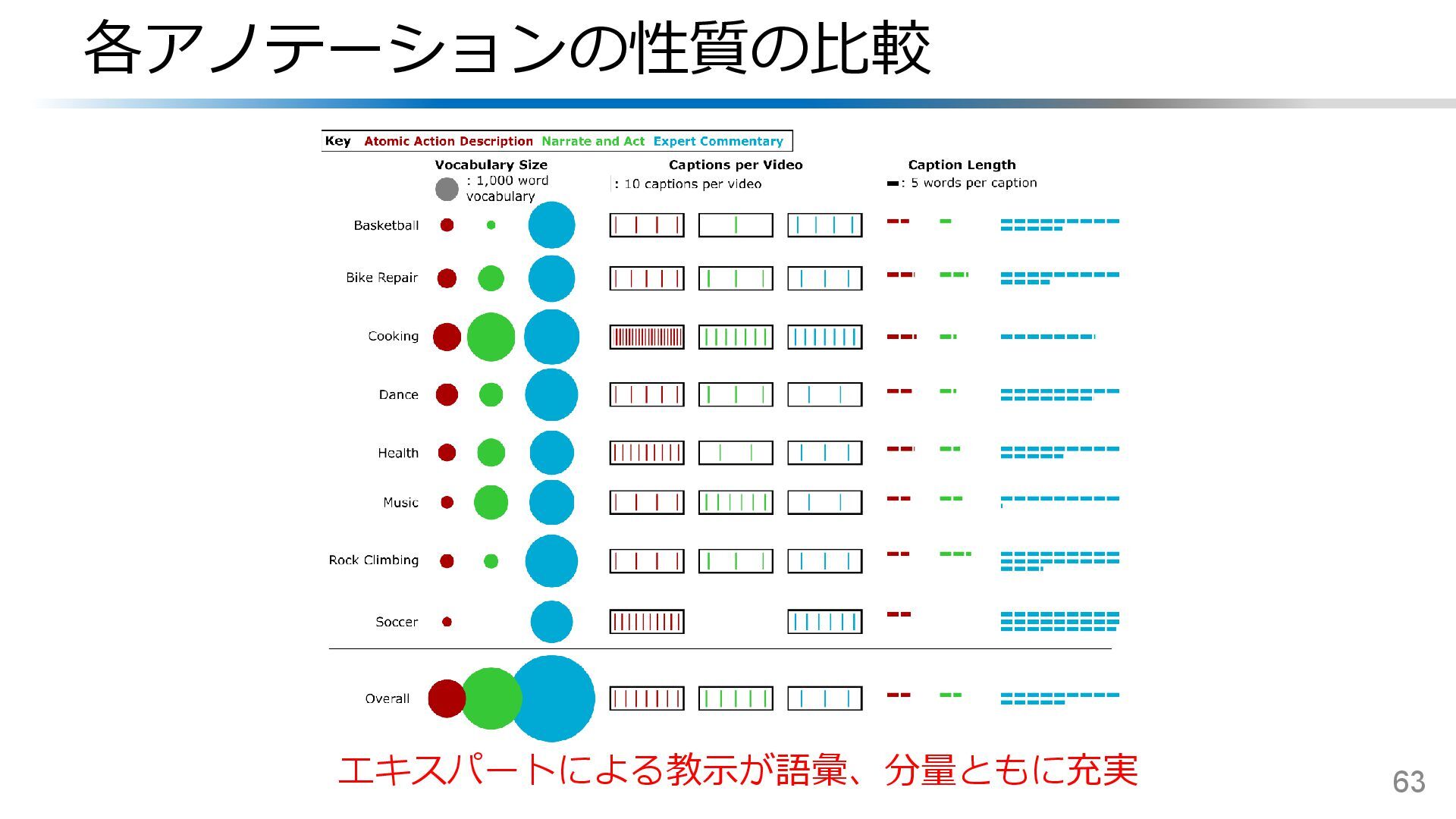{kind=link}
{kind=link}
![ExpertAF:一人称視点映像からの熟練者評価生成 身体部位ごとの要約生成 + 姿勢情報のtemporal alignmentにより訓練データを作成 映像からのコメント生成・検索・見本姿勢の生成を検証 65 ExpertAF [Ashutosh+, CVPR’25]](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_63.jpg){kind=link}
![ExpertAF:一人称視点映像からの熟練者評価生成 身体部位ごとの要約生成 + 姿勢情報のtemporal alignmentにより訓練データを作成 映像からのコメント生成・検索・見本姿勢の生成を検証 66 ExpertAF [Ashutosh+, CVPR’25]](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_64.jpg){kind=link}
{kind=link}
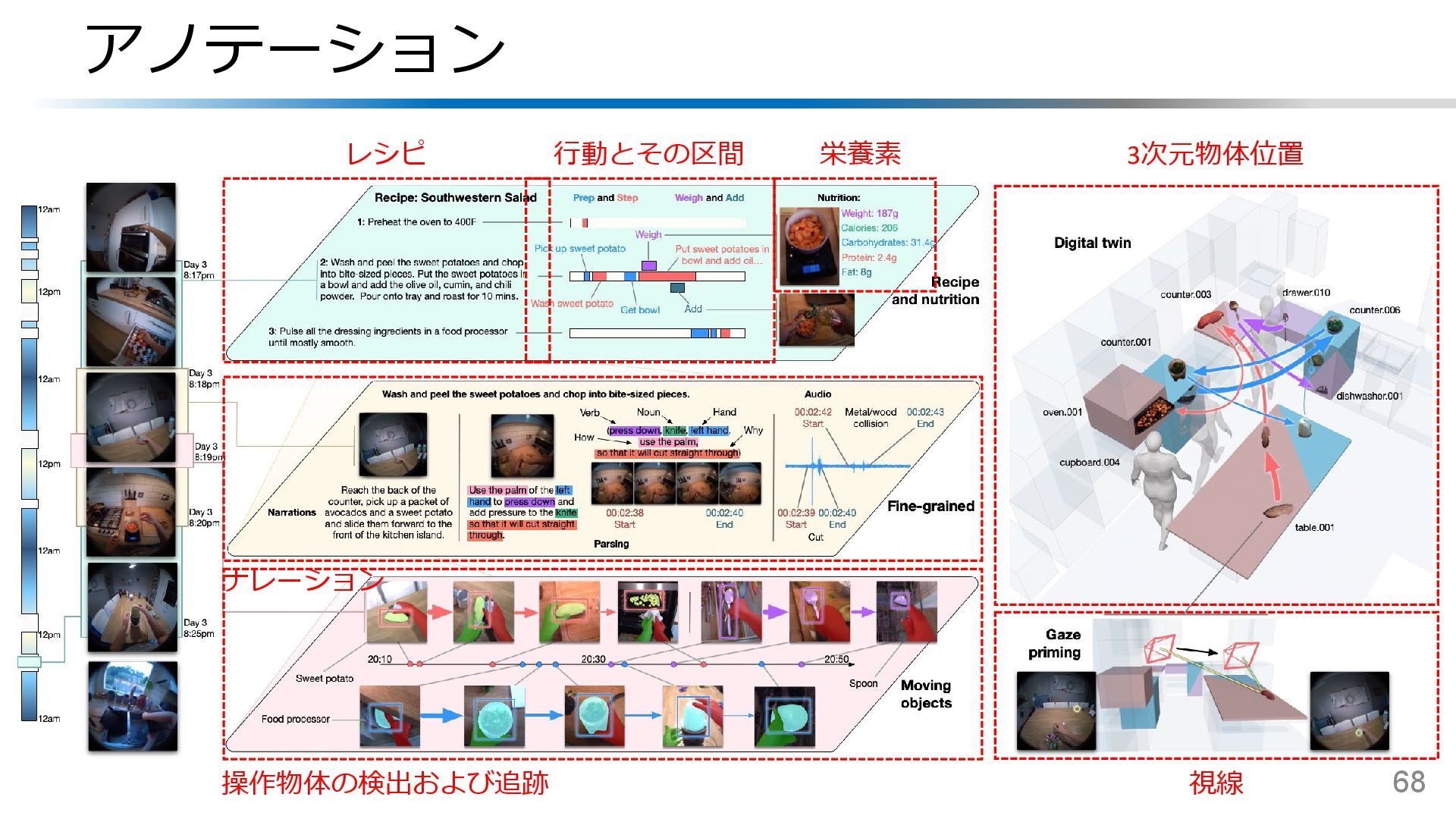{kind=link}
![質問例(Fine-grained Action) 69 以下の文のうち、どれがビデオ内の動作を最もよく表していますか? [00:03:56 – 00:04:03] A. 右手のスポンジでまな板を洗い、その後、裏面も洗えるようにまな板を回転させる B.](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_67.jpg){kind=link}
![質問例(Ingredients) 70 このビデオで参加者が計量した赤パプリカは何グラムでしたか? [00:14:04 – 00:14:21] A. 53 g B.](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_68.jpg){kind=link}
{kind=link}
{kind=link}
![その他のデータセット・ベンチマーク(1) 73 Assembly101 [Sener+, CVPR’22] 玩具模型の組立 EgoGen [Li+, CVPR’24] 環境認識モデル構築のための](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_71.jpg){kind=link}
![その他のデータセット・ベンチマーク(2) 74 EgoTextVQA [Zhou+, CVPR’25] 映像中のテキスト理解を要求するVideoQA HanDyVQA [Tateno+, MIRU’25] 詳細手物体インタラクション理解を要求するVideoQA](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_72.jpg){kind=link}
{kind=link}
![一人称視点映像解析のモデル Dual-Encoder型 EgoVLP [Lin+, CVPR’22] LaViLa [Zhao+, CVPR’23] Multimodal LLM型](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_74.jpg){kind=link}
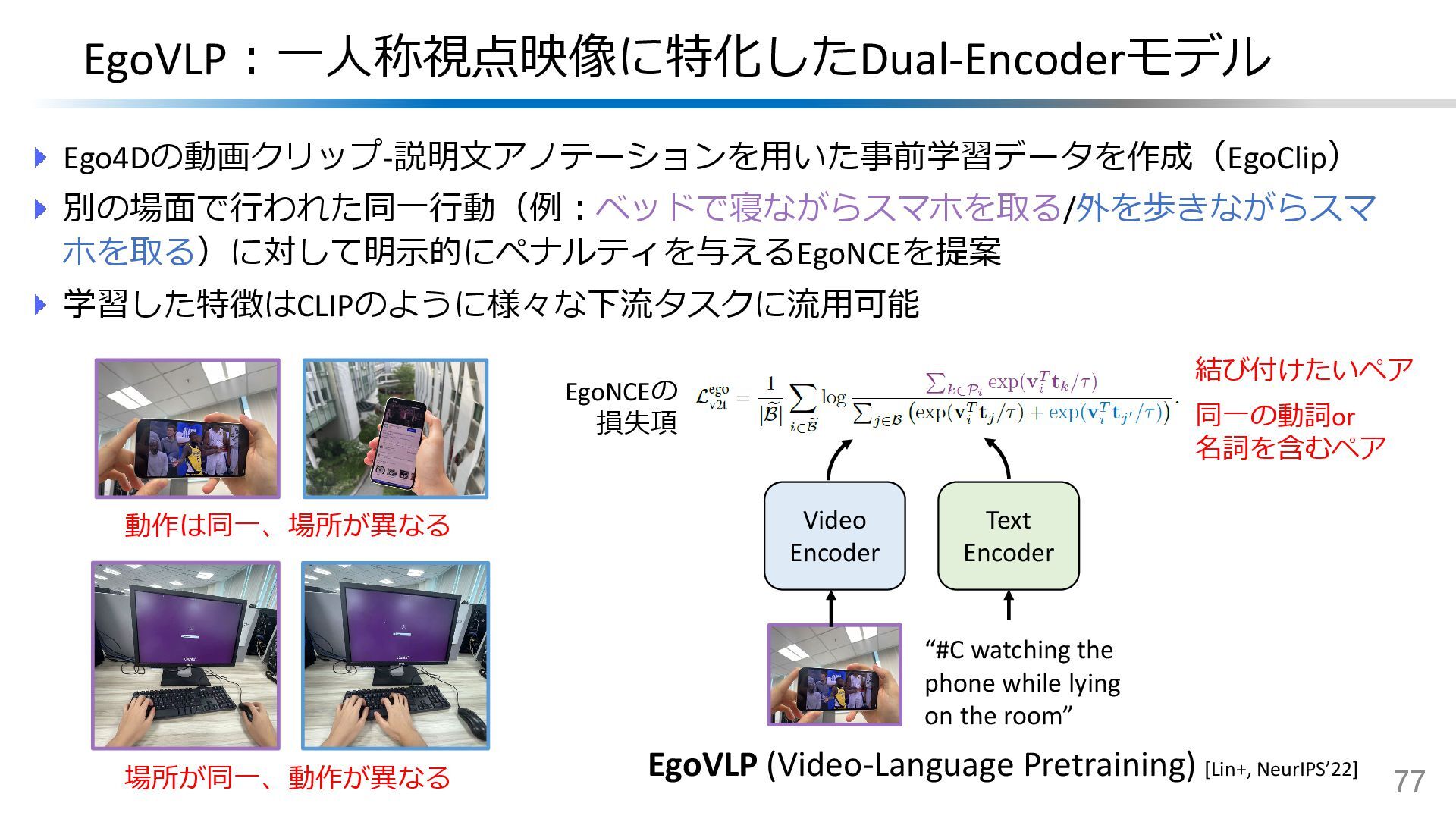{kind=link}
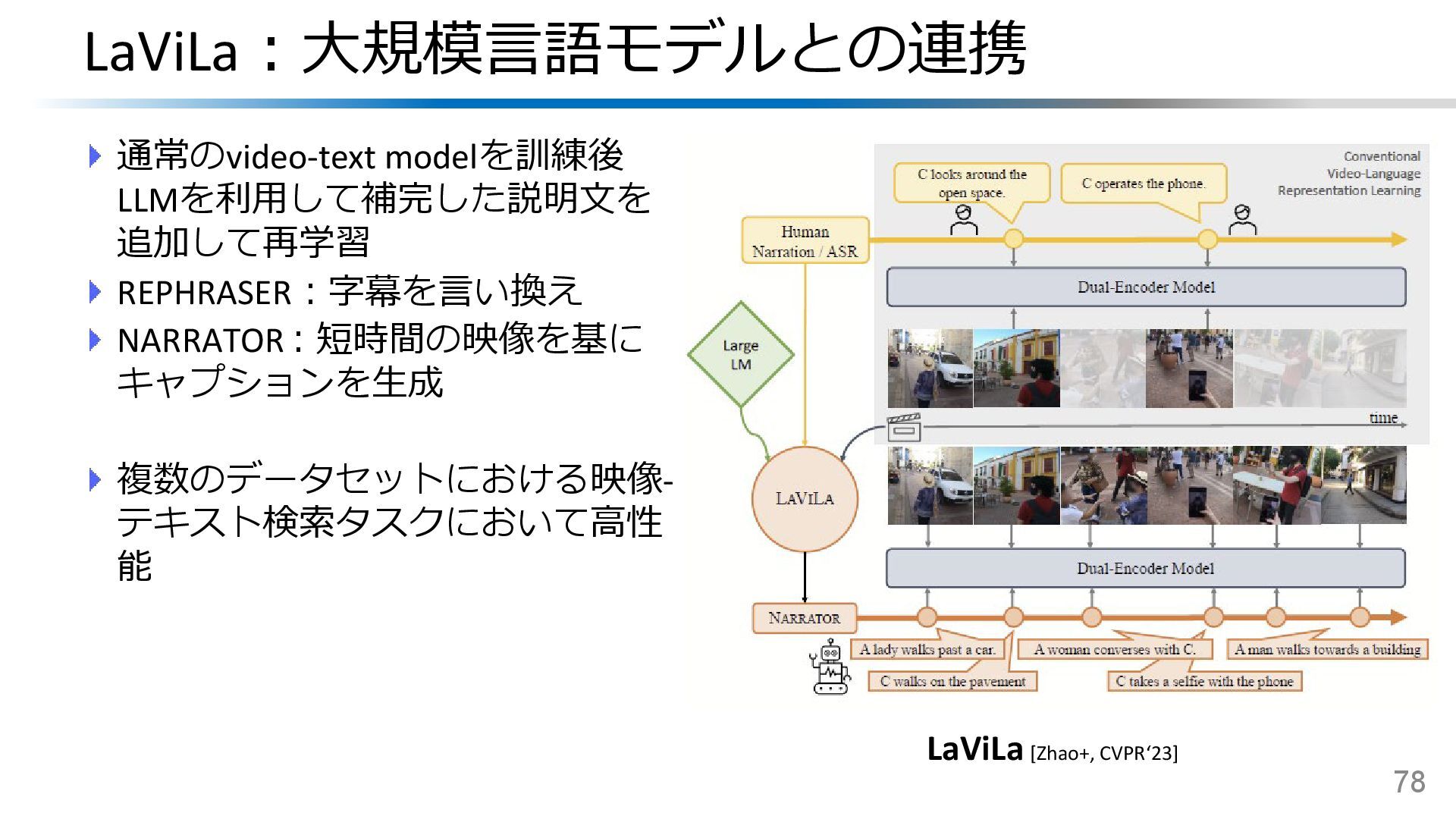{kind=link}
![MM-Ego:一人称視点映像に特化したMLLM Ego4Dの映像-ナレーションペアをLLMを通じてQAペアに変換 長時間の映像中で重要なタイミングを推定するための2段階推論 79 MM-Ego [Ye+, ICLR’25] LLaVA-OV +Ego SFT](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_77.jpg){kind=link}
![EgoLM:姿勢推定と行動認識の融合 一人称視点映像+疎なIMUから姿勢復元と動作説明を同時に生成 映像コンテキストが姿勢推定・動作説明双方に有効 80 入力映像 EgoLM [Hong+, CVPR’25] IMU入力 (頭、両手首)](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_78.jpg){kind=link}
![EgoLM:姿勢推定と行動認識の融合 通常のLLMを姿勢特徴量を受け付けるようfine-tune 81 [Hong+, CVPR’25] 姿勢情報トークンの事前学習 姿勢情報の事前学習 映像・IMU信号を含めたInstruction Tuning 推論時の入力トークン列](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_79.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![応用例:アクセシビリティ AIスーツケース(日本科学未来館) スーツケースにカメラ・LiDARを搭載して視覚障碍者の屋内外の移動をサポート 85 [Kamikubo+, CHI’25]](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_83.jpg){kind=link}
![応用例:AR作業支援 86 State-Aware Configuration Detection [Stanescu+, ISMAR’23] HoloLensを用いた組立作業のARチュートリアル](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_84.jpg){kind=link}
![応用例:バイオ実験の記録と自動化 87 実験者が作業 手順と結果を自動記録 手順GT 手順予測 FineBio [Yagi+, IJCV’25] 実験行動の自動認識のためのバイオ実験映像](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_85.jpg){kind=link}
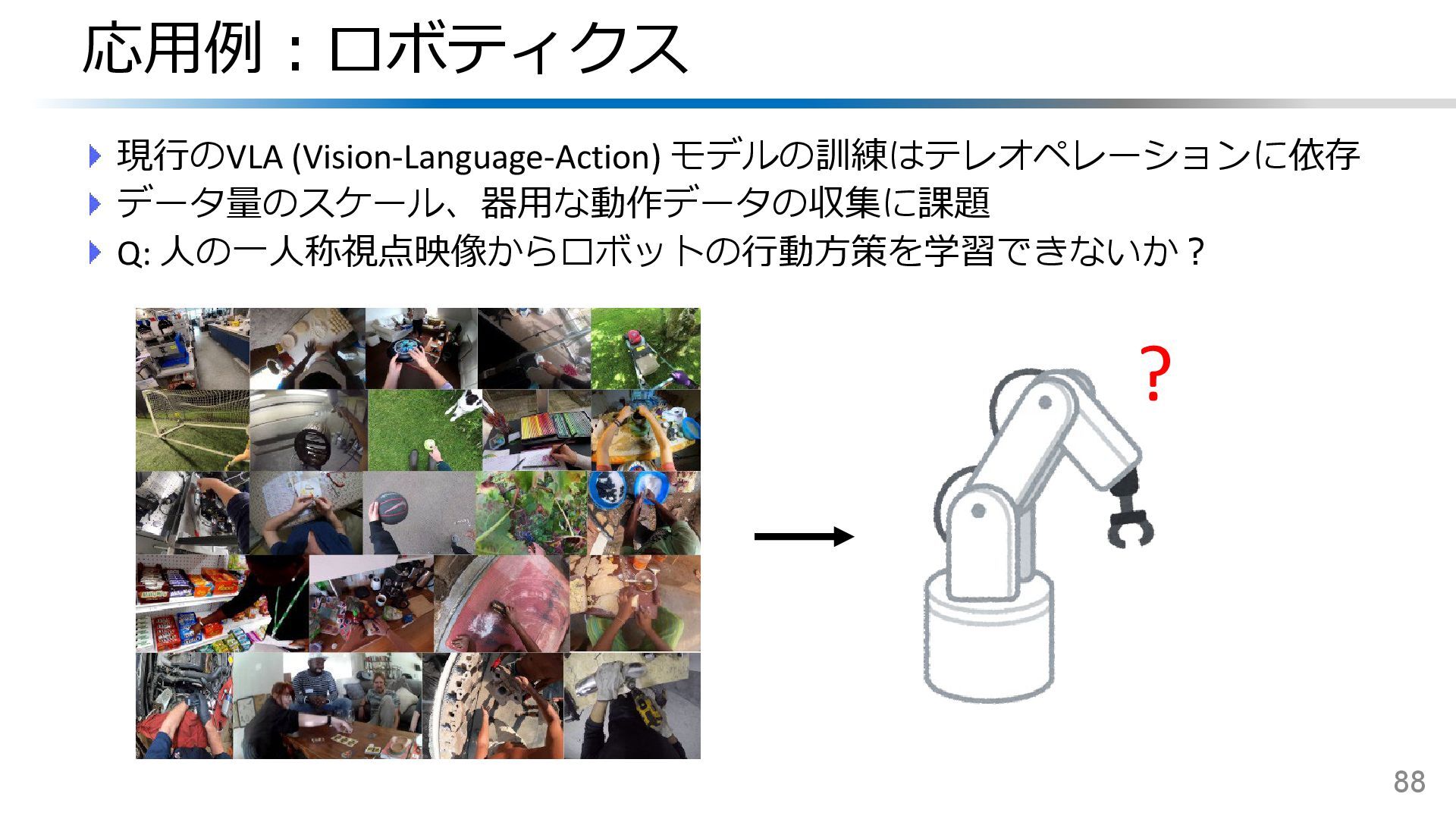{kind=link}
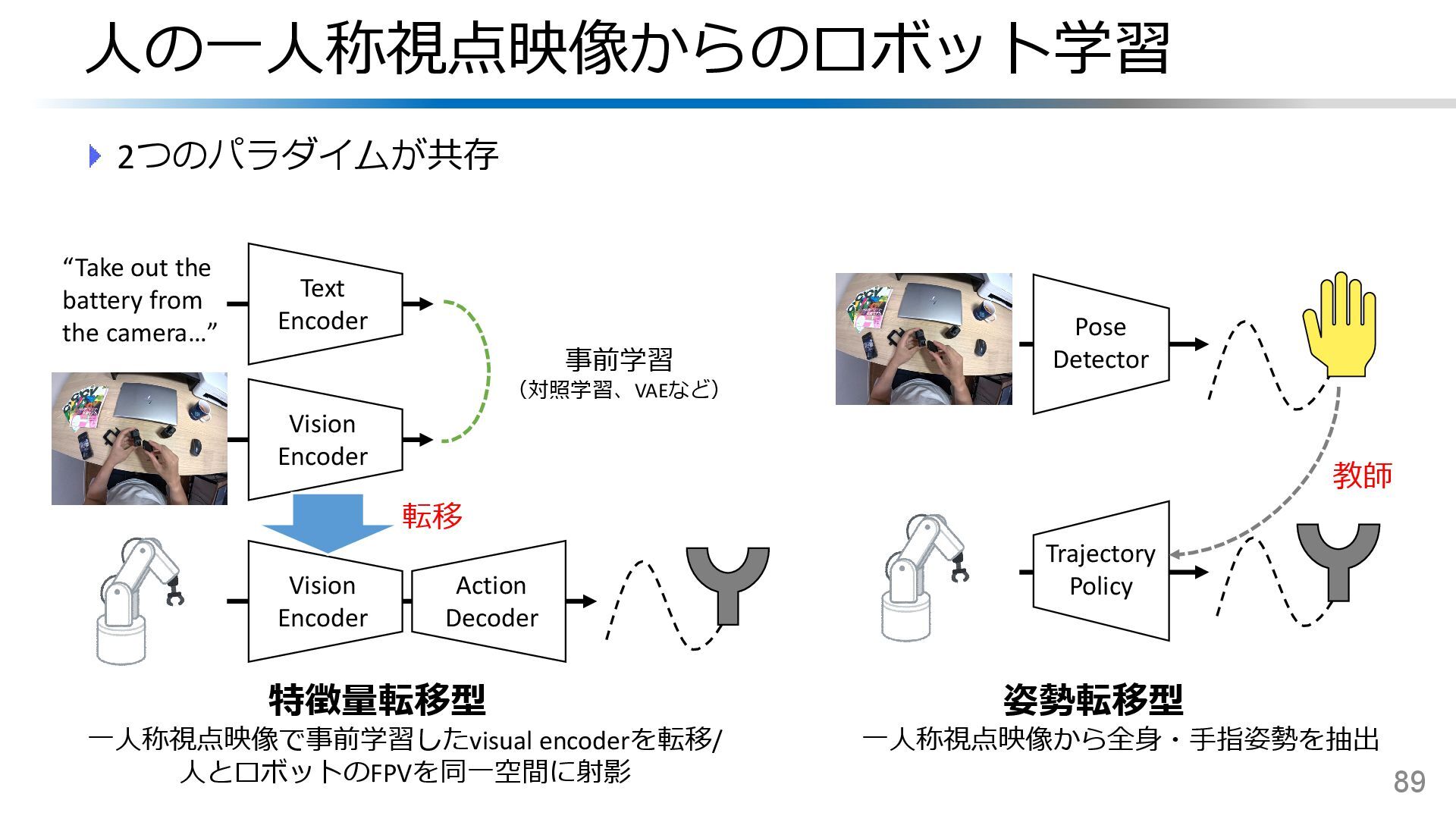{kind=link}
![特徴量転移型 一人称視点映像の背景・タスク・運動の多様性をそのまま視覚特徴学習に利用 汎用性が高い一方関節の制御そのものでの有用性は低い 90 R3M [Nair+, CoRL’22] Ego4Dの教示で時間方向に関する対照学習を行うことで ロボットアーム操作に有用な視覚特徴を学習](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_88.jpg){kind=link}
![姿勢転移型 手指の軌跡データをロボットのハンド部の軌跡学習に利用 高いデータ効率、ただしアクチュエータの違いの吸収の必要あり 同時並行で多数の手法が登場 ZeroMimic [Shi+, ICRA‘25], EgoVLA [Yang+, Arxiv’25],](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_89.jpg){kind=link}
![アフォーダンス推定の利用 人のタスク映像から学習される中間表現(接触点・手の軌跡)をロボットの 行動計画に利用 92 VRB [Bahl+, CVPR’23]](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_90.jpg){kind=link}
![ロボット学習に向けたデータ収集 Apple発の手指アノテーション付き映像データセット 今後も同様の試みが増えるかも? 93 EgoDex [Hoque+, ArXiv‘25] 194のタスクに関する338Kエピソードを収録 Vision Proを利用し手指姿勢(手首の位置回転+指位置)を収集](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_91.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![EgoLife: 長時間・多人数インタラクションの記録 6人の参加者が1日8時間×7日間、同一の建物内で日常生活を行う様子を記録 Aria Glassesによるマルチモーダル計測+15か所の三人称視点映像 97 EgoLife [Yang+, CVPR’25]](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_95.jpg){kind=link}
![EgoLife: 長時間・多人数インタラクションの記録 各人の行動習慣を把握したパーソナルアシスタントを指向 ただし素朴な連続行動記録はプライバシーの問題が大きく現実的ではないかも 98 EgoLife [Yang+, CVPR’25] https://egolife-ai.github.io/blog/](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_96.jpg){kind=link}
{kind=link}
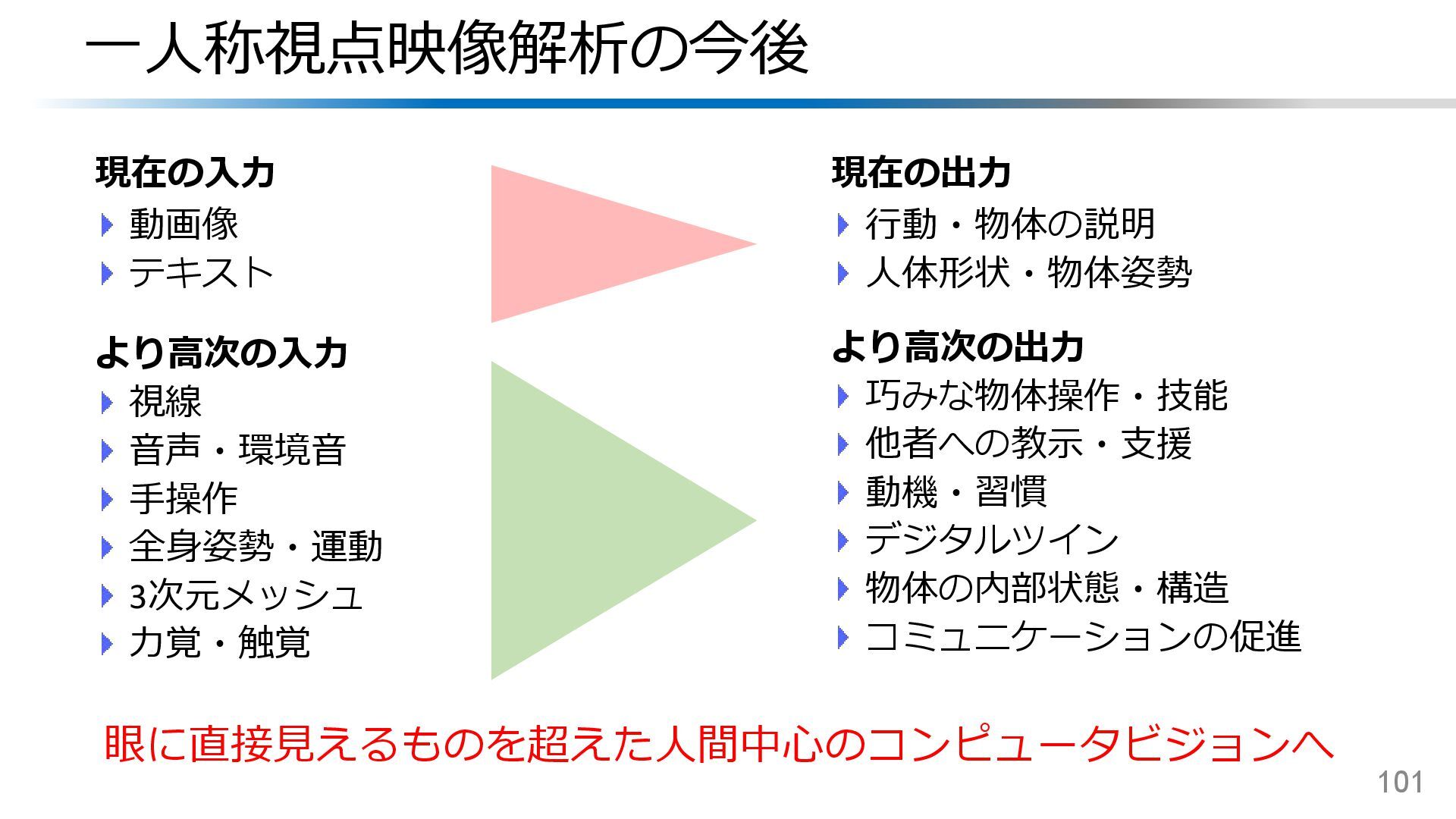
![一人称視点映像解析の現在地 今回扱っていないが重要なトピックは? 音声・音響モデリング(例:EPIC-SOUNDS) リアルタイム・ストリーミング処理(例:ProvideLLM [Chatterjee+, ICCV’25]) ウェアラブルデバイスのユーザビリティ 車載カメラ・ロボット視点映像理解 今後アツいトピックは? 日常生活のためのパーソナル・ウェアラブルAIアシスタントの開発](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_98.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考文献(1/6) [Heilbron+, CVPR'15] Caba Heilbron, F., Escorcia, V., Ghanem, B.,](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_102.jpg){kind=link}
![参考文献(2/6) [Huang+, ECCV’18] Y. Huang, M. Cai, Z. Li and](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_103.jpg){kind=link}
![参考文献(3/6) [Li+, CVPR’23] Li, J., Liu, K., & Wu, J.](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_104.jpg){kind=link}
![参考文献(4/6) [Damen+, ECCV’18] Damen, D., Doughty, H., Farinella, G. M.,](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_105.jpg){kind=link}
![参考文献(5/6) [Pan+, ICCV'23] Pan, X., Charron, N., Yang, Y., Peters,](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_106.jpg){kind=link}
![参考文献(6/6) [Kamikubo+, CHI'25] Kamikubo, R., Kayukawa, S., Kaniwa, Y., Wang,](https://files.speakerdeck.com/presentations/7ace33d6689f468c9dfdca532bcfa0f6/slide_107.jpg){kind=link}