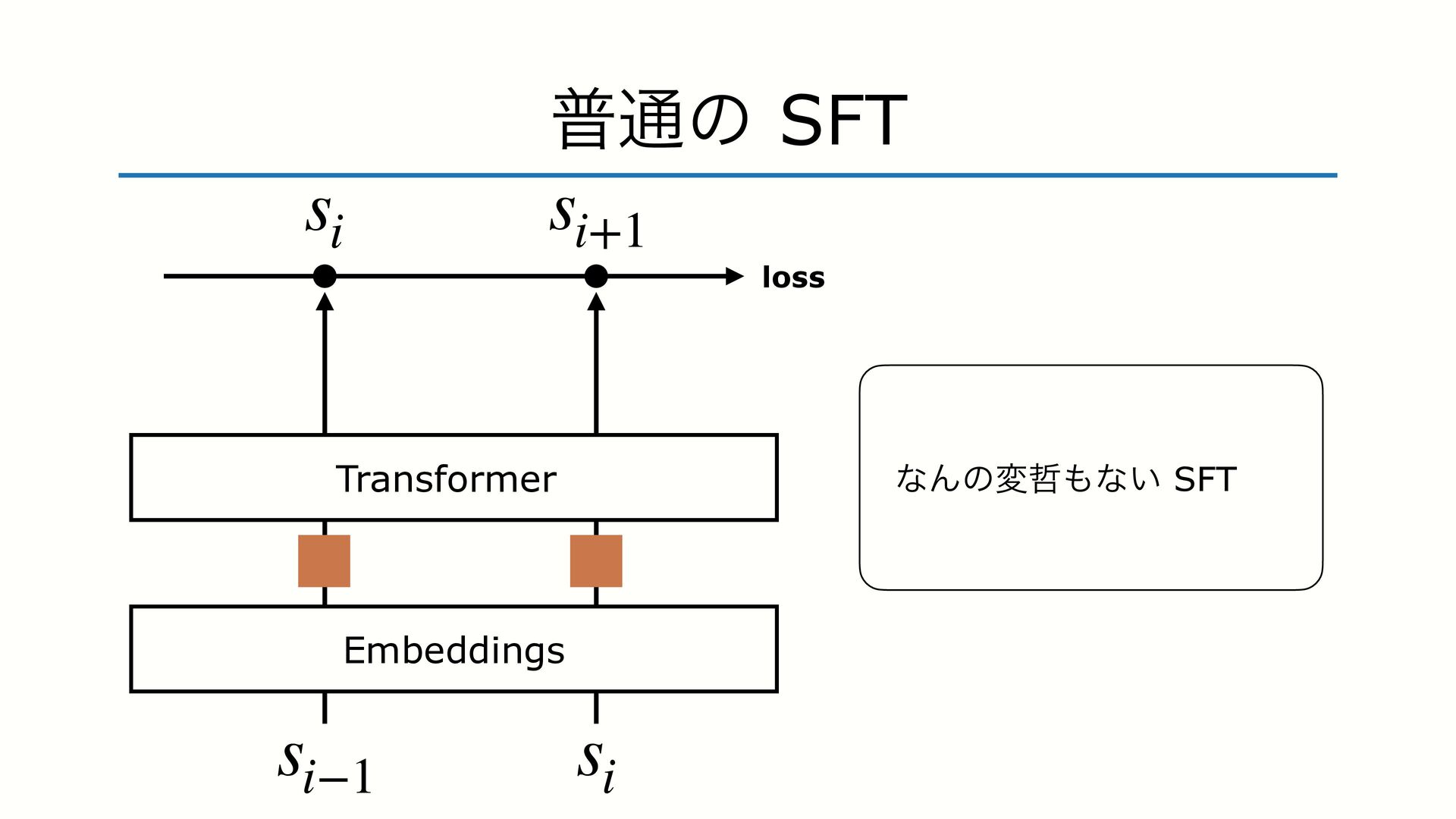
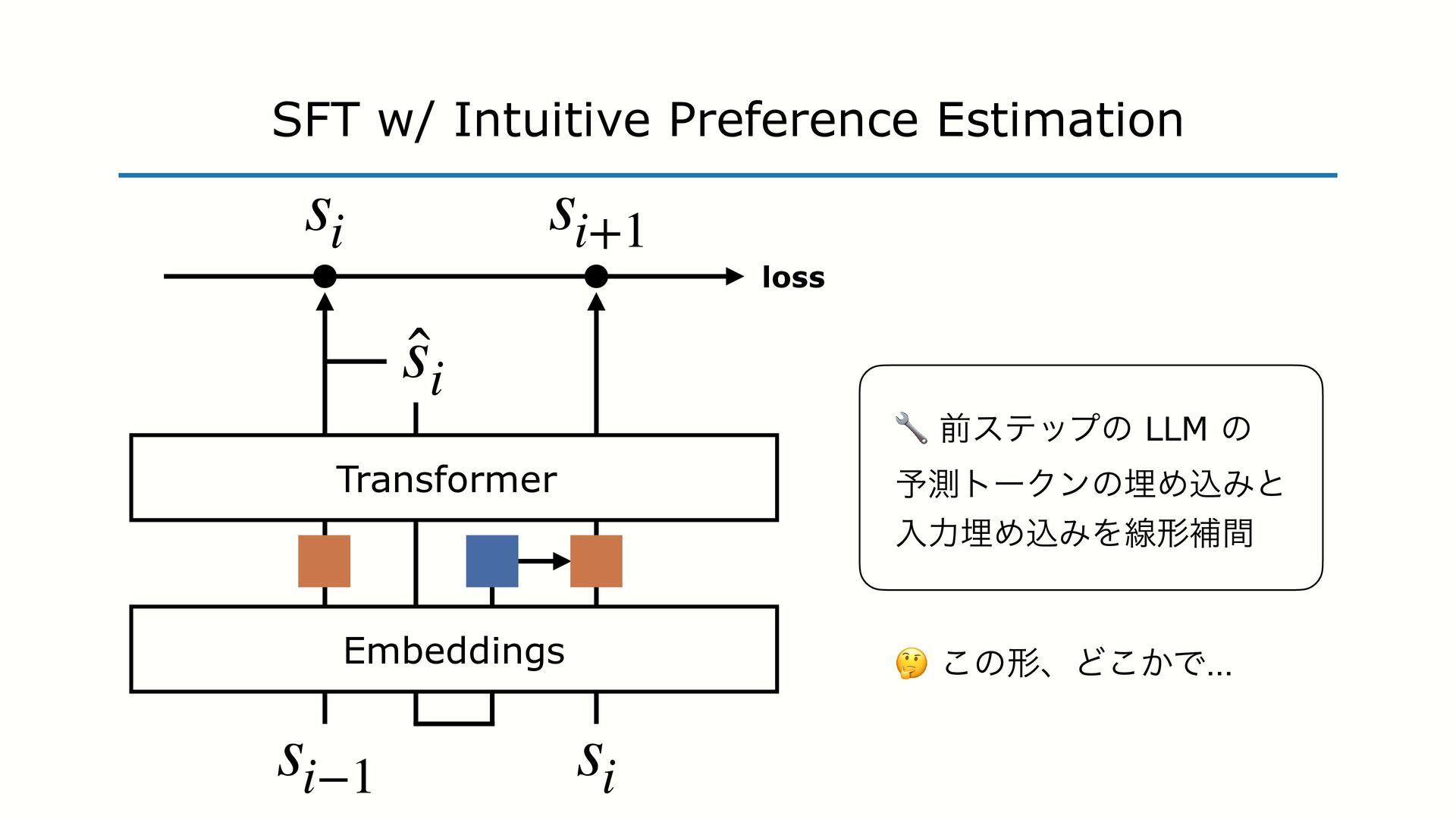
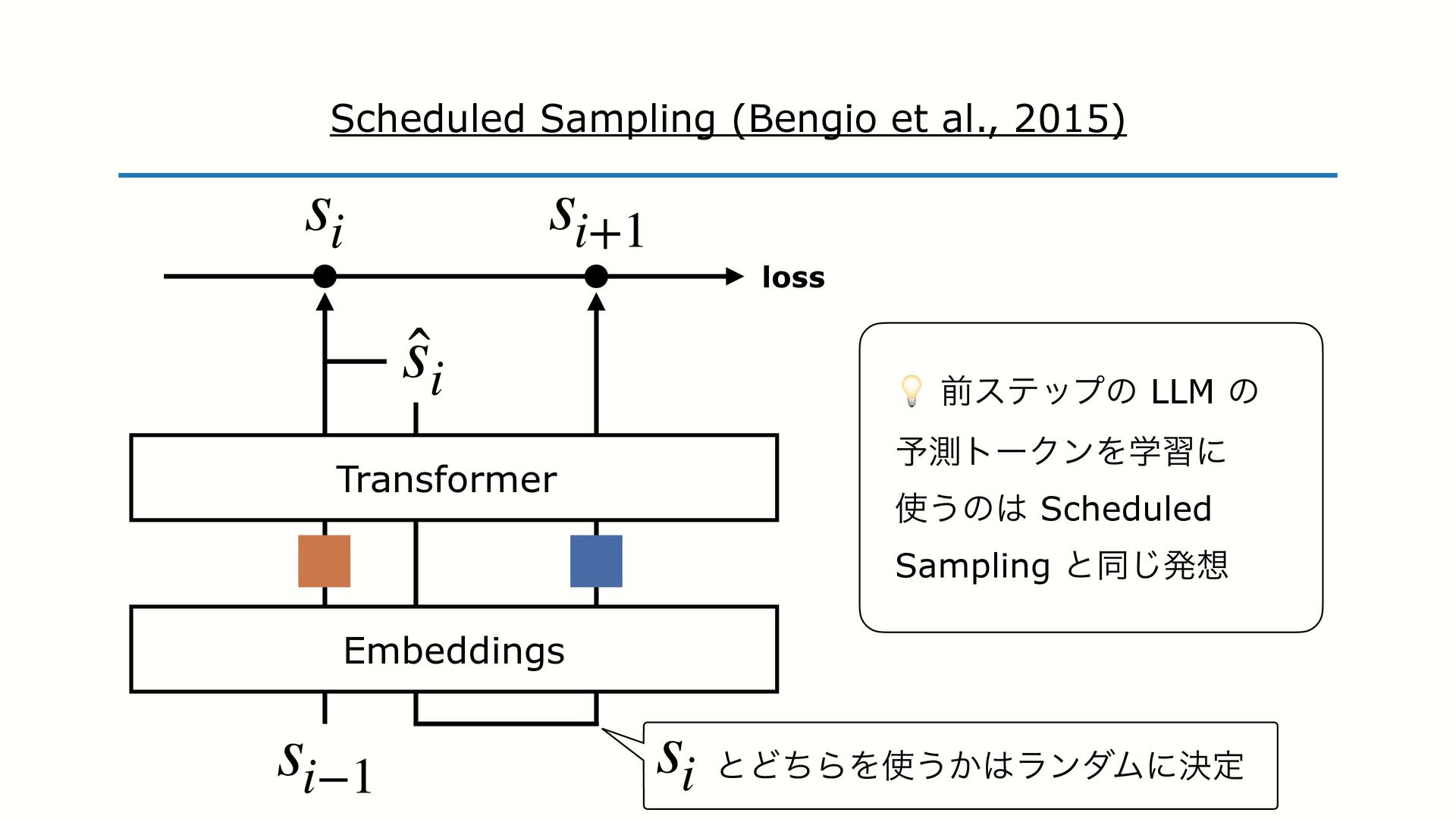
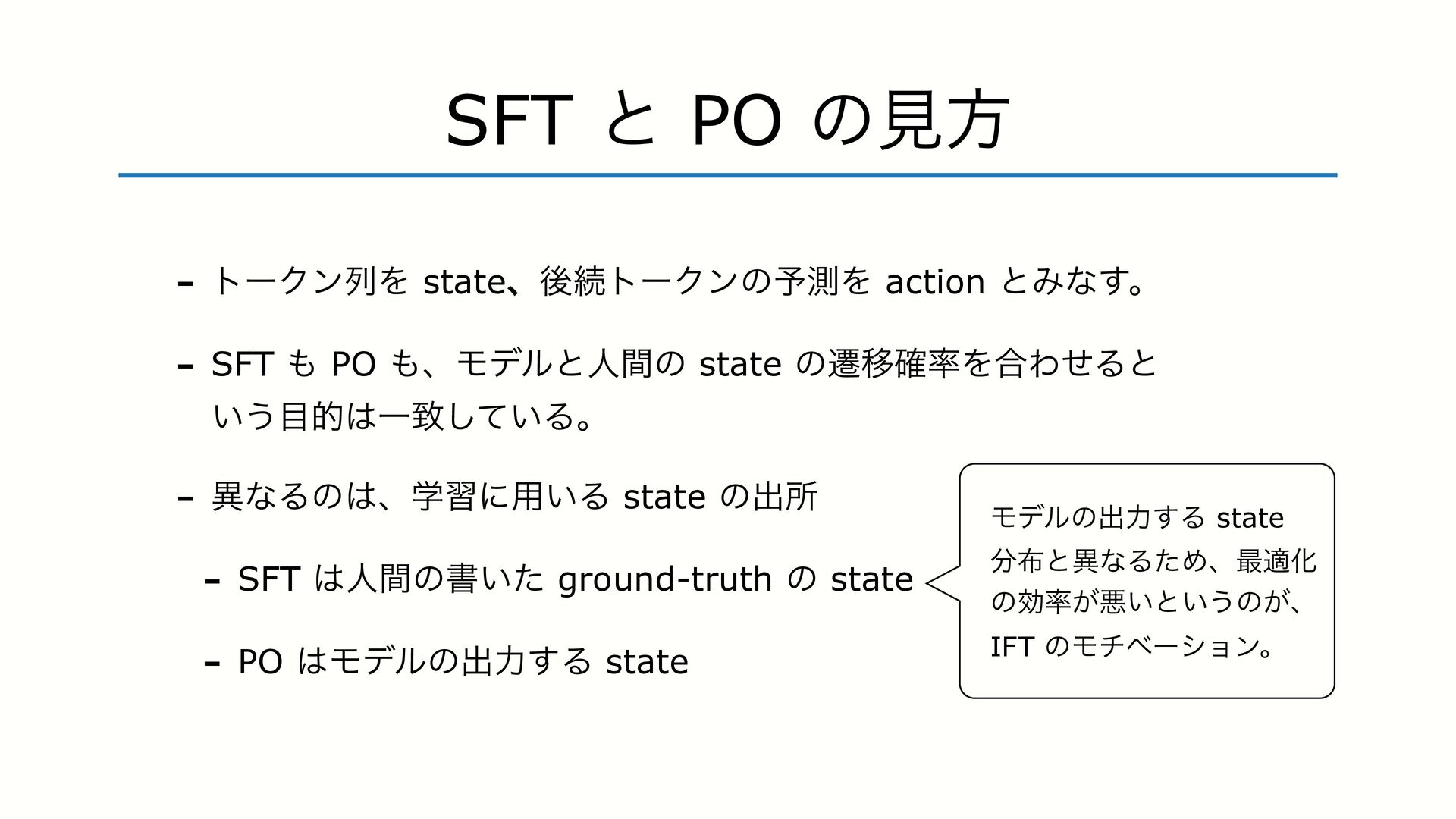
SFT PO ɺϞσϧͱਓؒͷ state ͷભҠ֬Λ߹ΘͤΔͱ ͍͏తҰக͍ͯ͠Δɻ - ҟͳΔͷɺֶशʹ༻͍Δ state ͷग़ॴ - SFT ਓؒͷॻ͍ͨ ground-truth ͷ state - PO Ϟσϧͷग़ྗ͢Δ state Ϟσϧͷग़ྗ͢Δ state ͱҟͳΔͨΊɺ࠷దԽ ͷޮ͕ѱ͍ͱ͍͏ͷ͕ɺ IFT ͷϞνϕʔγϣϯɻ
model/human preference” ͋ͨΓʣ - SFT ͱ PO/RL ͷؔ࿈ʹ͍ͭͯҎԼͷจݙͷํ͕Θ͔Γ͍͢ - DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models - On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}