- (1) - Expressive - Scale without rewriting - Perfect weak horizontal scaling - (1000x problem in 1x time with 1000x CPUs) - Predictable (no nasty RAM surprises) - Robust to small failures
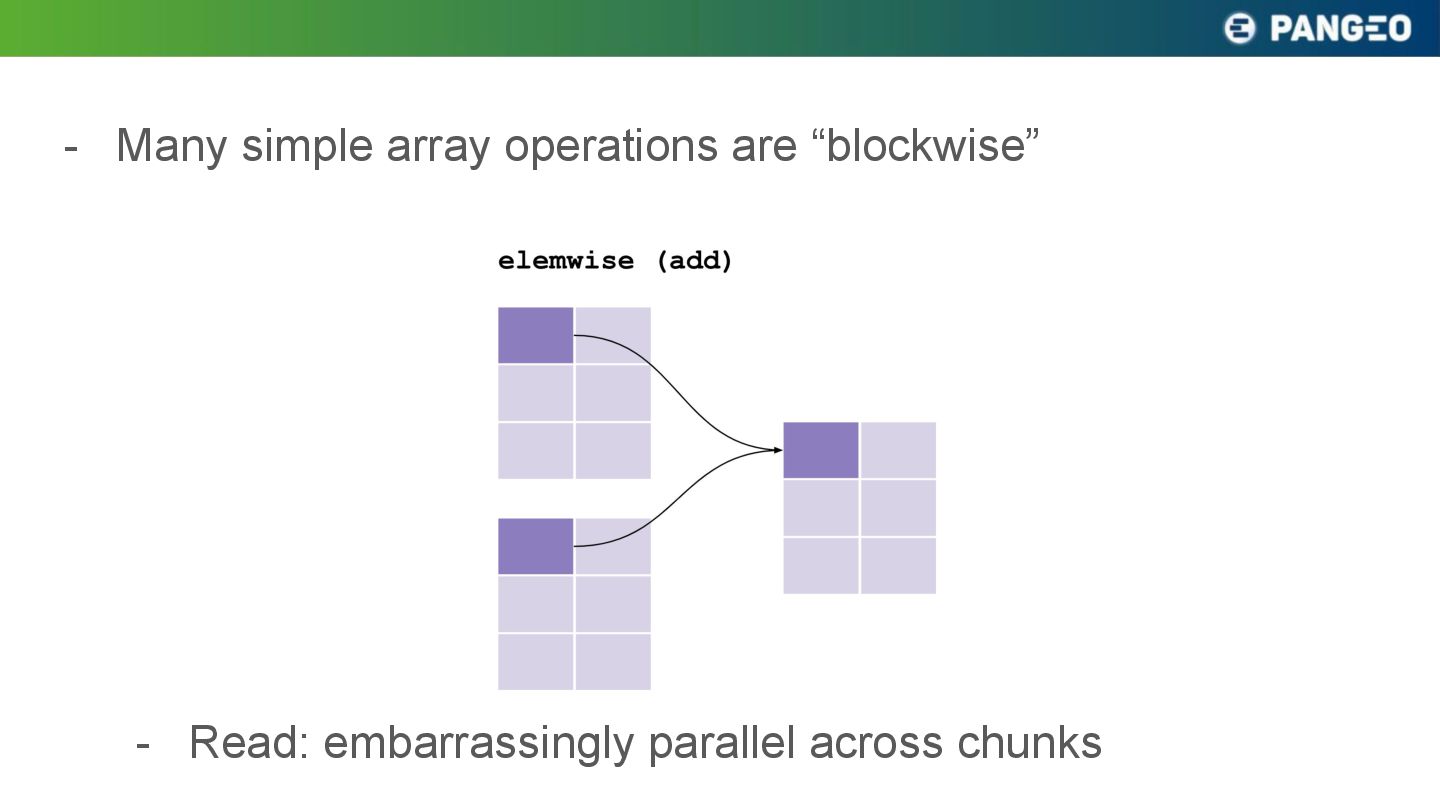
parallel tasks - Just launch them all simultaneously - Ideal fit for ✨Serverless✨ cloud services - e.g. AWS Lambda, Google Cloud Functions - (Means no cluster to manage!)
chunked array type - Install cubed & cubed-xarray - Then specify the allowed memory - (And the location for intermediate Zarr stores) from cubed import Spec spec = Spec(work_dir='tmp', allowed_mem='1GB')
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
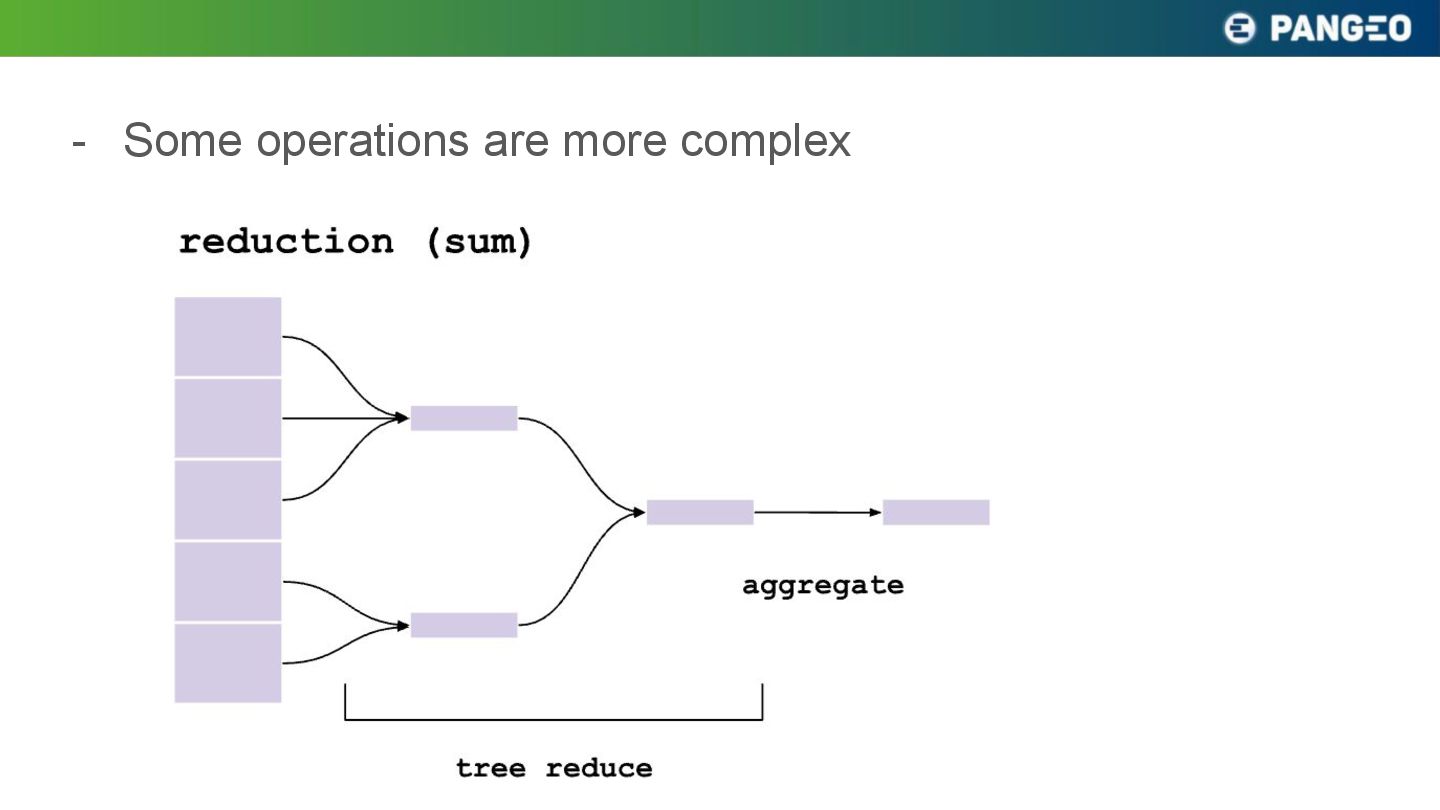{kind=link}
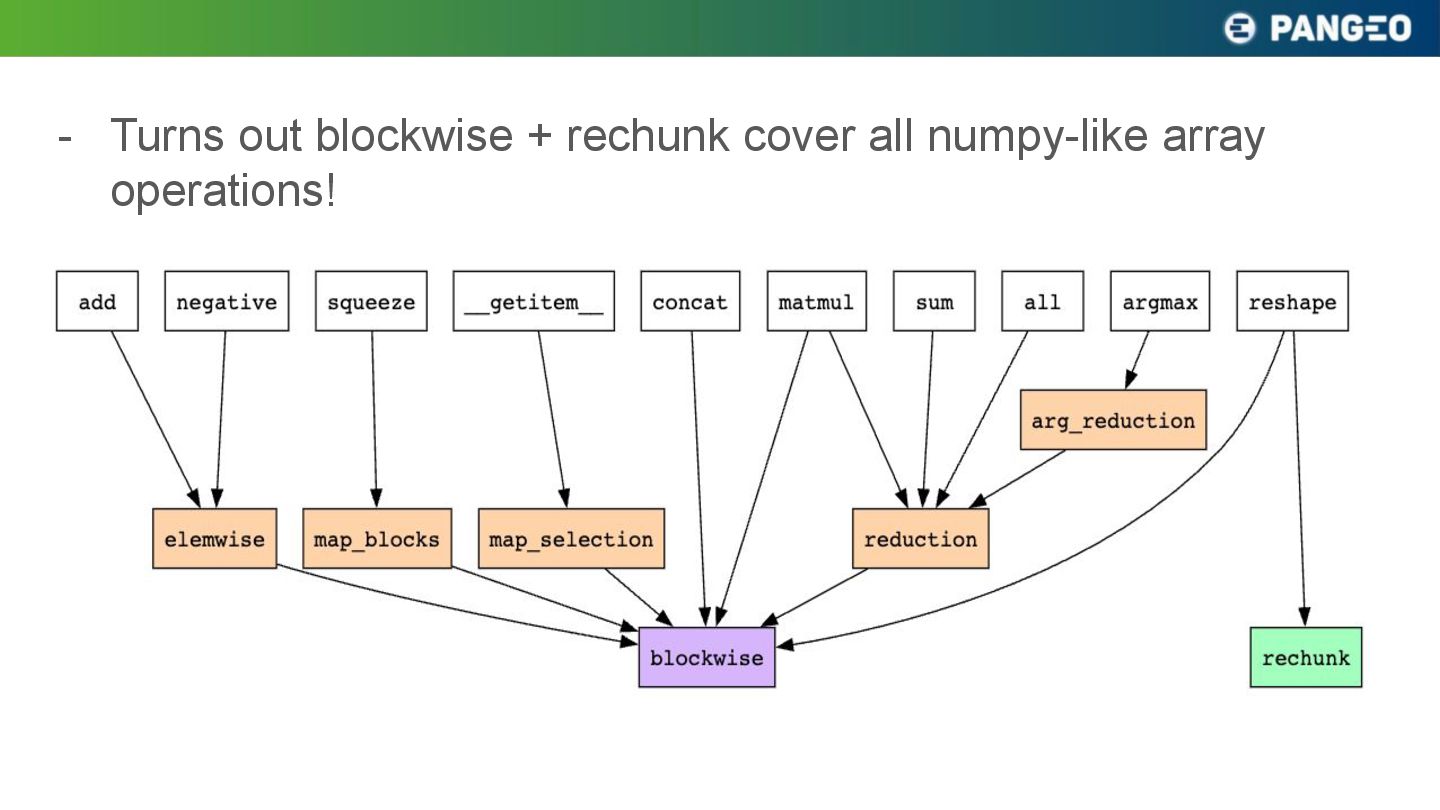{kind=link}
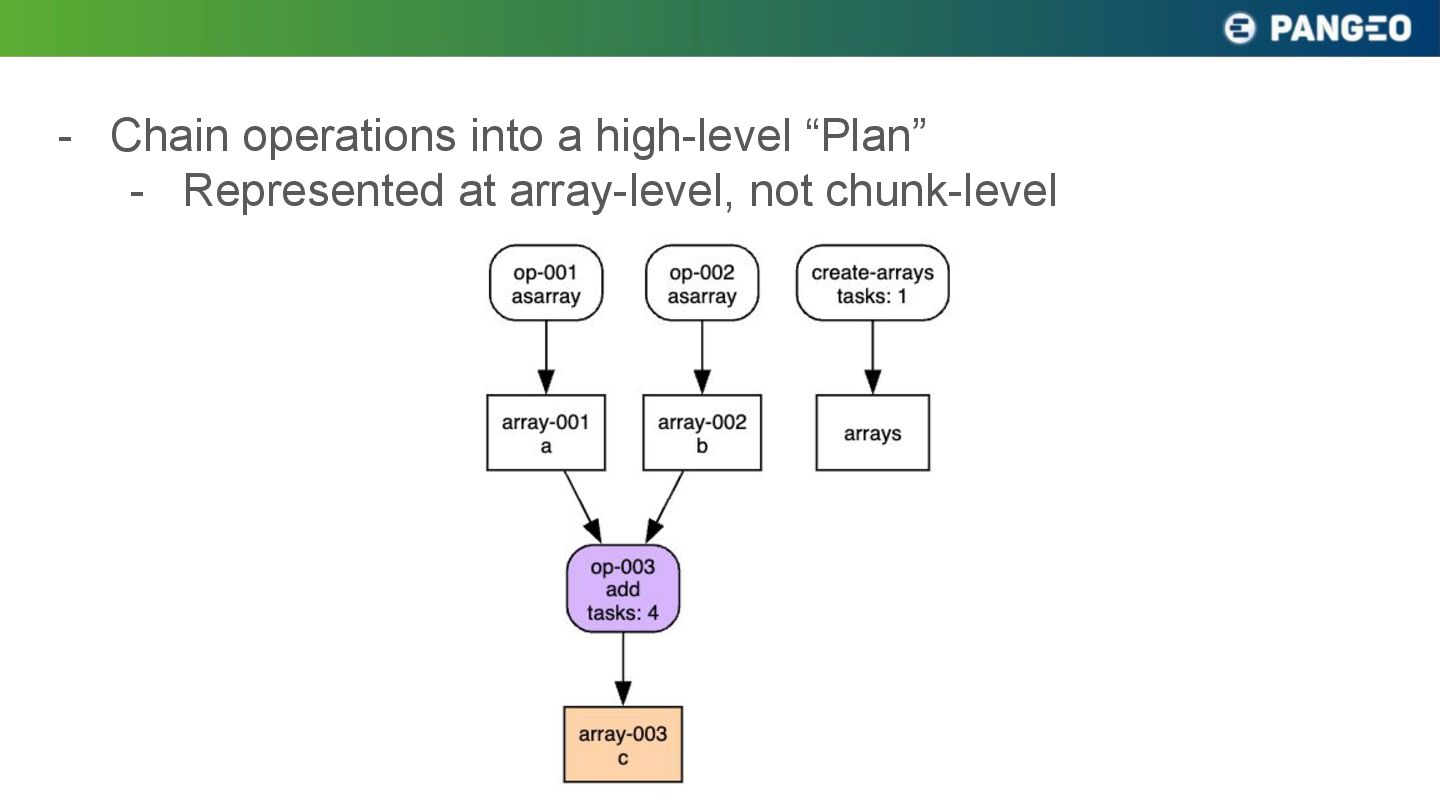{kind=link}
{kind=link}
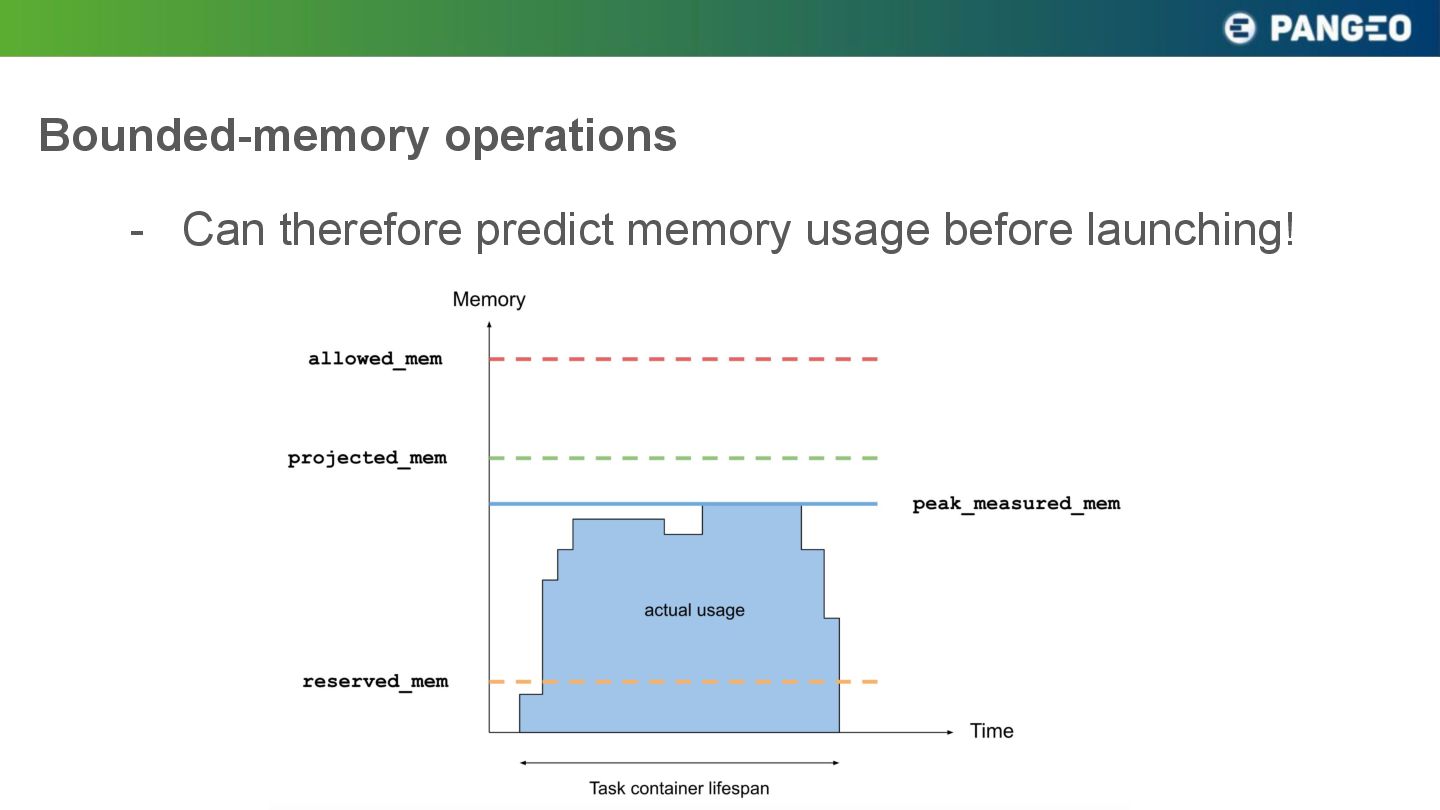{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}