Language Models) LLMs are being introduced in software development Using chat UI LLMs like ChatGPT to create/modify source code Software development assistants using LLMs LLMs fine-tuned/extended for source code Text input to LLMs is called a "prompt," and the output is called a "response." 2
Development Assistants Github Copilot An LLM integrated into the IDE references the code being edited by the developer to generate code and provide responses via chat. Overview of GitHub Copilot, https://docs.github.com/ja/copilot/using-github-copilot/getting-started-with-github-copilot AutoGen Generate code with LLM, execute the generated code, analyze the result with LLM, and return the result to the code generation AI to correct the code... repeat Literature: AutoGen: Enabling next-generation large language model applications, Microsoft Research, 2023- 09-25 Blog https://www.microsoft.com/en- us/research/blog/autogen-enabling-next-generation-large- language-model-applications/ 3
makes the product larger than it appears For example, the rich-cli targeted in the experiment mentioned later is 900 lines by itself but 220,000 lines including libraries. Reuse of libraries can be direct or indirect To identify the cause of issues, it is necessary to analyze including the libraries being used 4
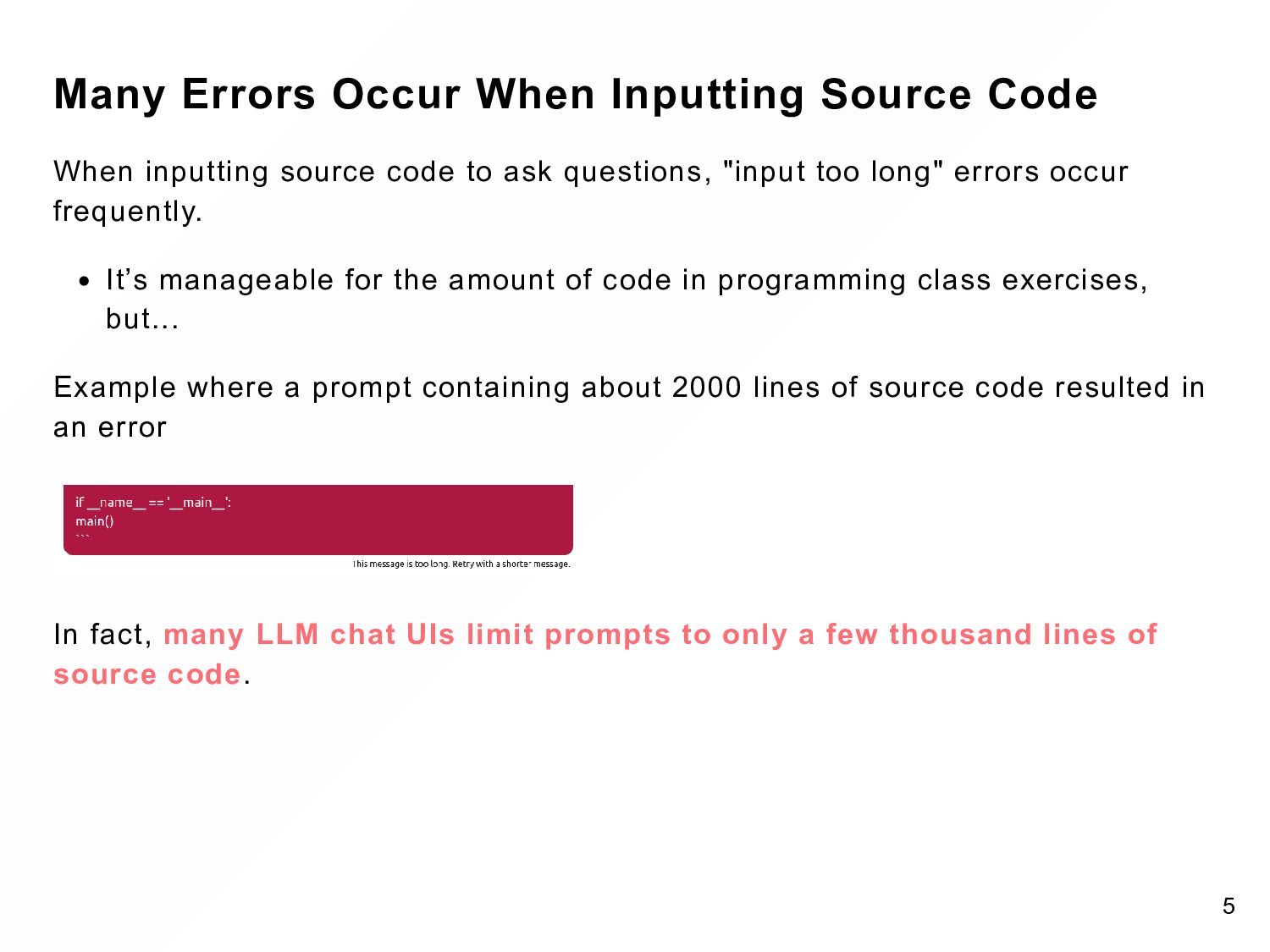
code to ask questions, "input too long" errors occur frequently. It’s manageable for the amount of code in programming class exercises, but... Example where a prompt containing about 2000 lines of source code resulted in an error In fact, many LLM chat UIs limit prompts to only a few thousand lines of source code. 5
does ... The following program does ... import os .... Context LLMs have a limitation on the length of context they can process (context length). If the context length is exceeded, the quality of the responses deteriorates. LLM chat UIs limit the maximum length of prompts. Representative LLM context lengths (many up to 200k tokens) LLM Prompt Length gpt-4 ※1 8k 〜 128k Gemini 1.5 Pro ※2 1m Claude 3 ※3 200k Llama 3 ※4 8k Mistral v0.2 ※5 32k Mixtral v0.1 ※6 64k ※1 https://platform.openai.com/docs/models/ ※2 https://ai.google.dev/gemini-api/docs/models/gemini? hl=ja#gemini-1.5-pro ※3 https://www.anthropic.com/news/claude-3-family ※4 https://huggingface.co/meta-llama/Meta-Llama-3-8B- Instruct ※5 https://huggingface.co/mistralai/Mistral-7B-Instruct- v0.2 ※6 https://mistral.ai/news/mixtral-8x22b/ Cause: Context Length 6
by Increasing Context Length? If the source code is 1 million lines (~7m tokens), can we query using an LLM with a context length of 10m tokens? Problem 1: Calculation time proportional to the square of the context → Cannot easily increase the context length Transformer-based neural networks, used in LLMs, employ a mechanism called attention. Attention determines which tokens in the context the LLM should focus on to generate the next token. Context = prompt and previously generated responses Attention is implemented using attention matrices. The size of the attention matrix grows with the square of the context length. Literature: J. Adrián, G. García-Mateos. "Preliminary Results on Different Text Processing Tasks Using Encoder-Decoder Networks and the Causal Feature Extractor" Applied Sciences 10, no. 17: 5772. https://doi.org/10.3390/app10175772 (2020). 7
1) Fig: Accuracy of Responses Relative to Context Length (quoted from Literature 2) Solve by Increasing Context Length? Problem 2: Needle in a Haystack Problem Various efforts to reduce computation costs by sparsifying the attention matrix to increase context length have been proposed. However, even with long-context LLMs, the quality of inference decreases as the input text length increases. Identifying necessary parts to answer the question becomes harder with longer input text. Literature 1: Jiayu Ding et al., "LongNet: Scaling Transformers to 1,000,000,000 Tokens," https://www.microsoft.com/en-us/research/publication/longnet-scaling-transformers-to-1000000000- tokens/, 2023. Literature 2: M. Levy, A. Jacoby, Y. Goldberg, "Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models," arXiv:2402.14848v1, 2024. 8
Search ① Retrieval: Search for documents related to the question Various retrieval methods, such as web search and semantic vectors ② Generation: Input the question and documents into the LLM to generate a response Benefits of RAG Enables inquiries about documents not in the training data Reduces hallucinations (responses are backed by documents) User Question Answer Prompt Response User Question Answer Prompt Response Information retrieval LLM LLM User Question Information retrieval 9
→ Reduce the amount of source code input to the LLM +α: Arrange the source code according to the order in which functions are called → Make it easier for the LLM to understand by reading the source code from top to bottom Source Code of Only the Functions Called During Execution Order in Which Functions Were Called Product Execution Proposed Method RAG that extracts only the source code related to the execution of the product 10
Step 2. Identify the executed functions and their call relationships Step 3. Obtain the locations of functions in the source code Step 4. Create a call tree representing the function call relationships Step 5. Input the query text, call tree, and corresponding source code as a prompt to the LLM and generate a response Processing of the Proposed Method Product Source Files Run & collect execution trace Identify Call Relationships Obtain Code Locations Build Call tree Execution trace Call Tree Source Code Response LLM Prompt User Query Reproduction Conditions ※ This part was added based on the Q&A session. 11
source product): Specific queries assumed to occur in software development Criteria for evaluating the quality of responses to those queries 4 queries ✕ 5 variations of the proposed method’s prompt ✕ 3 LLMs = 60 generations in total Queries: Prompts 1 to 4, with increasing difficulty Experiment 1: Identify which parts of the proposed method contribute to the quality of responses Experiment 2: Compare the context size reduction against the original source code 12
Gemini 1.5 Pro 1M Claude 3 Sonnet 200K ChatGPT-4 128k Due to the large size of the original source code, even withthe selective process by RAG, LLMs with long contexts were required. The latest and highest models from each company at the time of the experiment. ※ However, for Claude 3 Sonnet, the top-tier model Opus with 200K context was not available at the time of the experiment, so the lower-tier model Sonnet was used. 13
in formats like CSV, Markdown, and ReStructuredText as input and formats them for terminal output. Reason for selection: Rich functionality suitable for experiments. As a CLI tool, it ensures reproducibility in execution. 14
text, call tree, and source files in the prompt, but variants were prepared by removing/changing each component. Variant Query Call Tree Source Files full ◯ ◯ ◯ (in order of function calls) A ◯ (alphabetical order) C × ◯ (in order of function calls) CA ◯ (alphabetical order) T ◯ × The prompt of the proposed method is "full" In variant "CA", the call tree is not included, and the source files are in alphabetical order, so information about the order of function calls is not included. In the version where source code is arranged "in the order of function calls," the source code of a function is included multiple times if it is called from different functions. Alphabetical order includes the source code of a function only once. 15
feature that formats a CSV file into a table for output. Can you tell me functions related to the appearance of the table?" "Show the call tree and source code." 16
of the feature that formats and displays CSV files in the terminal. Scoring Criteria (1.0 point each for ①〜④) ① Output the names of classes and functions implementing the feature ② Explain that appearance elements of the table include not only borders but also colors and padding ③ Output the content of changes (modified code or how to modify) ④ Output the locations to be changed by function names Results Many cases achieved a perfect score of 4.0 Parts marked with "*" indicate potential data contamination Responses included identifiers not present in the prompt Prompt 1 17
for testing is inadvertently included in the training data Commercial LLMs often do not disclose their training data, making it difficult to directly confirm data contamination Some reports indicate that LLM performance drops on new benchmarks specifically created to avoid contamination Literature: Hugh Zhang et al., "A Careful Examination of Large Language Model Performance on Grade School Arithmetic," arXiv:2405.00332v3, 2024. 18
of the feature that formats and displays Markdown files containing tables in the terminal. Scoring criteria are the same as Prompt 1 Similar to Prompt 1, but Markdown files have more formats than CSV files, making related code more extensive and the task more challenging The prompt size also doubled (discussed later) Results The numbers marked with * indicate that the name of a global variable not included in the call tree wasincluded in the response. Overall, the evaluation scores decreased For each LLM, full or A achieved the highest evaluation scores Prompt 2 19
and displaying Markdown files containing tables) Scoring Criteria (1.0 point each for ①〜④) ① Explain differences and commonalities in implementation ② Indicate names of important functions or methods showing differences in control flow ③ Explain differences in data structures used by class names ④ Explain differences in features related to tables (e.g., right alignment) The prompt includes outputs of both executions The prompt length is the maximum (discussed later) Results The low evaluation score of ChatGPT-4's full prompt is noticeable Likely due to the prompt length approaching the LLM's context limit Prompt 3 20
command line but not when provided via a file. Ask for the cause and how to fix it. Scoring Criteria (1.0 point each for ①〜④) ① Output the cause ② Output the content of changes ③ Output the locations to be changed by function names ④ Output a modification plan reusing existing features Includes two executions Inquires about design knowledge Where to add features Implement functionality while reusing existing features Results Full achieved the highest evaluation scores for all LLMs For ChatGPT-4, all variants had the same score Prompt 4 21
Gemini 1.5 Pro Claude 3 Sonnet ChatGPT-4 AVE1 AVE2 Experiment 1 Analysis "Which parts of the proposed method contribute to response quality?" Graph averages evaluation scores of prompts 1 to 4 for each variant (full, A, C, CA, T). Black (AVE1, AVE2): Average scores for all LLMs AVE2 excludes suspected data contamination Other colors represent scores for each LLM Overall (AVE) Trends Variants with source code (full or A) > without source code (T) Among those with source code (full, A, C, CA), those with function call order (full or A) > without it (C) Among full, A, and C, those with call trees (full or A) > without them (C) 22
the original source code?" Compared to the original product (220,000 lines),```markdown variants full even reduced the context size to less than 1/20 Even if developers could pinpoint the necessary source files without excess or deficiency (since the proposed method extracts by function definition), the size would still be smaller Comparison with LLM context lengths For prompt 3 variant full, the prompt length approached nearly 70% of ChatGPT-4's context length, possibly affecting response quality. 23
and includes only functions called during execution and their call order in the prompt Call order is also provided as a call tree Experiment applied to a 220,000-line Python program Call tree, source code, and function arrangement affect response quality Effectively reduces context size Sufficient LLM context length is necessary Challenges and Future Work Long context LLMs are emerging even in open-source models Conduct broader application experiments on more extensive products 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}